
Изучите лучшие репозитории MLOps на GitHub, чтобы отслеживать новые тенденции и ресурсы.
СОДЕРЖАНИЕ
История
Проблемы постоянного использования машинного обучения в приложениях были освещены в документе 2015 года.
Прогнозируемый рост машинного обучения предполагал удвоение пилотных проектов и внедрений машинного обучения с 2017 по 2018 год и снова с 2018 по 2020 год.
Проект с открытым исходным кодом Kubeflow был создан в 2018 году Джереми Леви и Дэвидом Арончиком из Google для упрощения MLOps в Kubernetes.
Отчеты показывают, что большинство (до 88%) корпоративных инициатив в области ИИ не могут выйти за рамки этапов тестирования. Однако те организации, которые фактически внедрили ИИ и машинное обучение в производство, увидели рост прибыли на 3-15%.
Рынок MLOps оценивался в 23,2 миллиарда долларов в 2019 году и, по прогнозам, достигнет 126 миллиардов долларов к 2025 году из-за быстрого внедрения.
В 2020 году был основан популярный курс Made With ML MLOps с более чем 25000 звезд GitHub.
Архитектура
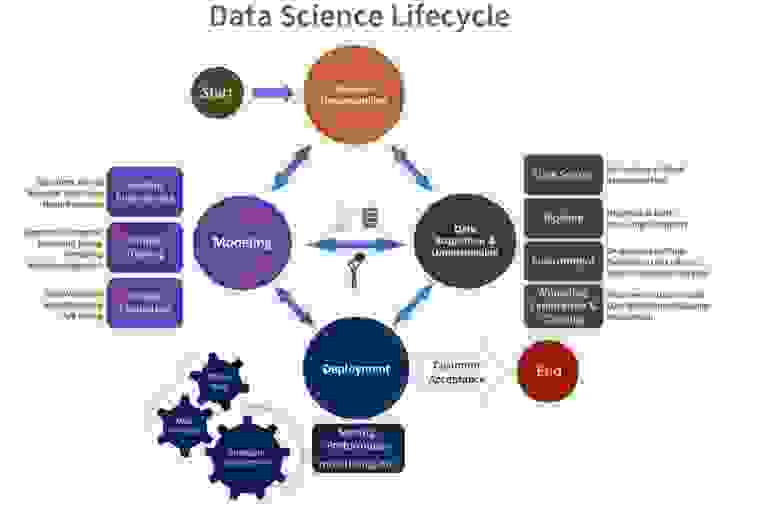
Системы машинного обучения можно разделить на восемь различных категорий: сбор данных, обработка данных, разработка функций, маркировка данных, проектирование модели, обучение и оптимизация модели, развертывание конечных точек и мониторинг конечных точек. Каждый этап жизненного цикла машинного обучения построен в отдельной системе, но требует взаимосвязи. Это минимальный набор систем, необходимых предприятиям для масштабирования машинного обучения в своей организации.
Есть ряд целей, которых предприятия хотят достичь с помощью систем MLOps, успешно внедряющих машинное обучение в масштабах всего предприятия, в том числе:
Стандартная практика, такая как MLOps, учитывает каждую из вышеупомянутых областей, что может помочь предприятиям оптимизировать рабочие процессы и избежать проблем во время внедрения.
Общая архитектура системы MLOps будет включать платформы для анализа данных, на которых создаются модели, и аналитические механизмы, в которых выполняются вычисления, с инструментом MLOps, который управляет перемещением моделей машинного обучения, данных и результатов между системами.
млопс: управление моделями, развертывание, журналы преобразований и мониторинг с помощью Машинное обучение Azure
в этой статье вы узнаете, как Машинное обучение операции (млопс) в Машинное обучение Azure для управления жизненным циклом моделей. MLOps улучшает качество и согласованность решений машинного обучения.
Что собой представляет MLOps?
