Ликбез по запуску Istio
Istio Service Mesh
Мы в Namely уже год как юзаем Istio. Он тогда только-только вышел. У нас здорово упала производительность в кластере Kubernetes, мы хотели распределенную трассировку и взяли Istio, чтобы запустить Jaeger и разобраться. Service mesh так здорово вписалась в нашу инфраструктуру, что мы решили вложиться в этот инструмент.
Пришлось помучиться, но мы изучили его вдоль и поперек. Это первый пост из серии, где я расскажу, как Istio интегрируется с Kubernetes и что мы узнали о его работе. Иногда будем забредать в технические дебри, но не сильно далеко. Дальше будут еще посты.
Что такое Istio?
Istio — это инструмент конфигурации service mesh. Он читает состояние кластера Kubernetes и делает обновление до прокси L7 (HTTP и gRPC), которые реализуются как sidecar-ы в подах Kubernetes. Эти sidecar-ы — контейнеры Envoy, которые читают конфигурацию из Istio Pilot API (и сервиса gRPC) и маршрутизируют по ней трафик. С мощным прокси L7 под капотом мы можем использовать метрики, трассировки, логику повтора, размыкатель цепи, балансировку нагрузки и канареечные деплои.
Начнем с начала: Kubernetes
В Kubernetes мы создаем под c помощью деплоя или StatefulSet. Или это может быть просто «ванильный» под без контроллера высокого уровня. Затем Kubernetes изо всех сил поддерживает желаемое состояние — создает поды в кластере на ноде, следит, чтобы они запускались и перезапускались. Когда под создается, Kubernetes проходит по жизненному циклу API, убеждается, что каждый шаг будет успешным, и только потом наконец создает под на кластере.
Этапы жизненного цикла API:

Спасибо Banzai Cloud за крутую картинку.
Один из этапов — модифицирующие вебхуки допуска. Это отдельная часть жизненного цикла в Kubernetes, где ресурсы кастомизируются до коммита в хранилище etcd — источнике истины для конфигурации Kubernetes. И здесь Istio творит свою магию.
Модифицирующие вебхуки допуска
Когда под создается (через kubectl или Deployment ), он проходит через этот жизненный цикл, и модифицирующие вебхуки доступа меняют его, прежде чем выпустить в большой мир.
Во время установки Istio добавляется istio-sidecar-injector как ресурс конфигурации модифицирующих вебхуков:
Sidecar-поды
Sidecar-ы — это трюки нашего фокусника Istio. Istio так ловко все проворачивает, что со стороны это прямо магия, если не знать деталей. А знать их полезно, если вдруг надо отладить сетевые запросы.
Init- и прокси-контейнеры
В Kubernetes есть временные одноразовые init-контейнеры, которые можно запускать до основных. Они объединяют ресурсы, переносят базы данных или, как в случае с Istio, настраивают правила сети.
@jimmysongio нарисовал отличную схему связи между правилами iptables и прокси Envoy:
Envoy получает весь входящий и весь исходящий трафик, поэтому весь трафик вообще перемещается внутри Envoy, как на схеме. Прокси Istio — это еще один контейнер, который добавляется во все поды, изменяемые sidecar-инжектором Istio. В этом контейнере запускается процесс Envoy, который получает весь трафик пода (за некоторым исключением, вроде трафика из вашего кластера Kubernetes).
Процесс Envoy обнаруживает все маршруты через Envoy v2 API, который реализует Istio.
Envoy и Pilot
У самого Envoy нет никакой логики, чтобы обнаруживать поды и сервисы в кластере. Это плоскость данных и ей нужна плоскость контроля, чтобы руководить. Параметр конфигурации Envoy запрашивает хост или порт сервиса, чтобы получить эту конфигурацию через gRPC API. Istio, через свой сервис Pilot, выполняет требования для gRPC API. Envoy подключается к этому API на основе sidecar-конфигурации, внедренной через модифицирующий вебхук. В API есть все правила трафика, которые нужны Envoy для обнаружения и маршрутизации для кластера. Это и есть service mesh.
Обмен данными «под Pilot»
Pilot подключается к кластеру Kubernetes, читает состояние кластера и ждет обновлений. Он следит за подами, сервисами и конечными точками в кластере Kubernetes, чтобы потом дать нужную конфигурацию всем sidecar-ам Envoy, подключенным к Pilot. Это мост между Kubernetes и Envoy.
Из Pilot в Kubernetes
Когда в Kubernetes создаются или обновляются поды, сервисы или конечные точки, Pilot узнает об этом и отправляет нужную конфигурацию всем подключенным экземплярам Envoy.
Какая конфигурация отправляется?
Какую конфигурацию получает Envoy от Istio Pilot?
По умолчанию Kubernetes решает ваши сетевые вопросы с помощью sevice (сервис), который управляет endpoint (конечные точки). Список конечных точек можно открыть командой:
Это список всех IP и портов в кластере и их адресатов (обычно это поды, созданные из деплоя). Istio важно это знать, чтобы настраивать и отправлять данные о маршрутах в Envoy.
Сервисы, прослушиватели и маршруты
Когда вы создаете сервис в кластере Kubernetes, вы включаете ярлыки, по которым будут выбраны все подходящие поды. Когда вы отправляете трафик на IP сервиса, Kubernetes выбирает под для этого трафика. Например, команда
Istio и Envoy слегка меняют эту логику. Istio настраивает Envoy на основе сервисов и конечных точек в кластере Kubernetes и использует умные функции маршрутизации и балансировки нагрузки Envoy, чтобы обойти сервис Kubernetes. Вместо проксирования по одному IP Envoy подключается прямо к IP пода. Для этого Istio сопоставляет конфигурацию Kubernetes с конфигурацией Envoy.
