Содержание урока
Алгоритмы оптического распознавания
Алгоритмы оптического распознавания
Если исходный документ имеет типографское качество (достаточно крупный шрифт, отсутствие плохо напечатанных символов или исправлений), то распознавание осуществляется методом сравнения с шаблонами символов. Сначала растровое изображение страницы разделяется на изображения отдельных символов. Затем каждый из них последовательно накладывается на шаблоны символов, имеющихся в памяти системы, и выбирается шаблон с наименьшим количеством точек, отличных от входного изображения.
При распознавании документов с низким качеством печати (машинописный текст, факс и т. д.) используется метод распознавания символов по наличию в них определенных структурных элементов (отрезков, колец, дуг и др.). Любой символ можно описать через набор параметров, определяющих взаимное расположение его элементов. Например, буква Н и буква И состоят из трех отрезков, два из которых расположены параллельно друг другу, а третий соединяет эти отрезки. Различие между буквами состоит в величине углов, которые образует третий отрезок с двумя другими. При распознавании структурным методом в искаженном символьном изображении выделяются характерные детали и сравниваются со структурными шаблонами символов. В результате выбирается тот символ, для которого совокупность всех структурных элементов и их расположение больше всего соответствует распознаваемому символу.
Наиболее распространенные системы оптического распознавания символов используют как растровый, так и структурный метод распознавания. Кроме того, эти системы являются «обучающимися» (для каждого конкретного документа они создают соответствующий набор шаблонов символов), и поэтому скорость и качество распознавания многостраничного документа постепенно возрастают.
Следующая страница  Оптическое распознавание документов
Оптическое распознавание документов
Cкачать материалы урока
Методы распознавания текстов
Несмотря на то, что в настоящее время большинство документов составляется на компьютерах, задача создания полностью электронного документооборота ещё далека до полной реализации. Как правило, существующие системы охватывают деятельность отдельных организаций, а обмен данными между организациями осуществляется с помощью традиционных бумажных документов.
Задача перевода информации с бумажных на электронные носители актуальна не только в рамках потребностей, возникающих в системах документооборота. Современные информационные технологии позволяют нам существенно упростить доступ к информационным ресурсам, накопленным человечеством, при условии, что они будут переведены в электронный вид.
Наиболее простым и быстрым является сканирование документов с помощью сканеров. Результат работы является цифровое изображение документа – графический файл. Более предпочтительным, по сравнению с графическим, является текстовое представление информации. Этот вариант позволяет существенно сократить затраты на хранение и передачу информации, а также позволяет реализовать все возможные сценарии использования и анализа электронных документов. Поэтому наибольший интерес с практической точки зрения представляет именно перевод бумажных носителей в текстовый электронный документ.
На вход системы распознавания поступает растровое изображение страницы документа. Для работы алгоритмов распознавания желательно, чтобы поступающее на вход изображение было как можно более высокого качества. Если изображение зашумлено, нерезко, имеет низкую контрастность, то это усложнит задачу алгоритмов распознавания.
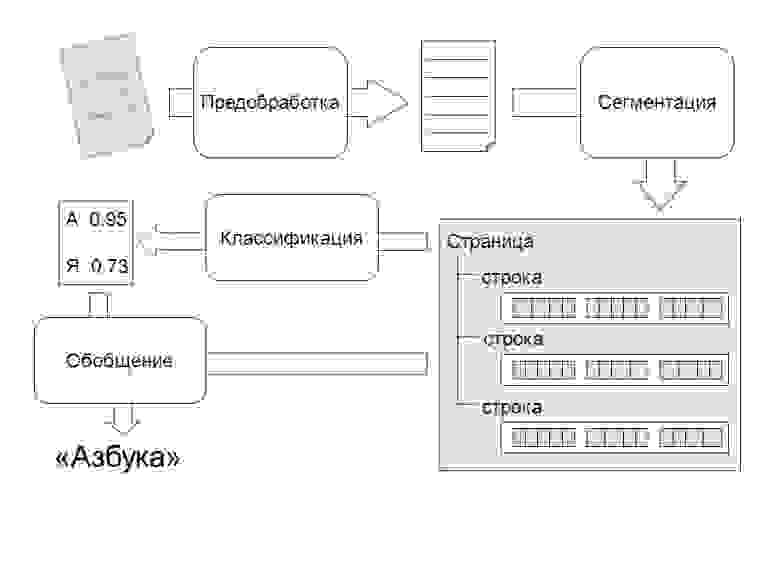
Поэтому перед обработкой изображения алгоритмами распознавания проводится его предварительная обработка, направленная на улучшение качества изображения. Она включает фильтрацию изображения от шумов, повышение резкости и контрастности изображения, выравнивание и преобразование в используемый системой формат (в нашем случае 8-битное изображение в градациях серого).
Подготовленное изображение попадает на вход модуля сегментации. Задачей этого модуля является выявление структурных единиц текста – строк, слов и символов. Выделение фрагментов высоких уровней, таких как строки и слова, может быть осуществлено на основе анализа промежутков между тёмными областями.
К сожалению, такой подход не может быть применён для выделения отдельных букв, поскольку, в силу особенностей начертания или искажений, изображения соседних букв могут объединяться в одну компоненту связанности (рис. 1) или наоборот — изображение одной буквы может распадаться на отдельные компоненты связанности (рис. 2). Во многих случаях для решения задачи сегментации на уровне букв используются сложные эвристические алгоритмы.

