Что означает в Python?
Когда мы начинаем работу с пандами или даже просматриваем веб-сайты для запросов, связанных с операциями с пандами, мы часто сталкиваемся с параметром inplace, присутствующим в
В этой статье мы рассмотрим функцию параметра inplace при выполнении операций с фреймом данных.
Что Делает Параметр inplace?
inplace=True используется в зависимости от того, хотим ли мы внести изменения в исходный df или нет.
Давайте рассмотрим операцию удаления строк, из которых были удалены записи NA. у нас есть фрейм данных (df).
В Панд приведенный выше код означает:
Итак, когда мы делаем df.dropna(axis=’index’,,) панды знают, что мы хотим изменить исходный фрейм данных, поэтому он выполняет необходимые изменения в исходном фрейме данных.
На месте В действии
Теперь давайте выполним операцию сортировки по длине лепестка функции
Теперь давайте проверим, что произошло с нашим исходным фреймом данных.
Мы просто получили исходный фрейм данных при печати даже после того, как применили к нему операцию сортировки.
Так… что только что произошло?
Приведенный выше пример лучше всего демонстрирует применение параметра inplace.
По умолчанию установлено значение False, и из-за этого операция не изменяет исходный кадр данных. Вместо этого он возвращает копию, на которой выполняются операции.
Как и в приведенном выше коде, мы не назначили возвращаемый фрейм данных какой-либо новой переменной, мы не получили новый фрейм данных, который сортируется.
Мы просто назначили возвращенный фрейм данных переменной, которую мы назвали new_df.
Теперь это отсортированная копия исходного фрейма данных.
Важным моментом, который следует учитывать здесь, является то, что исходный фрейм данных по-прежнему остается прежним и претерпел все указанные нами преобразования.
Теперь давайте посмотрим, что произойдет, если мы установим на место
Запуск кода, похоже, не возвращает выходных данных. но подождите…!
Исходный фрейм данных был изменен после того, как мы установили в Python.
Вывод
Эта статья была полностью посвящена параметру inplace. Теперь у нас есть определенное представление об этом скрытом параметре, который часто находится в функции, даже не осознавая этого.
В качестве заключительной мысли, мы должны быть очень осторожны при использовании, поскольку он изменяет исходный фрейм данных.
Предобработка данных на Python
Статья выполнена в виде инструкции с пошаговым прогрессом. Пороговый вход для понимания материала не высокий, но кое-что все же нужно знать:
Исходные данные:
На входе у нас есть Data Frame с данными о поле (м или ж), возрасте, контактной информацией, а также признаком. Для тех, кто не любит абстрагироваться признак – это ответ на вопрос «Играете ли вы в компьютерные игры?» и он может принимать одно из двух значений (да или нет)
Шаг 1. Знакомство с данными
На первом этапе важно, посмотреть, что за данные у нас на руках: какие столбцы, какие типы данных, какие значения принимают данные.
Выведем первые строки методом head():
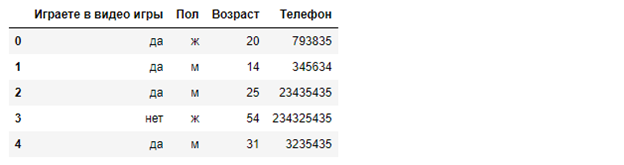
Посмотрим сводную информацию методом info():
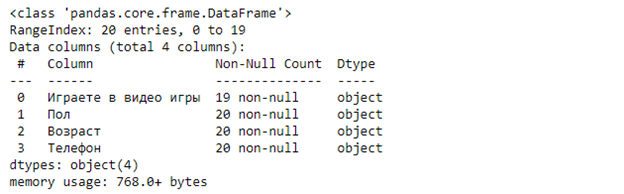
Метод info() дает много информации, из которой мы узнаем, что в таблице: 20 строк, 4 столбца, видим типы данных для каждого столбца и количество не нулевых значений.
Шаг 2. Переименование столбцов
Является необязательным шагом, но он делает дальнейшие действия более удобными, а внешний вид приятным. Обычной рекомендацией для названия столбцов является: применение латиницы в названии, нижний регистр, а также отсутствие пропусков в имени столбца (заменяется на символ «_»). Для переименования столбцов применим метод set_axis():