Термины Kubernetes, Istio и Envoy немного отличаются, и не сразу понятно, что с чем едят.
Сервисы
Все те же сервисы есть в этом пространстве имен:
Как Istio узнает, какой протокол использует сервис? Настраивает протоколы для манифестов сервисов по полю name в записи порта.
Если использовать kubectl и админскую страницу переадресации портов в Envoy, видно, что конечные точки account-grpc-public реализуются Pilot как кластер в Envoy с протоколом HTTP2. Это подтверждает наши предположения:
Порт 15000 — это админская страница Envoy, доступная в каждом sidecar.
Прослушиватели
Прослушиватели узнают конечные точки Kubernetes, чтобы пропускать трафик в поды. У сервиса проверки адреса здесь одна конечная точка:
Поэтому у пода проверки адреса один прослушиватель на порте 50051:
Маршруты
В Namely мы используем Istio Ingress-Gateway для всего внутреннего GRPC-трафика:
Если переадресовать порт пода Istio-IngressGateway и посмотреть конфигурацию Envoy, мы увидим, что делает VirtualService:
Что мы гуглили, копаясь в Istio
Возникает ошибка 503 или 404
Причины разные, но обычно такие:
Что означает NR/UH/UF в логах прокси Istio?
По поводу высокой доступности с Istio
Почему Cronjob не завершается?
Когда основная рабочая нагрузка выполнена, sidecar-контейнер продолжает работать. Чтобы обойти проблему, отключите sidecar в cronjobs, добавив аннотацию sidecar.istio.io/inject: “false” в PodSpec.
Как установить Istio?
Спасибо Bobby Tables и Michael Hamrah за помощь в написании поста.
Dark Launch в Istio: секретные службы
«Опасность – мое второе имя», – говаривал Остин Пауэрс, человек-загадка международного масштаба. Но то, что в почете у суперагентов и спецслужб, совсем не годится для служб компьютерных, где скукотища гораздо лучше опасностей.
И Istio вместе OpenShift и Kubernetes превращают развертывание микросервисов в дело по-настоящему скучное и предсказуемое – и это прекрасно. Об этом и о многом другом поговорим в четвертом и последнем посте из серии про Istio.
Когда скукотища – это правильно
В нашем случае скукотища возникает только в конечной фазе, когда остается только сидеть и наблюдать за процессом. Но для этого надо всё предварительно настроить, и здесь вас ждет много интересного.
При развертывании новой версии вашего софта стоит рассмотреть все варианты минимизации рисков. Работа в параллельном режиме – это очень мощный и проверенный способ тестирования, и Istio позволяет задействовать для этого «секретную службу» (скрытую от посторонних глаз версию вашего микросервиса) без вмешательства в работу продакшн-системы. Для этого есть даже специальный термин – «Тайный запуск» (Dark Launch), который в свою очередь активируется функцией с не менее шпионским названием «зеркалирование трафика».
Обратите внимание, что в первом предложении предыдущего абзаца используется термин «развертывание» (deploy), а не «запуск» (release). Вы действительно должны иметь возможность развертывать – и, разумеется, использовать – свой микросервис так часто, как пожелаете. Этот сервис должен быть способен принимать и обрабатывать трафик, выдавать результаты, а также писать в логи и мониториться. Но при этом сам этот сервис вовсе необязательно выпускать в продакшн. Развертывание и выпуск ПО – это не всегда одно и то же. Развертывание вы можете выполнять всегда, когда захотите, а вот выпуск – только тогда, когда будете окончательно готовы.
Организация скуки – это интересно
Взгляните на следующее правило маршрутизации Istio, которое направляет все HTTP-запросы на микросервис recommendation v1 (все примеры взяты из Istio Tutorial GitHub repo), одновременно зеркалируя их на микросервис recommendation v2:
Обратите внимание на метку mirror: внизу скрина – именно она задает зеркалирование трафика. Да, вот так просто!
Результатом работы этого правила станет то, что ваша продакшн-система (v1) будет по-прежнему обрабатывать поступающие запросы, но сами запросы при этом будут асинхронно зеркалиться на v2, то есть туда будут уходить их полные дубликаты. Таким образом, вы сможете протестировать работу v2 в реальных условиях – на настоящих данных и трафике, – никак не вмешиваясь в работу продакшн-системы. Превращает ли это организацию тестирования в скукотищу? Да, безусловно. Но делается это интересно.
Добавим драмы
Обратите внимание, что в коде v2 надо предусмотреть ситуации, когда поступающие запросы могут приводить к изменению данных. Сами запросы зеркалятся легко и прозрачно, но вот выбор способа обработки в тестовой остается за вами – а вот это уже немного волнительно.
Повторим важный момент
Тайный запуск с зеркалированием трафика (Dark Launch/Request Mirroring) можно выполнять, никак не затрагивая код.
Пища для размышления
А что, если место зеркалирования запросов отправлять часть из них не на v1, а на v2? Например, один процент от всех запросов или только запросы от определенной группы пользователей. И потом, уже глядя на то, как работает v2, постепенно переводить на новую версию все запросы. Или наоборот вернуть всё на v1, если с v2 что-то пойдет не так. Кажется, это называется Canary Deployment («канареечное развертывание» – термин восходит к горному делу, и будь у него русское происхождение, он вероятно содержал бы отсылку к кошкам), и сейчас мы это рассмотрим подробнее.