Рисунок 1. Объединение нескольких букв в одну компоненту связанности.
Рисунок 2. Распадение изображений букв на несвязанные компоненты вследствие низкого качества сканирования.
Полагаем, что для принятия окончательного решения о прохождении границы букв на таком раннем этапе обработки, системе распознавания недостаточно информации. Поэтому задачей модуля сегментации на уровне букв в разработанном алгоритме является нахождение возможных границ символов внутри буквы, а окончательное решение о разбиении слова принимается на последнем этапе обработки, с учётом идентификации отдельных фрагментов изображения как букв. Дополнительным преимуществом такого подхода является возможность работы с начертаниями букв, состоящих из нескольких компонент связанности без специальной обработки таких случаев.
Результатом работы модуля сегментации является дерево сегментации – структура данных, организация которой отражает структуру текста на странице. Самому верхнему уровню соответствует объект страница. Он содержит массив объектов, описывающих строки. Каждая строка в свою очередь включает набор объектов слов. Слова являются листьями этого дерева. Информация о возможных местах разделения слова на буквы храниться в слове, однако отдельные объекты для букв не выделяются. В каждом объекте дерева хранится информация об области, занимаемой соответствующим объектом на изображении. Данная структура легко может быть расширена для поддержки других уровней разбиения, например колонок, таблиц.
Выявленные фрагменты изображения подаются на вход классификатора, выходом которого является вектор возможности принадлежности изображения к классу той или иной буквы. В разработанном алгоритме используется классификатор составной архитектуры, организованный в виде дерева, листьями которого являются простые классификаторы, а внутренние узлы соответствуют операциям комбинирования результатов низлежащих уровней (рис. 3).
Рисунок 3. Архитектура классификатора.
Работа простого классификатора осуществляется в два шага (рис. 4). Сначала по исходному изображению вычисляются признаки. Значение каждого признака является функцией от яркостей некоторого подмножества пикселей изображения. В результате получается вектор значений признаков, который поступает на вход нейронной сети. Каждый выход сети соответствует одной из букв алфавита, а получаемое на выходе значение рассматривается как уровень принадлежности буквы нечёткому множеству.
Рисунок 4. Простой классификатор.
Задачей алгоритма комбинирования является обобщение информации, поступающей в виде входных нечётких множеств и вычисление на их основе выходного нечёткого подмножества множества распознаваемых символов. В качестве алгоритмов комбинирования используются операции теории нечётких множеств (такие как t-нормы и s-нормы), выбор наиболее уверенного эксперта.
Результатом работы классификатора является нечёткое множество, полученное в результате комбинирования на самом верхнем уровне.
На последнем этапе принимается решение о наиболее правдоподобном варианте прочтения слова. Для этого используются уровни возможности прочтения отдельных букв, межбуквенной сегментации и частоты сочетаний букв в русском языке.
Для оценки эффективности разработанного алгоритма было проведено сравнение с двумя существующими системами OCR. Это бесплатная open-source система CuneiForm v12 и коммерческая система ABBYY FineReader 10 Professional Edition.
К сожалению, для оценки эффективности работы систем распознавания, обычно используются наборы символов, подготовленных иностранными специалистами, либо наборы, собранные авторами и не опубликованные в открытом доступе. Так, например, оценивая эффективность работы алгоритмов ABBYY FineReader автор использовал базы данных CEDAR, NIST, CENPARMI а также сканированные анкеты ЕГЭ. Поскольку данные базы содержат английские и/или рукописные символы, они не могут быть использованы для оценки эффективности выполнения НИР по теме «разработка алгоритма распознавания печатных кириллических символов».
Сравнение производилось на образцах с разрешением 96 dpi и 180 dpi. В сравнении участвовал текст, состоящий из 300 слов, набранных шрифтами Arial 14pt и Times New Roman 14pt. Текст разрешением 96 dpi был создан на компьютере непосредственно в виде графического файла. Для теста с разрешением 180 dpi текст был распечатан на лазерном принтере, а затем сканирован с указанным разрешением. Фрагмент использованного текста приведен на рис. 5.
Рисунок 5. Фрагмент текста, использованного для тестирования систем распознавания.
Результаты сравнения для 96 dpi представлены в таблице 1.

