Внутренняя работа HashMap в Java
В этой статье мы увидим, как изнутри работают методы get и put в коллекции HashMap. Какие операции выполняются. Как происходит хеширование. Как значение извлекается по ключу. Как хранятся пары ключ-значение.
Как и в предыдущей статье, HashMap содержит массив Node и Node может представлять класс, содержащий следующие объекты:
Теперь мы увидим, как все это работает. Для начала мы рассмотрим процесс хеширования.
Хэширование
Здесь я использую свой собственный класс Key и таким образом могу переопределить метод hashCode() для демонстрации различных сценариев. Мой класс Key:
Здесь переопределенный метод hashCode() возвращает ASCII код первого символа строки. Таким образом, если первые символы строки одинаковые, то и хэш коды будут одинаковыми. Не стоит использовать подобную логику в своих программах.
Этот код создан исключительно для демонстрации. Поскольку HashCode допускает ключ типа null, хэш код null всегда будет равен 0.
Метод hashCode()
Метод equals()
Метод equals используется для проверки двух объектов на равенство. Метод реализованн в классе Object. Вы можете переопределить его в своем собственном классе. В классе HashMap метод equals() используется для проверки равенства ключей. В случае, если ключи равны, метод equals() возвращает true, иначе false.
Корзины (Buckets)
Вычисление индекса в HashMap
Хэш код ключа может быть достаточно большим для создания массива. Сгенерированный хэш код может быть в диапазоне целочисленного типа и если мы создадим массив такого размера, то легко получим исключение outOfMemoryException. Потому мы генерируем индекс для минимизации размера массива. По сути для вычисления индекса выполняется следующая операция:
где n равна числу bucket или значению длины массива. В нашем примере я рассматриваю n, как значение по умолчанию равное 16.
HashMap: 
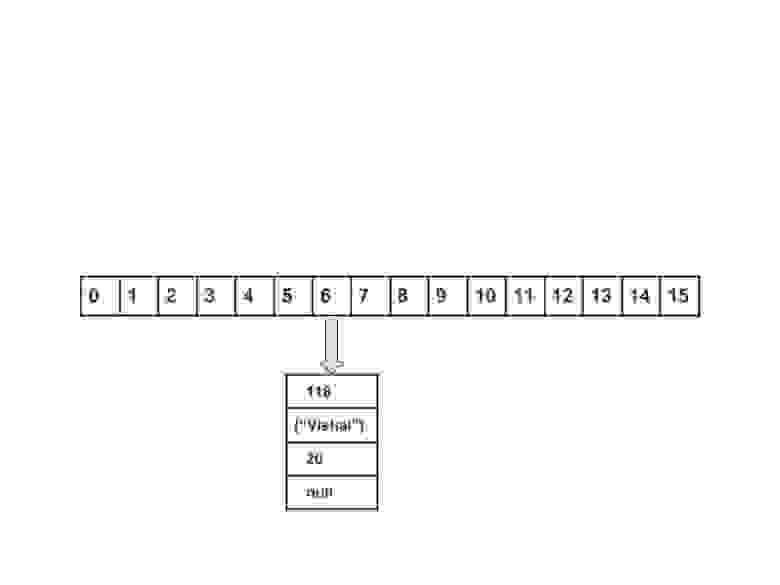
Вычислить значение ключа <"vishal">. Оно будет сгенерированно, как 118.
Создать объект node.
Поместить объект в позицию с индексом 6, если место свободно.
Теперь HashMap выглядит примерно так:
Вычислить значение ключа <"sachin">. Оно будет сгенерированно, как 115.
Создать объект node.
Поместить объект в позицию с индексом 3, если место свободно.
Теперь HashMap выглядит примерно так:

Вычислить значение ключа <"vaibhav">. Оно будет сгенерированно, как 118.
Создать объект node.
Поместить объект в позицию с индексом 6, если место свободно.
В данном случае в позиции с индексом 6 уже существует другой объект, этот случай называется коллизией.
В таком случае проверям с помощью методов hashCode() и equals(), что оба ключа одинаковы.
Если ключи одинаковы, заменить текущее значение новым.
