DevOps — это не автоматизация

Расскажу немного про наши (DevOps) процессы в компании.
Техничка
Наш DevOps отдел поддерживает все технологические процессы Отдела разработки.
Также выполняем запросы от остальных департаментов компании.
Nuget хранилище и Docker Registry также находятся в Gitlab.
Почти все бинарники как для Linux окружений так и для Windows собираются в Kubernetes.
Кластеры строятся на минимальных конфигурациях: 3 мастера + n..workers.
Разворачиваются с помощью Ansible плейбуков по требованию.
Вся инфраструктура лежит в Git. Используется подход Iac.
Всё, от конфигурирования DNS серверов до установки обновлений на Linux хосты, всё управляется через CI.
Инфраструктура состоит как из Linux окружений так и Windows.
Всё мониторится посредством Prometheus, Node Exporter, Grafana + доп экспортеры.
Многие компании используют тот же Slack (мы раньше тоже его использовали) и этого им вполне хватает.
Мы же перешли на self-hosted решения по причине нестабильности работы слака (как и многих других online-сервисов) еще в 19 году, во время начала пандемии.
Тогда наблюдались сильные проблемы в работе всех публичных online-сервисов.
Платформы просто не справлялись с такими массовыми наплывами потоков пользователей.
Но даже после того как нагрузки стабилизировались, мы всё равно остались на self-hosted решениях.
Работают всё же они стабильнее, плюс вся переписка и переговоры ведутся внутри компании.
Также, Mattermost используется для автоматического сбора метрик и алертов от инфраструктуры, сборок и пр.
Туда же автоматом падают ссылки на релизы для бизнеса, во время выпуска.
Многие используют сейчас и ранее использовали Облачные сервисы.
Мы пробовали работать с ними, но быстро поняли, что возможностей облака не хватает для работы наших продуктов, в силу специфики самих продуктов.
Поэтому мы используем свои мощности.
Плюс еще в том, что вы можете полностью управлять всей инфраструктурой, нагрузками, чего нельзя в полной мере сделать при работе с Облачными сервисами.
Тестовая инфраструктура расположена на мощностях VMware Vsphere в купе с Terraform (ноды и дисковые пулы мониторятся теми же Prometheus, Grafana).
Это много упрощает развертывание стендов, так как все они разворачиваются из Gitlab.
За минуты разворачивается необходимое окружение и туда же с помощью того же Gitlab можно накатить тестируемый продукт, без необходимости ручной установки.
В итоге тестировщик получает готовый стенд и, не тратя лишнее время на ручное развертывание, может выполнять свою работу.
На всех сборках настроены автотесты. Написанные как разработчиками, так и командами тестировщиков и DevOps.
Пишите как можно больше тестов!
Это позволяет иметь на выходе более стабильный продукт, уменьшать время поиска и устранения ошибок.
В ранее упомянутый Mattermost падают алерты о сломанных сборках, и DevOps инженер уже в курсе где, что сломалось. В итоге проблема чаще всего устраняется еще до того, как пользователь захочет завести задачу в Jira или написать о проблеме в мессенджер.
Для хранения секретов и паролей используется Hashicorp Vault.
Основное применение у нас, в CI сборках, позволяет не хранить секреты и пароли в репозиториях.
Практики
Взаимодействие между командами является одним из главнейших механизмов направления DevOps в нашей компании.
Каким бы мощным не был технологический стек и как сильно не был бы автоматизирован весь процесс, без прямого взаимодействия между командами желаемого результата будет достичь довольно трудно.
Как раз это взаимодействие и поддерживается с помощью Mattermost и BigBlueButton. Это еще один плюс в копилку self-hosted инструментов.
Так как на них не влияют внешние факторы, можно полностью сосредоточиться на рабочем процессе.
Еще хочется отметить, что при построении инфраструктуры и ее компонентов, не стоит сильно ее усложнять. Там где это возможно, необходимо настраивать простые и надежные сервисы. Не писать огромные скрипто-комбайны, чтобы не тратить потом свое время и время коллег на поиск причины аварии. А если таковые всё же существуют, особенно legacy, постарайтесь уйти от этих инструментов, переписать, заменить. Проще говоря улучшить технологический процесс.