Таблица 1. Результаты распознавания текста разрешением 96 dpi.
Результаты сравнения для текста с разрешением 180 dpi представлены в таблице 2.

Таблица 2. Результаты распознавания текста разрешением 180 dpi.
Лучшие результаты распознавания для 96 dpi можно объяснить тем, что текущая конфигурация системы была обучена на шрифтах Times New Roman 14pt и Arial 14pt при разрешающей способности 96 dpi. Можно ожидать улучшения результатов для этого текста при добавлении в систему простых классификаторов, обученных распознавать шрифты такого размера.
Суммарно, из 1200 слов было распознано:
• разработанным алгоритмом: 1180 слов (98,33%);
• системой с открытыми кодами CuneiForm: 597 слов (49,75%);
• коммерческой системой ABBYY FineReader: 1200 слов (100%).
Стоит отметить, что при низком разрешении, наличии большого числа шума Cuneiform не справляется с распознаванием текста, в то время как предложенный алгоритм распознает текст в таком качестве.
В целом, можно заключить, что хотя предложенный алгоритм уступает лучшему в данном классе коммерческому продукту фирмы Abbyy, он способен распознавать текст худшего качества, чем способна распознать система c открытыми исходными кодами CuneiForm.
Список использованной литературы.
Квасников В.П., Дзюбаненко А.В. Улучшение визуального качества цифрового изображения путем поэлементного преобразования // Авиационно-космическая техника и технология 2009 г., 8, стр. 200-204
Арлазаров В.Л., Куратов П.А., Славин О.А. Распознавание строк печатных текстов // Сб. трудов ИСА РАН «Методы и средства работы с документами». — М.: Эдиториал УРСС, 2000. — С. 31-51.
Проект СПбГУ Открытый код: распознавание текстовых изображений [Электронный ресурс] — Режим доступа: ocr.apmath.spbu.ru
Багрова И. А., Грицай А. А., Сорокин С. В., Пономарев С. А., Сытник Д. А. Выбор признаков для распознавания печатных кириллических символов // Вестник Тверского Государственного Университета 2010 г., 28, стр. 59-73
The concept of a linguistic variable and its application to approximate reasoning, Information Sciences, 8, 199-249; 9, 43-80.
Melin P., Urias J., Solano D., Soto M., Lopez M., Castillo O., Voice Recognition with Neural Networks, Type-2 Fuzzy Logic and Genetic Algorithms. Engineering Letters, 13:2, 2006.
Панфилов С. А. Методы и программный комплекс моделирования алгоритмов управления нелинейными динамическими системами на основе мягких вычислений. Диссертация на соискание ученой степени кандидата технических наук. Тверь, 2005.
Презентация по информатике «Системы оптического распознавания документов»

