Данные, хранящиеся в корпоративных сетях, зачастую являются основой для принятия важных решений, влияющих на работу или даже на выживание компаний. Получение требуемого и отсечение информационного шума становятся определяющими для конкурентноспособности.
Обилие информации уже давно воспринимается как нечто само собой разумеющееся. Количественные оценки ее суммарного объема, как таковые, вряд ли могут стать поводом для особых размышлений. Но если подобные показатели подвергнуть структурному анализу, то полученные результаты могут оказаться весьма неожиданными.
Возьмем исследование изменения объема информации в мире за год. Оно под руководством профессоров Питера Лаймана и Хола Вэриена с 2000 года проводится в Калифорнийском университете в Беркли. Ученые пришли к выводу, что на протяжении трех лет, предшествующих 2002 году, количество информации, произведенной человечеством, удвоилось. А в самом 2002 год в мире появились пять экзабайт (миллион терабайт) информации. Для сравнения приведем данные об объеме фонда библиотеки Конгресса США, где хранятся 19 млн. книг и 56 млн. рукописей: он составляет около десяти терабайт информации. В упомянутом исследовании информация структурировалась по типам носителей. Оказалось, что лидерство прочно удерживают магнитные носители, доля которых превышает 90%. Из них большую часть составляют жесткие диски. На кино, фото, печатные издания и другие бумажные документы вкупе с оптическими цифровыми носителями приходится лишь 7% информации.
Инструменты для корпоративных массивов
Итак, на жестких дисках отдельных компьютеров или на серверах в корпоративной сети накапливаются огромные массивы документов, навигация в которых по понятным причинам затруднена. Для обеспечения комфортности работы с такими массивами документы обычно пытаются классифицировать, распределить их по тематическим папкам или каталогам. Эта процедура трудоемкая, и, что самое главное, не исключает возможности внесения дополнительных ошибок.
Понятно, что создать информационную среду, инкапсулирующую разнородные объекты, непросто. Естественным выходом из этой ситуации оказались полнотекстовые информационно-поисковые системы, получившие в свое время широкое распространение в Интернете. В отличие от Сети, где данные в основном представлены в как html-файлы, поиск производится в другой среде. Ведь в корпоративных системах преимущественно используются форматы офисных приложений и систем документооборота. Наряду с поиском большое значение приобретают задачи группировки тематически близких документов, автоматического реферирования, перевода, выявления ключевых понятий, проведения нечеткого поиска.
Средства поиска
Рассмотрим некоторые популярные системы поиска для корпоративных сетей.
Универсальная поисковая система mnoGoSearch (mnogosearch.org) предназначена для интернет- или интранет-серверов. Она индексирует информацию, которая сканируется по локальным дискам или в соответствии с протоколами http, ftp, nntp. Система работает с документами в форматах html, txt, doc, pdf. В запросах воспринимаются различные формы слов и логические операторы. Результаты запросов можно настраивать с помощью html-шаблонов. Система mnoGoSearch может хранить данные во всех популярных реляционных СУБД. Существуют версии для Linux и Windows.
При первом запуске на основе заданного массива документов «Ищейка» создает и индексирует базу данных, которая представляет собой зону поиска, состоящую из каталогов. В пределах этой зоны и производится поиск документов и файлов.
Система допускает организацию собственных хранилищ данных из неструктурированной информации, создание до пятидесяти зон поиска с индексированием неограниченного количества файлов, накопление «популярных» запросов и т.п.
Полнотекстовый поиск под Microsoft SQL Server 2000 в «Следопыте» реализован для русского и английского языков (подразумевается возможность динамического отслеживания изменений в базе данных и обновления полнотекстового индекса Change Tracking, которая появилась в Microsoft SQL Server 2000).
Система поддерживает поиск документов разных типов, включая zip, rtf, pdf, html, xml, документы Microsoft Office (Word, Excel, PowerPoint) и WordPerfect. Поддерживается кодировка Unicode. Допускаются несколько видов поиска, а именно морфологический, и фонетический поиск, а также поиск синонимов и поиск в словах с орфографическими ошибками.
Система полнотекстового поиска CROS 4.01 (www.cronos.ru), предназначенна для накопления и обработки текстовых документов различных форматов. Хранение документов в базах данных системы обеспечивает уменьшение два-три раза необходимого объема дисковой памяти. Предусмотрено автоматическое определение форматов документов Microsoft Word версий 6.0, 7.0, 97, 2000, а также rtf и html. Помимо этого определяется тип кодировки (DOS, Win, КОИ8, Unicode).
CROS обеспечивает навигацию по найденным документам, способен работать в локальной сети и поддерживает защиту информации от несанкционированного доступа. При этом отсутствуют ограничения на количество иерархических областей поиска, осуществляется сортировка найденных документов по дате, имени, типу и атрибутам, которые задаются самим пользователем.
Система Greenstone (www.greenstone.org) представляет собой Open Source-решение для создания «цифровых библиотек». Естественно, она включает поиск с предварительным индексированием по документам всех популярных форматов, и прежде всего doc и pdf, которые могут быть представлены и в заархивированном виде. Система создает каталог документов, конвертирует их в html-формат, а затем обеспечивает удаленный доступ к библиотеке посредством браузера.