Шаг 3. Пропуски данных
В зависимости от решаемых задач, пропущенные значения могут быть либо удалены методом dropna() (может быть удален как столбец, в котором есть хоть одно пропущенное значение, так и строка).
В зависимости от данных и решаемой задачи пропущенные значения могут быть заменены на характерные значения: среднее арифметическое или медиана. Также стоит отметить, что пропущенные значения могут «маскироваться» (например под None), для определения этого, можно сначала выполнить поиск уникальных значений методом unique().
Удалим все строки, в которых пропущено значение в столбце ‘tag’ методом dropna():
Заменим пропущенный возраст ‘age’, на средний возраст, характерный для определенного пола с определенным признаком, но перед этим проверим какие уникальные значения принимаются в данном столбце. Затем применим метод replace() к значениям ‘None’ и заменим их на NaN:
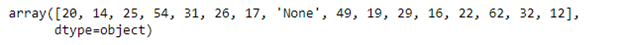
Выведем на экран срез данных с пропущенными значениями в столбце ‘age’ применив метод isnull():

Заменим пропущенные значения методом fillna() на средний возраст играющих в компьютерные игры мужчин (пропущенные значения соответствуют этим признакам):

Шаг 4. Дубликаты
Для нахождения дубликатов применяется метод duplicated(), совместно с методом sum() можно определить количество дубликатов.
Для удаления дубликатов используем методом следующую конструкцию:
Метод reset_index() необходим для изменения индексации, так как drop_duplicates() вместе со строками удаляет и их индексы.
Проверим наличие дубликатов:


Удалим дубликаты и проверим результат:

Шаг 5. Изменение типов данных
Проверим как сейчас выглядят наши данные. Для просмотра типа данных воспользуемся атрибутом dtypes:


Для того, чтобы они стали более «нарядными», нужно изменить тип данных в столбцах ‘age’ и ‘phone_num’ на int.
Для перевода значений формата string в числовой формат применяется метод библиотеки Pandas to_numeric(). От значения errors метода to_numeric(), зависят действия при работе с некорректным значением:
Применим метод to_numeric() к столбцу ‘phone_num’:

Для того, чтобы перевести данные в нужный тип, применяется метод astype():
При вызове метода была получена ошибка:

Она возникает, когда в столбце есть данные, принимающие значения NaN. Решением может быть или замена NaN на 0, или на NA. Заменим на NA и поменяем типы данных в нужных столбцах:
Посмотрим на достигнутый результат:
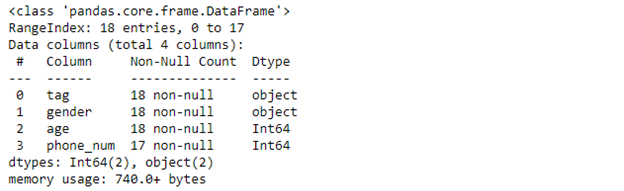

Можно считать задачу решенной, данные подготовлены к дальнейшему анализу.
Заключение
На этом статья подошла к концу, вспомним чему мы научились:
Понимание на месте = True
9 ответов
Когда inplace=True передается, данные переименовываются на место (ничего не возвращает), поэтому вы должны использовать:
Когда передается inplace=False (это значение по умолчанию, поэтому не нужно), выполняет операцию и возвращает копию объекта, поэтому вы должны использовать:
Сохраните его в той же переменной
Сохраните его в отдельной переменной
Но вы всегда можете перезаписать переменную
К вашему сведению: по умолчанию inplace = False
inplace=True используется в зависимости от того, хотите ли вы внести изменения в исходный df или нет.
Будет только просматривать пропущенные значения, но не вносит никаких изменений в df
Будет сбрасывать значения и вносить изменения в DF.
Надеюсь это поможет.:)
inplace=True делает функцию нечистой. Он изменяет исходный фрейм данных и возвращает None. В этом случае Вы разрываете цепочку DSL. Поскольку большинство функций dataframe возвращают новый dataframe, вы можете удобно использовать DSL. подобно
Вызов функции с inplace=True возвращает None и цепочка DSL разорвана. Например
Бросит NoneType object has no attribute ‘rename’
Что касается моего опыта в пандах, я бы хотел ответить.
Аргумент «inplace = True» означает, что фрейм данных должен сделать изменения постоянными, например.
Изменяет тот же самый фрейм данных (поскольку эта панда находит NaN-записи в индексе и удаляет их). Если мы попробуем
Pandas показывает информационный кадр с изменениями, которые мы вносим, но не будет изменять исходный информационный кадр ‘df’.
Если вы не используете inplace = True или inplace = False, вы в основном получаете обратно копию.
Изменит структуру с данными, отсортированными в порядке убывания.
Сделаю testdf2 копию. все значения будут одинаковыми, но сортировка будет обратной, и у вас будет независимый объект.
Затем дали другой столбец, скажите LongMA, и вы делаете:
Столбец LongMA в testdf будет иметь исходные значения, а testdf2 будет иметь отклоненные значения.
Важно отслеживать разницу, поскольку цепочка вычислений растет, а копии фреймов данных имеют собственный жизненный цикл.
В Pandas и вообще означает:
1. Pandas создает копию исходных данных.
1. Ваш код будет сложнее отлаживать (на самом деле SettingwithCopyWarning стоит предупредить вас об этой возможной проблеме)
2. Конфликт с цепочкой методов
Значит, есть даже случай, когда мы должны его использовать?
Определенно, да. Если мы используем pandas или любой другой инструмент для работы с огромным набором данных, мы легко можем столкнуться с ситуацией, когда некоторые большие данные могут занимать всю нашу память. Чтобы избежать этого нежелательного эффекта, мы можем использовать некоторые техники, такие как метод сцепление :
Окончательное заключение.
И последнее, о чем следует помнить: вызов inplace=True может вызвать SettingWithCopyWarning :
Который может вызвать неожиданное поведение. Используйте с осторожностью!
What Does inplace = True Mean in Python?

When getting started with pandas or even surfing on websites for queries related to pandas operations, we often come across the inplace parameter present in the code. The default value for inplace is set to False.
In this article, we’ll explore the function of inplace parameter when performing operations on Dataframe.
What Does The inplace Parameter Do?
inplace=True is used depending on if we want to make changes to the original df or not.
Let’s consider the operation of removing rows having NA entries dropped from it. we have a Dataframe (df).
In Pandas the above code means:
The above code returns nothing but modifies the original Dataframe.
If inplace set to False then pandas will return a copy of the Dataframe with operations performed on it.
In Pandas we have many functions that has the inplace parameter.
So, when we do df.dropna(axis=’index’, how=’all’, inplace=True) pandas know we want to change the original Dataframe, therefore it performs required changes on the original Dataframe.
Inplace = True In Action
Let’s see the inplace parameter in action. We’ll perform sorting operation on the IRIS dataset to demonstrate the purpose of inplace parameter.
You can know more about loading the iris dataset here.
Let’s now perform a sorting operation on petal length feature
Now let’s check what happened to our Original dataframe.
We just got the original Dataframe when printed even after we applied the sorting operation on it.
So… what just happened?
The above example best demonstrates the application of inplace parameter.
By default, it is set to False and due to this, the operation does not modify the original Dataframe. Instead, it returns a copy on which the operations are performed.
As in the above code, we did not assign the returned Dataframe to any new variable, we did not get a new Dataframe which is sorted.
We just assigned the returned Dataframe to a variable we named as new_df.
It is now a sorted copy of the original Dataframe.
An important point to consider here is that the original Dataframe is still the same and did undergo any transformation we specified.
Now let’s see what happens if we set inplace = True
Running the code seems to return no output. but wait.
After checking the original Dataframe we get the essence of what inplace = True is doing.
The original Dataframe got modified after we set inplace=true in Python.
Conclusion
This article was all about the inplace parameter. We now have a certain idea about this sneaky parameter that often sits around in a function without us even realizing it.
As a final thought, we should be very careful while using inplace=True as it modifies the original data frame.
Моя шпаргалка по pandas
Один преподаватель как-то сказал мне, что если поискать аналог программиста в мире книг, то окажется, что программисты похожи не на учебники, а на оглавления учебников: они не помнят всего, но знают, как быстро найти то, что им нужно.
Возможность быстро находить описания функций позволяет программистам продуктивно работать, не теряя состояния потока. Поэтому я и создал представленную здесь шпаргалку по pandas и включил в неё то, чем пользуюсь каждый день, создавая веб-приложения и модели машинного обучения.