Все процессы, происходящие внутри компании и поддерживаемые нашим отделом, носят очень занимательный характер. Иногда приходится совмещать несовмещаемое и автоматизировать не автоматизируемое. Но на выходе получается довольно стабильный и интересный продукт.
Заключение
В заключение хотелось бы сказать.
Автоматизировать можно всё, но не всё можно нужно автоматизировать.
Хотя мое мнение не стоит на том, что DevOps это только автоматизация.
Использование всех практик и методологий DevOps, в купе с хорошо налаженной коммуникацией внутри компании, принесут довольно быстро желаемый результат.
Если вам близка тема, пожалуйста, поделитесь своим опытом в комментариях. Спасибо за проявленное внимание.
Руководство для чайников: создание цепочек DevOps с помощью инструментов с открытым исходным кодом
Создание первой цепочки DevOps за пять шагов для новичков.
DevOps стал панацеей для слишком медленных, разобщенных и прочих проблемных процессов разработки. Но нужны минимальные познания в DevOps. Здесь будет рассмотрены такие понятия, как цепочка DevOps и как создать ее за пять шагов. Это не полное руководство, а только “рыба”, которую можно расширять. Начнем с истории.
Мое знакомство с DevOps
Когда-то я работал с облаками в Citi Group и разрабатывал веб-приложение IaaS, чтобы управлять облачной инфраструктурой Citi, но мне всегда было интересно, как можно оптимизировать цепочку разработки и улучшить культуру среди разработчиков. Грег Лавендер, наш техдиректор по облачной архитектуре и инфраструктуре, посоветовал мне книгу Проект «Феникс». Она прекрасно объясняет принципы DevOps, при этом читается, как роман.
В таблице на обороте показано, как часто компании выкатывают новые версии:
Как Amazon, Google и Netflix успевают столько выкатывать? А все просто: они поняли, как создать почти идеальную цепочку DevOps.
У нас в Citi все было совсем не так, пока мы не перешли на DevOps. Тогда у моей команды были разные среды, но поставку на сервер разработки мы делали вручную. У всех разработчиков был доступ только к одному серверу разработки на базе IBM WebSphere Application Server Community Edition. При одновременной попытке поставки сервер “падал”, а нам приходилось каждый раз “болезненно” договариваться между собой. А еще у нас было недостаточное покрытие кода тестами, трудоемкий ручной процесс поставки и никакой возможности отслеживать поставку кода по некоторой задаче или требованию клиента.
Было понятно, что нужно срочно что-то делать, и я нашел коллегу-единомышленника. Мы решили вместе создать первую цепочку DevOps — он настроил виртуальную машину и сервер приложений Tomcat, а я занялся Jenkins, интеграцией с Atlassian Jira и BitBucket, а также и покрытием кода тестами. Проект был успешным: мы полностью автоматизировали цепочку разработки, добились почти 100% бесперебойной работы сервера разработки, могли отслеживать и улучшать покрытие кода тестами, а ветку Git можно было привязать к поставке и задаче Jira. И почти все инструменты, которыми мы строили цепочку DevOps, были открытым исходным кодом.
По факту, цепочка была упрощенной, ведь мы даже не применяли расширенные конфигурации с помощью Jenkins или Ansible. Но у нас все получилось. Возможно, это следствие принципа Парето (он же правило 80/20).
Краткое описание цепочки DevOps и CI/CD
У DevOps есть разные определения. DevOps, как и Agile, включает в себя разные дисциплины. Но большинство согласятся с следующим определением: DevOps — это метод, или жизненный цикл, разработки ПО, главный принцип которого — создание культуры, где разработчики и другие сотрудники “на одной волне”, ручной труд автоматизирован, каждый занимаются тем, что лучше всего умеет, возрастает частота поставок, повышается продуктивность работы, увеличивается гибкость.
И хотя одних только инструментов недостаточно для создания среды DevOps, без них не обойтись. Самым важным из них является непрерывная интеграция и непрерывная поставка (CI/CD). В цепочке для каждого окружения есть разные этапы (например, DEV (разработка), INT (интеграция), TST (тестирование), QA (контроль качества), UAT (приемочное тестирование пользователями), STG (подготовка), PROD (использование)), ручные задачи автоматизированы, разработчики могут делать качественный код, делают его поставку и могут легко перестраиваться.
