Innodb mysql что это
InnoDB предназначается для получения максимальной производительности при обработке больших объемов данных. По эффективности использования процессора этот тип намного превосходит другие модели реляционных баз данных с памятью на дисках.
Технически InnoDB является завершенной системой управления базой данных в рамках MySQL. В InnoDB есть свой собственный буферный пул для кэширования данных и индексов в основной памяти. Таблицы и индексы InnoDB хранятся в специальном пространстве памяти, которое может состоять из нескольких файлов. В этом заключается отличие InnoDB от, например, таблиц MyISAM: каждая таблица MyISAM хранится в отдельном файле. Таблицы InnoDB могут быть любого размера даже в тех операционных системах, где установлено ограничение файла в 2 Гб.
Свежую информацию по InnoDB можно найти на http://www.innodb.com/. Здесь же находится последняя версия руководства по InnoDB. Кроме того, можно заказать коммерческие лицензии и поддержку для InnoDB.
В настоящий момент (октябрь 2001 года) таблицы InnoDB применяются на нескольких больших сайтах баз данных, для которых важна высокая производительность. Так, таблицы InnoDB используются на популярном сайте новостей Slashdot.org. Формат InnoDB применяется для хранения более 1Тб данных компании Mytrix, Inc; можно привести пример еще одного сайта, где при помощи при помощи InnoDB обрабатывается средняя нагрузка объемом в 800 вставок/обновлений в секунду.
Однако чтобы добиться высокой скорости работы, лучше указать рекомендуемые параметры. See section 7.5.2 Параметры запуска InnoDB.
InnoDB распространяется на условиях общедоступной лицензии версии 2 (от июня 1991 года). В дистрибутиве исходного кода MySQL InnoDB находится в подкаталоге `innobase'.
Различия индексов MySql, кластеризация, хранение данных в MyIsam и InnoDb

Как устроены индексы в MySql, чем отличается индексирование в двух наиболее популярных движках MyISAM и InnoDb, чем первичные ключи отличаются от простого индекса, что такое кластерные индексы и покрывающие индексы, как с помощью них можно ускорить запросы. Вот как мне кажется наиболее интересные темы которые раскрою в этой статье. Тут же постараюсь подробно раскрыть тему с позиции того как работает этот механизм внутри. Буквально на пальцах и с позиции абстракций а не конкретики. В общем чтоб было минимум текста и максимум понятно.
Что представляет из себя индекс в MySql
Скорость чтения из индекса
Отличия в индексах MyISAM и InnoDb
Первичные и «вторичные» индексы в чем отличия
Вводная информация
Что представляет из себя индекс в MySql
На рисунке изобразил схематично как устроен индекс. Имеются узловые элементы (квадраты) и листья (круги). Предположим у нас есть таблица с колонками «Val» и «ID» как на рисунке. В этой таблице индекс построен по числовому полю «ID». Тогда получается что в узловых элементах находятся значения индекса и ссылки на другой более нижний узел или лист. В листовых же элементах точно так же лежат значения индекса которые уже ссылаются непосредственно на данные из таблицы.
Процесс поиска происходит примерно следующим образом. Например нужно найти строку с индексом 11.
начинаем просмотр корневого (верхнего) узла
первое значение в нем 10
идем к следующему 19, оно уже больше чем нам нужно
по ссылке слева от 19 переходим к следующему нижнему узлу
там первое значение 13, оно больше чем нам нужно
опять по ссылке слева переходим к более нижнему элементу
это уже будет листовой элемент, в нем уже лежат непосредственно данные
просматриваем данные по порядку
переходим по ссылке непосредственно к строке в таблице.
Скорость чтения из индекса
Такое устройство индекса позволяет обеспечить логарифмическую скорость поиска O(log n). Это очень быстро. Вот таблица где для наглядности посчитал сколько сравнений нужно сделать для поиска записи в таблице с разным количеством данных:
Количество элементов в таблице
Количество сравнений
Отличия в индексах MyISAM и InnoDb
MyIsam это более старый движок чем InnoDb и все описанное выше хорошо описывает устройство индекса именно в MyIsam. Более того для MyIsam можно сказать что первичный индекс и просто обычный индекс ни чем между собой не отличаются. В целом таблицы построенные на движке MyIsam вполне себе могут существовать даже без первичного ключа и без всякого индекса в целом. А вот InnoDb уже более свежий и продвинутый движок, и тут как раз есть отличия первичного ключа и просто индекса. Создать таблицу InnoDb тоже можно не указав первичный ключ, но в этом случае первичный ключ все равно создастся. Это называется суррогатный первичный ключ. InnoDb сам выберет поле по которому нужно этот ключ создать, если ни одно поле не подходит, то создаст новое числовое поле, которое конечно же будет скрыто и в структуре его не увидеть. Для разбора индексов InnoDb первым делом нужно начать с кластеризации.
