Spring. Для чего нужен cервис-слой?
Во всех гайдах дают такую структуру проекта:

В тех же гайдах глядя в код видно только то, что сервис-слой полностью дублирует DAO. Для чего всё таки нужен этот слой? Как его правильно использовать?


Это общие слова и терминология человека, понимающего досконально или почти досконально структуру и принципы взаимодействия внутри контейнера Спринг. Да и логика очень часто несложная в сервисах — получить данные и иногда трансформировать их для отдачи контроллем. Понятно, встречаются и сложные сервисы, но в подавляющем большинстве это просто получение данных из базы по критериям.
Пользуясь не один год этим фреймворком, тоже часто грешил тем, что выкидывал сервис-слой, делегируя его функционал слою DAO (только как правильно заметил один гуру с одного ресурса, в терминологии Спринга называть этот слой правильно не DAO, а репозиторий — Repository). Было просто и удобно, тем более, что при небольших проектах фактически код в дао и сервисе повторяются. А различия заключаются в том, что @ Repository — наш DAO — это бин-синглтон, и при доступе к нему несколькими потоками, что для MVC — нормальная вещь, может произойти доступ к одним данным из разных потоков. Видимость же @ Service определена видимостью вызывающего @ Controller. Возможно, с определением и терминологией наблюдаются у меня некоторые напряги, да и тонкую настройку компонентов наверняка можно сделать, но общий принцип и назначение переданы.
Русские Блоги
Уровень DAO, уровень сервиса, уровень контроллера, уровень представления в Java