Данная заметка описывает, как за пять шагов создать цепочку DevOps, как показано на картинке ниже, с помощью инструментов с открытым исходным кодом.
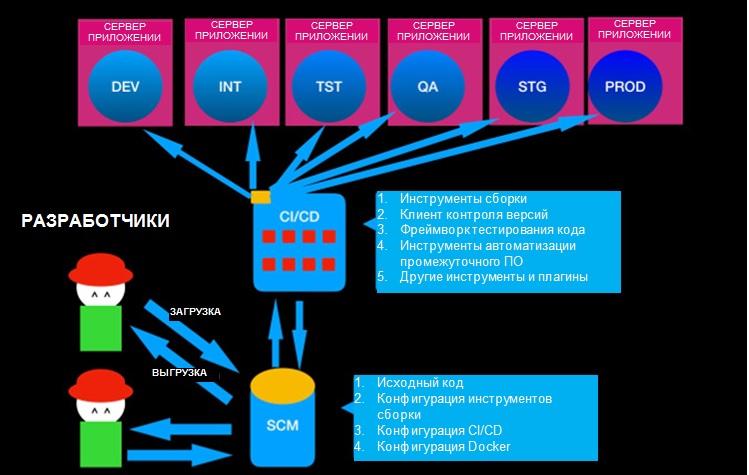
Шаг 1: Платформа CI/CD
Первым делом вам нужен инструмент CI/CD. Jenkins — это открытый инструмент CI/CD написанный на Java с лицензией MIT, с которого началась популяризация движения DevOps и который де-факто стал стандартом для CI\CD.
А что такое Jenkins? Представьте, что у вас есть волшебный пульт управления для самых разных сервисов и инструментов. Сам по себе инструмент CI/CD, типа Jenkins, бесполезен, но с разными инструментами и сервисами он становится всемогущим.
Кроме Jenkins есть множество других открытых инструментов, выбирайте любой.
Вот как выглядит процесс DevOps с инструментом CI/CD

У вас в localhost есть инструмент CI/CD, но делать пока особо нечего. Перейдем к следующему шагу.
Шаг 2: управление версиями
Лучший (и, пожалуй, самый простой) способ проверить магию инструмента CI/CD — интегрировать его с инструментом контроля версий (source control management, SCM). Зачем нужен контроль версий? Допустим вы делаете приложение. Вы пишете его на Java, Python, C++, Go, Ruby, JavaScript или на любом другом языке, коих вагон и маленькая тележка. То, что вы пишете, называется исходным кодом. Поначалу, особенно если вы работаете в одиночку, можно сохранять все в локальный каталог. Но когда проект разрастается и к нему присоединяется больше людей, вам нужен способ делиться изменениями в коде, но при этом избежать конфликтов при слияниях изменений. А еще вам нужно как-то восстанавливать предыдущие версии без использования резервных копий и применения метода copy-paste для файлов с кодом.
И тут без SCM никуда. SCM сохраняет код в репозиториях, управляет его версиями и координирует его среди разработчиков.
Инструментов SCM немало, но стандартом де-факто заслуженно стал Git. Я советую использовать именно его, но есть и другие варианты.
Вот как выглядит пайплайн DevOps после добавления SCM.
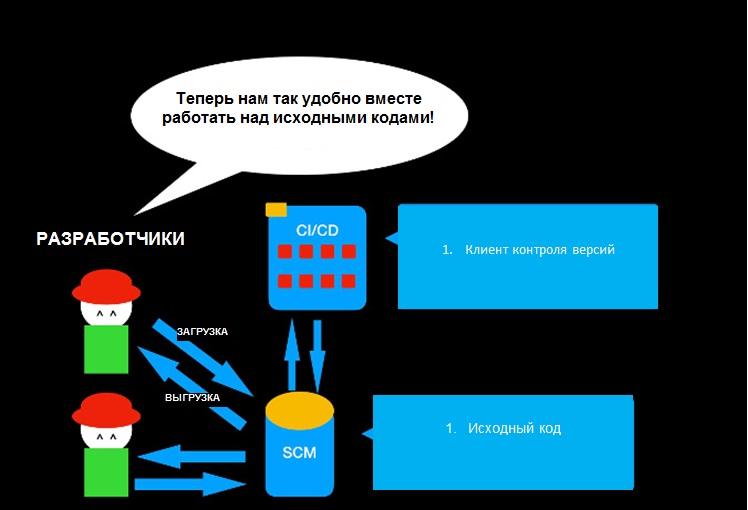
Инструмент CI/CD может автоматизировать загрузку и выгрузку исходного кода и совместную работу в команде. Неплохо? Но как теперь из этого сделать рабочее приложение, любимое миллиардами пользователей?