Управление машинным обучением (MLOps) основано на принципах и методиках DevOps, повышающих эффективность рабочих процессов. Например, непрерывная интеграция, поставка и развертывание. MLOps применяет эти принципы к процессу машинного обучения для следующего:
млопс в Машинное обучение Azure
Машинное обучение Azure предоставляет следующие возможности MLOps:
Дополнительные сведения о MLOps см. в разделе DevOps — Машинное обучение (MLOps).
Создание воспроизводимых конвейеров машинного обучения
Используйте конвейеры машин из Машинного обучения Azure, чтобы объединить все шаги, связанные с процессом обучения модели.
Конвейер машинного обучения может содержать шаги из процесса подготовки данных к извлечению компонентов в настройку параметров для оценки модели. Дополнительные сведения см. в разделе конвейеры машинного обучения.
Если вы используете конструктор для создания конвейеров машинного обучения, вы можете в любой момент нажать кнопку «. « в правом верхнем углу страницы конструктора, а затем выбрать Клонировать. Клонирование конвейера позволяет перебирать проект конвейера без потери старых версий.
Создание повторно используемых программных сред
Среды Машинного обучения Azure позволяют отслеживать и воспроизводить программные зависимости проектов по мере их развития. Среды позволяют обеспечить воспроизводимость сборок без ручных конфигураций программного обеспечения.
Среды описывают зависимости PIP и Conda для проектов и могут использоваться как для обучения, так и для развертывания моделей. Дополнительные сведения см. в разделе Что такое среды машинного обучения Azure.
Регистрация, создание пакетов и развертывание моделей из любого места
Регистрация и отслеживание моделей машинного обучения
Регистрация модели позволяет хранить и изменять модели в облаке Azure в рабочей области. Модель реестра позволяет легко организовывать и отслеживать ваши обученные модели.
Зарегистрированная модель — это логический контейнер для одного или нескольких файлов, составляющих эту модель. Например, если ваша модель хранится в нескольких файлах, их можно зарегистрировать как единую модель рабочей области Машинного обучения Azure. После регистрации вы сможете скачать или развернуть зарегистрированную модель, чтобы получить все зарегистрированные в ней файлы.
Зарегистрированные модели идентифицируются по имени и версии. При регистрации модели с уже существующим именем реестр увеличивает номер версии. Во время регистрации можно указать дополнительные теги метаданных. Затем эти теги используются при поиске модели. Служба машинного обучения Azure поддерживает любые модели, которые можно скачать с помощью Python 3.5.2 или выше.
Можно также зарегистрировать модель, обученную вне машинного обучения Azure.
Удалить зарегистрированную модель нельзя, если она используется в любом активном развертывании. Дополнительные сведения см. в разделе «Регистрация модели» статьи Развертывание моделей с помощью Службы машинного обучения Azure.
При использовании параметра «Фильтровать по Tags » на странице «Модели» в Студии машинного обучения Azure вместо использования TagName : TagValue клиентам следует использовать TagName=TagValue (без пробела)
Профилирование моделей
Машинное обучение Azure поможет вам понять требования к ЦП и памяти службы, которая будет создана при развертывании модели. Профилирование проверяет службу, которая выполняет модель, и возвращает такие сведения, как загрузка ЦП, использование памяти и задержка ответа. Оно также предоставляет рекомендации по ЦП и памяти на основе использования ресурсов. Дополнительные сведения см. в разделе «Профилирование» раздела Развертывание моделей.
Модели упаковки и отладки
Перед развертыванием модели в рабочей среде она упаковывается в образ DOCKER. В большинстве случаев создание изображений происходит автоматически в фоновом режиме во время развертывания. Образ можно указать вручную.
При возникновении проблем с развертыванием можно выполнить развертывание в локальной среде разработки для устранения неполадок и отладки.
Преобразование и оптимизация моделей
Преобразование модели для открытия обмена нейронными сетями (ONNX) может повысить производительность. В среднем преобразование в ONNX может привести к увеличению производительности в 2 раза.
Дополнительные сведения об ONNX с Машинное обучение Azure см. в статье Создание и ускорение моделей ML.
