Memory repo minecraft что это
Представляю вам свою карту! Она правда на любителя, ведь это сюжетная карта. Также тут есть небольшой паркур, лабиринт и какое-то непонятное испытание. Ну историю этого испытания мне кажется лучше не рассказывать. И да, многие скажут что сюжета нет, но точнее что он обрывками. То есть, вы заканчиваете карту, а саму историю не узнаёте. Но если бы, вы, её узнали то возможно не было бы второй части. Вторая часть расскажет вам о прошлом и будущем. А пока проходите первую часть.
Майнкрафт занимает всю оперативную память.
Выделение оперативной памяти (ОЗУ) для Minecraft и TLauncher
Для нормальной работы Minecraft рекомендуется выделять как можно больше памяти, особенно при использовании модов и ресурс-паков высокого разрешения. Существует несколько проблем в этом направлении, решить их просто.
1) Перед переустановкой Java, обязательно необходимо узнать, что у вас система 64 разрядная. Выполните следующие действия для определения разрядности:
2) Как только узнали, что у вас 64 разрядная система, приступаем к установке Java 64x. (Если у вас всё-таки 32-битная система, необходимо переустановка системы на 64-битную, при условии, что процессор поддерживает 64-битную схему.)
Для Windows
Скачиваем установщик Java 64, запускаем его и следующем инструкции (просто нажать Install).
Для Linux
Скачиваем установщик Java 64, запускаем его и следующем инструкции (просто нажать Install).
3) После этого, в настройках можно выделить максимальное количество памяти (при создании мод-паков тоже).
Старую версию Java 32x удалять необязательно, но если в настройках продолжает отображаться только 1 гб, то удалите старую версию и установите только Java 64x.
В игре Minecraft у меня проблема с модами: Помогите пожалуйста, не могу установить мод. Выходит такая папка memory_repo

СМОТРИ Я СДЕЛАЛ ТАК НЕ ПОЙМИ НЕ ПРАВИЛЬНО Я ПОСТАРАЛСЯ БОЛЕЕ ПОНЯТНО РАССКАЗАТЬ!
1 найди папку memory-repo
2 зайди в корзину (она пригодится)
3 (касается папки memory-repo) открывай её до lady lib ну или когда наткнёшься на файлы там будут идти папки остановись когда наткнёшься на файлы
4 поочерёдно удаляй все файлы (к примеру удалила lady lib там их 2, зашла в корзину окончательно удалила)
5 и так поочерёдно идёшь назад и удаляешь все папки (удалила папку зашла в корзину удалила окончательно)

Предупреждение :
Мод подходит не для всех и не факт, что он вам нужен. Он может сделать ситуацию еще хуже, прочитайте ниже советы автора по использованию мода.
Как многие знают, при работе игра постоянно генерирует информацию которая некоторое время накапливается в свободной оперативной памяти, а после очищается как «отработанная» специальным очистителем. При игре с большими сборками и маленьким количеством оперативной памяти некоторые игроки могут столкнуться с лагами или вылетами игры с ошибкой OutOfMemoryError, именно им, теоретически, может помочь данный мод, так как он иначе очищает кеш памяти.
Вы можете запустить процесс очистки самостоятельно при помощи команды /cleanmemory
Рекомендации автора по аргументам Java.
Нельзя использовать аргумент -XX:+DisableExplicitGC, так как с ним мод не будет работать.
Если ваша игра сильно фризится в момент очистки памяти, авто рекомендует использовать такие дополнительные аргументы:
Устранение ошибок при майнинге, связанных с неверной установкой или конфигурированием видеокарт

При настройке и эксплуатации оборудования для майнинга часто возникают различные ошибки.
В данной статье рассматриваются характерные ошибки, возникающие при майнинге при неверной сборке майнинг ферм или в связи с программными ошибками.
Аппаратные ошибки, приводящие к неверной работе или отсутствии видеокарт в диспетчере задач
На аппаратном уровне к ошибкам в определении видеокарт или к постоянному их вылету при работе приводят некоторые часто встречающиеся проблемы. К ним относятся:
Во всех случаях, связанных с поиском неисправностей в работе электро и радиоаппаратуры и вычислительной техники нужно помнить, что:
ОСНОВНЫМИ ПРИЧИНАМИ НЕИСПРАВНОСТЕЙ В ЛЮБЫХ ЭЛЕКТРИЧЕСКИХ УСТРОЙСТВАХ ЯВЛЯЮТСЯ НАЛИЧИЕ ЛИШНИХ ИЛИ ОТСУТСТВИЕ НУЖНЫХ КОНТАКТОВ.