Шаг 3: инструмент автоматизации сборки
Все идет как надо. Вы можете выгружать код и фиксировать изменения в системе контроля версий, а также пригласить друзей поработать с вами. Но приложения у вас пока нет. Чтобы это было веб-приложение, его нужно скомпилировать и поместить в пакет для поставки или запустить как исполняемый файл. (Интерпретируемый язык программирования, вроде JavaScript или PHP, компилировать не надо.)
Применяйте инструмент автоматизации сборки. Какой бы инструмент вы ни выбрали, он будет собирать код в нужном формате и автоматизировать очистку, компиляцию, тестирование и поставку. Инструменты сборки бывают разные в зависимости от языка, но обычно используются следующие варианты с открытым кодом.
Превосходно! Теперь вставим файлы конфигурации инструмента автоматизации сборки в систему контроля версий, чтобы инструмент CI/CD их собрал.
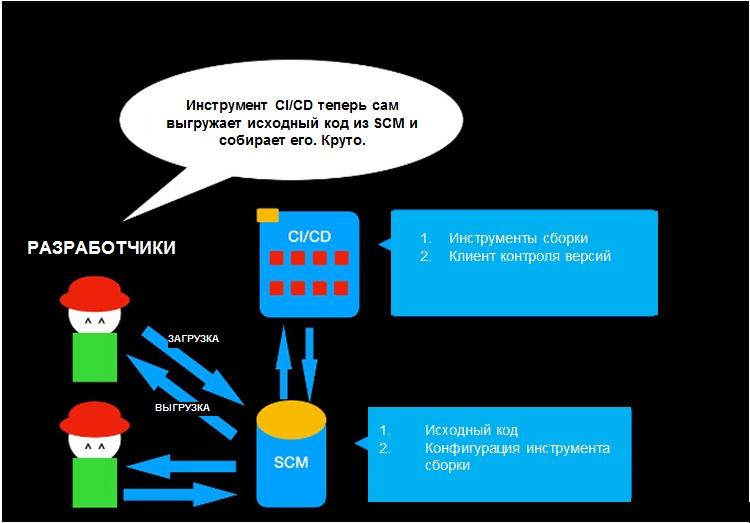
Вроде, все нормально. Но куда теперь все это выкатить?
Шаг 4: сервер веб-приложений
Итак, у вас есть запакованный файл, который можно исполнять или выкатывать. Чтобы приложение действительно приносило пользу, у него должен быть какой-то сервис или интерфейс, но вам нужно где-то это все разместить.
Веб-приложение можно разместить на сервере веб-приложений. Сервер приложений обеспечивает среду, где можно исполнить программную логику из пакета, выполнить отрисовку интерфейса и открыть web-сервисы через сокет. Вам нужен HTTP-сервер и несколько других окружений (виртуальная машина, например), чтобы установить сервер приложений. Пока давайте представим, что вы разбираетесь со всем этим в процессе (хотя о контейнерах я расскажу ниже).
Есть несколько открытых серверов веб-приложений.
У нас уже получился почти рабочая цепочка DevOps. Отличная работа!
