interface agreement
1 interface agreement
См. также в других словарях:
interface agreement — the contract between the construction subcontractor and the FM contractor (or FM contractors). The interface agreement regulates who bears the cost of, for example, a defect in the completed asset caused by the construction subcontractor, which… … Law dictionary
Interface based programming — is a concept that has a close relationship with Modular Programming and Object Oriented Programming.Modular Programming defines the application as a collection of intercoupled modules. This increases the modularity of the application and hence… … Wikipedia
Interface inheritance — In object oriented programming, interface inheritance is type of inheritance wherein one or more classes share a set of messages. This sharing can be realized by agreement, as in Python, or by use of programming language specific machinery, as in … Wikipedia
Look-Aside Interface — The Look Aside Interface is a computer interface that was specified by an interface interoperability agreement produced by the Network Processing Forum. It specifies the method to interface a Network Processing Element (of which an NPU is an… … Wikipedia
Out-of-band agreement — In the exchange of information over a communications channel, an out of band agreement is an agreement or understanding between the communicating parties that is not included in any message sent over the channel but which is relevant for the… … Wikipedia
Message Passing Interface — MPI, the Message Passing Interface, is standardized and portable message passing system designed by a group of researchers from academia and industry to function on a wide variety of parallel computers. The standard defines the syntax and… … Wikipedia
High-Definition Multimedia Interface — Infobox connector name=High Definition Multimedia Interface type=Digital audio/video connector logo= caption=HDMI cable and HDMI official logo designer=HDMI Founders design date=December 2002 manufacturer=HDMI Adopters production date=2003… … Wikipedia
Musical Instrument Digital Interface — MIDI (Musical Instrument Digital Interface, IPAEng|ˈmɪdi) is an industry standard protocol that enables electronic musical instruments, computers, and other equipment to communicate, control, and synchronize with each other. MIDI allows computers … Wikipedia
Flat Display Mounting Interface — The Flat Display Mounting Interface (FDMI), also known as VESA Mounting Interface Standard (MIS) or colloquially as VESA mount, is a family of standards defined by the Video Electronics Standards Association for mounting flat panel monitors, TVs … Wikipedia
Flat Display Mounting Interface — (сокращенно FDMI) это семейство стандартов консорциума VESA, определяющий физические интерфейсы установки мониторов, телевизоров, и других дисплеев с плоским экраном на стойки и настенные крепления.[1] Стандарты FDMI реализованы во всех… … Википедия
Standard Interface For Multiple Platform Link Evaluation — (SIMPLE) bezeichnet einen Datenaustauschstandard der NATO und ist im Standardization Agreement (STANAG) 5602 definiert. SIMPLE Protokolle sind eine Variante des DIS Standards und werden dazu genutzt, militärische Führungssysteme, die mittels… … Deutsch Wikipedia
Интерфейсы в C#
У тех, кто только начинает осваивать C# часто возникает вопрос что такое интерфейс и зачем он нужен.
Сначала о том, что можно найти по первой же ссылке в поисковике. В большинстве статей смысл интерфейса разъясняется как «договор» о том, что должен содержать класс, какие свойства и методы. Например у нас есть интерфейс:
Соответственно, если какой-то класс реализует данный интерфейс, то он должен содержать реализацию метода int GetForecast(int value) и свойство Size.
Практическая ценность такого договора минимальная. Если выкинуть интерфейс из проекта, то все будет замечательно работать и без него. Разве что вы захотите полностью переписать логику класса и тогда интерфейс поможет вам не забыть про необходимые методы.
Подводя итог этой части, если какой-то интерфейс реализуется только в одном единственном классе, то не тратьте время на него. Он просто не нужен.
Дополнение
Сразу после публикации на меня обрушили море критики, сначала я пытался отвечать, но потом понял, что смысла нет. Все критики упирают на то, что я написал в предыдущем абзаце и пытаются приводить сложные примеры проектов где много классов, всякие ссылки туда-сюда, поддержка командой и прочее. Я наверно был не прав, что так коротко подвел итог вступления. Но суть в том, что интерфейс нужен далеко не всегда. Если у вас ваш личный (или просто не очень большой) проект, который не планируется масштабировать, на который ни кто не ссылается и, самое главное, который успешно работает, то введение в проект интерфейсов ничего не изменит. И не надо придумывать истории, что где-то кто-то однажды реализовал интерфейс и обрел бессмертие. Если бы интерфейс был нужен везде, он был бы неотъемлемой частью класса.
Это статья о том, как можно использовать интерфейс не для связки между проектами, а внутри одного проекта. По этому поводу критики пока еще не было.
К счастью возможности интерфейса намного интереснее. Интерфейс может задать общий признак для разнородных объектов, а это открывает огромные возможности по части гибкости кода.
