CentOS / RHEL 7: Как настроить kdump
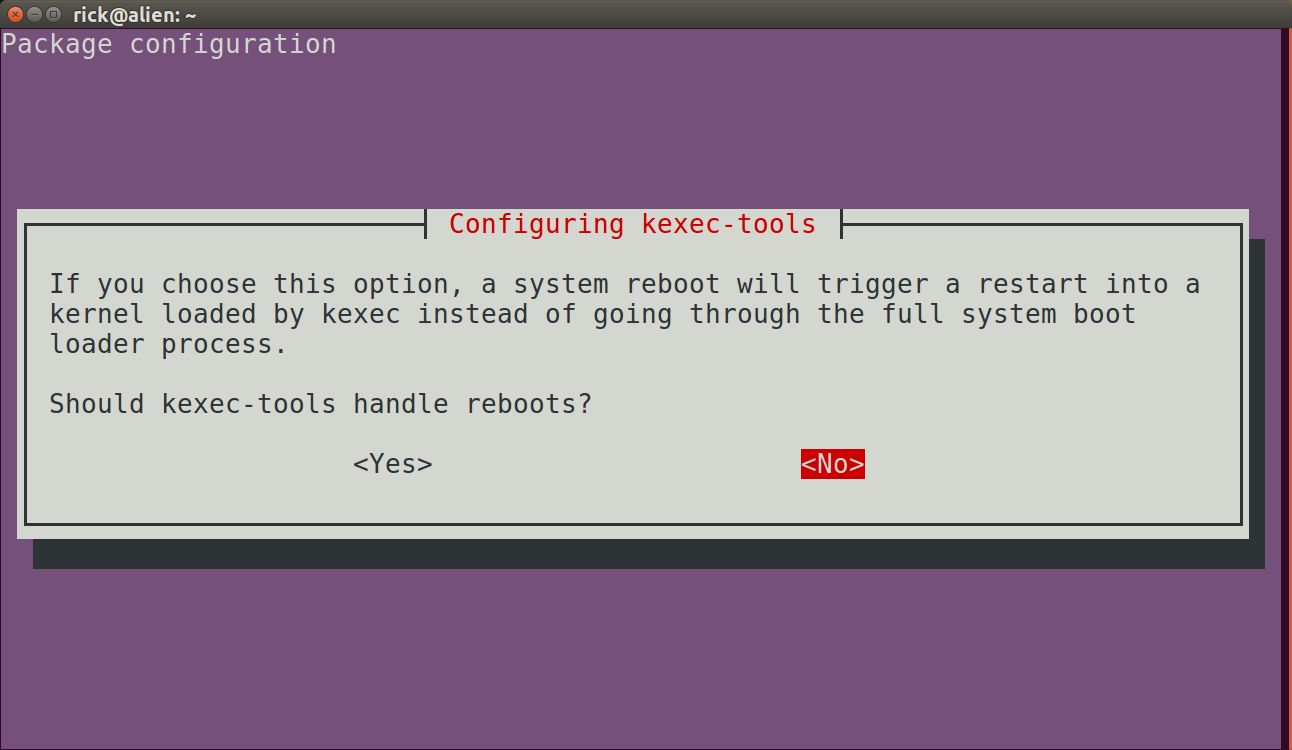
kdump – это продвинутый механизм сброса аварий.
Когда включен, система загружается из контекста другого ядра.
Это второе ядро резервирует небольшой объем памяти, и его единственной целью является захват изображения дампа ядра в случае сбоя системы.
Поскольку возможность анализа дампа ядра помогает значительно определить точную причину сбоя системы, настоятельно рекомендуется включить эту функцию.
1. Установите пакет kexec-tools, если он еще не установлен.
Чтобы использовать службу kdump, вы должны установить пакет kexec-tools. Если он еще не установлен, установите инструменты kexec.
2. Настройка использования памяти в GRUB2
Чтобы настроить объем памяти, зарезервированный для ядра kdump, отредактируйте /etc/default/grub и измените GRUB_CMDLINE_LINUX, установите параметр crashkernel = [размер] в список параметров ядра.
Выполните команду ниже, чтобы восстановить конфигурацию grub:
Перезагрузите систему, чтобы вступили в силу параметры ядра.