Программно-аппаратный комплекс Google Search Appliance обеспечивает поиск документов в рамках корпоративных сетей. Джон Пискителло, менеджер Google по продуктам, определил это устройство как «естественный шаг для компании, которая всегда стремится предложить пользователям новые способы доступа к информации». По его словам, пришлось учитывать возрастающие требования, включая поиск в границах, определенных корпоративными межсетевыми экранами, и это заставило Google разработать новые решения.
Поисковые устройства этой компании используют в своей работе армия США, администрация калифорнийского города Сан-Диего, фармацевтический гигант Pfizer, корпорация Boeing, Procter & Gamble, Cisco Systems и другие.
Поисковый механизм комплекса обеспечивает работу более чем с двумястами типами файлов (естественно, включая html, pdf, doc). При этом осуществляется учет синонимов при полнотекстовом поиске по запросам и возможна работа более чем пятьюдесятью естественными языками.
Google Search Appliance поддерживают функции поиска защищенной информации, находящейся на закрытых серверах. При этом пользователь может обратиться к защищенному документу лишь при наличии у него соответствующих полномочий доступа.
Новый уровень обработки информации в сети
Попытки анализа больших объемов неструктурированных или слабо структурированных данных очень часто усложняют процесс принятия решений. Если широкий спектр поисковых систем достаточно легко справляется с «простым» полнотекстовым поиском, то для подобного анализа нужны технологии совсем другого типа, представленные системами добычи знаний (Knowledge Mining). Стоимость внедрения таких систем составляет сотни тысяч долларов.
Итак, ставиться основная задача по выявлению знаний в массивах неструктурированных данных, с целью использования этих знаний в процессе принятия решений. Чтобы добиться этого, информацию необходимо сделать доступной для анализа, выявить классы понятий и сопоставить их с документами.
За счет предварительной обработки информации, проводимой на этапе формирования хранилищ данных, значительно повышается эффективность таких процессов, как интеллектуальный анализ данных, глубинный анализ текстов и обнаружение новых знаний в текстах. Как неожиданную производную этих процессов можно назвать появление средств, упрощающих поиск для пользователя, таких как реализация нечеткой логики запросов (нечеткого поиска), средств построения функциональных информационных портретов, визуализации семантических связей и т.д. В свою очередь, эти возможности напрямую связаны с распознаванием образов, поиском мультимедийных данных, анализом речевого ввода.
Разработка информационных ресурсов
В соответствии с уже сложившейся методологией, к основным элементам Text Mining относятся суммаризация (summarization), выделение феноменов, понятий (feature extraction), кластеризация (clustering), классификация (classification), ответ на запросы (question answering), тематическое индексирование (thematic indexing) и поиск по ключевым словам (keyword searching). Также в некоторых случаях набор дополняют средства поддержки и создания таксономии (oftaxonomies) и тезаурусов (thesauri). Александр Линден, директор компании Gartner Research, выделил четыре основных вида приложений технологий Text Mining:
— Классификация текста, в которой используются статистические корреляции для построения правил размещения документов в предопределенные категории. В современных системах классификация применяется, например, в таких задачах: группировка документов в intranet-сетях, размещение документов в определенные папки, избирательное распространение новостей подписчикам.
— Кластеризация, базирующаяся на признаках документов, использующая лингвистические и математические методы без использования предопределенных категорий. Кластеризация широко применяется при реферировании больших документальных массивов, определении взаимосвязанных групп документов, для упрощения визуализации информации, выявления дубликатов или близких по содержанию документов.
— Семантические сети или анализ связей, которые определяют появление дескрипторов (ключевых фраз) в документе для обеспеченияи навигации. Используемая при этом визуализация является ключевым звеном при представлении схем неструктурированных текстовых документов. Она используется как средство представления контента всего массива документов, а также для реализации навигационного механизма, который может применяться при исследовании документов и их классов.
— Извлечение фактов предназначено для получения некоторых фактов из текста с целью улучшения классификации, поиска и кластеризации.
Можно назвать еще несколько задач технологии Text Mining, например, прогнозирование и нахождение исключений, т.е. поиск объектов, которые своими характеристиками выделяются из общей массы. Все эти задачи находят свое воплощение в современных корпоративных хранилищах.
Обогатители знаний
Сегодня на рынке корпоративных систем все большую известность получает технология компании Autonomy (www.autonomy.com), которая позиционируется как инструментарий для автоматизированного управления информационными потоками. Основные научные принципы Autonomy базируются на информационной теории Клода Шеннона, байесовских вероятностях и нейронных сетях. Концепция адаптивного вероятностного моделирования позволяет системе Autonomy идентифицировать шаблоны в тексте документа и автоматически определять подобные шаблоны в массиве других документов.
Обрабатывая шаблоны строк в документах, система Autonomy определяет корреляцию образов и выявляет закономерности среди больших массивов документов. При этом не учитываются никакие специфичные правила (в том числе и лингвистические). Поскольку система не базируется на предопределенных ключевых словах, она может работать с любыми языками.