Кластерный индекс
Кластерный индекс отличается тем, что в отличии от предыдущей картинки, где от листьев шли ссылки непосредственно на строки в таблице, тут все данные строк хранятся непосредственно в самом индексе. Проиллюстрировал это на примере листьев 10, 11, 12. Это хорошо тем что позволяет избежать лишнего чтения диска при переходе по ссылке от листа на данные в строке. Тут непосредственно вся строка лежит в индексе. То есть получается что в InnoDb при создании таблицы и указании первичного ключа будет построено такое дерево, в котором все данные таблицы будут продублированы в листья индекса. Если первичный ключ не задать то колонка для него будет выбрана или создана автоматически и все равно по ней будет построен кластерный индекс.
Более того, если мы говорим о таблицах на основе движка InnoDb, то в целом понятие таблица довольно абстрактное. На картинке она нарисована просто для наглядности. На самом деле ни какой таблицы по сути не существует, а все данные просто хранятся в кластерном индексе.
Первичные и «вторичные» индексы в чем отличия
Выше было оговорено что для MyIsam нет разницы между первичными и «вторичными» ключами.
Первичный и вторичный индекс в MyIsam
На картинке нарисован первичный и вторичный ключ в MyIsam. Первичный ключ построен по полю «ID», вторичный по полю «Val». Видно что их структура одинакова. И в том и в другом в листьях расположены значения индекса и ссылки на строки в таблице.
В InnoDb это устроено немного по другому.
Первичный и вторичный индекс в InnoDb
Как уже говорил, таблица тут просто для наглядности. Все ее данные хранятся в первичном (кластерном ключе). Тут первичный ключ построен по полю «Id», вторичный по полю «Val». Видно что в листьях первичного ключа лежат значения индекса + все данные из строк таблицы. Во вторичном же ключе, в листьях лежат значения ключа + первичный ключ.
Можно резюмировать что для MyIsam нет различий между первичным и вторичными индексами. Для InnoDb первичный ключ содержит в себе все данные таблицы, вторичный же ключ содержит значения ключа плюс значение первичного ключа. Получается что при поиске по вторичному ключу, поиск будет произведен дважды. Первый раз непосредственно по самому индексу, будет найдено значение первичного индекса. И уже второй раз по найденому первичному индексу для поиска данных всей строки.
Покрывающие индексы
Смысл покрывающих индексов в том, что MySql может вытаскивать данные непосредственно из самого индекса, не читая при этом всю строку и вовсе не читая строку. Для такой оптимизации нужно чтобы все поля указанные в SELECT имелись в индексе. То есть например у нас имеется таблица с полями «id», «name», «surname», «age», «address». И мы проиндексировали ее по полю «id». В запросе мы хотим получить например «id» и «name». При таком условии MySql найдет по первичному ключу нужную строку, прочитает ее и отбросит все поля не указанные в SELECT. Если же мы немного оптимизируем этот запрос и построим индкес по двум полям «id» и «name», то в таком случае MySql найдя нужную строку по этому индексу не пойдет читать всю эту строку, а просто возьмет данные, которые нужны непосредственно из индекса. Правда есть обратная сторона такого подхода, а именно размер индекса в этом случае будет больше, по этому нужно грамотно подходить к построению покрывающих индексов.