3. Конфигурирование местоположения дампа
Чтобы настроить kdump, нам нужно отредактировать файл конфигурации /etc/kdump.conf.
Опцией по умолчанию является сохранение файла vmcore в каталоге / var / crash / локальной файловой системы.
Чтобы изменить локальный каталог, в котором необходимо сохранить дамп ядра, и замените значение на нужный путь к каталогу.
Например:
При желании вы также можете сохранить дамп ядра непосредственно в необработанном разделе.
Например:
Чтобы сохранить дамп на удаленном компьютере с использованием протокола NFS, удалите хэш-знак («#») с начала строки #nfs my.server.com:/export/tmp и замените значение допустимым именем хоста и путь к каталогу.
Например:
4. Настройка Core Collector
Чтобы уменьшить размер файла дампа vmcore, kdump позволяет вам указать внешнее приложение для сжатия данных и, при необходимости, оставить всю несущественную информацию.
В настоящее время единственным полностью поддерживаемым сборщиком ядра является makedumpfile.
5. Изменение действия по умолчанию
Мы также можем указать действие по умолчанию для выполнения, когда дамп ядра не может сгенерироваться в нужном месте. Если не указано действие по умолчанию, «перезагрузка» считается по умолчанию.
6. Запустите демон kdump
Проверьте и убедитесь, что в командной строке ядра включена конфигурация kdump и память зарезервирована для сбоя ядра:
Установите,чтобы служба kdump могла быть запущена при перезагрузке системы.
Чтобы запустить службу в текущем сеансе, используйте следующую команду:
7. Тестирование kdump (ручной запуск kdump)
Чтобы проверить конфигурацию, мы можем перезагрузить систему с включенным kdump и убедиться, что служба запущена.
Затем введите в командной строке следующие команды:
Для записи при сбое ядра в выбранное местоположение то есть в / var / crash /
Устранение проблем с kdump в CentOS / RHEL
Механизм kdump – это функция ядра Linux, которая позволяет создавать дампы в случае сбоя ядра.
Он производит точную копию памяти, которую можно проанализировать на предмет первопричины сбоя.
Это скрипт, который настраивает kdump (дамп ядра).
Kdump предоставляет дамп памяти в файл с именем vmcore, когда в ядре возникает критическая проблема.
Vmcore часто требуется, чтобы исследовать проблему.
Аварийный дамп записывается из контекста недавно загруженного ядра, а не из контекста аварийного ядра. Kdump использует kexec для загрузки второго ядра при сбое системы.
Kexec – это механизм быстрой загрузки, который позволяет перезагружать новое ядро Linux из контекста работающего ядра без прохождения прошивки или горячего запуска.
В этом посте объясняются шаги по устранению распространенных проблем с kdump.
Проверка настройки kdump
1. Проверьте, установлен ли в системе пакет kexec-tools.
2. Проверьте командную строку ядра в текущем работающем ядре на наличие параметра «crashkernel»:
3. Проверьте, зарезервирована ли память для аварийного ядра при запуске ядра:
4. Проверьте путь к дампу:
5. Проверьте объем памяти, доступный в файловой системе, указанной в параметре пути на предыдущем шаге:
6. Проверьте состояние сервиса kdump:
Когда служба Kdump не работает
1. Проверьте настройку kdump, следуя приведенному выше разделу.
2. Запустите сервис kdump
3. Проверьте ошибку с терминала.
4. Дополнительную информацию об ошибке запуска службы kdump можно найти в /var/log/messages.
Когда настройка kdump в порядке, а состояние службы kdump работает, но vmcore не генерируется при возникновении сбоя
1. Отредактируйте файл /etc/kdump.conf и добавьте следующую строку, чтобы получить оболочку при сбое генерации vmcore:
2. В оболочке проверьте доступное хранилище, проверьте, смонтирована ли целевая файловая система vmcore, а затем попробуйте скопировать vmcore вручную и определить,работает ли он.
Когда оболочка не получена и crashkernel застряло при загрузке
1. Проверьте сообщения на консоли и найдите сообщения о запуске аварийного ядра.
Ищите, где оно застряло.
Crashkernel – это то же самое ядро, которое запускается при запуске системы, и, следовательно, можно увидеть сообщения, похожие на обычные сообщения о загрузке ядра, но с активированными ограниченными устройствами. Например: в аварийном ядре включен только 1 процессор. Обнаружен только целевой диск хранения.