Например, предположим у нас есть два класса:
Это два совсем разных класса, но пусть у них будет что-то общее, т.е. мы хотим, чтобы один метод работал с ними обоими без дополнительной логики. В таком случае мы можем реализовать общий интерфейс, т.е. объявить эти классы как
Теперь мы можем сделать общий метод для них:
Как видно, переменная value получит значение функции GetForecast от того класса, который будет передан в качестве параметра без дополнительных действий по приведению типов и т.п.
Другой пример, мы не знаем заранее какой класс нам потребуется в ходе вычислений, однако нам надо объявить экземпляр этого класса до начала работы. В такой случае можно объявить экземпляр класса, реализующего интерфейс:
Можно пойти еще дальше и объявить массив (или list) таких объектов:
А потом можно например вычислить сумму всех свойств Size:
У объявления через интерфейс есть один недостаток: вам будут доступны только методы и свойства, объявленные в интерфейсе и самом классе. Если ваш класс унаследован от базового, то для доступа к его методам придется делать приведение типа:
Еще один фокус с интерфейсам можно провернуть используя возможность реализовать в одном классе два интерфейса с одинаковыми по сигнатуре, но разными по содержанию методами. Я не знаю какая от этого может быть практическая польза кроме уже упомянутой, но если вдруг вам не хватает фантазии придумывать имена функций, то можете вынести их в интерфейсы.
Например добавим в наш проект еще один интерфейс:
И создадим новый класс, наследующий оба интерфейса:
Это называется явной реализацией интерфейса. Теперь можно построить такую конструкцию:
Интересно, что при реализации таких интерфейсов методам не могут быть назначены модификаторы доступа (“public” или что-то еще), однако они вполне доступны как публичные через приведение типа.
Как видно, это работает, но выглядит слишком громоздко. Чтобы как-то улучшить код, можно написать несколько иначе:
bad и good будут ссылаться на third, но иметь в виду разные интерфейсы. Привидение можно сделать один раз, а его результат потом использовать многократно. Возможно, что в некоторых случаях это сделает код более читаемым.
Еще одно применение интерфейса — быстрое изготовление заглушек для функций.
Например, вы в команде строите большой проект и ваш класс зависит от класса, который пишет коллега. Но еще не написал. Мудрый начальник подготовил интерфейсы всех основных классов еще на первом этапе разработки проекта и вы теперь можете не ждать коллегу, а реализовать класс-заглушку для своего класса. Т.е. временный класс не будет содержать логики, а будет только делать вид что работает: принимать вызовы и возвращать адекватные значения. Для этого надо только реализовать тот же интерфейс, что получил ваш коллега.
Работающий проект со всеми примерами из этой статьи можно посмотреть здесь: ссылка
Интерфейсы, взаимодействие и изменение программ и данных
Определены общие задачи неоднородности ЯП, платформ и сред, влияющих на установление связей между разноязыковыми программами, сформулированы пути их решения. Рассмотрены рекомендации стандарта ISO/IEC 11404-1996 по обеспечению независимых от современных ЯП типов данных.
8.1. Задачи интерфейса при разработке программ
В программировании термин интерфейс олицетворяет собой набор операций, обеспечивающих определение видов услуг и способов их получения от программного объекта, предоставляющего эти услуги. На начальном этапе программирования в роли интерфейса выступают операторы обращения к ее процедурам и функциям программ через формальные параметры. Программы, процедуры и функции записывались в одном ЯП. Операторы обращения включали имена вызываемых объектов (процедур и функций) и список фактических параметров, задающих значения формальным параметрам и получаемым результатам. Последовательность и число формальных параметров соответствовало фактическим параметрам. Выполнение функции в среде программы на одном ЯП не вызывало проблем, так как типы данных параметров совпадали.
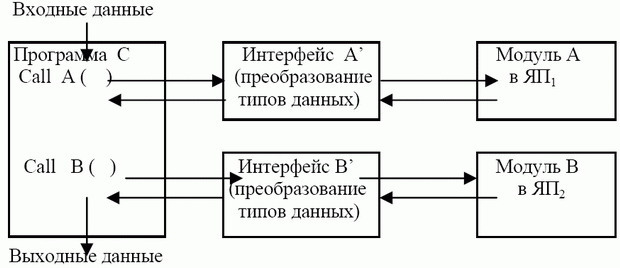
8.1.1. Интерфейс в ООП и в современных средах
Интерфейс содержит множество операций, описывающих его поведение. Класс может поддерживать несколько интерфейсов, каждый из которых содержит операции и сигналы, используются для задания услуг класса или программного компонента. Интерфейс именует множество операций или определяет их сигнатуру и результирующие действия. Если интерфейс реализуется с помощью класса, то он наследует все его операции. Одни и те же операции могут появляться в различных интерфейсах. Если их сигнатуры совпадают, то они задают одну и ту же операцию, соответствующую поведению системы. Класс может реализовывать другой класс через интерфейс.