Более подробно можно почитать в очень хорошей книге «MySQL по максимуму» Бэрон Шварц, Петр Зайцев, Вадим Ткаченко
InnoDB: подсистема хранения базы данных MySQL
 InnoDB является транзакционной подсистемой хранения по умолчанию в MySQL, а также наиболее значимой и широко используемой подсистемой хранения в целом. Она была создана для обработки большого количества краткосрочных транзакций, которые выполняются благополучно намного чаще, чем откатываются. Высокая производительность и автоматическое восстановление после сбоя делают ее популярной и для нетранзакционных целей. Вам следует применять InnoDB для своих таблиц, пока не возникнет необходимость использовать другую подсистему хранения. Если вы хотите изучить подсистемы хранения, не стоит рассматривать их все слишком подробно, но обязательно потратьте время на глубокое ознакомление с InnoDB, чтобы узнать о ней как можно больше.
InnoDB является транзакционной подсистемой хранения по умолчанию в MySQL, а также наиболее значимой и широко используемой подсистемой хранения в целом. Она была создана для обработки большого количества краткосрочных транзакций, которые выполняются благополучно намного чаще, чем откатываются. Высокая производительность и автоматическое восстановление после сбоя делают ее популярной и для нетранзакционных целей. Вам следует применять InnoDB для своих таблиц, пока не возникнет необходимость использовать другую подсистему хранения. Если вы хотите изучить подсистемы хранения, не стоит рассматривать их все слишком подробно, но обязательно потратьте время на глубокое ознакомление с InnoDB, чтобы узнать о ней как можно больше.
История InnoDB
История релизов InnoDB довольно сильно запутана, но очень помогает разобраться в этой подсистеме хранения данных. В 2008 году для версии MySQL 5.1 был выпущен так называемый плагин InnoDB. Это было следующее поколение InnoDB, созданное компанией Oracle, которой в то время принадлежала InnoDB, но не MySQL. По разным причинам, которые лучше обсуждать за кружкой пива, MySQL продолжала поставлять более старую версию InnoDB, скомпилированную на сервер. Но вы могли по собственному желанию отключить ее и установить новый, более эффективный и лучше масштабируемый плагин InnoDB. В конце концов компания Oracle приобрела компанию Sun Microsystems и, следовательно, СУБД MySQL и удалила старую кодовую базу, заменив ее «плагином» по умолчанию в версии MySQL 5.5. (Да, это означает, что теперь «плагин» фактически скомпилирован, а не установлен как плагин. Старая терминология изживается с трудом.)
Современная версия InnoDB, представленная в качестве плагина InnoDB в MySQL 5.1, обеспечивает новый функционал, например построение индексов путем сортировки, возможность удаления и добавления индексов без перестройки всей таблицы, новый формат хранения данных, который предполагает сжатие, новый способ хранения больших объемов данных, таких как столбцы BLOB, и управления форматом файлов. Многие люди, которые работают с MySQL 5.1, не применяют этот плагин, чаще всего потому, что не подозревают о нем. Если вы используете MySQL 5.1, убедитесь, пожалуйста, в том, что применяете плагин InnoDB. Он намного лучше более ранней версии InnoDB.
InnoDB настолько важна, что в ее разработку внесли свой вклад не только команда Oracle, но и многие другие люди и компании, в частности Ясуфуми Киносита (Yasufumi Kinoshita), а также компании Google, Percona и Facebook. Некоторые из внесенных ими усовершенствований были включены в официальный исходный код InnoDB, многие другие были немного переработаны командой InnoDB и затем внедрены. В целом развитие InnoDB значительно ускорилось за последние несколько лет, улучшения коснулись инструментария, масштабируемости, способности к изменению конфигурации, производительности, функций и поддержки для Windows и прочих важных вещей. Лабораторные превью и релизы ключевых изменений, вносимых в версию MySQL 5.6, также представляют множество замечательных новых функций InnoDB.
Oracle инвестирует колоссальные ресурсы и проделывает огромную работу для улучшения производительности InnoDB (и здесь очень полезным оказывается вклад, который вносят внешние разработчики). Во втором издании этой книги мы отмечали, что InnoDB выглядела довольно жалко, работая на основе четырехпроцессорных ядер. Теперь она хорошо масштабируется до 24 ядер процессора, а возможно, и до 32 или даже большего количества в зависимости от сценария.
Обзор InnoDB
InnoDB сохраняет данные в одном или нескольких файлах данных, которые называются табличным пространством (tablespace). Табличное пространство, в сущности, является черным ящиком, которым управляет сама InnoDB. В MySQL 4.1 и более поздних версиях InnoDB может хранить данные и индексы каждой таблицы в отдельных файлах. Кроме того, она может располагать табличные пространства в «сырых» (неформатированных) разделах диска. Но современные файловые системы делают эту возможность бессмысленной.