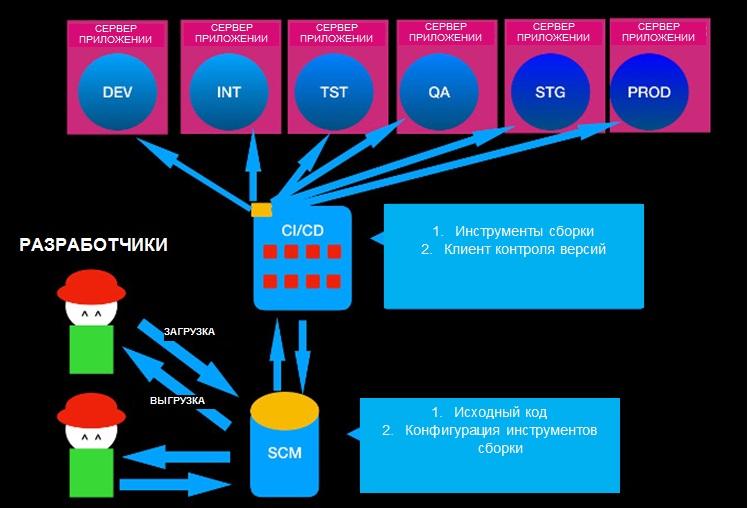
В принципе, здесь можно остановиться, дальше вы справитесь сами, но стоит еще рассказать о качестве кода.
Шаг 5: Тестовое покрытие
Тестирование отнимает много времени и сил, но лучше сразу найти ошибки и улучшить код, чтобы порадовать конечных пользователей. Для этой цели есть много открытых инструментов, которые не только протестируют код, а еще и посоветуют, как его улучшить. Большинство инструментов CI/CD могут подключаться к этим инструментам и автоматизировать процесс.
Тестирование разделено на две части: фреймворки тестирования, чтобы писать и выполнять тесты, и инструменты с подсказками по повышению качества кода.
Фреймворки тестирования
Инструменты с подсказками по качеству
Большинство этих инструментов и фреймворков написаны для Java, Python и JavaScript, потому что C++ и C# — проприетарные (хотя у GCC открытый исходный код).
Инструменты тестового покрытия мы применили, и теперь пайплайн DevOps должен выглядеть, как на рисунке в начале руководства.
Дополнительные шаги
Контейнеры
Как я уже говорил, сервер приложений можно разместить на виртуальной машине или сервере, но контейнеры более популярны.
Что такое контейнеры? Вкратце, в виртуальной машине операционная система чаще всего занимает больше места, чем приложение, а контейнеру обычно достаточно нескольких библиотек и конфигурации. В некоторых случаях без виртуальных машин не обойтись, но контейнер вмещает приложение вместе с сервером без лишних затрат.
Для контейнеров обычно берут Docker и Kubernetes, хотя есть и другие варианты.
Почитайте статьи о Docker и Kubernetes на Opensource.com:
Инструменты автоматизации промежуточного ПО
Наша цепочка DevOps ориентирована на совместную сборку и поставку приложения, но с инструментами DevOps можно делать и другие интересные штуки. Например, использовать инструменты «инфраструктура как код» (IaC), которые еще называются инструментами автоматизации промежуточного ПО. Эти инструменты помогают автоматизировать установку, управление и другие задачи для промежуточного ПО. Например, инструмент автоматизации может брать приложения (сервер веб-приложений, базу данных, инструменты мониторинга) с правильными конфигурациями и выкатывать их на сервер приложений.
Вот несколько вариантов открытых инструментов автоматизации промежуточного ПО:
Подробности в статьях на Opensource.com:
И что теперь?
Это только верхушка айсберга. Цепочка DevOps может гораздо больше. Начните с инструмента CI/CD и узнайте, что еще можно автоматизировать, чтобы упростить себе работу. Не забудьте про открытые инструменты коммуникации для эффективной совместной работы.
Вот еще несколько хороших статей о DevOps для начинающих:
А еще можно интегрировать DevOps с открытыми инструментами для agile:
Выстраиваем процесс разработки и CI pipeline, или Как разработчику стать DevOps для QA
Вот приходишь ты работать в маленький стартап с американскими корнями…
Пока ещё маленький такой стартап, но зато с многообещающим продуктом и большими планами на завоевание рынка.
И поначалу, пока команда разработчиков совсем крошечная (до 10 человек), разработка кодовой базы ведётся в общем репозитории на GitHub Enterprise, с быстрым выделением мелких фич, бранчеванием от master, и быстрыми же циклами релизов с мержем фич-бранчей напрямую в тот же мастер. Лид команды пока что способен отследить, кто чего накоммитил, и каждый коммит не только прочитать, но и понять, правильно ли оно, или не очень. Таким образом, пулл реквесты открываются, и быстро мержатся самим же разработчиком с устного одобрения лида (или отклоняются им).