![]()
Описание разработки
При coздании электронных библиотек и архивов путем перевода книг и документов в цифровой компьютерный формат, при переходе предприятий от бумажного к электронному документообороту, при необходимости отредактировать полученный по факсу документ используются системы оптического распознавания символов.

Оптическое распознавание символов (англ. optical character recognition, OCR) — механический или электронный перевод изображений рукописного, машинописного или печатного текста в последовательность кодов, использующихся для представления в текстовом редакторе.
С помощью сканера несложно получить изображение страницы текста в графическом файле.
Содержимое разработки

Системы оптического распознавания документов

Системы оптического распознавания символов
При coздании электронных библиотек и архивов путем перевода книг и документов в цифровой компьютерный формат, при переходе предприятий от бумажного к электронному документообороту, при необходимости отредактировать полученный по факсу документ используются системы оптического распознавания символов.

Оптическое распознавание символов
Оптическое распознавание символов (англ. optical character recognition, OCR) — механический или электронный перевод изображений рукописного, машинописного или печатного текста в последовательность кодов, использующихся для представления в текстовом редакторе.
С помощью сканера несложно получить изображение страницы текста в графическом файле.

Однако для получения документа в формате текстового файла необходимо провести распознавание текста , т. е. преобразовать элементы графического изображения в последовательности текстовых символов.
Хорошее качество текста Растровый метод распознавания текста
Хорошее качество текста Растровый метод распознавания текста
Например, распознаваемый символ «Б» накладывается на растровые шаблоны символов (А, Б, В и т. д.)

Плохое качество текста Структурный метод распознавания
Плохое качество текста Структурный метод распознавания
При pacпознавании структурным методом в искаженном символьном изображении выделяются характерные детали и сравниваются со структурными шаблонами символов.
В результате выбирается тот символ, для которого совокупность всех структурных элементов и их расположение больше всего coответствуют распознаваемому символу.
Например, распознаваемый символ «Б» накладывается на векторные шаблоны символов (А, Б, В и т. д.)

Системы оптического распознавания форм
Сложность состоит в том, что необходимо распознавать символы, написанные от руки, а они довольно сильно различаются у разных людей. Кроме того, система должна определить, к какому полю относится распознаваемый текст.

Системы оптического распознавания форм
Системы оптического распознавания форм
Системы распознавания рукописного текста
С появлением первого карманного компьютера Newton фирмы Apple в 1990 году начали создаваться системы распознавания рукописного текста. Такие системы преобразуют текст, написанный на экране карманного компьютера специальной ручкой, в текстовый компьютерный документ.
Системы распознавания рукописного текста