2. Если вы видите сообщения об ошибках выделения страниц, высока вероятность того, что зарезервированного crashkernel недостаточно, и вам потребуется увеличить значение параметра ядра ‘crashkernel’.
How to configure and Install kdump (crashkernel) in RHEL/CentOS 7
What is kdump?
kdump is a reliable kernel crash-dumping mechanism that utilizes the kexec software. The crash dumps are captured from the context of a freshly booted kernel; not from the context of the crashed kernel. Kdump uses kexec to boot into a second kernel whenever the system crashes. This second kernel, often called a capture kernel, boots with very little memory and captures the dump image.
Using kdump allows booting the capture kernel without going through BIOS hence the contents of the first kernel’s memory are preserved, which is essentially the kernel crash dump.
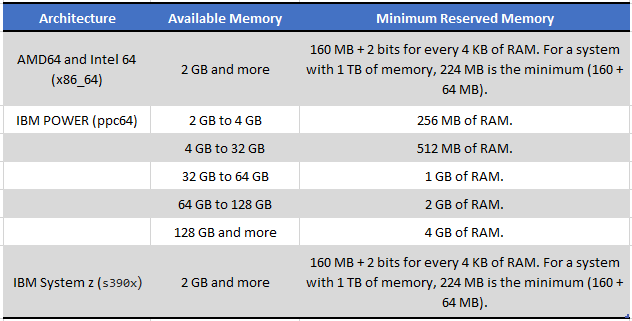
Memory requirements
In order for kdump to be able to capture a kernel crash dump and save it for further analysis, a part of the system memory has to be permanently reserved for the capture kernel. When reserved, this part of the system memory is not available to main kernel.
The memory requirements vary based on certain system parameters. One of the major factors is the system’s hardware architecture. To find out the exact name of the machine architecture (such as x86_64) and print it to standard output, type the following command at a shell prompt:
Another factor which influences the amount of memory to be reserved is the total amount of installed system memory. For example, on the x86_64 architecture, the amount of reserved memory is 160 MB + 2 bits for every 4 KB of RAM. On a system with 1 TB of total physical memory installed, this means 224 MB (160 MB + 64 MB).
Installing kdump
In order use the kdump service on your system, make sure you have the kexec-tools package installed.
To do so, type the following at a shell prompt as root:
On IBM Power (ppc64) and IBM System z (s390x), the capture kernel is provided in a separate package called kernel-kdump which must be installed for kdump to function:
Adding Boot Parameters
The “ crashkernel= ” option can be defined in multiple ways.
The example above means that kdump reserves 128 MB of memory starting at 16 MB (physical address 0x01000000). If the offset parameter is set to 0 or omitted entirely, kdump offsets the reserved memory automatically
Sample GRUB2 config file ( /etc/sysconfig/grub )
Where to find generated vmcores?
When the hypervisor comes back up, the vmcore can be found by default under /var/crash/:
]# egrep ‘^path’ /etc/kdump.conf
path /var/crash
Configuring the core collector
To reduce the size of the vmcore dump file, kdump allows you to specify an external application (a core collector) to compress the data, and optionally leave out all irrelevant information. Currently, the only fully supported core collector is makedumpfile.
To enable the dump file compression, add the -c parameter. For example:
To remove certain pages from the dump, add the -d value parameter, where value is a sum of values of pages you want to omit.
For example, to remove both zero and free pages, use the following:
Enabling the service
To start the kdump daemon at boot time, type the following at a shell prompt as root:
This enables the service for multi-user.target. Similarly, typing systemctl stop kdump disables it. To start the service in the current session, use the following command as root:
Testing the kdump configuration
To test the configuration, reboot the system with kdump enabled, and make sure that the service is running:
Then type the following commands at a shell prompt:
This forces the Linux kernel to crash, and the address-YYYY-MM-DD-HH:MM:SS/vmcore file is copied to the location you have selected in the configuration (that is, to /var/crash/ by default).
Analysing hung task
We must use “hung_task_panic” which controls the kernel’s behavior when a hung task is detected.
This file shows up if CONFIG_DETECT_HUNG_TASK is enabled.
For temporary changes:
For permanent changes
With this whenever a blocking process as seen is seen, a kernel panic will happen and core dump will be generated which can be abalysed further to debug the issue.