Использование моделей
Обученные модели машинного обучения развертываются как веб-службы в облаке или локально. В развертываниях используются ЦП, GPU или программируемые для полей массивы шлюзов (FPGA). Модели также можно использовать из Power BI.
При использовании модели в качестве веб-службы вы предоставляете следующие элементы:
Также предоставляется конфигурация целевой платформы развертывания. Например, тип семейства виртуальных машин, объем доступной памяти и число ядер при развертывании в службе Azure Kubernetes.
При создании образа также добавляются компоненты, необходимые для Машинного обучения Azure. Например, ресурсы, необходимые для запуска веб-службы.
Пакетная оценка
Пакетная оценка поддерживается через конвейеры ML. Дополнительные сведения см. в статье Пакетные прогнозы для больших данных.
Веб-службы в режиме реального времени
Вы можете использовать модели в веб-службах со следующими целевыми объектами вычислений:
Чтобы развернуть модель как веб-службу, необходимо предоставить следующие элементы:
Для получения дополнительных сведений см. раздел Модели развертывания.
Управляемое развертывание
При развертывании в службе Azure Kubernetes можно использовать управляемый выпуск, чтобы включить следующие сценарии:
Analytics
Microsoft Power BI поддерживает использование моделей машинного обучения для аналитики данных. Дополнительные сведения см. в статьеИнтеграция Машинного обучения Azure в Power BI (предварительная версия).
Запись данных управления, необходимых для Млопс
Служба машинного обучения Azure позволяет отслеживать сквозной журнал всех активов машинного обучения с помощью метаданных.
Хотя некоторые сведения о моделях и наборах данных регистрируются автоматически, можно добавлять дополнительные сведения с помощью тегов. При поиске зарегистрированных моделей и наборов данных в рабочей области можно использовать теги в качестве фильтра.
Связывание набора данных с зарегистрированной моделью является необязательным шагом. Сведения об обращении к набору данных при регистрации модели см. в разделе Справочник по классам модели.
Уведомлять, автоматизировать и оповещать о событиях в жизненном цикле машинного обучения
Служба машинного обучения Azure публикует ключевые события в Azure EventGrid, которые можно использовать для уведомления и автоматизации событий в жизненном цикле машинного обучения. Дополнительные сведения см. в этом практическом руководстве.
Мониторинг проблем процессов и машинного обучения
Мониторинг позволяет понять, какие данные отправляются в модель и какие прогнозы она возвращает.
Эти сведения помогут вам понять, как используется модель. Собранные входные данные также могут быть полезны при обучении будущих версий модели.
Переобучение модели на новых данных
Часто требуется проверить модель, обновить ее или даже переучить с нуля, когда вы получаете новые сведения. Иногда получение новых данных является ожидаемой частью домена. В других случаях, как описано в разделе Обнаружение смещения данных (предварительная версия) в наборах, производительность модели может снизиться, например, изменения конкретного датчика, естественные изменения данных, такие как сезонные эффекты, или функции, переопределяющие их связь с другими функциями.
Нет универсального ответа на «Разделы справки узнать, следует ли переучить?» Однако ранее обсуждаемые средства для событий и мониторинга Azure ML являются хорошими отправными точками для автоматизации. После того как вы решили переучить, вам нужно:
Тема описанных выше действий заключается в том, что переобучение должно быть автоматизированным, а не нерегламентированным. Конвейеры Машинного обучения Azure — хороший ответ на создание рабочих процессов, касающихся подготовки данных, обучения, проверки и развертывания. Прочтите раздел Переобучение моделей с помощью конструктора «Машинное обучение Azure», чтобы увидеть, как конвейеры и конструктор «Машинное обучение Azure» помещаются в сценарий повторного обучения.
Автоматизация жизненного цикла машинного обучения
Вы можете использовать GitHub и Azure Pipelines для создания процесса непрерывной интеграции, который обучает модель. В типичном сценарии, когда анализ данных проверяет изменение в репозитории Git для проекта, конвейер Azure начнет обучающий запуск. Затем результаты выполнения можно просмотреть, чтобы увидеть характеристики производительности обученной модели. Также можно создать конвейер, который развертывает модель как веб-службу.
