Нормализация данных в Python
Перевод статьи «Normalization of Data in Python».
Сегодня мы хотим поговорить о том, что такое нормализация данных в Python. Пожалуй, начать стоит с определения. Нормализация данных – это метод, который ускоряет получение желаемого результата за счет того, что машине приходится обрабатывать меньший диапазон данных.
Нормализация – непростая задача, потому что все ваши результаты зависят от выбора правильного метода нормализации. Выбрав неправильный метод, вы можете получить совсем не то, что ожидали.
Нормализация также зависит от типа данных, т.е. от того, имеете ли вы дело с изображением, текстом, числами и т. д. Каждый тип данных имеет свои методы нормализации. В этой статье мы сосредоточимся на числовых данных.
Метод 1. Использование sklearn
Метод sklearn – очень популярный метод нормализации данных.
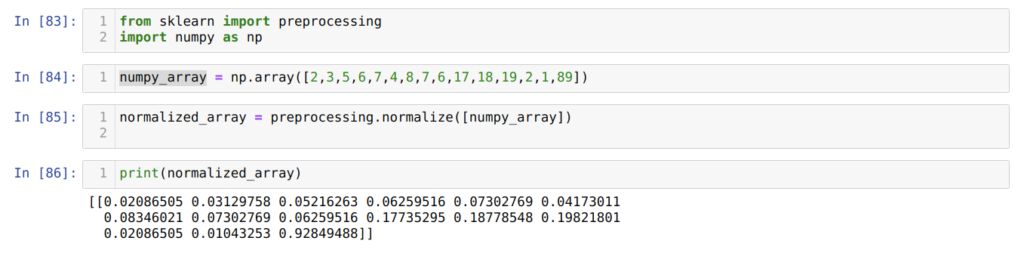
Далее, в ячейке номер [84] мы создаем массив NumPy с уникальными целочисленными значениями.
Как видно из результатов, в ячейке номер [86] все наши целочисленные данные теперь нормализованы между нулем и единицей.
Метод 2. Нормализация определенного столбца в наборе данных с помощью sklearn
Мы также можем нормализовать конкретный столбец нашего набора данных. Давайте разберем такой случай.
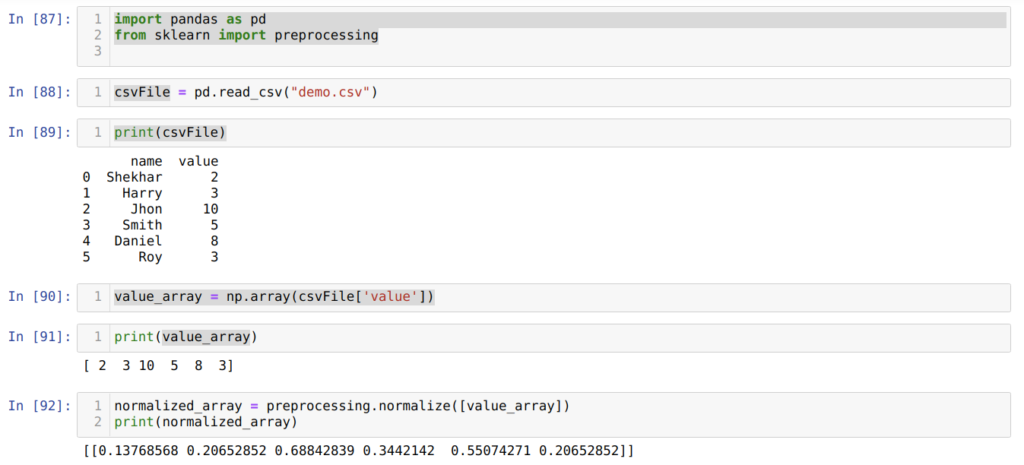
В ячейке номер [87] мы импортируем библиотеки pandas и sklearn.
В ячейке номер [88] создаем CSV-файл с поддельными данными и загружаем его с помощью модуля pandas (функция read_csv() ).
Далее, в ячейке номер [89] мы выводим на экран только что загруженный CSV-файл.