Программы оптического распознавания текста
Программы оптического распознавания документов
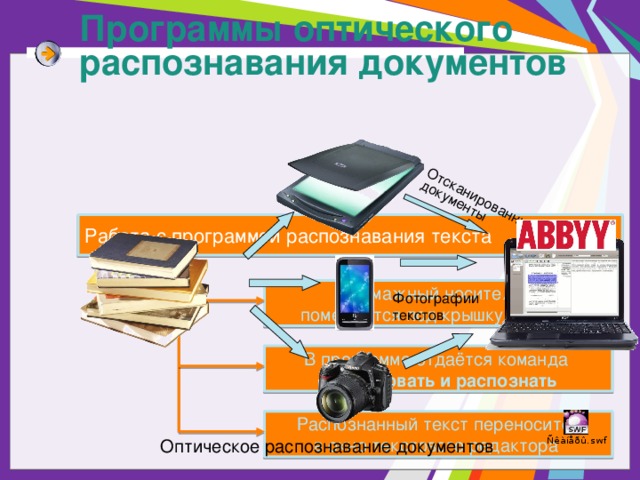
Работа с программой распознавания текста
помещается под крышку сканера
В программе отдаётся команда
Сканировать и распознать
Распознанный текст переносится
в окно текстового редактора
Оптическое распознавание документов

Принцип работы сканера
Принцип работы сканера состоит в следующем: в результате преобразования света получается электрический сигнал, содержащий информацию об активности цвета в исходной точке сканируемого изображения. После оцифровки аналогового сигнала в АЦП цифровой сигнал через аппаратный интерфейс сканера идет в компьютер, где его получает и анализирует программа для работы со сканером. После окончания одного такого цикла (освещение оригинала — получение сигнала — преобразование сигнала — получение его программой) источник света и приемник светового отражения перемещается относительно оригинала.

Программы распознавания текста
Современная OCR должна уметь многое: распознавать тексты, набранные не только определенными шрифтами, но и самыми экзотическими, вплоть до рукописных. Уметь корректно работать с текстами, содержащими слова на нескольких языках, корректно распознавать таблицы. И самое главное — корректно распознавать не только четко набранные тексты, но и такие, качество которых, мягко говоря, далеко от идеала. Например, текст с пожелтевшей газетной вырезки или третьей машинописной копии. Само собой, распознать текст — это еще полдела. Не менее важно обеспечить возможность сохранения результата в файле популярного текстового (или табличного) формата — скажем, формата Microsoft Word.