xxx: представляет название компании
Ггг: типичное название проекта
Com.xxx.yyy.dao интерфейс уровня dao
Com.xxx.yyy.dao.impl реализация слоя dao
Com.xxx.yyy.service интерфейс уровня обслуживания
Com.xxx.yyy.service.impl реализация уровня сервиса
Слой DAO:
Уровень обслуживания:
Уровень контроллера:
Слой просмотра:
Проектирование уровня логики обслуживания
Уровень сервиса построен на уровне DAO. После того, как уровень DAO установлен, уровень сервиса может быть установлен. Уровень сервиса находится под уровнем контроллера. Таким образом, уровень сервиса должен вызывать интерфейс уровня DAO и предоставлять интерфейс для Для вызова используется класс уровня контроллера, который находится как раз на среднем уровне. Каждая модель имеет интерфейс службы, и каждый интерфейс инкапсулирует собственный метод бизнес-обработки. Чтобы
Некоторые методы, определенные на уровне DAO, не используются на уровне сервиса, так почему они должны быть определены на уровне DAO? Это определяется нашей определенной логикой спроса. Работа уровня DAO в основном универсальна после абстракции, поэтому мы можем определить соответствующие методы при определении уровня DAO.Преимущество этого заключается в том, что нет необходимости изменять уровень DAO при расширении службы. Улучшение масштабируемости программы.
Многоуровневая архитектура в проекте на Java (Часть 1)
В настоящее время в разработке ПО достаточно часто применяется многоуровневая архитектура или многослойная архитектура (n-tier architecture), в рамках которой компоненты проекта разделяются на уровни (или слои). Классическое приложение с многоуровневой архитектурой, чаще всего, состоит из 3 или 4 уровней, хотя их может быть и больше, учитывая возможность разделения некоторых уровней на подуровни. Одним из примеров многоуровневой архитектуры является предметно-ориентированное проектирование (Domain-driven Design, DDD), где основное внимание сконцентрировано на предметном уровне.
В проектах с многоуровневой архитектурой можно выделить четыре уровня (или слоя):
Направление зависимостей между слоями идёт от слоя представления к слою доступа к данным. В идеальной ситуации каждый слой зависит только от следующего слоя: слой представления зависит от сервисного слоя (например, представление зависит от контроллера), сервисный слой зависит от слоя бизнес-логики (например, контроллер зависит от бизнес-сервиса), а слой бизнес-логики — от слоя доступа к данным (например, бизнес-сервис зависит от репозитория). При этом компоненты бизнес-слоя могут зависеть от других компонентов бизнес-слоя, тогда как в других слоях аналогичные зависимости нежелательны (например, зависимость одного репозитория от другого). Так же нежелательны зависимости в обратном направлении (бизнес-слой не должен зависеть от сервисного слоя) и зависимости между слоями, не являющимися соседними (сервисный слой не должен зависеть от слоя доступа к данным, например).
На практике иногда приходится сталкиваться с примерами, когда бизнес-логика частично или полностью находится в контроллере, а иногда встречаются и вовсе случаи обращения компонентов слоя представления к слою доступа к данным. Несоблюдение разделения кода между слоями непременно приводит к путанице, замедляет процесс разработки и развития проекта и делает процесс поддержки проекта трудоёмким и дорогим.
Допустим, у нас есть код, реализующий бизнес-логику приложения, который находится в контроллере. Что если нам требуется разработать SOAP-сервис, реализующий ту же функциональность? Мы можем скопировать существующий код в SOAP-сервис и внести в него изменения по мере необходимости. Будет ли ли такой подход работать? Да! Вызовет ли такой подход проблемы? Тоже да! В процессе жизненного цикла проекта требования к нему имеют свойство меняться, что ведёт к неизбежным изменениям и в коде. Но при таком подходе нам придётся изменить код и в контроллере, и в SOAP-сервисе, а также внести изменения в их тесты (вы же тестируете свой код?). Но граздо правильнее будет вынести общий код, реализующий бизнес-логику, в компонент слоя бизнес-логики. В этом случае в контроллере и SOAP-сервисе останется код, преобразующий запрос к общему виду, понятному компоненту бизнес-логики.
Очевидным фактом является то, что бизнес-логика — самая важная составляющая вашего проекта. И именно с проработки компонентов слоя бизнес-логики должна начинаться разработка проекта.