Иначе связать новый и старый объекты с помощью структуры данных «связанный список», указав ссылку на следующий объект в текущем и сохранить оба под индексом 6.
Теперь HashMap выглядит примерно так:

[примечание от автора перевода] Изображение взято из оригинальной статьи и изначально содержит ошибку. Ссылка на следующий объект в объекте vishal с индексом 6 не равна null, в ней содержится указатель на объект vaibhav.
Вычислить хэш код объекта <“sachin”>. Он был сгенерирован, как 115.
В нашем случае элемент найден и возвращаемое значение равно 30.
Вычислить хэш код объекта <"vaibhav">. Он был сгенерирован, как 118.
В данном случае он не найден и следующий объект node не равен null.
Если следующий объект node равен null, возвращаем null.
Если следующий объект node не равен null, переходим к нему и повторяем первые три шага до тех пор, пока элемент не будет найден или следующий объект node не будет равен null.
Изменения в Java 8
Для исправления этой проблемы в Java 8 после достижения определенного порога вместо связанных списков используются сбалансированные деревья. Это означает, что HashMap в начале сохраняет объекты в связанном списке, но после того, как колличество элементов в хэше достигает определенного порога происходит переход к сбалансированным деревьям. Что улучшает производительность в худшем случае с O(n) до O(log n).
30.15. Java – Класс HashMap
Класс HashMap в Java использует хэш-таблицу для реализации интерфейса Map. Это позволяет времени для выполнения основных операций, таких как get () и put (), оставаться постоянным даже для больших множеств.
Содержание
Конструкторы
Ниже приведен список конструкторов, поддерживаемых классом HashMap.
| № | Конструктор и описание |
| 1 | HashMap( ) Этот конструктор создает стандартный HashMap по умолчанию. |
| 2 | HashMap(Map m) Этот конструктор инициализирует хэш-карту, используя элементы Map данного объекта m. |
| 3 | HashMap(int capacity) Этот конструктор инициализирует емкость хэш-карты для заданного целочисленного значения, capacity. |
| 4 | HashMap(int capacity, float fillRatio) Этот конструктор инициализирует как ёмкость, так и коэффициент заполнения хэш-карты, используя ее аргументы. |
Методы
Помимо методов, унаследованных от родительских классов, HashMap определяет следующие методы:
| № | Методы и описание |
| 1 | void clear() Удаляет все соответствия с этого Map. |
| 2 | Object clone() Возвращает мелкую копию этого экземпляра HashMap: сами ключи и значения не клонируются. |
| 3 | boolean containsKey(Object key) Возвращает true, если этот Map содержит отображение для указанного ключа. |
| 4 | boolean containsValue(Object value) Возвращает true, если этот Map отображает одну или несколько клавиш в указанное значение. |
| 5 | Set entrySet() Возвращает представление (вид) коллекции отображений, содержащихся в этом Map. |
| 6 | Object get(Object key) Возвращает значение, для которого указанный ключ отображается в этой хэш-карте идентификатора, или null (нуль), если Map не содержит отображения для этого ключа. |
| 7 | boolean isEmpty() Возвращает true, если этот Map не содержит отображений значений ключа. |
| 8 | Set keySet() Возвращает заданное представление (вид) ключей, содержащихся на этом Map. |
| 9 | Object put(Object key, Object value) Связывает указанное значение с указанным ключом на этом Map. |
| 10 | putAll(Map m) Копирует все отображения с указанного Map на этот Map. Эти отображения заменят любые отображения, которые это отображение имело для любого из ключей, находящихся в настоящее время на указанном Map. |
| 11 | Object remove(Object key) Удаляет отображение для этого ключа с этого Map, если присутствует. |
| 12 | int size() Возвращает количество ключ-значение отображений на этом Map. |
| 13 | Collection values() Возвращает представление (вид) коллекции значений, содержащихся на этой карте. |
Пример
Следующая программа демонстрирует работу нескольких методов, поддерживаемых HashMap в Java:
Структуры данных в картинках. HashMap
Приветствую вас, хабрачитатели!