Для обеспечения целостности кодовой базы команда уповает на юнит- и интеграционные тесты, коих написана уже пара тысяч штук, и обеспечено покрытие порядка 60% (по крайней мере, для бэкэнда). Лид разработки тоже прогоняет у себя полный цикл тестов на мастере перед релизом.
Процесс выглядит как-то так:
КОММИТЫ » ТЕСТЫ ВРУЧНУЮ » РЕЛИЗ
Проходит пара месяцев. Стартап показывает жизнеспособность, инвестиции позволяют нарастить команду разработчиков до 15 человек. В основном приходят фронтэндеры, и начинают быстро расширять фасад, который видят и используют конечные пользователи. Тестируется фасад фронтерами прямо у себя на рабочих маках, они пишут какие-то кейсы на Selenium, но у лида разработки уже нет времени прогонять их перед релизом, потому что Selenium известен своей неспешностью.
И тут случаются два факапа, буквально один за другим.
Сначала один из бэкэндеров случайно делает push force в master (бедняга простыл, затемпературил, голова не соображала), после чего две недели работы всей команды приходится восстанавливать по коммитику из чудом уцелевших локальных копий — все давно уже привыкли первым делом, придя на работу, сделать себе pull.
Потом одна из крупных фич, разрабатываемая фронтерами примерно пару месяцев в отдельной ветке, и зелёная по всем UI тестам, после мержа в master резко окрашивает его в красный, и чуть-чуть не обрушивает работу всего продукта. Прошляпили breaking изменения в собственном API. И тесты никак не помогли их отловить. Бывает. Но непорядок.
Так перед стартапом встаёт в полный рост вопрос о заведении команды QA, да и вообще, регламентов работы с фич-бранчами и общей методикой разработки, вкупе с дисциплиной. А также становится очевидно, что код перед пулл реквестом должен ревьюить не только лид разработки (у него и без того дел полно), но и другие коллеги. Нормальная проблема роста, в общем-то.
Вот мы и пришли к пункту «Дано:».
Сначала настроим в амазоновском облаке головной инстанс TC (+ два бесплатных агента), повесим их слушать коммиты в гихабовском репозитории (на каждый PR гитхаб делает виртуальный HEAD — слушать изменения ну очень просто), и автоматические сборки с прогоном юнит-тестов пойдут практически сами собой. Как коммитнет кто-нибудь, так через пять минут и сборка в очередь становится. Удобно.
КОММИТЫ » ПУЛЛ РЕКВЕСТ » БИЛД + ТЕСТЫ » РЕЛИЗ
У гитхаба в то время был ещё весьма неприятный интерфейс для просмотра пулл реквестов, и комментарии там оставлять тоже было не айс. Больно уж длинную портянку экранов надо было проматывать. То есть, отобрать у членов команды право на мерж было можно, но обеспечить нормальное ревью кода без сторонних сервисов — никак. Вдобавок, хотелось ещё получить заодно вменяемую интеграцию с Джирой, чтобы фичи к таскам, а таски к фичам сами прикреплялись.
По счастью, у Atlassian есть подобное решение, называется оно BitBucket Server, а в то время ещё звалось Stash. Как раз позволяет делать всю такую интеграционную магию с другими атлассиановскими продуктами, и очень удобно для ревью кода. Решили смигрировать.
Вот только этот чудесный продукт, в отличие от гитхаба, виртуальных HEAD на каждый PR не создаёт, и тимсити после миграции стало нечего слушать. С post-commit hooks дело тоже не пошло по причине отсутствия у всех времени хорошенько с ними разобраться.
Забегая вперёд — когда время появилось, мне удалось переписать stash-watcher.sh по-человечески, забирая изменения через штатный REST, распарсивая JSON-ответ при помощи великой и могучей утилиты jq, — мега-вещь для любого девопса, делающего интеграцию тулзовин! — и дёргая TeamCity только тогда, когда это на самом деле надо. Ну, ещё заодно прописал скрипт системным демоном, чтобы он стартовал при перезагрузке сам. Амазоновские инстансы изредка надо бывает перестартовать.