Kdump — диагностика и анализ причин сбоев ядра

Хотя в современных Linux-системах ядро отличается достаточно высоким уровнем стабильности, вероятность серьезных системных ошибок, тем не менее, имеется всегда. Когда происходит неисправимая ошибка, имеет место состояние, называемое паникой ядра (kernel panic): стандартный обработчик выводит на экран информацию, которая должна помочь в устранении неисправности, и входит в бесконечный цикл.
Для диагностики и анализа причин сбоев ядра разработчиками компании RedHat был разработан специализированный инструмент — kdump. Принцип его работы можно кратко описать следующим образом. Создается два ядра: основное и аварийное (именно оно используется для сбора дампа памяти). При загрузке основного ядра под аварийное ядро выделяется определенный размер памяти. При помощи kexec во время паники основного ядра загружается аварийное и собирает дамп.
В этой статье мы подробно расскажем о том, как конфигурировать kdump и анализировать с его помощью системные ошибки. Мы рассмотрим особенности работы с kdump в OC Ubuntu; в других дистрибутивах процедуры настройки и конфигурирования kdump существенно отличаются.
Установка и настройка kdump
Установим kdump с помощью команды
Настройки kdump хранятся в конфигурационном файле /etc/default/kdump-tools
Установив все необходимые параметры, выполним команду update-grub и выберем install the package maintainer’s version.
Затем перезагрузим систему и убедимся в том, что kdump готов к работе:
Для того, чтобы мы могли анализировать дамп с помощью утилиты crash, нам понадобится также файл vmlinux, содержащий отладочную информацию:
По завершении установки еще раз проверим статус kdump:
Если kdump находится в рабочем состоянии, на консоль будет выведено следующее сообщение:
Тестируем kdump
Вызовем панику ядра при помощи следующих команд:
В результате их выполнения система «зависнет».
После этого в течение нескольких минут будет создан дамп, который будет доступен в директории /var/crash после перезагрузки.
Информацию о сбое ядра можно просмотреть с помощью утилиты crash:
На основе приведенного вывода мы можем заключить, что системному сбою предшествовало событие «Oops: 0002 [#1] SMP», произошедшее на CPU2 при выполнении команды tee.
Утилита crash обладает также широким спектром возможностей для диагностики причин краха ядра. Рассмотрим их более подробно.
Диагностика причин сбоя с помощью утилиты crash
Crash сохраняет информацию обо всех системных событиях, предшествовавших краху ядра. С ее помощью можно воссоздать состояние системы на момент сбоя: узнать, какие процессы были запущены на момент краха, какие файлы открыты и т.п. Эта информация помогает поставить точный диагноз и предупредить крахи ядра в будущем.
В утилите crash имеется свой набор команд:
Для каждой этой команды можно вызвать краткий мануал, например:
Все команды мы описывать не будем (с детальной информацией можно ознакомиться в официальном руководстве пользователя от компании RedHat), а расскажем лишь о наиболее важных из них.
В первую очередь следует обратить внимание на команду bt (аббревиатура от backtrace — обратная трассировка). С ее помощью можно посмотреть детальную информацию о содержании памяти ядра (подробности и примеры использования см. здесь). Однако во многих случаях для определения причины системного сбоя бывает вполне достаточно команды log, выводящее на экран содержимое буфера сообщений ядра в хронологическом порядке.
Приведем фрагмент ее вывода:
В одной из строк вывода будет указано событие, вызвавшее системную ошибку:
С помощью команды ps можно вывести на экран список процессов, которые были запущены на момент сбоя:
Для просмотра информации об использовании виртуальной памяти используется команда vm:
Команда swap выведет на консоль информацию об использовании области подкачки:
Информацию о прерываниях CPU можно просмотреть с помощью команды irq:
Вывести на консоль список файлов, открытых на момент сбоя, можно с помощью команды files:
Наконец, получить в сжатом виде информацию об общем состоянии системы можно с помощью команды sys:
Заключение
Анализ и диагностика причин падения ядра представляет собой очень специфическую и сложную тему, которую невозможно уместить в рамки одной статьи. Мы еще вернемся к ней в следующих публикациях.
Читателей, которые не могут оставлять комментарии здесь, приглашаем к нам в блог.