Продолжаю попытки визуализировать структуры данных в Java. В предыдущих сериях мы уже ознакомились с ArrayList и LinkedList, сегодня же рассмотрим HashMap.

HashMap — основан на хэш-таблицах, реализует интерфейс Map (что подразумевает хранение данных в виде пар ключ/значение). Ключи и значения могут быть любых типов, в том числе и null. Данная реализация не дает гарантий относительно порядка элементов с течением времени. Разрешение коллизий осуществляется с помощью метода цепочек.
Создание объекта
Вы можете указать свои емкость и коэффициент загрузки, используя конструкторы HashMap(capacity) и HashMap(capacity, loadFactor). Максимальная емкость, которую вы сможете установить, равна половине максимального значения int (1073741824).
Добавление элементов
Комментарий из исходников объясняет, каких результатов стоит ожидать — метод hash(key) гарантирует что полученные хэш-коды, будут иметь только ограниченное количество коллизий (примерно 8, при дефолтном значении коэффициента загрузки).
В моем случае, для ключа со значением »0» метод hashCode() вернул значение 48, в итоге:
При значении хэша 51 и размере таблице 16, мы получаем индекс в массиве:
Для того чтобы продемонстрировать, как заполняется HashMap, добавим еще несколько элементов.
Footprint
Object size: 376 bytes
Footprint
Object size: 496 bytes
Resize и Transfer
Когда массив table[] заполняется до предельного значения, его размер увеличивается вдвое и происходит перераспределение элементов. Как вы сами можете убедиться, ничего сложного в методах resize(capacity) и transfer(newTable) нет.
Метод transfer() перебирает все элементы текущего хранилища, пересчитывает их индексы (с учетом нового размера) и перераспределяет элементы по новому массиву.
Если в исходный hashmap добавить, скажем, еще 15 элементов, то в результате размер будет увеличен и распределение элементов изменится.
Удаление элементов
У HashMap есть такая же «проблема» как и у ArrayList — при удалении элементов размер массива table[] не уменьшается. И если в ArrayList предусмотрен метод trimToSize(), то в HashMap таких методов нет (хотя, как сказал один мой коллега — «А может оно и не надо?«).
Небольшой тест, для демонстрации того что написано выше. Исходный объект занимает 496 байт. Добавим, например, 150 элементов.
Теперь удалим те же 150 элементов, и снова замерим.
Как видно, размер даже близко не вернулся к исходному. Если есть желание/потребность исправить ситуацию, можно, например, воспользоваться конструктором HashMap(Map).
Итераторы
HashMap имеет встроенные итераторы, такие, что вы можете получить список всех ключей keySet(), всех значений values() или же все пары ключ/значение entrySet(). Ниже представлены некоторые варианты для перебора элементов:
Стоит помнить, что если в ходе работы итератора HashMap был изменен (без использования собственным методов итератора), то результат перебора элементов будет непредсказуемым.
Итоги
— Добавление элемента выполняется за время O(1), потому как новые элементы вставляются в начало цепочки;
— Операции получения и удаления элемента могут выполняться за время O(1), если хэш-функция равномерно распределяет элементы и отсутствуют коллизии. Среднее же время работы будет Θ(1 + α), где α — коэффициент загрузки. В самом худшем случае, время выполнения может составить Θ(n) (все элементы в одной цепочке);
— Ключи и значения могут быть любых типов, в том числе и null. Для хранения примитивных типов используются соответствующие классы-оберки;
— Не синхронизирован.
Ссылки
Инструменты для замеров — memory-measurer и Guava (Google Core Libraries).
Подробно про HashMap в Java
HashMap в Java – это реализация структуры данных хэш-таблицы (пары ключ-значение, словарь) интерфейса Map, являющейся частью структуры Java Collections.
Реализации HashMap в Java Collections Framework
HashMap имеет следующие особенности:
Давайте пройдемся по этому руководству, чтобы изучить их более подробно.
HashMap против LinkedHashMap и TreeMap
HashMap не имеет гарантий упорядочивания и работает быстрее, чем TreeMap (постоянное время по сравнению с временем журнала для большинства операций)
LinkedHashMap обеспечивает итерацию с упорядоченной вставкой и работает почти так же быстро, как HashMap.