Вот, сложилось два кусочка головоломки.
КОММИТЫ » ПУЛЛ РЕКВЕСТ » РЕВЬЮ КОДА || БИЛДЫ + ТЕСТЫ » РЕЛИЗ
За это время в команде возникли QA инженеры.
Бедненькие! За день переключаться локально между пятью фич-бранчами, собирать и запускать их вручную!? Да врагу такого не пожелаешь.
Признаюсь честно: я искренне люблю QA инженеров (особенно девушек). И, в общем-то, не я один. Даже коллеги из НЙ, изначально свято веровавшие в юнит-тесты, как оказалось, их любят. Только они об этом ещё не догадывались, когда расплывчато сформулировали задачку «надо как-нибудь исследовать такой вопрос, чтобы можно было автоматом запускать где-то у нас в облаке по экземпляру приложения на каждый бранч, ну, типа, чтобы бизнесу можно было глазами посмотреть, что конкретно там сейчас с разрабатываемой фичей происходит. Would you?»
— Окей, — сказал я (ну а кто ещё? Кто однажды вляпался в DevOps, тот и крайний), — Вот и пункт «Требуется:» прибыл.
Интересная задачка. Ведь если удастся настроить автоматический деплой по итогам билда, то одним махом можно обеспечить потребности и бизнеса, и наших бедных QA. Вместо того, чтобы мучиться со сборкой локально, они будут ходить в облако на готовый экземпляр.
Тут ещё надо сказать, что приложение представляет собой несколько WAR-контейнеров, которые запускаются под Apache Tomcat. WAR же, как известно, это обычный архив ZIP с особенной структурой директорий и манифестом внутри. И при сборке приложения его конфигурация (путь к базе, пути к REST endpoints других WAR, и всё такое прочее) зашивается куда-то внутрь ресурсов. А чтобы скормить WAR томкэту, надо прописать в конфигах, откудова его брать, по какому url, и на каком порту его развёртывать.
А если мы хотим запустить сразу много экземпляров одного и того же WAR? Конфигурить томкэт на лету, чтобы раскидывать их по разным портам или url-ам? И что делать с конфигами, зашитыми внутрь ресурсов WAR?
Какая-то дурная постановка вопроса.
Подсмотрев, что делает IDEA, пробуем повторить и улучшить этот алгоритм. Для начала, заводим в амазоновском облаке здоровущий виртуальный инстанс с сотнями дискового пространства (а в exploded виде наше приложение довольно жирное) и гигабайтами оперативы.
В билды на тимсити, которые собирают WAR, добавляем дополнительный шаг сборки, который по SSH перекидывает их на тот жирный амазоновский инстанс, и также по SSH дёргает скрипт на bash, делающий следующее:
КОММИТЫ » ПУЛЛ РЕКВЕСТ » РЕВЬЮ КОДА || БИЛДЫ + ТЕСТЫ » РАЗВЁРТЫВАНИЕ QA ЭКЗЕМПЛЯРА » QA ИНЖЕНЕРЫ ЕГО МУЧАЮТ » РЕЛИЗ
Так, минуточку, а наши любимые QA инженеры что, вручную будут, что ли, в облако по SSH ходить, томкэт из командной строки запускать? Как-то не супер. Можно бы автоматически его поднимать, но неудобно, так как фич-бранчей уже под 60, и память даже на самом жирном инстансе всё-таки не резиновая. Тормозить будет.
nginx у нас уже поднят, настроить в нём classic CGI — как два байта об файерволл. А что такое classic CGI? Это когда на стандартный вход какого-то бинарника подаётся HTTP-запрос со всеми заголовками, и ставятся некоторые переменные окружения, а со стандартного выхода забирается HTTP-ответ, также со всеми заголовками. Тоже проще пареной репы, всё это можно буквально руками сделать.
Руками? Так не написать ли мне обработчик директории /deployments на bash? Потому что, наверное, могу. Как напишу, да как выложу на list.dev.стартап.ком (доступен будет только из внутренней сети стартапа, как и все экземпляры)… Иногда хочется чего-нибудь не только полезного, но и слегка ненормального. Такого, как минимальный обработчик HTTP-запросов на bash.