Метод 3. Нормализация всего набора данных по столбцам или по строкам
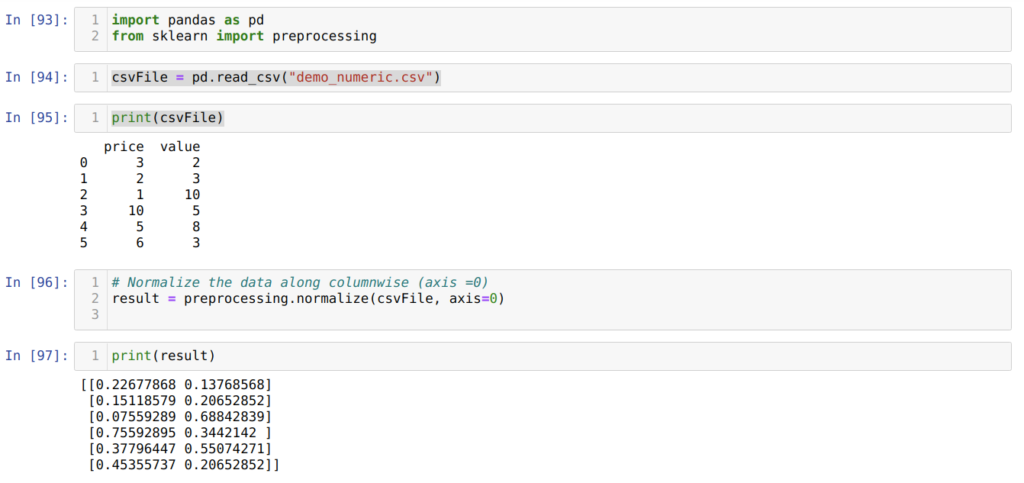
Итак, первые три шага абсолютно идентичны тому, что мы делали в предыдущем разделе.
В ячейке номер [96] мы передаем весь CSV-файл (demo_numeric.csv) вместе с еще одним дополнительным параметром axis = 0, который сообщает библиотеке, что мы хотим нормализовать весь набор данных по столбцам.
И далее, в ячейке [97] мы выводим результат нормализованных данных со значениями от нуля до единицы.
Метод 4. Использование MinMaxScaler()
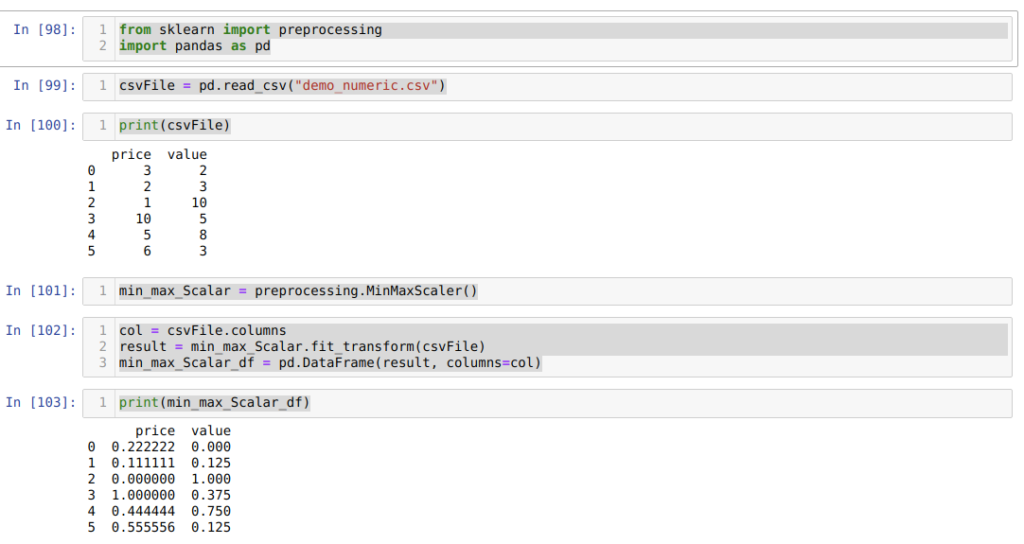
Для начала импортируем все необходимые пакеты. Затем создаем CSV-файл с фиктивными данными (demo_numeric.csv) и загружаем его с помощью пакета pandas (функция read_csv() ). После выводим этот файл на экран. В общем, всё, как и в предыдущих методах.
В ячейке номер [102] мы сначала читаем все имена столбцов для дальнейшего использования для отображения результатов. Затем мы вызываем fit_tranform() из созданного объекта min_max_Scalar и передаем туда CSV-файл.
После этого, в ячейке номер [103], мы получаем нормализованные результаты, находящиеся между 0 и 1.
Метод 5. Использование MinMaxScaler с разными параметрами
Sklearn также предоставляет возможность изменить нормализованные значения. По умолчанию функция нормализует значения в диапазоне от нуля до единицы. Однако есть параметр (называется feature_range ), с помощью которого можно устанавливать границы нормализованных значений в соответствии с нашими требованиями.