К слову сказать, очень хорошей практикой является применение UML, в данном конкретном случае — диаграммы классов. Из собственной практики помню случай, когда я решил для почти готового проекта составить диаграмму классов, результатом чего стал рефакторинг, уменьшивший количество кода примерно на 20%. Составление диаграммы классов на ранних этапах разработки позволяет уменьшить дублирование кода, сделать структуру классов и зависимости между ними более понятными.
В так полюбившейся мне книге Роберта Марина «Чистая архитектура» автор пропагандирует идею независимости (или минимизации зависимости) архитектуры приложения от внешних факторов: фреймворков, баз данных и прочих сторонних зависимостей. Это говорит не об отказе от использования этих зависимостей (вы же не будете разрабатывать собственный механизм трансляции HTTP-вызовов или хранения данных?), а о минимизации их влияния на архитектуру вашего проекта.
Разработка бизнес-логики
Давайте возьмём в качестве примера разработку блокнота, который пользователь может использовать для работы с заметками. Заметьте, я не указал, что это будет онлайн-сервис или настольное приложение. Для начала определимся с набором типов (классов и интерфейсов), которые нам понадобятся для нашего проекта. Класс-сущность, описывающий заметку — Note, компонент бизнес-логики, реализующий работу с заметками — NoteService, ещё нам потребуется компонент слоя доступа к данным — NoteRepository. Простая реализация NoteService — SimpleNoteService, использует NoteRepository для доступа к источнику данных. Диаграмма классов, описывающая текущую архитектуру, будет достаточно простая:
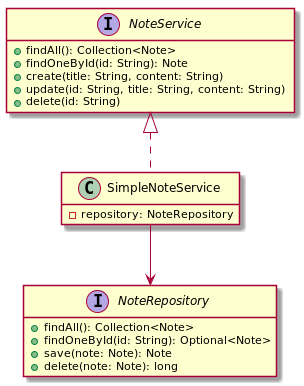
Теперь можно описать эти типы в коде, написать тесты для SimpleNoteService и реализовать этот класс.
Пишем Java веб-приложение на современном стеке. С нуля до микросервисной архитектуры. Часть 1
Авторизуйтесь
Пишем Java веб-приложение на современном стеке. С нуля до микросервисной архитектуры. Часть 1
На сегодняшний день в мире разработки на Java существует огромное количество библиотек и технологий, в которых новичку очень легко запутаться. В этом руководстве я постараюсь простым языком описать все шаги, возникающие проблемы и пути их решения. Начинать будем с самого простого и постепенно наращивать функциональность.
Spring Boot
Spring Boot — один из самых популярных универсальных фреймворков для построения веб-приложений на Java. Создадим в среде разработки Gradle Project. Для облегчения работы воспользуемся сайтом https://start.spring.io, который поможет сформировать build.gradle.
Для начала нам необходимо выбрать следующие зависимости:
В результате генерации build.gradle должно получиться что-то похожее:
Тот же результат можно получить и в самой IntelliJ Idea: File → New → Project → Spring Initializr.
Опишем самый простой контроллер, чтобы удостовериться, что проект работает:
Результат работы можно проверить в браузере перейдя по адресу http://localhost:8080/hello?name=World или с помощью консольной утилиты curl:
Наш сервис запускается и работает, пора переходить к следующему шагу.
Представим, что нам требуется разработать некий сервис для интернет-магазина по продаже книг. Это будет rest-сервис, который будет позволять добавлять, редактировать, получать описание книги. Хранить данные будем в БД Postgres.
Docker
Для хранения данных нам потребуется база данных. Проще всего запустить инстанс БД с помощью Docker. Docker позволяет запускать приложение в изолированной среде выполнения — контейнере. Поддерживается всеми операционными системами.
Выкачиваем образ БД и запускаем контейнер:
Lombok
Создадим data-класс «книга». Он будет иметь несколько полей, которые должны иметь getters, конструктор и должна быть неизменяемой (immutable). Среда разработки позволяет автоматически генерировать конструктор и методы доступа к полям, но чтобы уменьшить количество однотипного кода, будем использовать Lombok.
После сборки проекта можно посмотреть, как выглядит класс после компиляции. Воспользуемся стандартной утилитой, входящей в состав JDK:
Lombok очень упрощает читаемость подобного рода классов и очень широко используется в современной разработке.
Spring Data JPA
Для работы с БД нам потребуется Spring Data JPA, который мы уже добавили в зависимости проекта. Дальше нам нужно описать классы Entity и Repository. Первый соответствует таблице в БД, второй необходим для загрузки и сохранения записей в эту таблицу.
Класс Repository будет выглядеть совсем просто — достаточно объявить интерфейс и наследоваться от CrudRepository:
Никакой реализации не требуется. Spring всё сделает за нас. В данном случае мы сразу получим функциональность CRUD — create, read, update, delete. Функционал можно наращивать — чуть позже мы это увидим. Мы описали DAO-слой.
Теперь нам нужен некий сервис, который будет иметь примерно следующий интерфейс:
Это так называемый сервисный слой. Реализуем этот интерфейс:
При создании объекта класса Spring опять всё возьмёт на себя — сам создаст объект BookRepository и передаст его в конструктор. Имея объект репозитория мы можем выполнять операции с БД:
MapStruct
Смотря на код может показаться, что класс Book не нужен, и достаточно только BookEntity, но это не так. Book — это класс сервисного слоя, а BookEntity — DAO. В нашем простом случае они действительно повторяют друг друга, но бывают и более сложные случаи, когда сервисный слой оперирует с несколькими таблицами и соответственно DAO-объектами.
Если присмотреться, то и тут мы видим однотипный код, когда мы перекладываем данные из BookEntity в Book и обратно. Чтобы упростить себе жизнь и сделать код более читаемым, воспользуемся библиотекой MapStruct. Это mapper, который за нас будет выполнять перекладывание данных из одного объекта в другой и обратно. Для этого добавим зависимости в build.gradle:
Создадим mapper, для этого необходимо объявить интерфейс, в котором опишем методы для конвертации из BookEntity в Book и обратно:
После сборки проекта, в каталоге build/generated/sources/annotationProcessor появится сгенерированный исходный код mapper, избавив нас от необходимости писать однотипные десятки строк кода:
Воспользуемся мэппером и перепишем DefaultBookService. Для этого нам достаточно добавить добавить final-поле BookMapper, которое Lombok автоматически подставит в аргумент конструктора, а spring сам инстанциирует и передаст параметром в него:
Теперь опишем контроллер, который будет позволять выполнять http-запросы к нашему сервису. Для добавления книги нам потребуется описать класс запроса. Это data transfer object, который относится к своему слою DTO.
Нам также потребуется конвертировать объект AddBookRequest в объект Book. Создадим для этого BookToDtoMapper:
Теперь объявим контроллер, на эндпоинты которого будут приходить запросы на создание и получение книг, добавив зависимости BookService и BookToDtoMapper. При необходимости аналогично объекту AddBookRequest можно описать Response-объект, добавив соответствующий метод в мэппер, который будет конвертировать Book в GetBookResponse. Контроллер будет содержать 3 метода: методом POST мы будем добавлять книгу, методом GET получать список всех книг и книгу по идентификатору, который будем передавать в качестве PathVariable.
Настройка spring.jpa.hibernate.ddl-auto=update указывает hibernate необходимость обновить схему когда это нужно. Так как мы не создавали никаких схем, то приложение сделает это автоматически. В процессе промышленной разработки схемы баз данных постоянно меняются, и часто используются инструменты для версионирования и применения этих изменений, например Liquibase.
Запустим наше приложение и выполним запросы на добавление книг:
Запустим клиент БД и выполним sql-запрос:
Получим список всех книг:
Получим книгу через запрос к api нашего сервиса, указав идентификатор книги:
В документации можно подробнее прочитать об именовании методов. Здесь мы указываем findAll — найти все записи, ByAuthor — параметр обрамляется %. При вызове этого метода (например с аргументом ‘Bloch’) будет сгенерирован следующий запрос:
Далее добавим метод в BookService и DefaultBookService:
А в контроллере немного модифицируем метод получения списка книг таким образом, что при передаче get-параметра author мы искали по автору, а если параметр не передётся, то используется старая логика и выводится список всех книг:
Теперь можно выполнить поиск:
Итак, мы написали веб-сервис и познакомились с очень распространенными библиотеками. В следующей части продолжим улучшать наше приложение, добавив в него авторизацию, а также напишем отдельный микросервис, который будет выписывать токены доступа.
Spring Data JPA. Пишем DAO и Services. Часть 2