Операции и сигналы могут быть связаны отношениями обобщения. Интерфейс-потомок включает в себя все операции и сигналы своих предков и может добавлять собственные путем наследования всех операций прямого предка, т.е. его реализацию можно рассматривать как наследование поведения.
Дальнейшим развитием идеи взаимодействия, основанного на действиях, является язык AL (Action language), обеспечиывющий вызовов процедур (локальных или распределенных) с разверткой каждого вызова в программу [8.4], состоящую из операторов действий. Программа из вызовов процедур рассматривается в AL как ограниченное множество конечных программ, взаимодействующих со средой, в которую они погружаются.
Интерфейс в современных средах и сетях.Появление разных компьютеров и их объединение в локальные и глобальные сети привело к уточнению понятия интерфейса как удаленного вызова (сообщения) программ, расположенных в разных узлах сети или среды и получающих входные данные из сообщений.
Сети строятся на основе стандартной семиуровневой модели открытых систем OSI (Open Systems Interconnection) [8.5]. Объекты уровней в этой модели связываются между собой по горизонтали и вертикали. Запросы от приложений поступают на уровень представления данных для их кодирования (перекодирования) к виду используемой в приложении платформы. Открытые системы предоставляют любым приложениям разного рода услуги: управление удаленными объектами, обслуживание очередей и запросов, обработка интерфейсов и т. п.
Доступ к услугам осуществляется с помощью разных механизмов:
RPC- вызов задает интерфейс удаленным программам в языках высокого или низкого уровней. Язык высокого уровня служит для задания в RPC-вызове параметров удаленной процедуры, которые передаются ей через сетевое сообщение. Язык низкого уровня позволяет указывать более подробную информацию удаленной процедуре: тип протокола, размер буфера данных и т. п.
8.1.2. Интерфейс в среде клиента и сервера
Интерфейс в IDL или в API включает описание формальных и фактических параметров программ, их типов и порядка задания операций передачи параметров и результатов при их взаимодействии. Это описание есть не что иное, как спецификация интерфейсного посредника двух разноязыковых программ (аналогично, как на рис. 8.1), которые взаимодействуют друг с другом через механизм вызова интерфейсных функций или посредников двух типов программ (клиент и сервер), выполняемых на разных процессах.
В функции интерфейсного посредника клиента входят:
Общие функции интерфейсного посредника сервера состоят в следующем:
Описание интерфейсного посредника не зависит от ЯП взаимодействующих объектов и в целом одинаково для всех вызывающих и вызываемых объектов. Посредник описывается в языке спецификации интерфейса IDL.
Интерфейсные посредники задают связь между клиентом и сервером ( stub для клиента и skeleton для сервера). Их описания отображаются в те ЯП, в которых представлены соответствующие им объекты или компоненты. Эти интерфейсы используются в системах CORBA, DCOM, LAVA и др. Они предоставляют всевозможные сервисы разработки и выполнения приложений в распределенной среде. Системные сервисы подключаются к приложению с помощью брокера. Брокер обеспечивает интероперабельность компонентов и объектов при переходе из одной среды другую.
Под интероперабельностью понимается способность совместного, согласованного взаимодействия разнородных компонентов системы для решения определенной задачи.
К средствам обеспечения интероперабельности и передачи данных между разными средами и платформами относится, например, стандартный механизм связи между JAVA и C/C++ компонентами, основанный на применении концепции Java Native Interface ( JNI ), реализованной как средство обращения к функциям из JAVA- классов и библиотек, разработанных на других языках.
Еще вариант реализации аналогичной задачи предлагает технология Bridge2Java,которая обеспечивает обращение из JAVA- классов к COM-компонентам. В этих целях генерируется оболочка для COM-компонента, который включает прокси-класс, обеспечивает необходимое преобразование данных средствами стандартной библиотеки преобразований типов. Данная схема не требует изменений в исходном Java-классе и COM-компоненты могут быть написаны в разных языках.
REST, что же ты такое? Понятное введение в технологию для ИТ-аналитиков
Мы подготовили статью Андрея Буракова на основе его вебинара на нашем YouTube-канале:
Проектирование и работа с REST-сервисами стали повседневными задачами для многих аналитиков. Однако мы часто встречаемся на работе с различными или даже противоречащими друг другу трактовками таких понятий, как REST, RESTful-сервис, RESTAPI.
Сегодня мы разберём, какие принципы вложил в парадигму REST её автор и как они могут помочь нам при проектировании систем.
Выясним, почему существует терминологическая путаница вокруг REST и как нам научиться лучше понимать коллег.