TreeMap обеспечивает итерацию по порядку значений. TreeMap можно использовать для сортировки HashMap или LinkedHashMap
Объявление HashMap
В результате иерархии классов вы можете объявить HashMap следующими способами:
Создание и инициализация
Предоставьте фабричный метод Map.of или Map.ofEntries, начиная с Java 9, в конструктор HashMap (Map) для создания и инициализации HashMap в одной строке во время создания.
Вы также можете инициализировать HashMap после времени создания, используя put, Java 8+ putIfAbsent, putAll.
Итерация HashMap
Вы можете перебирать пары ключ-значение HashMap, используя Java 8+ forEach (BiConsumer).
Итерировать по HashMap keySet() или values() с Java 8+ forEach(Consumer).
Получение и фильтрация
Используйте entrySet(), keySet(), values(), чтобы получить набор записей сопоставления ключ-значение, набор ключей и набор значений соответственно.
Получить значение по указанному ключу с помощью get(key).
Фильтрация ключей или значений HashMap с помощью Java 8+ Stream API.
Добавление, обновление и удаление
HashMap предоставляет методы containsKey (ключ), containsValue (значение), put (ключ, значение), replace (ключ, значение) и remove (ключ), чтобы проверить, содержит ли HashMap указанный ключ или значение, чтобы добавить новый ключ. пара значений, обновить значение по ключу, удалить запись по ключу соответственно.
Сравнение объектов в HashMap
Внутренне основные операции HashMap, такие как containsKey, containsValue, put, putIfAbsent, replace и remove, работают на основе сравнения объектов элементов, которые зависят от их равенства и реализации hashCode.
В следующем примере ожидаемые результаты не достигаются из-за отсутствия реализации equals и hashCode для определенных пользователем объектов.
Вы можете решить указанную выше проблему, переопределив equals и hashCode, как показано в примере ниже.
Сортировка HashMap
В Java нет прямого API для сортировки HashMap. Однако вы можете сделать это через TreeMap, TreeSet и ArrayList вместе с Comparable и Comparator.
В следующем примере используются статические методы comparingByKey (Comparator) и comparingByValue (Comparator) для Map.Entry для сортировки ArrayList по ключам и по значениям соответственно. Этот ArrayList создается и инициализируется из entrySet() HashMap.
@Test
public void sortByKeysAndByValues_WithArrayListAndComparator() <
Map.Entry e1 = Map.entry(«k1», 1);
Map.Entry e2 = Map.entry(«k2», 20);
Map.Entry e3 = Map.entry(«k3», 3);
Map map = new HashMap<>(Map.ofEntries(e3, e1, e2));
List > arrayList1 = new ArrayList<>(map.entrySet());
arrayList1.sort(comparingByKey(Comparator.naturalOrder()));
assertThat(arrayList1).containsExactly(e1, e2, e3);
List > arrayList2 = new ArrayList<>(map.entrySet());
arrayList2.sort(comparingByValue(Comparator.reverseOrder()));
assertThat(arrayList2).containsExactly(e2, e3, e1);
>
Ниже представлен полный пример исходного кода.
