Метод mean() в Python
Среднее – это значение, представляющее весь набор объектов. Считается центральным значением набора чисел.
Среднее значение рассчитывается путем деления суммы всех значений объектов на количество объектов.
Формула: (сумма значений) / общие значения
Теперь давайте разберемся, как работает функция mean() для вычисления среднего значения.
Использование функции mean()
Функция mean() помогает вычислить среднее значение набора значений, переданных в функцию.
Модуль статистики в Python используется для выполнения всех статистических операций с данными. Нам нужно импортировать модуль статистики, используя следующую команду:
Функция statistics.mean() принимает значения данных в качестве аргумента и возвращает среднее значение переданных ей значений.
mean() с модулем NumPy
Модуль Python NumPy представляет набор значений в виде массива. Мы можем вычислить среднее значение этих элементов массива с помощью функции numpy.mean().
Функция numpy.mean() работает так же, как функция statistics.mean().
В приведенном выше примере мы использовали функцию numpy.arange (start, stop) для создания равномерно распределенных значений в диапазоне, указанном в качестве параметров. Кроме того, функция numpy.mean() используется для вычисления среднего значения всех элементов массива.
Функция mean() с модулем Pandas
Модуль Pandas работает с огромными наборами данных в виде DataFrames. Среднее значение этих огромных наборов данных можно вычислить с помощью функции pandas.DataFrame.mean().
Функция pandas.DataFrame.mean() возвращает среднее значение этих значений данных.
В приведенном выше примере мы создали массив NumPy с помощью функции numpy.arange(), а затем преобразовали значения массива в DataFrame с помощью функции pandas.DataFrame(). Кроме того, мы вычислили среднее значение значений DataFrame с помощью функции pandas.DataFrame.mean().
Входной набор данных:

В приведенном выше примере мы использовали вышеупомянутый набор данных и вычислили среднее значение всех значений данных, представленных в столбце данных «qsec».
numpy.std¶
Compute the standard deviation along the specified axis.
Returns the standard deviation, a measure of the spread of a distribution, of the array elements. The standard deviation is computed for the flattened array by default, otherwise over the specified axis.
Parameters a array_like
Calculate the standard deviation of these values.
axis None or int or tuple of ints, optional
Axis or axes along which the standard deviation is computed. The default is to compute the standard deviation of the flattened array.
New in version 1.7.0.
If this is a tuple of ints, a standard deviation is performed over multiple axes, instead of a single axis or all the axes as before.
dtype dtype, optional
Type to use in computing the standard deviation. For arrays of integer type the default is float64, for arrays of float types it is the same as the array type.
out ndarray, optional
Alternative output array in which to place the result. It must have the same shape as the expected output but the type (of the calculated values) will be cast if necessary.
ddof int, optional
keepdims bool, optional
If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the input array.
where array_like of bool, optional
Elements to include in the standard deviation. See reduce for details.
New in version 1.20.0.
If out is None, return a new array containing the standard deviation, otherwise return a reference to the output array.
Note that, for complex numbers, std takes the absolute value before squaring, so that the result is always real and nonnegative.
For floating-point input, the std is computed using the same precision the input has. Depending on the input data, this can cause the results to be inaccurate, especially for float32 (see example below). Specifying a higher-accuracy accumulator using the dtype keyword can alleviate this issue.
In single precision, std() can be inaccurate:
Найти среднее и стандартное отклонение в Python
Среднее и стандартное отклонение – две важные метрики в статистике.
Найти среднее и стандартное отклонение в Python
Среднее и стандартное отклонение – две важные метрики в статистике.
Давайте посмотрим на шаги, необходимые для расчета среднего и стандартного отклонения.
Шаги для расчета среднего
Шаги для расчета стандартного отклонения
Несколько методов для поиска среднего и стандартного отклонения в Python
Давайте напишем код Python для расчета среднего и стандартного отклонения. Вы получаете несколько вариантов для расчета среднего и стандартного отклонения в Python. Давайте посмотрим на встроенный статистический модуль, а затем попробуйте написать нашу собственную реализацию.
1. Использование модуля статистики
Этот модуль предоставляет вам возможность вычисления среднего и стандартного отклонения напрямую.
Давайте начнем, импортируя модуль.
Давайте объявим массив с фиктивными данными.
Теперь, чтобы рассчитать среднее значение образца данных, используйте:
Это утверждение вернет среднее значение данных. Мы можем напечатать среднее значение в выходе, используя:
Мы получаем вывод как:
Если вы используете IDE для кодирования, вы сможете наведите следующее заявление и получить дополнительную информацию о статистике. МЕС ().
В качестве альтернативы вы можете прочитать документацию здесь Отказ
Для расчета стандартного отклонения использования образцов использования:
Мы получаем вывод как:
Полный код, чтобы найти стандартное отклонение и среднее значение
Полный код для фрагментов выше выглядит следующим образом:
2. Напишите свою собственную функцию
Давайте напишем нашу функцию для расчета среднего.
Эта функция рассчитает среднее значение.
Теперь давайте напишем функцию для расчета стандартного отклонения.
Это может быть немного сложно, поэтому давайте пойдем на это шаг за шагом.
Стандартное отклонение – Квадратный корень дисперсии Отказ Таким образом, мы можем написать две функции:
Функция для расчетной дисперсии заключается в следующем:
Вы можете обратиться к шагам, указанным в начале учебника, чтобы понять код.
Теперь мы можем написать функцию, которая рассчитывает квадратный корень дисперсии.
Полный код
Полный код выглядит следующим образом:
Заключение
Это руководство было о расчете среднего и стандартного отклонения в Python. Надеюсь, вы веселились с нами!