InnoDB использует MVCC для обеспечения высокой степени конкурентности и реализует все четыре стандартных уровня изолированности SQL. Уровнем изоляции по умолчанию является REPEATABLE READ, а стратегия блокировки следующего ключа предотвращает фантомные чтения на этом уровне: вместо того чтобы блокировать только строки, затронутые в запросе, InnoDB блокирует пропуски в структуре индекса, предотвращая вставку фантомных строк.
Таблицы InnoDB строятся на кластеризованных индексах, которые мы детально рассмотрим в следующих главах. Структуры индексов в InnoDB значительно отличаются от используемых в других подсистемах хранения. В результате эта подсистема обеспечивает более быстрый поиск по первичному ключу. Однако вторичные индексы (индексы, не являющиеся первичным ключом) содержат все столбцы первичного ключа, так что если первичный ключ большой, то все прочие индексы тоже будут большими. Если в таблице планируется много индексов, нужно стремиться к тому, чтобы первичный ключ был небольшим. Формат хранения данных не зависит от платформы. Это означает, что вы можете без проблем скопировать файлы данных и индексов с сервера Intel на PowerPC или Sun SPARCI.
InnoDB поддерживает множество внутренних оптимизаций. В их число входят прогнозное упреждающее чтение для предварительной выборки данных с диска, адаптивный хеш-индекс, который автоматически выстраивает хеш-индексы в памяти для обеспечения очень быстрого поиска, и буфер вставок для ускорения операций вставки. Мы еще рассмотрим эти вопросы.
Подсистема InnoDB очень сложна, и если вы ее используете, то мы настоятельно рекомендуем вам прочитать раздел «InnoDB Transaction Model and Locking» («Транзакционная модель и блокировки в InnoDB») руководства по MySQL. Из-за наличия архитектуры MVCC в работе подсистемы InnoDB есть много тонкостей, о которых вы должны узнать прежде, чем создавать приложения. Работа с подсистемой хранения, поддерживающей согласованные представления данных для всех пользователей, даже когда некоторые пользователи меняют данные, может быть сложной.
В качестве транзакционной подсистемы хранения InnoDB поддерживает горячее онлайновое резервное копирование с помощью различных механизмов, включая запатентованную Oracle Enterprise Backup и Percona XtraBackup с открытым исходным кодом. В других подсистемах хранения MySQL нет горячих резервных копий — чтобы получить согласованную резервную копию, вам необходимо остановить все процессы записи в таблицу, которые при смешанной рабочей нагрузке на чтение и запись обычно заканчиваются также остановкой чтения.
Подсистемы (движки) хранения в базе данных MySQL 8
Эта команда в поле Engine показывает, что таблица хранится в подсистеме хранения данных InnoDB. Есть другая информация, которую можно использовать для других целей, в частности количество строк, длина индекса и т. д.
Подсистема хранения данных помогает обрабатывать различные операции SQL для различных типов таблиц. Каждая подсистема хранения имеет свои преимущества и недостатки. Выбор подсистемы хранения всегда будет зависеть от потребностей. Важно понимать особенности каждой подсистемы хранения и выбирать наиболее подходящую для ваших таблиц, чтобы максимизировать производительность базы данных. В MySQL всякий раз, когда мы создаем новую таблицу, подсистемой хранения данных по умолчанию является InnoDB.
InnoDB
В MySQL 8 подсистема хранения данных InnoDB используется по умолчанию и является наиболее широко применяемой из всех других доступных подсистем хранения. Подсистема InnoDB была выпущена вместе с MySQL 5.1 как плагин в 2008 году, и она рассматривается как подсистема хранения по умолчанию, начиная с версии 5.5 и выше. Поддержка подсистемы хранения InnoDB была перенята корпорацией Oracle в октябре 2005 года у финской компании Innobase Oy.