Поговорим о том, как связаны HTTP и REST. А также почему REST противопоставляют SOAP.
Терминология
Формат представления данных
Давайте представим, что я живу в девятнадцатом веке и хочу отправить письмо своему клиенту, который заинтересован в покраске своего автомобиля. Разумеется, я должен написать в письме про то, какие цвета для покраски автомобиля имеются в автосалоне.
Перед тем, как отправить письмо, я беру лист бумаги и пишу клиенту, что в автосалоне сейчас доступны цвета: синий, зелёный, красный, белый, чёрный.
Но я мог бы написать это и на английском: blue, green, red, white, black.
Выходит, что одна и та же информация может быть представлена разными способами. И такой способ представления одной и той же информации разными способами будем называть форматом представления данных.
Plain text — это обычный текст, который я использовал при написании письма;
XML — язык разметки информации;
JSON — текстовый формат обмена данными;
Binary — бинарный формат.
Давайте запомним из этой части статьи что XML и JSON — это форматы представления данных.
Протокол передачи данных
Я написал письмо и теперь хочу его отправить. Что мне нужно для этого сделать? Как правило, я кладу письмо в конверт. В нашем случае таким конвертом будет такое понятие, как протокол передачи данных.
Протокол передачи данных — это набор соглашений, которые определяют обмен данными между различными программами. Эти соглашения задают единообразный способ передачи сообщений и обработки ошибок.
 Аналогия протокола передачи данных с письмом в конверте
Аналогия протокола передачи данных с письмом в конверте
Если продолжать рассматривать аналогию с письмом, то стоит обратить, что:
1. конверт имеет структуру;
2. я наклеиваю на конверт марки, указываю определённую информацию: от кого письмо, куда я его отправляю, адрес и т.д.
Транспорт
Получил письмо в конверте, всё здорово! Но нужно его как-то отправить. Как мне его отправить? Я воспользуюсь услугами почты. Что для этого нужно сделать? Прийти на почту, отдать письмо. Затем его кто-то должен доставить, используя некоторый транспорт.
Транспорт — это подмножество сетевых протоколов, с помощью которых мы можем передавать данные по сети.
Такими протоколами могут быть, например: HTTP, AMQP, FTP.
Если продолжать аналогию с письмом, то почтовая служба может отправить это письмо с помощью голубя или, например, с помощью совы. Вроде бы, письмо одно и то же. Конверт (протокол) один и тот же, формат данных один и тот же, но, обратите внимание — транспорт разный.
Протокол HTTP
HyperText Transfer Protocol (HTTP) — это протокол передачи данных. Изначально для передачи данных в виде гипертекстовых документов в формате HTML, сегодня — для передачи произвольных данных.
Этот протокол имеет две особенности, которые должны учитывать все, кто работает с этим протоколом: ресурсы и HTTP-глаголы.
Ресурсы
Чтобы разобраться с понятием ресурса, давайте представим, что у нас имеется некоторая ссылка: http://webinar.ru/schedule/speech.
Это как раз и есть тот самый URL, который мы используем поверх HTTP. Рассмотрим, из чего состоит эта ссылка:
А вот как нам работать с этими объектами, нам говорят HTTP-глаголы (методы).
HTTP-глаголы
HTTP-глаголы — это элемент протокола HTTP, который используется в каждом запросе, чтобы указать, какое действие нужно выполнить над данным ресурсом.
GET/schedule/speech/id413 — получить информацию об объекте
Здесь мы видим некоторый объект (ресурс) с конкретным идентификатором с номером 413. Я могу использовать HTTP-глагол GET для, того чтобы получить информацию о выступлении 413.
Я могу воспользоваться каким-либо другим HTTP-глаголом, если мне необходимо выполнить какие-либо другие действия.
PUT/schedule/speech/id413 — создать или перезаписать объект
Или удалить объект:
Главное здесь то, что мы рассматриваем некоторые объекты (ресурсы) и совершаем над ними некоторые действия, которые определены в протоколе списком HTTP-методов: GET, PUT, POST, DELETE и т.д.
Что такое REST?
Какое же определение в понятие REST заложил его основатель Рой Филдинг?
Representational State Transfer — это архитектурный стиль взаимодействия компонентов распределённого приложения в сети. Архитектурный стиль – это набор согласованных ограничений и принципов проектирования, позволяющий добиться определённых свойств системы.
Но зачем нам REST? Зачем нам этот стиль? Что нам даст применение принципов REST?
Если мы обратимся опять же к первоисточнику — к работе Филдинга, то мы выясним, что назначение REST в том, чтобы придать проектируемой системе такие свойства как:
Гибкость к изменениям,
Это наиболее ценные свойства, с которыми встречается, например, аналитик при проектировании систем. В действительности их намного больше. Если внимательно посмотреть на эти свойства, то мы увидим ни что иное, как нефункциональные требования к системе, которых мы на своих проектах стремимся достичь.