Canary Deployment в Istio: упрощаем ввод в строй
Осторожно и постепенно
Суть модели развертывания Canary Deployment предельно проста: при запуске новой версии своего софта (в нашем случае – микросервиса) вы сначала даете к ней доступ небольшой группе пользователей. Если всё идет нормально, вы медленно увеличиваете эту группу до тех пор, пока новая версия не начинает барахлить, или – если этого так и не происходит – в итоге переводите на нее всех пользователей. Продуманно и постепенно вводя в строй новую версию и контролируемо переключая на нее пользователей, можно снизить риски и максимизировать обратную связь.
Разумеется, Istio упрощает Canary Deployment, предлагая сразу несколько хороших вариантов для интеллектуальной маршрутизации запросов. И да, все это можно сделать, никак не трогая ваш исходный код.
Фильтруем браузер
Один из самых простых критериев маршрутизации – это перенаправление в зависимости от браузера. Допустим, вы хотите, чтобы на v2 уходили только запросы из браузеров Safari. Вот как это делается:
Применим это правило маршрутизации и затем командой curl будем в цикле имитировать реальные запросы к микросервису. Как видно на скриншоте, все они уходят на v1:
А где же трафик на v2? Поскольку в нашем примере все запросы шли только из нашей же командной строки, то его попросту нет. Но обратите внимание на нижние строчки на скрине выше: это реакция на то, что мы выполнили запрос из браузера Safari, который в свою очередь выдал вот что:
Неограниченная власть
Мы уже писали, что регулярные выражения дают очень мощные возможности для маршрутизации запросов. Взгляните на следующий пример (думаем, вы и сами поймете, что он делает):
Теперь вы, вероятно, уже представляете, на что способны регулярные выражения.
Действуйте умно
Умная маршрутизация, в частности обработка заголовки пакетов с использованием регулярных выражений, позволяет рулить трафиком так, как вам хочется. И это значительно упрощает ввод в строй нового кода – это просто, это не требует изменения самого кода, и при необходимости все можно быстро вернуть как было.
Заинтересовались?
Загорелись желанием поэкспериментировать с Istio, Kubernetes и OpenShift на своем компьютере? Команда Red Hat Developer Team подготовила отличный учебник по этой теме и выложила в общий доступ все сопутствующие файлы. Так что вперед, и ни в чем себе не отказывайте.
Istio Egress: выход через сувенирную лавку
Применяя Istio вместе с Red Hat OpenShift и Kubernetes, можно значительно облегчить себе жизнь с микросервисами. Сервисная сетка Istio упрятана внутрь Kubernetes’овских pod’ов, а ваш код выполняется (в основном) изолированно. Производительность, простота изменения, трассировка и прочее – все это легко использовать именно за счет применения sidecar-контейнеров. Но что делать, если ваш микросервис должен общаться с другим сервисами, которые расположены за пределами вашей системы OpenShift-Kubernetes?
Здесь на помощь приходит Istio Egress. Если в двух словах, то он просто позволяет получить доступ к ресурсам (читай: «сервисам»), которые не входят в вашу систему Kubernetes’овских pod’ов. Если не выполнять дополнительную настройку, то в среде Istio Egress трафик маршрутизируется только внутри кластера pod’ов и между такими кластерами исходя из внутренних IP-таблиц. И такое закукливание прекрасно работает до тех пор, пока вам не нужен доступ к сервисам снаружи.
Egress позволяет обойти вышеупомянутые IP-таблицы, либо на основе правил Egress, либо для диапазона IP-адресов.
Допустим, у нас есть Java-программа, которая выполняет GET-запрос к httpbin.org/headers.
(httpbin.org – это просто удобный ресурс для тестирования исходящих сервис-запросов.)
Или можно открыть этот же адрес в браузере:
Как видим, расположенный там сервис просто возвращает переданные ему заголовки.
Импортозамещаем в лоб
Расширяем IP-таблицы на весь интернет
Винить (или благодарить) за это надо Istio. Ведь Istio – это просто sidecar- контейнеры, который отвечают за обнаружение и маршрутизацию (ну и за массу других вещей, о которых мы рассказывали ранее). По этой причине IP-таблицы знают только о том, что находится внутри вашей системы кластеров. А httpbin.org расположен снаружи и, следовательно, недоступен. И вот тут на помощь приходит Istio Egress – без малейших изменений в вашем исходном коде.
Приведенное ниже Egress-правило заставляет Istio искать (если надо, то и во всем всемирном интернете) нужный сервис, в данном случае, httpbin.org. Как видно из этого файла (egress_httpbin.yml), функциональность здесь довольно простая:
Осталось только применить это правило:
Просмотреть правила Egress можно командой istioctl get egressrules :
И наконец, опять запускаем команду curl – и видим, что все работает:
Мыслим открыто
Как видите, Istio позволяет организовать взаимодействие и с внешним миром. Иными словами, вы можете всё так же создавать сервисы OpenShift и рулить ими через Kubernetes, держа всё в pod’ах, которые масштабируются вверх-вниз по мере надобности. И при этом вы спокойно можете обращаться к внешним по отношению к вашей среде сервисам. И да, еще раз повторимся, что все это можно делать, никак не трогая ваш код.
Это был последний пост из серии по Istio. Оставайтесь с нами – впереди много интересного!
Istio: обзор и запуск service mesh в Kubernetes
Istio- одна из реализацией концепии Service Mesh, позволяющая реализовать Service Discovery, Load Balancing, контроль над трафиком, canary rollouts и blue-green deployments, мониторить трафик между приложениями.