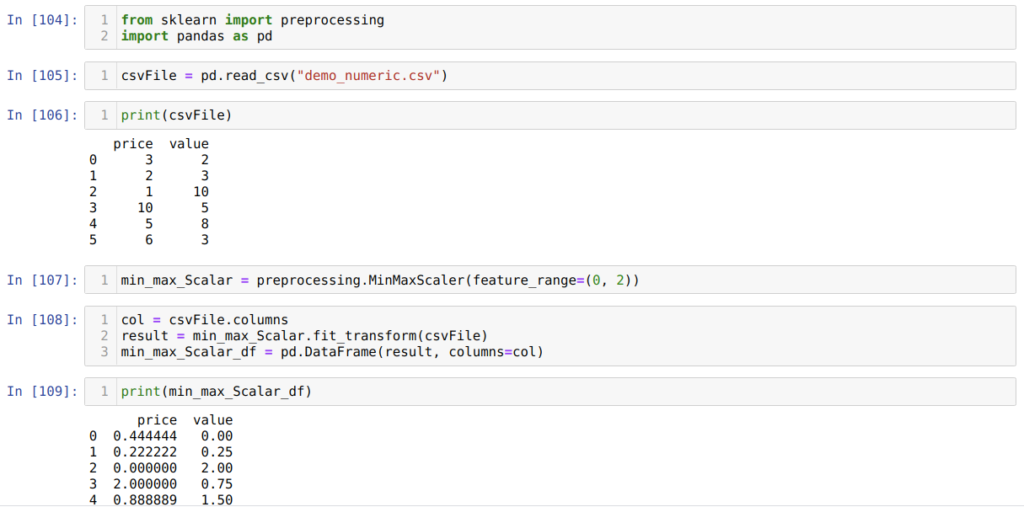
Первые три шага идентичны тому, что мы делали в прошлых примерах.
В ячейке [108] мы сначала читаем все имена столбцов, а затем вызываем fit_tranform() из созданного ранее объекта min_max_Scalar и передаем туда CSV-файл в качестве параметра.
И последним действием, в ячейке номер [109], мы получаем нормализованные результаты, которые находятся между 0 и 2.
Метод 6. Использование максимального абсолютного масштабирования
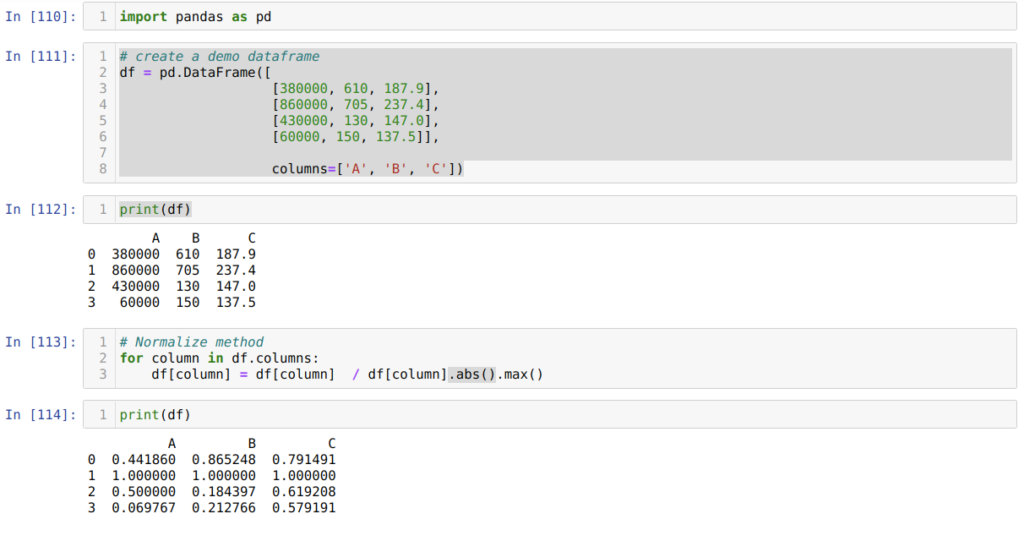
Сначала мы импортируем нужную нам библиотеку pandas.
Затем (в ячейке номер [111]) мы создаем фрейм фиктивных данных и выводим его на экран.
В ячейке номер [114] мы выводим получившийся результат, который подтверждает, что наши данные действительно нормализованы между 0 и 1.