Kdump — диагностика и анализ причин сбоев ядра


Хотя в современных Linux-системах ядро отличается достаточно высоким уровнем стабильности, вероятность серьезных системных ошибок, тем не менее, имеется всегда. Когда происходит неисправимая ошибка, имеет место состояние, называемое паникой ядра (kernel panic): стандартный обработчик выводит на экран информацию, которая должна помочь в устранении неисправности, и входит в бесконечный цикл.
Для диагностики и анализа причин сбоев ядра разработчиками компании RedHat был разработан специализированный инструмент — kdump. Принцип его работы можно кратко описать следующим образом. Создается два ядра: основное и аварийное (именно оно используется для сбора дампа памяти). При загрузке основного ядра под аварийное ядро выделяется определенный размер памяти. При помощи kexec во время паники основного ядра загружается аварийное и собирает дамп.
В этой статье мы подробно расскажем о том, как конфигурировать kdump и анализировать с его помощью системные ошибки. Мы рассмотрим особенности работы с kdump в OC Ubuntu; в других дистрибутивах процедуры настройки и конфигурирования kdump существенно отличаются.
Установка и настройка kdump
Установим kdump с помощью команды
Настройки kdump хранятся в конфигурационном файле /etc/default/kdump-tools
Чтобы активировать kdump, отредактируем этот файл и установим значение параметра USE_KDUMP=1.
Также в конфигурационном файле содержатся следующие параметры:
Установив все необходимые параметры, выполним команду update-grub и выберем install the package maintainer’s version.
Затем перезагрузим систему и убедимся в том, что kdump готов к работе:
Для того, чтобы мы могли анализировать дамп с помощью утилиты crash, нам понадобится также файл vmlinux, содержащий отладочную информацию:
По завершении установки еще раз проверим статус kdump:
Если kdump находится в рабочем состоянии, на консоль будет выведено следующее сообщение:
Тестируем kdump
Вызовем панику ядра при помощи следующих команд:
В результате их выполнения система «зависнет».
После этого в течение нескольких минут будет создан дамп, который будет доступен в директории /var/crash после перезагрузки.
Информацию о сбое ядра можно просмотреть с помощью утилиты crash:
На основе приведенного вывода мы можем заключить, что системному сбою предшествовало событие «Oops: 0002 [#1] SMP», произошедшее на CPU2 при выполнении команды tee.
Утилита crash обладает также широким спектром возможностей для диагностики причин краха ядра. Рассмотрим их более подробно.
Диагностика причин сбоя с помощью утилиты crash
Crash сохраняет информацию обо всех системных событиях, предшествовавших краху ядра. С ее помощью можно воссоздать состояние системы на момент сбоя: узнать, какие процессы были запущены на момент краха, какие файлы открыты и т.п. Эта информация помогает поставить точный диагноз и предупредить крахи ядра в будущем.
В утилите crash имеется свой набор команд:
Для каждой этой команды можно вызвать краткий мануал, например:
Все команды мы описывать не будем (с детальной информацией можно ознакомиться в официальном руководстве пользователя от компании RedHat ), а расскажем лишь о наиболее важных из них.
В первую очередь следует обратить внимание на команду bt (аббревиатура от backtrace — обратная трассировка). С ее помощью можно посмотреть детальную информацию о содержании памяти ядра (подробности и примеры использования см. здесь ). Однако во многих случаях для определения причины системного сбоя бывает вполне достаточно команды log, выводящее на экран содержимое буфера сообщений ядра в хронологическом порядке.
Приведем фрагмент ее вывода:
В одной из строк вывода будет указано событие, вызвавшее системную ошибку:
С помощью команды ps можно вывести на экран список процессов, которые были запущены на момент сбоя:
Для просмотра информации об использовании виртуальной памяти используется команда vm:
Команда swap выведет на консоль информацию об использовании области подкачки:
Информацию о прерываниях CPU можно просмотреть с помощью команды irq:
Вывести на консоль список файлов, открытых на момент сбоя, можно с помощью команды files:
Наконец, получить в сжатом виде информацию об общем состоянии системы можно с помощью команды sys:
Заключение
Анализ и диагностика причин падения ядра представляет собой очень специфическую и сложную тему, которую невозможно уместить в рамки одной статьи. Мы еще вернемся к ней в следующих публикациях.
Для желающих узнать больше — несколько полезных ссылок:



