Различия индексов MySql, кластеризация, хранение данных в MyIsam и InnoDb

Как устроены индексы в MySql, чем отличается индексирование в двух наиболее популярных движках MyISAM и InnoDb, чем первичные ключи отличаются от простого индекса, что такое кластерные индексы и покрывающие индексы, как с помощью них можно ускорить запросы. Вот как мне кажется наиболее интересные темы которые раскрою в этой статье. Тут же постараюсь подробно раскрыть тему с позиции того как работает этот механизм внутри. Буквально на пальцах и с позиции абстракций а не конкретики. В общем чтоб было минимум текста и максимум понятно.
Что представляет из себя индекс в MySql
Скорость чтения из индекса
Отличия в индексах MyISAM и InnoDb
Первичные и «вторичные» индексы в чем отличия
Вводная информация
Что представляет из себя индекс в MySql
На рисунке изобразил схематично как устроен индекс. Имеются узловые элементы (квадраты) и листья (круги). Предположим у нас есть таблица с колонками «Val» и «ID» как на рисунке. В этой таблице индекс построен по числовому полю «ID». Тогда получается что в узловых элементах находятся значения индекса и ссылки на другой более нижний узел или лист. В листовых же элементах точно так же лежат значения индекса которые уже ссылаются непосредственно на данные из таблицы.
Процесс поиска происходит примерно следующим образом. Например нужно найти строку с индексом 11.
начинаем просмотр корневого (верхнего) узла
первое значение в нем 10
идем к следующему 19, оно уже больше чем нам нужно
по ссылке слева от 19 переходим к следующему нижнему узлу
там первое значение 13, оно больше чем нам нужно
опять по ссылке слева переходим к более нижнему элементу
это уже будет листовой элемент, в нем уже лежат непосредственно данные
просматриваем данные по порядку
переходим по ссылке непосредственно к строке в таблице.
Скорость чтения из индекса
Такое устройство индекса позволяет обеспечить логарифмическую скорость поиска O(log n). Это очень быстро. Вот таблица где для наглядности посчитал сколько сравнений нужно сделать для поиска записи в таблице с разным количеством данных:
Количество элементов в таблице
Количество сравнений
Отличия в индексах MyISAM и InnoDb
MyIsam это более старый движок чем InnoDb и все описанное выше хорошо описывает устройство индекса именно в MyIsam. Более того для MyIsam можно сказать что первичный индекс и просто обычный индекс ни чем между собой не отличаются. В целом таблицы построенные на движке MyIsam вполне себе могут существовать даже без первичного ключа и без всякого индекса в целом. А вот InnoDb уже более свежий и продвинутый движок, и тут как раз есть отличия первичного ключа и просто индекса. Создать таблицу InnoDb тоже можно не указав первичный ключ, но в этом случае первичный ключ все равно создастся. Это называется суррогатный первичный ключ. InnoDb сам выберет поле по которому нужно этот ключ создать, если ни одно поле не подходит, то создаст новое числовое поле, которое конечно же будет скрыто и в структуре его не увидеть. Для разбора индексов InnoDb первым делом нужно начать с кластеризации.
Кластерный индекс
Кластерный индекс отличается тем, что в отличии от предыдущей картинки, где от листьев шли ссылки непосредственно на строки в таблице, тут все данные строк хранятся непосредственно в самом индексе. Проиллюстрировал это на примере листьев 10, 11, 12. Это хорошо тем что позволяет избежать лишнего чтения диска при переходе по ссылке от листа на данные в строке. Тут непосредственно вся строка лежит в индексе. То есть получается что в InnoDb при создании таблицы и указании первичного ключа будет построено такое дерево, в котором все данные таблицы будут продублированы в листья индекса. Если первичный ключ не задать то колонка для него будет выбрана или создана автоматически и все равно по ней будет построен кластерный индекс.
Более того, если мы говорим о таблицах на основе движка InnoDb, то в целом понятие таблица довольно абстрактное. На картинке она нарисована просто для наглядности. На самом деле ни какой таблицы по сути не существует, а все данные просто хранятся в кластерном индексе.
Первичные и «вторичные» индексы в чем отличия
Выше было оговорено что для MyIsam нет разницы между первичными и «вторичными» ключами.
Первичный и вторичный индекс в MyIsam
На картинке нарисован первичный и вторичный ключ в MyIsam. Первичный ключ построен по полю «ID», вторичный по полю «Val». Видно что их структура одинакова. И в том и в другом в листьях расположены значения индекса и ссылки на строки в таблице.
В InnoDb это устроено немного по другому.
Первичный и вторичный индекс в InnoDb
Как уже говорил, таблица тут просто для наглядности. Все ее данные хранятся в первичном (кластерном ключе). Тут первичный ключ построен по полю «Id», вторичный по полю «Val». Видно что в листьях первичного ключа лежат значения индекса + все данные из строк таблицы. Во вторичном же ключе, в листьях лежат значения ключа + первичный ключ.
Можно резюмировать что для MyIsam нет различий между первичным и вторичными индексами. Для InnoDb первичный ключ содержит в себе все данные таблицы, вторичный же ключ содержит значения ключа плюс значение первичного ключа. Получается что при поиске по вторичному ключу, поиск будет произведен дважды. Первый раз непосредственно по самому индексу, будет найдено значение первичного индекса. И уже второй раз по найденому первичному индексу для поиска данных всей строки.
Покрывающие индексы
Смысл покрывающих индексов в том, что MySql может вытаскивать данные непосредственно из самого индекса, не читая при этом всю строку и вовсе не читая строку. Для такой оптимизации нужно чтобы все поля указанные в SELECT имелись в индексе. То есть например у нас имеется таблица с полями «id», «name», «surname», «age», «address». И мы проиндексировали ее по полю «id». В запросе мы хотим получить например «id» и «name». При таком условии MySql найдет по первичному ключу нужную строку, прочитает ее и отбросит все поля не указанные в SELECT. Если же мы немного оптимизируем этот запрос и построим индкес по двум полям «id» и «name», то в таком случае MySql найдя нужную строку по этому индексу не пойдет читать всю эту строку, а просто возьмет данные, которые нужны непосредственно из индекса. Правда есть обратная сторона такого подхода, а именно размер индекса в этом случае будет больше, по этому нужно грамотно подходить к построению покрывающих индексов.
Более подробно можно почитать в очень хорошей книге «MySQL по максимуму» Бэрон Шварц, Петр Зайцев, Вадим Ткаченко
Что такое индекс mysql и как их использовать
3 ответа 3
Если в кратце, то индекс, это поле по которому оптимизирован(ускорен) поиск.