Таблицы InnoDB поддерживают ACID-совместимые фиксации транзакций, откат и возможности аварийного восстановления для защиты пользовательских данных. InnoDB также поддерживает блокировку на уровне строк, что помогает улучшить параллелизм и производительность. InnoDB хранит данные в кластеризованных индексах, чтобы уменьшить операции ввода-вывода для всех запросов SQL на выборку данных на основе первичного ключа. InnoDB также поддерживает ограничения внешнего ключа, которые обеспечивают лучшую целостность данных в базе данных. Максимальный размер таблицы InnoDB может масштабироваться до 256 Тб, что должно быть вполне достаточным во многих случаях использования больших данных.
Важные замечания по InnoDB
MyISAM
Подсистема хранения данных MyISAM использовалась по умолчанию для MySQL вплоть до версии 5.5 1. В отличие от InnoDB, таблицы подсистемы хранения данных MylSAM не поддерживают ACID-совместитмость. Таблицы MylSAM поддерживают только блокировку уровня таблицы, поэтому таблицы MyISAM небезопасны для транзакций. Таблицы MyISAM оптимизированы для сжатия и скорости. MyISAM обычно используется, когда вам нужно иметь в основном операции чтения с минимальными транзакционными данными. Максимальный размер таблицы My- ISAM может достигать 256 Тб, что помогает в таких случаях, как анализ данных.
Важные примечания относительно таблиц MyISAM
Из-за низких накладных расходов MyISAM использует более простую структуру, которая обеспечивает хорошую производительность; однако это не сильно помогает для получения хорошей производительности, когда есть потребность в лучшем параллелизме и случаях использования, которые не нуждаются в тяжелых операциях чтения. Наиболее распространенной проблемой производительности MyISAM является блокировка таблицы, которая может задерживать ваши параллельные запросы в очереди. Это происходит, когда она блокирует таблицу для любой другой операции до тех пор, пока более ранняя операция не будет выполнена.
Таблица MyISAM не поддерживает транзакции и внешние ключи. Судя по всему, из-за этих ограничений вместо таблиц MyISAM теперь системные таблицы схемы MySQL 8 используют таблицы InnoDB.
Memory
Подсистема хранения в памяти (подсистема оперативного хранения данных) обычно называется подсистемой хранения данных на основе кучи. Она используется для чрезвычайно быстрого доступа к данным. Эта подсистема хранения содержит данные в оперативной памяти, поэтому ей не нужны операции ввода- вывода. Поскольку она хранит данные в оперативной памяти, все данные теряются при перезапуске сервера. Такая подсистема в основном используется для временных таблиц или таблицы подстановки. Эта подсистема поддерживает блокировку на уровне таблицы, которая ограничивает параллелизм с высокой частотой записи.
Ниже приведены важные примечания об оперативных таблицах Memory.
Archive
Blackhole
Эта подсистема хранения данных принимает данные, но их не сохраняет. Вместо сохранения данных она отбрасывает (уничтожает) их после каждой вставки.
В следующем ниже примере показана работа таблицы BLACKHOLE :
Эта подсистема хранения полезна для репликации с большим количеством серверов. Подсистема хранения данных Blackhole работает в качестве фильтрующего сервера между ведущим и ведомым серверами, который не хранит никаких данных, но который применяет только правила replicate-do-* и replicate-ignore-* и пишет двоичные журналы. Эти двоичные журналы используются для выполнения репликации на ведомых серверах. Мы обсудим это подробно в главе 6 «Репликация для построения высокодоступных решений».
Merge
В следующем ниже примере показано, как создавать таблицы MERGE:
Как правило, эта подсистема используется для управления таблицами, связанными с журналом регистрации событий. В отдельных таблицах MyISAM можно задавать различные месяцы журналов и объединять эти таблицы с помощью подсистемы хранения данных MERGE.
Таблицы MyISAM имеют ограничение по объему хранения для операционной системы, но коллекция таблиц MyISAM (MERGE) не имеет таких ограничений. Таким образом, использование подсистемы MERGE позволит вам разделять данные на многочисленные таблицы MyISAM, что может помочь в преодолении ограничений по объему хранения.
С помощью подсистемы MERGE трудно выполнять разделение, следовательно, таблицами MERGE оно не поддерживается, и мы не можем реализовать раздел на таблице MERGE или любой таблице MyISAM.
Federated
Давайте создадим таблицу FEDERATED.