import static java.util.Map.Entry.comparingByKey;
import static java.util.Map.Entry.comparingByValue;
import static org.assertj.core.api.Assertions.assertThat;
public class HashMapTest <
@Test
public void declare() <
Map map1 = new HashMap<>();
assertThat(map1).isInstanceOf(HashMap.class);
HashMap map2 = new HashMap<>();
>
@Test
public void initInOneLineWithFactoryMethods() <
// create and initialize a HashMap from Java 9+ Map.of
Map map1 = new HashMap<>((Map.of(«k1», 1, «k3», 2, «k2», 3)));
assertThat(map1).hasSize(3);
// create and initialize a HashMap from Java 9+ Map.ofEntries
Map map2 = new HashMap<>(Map.ofEntries(Map.entry(«k4», 4), Map.entry(«k5», 5)));
assertThat(map2).hasSize(2);
>
@Test
public void initializeWithPutIfAbsent() <
// Create a new HashMap
Map map = new HashMap<>();
// Add elements to HashMap
map.putIfAbsent(«k1», 1);
map.putIfAbsent(«k2», 2);
map.putIfAbsent(«k3», 3);
// Can add null key and value
map.putIfAbsent(null, 4);
map.putIfAbsent(«k4», null);
// Duplicate key will be ignored
map.putIfAbsent(«k1», 10);
assertThat(map).hasSize(5);
// The output ordering will be vary as HashMap is not reserved the insertion order
System.out.println(map);
>
@Test
public void retrieve() <
Map hashMap = new HashMap<>(Map.of(«k1», 1, «k2», 2));
Set > entrySet = hashMap.entrySet();
assertThat(entrySet).contains(Map.entry(«k1», 1), Map.entry(«k2», 2));
Set keySet = hashMap.keySet();
assertThat(keySet).contains(«k1», «k2»);
Collection values = hashMap.values();
assertThat(values).contains(1, 2);
>
@Test
public void getValueByKey() <
Map map = new HashMap<>(Map.of(«k1», 1, «k2», 2));
int value = map.get(«k1»);
@Test
public void containsPutReplaceRemove() <
Map map = new HashMap<>(Map.of(«k1», 1, «k2», 2));
boolean containedKey = map.containsKey(«k1»);
assertThat(containedKey).isTrue();
boolean containedValue = map.containsValue(2);
assertThat(containedValue).isTrue();
map.put(«k3», 3);
assertThat(map).hasSize(3);
map.replace(«k1», 10);
assertThat(map).contains(Map.entry(«k1», 10), Map.entry(«k2», 2), Map.entry(«k3», 3));
map.remove(«k3»);
assertThat(map).contains(Map.entry(«k1», 10), Map.entry(«k2», 2));
>
@Test
public void objectsComparingProblem() <
Map hashMap = new HashMap<>();
hashMap.put(new Category(1, «c1»), new Book(1, «b1»));
boolean containedKey = hashMap.containsKey(new Category(1, «c1»));
assertThat(containedKey).isFalse();
boolean containedValue = hashMap.containsValue(new Book(1, «b1»));
assertThat(containedValue).isFalse();
hashMap.put(new Category(1, «c1»), new Book(1, «b1»));
assertThat(hashMap).hasSize(2);
Book previousValue = hashMap.replace(new Category(1, «c1»), new Book(2, «b1»));
assertThat(previousValue).isNull();
hashMap.remove(new Category(1, «c1»));
assertThat(hashMap).hasSize(2);
>
static class Category <
int id;
String name;
Category(int id, String name) <
this.id = id;
this.name = name;
>
>
static class Book <
int id;
String title;
Book(int id, String title) <
this.id = id;
this.title = title;
>
>
@Test
public void objectsComparingFixed() <
Map hashMap = new HashMap<>();
hashMap.put(new CategoryFixed(1, «c1»), new BookFixed(1, «b1»));
boolean containedKey = hashMap.containsKey(new CategoryFixed(1, «c1»));
assertThat(containedKey).isTrue();
boolean containedValue = hashMap.containsValue(new BookFixed(1, «b1»));
assertThat(containedValue).isTrue();
hashMap.put(new CategoryFixed(1, «c1»), new BookFixed(1, «b1»));
assertThat(hashMap).hasSize(1);
BookFixed previousValue = hashMap.replace(new CategoryFixed(1, «c1»), new BookFixed(2, «b1»));
assertThat(previousValue).isNotNull();
hashMap.remove(new CategoryFixed(1, «c1»));
assertThat(hashMap).hasSize(0);
>
static class CategoryFixed <
int id;
String name;
CategoryFixed(int id, String name) <
this.id = id;
this.name = name;
>
@Override
public int hashCode() <
return Objects.hash(id, name);
>
>
static class BookFixed <
int id;
String title;
BookFixed(int id, String title) <
this.id = id;
this.title = title;
>
@Override
public int hashCode() <
return Objects.hash(id, title);
>
>
@Test
public void sortByKeysAndByValues_WithArrayListAndComparator() <
Map.Entry e1 = Map.entry(«k1», 1);
Map.Entry e2 = Map.entry(«k2», 20);
Map.Entry e3 = Map.entry(«k3», 3);
Map map = new HashMap<>(Map.ofEntries(e3, e1, e2));
List > arrayList1 = new ArrayList<>(map.entrySet());
arrayList1.sort(comparingByKey(Comparator.naturalOrder()));
assertThat(arrayList1).containsExactly(e1, e2, e3);
List > arrayList2 = new ArrayList<>(map.entrySet());
arrayList2.sort(comparingByValue(Comparator.reverseOrder()));
assertThat(arrayList2).containsExactly(e2, e3, e1);
>
>
Средняя оценка / 5. Количество голосов:
Или поделись статьей
Видим, что вы не нашли ответ на свой вопрос.