Принципы REST
Каким образом REST может помочь нам достичь этих свойств и реализовать эти нефункциональные требования?
Чтобы это понять, давайте рассмотри 6 принципов REST — ограничений, которые и помогают нам добиться этих нефункциональных требований.
6 принципов REST:
Далее мы рассмотрим эти шесть принципов поподробнее.
Принцип 1. Клиент-серверная архитектура
Сама концепция клиент-серверной архитектуры заключается в разделении некоторых зон ответственности: в разделении функций клиента и сервера. Что это означает?
Например, мы разделяем нашу систему так, что клиент (допустим, это мобильное приложение) реализует только функциональное взаимодействие с сервером. При этом сервер реализует в себе логику хранения данных, сложные взаимодействия со смежными системами и т.д.
Что мы этим добиваемся и как могло бы быть иначе? Давайте представим, что клиент и сервер у нас объединены. Тогда, если мы говорим о мобильном приложении, каждое мобильное приложение каждого клиента должно было бы быть абсолютно самодостаточной единицей. И тогда, поскольку у нас единого сервера нет для получения/отправки информации, у нас получилась бы какая-то сеть единообразных компонентов – например, мобильные приложения общались бы друг с другом – такая распределённая сеть равноценных узлов.
Такие системы в реальной жизни есть и можно найти их примеры. Например, в блокчейне. Тем не менее, в случае с REST мы говорим о том, что разделяем ответственность. Например, отображение информации, её обработку и хранение.
Клиент-серверная архитектура
Также сервер может иметь базу данных (см. рисунок ниже). В данном случае надо понимать, что пара «сервер и БД» тоже будет парой «клиент-сервер». Только в данном случае сервером будет БД, а сам сервер — клиентом.
Трёхзвенная архитектура
Что дает клиент-серверная архитектура и зачем она нужна?
Во-первых, клиент-серверная архитектура дает нам определённую масштабируемость: есть сервер, есть единая точка обработки запросов. При необходимости выдерживать большую нагрузку мы можем поставить несколько серверов. Также к нему можно подключать достаточно большое количество клиентов (сколько сможет выдержать). Таким образом, клиент-серверная архитектура позволяет добиться масштабируемости.
Во-вторых, REST даёт определённую простоту поддержки. Если мы хотим изменить логику обработки информации на сервере, то выполним эти изменения на сервере. В данном случае мы можем и не менять каждого клиента, как если бы они были абсолютно равноценной сетью.
Конечно, есть и минусы. В случае с клиент-серверной архитектурой мы понимаем, что у нас есть единая точка отказа в виде сервера. Если отказал сервер и у нас нет дополнительных инстансов, то для нас это будет означать неработоспособность системы.
Также потенциально может увеличиться нагрузка, поскольку часть логики мы вынесли с клиента на сервер. Клиент будет совершать меньше каких-либо действий самостоятельно, соответственно, у нас возрастёт количество запросов между клиентом и сервером.
Принцип 2. Stateless
Принцип заключается в том, что сервер не должен хранить у себя информацию о сессии с клиентом. Он должен в каждом запросе получать всю информацию для обработки.
Пример реализации принципа Stateless. Запрос погоды на 20.06 в Москве
Представим, что у нас есть некоторый сервис прогноза погоды, в котором уже реализована клиент-серверная архитектура, и мы хотим получить сообщение о прогнозе погоды на завтра.
Что мы делаем в случае, если мы работаем с Stateless? Мы отправляем запрос «Какая погода?», отправляем место, где хотим погоду узнать, и дату. Соответственно, прогноз погоды отвечает нам — «Будет жарко».
Если я захочу узнать, какая будет погода через день, то опять укажу место, где хочу узнать погоду, укажу другую дату. Сервер получит этот запрос, обработает и сообщит мне, что там уже будет очень жарко.
Пример реализации принципа Stateless. Запрос погоды на 21.06 в Москве
Рассмотрим ситуацию: что было бы, если бы у нас не было Stateless? В таком случае у нас бы был Stateful. В этом случае сервер хранит информацию о предыдущих обращениях клиента, хранит информацию о сессии, какую-то часть контекста взаимодействия с клиентом. А затем может использовать эту информацию при обработке следующих запросов.
Приведём пример на рисунке:
Пример реализации принципа Stateful
Я всё так же хочу узнать, какая погода будет завтра: отправляю запрос, сервер его обрабатывает, формирует ответ и, помимо того, что он возвращает ответ клиентам, он еще сохраняет какую-то информацию (часть или всю) о том, какой запрос он получил. В случае, если я захочу узнать, какая погода будет через день, я могу сделать такой вызов: «А завтра?». Не сообщая ничего о месте и о дате.