Одним из программных продуктов Autonomy является пакет Portal-in-a-box, который помимо традиционных функций агрегирования информации из разнородных источников имеет и средства для решения такой проблемы, возникающей при построении порталов, как систематизация неструктурированных данных. Очевидно, что группировка документов по категориям и создание их метаописаний требует немалых редакторских усилий. Portal-in-a-box в этом случае полностью автоматизирует процессы категоризации информации, ее реферирования и расстановки гиперссылок.
Архитектура Retrieval Ware позволяет работать с системой как через корпоративную локальную сеть, так и через Интернет. Серверная часть системы поддерживает все распространенные серверные платформы, а клиентским местом может быть любой компьютер, имеющий графический веб-браузер. Система обладает возможностью работы в различных многопроцессорных и распределенных многосерверных конфигурациях.
Лежащая в основе системы технология адаптивного распознавания образов базируется на нейронных сетях для обработки информации и действует как самоорганизующаяся система, которая выделяет в массиве хранимой информации и индексирует бинарные образы. К преимуществам применения этой технологии для поиска текстовой информации можно отнести осуществление нечеткого поиска, языковую независимость, малые объемы индексных файлов.
Основой технологии семантического поиска является использование семантических сетей, описывающих смысл слов естественного языка и связи между обозначаемыми ими понятиями. Реализована также поддержка русской морфологии. Семантическая сеть словаря этого языка включает в себя около 40 тысяч семантических групп в базовом варианте. Это позволяет пользователю вводить запрос на естественном языке, предоставив системе самой искать все документы, контекст которых совпадает с контекстом запроса. Применение семантики позволяет учитывать общий контекст документа.
Модуль аннотирования в системе Retrieval Ware, который позволяет строить аннотации документов в виде связного текста, построен на базе сервера аннотирования ML NetLibretto компании «Медиалингва».
В список компаний и организаций, пользующихся этой системой, входят ABC News, Encyclopedia Britannica, Microsoft, Sun Microsystems, Всемирный банк, ФАПСИ, Центральный Банк России, «Лукойл» и другие.
Яndex.ServerStandard 3.0 (www.yandex.ru) представляет собой системный сервис для организации полнотекстового поиска информации в заданной коллекции документов. Он предназначен для работы с текстами как в локальной, так и в глобальной сетях. Система не содержит лицензионных ограничений на число индексируемых документов, их размер или суммарный размер индекса и позволяет индексировать документы как через http-соединение, так и чтением локальной файловой системы.
Яndex.Server 3.0 состоит из двух основных логических частей: индексатора и поискового сервера. Индексатор анализирует документы, среди которых должен проводиться поиск, и сохраняет информацию о них в специальных индексных файлах.
Обычно используется режим работы, при котором не создаются заново индексные файлы, а отрабатывается информация только по изменившимся, новым и удаленным документам. Поисковый сервер после запуска находится в постоянном ожидании запросов, которые могут быть представлены на естественном языке. Поиск может осуществляться с учетом морфологии языка, в одной или нескольких коллекциях документов.
Яndex.Server 3.0 поддерживает форматы html, xml, rtf, pdf, doc, mp3 и многие другие. Содержимое индексируемых документов также может быть получено при обращении к произвольной базе данных, в частности, MySQL и MS SQL.
Система предоставляет возможность кластеризации результатов поиска (группирует найденные документы в соответствии с внешними атрибутами), а также ранжирует результаты (сортирует документы по степени соответствия запросу).
Модуль Link Terms обеспечивает связь понятий. Он позволяет выявлять связи между понятиями, встречающимися в текстовых полях изучаемой базы данных, и представлять их в виде графа, который может быть использован для выделения записей, реализующих выбранную связь. Модуль Link Analysis выявляет корреляционные и антикорреляционные связи между значениями категориальных и булевых полей.
Благодаря уникальной технологии «эволюционного программирования» и другим интеллектуальным алгоритмам, PolyAnalyst с успехом применяется в различных типах бизнес-задач, в социологических исследованиях, в прикладных научных и инженерных задачах, в банковском деле, в страховании и медицине.
PolyAnalyst получил широкое распространение в мире, среди ее пользователей Boeing, 3M, Chase Manhattan Bank, Dupont, Siemens и другие.
Ядром механизма обработки контента InfoStream (infostream.com.ua) является полнотекстовая информационно-поисковая система InfoReS. Технология InfoStream позволяет создавать полнотекстовые базы данных и осуществлять поиск информации, формировать тематические информационные каналы, автоматически рубрицировать информацию, формировать дайджесты, таблицы взаимосвязей понятий (относительно встречаемости их в сетевых публикациях), гистограммы распределения весовых значений отдельных понятий, а также динамики их встречаемости по времени. С помощью InfoStream можно обрабатывать данные в форматах Microsoft WORD (версии 2000, 97, 6), rtf, pdf, и всех текстовых форматах (простой текст, html, xml). Системы на основе InfoStream в настоящее время функционируют под управлением таких операционных систем, как FreeBDS, Linux, Solaris.