Различные способы найти Стандартное отклонение в Numpy
Функция numpy.std() в python используется для вычисления стандартного отклонения вдоль заданной оси с точным и более точным значением.
Вступление
В этом уроке мы узнаем, как найти стандартное отклонение массива numpy. мы можем найти стандартное отклонение массива numpy с помощью функции numpy.std (). мы научимся вычислять это в глубоком, тщательном объяснении каждой части кода с примерами.
Что такое Стандартное отклонение Numpy?
Numpy – это инструментарий, который помогает нам в работе с числовыми данными. Он содержит набор инструментов для создания структуры данных, называемой массивом Numpy. Это в основном сетка строк и столбцов чисел.
Стандартное отклонение-это статистика, которая измеряет величину вариации в наборе данных относительно его среднего значения и вычисляется как квадратный корень дисперсии. Он рассчитывается путем определения отклонения каждой точки данных относительно среднего.
Модуль numpy в python предоставляет различные функции, одной из которых является numpy.std(). Он используется для вычисления стандартного отклонения вдоль указанной оси. Эта функция возвращает стандартное отклонение элементов массива numpy. Квадратный корень среднего квадратного отклонения (известного как дисперсия) называется стандартным отклонением.
Синтаксис стандартного отклонения Numpy
Параметры стандартного отклонения Numpy
Возвращается
Он вернет новый массив, содержащий стандартное отклонение. Если параметр “out” не имеет значения “None”, то он вернет ссылку на выходной массив.
Примеры стандартного отклонения Numpy
1. Numpy.std() – массив 1D
Выход:
Здесь, во-первых, мы импортировали numpy с псевдонимом np. Во – вторых, мы создали массив ‘arr’ с помощью функции array (). В-третьих, мы объявили переменную “результат” и присвоили возвращаемое значение функции std (). Мы передали массив ‘arr ‘ в функцию. Наконец, мы напечатали значение результата.
2. Numpy.std() с помощью
Здесь, во-первых, мы импортировали numpy с псевдонимом np. Во – вторых, мы создали массив ‘arr’ с помощью функции array (). В-третьих, мы объявили переменную “результат” и присвоили возвращаемое значение функции std (). Мы передали массив ‘arr’ в функцию. В-четвертых, мы напечатали значение результата. Затем мы использовали параметр type для более точного значения стандартного отклонения, которое имеет значение.float32. И, наконец, мы напечатали результат.
3. Numpy.std() с помощью
Здесь, во-первых, мы импортировали numpy с псевдонимом np. Во – вторых, мы создали массив ‘arr’ с помощью функции array (). В-третьих, мы объявили переменную “результат” и присвоили возвращаемое значение функции std (). Мы передали массив ‘arr’ в функцию. В-четвертых, мы напечатали значение результата. Затем мы использовали параметр type для более точного значения стандартного отклонения, которое имеет значение.float64. И наконец, мы напечатали вывод.
4. Numpy.std() – 2D массив
Здесь, во-первых, мы импортировали numpy с псевдонимом np. Во-вторых, мы создали 2D-массив ‘arr’ с помощью функции array (). В-третьих, мы объявили переменную | ‘result’ и присвоили возвращаемое значение функции std (). Мы передали массив ‘arr’ в функцию. Наконец, мы напечатали значение результата.
5. Использование на 2D-массиве для поиска Numpy стандартного отклонения
Здесь, во-первых, мы импортировали numpy с псевдонимом np. Во-вторых, мы создали 2D-массив ‘arr’ с помощью функции array (). В-третьих, мы объявили переменную “результат” и присвоили возвращаемое значение функции std (). Мы передали массив ‘arr’ в функцию, в которой мы использовали еще один параметр, т. е. |/axis=0. Наконец, мы напечатали значение результата.
6. использование в 2D-массиве для поиска Numpy стандартного отклонения
Здесь, во-первых, мы импортировали numpy с псевдонимом np. Во-вторых, мы создали 2D-массив ‘arr’ с помощью функции array (). В-третьих, мы объявили переменную ‘result’ и присвоили возвращаемое значение функции std (). мы передали массив ‘arr’ в функцию, в которой мы использовали еще один параметр, т. е., Наконец, мы напечатали значение результата.
Должен Читать
Вывод: Стандартное Отклонение Numpy
В этом уроке мы подробно узнали о вычислении стандартного отклонения с помощью функции numpy.std (). Мы также подробно рассмотрели все примеры, чтобы лучше понять концепцию.
Однако, если у вас есть какие-либо сомнения или вопросы, дайте мне знать в разделе комментариев ниже. Я постараюсь помочь вам как можно скорее.
Computing the Mean and Std of a Dataset in Pytorch
PyTorch provides various inbuilt mathematical utilities to monitor the descriptive statistics of a dataset at hand one of them being mean and standard deviation. Mean, denoted by, is one of the Measures of central tendencies which is calculated by finding the average of the given dataset. Standard Deviation, denoted by σ, is one of the measures of dispersion that signifies by how much are the values close to the mean. The formula for mean and standard deviation are as follows:-
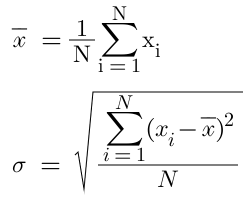
Attention geek! Strengthen your foundations with the Python Programming Foundation Course and learn the basics.
Installing PyTorch:
Installing PyTorch is the same as that of any other library in python.
Or if you want to install it in a conda environment you can use the following command:-
Mean and Standard Deviation of 1-D Tensor:
Before understanding how to find mean and standard deviation let’s ready our dataset by generating a random array.
Now that we have the data we can find the mean and standard deviation by calling mean() and std() methods.
The above method works perfectly, but the values are returned as tensors, if you want to extract values inside that tensor you can either access it via index or you can call item() method.