Что такое HashMap
Почему я выбрал эту тему? Ее нужно знать обязательно если Вы пришли на собеседование. Не знаете = не готовы!
Ниже я перечислил наиболее популярные вопросы по этой теме. Для тех кому лень читать – можно посмотреть видос.
Расскажите про устройство HashMap?
Во-первых что такое HashMap? HashMap – это ассоциативный массив. Если вкратце, то ассоциативный массив – это структура данных, которая хранит пары ключ-значения.
Чтобы было проще понять что это такое, можно представлять HashMap как пронумерованные корзинки, в которых хранятся какие-то данные. При добавлении нового объекта в HashMap, мы помимо самого объекта передаем еще и ключ, по которому в дальнейшем, его можно будет отыскать.

Как по ключу можно определить положение искомого объекта? Для этого нам нужно знать hashCode ключа. Где же его взять? Все очень просто, если понимать, что в качестве ключа, может выступать любой объект в java. Все знают что класс Object реализует метод hashCode(), это означает что он будет унаследован или переопределен самим “ключом”. Т.к. все в java наследуются от класса Object. Теперь понятно откуда у ключа берется hashCode!
После того как в hashMap, был передан ключ + сохраняемый объект, специальная hash-функция вычисляет то в какую корзину отнести наши данные.
Как вы понимаете, никаких корзинок в HashMap-е нет. Вместо них есть массив, который хранит ссылки на связанные списки в которых хранятся наши данные. Каждому элементу массива соответствует один список.
Какое начальное количество корзин в HashMap?
Данный вопрос мне ни разу не задавали я его нашел на хабре. Ответ – 16. Но как и с ArrayList-ом в конструкторе можно задать другое количество.
Что такое коллизия? Способ решения коллизий.
Этот вопрос так же часто встречается. Коллизия это когда два разных объекта попадают в одну корзинку(связанный список). Причиной этому служит то, что они имеют одинаковый hashcode. Для более эффективной работы с HashMap, hashcode не должен повторяться для не эквивалентных объектов.
Как я уже упомянул выше, все данные хранятся в списках. Почему так? Почему не хранить всего один объект? Ответ прост. Все потому, что это способ разрешения коллизий. Как происходит добавление? Смотр код 1
Первое – мы выясняем то какая корзина соответствует ключу объекта. Затем проверяем, есть ли в ней уже какие-то объекты, если нет – то добавляем текущий. Если да, то это случилась коллизия.
Тогда мы начинаем сравнивать ключ и hashcode текущего объекта и тех которые внутри (если конечно их там несколько).
Сначала проверяем равны ли hashcode ключей.
Если да, то сравниваем их ключ методом equals.
Если equals возвращает true, значит ключи совпадают по “значению” и hashcode – производится замена, новый объект заменяет тот который уже там находится под тем же ключом,
Если hashcode и “значение” ключа неравны – новый объект добавляется в конец списка.
Как и когда происходит увеличение количества корзин в HashMap?
HashMap имеет поле loadFactor. Оно может быть задано через конструктор. По умолчанию равняется 0.75. Для чего оно нужно? Его произведение на количество корзин дает нам необходимое число объектов, которое нужно добавить, чтобы состоялось удвоение количества корзин. Например, если у нас мапка с 16-ю корзинами, а loadFactor равняется 0.75, то расширение произойдет когда мы добавим 16 * 0.75 = 12 объектов. Мапка увеличивается вдвое.