Мы будем использовать Istio в AWS Elastic Kubernetes Service для мониторинга трафика, в роли API gateway, разграничения трафика и, возможно, для реализации различных deployment strategies.
В этом посте рассмотрим что такое Service mesh вообще, общую архитектуру и компоненты Istio, его установку и настройку тестового приложения.
Перед тем, как рассматривать Istio – давайте разберёмся, что такое Service Mesh.
Service Mesh
По сути, это менеджер прокси-сервисов, таких как NGINX, HAProxy или Envoy, система, работающая на Layer 7 модели OSI и позволяющая динамически управлять трафиком и настраивать коммуникацию между приложениями.
Service mesh занимается обнаружением новых сервисов/приложений, балансировкой нагрузки, аутентификацией и шифрованием трафика.
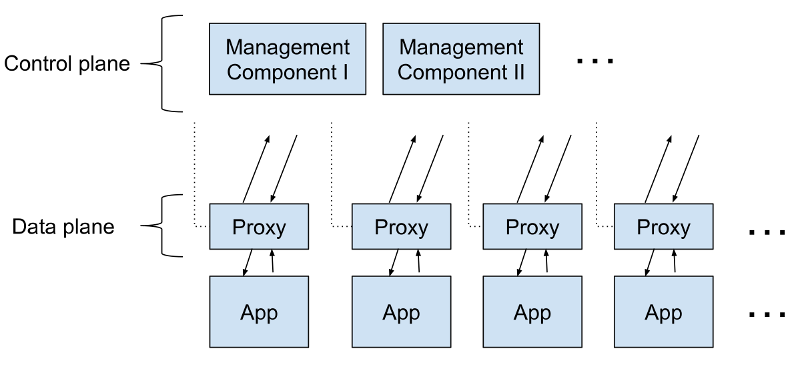
Для контроля трафика в service mesh для каждого приложения, или в случае с Kubernetes – для каждого пода, запускается прокси-сервис называемый sidecar, и эти sidecar-сервисы проксируют и управляют трафиком.
Вместе эти sidecar-контейнеры представляют собой Data Plane.
Для их конфигурирования и управления существует другая группа процессов или сервисов, называемых Control Plane. Они занимаются обнаружением новых приложений, обеспечивают управление ключами шифрования, сбором метрик и т.д.
Схематично сервис меш можно отобразить так:
Среди Service mesh решений можно выделить:
Архитектура Istio
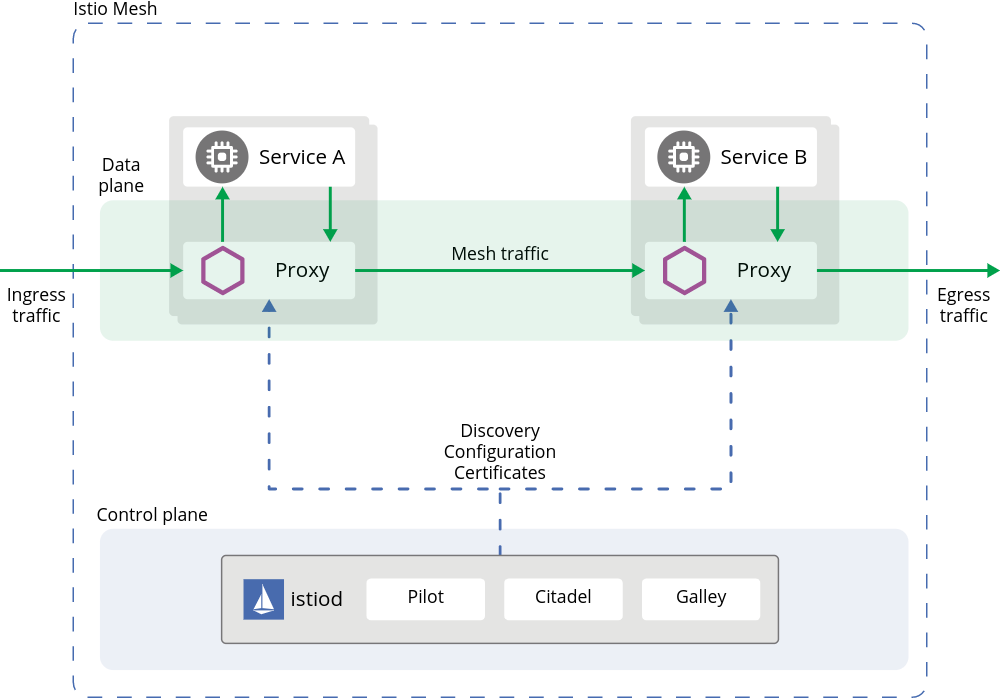
Итак, Istio как service mesh состоит из двух основных частей – Data plane и Control plane:
В целом схема Istio выглядит так:
Control Plane
Istio включает в себя четыре основных компонента:
Data Plane
Состоит из sidecar-контейнеров, которые в Kubernetes запускаются внутри подов через kube-inject, см. Installing the Sidecar.
Контейнеры являются инстансами Envoy-прокси, которые позволяют:
Модель сети Istio
Перед тем, как приступать к запуску и настройке приложения и Istio – кратко рассмотрим ресурсы, которые участвуют в управлении трафиком.
При установке Istio создаёт ресурс Ingress Gateway (и Egress Gateway, если было определено при установке) – новый объект в Kubernetes, который описывается в Kubernetes CRD при установке Istio.