Поскольку индекс занимает место, то индексировать нужно только те поля, по которым происходит выборка.
Допустим есть таблица.
Допустим вам нужен поиск по имени (firstname).
тогда есть смысл добавить индекс по данному полю.
Будет созданна «карта» которая позволет легко находить записи в оригинальном списке.
Для одной небольшой таблицы приемущество не будет очевидно join несколько (3-4 уже достаточно) таблиц по неиндексированным полям. Убивает сервер на раз!
Вкратце, индексы создаются для повышения производительности поиска данных. Таблицы могут иметь огромное количество строк, которые хранятся в произвольном порядке. Без индекса поиск нужных строк идёт по порядку (последовательно), что на больших объемах данных отнимает много времени.
Индекс создаётся по правилу:
то, чтобы этот запрос отработал быстрее обычного, следует добавить индекс по вышеуказанному правилу:
Тогда тот же самый запрос
отработает гораздо быстрее, если столбец city будет проиндексирован.

На пальцах можно объяснить так:
Когда Вы создаёте таблицу, добавляете в неё данные, то таблица разрастается и она выглядит как просто последовательный список, упорядоченный по тому как в неё данные добавлялись.
Это связано с тем, что когда Вы ищите какую-то запись, то просматриваются все записи, пока не дойдут до нужной.
Когда Вам это окончательно надоедает и Вы хотите что-нибудь сделать, то к Вам на помощь приходят индексы.
Индекс создаётся по какому-то определённому полю (можно по нескольким) по которому, обычно, выполняется поиск. Когда Вы создаёте индекс, то MySql (и любая другая БД) обходит все записи в таблице и строит дерево (скорее всего B-дерево или разновидность), в котором ключами выступает выбранное поле, а содержимым ссылки на записи в таблице.
И когда Вы делаете очередной свой select запрос по таблице, по полю для которого создали индекс MySql (и любая другая БД) знает что у неё есть индекс, по которому пройтись будет быстрее, нежели перебирать все записи и Ваш запрос будет направлен этому индексу и записи, удовлетворяющие условию, будут найдены гораздо быстрее, так как поиск по построенному дереву будет гораздо быстрее, нежели простой перебор всех записей.
Index mysql что это
Индексы применяются для быстрого поиска строк с указанным значением одного столбца. Без индекса чтение таблицы осуществляется по всей таблице начиная с первой записи, пока не будут найдены соответствующие строки. Чем больше таблица, тем больше накладные расходы. Если же таблица содержит индекс по рассматриваемым столбцам, то MySQL может быстро определить позицию для поиска в середине файла данных без просмотра всех данных. Для таблицы, содержащей 1000 строк, это будет как минимум в 100 раз быстрее по сравнению с последовательным перебором всех записей. Однако в случае, когда необходим доступ почти ко всем 1000 строкам, быстрее будет последовательное чтение, так как при этом не требуется операций поиска по диску.
Индексы используются для того, чтобы:
Предположим, что вызывается следующий оператор SELECT :
Если по столбцам col1 и col2 существует многостолбцовый индекс, то соответствующие строки могут выбираться напрямую. В случае, когда по столбцам col1 и col2 существуют раздельные индексы, оптимизатор пытается найти наиболее ограничивающий индекс путем определения, какой индекс найдет меньше строк, и использует данный индекс для выборки этих строк.
Если данная таблица имеет многостолбцовый индекс, то любой крайний слева префикс этого индекса может использоваться оптимизатором для нахождения строк. Например, если имеется индекс по трем столбцам ( col1,col2,col3 ), то существует потенциальная возможность индексированного поиска по ( col1 ), ( col1,col2 ) и ( col1,col2,col3 ).
Если индекс существует по ( col1,col2,col3 ), то только первый показанный выше запрос использует данный индекс. Второй и третий запросы действительно включают индексированные столбцы, но ( col2 ) и ( col2,col3 ) не являются крайней слева частью префиксов ( col1,col2,col3 ).
Следующие команды SELECT не будут использовать индексы:
В первой команде величина LIKE начинается с шаблонного символа. Во второй команде величина LIKE не является константой.
При поиске с использованием column_name IS NULL будут использоваться индексы, если column_name является индексом.
Следующие выражения WHERE используют индексы:
Следующие выражения WHERE не используют индексы:
В некоторых случаях MySQL не использует индекс, даже если это возможно. Несколько примеров таких ситуаций приведено ниже:
Индексы в MySQL



Индексы в MySQL (Mysql indexes) — отличный инструмент для оптимизации SQL запросов. Чтобы понять, как они работают, посмотрим на работу с данными без них.
1. Чтение данных с диска
На жестком диске нет такого понятия, как файл. Есть понятие блок. Один файл обычно занимает несколько блоков. Каждый блок знает, какой блок идет после него. Файл делится на куски и каждый кусок сохраняется в пустой блок.
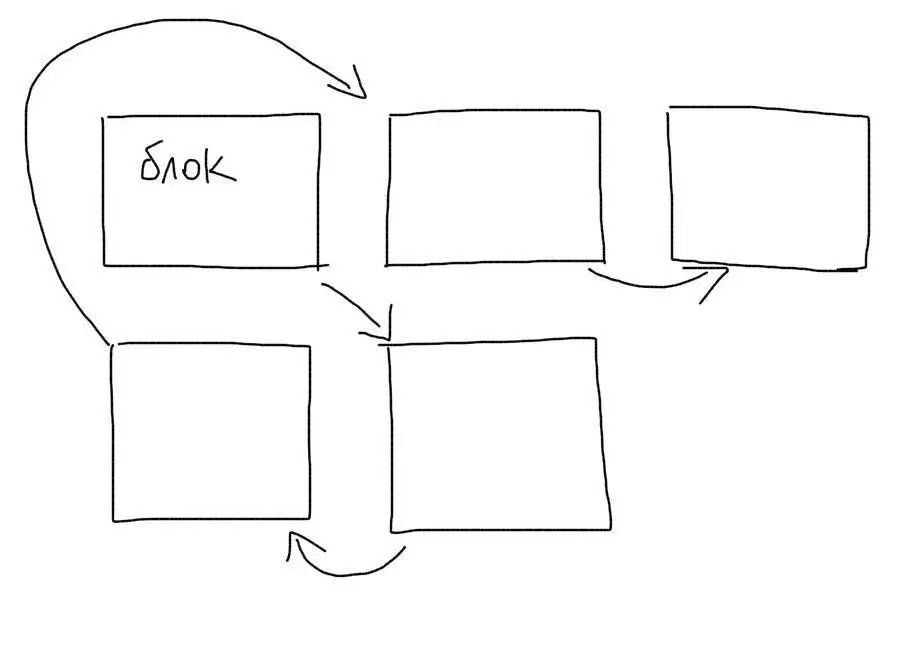
При чтении файла, мы по очереди проходимся по всем блокам и собираем файл из кусков. Блоки одного файла могут быть раскиданы по диску (фрагментация). Тогда чтение файла замедлится, так как понадобится прыгать по разным участкам диска.
Когда мы ищем что-то внутри файла, нам понадобится пройтись по всем блокам, в которых он сохранен. Если файл очень большой, то и количество блоков будет значительным. Необходимость перепрыгивать с блока на блок, которые могут находиться в разных местах, сильно замедлит поиск данных.
2. Поиск данных в MySQL
Таблицы MySQL – это обычные файлы. Выполним запрос такого вида:
MySQL при этом открывает файл, где хранятся данные из таблицы users. А дальше — начинает перебирать весь файл, чтобы найти нужные записи.
Кроме этого, MySQL будет сравнивать данные в каждой строке таблицы со значением в запросе. Допустим работа ведется с таблицей, в которой есть 10 записей. Тогда MySQL прочитает все 10 записей, сравнит колонку age каждой из них со значением 29 и отберет только подходящие данные:

Итак, есть две проблемы при чтении данных:
3. Сортировка данных
Представим, что мы отсортировали наши 10 записей по убыванию. Тогда используя алгоритм бинарного поиска, мы могли бы максимум за 4 операции отобрать нужные нам значения:
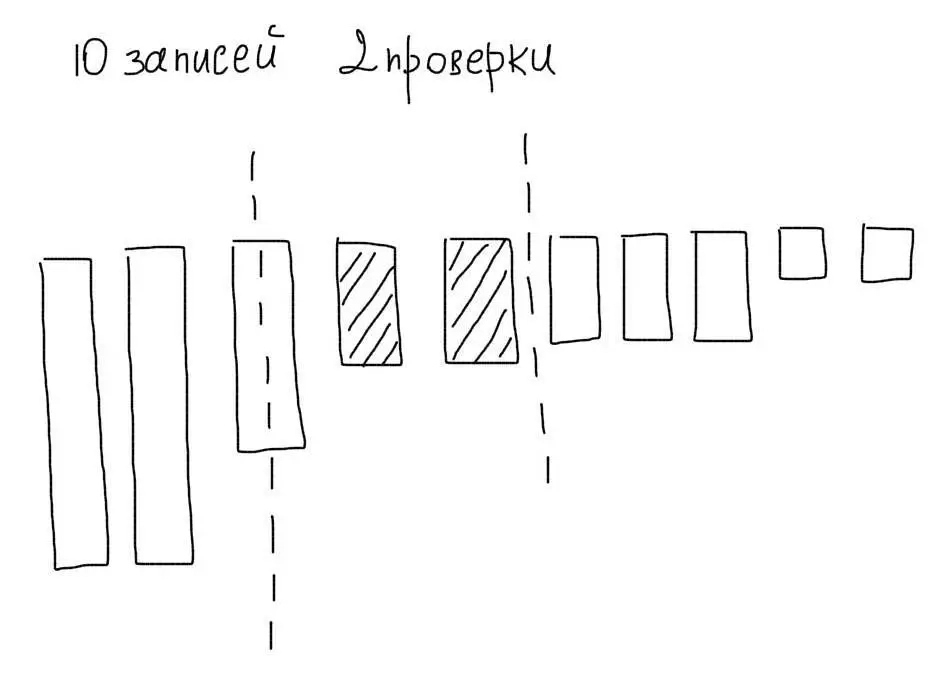
Кроме меньшего количества операций сравнения, мы сэкономили бы на чтении ненужных записей.
Индекс – это и есть отсортированный набор значений. В MySQL индексы всегда строятся для какой-то конкретной колонки. Например, мы могли бы построить индекс для колонки age из примера.
4. Выбор индексов в MySQL
В самом простом случае, индекс необходимо создавать для тех колонок, которые присутствуют в условии WHERE.
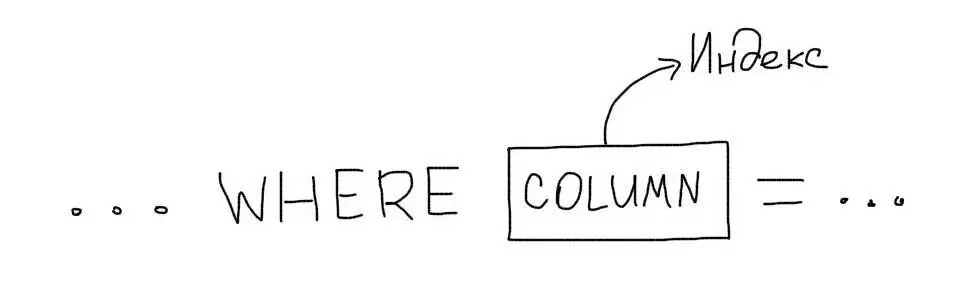
Рассмотрим запрос из примера:
Нам необходимо создать индекс на колонку age:
После этой операции MySQL начнет использовать индекс age для выполнения подобных запросов. Индекс будет использоваться и для выборок по диапазонам значений этой колонки:
Сортировка
Для запросов такого вида:
действует такое же правило – создаем индекс на колонку, по которой происходит сортировка:
Внутренности хранения индексов
Представим, что наша таблица выглядит так:
После создания индекса на колонку age, MySQL сохранит все ее значения в отсортированном виде:
Кроме этого, будет сохранена связь между значением в индексе и записью, которой соответствует это значение. Обычно для этого используется первичный ключ:
Уникальные индексы
MySQL поддерживает уникальные индексы. Это удобно для колонок, значения в которых должны быть уникальными по всей таблице. Такие индексы улучшают эффективность выборки для уникальных значений. Например:
На колонку email необходимо создать уникальный индекс:
Тогда при поиске данных, MySQL остановится после обнаружения первого соответствия. В случае обычного индекса будет обязательно проведена еще одна проверка (следующего значения в индексе).
5. Составные индексы
MySQL может использовать только один индекс для запроса (кроме случаев, когда MySQL способен объединить результаты выборок по нескольким индексам). Поэтому, для запросов, в которых используется несколько колонок, необходимо использовать составные индексы.
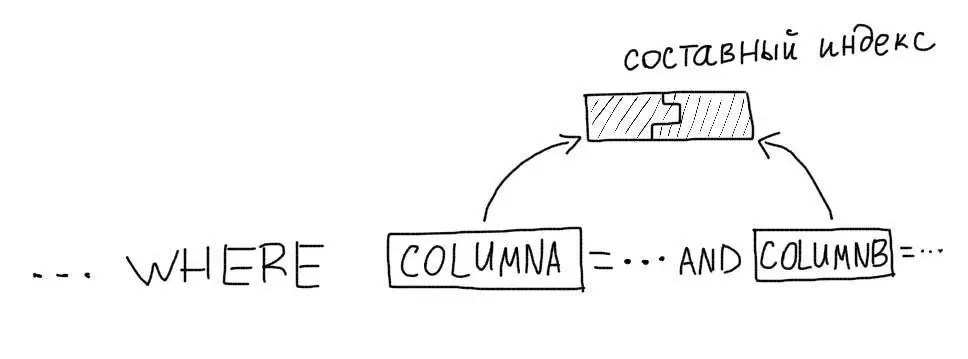
Рассмотрим такой запрос:
Нам следует создать составной индекс на обе колонки:
Устройство составного индекса
Чтобы правильно использовать составные индексы, необходимо понять структуру их хранения. Все работает точно так же, как и для обычного индекса. Но для значений используются значения всех входящих колонок сразу. Для таблицы с такими данными:
значения составного индекса будут такими:
Это означает, что очередность колонок в индексе будет играть большую роль. Обычно колонки, которые используются в условиях WHERE, следует ставить в начало индекса. Колонки из ORDER BY — в конец.
Поиск по диапазону
Представим, что наш запрос будет использовать не сравнение, а поиск по диапазону:
Тогда MySQL не сможет использовать полный индекс, т.к. значения gender будут отличаться для разных значений колонки age. В этом случае база данных попытается использовать часть индекса (только age), чтобы выполнить этот запрос:
Сортировка
Составные индексы также можно использовать, если выполняется сортировка:
В этом случае нам нужно будет создать индекс в другом порядке, т.к. сортировка (ORDER) происходит после фильтрации (WHERE):
Такой порядок колонок в индексе позволит выполнить фильтрацию по первой части индекса, а затем отсортировать результат по второй.
Колонок в индексе может быть больше, если требуется:
В этом случае следует создать такой индекс:
6. Использование EXPLAIN для анализа индексов
Инструкция EXPLAIN покажет данные об использовании индексов для конкретного запроса. Например:

Колонка key показывает используемый индекс. Колонка possible_keys показывает все индексы, которые могут быть использованы для этого запроса. Колонка rows показывает число записей, которые пришлось прочитать базе данных для выполнения этого запроса (в таблице всего 336 записей).
Как видим, в примере не используется ни один индекс. После создания индекса:

Прочитана всего одна запись, так как был использован индекс.
Проверка длины составных индексов
Explain также поможет определить правильность использования составного индекса. Проверим запрос из примера (с индексом на колонки age и gender):

Значение key_len показывает используемую длину индекса. В нашем случае 24 байта – длина всего индекса (5 байт age + 19 байт gender).
Если мы изменим точное сравнение на поиск по диапазону, увидим что MySQL использует только часть индекса:

Это сигнал о том, что созданный индекс не подходит для этого запроса. Если же мы создадим правильный индекс:

В этом случае MySQL использует весь индекс gender_age, т.к. порядок колонок в нем позволяет сделать эту выборку.
7. Селективность индексов
Вернемся к запросу:
Для такого запроса необходимо создать составной индекс. Но как правильно выбрать последовательность колонок в индексе? Варианта два:
Подойдут оба. Но работать они будут с разной эффективностью.
Чтобы понять это, рассмотрим уникальность значений каждой колонки и количество соответствующих записей в таблице:
68 rows in set (0.00 sec)
Эта информация говорит нам вот о чем:
Если колонка age будет идти первой в индексе, тогда MySQL после первой части индекса сократит количество записей до 200. Останется сделать выборку по ним. Если же колонка gender будет идти первой, то количество записей будет сокращено до 6000 после первой части индекса. Т.е. на порядок больше, чем в случае age.
Это значит, что индекс age_gender будет работать лучше, чем gender_age.
Селективность колонки определяется количеством записей в таблице с одинаковыми значениями. Когда записей с одинаковым значением мало – селективность высокая. Такие колонки необходимо использовать первыми в составных индексах.
8. Первичные ключи
Первичный ключ (Primary Key) — это особый тип индекса, который является идентификатором записей в таблице. Он обязательно уникальный и указывается при создании таблиц:
При использовании таблиц InnoDB всегда определяйте первичные ключи. Если первичного ключа нет, MySQL все равно создаст виртуальный скрытый ключ.
Кластерные индексы
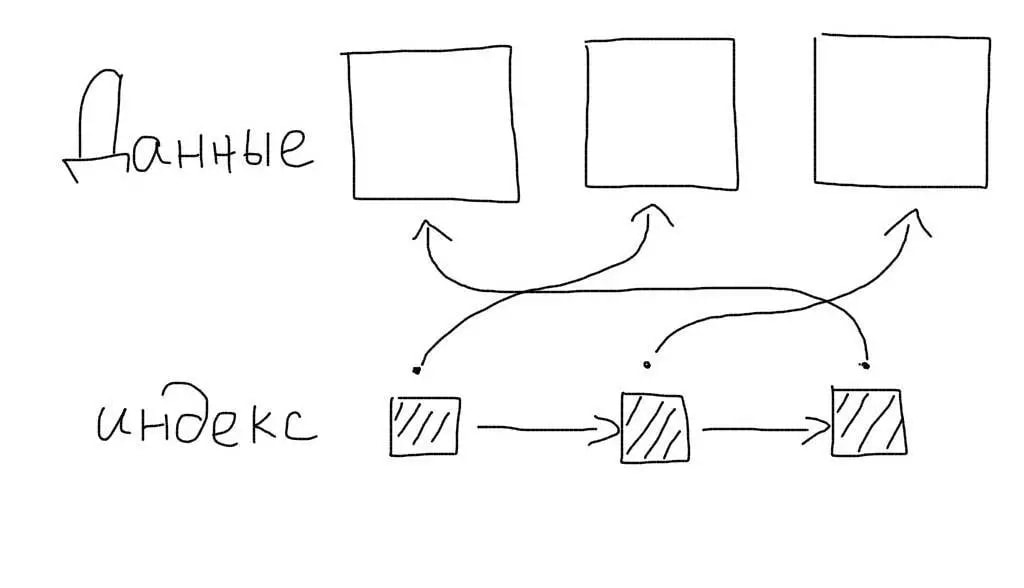
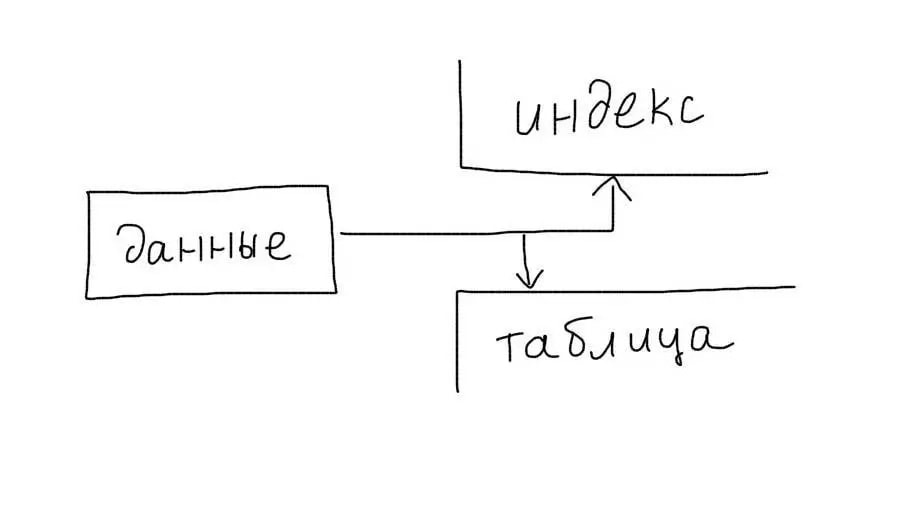
Обычные индексы являются некластерными. Это означает, что сам индекс хранит только ссылки на записи таблицы. Когда происходит работа с индексом, определяется только список записей (точнее список их первичных ключей), подходящих под запрос. После этого происходит еще один запрос — для получения данных каждой записи из этого списка.
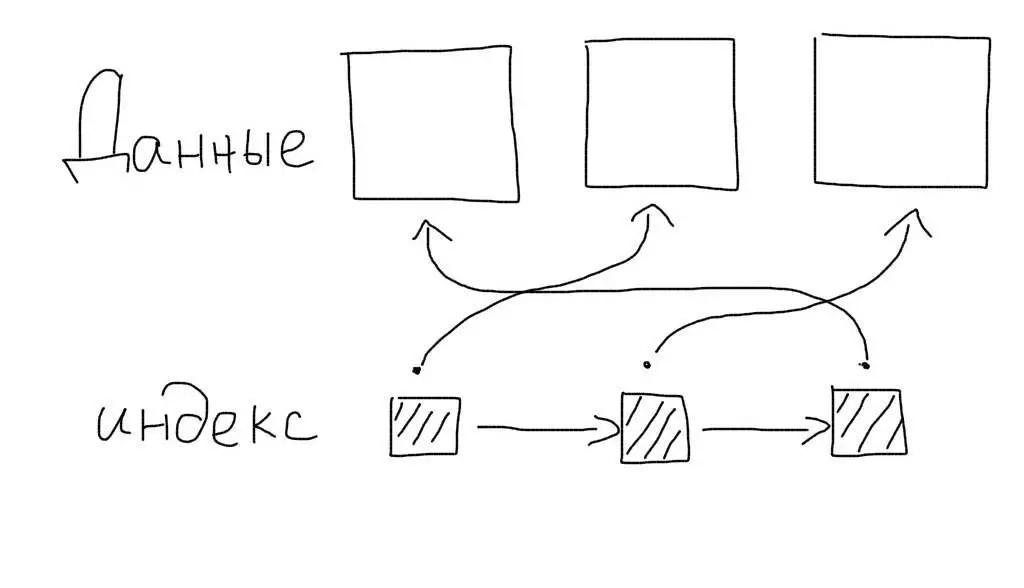
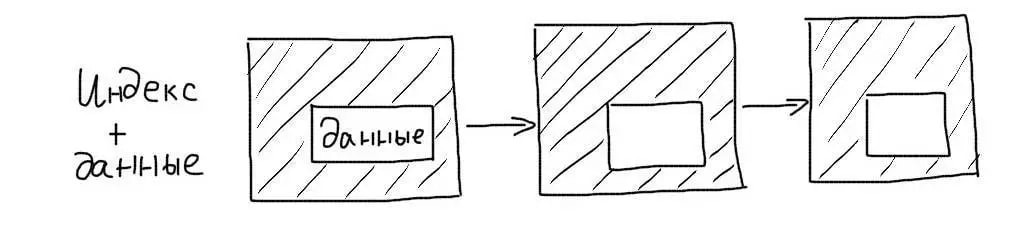
Кластерные индексы сохраняют данные записей целиком, а не ссылки на них. При работе с таким индексом не требуется дополнительной операции чтения данных.
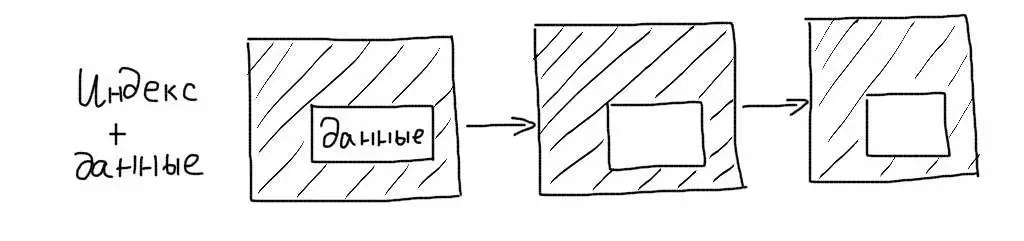
Первичные ключи таблиц InnoDB являются кластерными. Поэтому выборки по ним происходят очень эффективно.
Overhead
Важно помнить, что индексы предполагают дополнительные операции записи на диск. При каждом обновлении или добавлении данных в таблицу, происходит также запись и обновление данных в индексе.
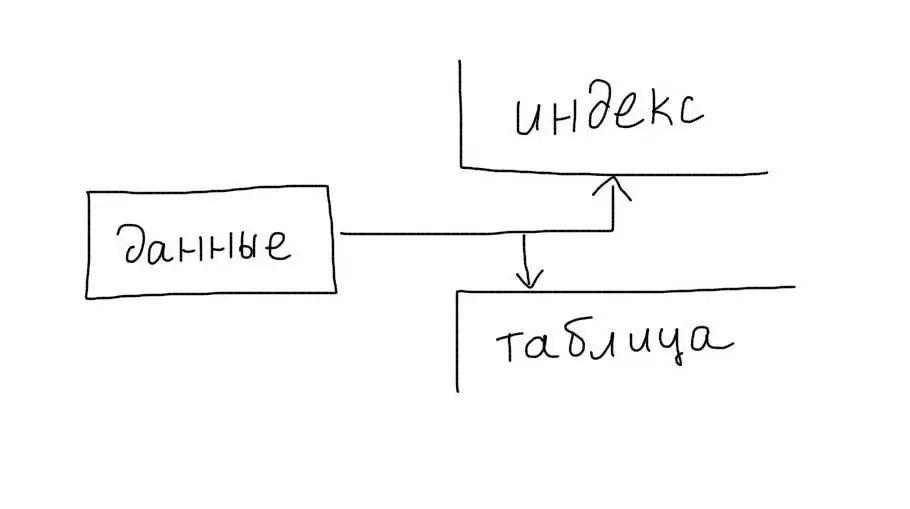
Создавайте только необходимые индексы, чтобы не расходовать зря ресурсы сервера. Контролируйте размеры индексов для Ваших таблиц:
Когда создавать индексы?
Самое важное
Выделяйте достаточно времени на анализ и организацию индексов в MySQL (и других базах данных). На это может уйти намного больше времени, чем на проектирование структуры базы данных. Удобно будет организовать тестовую среду с копией реальных данных и проверять там разные структуры индексов.
Не создавайте индексы на каждую колонку, которая есть в запросе, MySQL так не работает. Используйте уникальные индексы, где необходимо. Всегда устанавливайте первичные ключи.
Как исправить ошибку доступа к базе 1045 Access denied for user
Основные понятия о шардинге и репликации
Настройка Master-Master репликации на MySQL за 6 шагов
Примеры ad-hoc запросов и технологии для их исполнения
Анализ медленных PHP скриптов с помощью XHprof
Анализ медленных запросов (профилирование) в MySQL с помощью Percona Toolkit
Как создать и использовать составной индекс в Mysql
Типы и способы применения репликации на примере MySQL
Синтаксис и оптимизация Mysql LIMIT
Настройка Master-Slave репликации на MySQL за 6 простых шагов
Правильная настройка Mysql под нагрузки и не только. Обновлено.
И как правильно работать с длительными соединениями в MySQL
Check-unused-keys для определения неиспользуемых индексов в базе данных
Запрос для определения версии Mysql: SELECT version()
Как работают индексы в Clickhose и как их использовать.
3 примера установки индексов в JOIN запросах
Анализ медленных запросов с помощью EXPLAIN
Что значит и как это починить
Описание, рекомендации и значение параметра query_cache_size
Быстрый подсчет уникальных значений за разные периоды времени
Использование партиций для ускорения сложных удалений
Правила выбора типов данных для максимальной производительности в Mysql
Включение и использование логов ошибок, запросов и медленных запросов, бинарного лога для проверки работы MySQL
Индексы в MySQL
Индексы в MySQL (Mysql indexes) — отличный инструмент для оптимизации SQL запросов. Чтобы понять, как они работают, посмотрим на работу с данными без них.
1. Чтение данных с диска
На жестком диске нет такого понятия, как файл. Есть понятие блок. Один файл обычно занимает несколько блоков. Каждый блок знает, какой блок идет после него. Файл делится на куски и каждый кусок сохраняется в пустой блок.
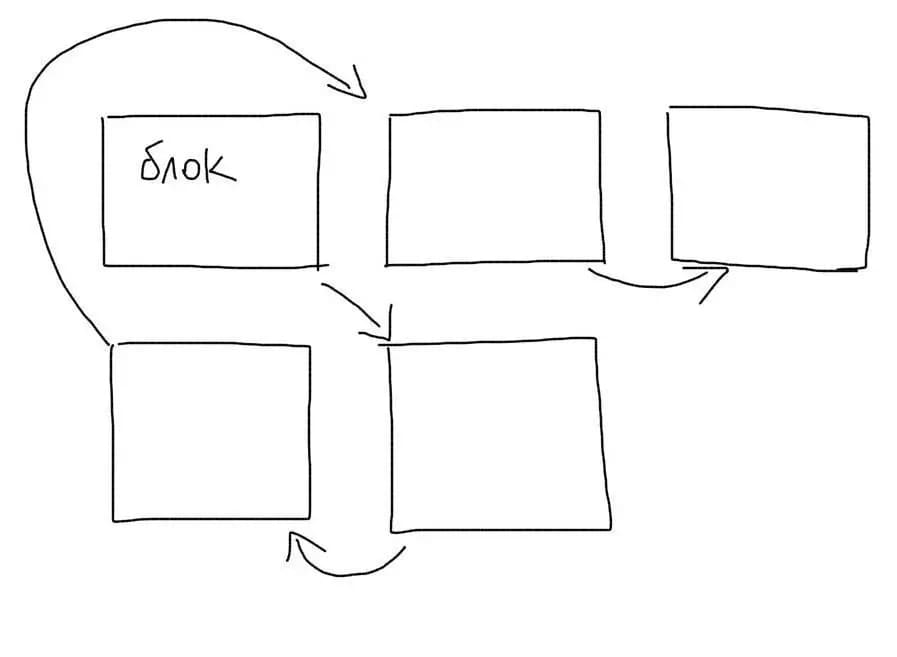
При чтении файла, мы по очереди проходимся по всем блокам и собираем файл из кусков. Блоки одного файла могут быть раскиданы по диску (фрагментация). Тогда чтение файла замедлится, т.к. понадобится прыгать разным участкам диска.
Когда мы ищем что-то внутри файла, нам понадобится пройтись по всем блокам, в которых он сохранен. Если файл очень большой, то и количество блоков будет значительным. Необходимость перепрыгивать с блока на блок, которые могут находиться в разных местах, сильно замедлит поиск данных.
2. Поиск данных в MySQL
Таблицы MySQL — это обычные файлы. Выполним запрос такого вида:
MySQL при этом открывает файл, где хранятся данные из таблицы users. А дальше — начинает перебирать весь файл, чтобы найти нужные записи.