Технологии InfoStream позволяют создать комплекс поддержки документального информационного хранилища, в котором реализуется интегрированная информационно-поисковая среда на основе веб-решений. С ее помощью обеспечивается доступ к электронным документам, размещенным на компьютерах в корпоративной сети, в режимах поиска, навигации по компьютерам/каталогам, просмотра как оригиналов документов, так и их текстовых образов. Комплекс обеспечивает интерактивный полнотекстовый поиск информации по сложным запросам, состоящим из ключевых слов, логических и контекстных операторов, разнообразное ранжирование результатов поиска. Предоставляется возможность уточнения результатов поиска с помощью механизма «информационных портретов».
Порталы знаний
БЕЗ ПОИСКОВЫХ СИСТЕМ, СИСТЕМ АНАЛИЗА ТЕКСТОВ И СИСТЕМ ДОБЫЧИ ЗНАНИЙ
ЛЮБЫЕ СЕРЬЕЗНЫЕ ИНФОРМАЦИОННЫЕ НАЧИНАНИЯ ОБРЕЧЕНЫ НА ПРОВАЛ
Именно для решения данной проблемы созданы и продолжают создаваться корпоративные поисковые системы и порталы знаний, представляющие среду для эффективного поиска и обмена знаниями. Это инструменты, представляющие собой совокупность технологических решений для выявления, хранения, классификации, обработки и распространения знаний.
Современные порталы управления знаниями обеспечивают решения целого комплекса задач, среди которых сбор информации об объектах, определение связи объектов, выявление тенденций. Функциональные возможности таких систем позволяют проводить многофакторные динамические исследования, выполнять диагностику и прогнозирование развития ситуации. В дополнение к возможностям глубинного анализа данных и текста, в порталах знаний широко используется человеческий опыт, знания экспертов.
Очень близким к Avalanche по идеологии является подход компании Vivisimo, в рамках которого результаты интернет-поиска распределяются по папкам-категориям, автоматически создаваемым системой. Достигается это за счет логического сопоставления запросов и результатов поиска.
Естественно, свое применение Vivisimo сразу же нашла в корпоративных сетях и веб-сервисах. Рауль-Валдес-Перес, один из учередителей Vivisimo, сравнил систему с очень умным библиотекарем, который мгновенно находит нужную книгу в море неупорядоченной информации.
Перспективы обработки информации
Сегодня данные, представленные на компьютерах корпоративных сетей, зачастую являются основой для принятия важных решений, влияющих на работу или даже на выживание компаний. Интенсивная информатизация государственных органов и коммерческих структур, растущая доступность инструментария для сбора и мониторинга данных ведут к изобилию информации, в котором может утонуть работа практически любой организации.
Эффективный поиск, вовремя предлагающий необходимые сведения, сопровождаемый способностью избавляться от информационного шума, оказывается решающим фактором для повышения конкуретноспособности. Без поисковых систем, систем анализа текстов и систем добычи знаний любые серьезные информационные начинания завтра будут обречены на провал.
Естественно, эти технологии широко используются «силовиками». В прошлом году свои технологии «добычи данных», применяемые для поиска информации в текстах, радио- и телепередачах публично представило ЦРУ. Оказалось, что объектами поиска спецслужбы являются тексты в печатных изданиях и в цифровом виде, графические изображения, аудиоинформация на 35 языках. Для отсеивания аудиоинформации используется методика Oasis, которая распознает речь и превращает ее в текст. Методика позволяет выделять из аудиопотока только те голоса или ту конкретную информацию, которая заложена в настройках поиска. Еще одна технология, Fluent, позволила ЦРУ искать информацию в текстовых документах, причем запрос вводится на английском языке и тут же переводится на целый ряд других языков, а найденная информация из базы данных на разных языках поступает исследователю после автоматического перевода.
Data Mining – интеллектуальный анализ данных
1. Что такое Data Mining?
Data Mining переводится как “добыча” или “раскопка данных”. Нередко рядом с Data Mining встречаются слова “обнаружение знаний в базах данных” (knowledge discovery in databases) и “интеллектуальный анализ данных”. Их можно считать синонимами Data Mining. Возникновение всех указанных терминов связано с новым витком в развитии средств и методов обработки данных.
До начала 90-х годов, казалось, не было особой нужды переосмысливать ситуацию в этой области. Все шло своим чередом в рамках направления, называемого прикладной статистикой (см. например, [1]). Теоретики проводили конференции и семинары, писали внушительные статьи и монографии, изобиловавшие аналитическими выкладками.
Вместе с тем, практики всегда знали, что попытки применить теоретические экзерсисы для решения реальных задач в большинстве случаев оказываются бесплодными. Но на озабоченность практиков до поры до времени можно было не обращать особого внимания – они решали главным образом свои частные проблемы обработки небольших локальных баз данных.
И вот прозвенел звонок. В связи с совершенствованием технологий записи и хранения данных на людей обрушились колоссальные потоки информационной руды в самых различных областях. Деятельность любого предприятия (коммерческого, производственного, медицинского, научного и т.д.) теперь сопровождается регистрацией и записью всех подробностей его деятельности. Что делать с этой информацией” Стало ясно, что без продуктивной переработки потоки сырых данных образуют никому не нужную свалку.