Расширение машинного обучения Azure упрощает работу с Azure Pipelines. Он предоставляет следующие усовершенствования Azure Pipelines:
Дополнительные сведения об использовании Azure Pipelines с Машинным обучением Azure см. по следующим ссылкам:
Фабрику данных Azure также можно использовать для создания конвейера приема данных, который готовит данные для использования в процессе обучения. См. дополнительные сведения о конвейере приема данных.
Дальнейшие действия
Дополнительные сведения см. в следующих ресурсах:
Как и где развертывать модели с помощью Службы машинного обучения Azure
MLOps: DevOps в мире Machine Learning
В 2018 году в профессиональных кругах и на тематических конференциях, посвященных AI, появилось понятие MLOps, которое быстро закрепилось в отрасли и сейчас развивается как самостоятельное направление. В перспективе MLOps может стать одной из наиболее востребованных сфер в IT. Что же это такое и с чем его едят, разбираемся под катом.

Что такое MLOps
MLOps (объединение технологий и процессов машинного обучения и подходов к внедрению разработанных моделей в бизнес-процессы) — это новый способ сотрудничества между представителями бизнеса, учеными, математиками, специалистами в области машинного обучения и IT-инженерами при создании систем искусственного интеллекта.
Иными словами, это способ превращения методов и технологий машинного обучения в полезный инструмент для решений задач бизнеса.
Нужно понимать, что цепочка продуктивизации начинается задолго до разработки модели. Ее первым шагом является определение задачи бизнеса, гипотезы о ценности, которую можно извлечь из данных, и бизнес-идеи по ее применению.
Само понятие MLOps возникло как аналогия понятия DevOps применительно к моделям и технологиям машинного обучения. DevOps — это подход к разработке ПО, позволяющий повысить скорость внедрения отдельных изменений при сохранении гибкости и надежности с помощью ряда подходов, среди которых непрерывная разработка, разделение функций на ряд независимых микросервисов, автоматизированное тестирование и деплоймент отдельных изменений, глобальный мониторинг работоспособности, система оперативного реагирования на выявленные сбои и др.
DevOps определил жизненный цикл программного обеспечения и в сообществе специалистов возникла идея использовать ту же методику применительно к большим данным. DataOps — попытка адаптировать и расширить методику с учетом особенностей хранения, передачи и обработки больших массивов данных в разнообразных и взаимодействующих друг с другом платформах.
С появлением определенной критической массы моделей машинного обучения, внедренных в бизнес-процессы предприятий, было замечено сильное сходство жизненного цикла математических моделей машинного обучения и жизненного цикла ПО. Разница только в том, что алгоритмы моделей создаются с помощью инструментов и методов машинного обучения. Поэтому естественным образом возникла идея применить и адаптировать для моделей машинного обучения уже известные подходы к разработке ПО. Таким образом, в жизненном цикле моделей машинного обучения можно выделить следующие ключевые этапы:
Отступление. Почему дообучить, а не переобучить? Термин «переобучение модели» имеет двоякое толкование: среди специалистов он означает дефект модели, когда модель хорошо предсказывает, фактически повторяет прогнозируемый параметр на обучающей выборке, но гораздо хуже работает на внешней выборке данных. Естественно, такая модель является браком, поскольку данный дефект не позволяет ее применять.
В этом жизненном цикле выглядит логичным использование DevOps-инструментов: автоматизированное тестирование, деплоймент и мониторинг, оформление расчета моделей в виде отдельных микросервисов. Но есть и ряд особенностей, которые препятствуют прямому применению этих инструментов без дополнительной ML-обвязки.