В поле CONNECTION содержится следующая ниже информация для вашей справки:
NDB Cluster
Кластерная подсистема хранения данных NDB Cluster может конфигурироваться с помощью ряда параметров аварийного переключения и балансировки нагрузки, но проще всего начать с подсистемы хранения на уровне кластера. NDB Cluster использует подсистему хранения NDB и содержит полный набор данных, который зависит только от других наборов данных, доступных в кластере.
Кластерная часть NDB Cluster настроена независимо от серверов MySQL. В NDB Cluster каждая часть кластера считается узлом.
Как выбрать движок (подсистему хранения) MySQL?
Следующая ниже схема поможет вам понять, какую подсистему хранения данных вам нужно использовать для ваших потребностей:
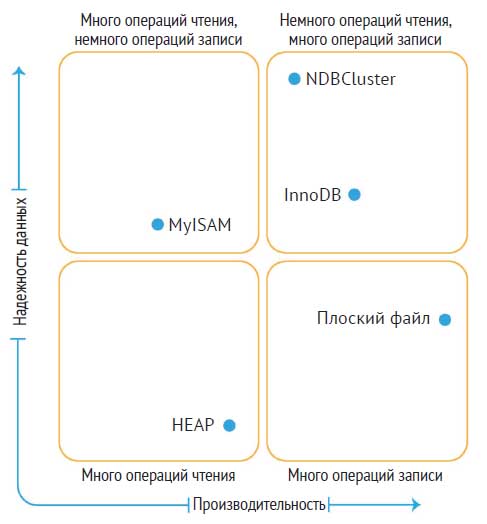
Каждая подсистема хранения данных имеет свое преимущество и удобство использования:
Теперь у вас есть более четкое представление о различных подсистемах хранения данных вместе с различными случаями использования, которые помогут вам выбрать свою подсистему в зависимости от ваших потребностей. Давайте рассмотрим операторы обработки данных, используемые для извлечения, сохранения и обновления данных.
MySQL Storage Engines
Двигатели хранения
Механизмы хранения (базовый программный компонент) являются компонентами MySQL, которые могут обрабатывать операции SQL для различных типов таблиц для хранения и управления информацией в базе данных. InnoDB в основном используется механизм хранения общего назначения и начиная с MySQL 5.5 и более поздних версий это механизм по умолчанию. В MySQL доступно множество механизмов хранения, и они используются для разных целей.
Версия: MySQL 5.6
Системы хранения MySQL
Это механизм хранения по умолчанию для MySQL 5.5 и выше. Он предоставляет безопасные транзакции (ACID-совместимые) таблицы, поддерживает ограничения ссылочной целостности FOREIGN KEY. Он поддерживает функции фиксации, отката и восстановления после сбоя для защиты данных. Он также поддерживает блокировку на уровне строк. Это «согласованное чтение без блокировки» повышает производительность при использовании в многопользовательской среде. Он хранит данные в кластерных индексах, что уменьшает количество операций ввода-вывода для запросов на основе первичных ключей.
Другие темы:
Список модулей хранения, поддерживаемых вашей установкой MySQL
Следующая команда отображает информацию о состоянии механизмов хранения сервера.
Настройка механизма хранения
В CREATE TABLE STATEMENT вы можете добавить опцию ENGINE table, чтобы упомянуть механизм хранения. Смотрите следующие операторы CREATE TABLE, где использовались разные движки:
Вы можете установить механизм хранения по умолчанию для текущего сеанса, установив переменную default_storage_engine с помощью команды set.
Если вы хотите преобразовать таблицу из одного механизма хранения в другой, используйте инструкцию ALTER TABLE. Смотрите следующее утверждение:
MySQL: механизм хранения InnoDB
Особенности движка хранения InnoDB:
| Пределы хранения | 64TB | операции | да | Блокировка детализации | Строка |
| MVCC (Multiversion параллельный контроль) | да | Поддержка типов геопространственных данных | да | Поддержка геопространственной индексации | нет |
| B-древовидные индексы | да | T-дерево индексов | нет | Хеш-индексы | нет |
| Индексы полнотекстового поиска | да | Кластерные индексы | да | Кэши данных | да |
| Индексные кеши | да | Сжатые данные | да | Зашифрованные данные | да |
| Поддержка базы данных кластера | нет | Поддержка репликации | да | Поддержка внешнего ключа | да |
| Резервное копирование / восстановление на момент времени | да | Поддержка кеша запросов | да | Обновить статистику для словаря данных | да |
Преимущества хранилища InnoDB
Создание таблиц InnoDB:
Используйте оператор CREATE TABLE, чтобы создать таблицу InnoDB без каких-либо специальных предложений. Начиная с MySQL 5.5, это стандартный механизм хранения MySQL. В MySQL 5.6 при выполнении оператора CREATE TABLE без предложения ENGINE = создается таблица InnoDB. Вот пример:
Следующий оператор SHOW TABLE STATUS показывает свойства таблиц (принадлежит базе данных «tutorial»).