Программные ошибки, связанные с видеокартами, приводящие к сбоям майнеров
При неверной настройке операционной системы, сбое в установке драйверов, неправильной конфигурации майнеров, избыточном разгоне возникают ошибки, в результате которых происходит сбой при запуске программы-майнера.
Ошибки, вызванные неправильной установкой драйверов
Как правило, в майнинг фермах с несколькими видеокартами возникают следующие ошибки, связанные с неправильной установкой драйверов:
Ошибка с кодом 43, как правило, возникает при установке новых драйверов в системе, что может сделать и сама система во время автоматической установки обновлений. Кроме того, драйвера могут слететь при сбоях в питании, появлении ошибок на носителе системы, воздействии вирусов и других проблемах.
После такого обновления может появиться ошибка 43, а также значительно упасть хешрейт видеокарт. Для видеокарт AMD после установки драйверов нужно применить AMD-Compute-Switcher, а для видеокарт Нвидиа включить P0 state согласно методике, описанной в статье «Оптимизация потребления видеокарт Nvidia при майнинге».
Если после применения патчера и мода (для Windows 7) и перезагрузки системы ошибка не исчезает, то возможно на видеокарте прошит неверный BIOS, произошел сбой при его записи, либо вышла из строя микросхема BIOS на видеокарте. Для устранения такой ошибки нужно:
При невозможности восстановить рабочее состояние видеокарты прошивкой верного Биоса или переключением переключателя BIOS на резерв нужно менять чип BIOS в сервис-центре, либо искать другую причину неполадок.
Ошибки в конфигурации майнера при указании видеокарт
Этот вид ошибок возникает в случае отсутствия или неправильного указания в пакетном файле для запуска майнинга видеокарт, которые должны осуществлять майнинг (как АМД, так и Nvidia).
Например, в программе claymore dual miner и других программах от этого программиста, иногда возникает ошибка NO AMD OPENCL found. Она появляется при запуске программы для майнинга и обозначает, что не найдено устройств, поддерживающих технологию OPENCL. В разных программах она может иметь различное написание, но ее суть сводится к невозможности найти подходящее для майнинга устройство. При отсутствии аппаратных ошибок и проблем, связанных с неверной установкой драйверов, неисправность нужно искать в конфигурации майнера.
Эта ошибка может возникать и в других программах, использующихся для майнинга. Например, в программе sgminer подобная ошибка называется clDevicesNum returned error, no GPUs usable. При запуске майнера появляется подобное сообщение:
[02:56:02] Started sgminer v0.1.1
[02:56:02] * using Jansson 2.11
[02:56:09] Specified platform that does not exist
[02:56:09] clDevicesNum returned error, no GPUs usable
[02:56:09] Command line options set a device that doesn’t exist
Еще раз повторимся, что если в диспетчере устройств нужные видеокарты отображены корректно и не имеют восклицательных знаков с кодами ошибки, то неправильно сконфигурирован BAT-файл. Это случается в системах с различными типами карт, установленными в системе (например, интегрированная видеокарта плюс видеокарты AMD или одновременное использование GPU от AMD и Nvidia и все три типа устройств вместе). Как правило, для устранения этой ошибки нужно либо правильно указать номера использующихся в майнере видеокарт, либо указать какую платформу (AMD или Nvidia) нужно использовать.
В sgminer (его различных версиях и подобных программах, например, cgminer) в смешанных системах может понадобиться указывать в командной строке параметр —gpu-platform 1 или 2.
Обычно, при отсутствии включенной внутренней видеокарты этот майнер работает без указания этого парметра, но в этом случае иногда может потребоваться использование команды —gpu-platform 0.