Кроме этого, MySQL будет сравнивать данные в каждой строке таблицы со значением в запросе. Допустим работа ведется с таблицей, в которой есть 10 записей. Тогда MySQL прочитает все 10 записей, сравнит колонку age каждой из них со значением 29 и отберет только подходящие данные:
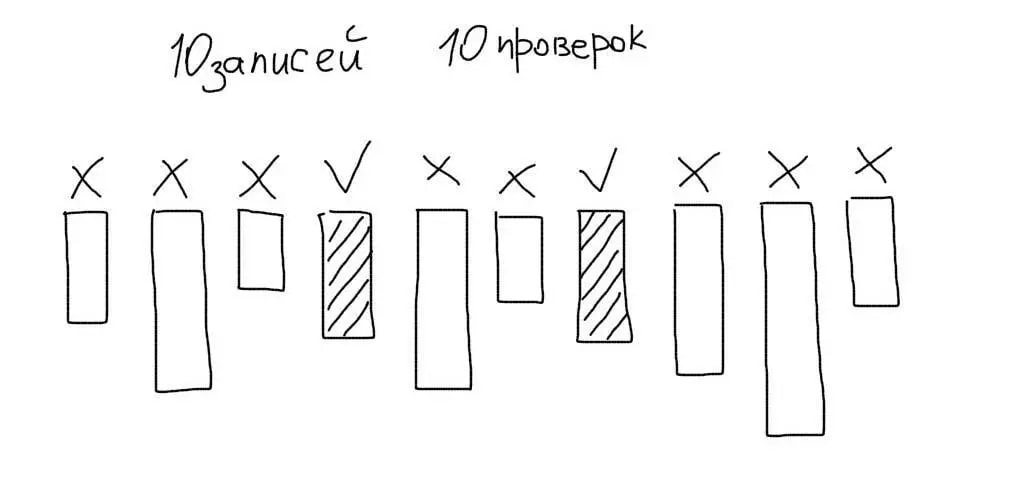
Итак, есть две проблемы при чтении данных:
3. Сортировка данных
Представим, что мы отсортировали наши 10 записей по убыванию. Тогда используя алгоритм бинарного поиска, мы могли бы максимум за 4 операции отобрать нужные нам значения:
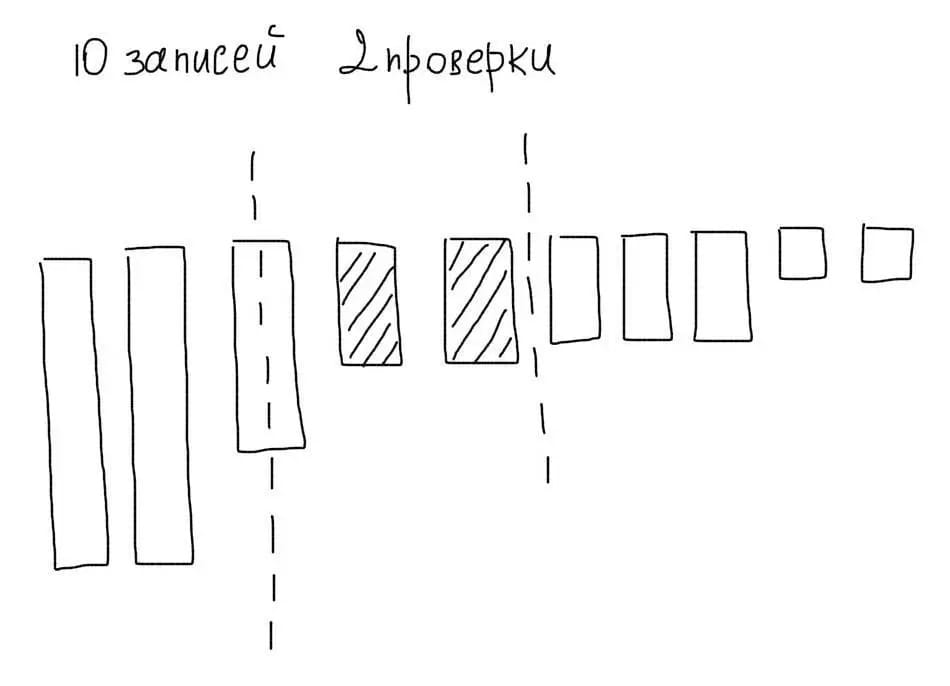
Кроме меньшего количества операций сравнения, мы сэкономили бы на чтении ненужных записей.
Индекс — это и есть отсортированный набор значений. В MySQL индексы всегда строятся для какой-то конкретной колонки. Например, мы могли бы построить индекс для колонки age из примера.
4. Выбор индексов в MySQL
В самом простом случае, индекс необходимо создавать для тех колонок, которые присутствуют в условии WHERE.
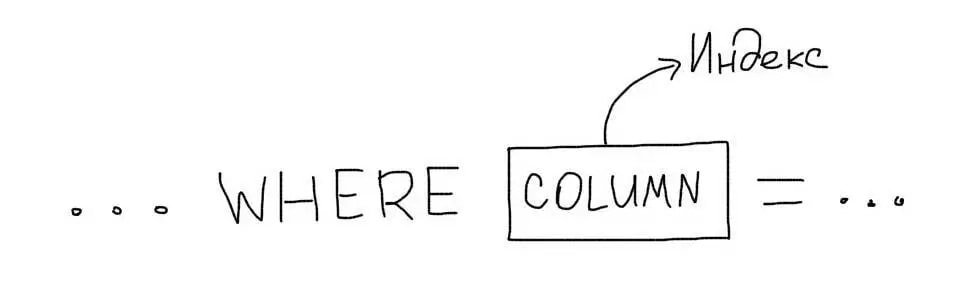
Рассмотрим запрос из примера:
Нам необходимо создать индекс на колонку age:
После этой операции MySQL начнет использовать индекс age для выполнения подобных запросов. Индекс будет использоваться и для выборок по диапазонам значений этой колонки:
Сортировка
Для запросов такого вида:
действует такое же правило — создаем индекс на колонку, по которой происходит сортировка:
Внутренности хранения индексов
Представим, что наша таблица выглядит так:
id | name | age
После создания индекса на колонку age, MySQL сохранит все ее значения в отсортированном виде:
age index
Кроме этого, будет сохранена связь между значением в индексе и записью, которой соответствует это значение. Обычно для этого используется первичный ключ:
age index и связь с записями
Уникальные индексы
MySQL поддерживает уникальные индексы. Это удобно для колонок, значения в которых должны быть уникальными по всей таблице. Такие индексы улучшают эффективность выборки для уникальных значений. Например:
На колонку email необходимо создать уникальный индекс:
Тогда при поиске данных, MySQL остановится после обнаружения первого соответствия. В случае обычного индекса будет обязательно проведена еще одна проверка (следующего значения в индексе).