Специфика современных требований к такой переработке следующие:
Традиционная математическая статистика, долгое время претендовавшая на роль основного инструмента анализа данных, откровенно спасовала перед лицом возникших проблем. Главная причина – концепция усреднения по выборке, приводящая к операциям над фиктивными величинами (типа средней температуры пациентов по больнице, средней высоты дома на улице, состоящей из дворцов и лачуг и т.п.). Методы математической статистики оказались полезными главным образом для проверки заранее сформулированных гипотез (verification-driven data mining) и для “грубого” разведочного анализа, составляющего основу оперативной аналитической обработки данных (online analytical processing, OLAP).
В основу современной технологии Data Mining (discovery-driven data mining) положена концепция шаблонов (паттернов), отражающих фрагменты многоаспектных взаимоотношений в данных. Эти шаблоны представляют собой закономерности, свойственные подвыборкам данных, которые могут быть компактно выражены в понятной человеку форме. Поиск шаблонов производится методами, не ограниченными рамками априорных предположений о структуре выборке и виде распределений значений анализируемых показателей. Примеры заданий на такой поиск при использовании Data Mining приведены в табл. 1.
Таблица 1. Примеры формулировок задач при использовании методов OLAP и Data Mining [2]
| OLAP | Data Mining |
| Каковы средние показатели травматизма для курящих и некурящих? | Какие факторы лучше всего предсказывают несчастные случаи? |
| Каковы средние размеры телефонных счетов существующих клиентов в сравнении со счетами бывших клиентов (отказавшихся от услуг телефонной компании)? | Какие характеристики отличают клиентов, которые, по всей вероятности, собираются отказаться от услуг телефонной компании? |
| Какова средняя величина ежедневных покупок по украденной и не украденной кредитной карточке? | Какие схемы покупок характерны для мошенничества с кредитными карточками? |
Важное положение Data Mining – нетривиальность разыскиваемых шаблонов. Это означает, что найденные шаблоны должны отражать неочевидные, неожиданные (unexpected) регулярности в данных, составляющие так называемые скрытые знания (hidden knowledge). К обществу пришло понимание, что сырые данные (raw data) содержат глубинный пласт знаний, при грамотной раскопке которого могут быть обнаружены настоящие самородки (рис.1).
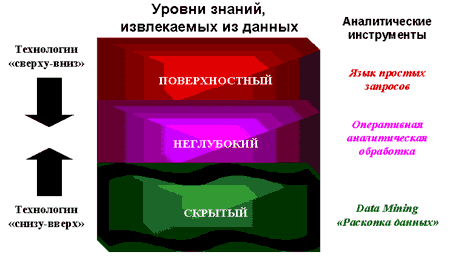
Рисунок 1. Уровни знаний, извлекаемых из данных
В целом технологию Data Mining достаточно точно определяет Григорий Пиатецкий-Шапиро – один из основателей этого направления:
Data Mining – это процесс обнаружения в сырых данных
G. Piatetsky-Shapiro, Knowledge Stream Partners
2. Кому это нужно”
Сфера применения Data Mining ничем не ограничена – она везде, где имеются какие-либо данные. Но в первую очередь методы Data Mining сегодня, мягко говоря, заинтриговали коммерческие предприятия, развертывающие проекты на основе информационных хранилищ данных (Data Warehousing). Опыт многих таких предприятий показывает, что отдача от использования Data Mining может достигать 1000%. Например, известны сообщения об экономическом эффекте, в 10-70 раз превысившем первоначальные затраты от 350 до 750 тыс. дол. [3]. Известны сведения о проекте в 20 млн. дол., который окупился всего за 4 месяца. Другой пример – годовая экономия 700 тыс. дол. за счет внедрения Data Mining в сети универсамов в Великобритании.
Data Mining представляют большую ценность для руководителей и аналитиков в их повседневной деятельности. Деловые люди осознали, что с помощью методов Data Mining они могут получить ощутимые преимущества в конкурентной борьбе. Кратко охарактеризуем некоторые возможные бизнес-приложения Data Mining [2].
2.1. Некоторые бизнес-приложения Data Mining
Розничная торговля
Предприятия розничной торговли сегодня собирают подробную информацию о каждой отдельной покупке, используя кредитные карточки с маркой магазина и компьютеризованные системы контроля. Вот типичные задачи, которые можно решать с помощью Data Mining в сфере розничной торговли:
Банковское дело
Достижения технологии Data Mining используются в банковском деле для решения следующих распространенных задач:
Телекоммуникации
В области телекоммуникаций методы Data Mining помогают компаниям более энергично продвигать свои программы маркетинга и ценообразования, чтобы удерживать существующих клиентов и привлекать новых. Среди типичных мероприятий отметим следующие:
Страхование
Страховые компании в течение ряда лет накапливают большие объемы данных. Здесь обширное поле деятельности для методов Data Mining:
Другие приложения в бизнесе
Data Mining может применяться во множестве других областей:
2.2. Специальные приложения
Медицина
Известно много экспертных систем для постановки медицинских диагнозов. Они построены главным образом на основе правил, описывающих сочетания различных симптомов различных заболеваний. С помощью таких правил узнают не только, чем болен пациент, но и как нужно его лечить. Правила помогают выбирать средства медикаментозного воздействия, определять показания – противопоказания, ориентироваться в лечебных процедурах, создавать условия наиболее эффективного лечения, предсказывать исходы назначенного курса лечения и т. п. Технологии Data Mining позволяют обнаруживать в медицинских данных шаблоны, составляющие основу указанных правил.