В AWS при настройках по-умолчанию Ingress Gateway создаёт AWS Classic LoadBalancer, т.к. Ingress Gateway является Kubernetes-объектом Ingress с типом LoadBalancer.
“За” Ingress Gateway создаётся ресурс Gateway, который также описывается в Kubernetes CRD во время установки Istio и описывает хосты и порты, на которые будет отправляться трафик через этот Gateway.
Далее следует ещё один ресурс – VirtualService, который описывает маршрутизацию трафика, прошёдшего через Gateway, и отправляет его на Kubernetes Services следуя заданным Destination rules.
Ingress Gateway состоит из двух компонентов – Kubernetes Pod с инстансом Envoy, который управляет входящим трафиком, и Kubernetes Ingress, который принимает подключения.
В свою очередь Gateway и VirtualService управляют конфигурацией Envoy, который является Ingress Gateway controller.
Т.е. в целом схема прохождения пакета выглядит так:
Запуск Istio в Kubernetes
Istio поддерживает различные Deployment models. В нашем случае используется один EKS-кластер, а поды в нём работают в общей VPC сети.
Установить Istio можно разными способами – с помощью istioctl из манифест-файлов, из Helm-чарта, либо с помощью Ansible.
Также, стоит обратить внимание на Mutual TLS (mTLS) – см. Permissive mode. Если кратко, то по-умолчанию Istio устанавливается в Permissive mode, что позволяет уже существующим приложениям продолжать коммуникацию используя plaintext-трафик. При этом новые подключения через Envoy-контейнеры, sidecars, уже будут выполняться с TLS-шированием.
Пока выполним установку руками, а на Дев и Прод кластера Кубера скорее всего будем инсталить через Helm.
Генерируем kubeconfig для нового тестового кластера (для AWS EKS, если используется Minikube – он при старте сгенерирует конфиг сам):
Устанавливаем Istio с профилем default:
Проверяем версию ещё раз:
Далее задеплоим тестовое приложение, и настроим роутинг через Istio Ingress Gateway.
Тестовое приложение
Не будем использовать Bookinfo приложение из Istio Gettings Started, а напишем свой велосипед создадим свой Namespace, Deployment с одним подом с NGINX, и к нему Service – эмулируем миграцию уже имеющихся у нас приложений под управление Istio.
Кроме того, сейчас специально не будем настраваить добавление sidecar-контейнеров в приложение – вернёмся к этому вопросу чуть позже.
Манифест сейчас выглядит так:
Что ждать от внедрения Istio? (обзор и видео доклада)
Istio — частный случай «сервисной сетки» (Service Mesh), понятия, о котором наверняка все слышали, и многие даже знают, что это такое. Мой доклад на Kuber Conf 2021 (мероприятие Yandex.Cloud, которое проходило 24 июня в Москве) посвящен возможным проблемам, к которым надо готовиться при внедрении Istio. Среди прочего я рассказал о том, как Istio влияет на трафик, какие есть возможности для его мониторинга, насколько безопасен mTLS.
Доклад отчасти отражает наш опыт работы с Istio как с одним из компонентов Kubernetes-платформы Deckhouse, отчасти основан на результатах внутренних нагрузочных тестов.

30 минут) и основную выжимку в текстовом виде.
Что такое Service Mesh
Для начала синхронизируем понимание, что такое Service Mesh.
Допустим, у вас есть приложение, оно живет своей жизнью, развивается. Вы нанимаете новых программистов, от бизнеса поступают новые задачи. Нормальная эволюция.
При этом объемы сетевого трафика растут, и в этой ситуации вы просто не можете не столкнуться с задачами по его управлению. Разберем эти задачи подробнее.
Типовая сетевая задача №1
Возьмем небольшой кусочек архитектуры — фронтенд и бэкенд. С точки зрения кластера он выглядит как две группы Pod’ов, которые общаются друг с другом.
Предположим, одному из Pod’ов стало плохо — не терминально, но приложение глючит. Health check’и в Kubernetes этого не замечают: сохраняют Pod в балансировке, и трафик на него продолжает поступать. От этого становится только хуже.
Было бы здорово выявлять эти пограничные состояния, когда вроде бы почти всё окей, но все-таки что-то идет не так. А выявив — дать нашему Pod’у отдохнуть, временно перенаправив трафик на другие Pod’ы. Такой подход называется circuit breaking.
Типовая сетевая задача №2
Вы написали новую версию бэкенда, прошли все тесты, на stage бэкенд показал себя хорошо. Но прежде, чем катить его в production, хорошо бы обкатать на настоящем трафике. То есть выделить группу пользователей для новой версии бэкенда и протестировать его на этой группе.
Если тесты прошли успешно — выкатываем бэкенд в production и обновляем все Pod’ы. Такая стратегия деплоя называется canary deployment. (Подробнее о разных стратегиях деплоя в Kubernetes мы писали здесь.)
Типовая сетевая задача №3
Например, ваш кластер развернут в публичном облаке. Из соображений отказоустойчивости вы «размазали» Pod’ы по разным зонам. При этом фронтенд- и бэкенд-Pod’ы общаются друг с другом беспорядочно, не обращая внимание на зоны. В мире облачных платформ такое беспорядочное общение не будет для вас бесплатным. Например, в AWS это выльется в дополнительные финансовые расходы, в Яндекс.Облаке — в дополнительный latency.
Нужно сделать так, чтобы фронтенды выбирали такие бэкенды, которые находятся в их зоне, а остальные бэкенды оставались бы для них «запасными». Такой способ маршрутизации называется locality load balancing.