Метод 7. Использование метода z-оценки
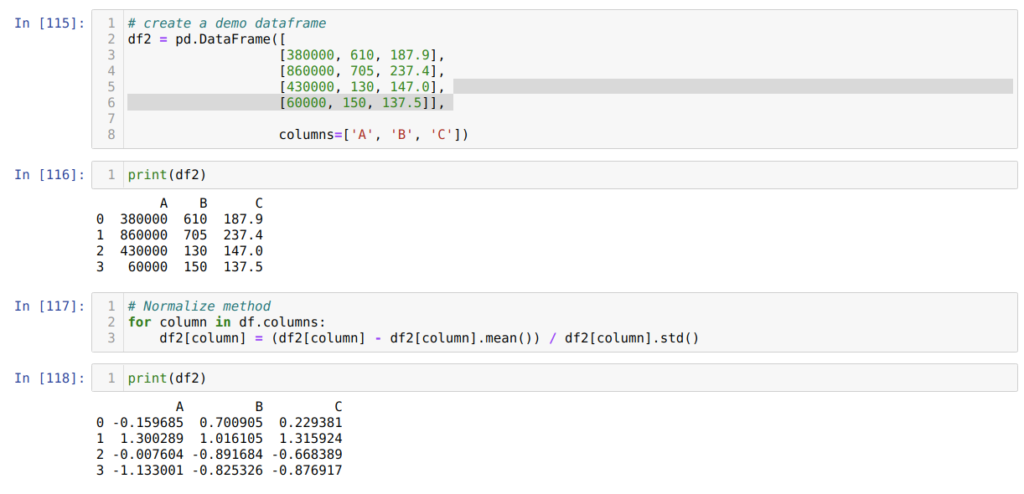
В ячейке номер [115] мы создаем фрейм фиктивных данных и выводим его.
Далее, в ячейке [117], мы вычисляем среднее значение столбцов и вычитаем его из каждого столбца. Затем делим значение столбца на стандартное отклонение.
Заключение
Сегодня мы обсудили, что такое нормализация данных в Python, и разобрали разные виды методов нормализации. Среди них sklearn, который очень известен благодаря широкому использованию в машинном обучении.
Однако не стоит забывать, что всё зависит от требований пользователя. Иногда для нормализации данных достаточно функции pandas.
Нельзя сказать, что существуют только данные методы нормализации. Нет, различных методов нормализации довольно много, причем они зависят от типа данных. В этой статье мы сфокусировались на числовых данных.
2 простых способа нормализовать данные в Python

В этом руководстве мы узнаем, как нормализовать данные в Python. При нормализации меняем масштаб данных. Чаще всего масштабирование данных изменяется в диапазоне от 0 до 1.
Почему нам нужно нормализовать данные в Python?
Алгоритмы машинного обучения, как правило, работают лучше или сходятся быстрее, когда различные функции (переменные) имеют меньший масштаб. Поэтому перед обучением на них моделей машинного обучения данные обычно нормализуются.
Нормализация также делает процесс обучения менее чувствительным к масштабу функций. Это приводит к улучшению коэффициентов после тренировки.
Этот процесс повышения пригодности функций для обучения путем изменения масштаба называется масштабированием функций.
Формула нормализации приведена ниже:
Шаги по нормализации данных в Python
Мы собираемся обсудить два разных способа нормализации данных в Python.
Использование normalize() из sklearn
Начнем с импорта processing из sklearn.
Теперь мы можем использовать метод normalize() для массива. Этот метод нормализует данные по строке. Давайте посмотрим на метод в действии.
Полный код
Вот полный код из этого раздела:
Мы видим, что все значения теперь находятся в диапазоне от 0 до 1. Так работает метод normalize() в sklearn.
Вы также можете нормализовать столбцы в наборе данных, используя этот метод.
Нормализовать столбцы в наборе данных с помощью normalize()
Поскольку normalize() нормализует только значения по строкам, нам нужно преобразовать столбец в массив, прежде чем применять метод.
Чтобы продемонстрировать, мы собираемся использовать набор данных California Housing.
Начнем с импорта набора данных.
Как нормализовать набор данных без преобразования столбцов в массив?
Давайте посмотрим, что произойдет, когда мы попытаемся нормализовать набор данных без преобразования функций в массивы для обработки.
Здесь значения нормализованы по строкам, что может быть очень неинтуитивно. Нормализация по строкам означает, что нормализуется каждая отдельная выборка, а не признаки.
Однако вы можете указать ось при вызове метода для нормализации по элементу (столбцу).
Значение параметра оси по умолчанию установлено на 1. Если мы изменим значение на 0, процесс нормализации произойдет по столбцу.

Вы можете видеть, что столбец total_bedrooms в выходных данных совпадает с столбцом, который мы получили выше после преобразования его в массив и последующей нормализации.
Использование MinMaxScaler() для нормализации данных в Python
Когда дело доходит до нормализации данных, Sklearn предоставляет еще один вариант: MinMaxScaler.
Это более популярный выбор для нормализации наборов данных.
Вот код для нормализации набора данных жилья с помощью MinMaxScaler:

Вы можете видеть, что значения на выходе находятся между (0 и 1).
MinMaxScaler также дает вам возможность выбрать диапазон функций. По умолчанию диапазон установлен на (0,1). Посмотрим, как изменить диапазон на (0,2).
Значения на выходе теперь находятся в диапазоне (0,2).
Вывод
Это два метода нормализации данных в Python. Мы рассмотрели два метода нормализации данных в разделе sklearn. Надеюсь, вам было весело учиться с нами!
6.3. Предварительная обработка данных ¶
6.3.1. Стандартизация или удаление среднего и масштабирование дисперсии
На практике мы часто игнорируем форму распределения и просто преобразуем данные для их центрирования, удаляя среднее значение каждой функции, а затем масштабируем ее, деля непостоянные характеристики на их стандартное отклонение.
Например, многие элементы, используемые в целевой функции алгоритма обучения (такие как ядро RBF машин опорных векторов или регуляризаторы l1 и l2 линейных моделей), предполагают, что все функции сосредоточены вокруг нуля и имеют дисперсию в том же порядке. Если характеристика имеет дисперсию, которая на порядки больше, чем у других, она может доминировать над целевой функцией и сделать оценщик неспособным правильно учиться на других функциях, как ожидалось.
Масштабированные данные имеют нулевое среднее значение и единичную дисперсию:
Этот класс реализует Transformer API для вычисления среднего и стандартного отклонения на обучающем наборе, чтобы иметь возможность позже повторно применить то же преобразование к набору тестирования. Таким образом, этот класс подходит для использования на ранних этапах Pipeline :
6.3.1.1. Масштабирование функций до диапазона
Альтернативная стандартизация — это масштабирование функций таким образом, чтобы они находились между заданным минимальным и максимальным значением, часто между нулем и единицей, или так, чтобы максимальное абсолютное значение каждой функции масштабировалось до размера единицы. Этого можно добиться с помощью MinMaxScaler или MaxAbsScaler соответственно.
Мотивация к использованию этого масштабирования включает устойчивость к очень небольшим стандартным отклонениям функций и сохранение нулевых записей в разреженных данных.
Вот пример масштабирования матрицы данных игрушки до диапазона [0, 1]:
Тот же экземпляр преобразователя затем можно применить к некоторым новым тестовым данным, невидимым во время вызова подгонки: будут применены те же операции масштабирования и сдвига, чтобы они согласовывались с преобразованием, выполняемым с данными поезда:
Можно проанализировать атрибуты масштабатора, чтобы узнать точную природу преобразования, полученного на обучающих данных:
Если MinMaxScaler дано явное указание, полная формула будет иметь следующий вид : feature_range=(min, max)
MaxAbsScaler работает очень похожим образом, но масштабируется таким образом, что обучающие данные лежат в пределах диапазона [-1, 1], путем деления на наибольшее максимальное значение в каждой функции. Он предназначен для данных, которые уже сосредоточены на нуле или разреженных данных.
Вот как использовать данные игрушки из предыдущего примера с этим скейлером:
6.3.1.2. Масштабирование разреженных данных
Центрирование разреженных данных разрушило бы структуру разреженности данных, и поэтому редко бывает разумным делом. Однако может иметь смысл масштабировать разреженные входные данные, особенно если функции находятся в разных масштабах.
Наконец, если ожидается, что центрированные данные будут достаточно маленькими, toarray еще один вариант — явное преобразование входных данных в массив с использованием метода разреженных матриц.
6.3.1.3. Масштабирование данных с помощью выбросов
Если ваши данные содержат много выбросов, масштабирование с использованием среднего значения и дисперсии данных, вероятно, не будет работать очень хорошо. В этих случаях вы можете использовать RobustScaler вместо него замену. Он использует более надежные оценки для центра и диапазона ваших данных.
Дальнейшее обсуждение важности центрирования и масштабирования данных доступно в этом FAQ: Следует ли нормализовать / стандартизировать / масштабировать данные?
Масштабирование против отбеливания
Иногда недостаточно центрировать и масштабировать элементы независимо, поскольку последующая модель может дополнительно сделать некоторые предположения о линейной независимости функций.
Чтобы решить эту проблему, вы можете использовать PCA с whiten=True для дальнейшего удаления линейной корреляции между функциями.
6.3.1.4. Центрирование ядерных матриц
6.3.2. Нелинейное преобразование
Доступны два типа преобразований: квантильные преобразования и степенные преобразования. И квантильные, и степенные преобразования основаны на монотонных преобразованиях характеристик и, таким образом, сохраняют ранг значений по каждой характеристике.
Преобразования мощности — это семейство параметрических преобразований, цель которых — сопоставить данные из любого распределения как можно ближе к гауссовскому распределению.
6.3.2.1. Отображение в равномерное распределение
QuantileTransformer обеспечивает непараметрическое преобразование для отображения данных в равномерное распределение со значениями от 0 до 1:
Эта особенность соответствует длине чашелистиков в см. После применения квантильного преобразования эти ориентиры близко подходят к ранее определенным процентилям:
Это можно подтвердить на независимом тестовом наборе с аналогичными замечаниями:
6.3.2.2. Отображение в гауссово распределение
Во многих сценариях моделирования желательна нормальность функций в наборе данных. Преобразования мощности — это семейство параметрических монотонных преобразований, которые нацелены на отображение данных из любого распределения как можно ближе к гауссовскому распределению, чтобы стабилизировать дисперсию и минимизировать асимметрию.
PowerTransformer в настоящее время предоставляет два таких преобразования мощности, преобразование Йео-Джонсона и преобразование Бокса-Кокса.
Преобразование Йео-Джонсона определяется следующим образом:
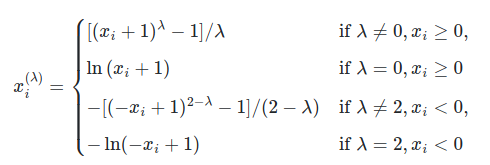
в то время как преобразование Бокса-Кокса задается следующим образом:
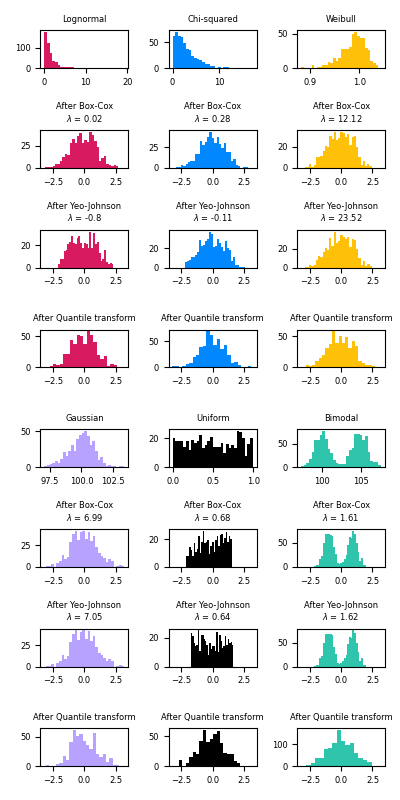
Ниже приведены примеры Бокса-Кокса и Йео-Джонсона, примененные к различным распределениям вероятностей. Обратите внимание, что при применении к определенным распределениям степенные преобразования достигают результатов, очень похожих на гауссову, но с другими они неэффективны. Это подчеркивает важность визуализации данных до и после преобразования.
Таким образом, медиана входа становится средним значением выхода с центром в 0. Нормальный выход обрезается так, чтобы минимум и максимум входа — соответствующие квантилям 1e-7 и 1 — 1e-7 соответственно — не становились бесконечными при преобразование.
6.3.3. Нормализация
Это предположение является основой модели векторного пространства, часто используемой в контекстах классификации и кластеризации текста.
Таким образом, этот класс подходит для использования на ранних этапах Pipeline :
Экземпляр нормализатора затем можно использовать в векторах выборки как любой преобразователь:
Примечание. Нормализация L2 также известна как предварительная обработка пространственных знаков.
Для разреженного ввода данные преобразуются в представление сжатых разреженных строк (см. Раздел «Ресурсы» scipy.sparse.csr_matrix ) перед подачей в эффективные подпрограммы Cython. Чтобы избежать ненужных копий памяти, рекомендуется выбирать представление CSR в восходящем направлении.
6.3.4. Кодирование категориальных признаков
Такое целочисленное представление, однако, не может использоваться напрямую со всеми оценщиками scikit-learn, поскольку они ожидают непрерывного ввода и интерпретируют категории как упорядоченные, что часто нежелательно (т. Е. Набор браузеров был упорядочен произвольно).
Продолжая пример выше:
По умолчанию значения, которые может принимать каждый объект, автоматически выводятся из набора данных и могут быть найдены в categories_ атрибуте:
Если есть вероятность, что в обучающих данных могут отсутствовать категориальные особенности, часто бывает лучше указать, handle_unknown=’ignore’ а не устанавливать categories вручную, как указано выше. Если handle_unknown=’ignore’ задано значение и во время преобразования встречаются неизвестные категории, ошибка не возникает, но в столбцах с горячим кодированием для этой функции будут все нули ( handle_unknown=’ignore’ поддерживается только для горячего кодирования):
Также можно кодировать каждый столбец в столбцы n_categories — 1 вместо столбцов n_categories с помощью параметра drop. Этот параметр позволяет пользователю указать категорию для каждой удаляемой функции. Это полезно, чтобы избежать коллинеарности входной матрицы в некоторых классификаторах. Такая функциональность полезна, например, при использовании нерегуляризованной регрессии ( LinearRegression ), поскольку коллинеарность приведет к тому, что ковариационная матрица будет необратимой. Если этот параметр не равен None, handle_unknown необходимо установить значение error :
OneHotEncoder поддерживает категориальные функции с пропущенными значениями, рассматривая отсутствующие значения как дополнительную категорию:
См. Раздел Загрузка функций из dicts, чтобы узнать о категориальных функциях, которые представлены как dict, а не как скаляры.
6.3.5. Дискретность
Дискретизация (также известная как квантование или биннинг) обеспечивает способ разделения непрерывных функций на дискретные значения. Определенные наборы данных с непрерывными объектами могут выиграть от дискретизации, потому что дискретизация может преобразовать набор данных с непрерывными атрибутами в набор только с номинальными атрибутами.
Дискретизированные признаки, закодированные одним горячим способом (One-hot encoded), могут сделать модель более выразительной, сохраняя при этом интерпретируемость. Например, предварительная обработка с помощью дискретизатора может внести нелинейность в линейные модели.
6.3.5.1. Дискретизация K-бинов
KBinsDiscretizer дискретизирует функции в k бункеры:
По умолчанию выходные данные быстро кодируются в разреженную матрицу (см. Категориальные функции кодирования ), и это можно настроить с помощью encode параметра. Для каждого объекта границы fit интервалов вычисляются во время и вместе с количеством интервалов они определяют интервалы. Следовательно, для текущего примера эти интервалы определены как:
На основе этих интервалов бинов X преобразуется следующим образом:
Дискретизация аналогична построению гистограмм для непрерывных данных. Однако гистограммы фокусируются на подсчете объектов, которые попадают в определенные интервалы, тогда как дискретизация фокусируется на присвоении значений признаков этим интервалам.
KBinsDiscretizer реализует различные стратегии биннинга, которые можно выбрать с помощью strategy параметра. «Равномерная» стратегия использует ячейки постоянной ширины. Стратегия «квантилей» использует значения квантилей, чтобы иметь одинаково заполненные ячейки в каждой функции. Стратегия «k-средних» определяет интервалы на основе процедуры кластеризации k-средних, выполняемой для каждой функции независимо.
6.3.5.2. Бинаризация функций
В сообществе обработки текста также распространено использование двоичных значений признаков (вероятно, для упрощения вероятностных рассуждений), даже если нормализованные подсчеты (также известные как частоты терминов) или функции, оцениваемые по TF-IDF, часто работают немного лучше на практике.
Есть возможность настроить порог бинаризатора:
Что касается Normalizer класса, модуль предварительной обработки предоставляет вспомогательную функцию, binarize которая будет использоваться, когда API-интерфейс преобразователя не нужен.
6.3.6. Вменение пропущенных значений
6.3.7. Создание полиномиальных признаков
Часто бывает полезно усложнить модель, учитывая нелинейные особенности входных данных. Простой и распространенный метод использования — это полиномиальные функции, которые могут получить термины высокого порядка и взаимодействия функций. Реализован в PolynomialFeatures :
В некоторых случаях требуются только условия взаимодействия между функциями, и это можно получить с помощью настройки interaction_only=True :
См. Раздел Полиномиальная интерполяция для регрессии Риджа с использованием созданных полиномиальных функций.
6.3.8. Трансформаторы на заказ
Полный пример кода, демонстрирующий использование a FunctionTransformer для извлечения функций из текстовых данных, см. В разделе Преобразователь столбцов с гетерогенными источниками данных.
Машинное обучение — подготовка данных
Алгоритмы машинного обучения полностью зависят от данных, потому что это наиболее важный аспект, который делает возможным обучение модели. С другой стороны, если мы не сможем разобраться в этих данных, прежде чем передавать их в алгоритмы ML, машина будет бесполезна. Проще говоря, нам всегда нужно предоставлять правильные данные, то есть данные в правильном масштабе, формате и содержащие значимые функции, для решения проблемы, которую мы хотим решить машиной.