Обработка AUTO_INCREMENT в InnoDB :
InnoDB предоставляет метод, который улучшает масштабируемость и производительность операторов SQL, которые вставляют строки в таблицы со столбцами AUTO_INCREMENT. Чтобы использовать механизм AUTO_INCREMENT с таблицей InnoDB, столбец AUTO_INCREMENT (в данном случае col1) должен быть определен как часть индекса. Смотрите следующий пример:
Обработка ограничений FOREIGN KEY в InnoDB :
MySQL поддерживает внешние ключи, которые позволяют перекрестно ссылаться на связанные данные между таблицами, и ограничения внешнего ключа, которые помогают поддерживать согласованность этих распределенных данных. На определения внешнего ключа для таблиц InnoDB распространяются следующие условия:
Ограничение: таблица InnoDB :
MySQL: механизм хранения MyISAM
Механизм хранения MyISAM основан на более старом механизме хранения ISAM (сейчас недоступен), но имеет много полезных расширений.
Особенности механизма хранения MyISAM:
| Пределы хранения | 256TB | операции | нет | Блокировка детализации | Таблица |
| MVCC (Multiversion параллельный контроль) | нет | Поддержка типов геопространственных данных | да | Поддержка геопространственной индексации | да |
| B-древовидные индексы | да | T-дерево индексов | нет | Хеш-индексы | нет |
| Индексы полнотекстового поиска | да | Кластерные индексы | нет | Кэши данных | нет |
| Индексные кеши | да | Сжатые данные | да | Зашифрованные данные | да |
| Поддержка базы данных кластера | нет | Поддержка репликации | да | Поддержка внешнего ключа | нет |
| Резервное копирование / восстановление на момент времени | да | Поддержка кеша запросов | да | Обновить статистику для словаря данных | да |
Каждая таблица MyISAM хранится на диске в трех файлах.
Создание таблиц MyISAM:
Используйте оператор CREATE TABLE, чтобы создать таблицу MyISAM с предложением ENGINE. Начиная с MySQL 5.6, необходимо использовать предложение ENGINE, чтобы указать механизм хранения MyISAM, потому что InnoDB является механизмом по умолчанию. Вот пример:
Следующий оператор SHOW TABLE STATUS показывает свойства таблиц (принадлежит базе данных «tutorial»).
Основные характеристики таблиц MyISAM:
Поврежденные таблицы MyISAM:
Формат таблицы MyISAM очень надежен, но в некоторых случаях вы можете получить поврежденные таблицы, если произойдет любое из следующих событий:
MySQL: MEMORY Storage Engine
Механизм хранения MEMORY создает таблицы, которые хранятся в памяти. Поскольку данные могут быть повреждены из-за проблем с оборудованием или электропитанием, эти таблицы можно использовать только как временные рабочие области или кэши только для чтения для данных, извлеченных из других таблиц. Когда сервер MySQL останавливается или перезапускается, данные в таблицах MEMORY теряются.