Как заставить модели работать и приносить прибыль
В качестве примера, на котором мы продемонстрируем применение подхода MLOps, возьмем ставшую классической задачу роботизации чата поддержки банковского (или любого другого) продукта. Обычно бизнес-процесс поддержки с помощью чата выглядит следующим образом: клиент вводит в чате сообщение с вопросом и получает ответ специалиста в рамках заранее определенного дерева диалогов. Задача автоматизации такого чата обычно решается с помощью экспертно определенных наборов правил, очень трудоемких в разработке и сопровождении. Эффективность такой автоматизации, в зависимости от уровня сложности задачи, может составлять 20–30%. Естественно, возникает идея, что более выгодным является внедрение модуля искусственного интеллекта — модели, разработанной с помощью машинного обучения, которая:
Как заставить такую продвинутую модель работать?
Как и при решении любой другой задачи, прежде чем разрабатывать такой модуль, необходимо определить бизнес-процесс и формально описать конкретную задачу, которую мы будем решать с применением метода машинного обучения. В этой точке и начинается процесс операционализации, обозначенный в аббревиатуре Ops.
Следующим шагом специалист Data science в сотрудничестве с инженером по данным проверяет доступность и достаточность данных и гипотезу бизнеса о работоспособности бизнес-идеи, разрабатывая прототип модели и проверяя ее фактическую эффективность. Только после подтверждения бизнесом может начинаться переход от разработки модели к встраиванию ее в системы, выполняющие конкретный бизнес-процесс. Сквозное планирование внедрения, глубокое понимание на каждом этапе, как модель будет использоваться и какой экономический эффект она принесет, является основополагающим моментом в процессах внедрения подходов MLOps в технологический ландшафт компании.
С развитием технологий ИИ лавинообразно увеличивается количество и разнообразие задач, которые могут быть решены при помощи машинного обучения. Каждый такой бизнес-процесс — это экономия компании за счет автоматизации труда сотрудников массовых позиций (колл-центр, проверка и сортировка документов и т. п.), это расширение клиентской базы за счет добавления новых привлекательных и удобных функций, экономия средств за счет оптимального их использования и перераспределения ресурсов и многое другое. В конечном счете любой процесс ориентирован на создание ценности и, как следствие, должен приносить определенный экономический эффект. Здесь очень важно четко сформулировать бизнес-идею и рассчитать предполагаемую прибыль от внедрения модели в общей структуре создания ценности компании. Случаются ситуации, когда внедрение модели не оправдывает себя, и время, затраченное специалистами по машинному обучению, обходится гораздо дороже, нежели рабочее место оператора, выполняющего эту задачу. Именно поэтому такие случаи необходимо стараться выявлять на ранних этапах создания систем ИИ.
Следовательно, прибыль модели начинают приносить только тогда, когда в процессе MLOps была верно сформулирована бизнес-задача, расставлены приоритеты и на ранних этапах разработки сформулирован процесс внедрения модели в систему.
Новый процесс – новые вызовы
Исчерпывающий ответ на принципиальный вопрос бизнеса о том, насколько ML-модели применимы для решения задач, общий вопрос доверия к ИИ — это один из ключевых вызовов в процессе развития и внедрения подходов MLOps. Первоначально бизнес скептически воспринимает внедрение машинного обучения в процессы — сложно полагаться на модели в тех местах, где ранее, как правило, работали люди. Для бизнеса программы представляются «черным ящиком», релевантность ответов которого еще надо доказать. Кроме того, в банковской деятельности, в бизнесе операторов связи и других существуют жесткие требования государственных регуляторов. Аудиту подвергаются все системы и алгоритмы, которые внедрены в банковские процессы. Чтобы решить эту задачу, доказать бизнесу и регуляторам обоснованность и корректность ответов искусственного интеллекта, вместе с моделью внедряются средства мониторинга. Кроме того, существует процедура независимой валидации, обязательная для регуляторных моделей, которая соответствует требованиям ЦБ. Независимая экспертная группа проводит аудит результатов, полученных моделью с учетом входных данных.
Второй вызов — оценка и учет модельных рисков при внедрении модели машинного обучения. Если даже человек не может со стопроцентной уверенностью ответить на вопрос, белым было то самое платье или голубым, то и искусственный интеллект тоже имеет право на ошибку. Также стоит учесть, что со временем данные могут меняться, и моделям необходимо дообучаться, чтобы выдавать достаточно точный результат. Чтобы бизнес-процесс не пострадал, необходимо управлять модельными рисками и отслеживать работу модели, регулярно дообучая ее на новых данных.