Другие ошибки, приводящие к сбоям в работе майнеров
Рассмотрим другие ошибки, которые иногда возникают при работе программ для майнинга:


ошибка WATCHDOG: GPU hangs in OpenCL call появляется при переразгоне видеокарт, некачественных райзерах, плохих (очень длинных) соединительных USB-кабелях. Не нужно выжимать из видеокарт все соки, увеличивая частоту памяти и видеоядра, так как простои, вызванные переразгоном, сведут на нет весь доход от такого майнинга. Понять то, где выставлены очень большие значения частоты поможет программа hwinfo, которая показывает ошибки по памяти для видеокарт AMD:

Как правило, при переразгоне по памяти вылетает одна из видеокарт, а при чрезмерном разгоне по ядру (или очень сильном даунвольтинге) компьютер полностью зависает;
Заключение
Майнинг требует наличия определенных знаний, связанных с эксплуатацией вычислительной техники и сетей связи. Это необходимо, потому что знание основ функционирования радиоаппаратуры и каналов связи дает возможность самостоятельно разобраться в причинах появления неполадок и понять, как их можно устранить наиболее рациональным способом.
Знание основ электротехнических цепей поможет избежать ошибок, связанных с навешиванием чрезмерной нагрузки на одну линию (например, более одной видеокарты на линию Molex), что часто приводит к подгоранию контактов или выходу из строя райзеров и видеокарт.
Понимание закона Ома поможет избежать проблем, связанных с использованием переходников с разъема питания SATA на райзера, которое гарантированно приведет к прогоранию контактов и связанным с этим проблемам.
Чем больше человек знает, тем больше он понимает, что знает очень мало или не знает ничего… Процесс поиска истины благотворно воздействует на человеческую карму и дает жизненный опыт, для обретения которого, возможно, мы и живем…
Here be dragons: Управление памятью в Windows как оно есть [1/3]

Каталог:
Один
Два
Три
Менеджер памяти (и связанные с ним вопросы контроллера кеша, менеджера ввода/вывода и пр) — одна из вещей, в которой (наряду с медициной и политикой) «разбираются все». Но даже люди «изучившие винду досконально» нет-нет, да и начинают писать чепуху вроде (не говоря уже о другой чепухе, написанной там же):
Грамотная работа с памятью. За все время использования у меня своп файл не увеличился ни на Килобайт. По этому Фаерфокс с 10-20 окнами сворачивается / разворачивается в/из трея как пуля. Такого эффекта я на винде добивался с отключенным свопом и с переносом tmp файлов на RAM диск.
Цель данной статьи — не полное описание работы менеджера памяти (не хватит ни места ни опыта), а попытка пролить хоть немного света на темное царство мифов и суеверий, окружающих вопросы управления памятью в Windows.
Disclaimer
Сам я не претендую на то, чтобы знать все и никогда не ошибаться, поэтому с радостью приму любые сообщения о неточностях и ошибках.
Введение
С чего начать не знаю, поэтому начну с определений.
Commit Size — количество памяти, которое приложение запросило под собственные нужды.
Working Set (на картинке выше он так и называется Working Set) — это набор страниц физической памяти, которые в данный момент «впечатаны» в адресное пространство процесса. Рабочий набор процесса System принято выделять в отдельный «Системный рабочий набор», хотя механизмы работы с ним практически не отличаются от механизмов работы с рабочими наборами остальных процессов.
И уже здесь зачастую начинается непонимание. Если присмотреться, можно увидеть, что Commit у многих процессов меньше Working Set-а. То есть если понимать буквально, «запрошено» меньше памяти, чем реально используется. Так что уточню, Commit — это виртуальная память, «подкрепленная» (backed) только физической памятью или pagefile-ом, в то время как Working Set содержит еще и страницы из memory mapped файлов. Зачем это делается? Когда делается NtAllocateVirtualMemory (или любые обертки над heap manager-ом, например malloc или new) — память как бы резервируется (чтоб еще больше запутать, это не имеет никакого отношения к MEM_RESERVE, который резервирует адресное пространство, в данном же случае речь идет о резервировании именно физических страниц, которые система действительно может выделить), но физические страницы впечатываются только при фактическом обращении по выделенному адресу виртуальной памяти. Если позволить приложениям выделить больше памяти, чем система реально может предоставить — рано или поздно может случиться так, что все они попросят реальную страницу, а системе неоткуда будет ее взять (вернее некуда будет сохранить данные). Это не касается memory mapped файлов, так как в любой момент система может перечитать/записать нужную страницу прямо с/на диск(а).