В этом случае у сервера хранится некоторый контекст. Он понимает, что я у него спрашиваю про 21-е число и могу дать ответ на основе информации, хранимой у него в БД или в кэше. Один из примеров, где можно встретить подход Stateful в жизни — это работа с FTP-сервером.
Вернёмся к Statless-подходу. Почему в REST-архитектуре мы должны использовать именно Statless-подход?
Какие он даёт плюсы?
Уменьшение времени обработки запроса,
Возможность использовать кэширование.
В первую очередь, это масштабирование сервера. Если каждый запрос содержит в себе абсолютно весь контекст, необходимый для обработки, то можно, например, клонировать сервер-обработчик: вместо одного поставить десять таких. Мне будет абсолютно неважно, в какой из этих клонов придёт запрос. Если бы они хранили состояние, то либо должны были синхронизироваться, либо мне нужно было бы умело направлять запрос в нужное место.
Помимо этого, появляется простота поддержки. Каждый раз я вижу в логах, какое сообщение приходило от клиента, какой ответ он получал. Мне не нужно дополнительно узнавать о том, какое состояние хранил сервер.
Также подход Stateless позволяет использовать кэширование.
Какие проблемы может создать Stateless-подход?
Усложнение логики клиента (именно на стороне клиента нам нужно хранить всю информацию о состоянии, о допустимых действиях, о недопустимых действиях и подобных вещах).
Увеличение нагрузки на сеть (каждый раз мы передаём всю информацию, весь контекст. Таким образом, больше информации гоняем по сети).
Принцип 3. Кэширование
В оригинале этот принцип говорит нам о том, что каждый ответ сервера должен иметь пометку, можно ли его кэшировать.
Что такое кэширование?
Представим, что у нас всё так же есть сервис по прогнозу погоды, есть клиент, с которым взаимодействуют. Сам по себе этот сервис погоду не определяет. Погоду определяет метеостанция, с которой он связывается с помощью специальных удалённых вызовов. Что происходит, когда мы используем кэширование?
Например, клиент обратился к серверу с запросом «Хочу узнать погоду». Что делает сервер?
Если мы его только запустили и используем кэширование или если мы не используем кэширование вообще — сервер обратится к метеостанции, а она вернёт ему ответ. Перед тем, как сервер ответит клиенту, он должен сохранить эту информацию в кэше. И только потом вернуть ответ. Для чего?
Когда клиент в следующий раз отправит ровно такой же запрос, сервер сможет не обращаться к метеостанции. Он сможет извлечь прогноз из кэша и вернуть ответ клиенту.
Пример реализации архитектуры с использованием кэширования
Чего мы добились? Мы убрали одну часть взаимодействия между сервером и метеостанцией. Зачем нам это нужно? Это нужно и полезно, если у сервера часто запрашивают одинаковую информацию. Например, кэширование активно используется на новостных сайтах или в соцсетях (на веб-ресурсах, к которым происходит много обращений).
Какие у кэширования плюсы?
Уменьшение количества сетевых взаимодействий.
Уменьшение нагрузки на системы (не грузим их дополнительными запросами).
В каких-то случаях одинаковых обращений будет не так много. Тогда кэширование использовать нет смысла.
При этом важно понимать, что кэширование — это совсем не простая штука. Она бывает достаточно сложна и нетривиальна в реализации.
Также мы должны учитывать, что если отдаём какие-то данные, которые сохранили раньше, то важно помнить, что эти данные могли уже устареть.
В каких-то случаях это может быть приемлемо, но в каких-то случаях — абсолютно недопустимо. Соответственно, стоит ли использовать кэширование — всегда нужно обдумывать на конкретном примере.
Принцип 4. Единообразие интерфейса. HATEOAS
Hypermedia as the Engine of Application State (HATEOAS) — одно из ограничений REST, согласно которому сервер возвращает не только ресурс, но и его связи с другими ресурсами и действия, которые можно с ним совершить.
Рассмотрим пример. Возьмём HTTP-запрос, в котором я хочу получить определенный ресурс:
Пример запроса ресурса
Здесь мы используем HTTP-глагол GET, то есть хотим получить ресурс. Обращаемся к некоторому счёту с номером 12345.
Если бы мы не использовали подход HATEOAS, то получили бы примерно такой XML-ответ:
Пример ответа без использования принципа HATEOAS
Здесь указан номер счёта, баланс и валюта.
Что же предлагает HATEOAS? Если бы мы с учётом этого ограничения выполняли бы этот запрос, то в ответе получим не только информацию об этом объекте, но и все те действия, которые мы можем с ним совершить. И, если бы у него были бы какие-то важные связанные объекты, мы получили бы ещё и ссылки на них.
