AirTest IDE и Image Recognition — автоматизация тестирования мобильных игр на основе распознавания изображений
В предыдущей статье мы познакомились с AirTest IDE, но, на всякий случай, давайте повторим: AirTest IDE разработан компанией NetEase и предназначен для «hard-to-automate» приложений, таких как, например, игр. Собственно на них и делается основной упор разработчиками, хотя это не мешает использовать AirTest и для любых других приложений.
Данная работа является второй в цикле, посвящённому AirTest IDE. Первую, обзорную, статью про AirTest IDE вы можете найти здесь, а третью и последнюю, которая посвящена фреймворку UI автоматизации Poco — по данной ссылке.
Сегодня же я расскажу вам об одном из 2х основных фреймворков — AirTest. AirTest — это кросс-платформенный фреймворк для автоматизации UI, основанный на принципах распознавания изображений (Image Recognition), который, как заявляют разработчики, подходит для игр и приложений. AirTest Project на GitHub содержит 4 проекта: Airtest, Poco, iOS-Tangent, multi-device-runner.
А теперь давайте перейдём к самому интересному!
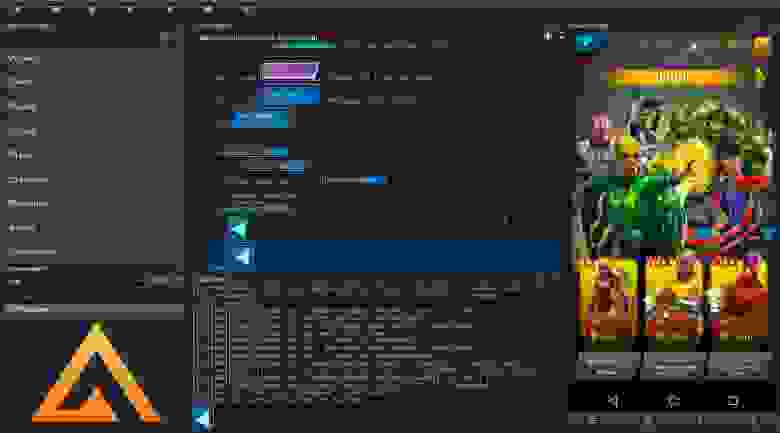
Как работает AirTest
AirTest обрабатывает полученные скриншоты на основе процесса thresholding. Суть заключается в том, чтобы сравнить интенсивность пикселей на изображении с некоторым числом (threshold value) и, если значение пикселя больше, то назначить ему цвет (чаще всего используется белый). В противном случае назначается другой цвет — чёрный. Как итог, на выходе получаем черно-белое изображение. Из этого следует естественное ограничение — AirTest не учитывает цвет во время распознавания. К примеру, если у вас используется объект с одним и тем же силуэтом, но разной, к примеру, раскраской и вам нужно проверить наличие элемента именно с определенной цветовой палитрой, то это будет крайне затруднительно, а может и не сработает вовсе.
К примеру в рамках пробы AirTest IDE было решено поработать с игрой Marvel Puzzle Quest. При загрузке персонажи с данной комикс вселенной мелькают на экране в определенном порядке. Время от времени у них меняются костюмы и это впервые насторожило меня. В примере ниже я ожидал, в рамках теста, Человека Паука в классическом, а получил в стелс костюме. Тест, собственно, прошёл успешно, а произошло это по причине описанной выше — использование чёрно-белого изображения во время распознавания. Пример того, что ожидалось и что, в итоге, получилось:

Улучшение вероятности успешного завершения тестов
Как вы уже поняли, Image Recognition — это далеко не панацея, хоть и работает здесь он хорошо. Для написания качественных тестов вам не избежать написания кода и, соответственно, знания основ Python. К примеру прежде чем искать конкретный элемент, неплохо было бы убедиться, что он действительно есть на экране. Бывают случаи, когда AirTest «промахивается» и может принять неправильный элемент за тот, что нужен вам. Время от времени бывают проблемы с распознаванием текста, который вы хотите найти при помощи Image Recognition. AirTest может спутать результаты и считать, что нужный вам текст есть на экране, но, на самом деле, текст там совершенно другой. Процесс анализа результатов призвана упростить система генерации отчётов, которая уже встроена в AirTest IDE. Создать и открыть отчёт можно после завершения теста/скрипта при помощи сочетания клавиш Ctrl/Cmd+L.