Молекулярная генетика и генная инженерия
Пожалуй, наиболее остро и вместе с тем четко задача обнаружения закономерностей в экспериментальных данных стоит в молекулярной генетике и генной инженерии. Здесь она формулируется как определение так называемых маркеров, под которыми понимают генетические коды, контролирующие те или иные фенотипические признаки живого организма. Такие коды могут содержать сотни, тысячи и более связанных элементов.
На развитие генетических исследований выделяются большие средства. В последнее время в данной области возник особый интерес к применению методов Data Mining. Известно несколько крупных фирм, специализирующихся на применении этих методов для расшифровки генома человека и растений.
Прикладная химия
Методы Data Mining находят широкое применение в прикладной химии (органической и неорганической). Здесь нередко возникает вопрос о выяснении особенностей химического строения тех или иных соединений, определяющих их свойства. Особенно актуальна такая задача при анализе сложных химических соединений, описание которых включает сотни и тысячи структурных элементов и их связей.
Можно привести еще много примеров различных областей знания, где методы Data Mining играют ведущую роль. Особенность этих областей заключается в их сложной системной организации. Они относятся главным образом к надкибернетическому уровню организации систем [4], закономерности которого не могут быть достаточно точно описаны на языке статистических или иных аналитических математических моделей [5]. Данные в указанных областях неоднородны, гетерогенны, нестационарны и часто отличаются высокой размерностью.
3. Типы закономерностей
Выделяют пять стандартных типов закономерностей, которые позволяют выявлять методы Data Mining: ассоциация, последовательность, классификация, кластеризация и прогнозирование (рис. 2).

Рисунок 2. Типы закономерностей, выявляемых методами Data Mining
Ассоциация имеет место в том случае, если несколько событий связаны друг с другом. Например, исследование, проведенное в супермаркете, может показать, что 65% купивших кукурузные чипсы берут также и “кока-колу”, а при наличии скидки за такой комплект “колу” приобретают в 85% случаев. Располагая сведениями о подобной ассоциации, менеджерам легко оценить, насколько действенна предоставляемая скидка.
Если существует цепочка связанных во времени событий, то говорят о последовательности. Так, например, после покупки дома в 45% случаев в течение месяца приобретается и новая кухонная плита, а в пределах двух недель 60% новоселов обзаводятся холодильником.
С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил.
Кластеризация отличается от классификации тем, что сами группы заранее не заданы. С помощью кластеризации средства Data Mining самостоятельно выделяют различные однородные группы данных.
Основой для всевозможных систем прогнозирования служит историческая информация, хранящаяся в БД в виде временных рядов. Если удается построить найти шаблоны, адекватно отражающие динамику поведения целевых показателей, есть вероятность, что с их помощью можно предсказать и поведение системы в будущем.
4. Классы систем Data Mining
Data Mining является мультидисциплинарной областью, возникшей и развивающейся на базе достижений прикладной статистики, распознавания образов, методов искусственного интеллекта, теории баз данных и др. (рис. 3). Отсюда обилие методов и алгоритмов, реализованных в различных действующих системах Data Mining. Многие из таких систем интегрируют в себе сразу несколько подходов. Тем не менее, как правило, в каждой системе имеется какая-то ключевая компонента, на которую делается главная ставка. Ниже приводится классификация указанных ключевых компонент на основе работы [6]. Выделенным классам дается краткая характеристика.
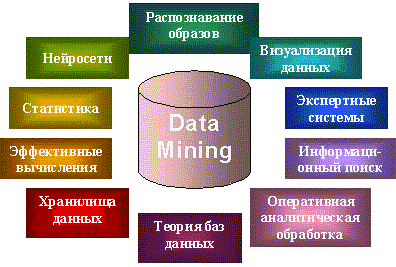
Рисунок 3. Data Mining – мультидисциплинарная область

Рисунок 4. Популярные продукты для Data Mining
4.1. Предметно-ориентированные аналитические системы
4.2. Статистические пакеты
Есть еще более серьезный принципиальный недостаток статистических пакетов, ограничивающий их применение в Data Mining. Большинство методов, входящих в состав пакетов опираются на статистическую парадигму, в которой главными фигурантами служат усредненные характеристики выборки. А эти характеристики, как указывалось выше, при исследовании реальных сложных жизненных феноменов часто являются фиктивными величинами.
В качестве примеров наиболее мощных и распространенных статистических пакетов можно назвать SAS (компания SAS Institute), SPSS (SPSS), STATGRAPICS (Manugistics), STATISTICA, STADIA и другие.