Решаем сетевые задачи систематически
Подобные задачи по управлению сетевым трафиком можно перечислять ещё долго и каждый хотя бы раз сталкивался хотя бы с одной из них. Безусловно, у каждой из задач есть решение, которое можно реализовать на уровне приложения. Но проблема в том, что среднестатистическое приложение состоит из множества компонентов, или «шестеренок». И все они разные, к каждой нужен свой подход.
Именно для систематического решения подобных задач и придумали Service Mesh.
Service Mesh дает набор «кирпичей», из которых мы можем собирать собственные паттерны управления сетью. По-другому: Service Mesh — это фреймворк для управления любым TCP-трафиком с собственным декларативном языком. А в качестве бонуса Service Mesh предлагает дополнительные возможности для мониторинга (observability).
Благодаря Service Mesh вам не нужно задумываться о нюансах сетевого взаимодействия на уровне отдельных компонентов.
Вы можете рассматривать ваше приложение просто как дерево компонентов с очень примитивными связями. А все нюансы вынести за скобки и описать их с помощью Service Mesh.
Как это работает
Представим, что мы — большие любители «велосипедов»: мы не ищем готовые решения, потому что любим писать свои. И мы решили написать свой Service Mesh — supermesh.
Предположим, у нас есть приложение. Оно принимает запросы, генерирует новые — вот этим трафиком мы и хотим управлять. Но чтобы им управлять, нам нужно его перехватить. Для этого:
проникаем в сетевое окружение приложения;
внедряем туда наш перехватчик;
DNAT’ом перенаправляем на него входящий и исходящий трафик.
Поскольку мы работаем с Kubernetes, наше приложение «живет» в Pod’e, то есть внутри контейнера. Это значит, что мы для удобства можем «подселить» к приложению наш перехватчик в качестве sidecar-контейнера.
Теперь с этим перехваченным трафиком нужно что-то сделать, как-то его модифицировать. Очевидное решение — использовать прокси (например, nginx, HAProxy или Envoy).
Мы можем написать и свой прокси, но мы не настолько велосипедисты, поэтому остановимся на Envoy. Он хорошо вписывается в эту архитектуру, потому что умеет конфигурироваться удаленно, «на лету», и у него есть множество готовых удобных API.
В итоге мы можем перехватить трафик и влиять на него. Осталось сделать с ним что-то полезное, то есть реализовать какой-то из упомянутых выше паттернов управления — причем не абы какой, а такой, который выберет разработчик нашего приложения.
Мы могли бы передать разработчику «пульт управления» нашими sidecar’ами, чтобы он сам настраивал все нюансы. Но изначально вроде бы не этого хотели: нам нужна систематизация.
Очевидно, что нам не хватает какого-то промежуточного компонента — условного контроллера (supermeshd), который взял бы на себя управление, а разработчику предоставил декларативный язык, с помощью которого тот строил бы свои стратегии.
Теперь мы можем взять от разработчика набор паттернов, которые он хочет, а контроллер будет бегать по sidecar’ам и настраивать их. В мире Service Mesh такой контроллер называется Control Plane, а sidecar’ы с нашим перехватчиком — Data Plane.
Именно по такому принципу — естественно, с большими допущениями — и работает большинство реализаций Service Mesh: Kuma, Istio, Linkerd и пр.
В этом докладе я рассматриваю только Istio и делаю это «без объяснения причин». Кстати, согласно прошлогоднему опросу CNCF, это самое популярное Service Mesh-решение, которое используется в production.
Перед внедрением Istio к нему сразу же возникает ряд вопросов:
Как он повлияет на приложение? А на кластер?
Какие у него возможности по observability?
Надежен ли его Mutual TLS?
Как правильно засетапить Istio? А обновить?
Что, если что-то сломается?
Конечно, вопросов гораздо больше. Постараюсь ответить хотя бы на некоторые из них.
Как Istio влияет на приложение
Раньше, когда не было Istio, всё было просто и прозрачно: пользователь генерирует запрос, фронтенд генерирует дочерний запрос к бэкенду.
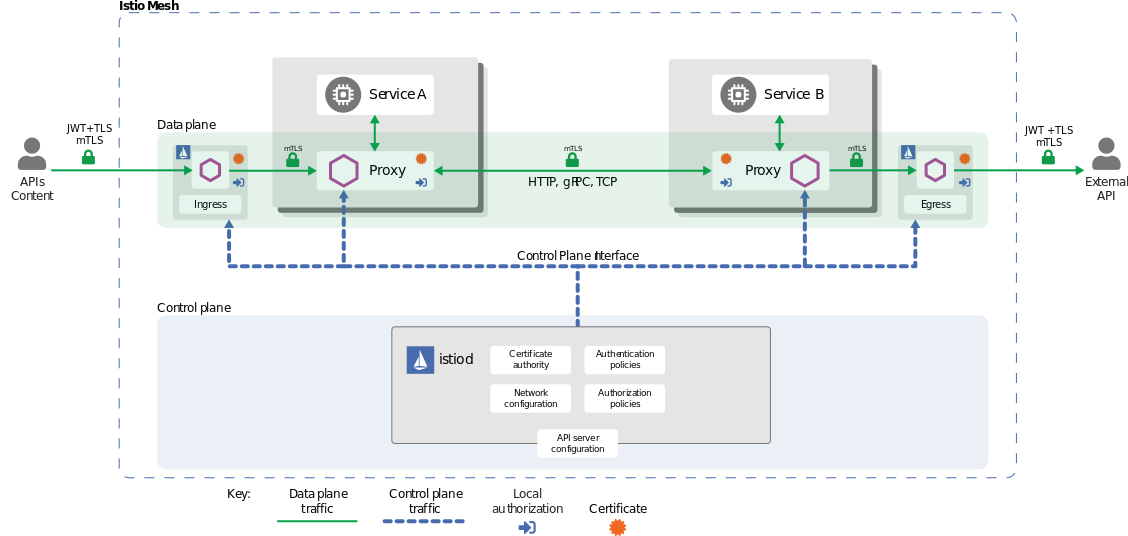
Как только появляется Istio, схема усложняется:
По сравнению с чистой инсталляцией «хопов» стало гораздо больше. Понятно, что это не может быть бесплатным. И самая очевидная цена — это latency.