Но после первой стадии недоверия начинает проявляться обратный эффект. Чем больше моделей успешно внедряется в процессы, тем больше у бизнеса растет аппетит к использованию искусственного интеллекта — находятся новые и новые задачи, которые можно решить методами машинного обучения. Каждая задача запускает целый процесс, требующий тех или иных компетенций:
К вопросу о компетенциях
В теории все задачи MLOps можно решать классическими инструментами DevOps и не прибегать к специализированному расширению ролевой модели. Тогда, как мы уже отметили выше, дата-сайентист должен быть не только математиком и специалистом по аналитике данных, но и гуру всего пайплайна — на его плечи ложится разработка архитектуры, программирование моделей на нескольких языках в зависимости от архитектуры, подготовка витрины данных и деплоймент самого приложения. Однако создание технологической обвязки, реализуемой в сквозном процессе MLOps, занимает до 80% трудозатрат, а это значит, что квалифицированный математик, которым является качественный Data Scientist, будет только 20% времени посвящать своей специальности. Поэтому разграничение ролей специалистов, осуществляющих процесс внедрения моделей машинного обучения, становится жизненно необходимым.
Насколько детально должны разграничиваться роли, зависит от масштабов предприятия. Одно дело, когда в стартапе один специалист, труженик на запасе энергетиков, сам себе и инженер, и архитектор, и DevOps. Совсем другое дело, когда на крупном предприятии все процессы разработки моделей сконцентрированы на нескольких Data Science специалистах высокого уровня, в то время как программист или специалист по работе с базами данных — более распространенная и менее дорогая компетенция на рынке труда — может взять на себя большую часть рутинных задач.
Таким образом, от того, где же проходит граница в выборе специалистов для обеспечения процесса MLOps и как организован процесс операционализации разрабатываемых моделей, напрямую зависит скорость и качество разрабатываемых моделей, производительность команды и микроклимат в ней.
Что уже сейчас сделано нашей командой
Мы не так давно начали строить структуру компетенций и процессы MLOps. Но уже сейчас в стадии тестирования MVP находятся наши проекты по управлению жизненным циклом моделей и по применению моделей как сервис.
Также мы определили оптимальную для крупного предприятия структуру компетенций и организационную структуру взаимодействия между всеми участниками процесса. Были организованы Agile-команды, решающие задачи для всего спектра бизнес-заказчиков, а также налажен процесс взаимодействия с проектными командами по созданию платформ, инфраструктуры, которая является фундаментом строящегося здания MLOps.
Вопросы на будущее
MLOps — развивающееся направление, которое испытывает нехватку компетенций и в будущем наберет обороты. А пока лучше всего отталкиваться от наработок и практик DevOps. Основной целью MLOps является более эффективное использование ML-моделей для решения задач бизнеса. Но при этом возникает множество вопросов:
5 столпов MLOps
Команда Advanced Analytics GlowByte запускает цикл статей посвященных MLOps. MLOps — это набор практик и технологий, которые объединяют Machine Learning, DevOps, Data Engineering и Model Governance в единую методологию создания, внедрения и эксплуатации моделей машинного обучения. MLOps помогает бизнесу развивать Data Science и внедрять качественные ML модели на 80% быстрее.
Из статей узнаете о следующем:
В этой статье команда рассказывает как из общих методов и технологий машинного обучения получить приложения для решения конкретных бизнес-задач.