5. Составные индексы
MySQL может использовать только один индекс для запроса (кроме случаев, когда MySQL способен объединить результаты выборок по нескольким индексам). Поэтому, для запросов, в которых используется несколько колонок, необходимо использовать составные индексы.
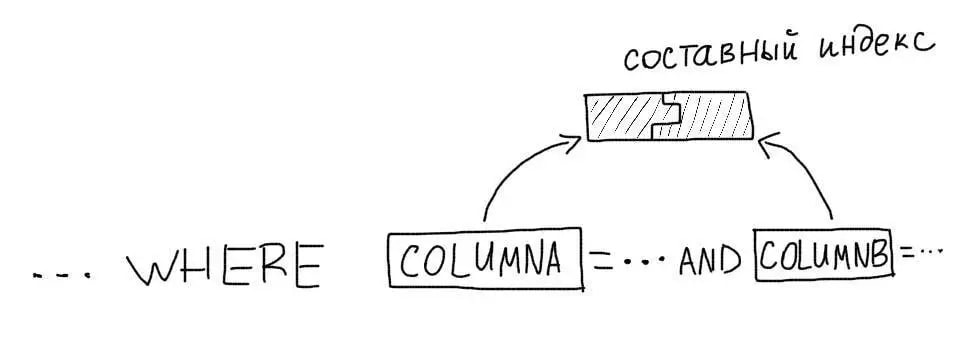
Рассмотрим такой запрос:
Нам следует создать составной индекс на обе колонки:
Устройство составного индекса
Чтобы правильно использовать составные индексы, необходимо понять структуру их хранения. Все работает точно так же, как и для обычного индекса. Но для значений используются значений всех входящих колонок сразу. Для таблицы с такими данными:
id | name | age | gender
значения составного индекса будут такими:
age_gender
Это означает, что очередность колонок в индексе будет играть большую роль. Обычно колонки, которые используются в условиях WHERE, следует ставить в начало индекса. Колонки из ORDER BY — в конец.
Поиск по диапазону
Представим, что наш запрос будет использовать не сравнение, а поиск по диапазону:
Тогда MySQL не сможет использовать полный индекс, т.к. значения gender будут отличаться для разных значений колонки age. В этом случае база данных попытается использовать часть индекса (только age), чтобы выполнить этот запрос:
age_gender
Сортировка
Составные индексы также можно использовать, если выполняется сортировка:
В этом случае нам нужно будет создать индекс в другом порядке, т.к. сортировка (ORDER) происходит после фильтрации (WHERE):
Такой порядок колонок в индексе позволит выполнить фильтрацию по первой части индекса, а затем отсортировать результат по второй.
Колонок в индексе может быть больше, если требуется:
В этом случае следует создать такой индекс:
6. Использование EXPLAIN для анализа индексов
Инструкция EXPLAIN покажет данные об использовании индексов для конкретного запроса. Например:
Колонка key показывает используемый индекс. Колонка possible_keys показывает все индексы, которые могут быть использованы для этого запроса. Колонка rows показывает число записей, которые пришлось прочитать базе данных для выполнения этого запроса (в таблице всего 336 записей).
Как видим, в примере не используется ни один индекс. После создания индекса:
Прочитана всего одна запись, т.к. был использован индекс.
Проверка длинны составных индексов
Explain также поможет определить правильность использования составного индекса. Проверим запрос из примера (с индексом на колонки age и gender):
Значение key_len показывает используемую длину индекса. В нашем случае 24 байта — длинна всего индекса (5 байт age + 19 байт gender).
Если мы выполним изменим точное сравнение на поиск по диапазону, увидим что MySQL использует только часть индекса:
Это сигнал о том, что созданный индекс не подходит для этого запроса. Если же мы создадим правильный индекс:
В этом случае MySQL использует весь индекс gender_age, т.к. порядок колонок в нем позволяет сделать эту выборку.
7. Селективность индексов
Вернемся к запросу:
Для такого запроса необходимо создать составной индекс. Но как правильно выбрать последовательность колонок в индексе? Варианта два:
Подойдут оба. Но работать они будут с разной эффективностью.
Чтобы понять это, рассмотрим уникальность значений каждой колонки и количество соответствующих записей в таблице:
Эта информация говорит нам вот о чем:
Если колонка age будет идти первой в индексе, тогда MySQL после первой части индекса сократит количество записей до 200. Останется сделать выборку по ним. Если же колонка gender будет идти первой, то количество записей будет сокращено до 6000 после первой части индекса. Т.е. на порядок больше, чем в случае age.
Это значит, что индекс age_gender будет работать лучше, чем gender_age.
Селективность колонки определяется количеством записей в таблице с одинаковыми значениями. Когда записей с одинаковым значением мало — селективность высокая. Такие колонки необходимо использовать первыми в составных индексах.
8. Первичные ключи
Первичный ключ (Primary Key) — это особый тип индекса, который является идентификатором записей в таблице. Он обязательно уникальный и указывается при создании таблиц:
При использовании таблиц InnoDB всегда определяйте первичные ключи. Если первичного ключа нет, MySQL все равно создаст виртуальный скрытый ключ.
Кластерные индексы
Обычные индексы являются некластерными. Это означает, что сам индекс хранит только ссылки на записи таблицы. Когда происходит работа с индексом, определяется только список записей (точнее список их первичных ключей), подходящих под запрос. После этого происходит еще один запрос — для получения данных каждой записи из этого списка.
Кластерные индексы сохраняют данные записей целиком, а не ссылки на них. При работе с таким индексом не требуется дополнительной операции чтения данных.
Первичные ключи таблиц InnoDB являются кластерными. Поэтому выборки по ним происходят очень эффективно.
Overhead
Важно помнить, что индексы предполагают дополнительные операции записи на диск. При каждом обновлении или добавлении данных в таблицу, происходит также запись и обновление данных в индексе.
Создавайте только необходимые индексы, чтобы не расходовать зря ресурсы сервера. Контролируйте размеры индексов для Ваших таблиц:
Когда создавать индексы?
Самое важное
Выделяйте достаточно времени на анализ и организацию индексов в MySQL (и других базах данных). На это может уйти намного больше времени, чем на проектирование структуры базы данных. Удобно будет организовать тестовую среду с копией реальных данных и проверять там разные структуры индексов.
Не создавайте индексы на каждую колонку, которая есть в запросе, MySQL так не работает. Используйте уникальные индексы, где необходимо. Всегда устанавливайте первичные ключи.