Разработчики Istio обещают, что задержка не будет превышать 2,65 мс. Мне эти цифры показались не очень убедительными, поэтому я решил сделать свои замеры.
Нагрузочное тестирование
Для начала я написал примитивное клиент-серверное приложение. В качестве клиента использовал утилиту для нагрузочного тестирования k6, а в качестве сервера — nginx, который просто отдает статичные файлы. k6 отправляла по 10 тыс. запросов с предварительным прогревом в сторону сервера. Важно: клиент и сервер работали на разных узлах, чтобы не мешать друг другу.
Из этого приложения я собрал несколько вариантов инсталляции:
«чистую» схему, без Istio и всяких sidecar’ов;
сетап с Envoy в качестве sidecar’а;
сетап, в котором просто включен Istio;
еще один сетап с Istio, в котором задействованы 1000 правил авторизации — чтобы понять, влияют ли какие-то дополнительные правила на задержку, и как именно.
Что еще я посчитал важным сделать:
отключил логи на sidecar’ах;
включил сбор метрик sidecar’ах Istio;
использовал разные версии TLS;
включал и выключал HTTP/2;
включал и выключал keepalive на стороне клиента и между sidecar’ами;
использовал JSON-файлы трех размеров: 500Б, 200КБ, 1,7МБ;
экспериментировал с многопоточностью.
В итоге получилось 252 теста. Попробуем оценить собранные метрики.
1. Классический сценарий: примитивный клиент отправляет запросы серверу в один поток и не умеет держать keepalive.
Посмотрим на картину задержек:
Самый первый и очевидный вывод: действительно, перехват трафика не бесплатен. Причем в случае с Envoy в качестве sidecar’а и «тяжелым» файлом мы видим пятикратный рост задержки.
Уровень драматичности снижается, если мы посмотрим на полный round-trip (RTD) запроса. В самом худшем случае мы увидим троекратный оверхэд. А в некоторых случаях он почти не заметен:
Важно учитывать, что в моем случае естественный фон задержки у бэкенда крайне мал — 0,23 мс. В этом случае прирост в 2 мс кажется огромным — 800%. Но если у вас более сложный бэкенд, у которого задержка составляет десятки мс, то эти лишние 2 мс вы не заметите.
Второй вывод: по сравнению с «голым» Envoy’ем Istio все-таки дает небольшие накладные расходы. Возможно, это связано со сбором метрик и это стоит учитывать.
Третий вывод: правила авторизации, как и любые другие дополнительные настройки Istio, влияют на latency. Но это тоже не должно смущать, т. к. в реальной жизни вряд ли кому-то понадобится тысяча дополнительных правил.
Четвертый вывод: рост задержки при росте размера файла. Здесь задержка растет так же предсказуемо, и все пропорции по сравнению с «голой» инсталляцией сохраняются. То есть можно считать, что объем данных, которые мы прогоняем через Istio, на задержку не влияет.
2. Сценарий с шифрованием Mutual TLS
Результаты оказались везде более-менее одинаковыми, поэтому я покажу их на примере одной инсталляции, когда просто включен Istio:
Да, влияние есть. Но, опять же, это «копейки», которые можно не учитывать. Так что шифрование можно смело включать.
3. Любопытные наблюдения
Они не связаны напрямую с Istio, но я подумал, что ими не помешает поделиться.
Я решил: а что, если включить keepalive на клиентах? Не выиграю ли я в задержке? Потому что, во-первых, handshakes. Во-вторых, sidecar’ам надо будет поменьше думать.
Результаты покажу на примере того же сетапа с Istio:
Выигрыш хоть и небольшой, но есть. Мелочь, а приятно!
А что, если еще включить многопоточность. И вот тут я расстроился: при тестах на «средневесе» и «тяжеловесе» задержка выросла.
Разбираясь с этой проблемой, я нашел убедительное объяснение в статье блога Cloudflare, почему keepalive — это не всегда хорошо.
Итак, два главных вывода о влиянии Istio на приложение:
перехват трафика не бесплатен — можно смело закладывать накладные расходы по задержке порядка 2,5 мс;
если ваша естественная задержка измеряется в десятках и сотнях мс, лишние 2,5 мс вы не заметите.
Как Istio влияет на кластер
У нашего Istio, как и у supermeshd, который мы ранее реализовали сами, тоже есть Control Plane. Называется он istiod, и это отдельный контроллер, который работает в кластере.
Также у Istio есть свой декларативный язык, с помощью которого можно строить паттерны по управлению сетью. Технически язык представляет собой набор ресурсов Kubernetes, за которыми istiod пристально следит. Еще он следит за набором системных ресурсов: Namespace’ами, Pod’ами, узлами и т. д. В этом смысле контроллер Istio ничем не отличается от любого другого контроллера или оператора. И на практике никаких проблем с ним мы не выявили. Можем идти дальше.