Процесс обработки FineReader
Методы распознавания текста
Немного теории
Тема распознавания текста попадает под раздел распознавания образов. И для начала коротко о самом распознавании образов.
Распознавание образов или теория распознавания образов это раздел информатики и смежных дисциплин, развивающий основы и методы классификации и идентификации предметов, явлений, процессов, сигналов, ситуаций и т. п. объектов, которые характеризуются конечным набором некоторых свойств и признаков. Данное определение нам дает Wikipedia.
Итак, моя тема — это распознавание текста на графических изображениях и сейчас говорить о важности данного подраздела не приходиться. Всем давно известно, что существуют миллионы старых книг, которые хранятся в хранилищах строгого режима, доступ к которым имеет только специализированный персонал. Использование этих книг запрещено по причине их ветшалости и дряхлости, так как возможно, что они могут рассыпаться прямо в руках читателя, но знания которые они хранят, представляют, несомненно, большой клад для человечества и поэтому оцифровка этих книг столь важна. Именно этим в частности занимаются специалисты в области обработки данных.
Теперь о самой работе. Было написано приложение, способное распознавать текст при использовании изображений высокого либо среднего качества, со слабым шумом либо без него. Приложение способно распознавать буквы английского алфавита, верхнего и нижнего регистра. Изображение подается для распознавания непосредственно из самого приложения.
Фильтрация и обработка
Сегментация
Непосредственно перед распознаванием изображение нормализуется и приводится до размеров шаблонов, подготовленных заранее.
Далее наступает сам процесс распознавания. Для пользователя имеется два выбора, при помощи метрик и при помощи нейронной сети.
Распознавание
Рассмотрим первый случай — распознавание при помощи метрик.
Метрика – некоторое условное значение функции, определяющее положение объекта в пространстве. Таким образом, если два объекта расположены близко друг от друга, то есть похожи (например, две буквы А написанные разным шрифтом), то метрики для таких объектов будут совпадать или быть предельно похожими. Для распознавания в этом режиме была выбрана метрика Хэмминга.
Метрика Хэмминга – метрика которая показывает, как сильно объекты не похожи между собой.
Данную метрику часто используют при кодировании информации и передаче данных. Например, после сеанса передачи на выходе имеется следующая последовательность бит (1001001), также нам известно, что должна прийти другая последовательность бит (1000101). Мы вычисляем метрику путем сравнения частей последовательности с соответствующими местами из другой последовательности. Таким образом метрика Хэмминга в нашем случае равна 2. Так как объекты отличаются в двух позициях. 2- это степень непохожести, чем больше, тем хуже в нашем случае.
Следовательно, чтобы определить какая буква изображена нужно найти ее метрику со всеми готовыми шаблонами. И тот шаблон, чья метрика окажется наиболее близкой к 0 будет ответом.
Но как показала практика подсчет одной лишь метрики не дает положительного результата, так многие буквы похожи между собой. например «j» «i», что приводит к ошибочному распознаванию.
Тогда было принято решение придумать новые метрики, позволяющие разграничить некоторое множество букв в отдельный класс. В частности, были реализованы метрики (Отражения горизонтального и вертикального, преобладания веса горизонтального и вертикального).
Экспериментом было выяснено, что такие буквы как «H» «I» «i» «O» «o» «X» «x» «l» обладают суперсимметрией (полностью совпадают со своими отражениями и значимые пиксели распределены равномерно по всему изображению), поэтому они были вынесены в отдельный класс, что сокращает перебор всех метрик примерно в 6 раз. Аналогичные действия были проведены в отношении других букв. В среднем уменьшение перебора достигает примерно 3 раза.
Также есть уникальная буква такая как «J», которая находится в своем классе одна, и значит идентифицируются однозначно. Далее, для каждого класса высчитывается метрика Хэмминга, которая на данном этапе дает лучшие показатели чем при прямом применении.
При создании шаблонов использовался шрифт «consolas», поэтому, если распознаваемый текст написан этим шрифтом, распознавание имеет точность порядка 99 процентов. При изменении шрифта, точность падает до 70 процентов.
Второй способ распознавания – при помощи нейронной сети.
Что такое нейронная сеть и в биологическом понимании, и в математическом я рассказывать не буду, так как данного материала полно в интернете и повторять его не хочется. Сказать лишь можно то, что в математическом смысле нейронная сеть — это лишь модель биологического определения.
Существуют также множества разновидностей этих моделей. В своей работе я использовал однослойную сеть Кохонена.
Принцип работы нейронной сети таков, что поучив на входной слой нейронов новое изображение сеть реагирует импульсом того или иного нейрона. Так как все нейроны поименованы значениями букв, следовательно, среагировавший нейрон и несет ответ распознавания. Углубляясь в терминологию сетей можно сказать, что нейрон помимо выхода имеет также множество входов. Данные входы описывают значение пикселя изображения. То есть, если имеется изображение 16х16, входов у сети должно быть 256.
Каждый вход воспринимается с определенным коэффициентом и в результате, по окончанию распознавания на каждом нейроне скапливается определенный заряд, чем заряд будет больше тот нейрон и испустит импульс.
Но что бы коэффициенты входов были правильно настроены необходимо сначала обучить сеть. Этим занимается отдельный модуль обучения. Данный модуль берет очередное изображение из обучающей выборки и скармливает сети. Сеть анализирует все позиции черных пикселей и выравнивает коэффициенты минимизируя ошибку совпадения методом градиента, после чего определенному нейрону сопоставляется данное изображение.
Все коэффициенты выровнены и готовы воспринимать изображения.
Точность распознавания при этом методе достигает 80 процентов. Следует заметить, что точность распознавания зависит от обучающей выборки, как от количества, так и от качества.