4.3. Нейронные сети
Это большой класс систем, архитектура которых имеет аналогию (как теперь известно, довольно слабую) с построением нервной ткани из нейронов. В одной из наиболее распространенных архитектур, многослойном перцептроне с обратным распространением ошибки, имитируется работа нейронов в составе иерархической сети, где каждый нейрон более высокого уровня соединен своими входами с выходами нейронов нижележащего слоя. На нейроны самого нижнего слоя подаются значения входных параметров, на основе которых нужно принимать какие-то решения, прогнозировать развитие ситуации и т. д. Эти значения рассматриваются как сигналы, передающиеся в следующий слой, ослабляясь или усиливаясь в зависимости от числовых значений (весов), приписываемых межнейронным связям. В результате на выходе нейрона самого верхнего слоя вырабатывается некоторое значение, которое рассматривается как ответ – реакция всей сети на введенные значения входных параметров. Для того чтобы сеть можно было применять в дальнейшем, ее прежде надо “натренировать” на полученных ранее данных, для которых известны и значения входных параметров, и правильные ответы на них. Тренировка состоит в подборе весов межнейронных связей, обеспечивающих наибольшую близость ответов сети к известным правильным ответам.
Основным недостатком нейросетевой парадигмы является необходимость иметь очень большой объем обучающей выборки. Другой существенный недостаток заключается в том, что даже натренированная нейронная сеть представляет собой черный ящик. Знания, зафиксированные как веса нескольких сотен межнейронных связей, совершенно не поддаются анализу и интерпретации человеком (известные попытки дать интерпретацию структуре настроенной нейросети выглядят неубедительными – система “KINOsuite-PR”).

Рисунок 5. Полиномиальная нейросеть
4.4. Системы рассуждений на основе аналогичных случаев
Идея систем case based reasoning – CBR – на первый взгляд крайне проста. Для того чтобы сделать прогноз на будущее или выбрать правильное решение, эти системы находят в прошлом близкие аналоги наличной ситуации и выбирают тот же ответ, который был для них правильным. Поэтому этот метод еще называют методом “ближайшего соседа” (nearest neighbour). В последнее время распространение получил также термин memory based reasoning, который акцентирует внимание, что решение принимается на основании всей информации, накопленной в памяти.
Системы CBR показывают неплохие результаты в самых разнообразных задачах. Главным их минусом считают то, что они вообще не создают каких-либо моделей или правил, обобщающих предыдущий опыт, – в выборе решения они основываются на всем массиве доступных исторических данных, поэтому невозможно сказать, на основе каких конкретно факторов CBR системы строят свои ответы.
Другой минус заключается в произволе, который допускают системы CBR при выборе меры “близости”. От этой меры самым решительным образом зависит объем множества прецедентов, которые нужно хранить в памяти для достижения удовлетворительной классификации или прогноза [7].
Примеры систем, использующих CBR, – KATE tools (Acknosoft, Франция), Pattern Recognition Workbench (Unica, США).
4.5. Деревья решений (decision trees)
Деревья решения являются одним из наиболее популярных подходов к решению задач Data Mining. Они создают иерархическую структуру классифицирующих правил типа “ЕСЛИ… ТО…” (if-then), имеющую вид дерева. Для принятия решения, к какому классу отнести некоторый объект или ситуацию, требуется ответить на вопросы, стоящие в узлах этого дерева, начиная с его корня. Вопросы имеют вид “значение параметра A больше x””. Если ответ положительный, осуществляется переход к правому узлу следующего уровня, если отрицательный – то к левому узлу; затем снова следует вопрос, связанный с соответствующим узлом.
Популярность подхода связана как бы с наглядностью и понятностью. Но деревья решений принципиально не способны находить “лучшие” (наиболее полные и точные) правила в данных. Они реализуют наивный принцип последовательного просмотра признаков и “цепляют” фактически осколки настоящих закономерностей, создавая лишь иллюзию логического вывода.
Вместе с тем, большинство систем используют именно этот метод. Самыми известными являются See5/С5.0 (RuleQuest, Австралия), Clementine (Integral Solutions, Великобритания), SIPINA (University of Lyon, Франция), IDIS (Information Discovery, США), KnowledgeSeeker (ANGOSS, Канада). Стоимость этих систем варьируется от 1 до 10 тыс. долл.