В общем, суммарный Commit Charge в любой момент времени не должен превышать системный Commit Limit (грубо, суммарный объем физической памяти и всех pagefile-ов) и с этим связана одна из неверно понимаемых цифр на Task Manager-ах до Висты включительно.
Commit Limit не является неизменным — он может увеличиваться с ростом pagefile-ов. Вообще говоря, можно считать, что pagefile — это такой очень специальный memory mapped файл: привязка физической страницы в виртуальной памяти к конкретному месту в pagefile-е происходит в самый последний момент перед сбросом, в остальном же механизмы memory mapping-а и swapping-а очень схожи.
Working Set процесса делится на Shareable и Private. Shareable — это memory mapped файлы (в том числе и pagefile backed), вернее те части, которые в данный момент действительно представлены в адресном пространстве процесса физической страницей (это же Working Set в конце концов), а Private — это куча, стеки, внутренние структуры данных типа PEB/TEB и т.д. (опять таки, повторюсь на всякий случай: речь идет только той части кучи и прочих структур, которые физически находятся в адресном пространстве процесса). Это тот минимум информации, с которой уже можно что то делать. Для сильных духом есть Process Explorer, который показывает еще больше подробностей (в частности какая часть вот той Shareable действительно Shared).
И, самое главное, ни один из этих параметров по отдельности не позволяет сделать более менее полноценных выводов о происходящем в программе/системе.
Task Manager
Столбец «Memory» в списке процессов и практически вся вкладка «Performance» настолько часто понимаются неправильно, что у меня есть желание, чтоб Task Manager вообще удалили из системы: те, кому надо смогут воспользоваться Process Explorer-ом или хотя бы Resource Monitor-ом, всем остальным Task Manager только вредит. Для начала, собственно о чем речь 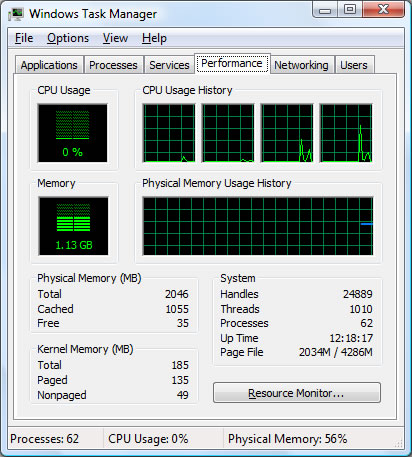
Начну с того, о чем я уже упоминал: Page File usage. XP показывает текущее использование pagefile-а и историю (самое забавное, что в статус баре те же цифры названы правильно), Виста — показывает Page File (в виде дроби Current/Limit), и только Win7 называет его так, чем оно на самом деле является: Commit Charge/Commit Limit.
Эксперимент. Открываем таск менеджер на вкладке с «использованием пейджфайла», открываем PowerShell и копируем в него следующее (для систем, у которых Commit Limit ближе, чем на 3 Гб от Commit Charge можно в последней строчке уменьшить 3Gb, а лучше увеличить pagefile):
Это приводит к мгновенному повышению «использования свопфайла» на 3 гигабайта. Повторная вставка «использует» еще 3 Гб. Закрытие процесса мгновенно освобождает весь «занятый свопфайл». Самое интересное, что, как я уже говорил memory mapped файлы (в том числе и pagefile backed) являются shareable и не относятся к какому либо конкретному процессу, поэтому не учитываются в Commit Size никакого из процессов, с другой стороны pagefile backed секции используют (charged against) commit, потому что именно физическая память или пейджфайл, а не какой нибудь посторонний файл, будут использоваться для того, чтобы хранить данные, которые приложение захочет разместить в этой секции. С третьей стороны, после меппинга секции себе в адресное пространство, процесс не трогает ее — следовательно, физические страницы по этим адресам не впечатываются и никаких изменений в Working Set процесса не происходит.
Строго говоря, пейджфайл действительно «используется» — в нем резервируется место (не конкретное положение, а именно место, как размер), но при этом реальная страница, для которой это место было зарезервировано может находиться в физической памяти, на диске или И ТАМ И ТАМ одновременно. Вот такая вот циферка, признайтесь честно, сколько раз глядя на «Page File usage» в Task Manager-е Вы действительно понимали, что она означает.