Это делает подготовку данных наиболее важным шагом в процессе ОД. Подготовка данных может быть определена как процедура, которая делает наш набор данных более подходящим для процесса ML.
Почему предварительная обработка данных?
После выбора необработанных данных для обучения ОД наиболее важной задачей является предварительная обработка данных. В широком смысле, предварительная обработка данных преобразует выбранные данные в форму, с которой мы можем работать или можем передавать алгоритмы ML. Нам всегда нужно предварительно обрабатывать наши данные, чтобы они могли соответствовать алгоритму машинного обучения.
Методы предварительной обработки данных
У нас есть следующие методы предварительной обработки данных, которые можно применять к набору данных для получения данных для алгоритмов ML —
пересчет
В этом примере мы будем масштабировать данные набора данных диабета индейцев Пима, которые мы использовали ранее. Сначала будут загружены данные CSV (как это делалось в предыдущих главах), а затем с помощью класса MinMaxScaler они будут масштабироваться в диапазоне от 0 до 1.
Первые несколько строк следующего скрипта такие же, как мы писали в предыдущих главах при загрузке данных CSV.
Теперь мы можем использовать класс MinMaxScaler для изменения масштаба данных в диапазоне от 0 до 1.
Мы также можем суммировать данные для вывода по нашему выбору. Здесь мы устанавливаем точность в 1 и показываем первые 10 строк в выводе.
Из вышеприведенного вывода все данные были перераспределены в диапазоне от 0 до 1.
нормализация
Типы нормализации
В машинном обучении существует два типа методов предварительной обработки нормализации:
бинаризации
Как следует из названия, это метод, с помощью которого мы можем сделать наши данные двоичными. Мы можем использовать двоичный порог для того, чтобы сделать наши данные двоичными. Значения выше этого порогового значения будут преобразованы в 1, а ниже этого порогового значения будут преобразованы в 0.
Например, если мы выберем пороговое значение = 0,5, то значение набора данных выше этого станет 1, а ниже этого станет 0. Поэтому мы можем назвать его бинаризацией данных или пороговым значением данных. Этот метод полезен, когда у нас есть вероятности в нашем наборе данных и мы хотим преобразовать их в четкие значения.
Мы можем преобразовать данные в двоичную форму с помощью класса Python библиотеки Scinit-learn Binarizer.
В этом примере мы будем масштабировать данные набора данных диабета индейцев Пима, которые мы использовали ранее. Сначала будут загружены данные CSV, а затем с помощью класса Binarizer они будут преобразованы в двоичные значения, то есть 0 и 1, в зависимости от порогового значения. Мы берем 0,5 в качестве порогового значения.
Первые несколько строк следующего скрипта такие же, как мы писали в предыдущих главах при загрузке данных CSV.
Теперь мы можем использовать класс Binarize для преобразования данных в двоичные значения.
Здесь мы показываем первые 5 строк в выводе.
Стандартизация
В этом примере мы будем масштабировать данные набора данных диабета индейцев Пима, которые мы использовали ранее. Сначала будут загружены данные CSV, а затем с помощью класса StandardScaler они будут преобразованы в гауссово распределение со средним значением = 0 и SD = 1.
Первые несколько строк следующего скрипта такие же, как мы писали в предыдущих главах при загрузке данных CSV.
Теперь мы можем использовать класс StandardScaler для изменения масштаба данных.
Мы также можем суммировать данные для вывода по нашему выбору. Здесь мы устанавливаем точность до 2 и показываем первые 5 строк в выводе.
Маркировка данных
Мы обсудили важность хороших данных для алгоритмов ML, а также некоторые методы предварительной обработки данных перед их отправкой в алгоритмы ML. Еще один аспект в этом отношении — маркировка данных. Также очень важно отправлять данные в алгоритмы ML с надлежащей маркировкой. Например, в случае проблем с классификацией в данных имеется множество меток в виде слов, цифр и т. Д.
Что такое кодирование меток?
В следующем примере скрипт Python выполнит кодирование метки.
Сначала импортируйте необходимые библиотеки Python следующим образом:
Теперь нам нужно указать следующие метки ввода:
Следующая строка кода создаст кодировщик меток и обучит его.
Следующие строки скрипта будут проверять производительность путем кодирования случайного упорядоченного списка —
Мы можем получить список закодированных значений с помощью следующего скрипта Python —