1. Подготовка к работе
Если вы хотите самостоятельно опробовать то, о чём тут пойдёт речь, загрузите набор данных Anime Recommendations Database с Kaggle. Распакуйте его и поместите в ту же папку, где находится ваш Jupyter Notebook (далее — блокнот).
Теперь выполните следующие команды.
После этого у вас должна появиться возможность воспроизвести то, что я покажу в следующих разделах этого материала.
2. Импорт данных
▍Загрузка CSV-данных
Здесь я хочу рассказать о преобразовании CSV-данных непосредственно в датафреймы (в объекты Dataframe). Иногда при загрузке данных формата CSV нужно указывать их кодировку (например, это может выглядеть как encoding=’ISO-8859–1′ ). Это — первое, что стоит попробовать сделать в том случае, если оказывается, что после загрузки данных датафрейм содержит нечитаемые символы.

▍Создание датафрейма из данных, введённых вручную
Это может пригодиться тогда, когда нужно вручную ввести в программу простые данные. Например — если нужно оценить изменения, претерпеваемые данными, проходящими через конвейер обработки данных.
Данные, введённые вручную
▍Копирование датафрейма
Копирование датафреймов может пригодиться в ситуациях, когда требуется внести в данные изменения, но при этом надо и сохранить оригинал. Если датафреймы нужно копировать, то рекомендуется делать это сразу после их загрузки.
3. Экспорт данных
▍Экспорт в формат CSV
При экспорте данных они сохраняются в той же папке, где находится блокнот. Ниже показан пример сохранения первых 10 строк датафрейма, но то, что именно сохранять, зависит от конкретной задачи.
4. Просмотр и исследование данных
▍Получение n записей из начала или конца датафрейма
Сначала поговорим о выводе первых n элементов датафрейма. Я часто вывожу некоторое количество элементов из начала датафрейма где-нибудь в блокноте. Это позволяет мне удобно обращаться к этим данным в том случае, если я забуду о том, что именно находится в датафрейме. Похожую роль играет и вывод нескольких последних элементов.
Данные из начала датафрейма
Данные из конца датафрейма
▍Подсчёт количества строк в датафрейме
▍Подсчёт количества уникальных значений в столбце
Для подсчёта количества уникальных значений в столбце можно воспользоваться такой конструкцией:
▍Получение сведений о датафрейме
В сведения о датафрейме входит общая информация о нём вроде заголовка, количества значений, типов данных столбцов.
Сведения о датафрейме
▍Вывод статистических сведений о датафрейме
Знание статистических сведений о датафрейме весьма полезно в ситуациях, когда он содержит множество числовых значений. Например, знание среднего, минимального и максимального значений столбца rating даёт нам некоторое понимание того, как, в целом, выглядит датафрейм. Вот соответствующая команда:
Статистические сведения о датафрейме
▍Подсчёт количества значений
Для того чтобы подсчитать количество значений в конкретном столбце, можно воспользоваться следующей конструкцией:
Подсчёт количества элементов в столбце
5. Извлечение информации из датафреймов
▍Создание списка или объекта Series на основе значений столбца
Это может пригодиться в тех случаях, когда требуется извлекать значения столбцов в переменные x и y для обучения модели. Здесь применимы следующие команды:
Результаты работы команды anime[‘genre’].tolist()
Результаты работы команды anime[‘genre’]
▍Получение списка значений из индекса
Результаты выполнения команды
▍Получение списка значений столбцов
Вот команда, которая позволяет получить список значений столбцов:
Результаты выполнения команды
6. Добавление данных в датафрейм и удаление их из него
▍Присоединение к датафрейму нового столбца с заданным значением
Иногда мне приходится добавлять в датафреймы новые столбцы. Например — в случаях, когда у меня есть тестовый и обучающий наборы в двух разных датафреймах, и мне, прежде чем их скомбинировать, нужно пометить их так, чтобы потом их можно было бы различить. Для этого используется такая конструкция:
▍Создание нового датафрейма из подмножества столбцов
Это может пригодиться в том случае, если требуется сохранить в новом датафрейме несколько столбцов огромного датафрейма, но при этом не хочется выписывать имена столбцов, которые нужно удалить.
Результат выполнения команды
▍Удаление заданных столбцов
Этот приём может оказаться полезным в том случае, если из датафрейма нужно удалить лишь несколько столбцов. Если удалять нужно много столбцов, то эта задача может оказаться довольно-таки утомительной, поэтому тут я предпочитаю пользоваться возможностью, описанной в предыдущем разделе.
Результаты выполнения команды
▍Добавление в датафрейм строки с суммой значений из других строк
Результат выполнения команды
Команда вида df.sum(axis=1) позволяет суммировать значения в столбцах.
7. Комбинирование датафреймов
▍Конкатенация двух датафреймов
Эта методика применима в ситуациях, когда имеются два датафрейма с одинаковыми столбцами, которые нужно скомбинировать.
В данном примере мы сначала разделяем датафрейм на две части, а потом снова объединяем эти части:
Датафрейм, объединяющий df1 и df2
▍Слияние датафреймов
Результаты выполнения команды
8. Фильтрация
▍Получение строк с нужными индексными значениями
Индексными значениями датафрейма anime_modified являются названия аниме. Обратите внимание на то, как мы используем эти названия для выбора конкретных столбцов.
Результаты выполнения команды
▍Получение строк по числовым индексам
Следующая конструкция позволяет выбрать три первых строки датафрейма:
Результаты выполнения команды
▍Получение строк по заданным значениям столбцов
Для получения строк датафрейма в ситуации, когда имеется список значений столбцов, можно воспользоваться следующей командой:
Результаты выполнения команды
Если нас интересует единственное значение — можно воспользоваться такой конструкцией:
▍Получение среза датафрейма
Эта техника напоминает получение среза списка. А именно, речь идёт о получении фрагмента датафрейма, содержащего строки, соответствующие заданной конфигурации индексов.
Результаты выполнения команды
▍Фильтрация по значению
Из датафреймов можно выбирать строки, соответствующие заданному условию. Обратите внимание на то, что при использовании этого метода сохраняются существующие индексные значения.
Результаты выполнения команды
9. Сортировка
Для сортировки датафреймов по значениям столбцов можно воспользоваться функцией df.sort_values :
Результаты выполнения команды
10. Агрегирование
▍Функция df.groupby и подсчёт количества записей
Вот как подсчитать количество записей с различными значениями в столбцах:
Результаты выполнения команды
▍Функция df.groupby и агрегирование столбцов различными способами
▍Создание сводной таблицы
Для того чтобы извлечь из датафрейма некие данные, нет ничего лучше, чем сводная таблица. Обратите внимание на то, что здесь я серьёзно отфильтровал датафрейм, что ускорило создание сводной таблицы.
Результаты выполнения команды
11. Очистка данных
▍Запись в ячейки, содержащие значение NaN, какого-то другого значения
Таблица, содержащая значения NaN
Результаты замены значений NaN на 0
12. Другие полезные возможности
▍Отбор случайных образцов из набора данных
Результаты выполнения команды
▍Перебор строк датафрейма
Следующая конструкция позволяет перебирать строки датафрейма:
Результаты выполнения команды
▍Борьба с ошибкой IOPub data rate exceeded
Если вы сталкиваетесь с ошибкой IOPub data rate exceeded — попробуйте, при запуске Jupyter Notebook, воспользоваться следующей командой:
Итоги
Здесь я рассказал о некоторых полезных приёмах использования pandas в среде Jupyter Notebook. Надеюсь, моя шпаргалка вам пригодится.