Что же до Processes таба — там все еще по дефолту показывается Memory (Private Working Set) и несмотря на то, что он называется совершенно правильно и не должен вызывать недоразумений у знающих людей — проблема в том, что подавляющее большинство людей, которые смотрят на эти цифры совершенно не понимают, что они означают. Простой эксперимент: запускаем утилилиту RamMap (советую скачать весь комплект), запускаете Task Manager со списком процессов. В RamMap выбираете в меню Empty->Empty Working Sets и смотрите на то, что происходит с памятью процессов.
Если кого-то все еще раздражают циферки в Task Manager-е, можете поместить следующий код в профайл павершелла:
В первую очередь отмечу, что кеш в Windows не блочный, а файловый. Это дает довольно много преимуществ, начиная от более простого поддержания когерентности кеша например при онлайн дефрагментации и простого механизма очистки кеша при удалении файла и заканчивая более консистентными механизмами его реализации (кеш контроллер реализован на основе механизма memory mapping-а), возможностью более интеллектуальных решений на основе более высокоуровневой информации о читаемых данных (к примеру интеллектуальный read-ahead для файлов открытых на последовательный доступ или возможность назначать приоритеты отдельным файловым хендлам).
В принципе из недостатков я могу назвать только значительно более сложную жизнь разработчиков файловых систем: слышали о том, что написание драйверов — это для психов? Так вот, написание драйверов файловых систем — для тех, кого даже психи считают психами.
Страница из лекции какого то токийского университета (эх, мне бы так):
На этом работа собственно кеш-менеджера заканчивается и начинается работа менедера памяти. Когда выше мы делали EmptyWorkingSet это не приводило ни к какой дисковой активности, но тем не менее, физическая память используемая процессом сокращалась (и все физические страницы действительно уходили из адресного пространства процесса делая его почти полностью невалидным). Так куда же она уходит после того, как отбирается у процесса? А уходит она, в зависимости от того, соответствует ли ее содержимое тому, что было прочитано с диска, в один из двух списков: Standby (начиная с Висты это не один список, а 8, о чем позже) или Modified:
Standby список таким образом — это свободная память, содержащая какие то данные с диска (в том числе возможно и pagefile-а).
Если Page Fault происходит по адресу, который спроецирован на часть файла, которая все еще есть в одном из этих списков — она просто возвращается обратно в рабочий набор процесса и впечатывается по искомому адресу (этот процесс называется softfault). Если нет — то, как и в случае со слотами кеш менеджера, выполняется PAGING_IO запрос (называется hardfault).
Modified список может содержать «грязные» страницы достаточно долго, но либо когда размер этого списка чрезмерно вырастает, либо по когда система видит недостаток свободной памяти, либо по таймеру, просыпается modified page writer thread и начинает частями сбрасывать этот список на диск, и перемещая страницы из modified списка в standby (ведь эти страницы опять содержат неизмененную копию данных с диска).
Upd:
Пользователь m17 дал ссылки на выступление Руссиновича на последнем PDC на ту же тему (хм, я честно его до этого не смотрел, хотя пост во много перекликается). Если понимание английского на слух позволяет, то чтение данного топика можно заменить прослушиванием презентаций:
Mysteries of Windows Memory Management Revealed, Part 1 of 2
Mysteries of Windows Memory Management Revealed, Part 2 of 2
Пользователь DmitryKoterov подсказывает, что перенос пейджфайла на RAM диск иногда действительно может иметь смысл (вот уж никогда б наверное и не догадался, если б не написал топик), а именно, если RAM-диск использует физическую память, недоступную остальной системе (PAE + x86 + 4+Gb RAM).
Пользователь Vir2o в свою очередь подсказывает что хотя при некоторых условиях и пожертвовав стабильностью системы ram-диск, использующий физическую память, невидимую остальной системе написать можно, но такое очень маловероятно.
Управление памятью: Взгляд изнутри

Доброго времени суток!
Хочу представить вашему вниманию перевод статьи Джонатана Барлетта (Jonathan Bartlett), который является техническим директором в компании New Medio. Статья была опубликована 16 ноября 2004 года на сайте ibm.com и посвящена методам управления памятью. Хотя возраст статьи достаточно высок (по меркам IT), информация в ней является фундаментальной и описывает подходы к распределению памяти, их сильные и слабые стороны. Всё это сопровождается «самопальными» реализациями, для лучшего усвоения материала.