Бизнес собирает петабайты данных для использования в Data Science проектах, но это не гарантирует прибыль. Единого понимания, как работать с ML-приложениями, еще нет, хотя у многих компаний есть обнадеживающие пилоты и удачные эксперименты, превратить их в стабильную ценность для бизнеса не всегда получается и многие компании не могут превратить обнадеживающие пилоты и удачные эксперименты в стабильную ценность для бизнеса. Причина — не изъяны технологий ML, и даже не слабая квалификация специалистов, а отсутствие проторенной дороги от среды экспериментов в промышленную эксплуатацию (как вариант — “от теста в продакшн”). Концепция MLOps такую дорогу прокладывает операционализацией работы с моделями, систематизацией внедрения и автоматизацией всего что только можно в жизненном цикле моделей.
Как организовать процесс разработки? Во-первых, каждому разработчику нужна полноценная среда разработки, которая не ограничивает в технологиях и ресурсах. Время разработки на локальных машинах уходит. Компании смотрят в сторону выделенных серверов или кластеров с изолированными средами разработки (например: JupyterHub на k8s) или же на облачные технологии (например: Yandex DataSphere, Amazon SageMaker). Во-вторых, все репозитории моделей важно вести в одинаковой структуре, а модели вызывать единообразно. Это упростит взаимодействие в команде и позволит организовать единый автоматизированный CI/CD-процесс внедрения моделей.
Как выстроить сквозной жизненный цикл моделей (ЖЦМ)? Для начала вспомним, что в ЖЦМ участвует не только непосредственный разработчик модели (Data Scientist), но еще и инженер данных (Data Engineer), IT специалист (IT Engineer), специалист по операционализации (MLOps engineer) и сам бизнес-заказчик. ЖЦМ описывает взаимодействие между ролями участников процесса и внешними системами. Его можно представить в виде бизнес-процесса в BPMN-нотации. Шаг процесса — это конкретная задача конкретного специалиста. Например, для окончания разработки витрины данных для модели, необходимо наличие кода сборки витрины, ссылки на саму витрину и документации о разработке.
Как выстроить коммуникацию и взаимодействие между командами? Выстроив бизнес процессы, мы уже упростили взаимодействие между командами, но нужна система хранения артефактов и метаданных модели, чтобы разработчикам не приходилось искать информацию в почте или мессенджерах. Для этого подойдет единый портал, в котором будут храниться все данные конкретной модели, и этот портал должен наполняться в соответствии с течением бизнес процесса ЖЦМ. Для решения таких задач существует ряд решений (например: BPMN движки, Jira, таск-менеджеры и тд), однако ни одно решение не может закрыть все проблемы на 100%.
Как управлять моделями? Бизнес-заказчик хочет держать руку на пульсе ML-проектов, чтобы понимать статус разработки, управлять человеческими ресурсами и вовремя отменять нерентабельные проекты. Этого позволяет достичь реализация БП на каком-либо движке и объединение БП с системой хранения метаданных. Так мы получим одну точку входа для разработчиков и менеджмента.
Как сократить время доставки моделей в продакшн? Вопрос сложный и затрагивает многие этапы жизненного цикла моделей. MLOps-подход сокращает time-to-market моделей. Он позволяет структурировать процесс разработки и упаковки моделей. Используя DevOps методологию, мы выстраиваем автоматизированный CI/CD пайплайн сборки ML приложения из кода Data Scientist`а и доставки его до всех контуров. В свою очередь, выстроенный бизнес-процесс и единый портал сокращают время на коммуникацию и менеджмент проектов.
Что делать после внедрения модели? Понятно, что ЖЦМ не заканчивается на внедрении. На промышленной среде придется присматривать за качеством поступающих данных, за степенью деградации самой модели и за инфраструктурой, на которой работает модель. При падении качества, модель необходимо откалибровать или обучить заново на новых данных. А при наличии проблем с серверной частью, мы хотим своевременно обнаружить их и проинформировать ответственных лиц. Для этого стоит выстроить дашборд мониторинга (а лучше — полноценную систему), который бы включал в себя все метрики, влияющие на работоспособность модели и на бизнес в целом.
Однако помимо этих столпов есть и другие системы, связанные с MLOps:
Об этом мы подробно расскажем в следующих статьях этого цикла, где остановимся на готовых решениях и технологиях для реализации MLOps-подхода в широком смысле.