Вот и написал. Реально, скрипт на bash, который при помощи awk, sed, grep, find, и такой-то матери пробегается по поддиректориям /deployments, и выцепляет, где в какой что лежит. Номер билда, номер гитовой ревизии, имя фич-бранча — вся эта фигня и так на всякий случай уже передавалась из TC вместе с WAR-ником.
Заработало с полпинка. Один недостаток — парсить входные команды вида list.dev.стартап.ком/refresh?start=d### при помощи регулярок bash и никсовых утилит всё же не очень удобно. Но это уже я сам виноват — придумал глобальные слэш-команды и знак-вопроса-действия для экземпляров. Да, и вызывались внешние утилиты там для 60 поддиректорий много сотен раз, отчего консолька работала небыстро.
Проходит ещё совсем немного времени, и набор тесткейсов разрастается до такой степени, что QA инженерам приходится насоздавать довольно много сущностей в базе экземпляра, чтобы пройти полный цикл регресса для крупной фичи. А это уже и не один день. И если за это время разработчик успел что-то накоммитить в ветку по итогам ревью кода, то база экземпляра будет после билда развёрнута заново, отчего сущности потеряются. Упс.
Добавляем возможность сделать моментальный снимок для задеплоенного экземпляра. Его привязываем уже к номеру гитовой ревизии (там циферки, по результатов экспериментов, вполне уникальные), и складываем в /deployments/s### (другая буква префикса, чтобы у экземпляров и снимков были разные пространства имён). Деплоим примерно тем же скриптом, что и с тимсити, только базу копируем не из дампа, а существующую.
Так QA инженеры получают возможность тестировать конкретную ревизию до посинения, за это время разработчик может коммитить в основную ветку исправления по ревью сколько нужно. Потом, перед релизом, проверяться будут уже только эти точечные изменения в основном экземпляре.
КОММИТЫ » ПУЛЛ РЕКВЕСТ » РЕВЬЮ КОДА || БИЛДЫ + ТЕСТЫ » РАЗВЁРТЫВАНИЕ QA ЭКЗЕМПЛЯРА || СНИМОК QA ЭКЗЕМПЛЯРА » QA ИНЖЕНЕРЫ ЕГО МУЧАЮТ » РЕЛИЗ
Ого! Всего-то за полгода с хаотического процесса, когда разработчики коммитят фичи кто во что горазд, мы пришли к логичной, стройной системе continuous integration pipeline, где каждый шаг регламентирован, и каждый инструмент максимально автоматизирован.
Стоит только разработчику создать PR, как процесс деплоймента тестового экземпляра уже, считай, запущен, и буквально через час (если повезёт — число параллельных фич-бранчей с ростом команды вскоре возросло до сотни, пришлось поднимать аж семь инстансов под TC) у QA будет готовая к тестированию фича. Гоняй хоть вручную, хоть скриптами через REST API, а если надо, то диагностируй её и разбирайся с багами при помощи консоли управления тестовыми экземплярами.
Ну а дальше уже лирика. Через некоторое время тормоза консоли всем надоели, и мне пришлось вспоминать молодость, переписав её с bash (жаль, вся ненормальность этого маленького проекта разом потерялась) на обычный скучный PHP (впрочем, не на Java же такие задачи делать, в самом деле), а один из фронтеров сподобился переделать UI из олдскульного plain HTML на вполне современное ангуляровское приложение. Впрочем, я настоял на сохранении интерфейса а-ля девяностые, просто по приколу. Добавилась возможность просмотра stdout и stderr у томкэта. Сделали специальный CLI интерфейс для вызова REST API прямо на месте, ну и ещё немножко маленьких полезняшек.
Жутко удобная штука получилась.*

Вы только посмотрите, какие счастливые лица у команды QA инженеров!
Напишите мне. С удовольствием рассмотрю предложения о работе в местах, где нужны матёрые (больше 10 лет опыта) специалисты с Primary Skill == Java, и возможностью иногда позаниматься подобного рода ненормальным программированием. Или процессами порулить. Можно всё сразу.
Только в Москву переехать не смогу. А вот поработать удалённо — с удовольствием.