Аннотация от автора
Решения, компромиссы и реализации динамического распределения памяти
Получите представление о методах управления памятью, которые доступны Linux разработчикам. Данные методы не ограничиваются языком C, они также применяются и в других языках программирования. Эта статья даёт подробное описание как происходит управление памятью, на примерах ручного подхода (manually), полуавтоматического (semi-manually) с использованием подсчёта ссылок (referencing count) или пула (pooling) и автоматического при помощи сборщика мусора (garbage collection).
Почему возникает необходимость в управлении памятью
Управление памятью одна из наиболее фундаментальных областей в программировании. Во множестве скриптовых языков, вы можете не беспокоится об управлении памятью, но это не делает сей механизм менее значимым. Знания о возможностях вашего менеджера памяти (memory manager) и тонкостях его работы, являются залогом эффективного программирования. В большинстве системных языков, например таких как C/C++, разработчику необходимо самому следить за используемой памятью. Статья повествует о ручных, полуавтоматических и автоматических методах управления памятью.
Было время, когда управления памятью не было большой проблемой. В качестве примера можно вспомнить времена разработки на ассемблере под Apple II. В основном программы запускались не отдельно от ОС, а вместе с ней. Любой участок памяти мог использоваться как системой, так и разработчиком. Не было необходимости в расчёте общего объёма памяти, т.к. она была одинакова для всех компьютеров. Так что требования к памяти были достаточно статичны — необходимо было просто выбрать участок памяти и использовать его.
Физическая и виртуальная память
Для понимая, как происходит выделение в пределах программы, необходимо иметь представление как ОС выделяет память под программу. (прим. переводчика: т.к. программа запускается под конкретной ОС, то именно она решает, сколько памяти выделить под ту или иную программу) Каждый запущенный процесс считает что имеет доступ ко всей физической памяти компьютера. Очевиден тот факт, что одновременно работает множество процессов, и каждый из них не может иметь доступ ко всей памяти. Но что будет если процессам использовать виртуальную память (virtual memory).
В качестве примера, допустим программа обращается к 629-у участку в памяти. Система виртуальной памяти (virtual memory system), не гарантирует что данные хранятся в RAM по адресу 629. Фактически, это может быть даже не RAM — данные могли быть перенесены на диск, если RAM оказалась вся занята. Т.е. в вирт. памяти могут храниться адреса, соответствующие физическому устройству. ОС хранит таблицу соответствий вирт. адресов к физическим (virtual address-to-physical address), чтобы компьютер мог правильно реагировать на запрос по адресу (address requests). Если RAM хранит физические адреса, то ОС будет вынуждена временно приостановить процесс, выгрузить часть данных НА ДИСК (из RAM), подгрузить необходимые данные для работы процесса С ДИСКА и перезапустить процесс. Таким образом, каждый процесс получает своё адресное пространство с которым может оперировать и может получить ещё больше памяти, чем ему было выделила ОС.
В 32-х битных приложениях (архитектура x86), каждый процесс может работать с 4 гигабайтами памяти. На данный момент большинство пользователей не владеют таким объёмом. Даже если используется подкачка (swap), всё равно должно получиться меньше 4 Гб на процесс. Таким образом, когда процесс выгружается в память, ему выделяется определённое пространство. Конец этого участка памяти именуется как system break. За этой границей находится неразмеченная память, т.е. без проекции на диск или RAM. Поэтому когда у процесса заканчивается память (из той, что ему была выделена при загрузке) он должен запросить у ОС больший кусок памяти. (Mapping (от англ. mapping — отражение, проекция ) — это математический термин, означающий соответствие один к одному — т.е. когда по виртуальному адресу хранится другой адрес (адрес на диске), по которому уже хранятся реальные данные)
Как вы можете видеть, простые вызовы brk() или mmap() могут быть использованы для расширения памяти процесса. Дальше по тексту будут использоваться brk() т.к. он является наиболее простым и распространённым инструментом.