Какая оценка временной сложности операций с HashMap? Гарантирует ли HashMap указанную сложность выборки элемента?
Рассмотрим сначала случай в котором нет коллизий. В этом случае добавление, удаление и поиск объектов по ключу выполняется за константное время O(1). Разумеется, не учитывается случай с расширением количества элементов. Вообще говоря, когда Вы работаете с HashMap, лучше сразу указать в конструкторе, сколько корзин нужно для работы и хорошо если оно равняется числу уникальных объектов с которыми Вы будите работать. В таком случае не придется тратить время и ресурсы на создание нового HashMap с удвоенным количеством bucket-ов. Почему такая хорошая производительность? Тут все просто. Повторюсь что коллизий нет – в таком случае нет никакой зависимости от других элементов из этой мапки. Удаление, Вставка, Поиск выполняются примерно по одной схеме. Берется HashCode ключа, вычисляется корзинка, и производится удаление, вставка или поиск. Все! Нигде не встречаются другие объекты. Но это лишь в том случае, если нет коллизий.
Теперь поговорим о случае когда коллизии все-таки присутствуют. Теоретически работая с HashMap в котором могут присутствовать коллизии, мы получаем временную сложность O(log(n)) на операции вставки, сохранения и удаления. В самом худшем случае, когда все объекты возвращают один и тот же HashCode, а значит попадают в одну корзину. На самом деле это связный список и тогда временная сложность как у LinkedList O(n).
Вопросы на собеседовании 2. HashMap.
Предположим, что в мапку, созданную данным способом (Код 1), нужно добавить 1 миллион объектов. Что тут плохого? Давайте подумаем.
Как обычно, видос для ленивых:
Что произойдет, когда выполнится данный код? Создастся массив на 16 элементов с loadFactor = 0.75. Получаем, что после добавления 12 элементов произойдет удвоение длинны массива. Напомню, что это число получается перемножив loadFactor и текущее количество корзинок или длину массива.
Как-бы, что тут плохого, ну удвоилось количество корзинок, можно добавлять дальше. Нет! Все работает не так. После того как состоялось удвоение, все элементы, которые уже были добавлены, будут перераспределены по корзинкам заново с учетом их нового количества.
Добавили 12. Потом эти 12 снова добавили, после увеличения массива. Грубо говоря добавили всего 24. Что получаем? В следующий раз, удвоение числа корзинок произойдет после добавления 24-го элемента, а в мапке уже 12.
Добавили еще 12 + снова перераспределение и еще 24, получаем 36.
Представляете сколько нужно будет выполнить работы, пока мы не закончим добавлять все 1 миллион объектов.
Когда я обдумывал данный пример, предполагал, что коллизий нет совсем. Боюсь представить, что было бы, если бы они все таки присутствовали.
В каком случае может быть потерян элемент в HashMap?
После добавления элемента в HashMap, у объекта, который выступает в качестве ключа, изменяют одно поле, которое участвует в вычислении хеш-кода. В результате, при попытке найти данный элемент по исходному ключу, будет происходить обращение к правильной корзине, а вот equals (ведь equals и hashCode должны работать с одним и тем же набором полей) уже не найдет указанный ключ в списке элементов. Тем не менее, даже если equals реализован таким образом, что изменение данного поля объекта не влияет на результат, то после увеличения размера корзин и пересчета хеш-кодов элементов, указанный элемент, с измененным значением поля, с большой долей вероятности попадет совсем в другую корзину и тогда он уже совсем потеряется.
Related Posts
Шаг 1 Первым делом Вы должны установить себе git на компьютер. Посмотрите для этого небольшое…
В этой статье я попробую простым языком и кратко рассказать, что такое класс в общем…
В этой статье я поговорю частично о технологиях без которых, никуда Вас не возьмут и…
На этот раз я расскажу о состоянии дел связанных с высшим образованием при устройстве на…