Пример ответа с использованием принципа HATEOAS
Получая такие ответы, клиент самостоятельно понимает, какие конкретные действия он может совершать над этим объектом и какую ещё информацию о связанных объектах он может получить. Мы даём клиентскому приложению намного больше информации и свободы действий. Логика клиента становится более гибкой, но при этом и более сложной.
Главный плюс этого подхода — клиент становится очень гибким в плане изменений на сервере с точки зрения изменения допустимых действий, изменения модели данных и т.д.
В качестве обратной стороны медали мы получаем сильное усложнение логики, в первую очередь, клиента. Это может потянуть за собой и усложнение логики на сервере, потому что такие ответы нужно правильно формировать. Фактически ответственность за действия, которые совершает клиент, мы передаём на его же сторону. Мы ослабляем контроль валидности совершаемых операций на стороне сервера.
Принцип 5. Layered system (слоистая архитектура)
В предыдущих схемах мы рассматривали сторону клиента и сторону сервера, но не думали, что между ними могут быть посредники.
В реальной жизни между ними могут быть, к примеру, proxy-сервера, роутеры, балансировщики — все, что угодно. И то, по какому пути запрос проходит от клиента до сервера, мы часто не можем знать.
Концепция слоистой архитектуры заключается в том, что ни клиент, ни сервер не должны знать о том, как происходит цепочка вызовов дальше своих прямых соседей.
Модель слоистой архитектуры
Знания балансировщика в этой схеме об участниках конкретно этой цепочки вызовов должны заканчиваться proxy-сервером слева и сервером справа. О клиенте он уже ничего не знает.
Если изменяется поведение proxy-сервера (балансировщика, роутера или чего-то ещё), это не должно повлечь изменения для клиентского приложения или для сервера. Помещая их в эту цепочку вызовов, мы не должны замечать никакой разницы. Это позволяет нам изменять общую архитектуру без доработок на стороне клиента или сервера.
Увеличение нагрузки на сеть (больше участников и больше вызовов, чем если бы мы шли один раз от клиента до сервера напрямую).
Увеличение времени получения ответа (из-за появления дополнительных участников).
Принцип 6. Code on done (код по требованию)
Идея передачи некоторого исполняемого кода (по сути какой-то программы) от сервера клиенту.
Модель архитектуры, реализующей принцип «Код по запросу»
Представьте, что клиент — это, например, обычный браузер. Клиент отправляет некоторый запрос и ждёт ответа — страницу с определённым интерактивом (например, должен появляться фейерверк в том месте, где пользователь кликает кнопкой мышки). Это всё может быть реализовано на стороне клиента.
Либо клиент, запрашивая данную страницу приветствия, получит в ответ от сервера не просто HTML-код для отображения, а ещё программу, которую он сам и исполнит. Получается, что сервер передаёт исходный код клиенту, а тот его выполняет.
Что мы за счёт этого получаем? Отчасти, это схоже с принципом HATEOAS. Мы позволяем клиенту стать гибче. Если мы захотим изменить цвет фейерверка, то нам не нужно вносить изменений на клиенте — мы можем сделать это на сервере, а затем передавать клиенту. Пример такого языка — javascript.
Насколько же сходятся идеи, которые вложил Рэй Филдинг в концепцию REST, с восприятием REST аналитиками?
Давайте рассмотрим наиболее частые заблуждения, которые вы можете встретить относительно концепции REST.
1. Ограничения REST опциональны (необязательны)
С точки зрения создателя этой концепции существует ровно одно необязательное ограничение — код по требованию. Все остальные ограничения должны выполняться. Если одно из них не выполняется — это уже не REST-подход.
2. REST — протокол передачи данных
REST — это не протокол передачи данных. Он не определяет правила о том, как мы должны передавать запросы, какая у них должна быть структура, что мы должны возвращать в ошибках. Единственное, что косвенно можно было бы приписать — это указание на то, что каждый ответ сервера должен содержать информацию о том, можно ли его кэшировать.
Но, в целом, REST — это концепция, парадигма, но не протокол. В отличие от HTTP, который действительно является протоколом.
3. REST — это всегда HTTP
С одной стороны, ни один из архитектурных принципов REST не говорит нам о том, какой транспорт мы должны использовать — HTTP или очереди.
Но при этом в жизни очень часто встречаются люди, для которых REST и HTTP — это аксиома.
Поэтому, если сказать человеку, что REST — это необязательно HTTP, то вас могут посчитать сумасшедшими.
Почему же все считают, что REST — это HTTP? Здесь нужно сделать ремарку, что одним из главных авторов протокола HTTP — это Рэй Филдинг, автор концепции REST. Рэй Филдинг стремился спроектировать HTTP так, чтобы с помощью него концепцию REST было максимально удобно реализовывать.