Листинг 1: Глобальные переменные для нашего аллокатора
Как упоминалось выше, «край» размеченной памяти (последний действительный адрес) имеет несколько названий — System break или Current break. В большинстве Unix-like систем, для поиска current system break, используется функция sbrk(0). sbrk отодвигает current break на n байт (передаётся в аргументе), после чего current break примет новое значение. Вызов sbrk(0) просто вернёт current system. Напишем код для нашего malloc, который будет искать current break и инициализировать переменные:
Листинг 2: Инициализации Allocator-а
Для правильного управления, необходимо следить за выделяемой и освобождаемой памятью. Необходимо помечать память как “неиспользуемую”, после вызова free() для какого либо участка памяти. Это необходимо для поиска свободной памяти, когда вызывается malloc(). Таким образом, начало каждого участка памяти, которое возвращает malloc() будет будет иметь следующую структуру:
Листинг 3: Структура Memory Control Block
Можно догадаться, что данная структура будет мешать, если вернуть на неё указатель (вызов функции malloc). (прим. переводчика: имеется ввиду, что если указатель установить на начало этой структуры, то при записи в эту память, мы потеряем информацию о том, сколько памяти было выделено) Решается всё достаточно просто — её необходимо скрыть, а именно вернуть указатель на память, которая располагается сразу за этой структурой. Т.е. по факту вернуть указатель на ту область, которая не хранит в себе никакой информации и куда можно “писать” свои данные. Когда происходит вызов free(), в котором передаётся указатель, мы просто отматываем назад некоторое количество байт (а конкретно sizeof(mem_control_block) ), чтобы использовать данные в этой структуре для поиска в дальнейшем.
Для начала поговорим об освобождении памяти, т.к. этот процесс проще чем выделение. Всё что необходимо сделать для освобождения памяти, это взять указатель, переданный в качестве параметра функции free(), переместить его на sizeof(struct mem_control_block) байт назад, и пометить память как свободную. Вот код:
Листинг 4: Освобождение памяти
Как вы можете заметить, в данном примере освобождение происходит за константное время, т.к. имеет очень простую реализацию. С выделением уже немного сложнее. Рассмотрим алгоритм в общих чертах:
Листинг 5: Псевдокод алгоритма работы аллокатора
Вся суть заключается в своего рода “прогулке” по памяти с целью нахождения свободных участков. Взглянем на код:
Листинг 6: Реализация алгоритма работы
Это наш Memory Manager. Теперь его необходимо собрать, для использования в своих программах.
Чтобы построить наш malloc-подобный allocator, нужно набрать следующую команду (мы не затронули такие функции как realloc(), но malloc() и free() являются наиболее значимыми):
Листинг 7: Компиляция
На выходе получим файл malloc.so, который является библиотекой и содержит наш код.
На Unix системах, вы можете использовать свой allocator, вместо системного. Делается это так:
Листинг 8: Заменяем стандартный malloc
LD_PRELOAD это переменная среды окружения (environment variable). Она используется динамическим линковщиком (dynamic linker) для определения символов, которые содержаться в библиотеке, перед тем как эта библиотека будет подгружена каким-либо приложением. Это подчёркивает важность символов в динамических библиотеках. Таким образом, приложения, которые будут создаваться в рамках текущей сессии, будут использовать malloc(), которой мы только что написали. Некоторые приложения не используют malloc(), но это скорее исключение, чем правило. Другие же, которые использую аллокаторы на подобии realloc(), или которые не имеют представления о внутреннем поведении malloc(), скорее всего упадут. Ash shell (ash — это командная оболочка UNIX подобных систем) отлично работает с нашим malloc аллокатором.
Если вы хотите убедиться в том, что используется именно ваш malloc(), можете добавить вызов write() в начало ваших функций.
В C++ вы можете реализовать свой аллокатор для класса или шаблона с помощью перегрузки (overload) оператора new(). Андрей Александреску в своей книге Современное программирование на C++ описал небольшой объект аллокатора (Глава 4: Размещение в памяти небольших объектов).