Шаг 0. Подготовка БД
Не забывайте что мы используем MySQL базу данных, поэтому вам нужно установить MySQL сервер и желательно редактор БД MySQL Workbench. Скачать можно тут.
После установки откройте MySQL Workbench, подключитесь к серверу:

После, создайте базу данных, нажав по соответствующем значку:

либо выполнив SQL запрос:
После этого можно переходить к созданию репозиториев. Нам не придётся создавать таблицы в БД их проект создаст сам.
Шаг 1. DAO либо Repository
DAO ( Data Access Object ) – это слой объектов которые обеспечивают доступ к данным.
Обычно для реализации DAO используется EntityManager и с его помощью мы работаем с нашей БД, но в нашем случае это система не подойдет, так как мы изучаем Spring Data нам нужно использовать её средства иначе незачем он нам.
О самом фреймворке Spring Data вы можете почитать тут.
Теперь давайте для каждого Entity создадим Repository, который позволит оперировать объектом в БД.

Создать Repository довольно просто, даже больше чем просто, давайте создадим для Bank entity его Repository и увидим на сколько все просто:
В 6-й строке видно что мы создали интерфейс с именем BankRepository и унаследовались от JpaRepository.
JpaRepository – это интерфейс фреймворка Spring Data предоставляющий набор стандартных методов JPA для работы с БД.
Ну создали интерфейс и что дальше? Спросите вы. На основе этого интерфейса Spring Data предоставит реализации с методами, которые мы использовали в Entity Manager, немного позже вы увидите пример использования Repository.
Для создания Repository нужно придерживаться несколько правил:

1 – Имя репозитория должно начинаться с имени сущности NameReposytory (необязательно).
2 – Второй Generic должен быть оберточным типом того типа которым есть ID нашей сущности (обязательно).
3 – Первый Generic должен быть объектом нашей сущности для которой мы создали Repository, это указывает на то, что Spring Data должен предоставить реализацию методов для работы с этой сущностью (обязательно).
4 – Мы должны унаследовать свой интерфейс от JpaRepository, иначе Spring Data не предоставит реализацию для нашего репозитория (обязательно).
Давайте продолжим создание Repositories для других сущностей.
Создаем BankAccountRepositroy для BankAccount:
Создаем ClientRepository для Client:
Создаем WorkerRepository для Worker:
В результате мы получим набор следующих Repositories:

По сути, теперь у нас есть слой обеспечивающий доступ к данным в БД.
Шаг 2. Создание Services
Service – это Java класс, который предоставляет с себя основную (Бизнес-Логику). В основном сервис использует готовые DAO / Repositories или же другие сервисы, для того чтобы предоставить конечные данные для пользовательского интерфейса.
Давайте создадим пакет service и в нем создадим наш первый сервис который будет предоставлять конечные данные для пользовательского интерфейса.
Я создам сервис для сущности Bank по аналогии делаются другие.
Создаем новый интерфейс BankService :
В этом интерфейс мы указали, какие методы нам будут нужны для написания бизнес-логики проекта.
Теперь создаем в этом же пакете, новый пакет impl в котором будут лежать реализации всех интерфейсов. Структура сервиса и его реализации:

Давайте создадим BankServiceImpl который будет реализовывать BankService интерфейс:
Теперь разберем, что же мы тут написали:
14 строка – это аннотация которая позволит Spring инициализировать наш сервис;
15 строка – объявление нашего сервиса (обратите внимание, что это интерфейс, а не реализация), который позволит нам использовать его бизнес-логику;
19 строка – тут мы сохраняем Bank в БД используя метод saveAndFlush, используя просто save() мы сохраняем запись но после вызова flush данные попадают в БД;
26 строка – удаление Bank по его id;
31 строка – этот метод не предоставляется Spring Data в следующем шаге мы рассмотрим как его сделать;
36 строка – update можно сделать тем же методом что и сохранение, так как hibernate умный, и он проверит, есть ли запись в БД, которую мы хотим сохранить, если есть, то он её обновит;
41 строка – получаем все данные с БД, а именно все банки.
Шаг 3. Кастомный метод в Spring Data
И так, в реализации BankService есть метод getByName(), который должен получать Bank по имени, в стандартных средствах Spring Data нет такой возможности, поэтому мы напишем свой кастомный метод.
Для этого зайдите в интерфейс BankRepository и там напишите следующий метод:
В строке 3 мы используем аннотацию @Query которая позволяет создать SQL запрос, но этот запрос содержит параметр :name, его иы проставляем в структуре метода findByName() используя аннотация @Param в параметре которой мы указываем имя параметра запроса name.
Spring Data на основе предоставленных данных в аннотациях сам предоставит реализацию этого метода, и это замечательно, так как теперь мы его можем использовать:
И вот финальная структура проекта:

Смотрите в следующем уроке, как тестировать Сервисы:
На этом все, качайте исходники в начале урока, разбирайтесь, если что-то непонятно, то все вопросы в комментарии.