Особенности MEMORY Storage Engine:
| Пределы хранения | баран | операции | нет | Блокировка детализации | Таблица |
| MVCC | нет | Поддержка типов геопространственных данных | нет | Поддержка геопространственной индексации | нет |
| B-древовидные индексы | да | T-дерево индексов | нет | Хеш-индексы | да |
| Индексы полнотекстового поиска | нет | Кластерные индексы | нет | Кэши данных | N / A |
| Индексные кеши | N / A | Сжатые данные | нет | Зашифрованные данные | да |
| Поддержка базы данных кластера | нет | Поддержка репликации | да | Поддержка внешнего ключа | нет |
| Резервное копирование / восстановление на момент времени | да | Поддержка кеша запросов | да | Обновить статистику для словаря данных | да |
Создание таблиц MEMORY:
Используйте оператор CREATE TABLE для создания таблицы MEMORY с предложением ENGINE. Начиная с MySQL 5.6, необходимо использовать предложение ENGINE, чтобы указать механизм хранения MEMORY, потому что InnoDB является механизмом по умолчанию. В следующем примере показано, как создать и использовать таблицу MEMORY:
Следующий оператор SHOW TABLE STATUS показывает свойства таблиц (принадлежит базе данных «tutorial»).
Удалить таблицу MEMORY:
Индексы: Механизм хранения MEMORY поддерживает индексы HASH и BTREE. Добавляя предложение USING, вы можете указать одно или другое для данного индекса. Смотрите следующие примеры:
Когда использовать механизм хранения MEMORY:
MySQL: MERGE Storage Engine
Механизм хранения MERGE (также известный как MRG_MyISAM) представляет собой набор идентичных таблиц MyISAM (идентичные столбцы и индексные данные в одинаковом порядке), которые можно использовать как одну таблицу. У вас должны быть привилегии SELECT, DELETE и UPDATE для таблиц MyISAM, которые вы сопоставляете с таблицей MERGE.
Создание таблиц MERGE:
Чтобы создать таблицу MERGE, необходимо указать параметр UNION = (список таблиц) (указывает, какие таблицы MyISAM использовать) в операторе CREAE TABLE. В следующем примере сначала мы создали три таблицы с двумя строками, затем объединили их в одну таблицу, используя механизм хранения MERGE:
Следующий оператор SHOW TABLE STATUS показывает свойства таблиц (принадлежит базе данных «tutorial»).
Проблема безопасности: если у пользователя есть доступ к таблице MyISAM, скажем, t1, он может создать таблицу MERGE m1, которая обращается к t1. Однако, если администратор аннулирует привилегии пользователя на t1, пользователь может продолжить доступ к данным с t1 по m1.
MySQL: CSV Storage Engine
Вы можете прочитать, изменить файл ‘color.CSV’ с помощью приложений для работы с электронными таблицами, таких как Microsoft Excel или StarOffice Calc.
Ограничения CSV:
Следующий оператор SHOW TABLE STATUS показывает свойства таблиц (принадлежит базе данных «tutorial»).
MySQL: ARCHIVE Storage Engine
Особенности хранилища ARCHIVE:
| Пределы хранения | Никто | операции | нет | Блокировка детализации | Таблица |
| MVCC | нет | Поддержка типов геопространственных данных | да | Поддержка геопространственной индексации | нет |
| B-древовидные индексы | нет | T-дерево индексов | нет | Хеш-индексы | нет |
| Индексы полнотекстового поиска | нет | Кластерные индексы | нет | Кэши данных | нет |
| Индексные кеши | нет | Сжатые данные | да | Зашифрованные данные | да |
| Поддержка базы данных кластера | нет | Поддержка репликации | да | Поддержка внешнего ключа | нет |
| Резервное копирование / восстановление на момент времени | да | Поддержка кеша запросов | да | Обновить статистику для словаря данных | да |
АРХИВ поддерживает механизм хранения
ARCHIVE хранилище не поддерживает
АРХИВ хранилища: хранение и поиск
MySQL: ПРИМЕР Механизма хранения
MySQL: BLACKHOLE Storage Engine
Следующий оператор SHOW TABLE STATUS показывает свойства таблиц (принадлежит базе данных «tutorial»).
MySQL: FEDERATED Storage Engine
Создать FEDERATED таблицу
Вы можете создать таблицу FEDERATED следующими способами:
Использование CONNECTION : Чтобы использовать этот метод, необходимо указать строку CONNECTION после типа механизма в инструкции CREATE TABLE. Смотрите следующий пример:
Формат строки подключения выглядит следующим образом:
Использование CREATE SERVER: чтобы использовать этот метод, необходимо указать строку CONNECTION после типа механизма в инструкции CREATE TABLE. Смотрите следующий пример:
Имя_сервера используется в строке подключения при создании новой таблицы FEDERATED.
Различия между InnoDB и MyISAM