Недостатки распределения с помощью malloc()
Не только наш менеджер памяти имеет недостатки, они также присутствуют и у других реализаций. Управление с помощью malloc() довольно опасная вещь для программ, которые хранят данные долгое время и которые должны быть легко доступны. Имея множество ссылок на динамически выделенную память, часто бывает затруднительно узнать, когда её необходимо освободить. Менеджер, обычно легко справляется со своей работой, если время жизни переменной (или время работы с куском памяти), ограничено рамками какой-либо функции (локальные переменные), но для глобальных переменных, чья память используется на всём протяжении работы программы, задача становится значительно сложнее. Также многие API описаны не совсем чётко и становится не понятно, на ком лежит ответственность за управление памятью — на самой программе или на вызванной функции.
Из-за подобных проблем, многие программы работают с памятью согласно собственным правилам. Иногда может показать, что больше операций (прим. переводчика: по тексту “больше кода”) тратится на выделение и освобождение памяти, чем на вычислительную составляющую. Поэтому рассмотрим альтернативные способы управления памятью.
Полу-автоматические (semi-automatic) подходы к управлению памятью
Подсчёт ссылок (reference-counting)
Подсчёт ссылок (reference-counting) — это полу-автоматический метод работы с памятью, требующий дополнительного кода и при котором можно не следить за тем, когда память перестаёт использоваться. Reference-counting делает это за вас.
Механизм работы следующий — для каждой динамически выделенной памяти существует поле, которое хранит число ссылающихся на неё ссылок. Если в программе появляется переменная, ссылающаяся на этот кусок памяти, счётчик увеличивается. И наоборот — при уменьшении переменных, ссылающихся на эту память, счётчик уменьшается. При декременте счётчика, происходит проверка — если количество ссылок 0, то память освобождается.
Каждая ссылка ссылающаяся на эту память, просто увеличивает или уменьшает счётчик. Это предотвращает ситуации очистки памяти, когда она используется. В любом случае, вы не должны забывать использовать функции отвечающие за подсчёт ссылок, если работаете с таким типом (“подсчитываемых”) структур. Также встроенные функции и сторонние библиотеки могут не уметь работать с reference-counting или иметь свой механизм работы.
Для реализации этого механизма, вам достаточно двух функций. Первая будет увеличивать счётчик ссылок, вторая уменьшать и освобождать память, если он достиг нуля.
Например функция подсчёта ссылок может выглядеть примерно так:
Листинг 9. Принцип работы reference-counting
Memory pools
Memory pools ещё один способ полу-автоматического управления памятью. Он автоматизирует процесс для программ, которые проходят через определенные стадии/фрагменты (stages) выполнения, на каждой стадии которой известно сколько места потребуется программе. В качестве примера можно привести серверные процессы, где выделено много памяти под соединения — у неё максимальное время жизни (lifespan) совпадает с временем жизни соединения. Тот же Apache — каждое соединение это отдельный stage, который имеет свой memory pool. После выполнения фрагмента, память моментально освобождается.
В “пуловой” модели управления, каждое выделение памяти относится к конкретному пулу, из которого память и будет выделена. (прим. переводчика: представьте функцию, в которой 5 локальных переменных типа char. Т.е. заранее известно что при выполнении этой функции, необходимо будет 5 байт памяти. Т.е. тело этой функции это как stage через который проходит программа в процессе выполнения, и можно сразу под него выделить кусок памяти фиксированного размера в 5 байт. Это сэкономит время на поиск и “резку” памяти по мере появления переменных в функции и даст гарантию того, что памяти всегда хватит.) Каждый pool имеет своё время жизни. В apache, pool может иметь время жизни равное времени работы сервера, длительности соединения, времени обработки запроса и т.д… Поэтому, если имеется набор функций, которые требуют память не превышающую размер соединения, то её можно просто выделить из пула соединений и по завершению работы, она будет освобождена автоматически. Кроме того, некоторые реализации дают возможность регистрировать функции очистки (cleanup functions), которые вызываются чтобы выполнить некоторые действия перед тем как пул будет очищен (что-то вроде деструкторов в ООП).
Чтобы использовать пул в своих программах, вы можете просто воспользоваться реализацией obstack (GNU — libc) или Apache Protable Runtime (Apache). Преимущество obstack это то, что он по умолчанию идёт со всеми Linux дистрибутивами. А Apache Portable Runtime это возможность использования на множестве платформ. Чтобы узнать больше об их реализациях, в конце статьи лежат ссылки.
Следующий “надуманный” пример демонстрирует применение obstack:
Листинг 11. Пример с использованием obstack