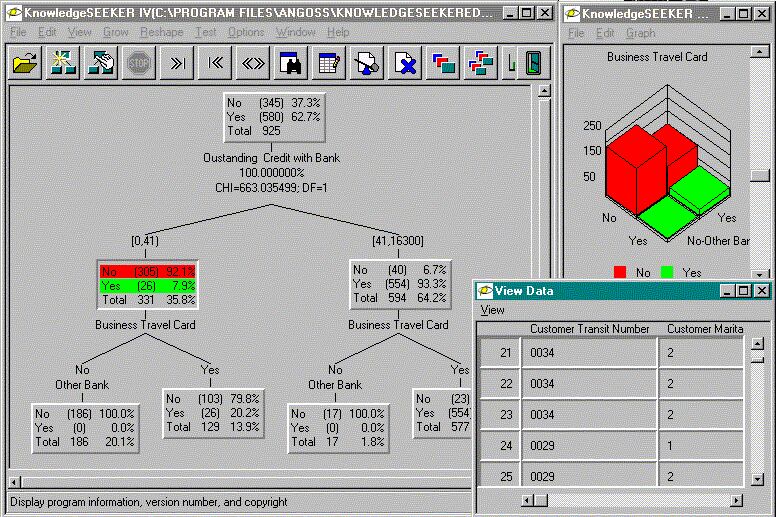
Рисунок 6. Система KnowledgeSeeker обрабатывает банковскую информацию
4.6. Эволюционное программирование
Проиллюстрируем современное состояние данного подхода на примере системы PolyAnalyst – отечественной разработке, получившей сегодня общее признание на рынке Data Mining. В данной системе гипотезы о виде зависимости целевой переменной от других переменных формулируются в виде программ на некотором внутреннем языке программирования. Процесс построения программ строится как эволюция в мире программ (этим подход немного похож на генетические алгоритмы). Когда система находит программу, более или менее удовлетворительно выражающую искомую зависимость, она начинает вносить в нее небольшие модификации и отбирает среди построенных дочерних программ те, которые повышают точность. Таким образом система “выращивает” несколько генетических линий программ, которые конкурируют между собой в точности выражения искомой зависимости. Специальный модуль системы PolyAnalyst переводит найденные зависимости с внутреннего языка системы на понятный пользователю язык (математические формулы, таблицы и пр.).
Другое направление эволюционного программирования связано с поиском зависимости целевых переменных от остальных в форме функций какого-то определенного вида. Например, в одном из наиболее удачных алгоритмов этого типа – методе группового учета аргументов (МГУА) зависимость ищут в форме полиномов. В настоящее время из продающихся в России систем МГУА реализован в системе NeuroShell компании Ward Systems Group.
4.7. Генетические алгоритмы
Data Mining не основная область применения генетических алгоритмов. Их нужно рассматривать скорее как мощное средство решения разнообразных комбинаторных задач и задач оптимизации. Тем не менее генетические алгоритмы вошли сейчас в стандартный инструментарий методов Data Mining, поэтому они и включены в данный обзор.
Первый шаг при построении генетических алгоритмов – это кодировка исходных логических закономерностей в базе данных, которые именуют хромосомами, а весь набор таких закономерностей называют популяцией хромосом. Далее для реализации концепции отбора вводится способ сопоставления различных хромосом. Популяция обрабатывается с помощью процедур репродукции, изменчивости (мутаций), генетической композиции. Эти процедуры имитируют биологические процессы. Наиболее важные среди них: случайные мутации данных в индивидуальных хромосомах, переходы (кроссинговер) и рекомбинация генетического материала, содержащегося в индивидуальных родительских хромосомах (аналогично гетеросексуальной репродукции), и миграции генов. В ходе работы процедур на каждой стадии эволюции получаются популяции со все более совершенными индивидуумами.
Генетические алгоритмы удобны тем, что их легко распараллеливать. Например, можно разбить поколение на несколько групп и работать с каждой из них независимо, обмениваясь время от времени несколькими хромосомами. Существуют также и другие методы распараллеливания генетических алгоритмов.
Генетические алгоритмы имеют ряд недостатков. Критерий отбора хромосом и используемые процедуры являются эвристическими и далеко не гарантируют нахождения “лучшего” решения. Как и в реальной жизни, эволюцию может “заклинить” на какой-либо непродуктивной ветви. И, наоборот, можно привести примеры, как два неперспективных родителя, которые будут исключены из эволюции генетическим алгоритмом, оказываются способными произвести высокоэффективного потомка. Это особенно становится заметно при решении высокоразмерных задач со сложными внутренними связями.
4.8. Алгоритмы ограниченного перебора
Алгоритмы ограниченного перебора были предложены в середине 60-х годов М.М. Бонгардом для поиска логических закономерностей в данных. С тех пор они продемонстрировали свою эффективность при решении множества задач из самых различных областей.
Эти алгоритмы вычисляют частоты комбинаций простых логических событий в подгруппах данных. Примеры простых логических событий: X = a; X 4.9. Системы для визуализации многомерных данных
В той или иной мере средства для графического отображения данных поддерживаются всеми системами Data Mining. Вместе с тем, весьма внушительную долю рынка занимают системы, специализирующиеся исключительно на этой функции. Примером здесь может служить программа DataMiner 3D словацкой фирмы Dimension5 (5-е измерение).
В подобных системах основное внимание сконцентрировано на дружелюбности пользовательского интерфейса, позволяющего ассоциировать с анализируемыми показателями различные параметры диаграммы рассеивания объектов (записей) базы данных. К таким параметрам относятся цвет, форма, ориентация относительно собственной оси, размеры и другие свойства графических элементов изображения. Кроме того, системы визуализации данных снабжены удобными средствами для масштабирования и вращения изображений. Стоимость систем визуализации может достигать нескольких сотен долларов.
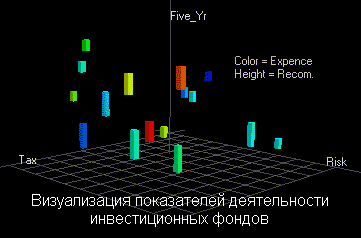
Рисунок 8. Визуализация данных системой DataMiner 3D