4. REST — это обязательно JSON
Почему так сложилось? Главная причина в том, что какое-то время назад сервисы вида JSON over HTTP стали противопоставлять SOAP. JSON одновременно стал популярным и стал антагонистом XML, как SOAP подходу. JSON использовался, потому что это не SOAP.
Модель зрелости REST-сервисов
Ричардсон выделил уровни зрелости REST-сервисов. Выделение происходило исходя из подхода, что REST — это, с точки зрения протокола, всё-таки HTTP. Соответственно, он спроектировал модель, по которой можно понять: насколько сервис REST или не REST.
Уровень 0
В первую очередь, он выделил нулевой уровень. К нему относятся любые сервисы, которые в качестве транспорта используют HTTP и какой-то формат представления данных. Например, когда мы говорим про JSON over HTTP – мы говорим про нулевой уровень.
Если более наглядно «пощупать ручками» с точки зрения использования протокола HTTP, то можно представить, что мы выставляем некоторый API. Мы начинаем с того, что объявляем единый путь для отправки команд и всегда используем один и тот же HTTP-глагол для совершения абсолютно любых действий с любыми объектами. Например: создай вебинар, запиши вебинар, удали вебинар и т.д. То есть мы всегда используем один и тот же URL и всегда используем один и тот же HTTP-метод, обычно POST.
Как один из примеров:
Пример 0-го уровня соответствия REST
Уровень 1
Следующий уровень — первый. Мы уже научились использовать разные ресурсы и делаем это не по одному URL. Но при этом всё ещё игнорируем HTTP-глаголы.
Мы просто разделяем явно наши объекты, как некоторые ресурсы. Например: спикер, курс, вебинар. Но, независимо от того, что мы хотим сделать — удалить, создать, редактировать, мы всё равно используем один и тот же HTTP-глагол POST.
Пример 1-го уровня соответствия REST
Уровень 2
Второй уровень — это когда мы начинаем правильно с точки зрения спецификации HTTP-протокола использовать HTTP-глаголы.
Например, если есть спикер, то, чтобы создать спикера и получить информацию о нём, я использую соответствующий глагол: GET, POST. Когда хочу создать или удалить спикера — я использую глаголы: PUT, DELETE.
По сути, второй уровень зрелости — это то, что чаще всего называют REST.
Надо понимать, что, с точки зрения изначальной концепции, если мы дошли до второго уровня зрелости, то это еще не означает, что мы спроектировали REST-систему/ REST-сервис. Но в очень распространённом понимании соответствие 2-ому уровню часто называют RESTfull сервисом.
RESTfull-сервис — это такой сервис, который спроектирован с учётом REST-ограничений. Хотя, в целом, правильнее сервис такого уровня зрелости называть HTTP-сервисом или HTTP-API, нежели REST-API.
Пример 2-го уровня соответствия REST
Уровень 3
Третий уровень зрелости — это уровень, в котором мы начинаем использовать концепцию HATEOAS. Когда мы передаём информацию, ресурсы, мы сообщаем потребителям (клиентам) о том, какие ещё действия необходимо совершить ресурсу, а также связи с другими ресурсами.
Пример 3-го уровня соответствия REST
Выводы, которые мы можем сделать из модели зрелости
Итак, как нам эта модель может помочь понять то, что наши коллеги называют RESTом в каждой отдельно взятой компании? REST у вас или не REST?
Первая распространенная трактовка термина REST — всё, что передаётся в виде JSON поверх HTTP.
Вторая, не менее популярная версия, REST — это сервис второго уровня зрелости, то есть HTTP-API, составленное в соответствии со спецификацией HTTP-протокола. Если мы правильно выделяем ресурсы, правильно используем HTTP-глаголы, а также выполняем некоторые требования HTTP-протокола, то у нас REST.
Что называют RESTом?
Подведём итоги
Во-первых, у каждого свой REST. Мнения о том, что такое REST, часто разнятся. Когда мы работаем с новыми проектами, новыми коллегами или специалистами, очень важно понять, что именно ваш коллега называет RESTом. Это полезно для того, чтобы на одном из этапов проектирования или разработки не оказалось, что мы половину проекта говорили о разных вещах.
Во-вторых, принципы REST мы часто применяем в жизни. Они очень полезны для осмысления. Кэширование, STATELESS и STATEFUL, клиент-серверная модель или код по требованию — это те вещи, которые аналитику полезно знать для понимания.
Третье — это то, что парадигма REST помогает нам выявить и определить важнейшие свойства архитектуры — масштабируемость, производительность и т.д.
1. Способы описания API
2. Инструменты для тестирования API