Observability
У Istio есть интеграция со сторонними инструментами для мониторинга. Например, с дашбордом Kiali, с помощью которого можно визуализировать приложение в виде графа, рассмотреть отдельные связи компонентов, как они устроены, что у них «болит» и т. д.
Есть хороший набор дашбордов для графиков Grafana.
Istio также предоставляет базовые возможности для внедрения трассировки на основе Jaeger.
К сожалению, ничего из этого у вас не заработает «из коробки». Для Kiali и Grafana нужно будет установить Prometheus (и саму Grafana). В случае с трассировкой придется, как минимум, установить где-то Jaeger, а как максимум — научить ваше приложение грамотно обрабатывать HTTP-заголовки со служебными данными от трассировки.
Безопасность (Mutual TLS)
Напомню, протокол Mutual TLS (mTLS) — это взаимная, или двусторонняя, аутентификация клиента и сервера. Он нужен, когда мы хотим, чтобы наши клиент и сервер достоверно знали друг друга, не общались со всякими «незнакомцами». Также mTLS нужен, когда мы хотим зашифровать трафик между нашими приложениями. Технически это достигается с помощью обычных SSL-сертификатов.
В мире Istio у каждого Pod’а есть сертификат, который подтверждает подлинность этого Pod’а, а именно — подлинность его идентификатора (ID). В терминологии Istio идентификатор — это principal. Он состоит из трех частей:
ID кластера (Trust Domain),
ServiceAccount’а, под которым работает Pod.
За выпуск сертификатов отвечает Control Plane, на основе собственного корневого сертификата. У каждой инсталляции Istio есть собственный корневой сертификат — root CA (его не стоит путать с корневым сертификатом самого кластера). На основе корневого сертификата выпускаются индивидуальные.
Давайте разберём весь жизненный цикл индивидуального сертификата.
Envoy в Istio не общается напрямую с Control Plane: он это делает через посредника, который называется Istio agent — утилита, написанная на Go, которая живет в одном контейнере с Envoy. Этот агент отвечает за ротацию сертификатов.
Istio-agent генерирует CSR с заявкой на ID (principal), который полагается нашему Pod’у. Но сначала этот ID нужно как-то сгенерировать. С Trust Domain всё просто: агент знает, в каком кластере работает Pod (переменная в ENV). С Namespace’ом и ServiceAccount’ом чуть сложнее…
Но вообще: что такое ServiceAccount? Остановимся на этом чуть подробнее.
ServiceAccount
У Kubernetes есть свой API, который подразумевает, что с ним никто анонимно общаться не будет. С другой стороны, API подразумевает, что к нему будут общаться Pod’ы. Рядовым приложениям это, как правило, не нужно: обычно с API Kubernetes общаются контроллеры, операторы и т. п. И чтобы решить этот вопрос, придумали специальные учетные записи, которые называются ServiceAccount.
ServiceAccount — это примитивный ресурс в K8s, который в момент создания никакой информации не несет. Он просто существует в каком-то Namespace’е, с каким-то именем. Как только такой ресурс появляется в кластере, Kubernetes на это реагирует и выпускает JWT-токен. Этот токен целиком описывает появившийся ServiceAccount. То есть Kubernetes подтверждает: «в моем кластере, в таком-то Namespace’е, с таким-то именем есть ServiceAccount» — и выдает специальный токен, который складывает в Secret ( mysa-token-123 ).
Secret привязывается к ServiceAccount’у, который тем самым становится чем-то вроде ресурса со свидетельством о рождении. Данный ServiceAccount можно «привязать» к любому Pod’у, после чего, в ФС Pod’а будет автоматически примонтирован Secret с токеном, причем по заранее известному пути ( /run/secret/kubernetes.io/serviceaccount/token ). Собственно, данный токен и пригодится нам для того, чтобы узнать Namespace, в котором мы работаем, и ServiceAccount, от имени которого мы работаем.
Мы сгенерировали principal — теперь можем положить его в CSR.
Полученный CSR мы можем отправить в istiod. Но чтобы istiod поверил, что мы — это мы, в дополнение отправляем токен. Далее istiod проверяет этот токен через API K8s ( TokenReview ). Если K8s говорит, что всё хорошо, istiod подписывает CSR и возвращает в sidecar.
Для каждого Pod’а ротация сертификатов происходит раз в сутки.
Чтобы что-то взломать в этой системе, можно:
украсть сертификат (он будет действовать не более суток);
украсть токен ServiceAccount’а Pod’а, чтобы заказывать сертификаты от имени этого Pod’а;
взломать API Kubernetes — тогда можно заказать сколько угодно токенов, от имени какого угодно Pod’а;
украсть корневой сертификат Control Plane — самый примитивный и опасный взлом.
Всё это на самом деле довольно сложно реализовать. Поэтому можем считать, что mTLS в Istio безопасен.
Другие вопросы к Istio
К сожалению, осталось еще много вопросов, не раскрытых в докладе. И по каждому из этих вопросов достаточно много нюансов. Порой эти нюансы либо очень плохо описаны в документации, либо не описаны вовсе — приходится ковыряться в коде и обращаться к разработчикам Istio.
Множество из этих нюансов мы учли в модуле Istio для нашей платформы Deckhouse. С ее помощью вы можете за 8 минут развернуть готовый к использованию Kubernetes-кластер на любой инфраструктуре: в облаке, на «голом железе», в OpenStack и т. д.
Подробнее познакомиться с функциями, которые решает Istio в рамках Deckhouse, можно в нашей документации.