По общим рекомендациям я бы выделил ещё и следующее.
И если вы хотите спросить «Возможно ли изменить настройки процесса поиска изображений?», то я вам отвечу — да, это возможно.
Настройки поиска изображений (Image Recognition)
Пользователю позволено и рекомендуется работать с настройками Image Recognition, чтобы добиться нужных результатов, оптимизировать время и вероятность успешного распознавания элементов (success rate) на экране. Эти настройки хранятся в окне Image Editor и, чтобы открыть его, вам нужно дважды кликнуть на нужное изображение в Script Editor. Настройки распознавания каждой картинки нужно менять отдельно либо использовать глобальные переменные, если, к примеру, вы хотите увеличить требования к точности threshold операции для вашего проекта.
Image Editor содержит в себе рабочую зону, а также «Snapshot+Recognition» и «Show Help» кнопки. Первая отвечает за сравнение вашей текущей картинки со snapshot версией. Snapshot картинка захватывается с текущего окна на вашем девайсе. Вторая кнопка открывает мануал по функционалу Image Editor. В правой части окна отображается текущая картинка для поиска, а также такие настройки как filename, threshold, target_pos и rgb.
Написание автоматизированных тестов при помощи AirTest
В текущей версии программы вы можете пользоваться следующими командами, которые доступны в окне AirTest Assistant:
Данные команды разделены на 3 основные группы: Операции (Operations), вспомогательные функции (Auxiliary functions) и проверки (Assertions). Вы можете выбрать нужную вам группу при помощи соответствующего фильтра (выпадающее меню сразу под названием окна).
Команды, которым необходимо изображение, активируют функции записи скриншота сразу после нажатия на соответствующую кнопку. К примеру, чтобы выбрать на какой элемент нажать на экране, выберите команду touch в AirTest Assistant и в окне Device Screen, на активном устройстве, обведите нужный для нажатия элемент. После этого в главном окне (Script Editor) появится соответствующая команда, в нашем случае touch, с изображением в качестве параметра. Как итог, процесс автоматизации выглядит следующим образом (гифка записана с устаревшей версии AirTest IDE):
Если вы по какой-то причине не хотите вручную создавать скриншоты и\или в целом писать код, то можете воспользоваться функцией автоматической записи. Активировать её можно при помощи нажатии на кнопку «камеры» напротив выпадающего меню с группами команд в окне Airtest Assistant. Автозапись — штука достаточно точная и удобная, но, само-собой, не является панацеей и не заменит ручного набора кода.
Стоит упомянуть ещё 3 горячие клавиши — F5 (запуск скрипта), F10 (остановка запущенного скрипта), Ctrl+L/Cmd+L (создание отчёта на основе законченного теста).
Запускать готовые тесты можно и без UI, используя терминал (command line). Больше информации об этом в целом и о запуске тестов в частности можно найти здесь.
Пример отрывка теста, написанного при помощи AirTest фреймворка можно найти под спойлером!
Само-собой UI в вашем приложении/игре не состоит сплошь и рядом из уникальных иконок, кнопок, задников и т.п. Плюс ко всему периодически визуально идентичные элементы могут встречаться на одном экране, например кнопки, слайдеры и т.д. Чаще всего в таких случаях AirTest не сможет распознать нужный вам элемент и, либо тест упадет с ошибкой, либо будет выбран неверный элемент интерфейса для дальнейших манипуляций.

Специально для таких случаев был разработан ещё один фреймворк, который уже встроен в AirTest IDE. Он Poco и вкратце о нём уже было рассказано в статье с общим обзором Airtest IDE. Подробнее же о данном фреймворке я расскажу в следующей статье.
Расскажите, пользовались ли вы уже AirTest IDE и что вы думаете о данном инструменте. Буду рад обсуждению в комментариях!
Image Recognition
| Разработчики: | Intelligence Retail |
| Дата последнего релиза: | 2018/07/25 |
| Отрасли: | Торговля |
| Технологии: | Системы автоматизации торговли, Системы видеоаналитики |
Решение Intelligence Retail базируется на использовании технологий компьютерного зрения для распознавания товаров различных категорий с целью контроля наличия и корректности выкладки товаров в сети продаж. Система позволяет полевому сотруднику компании в течение 10 сек. получить необходимую информацию по ассортименту и выкладке. Онлайн аналитика в магазинах позволяет повысить эффективность визита, исключив сбор информации вручную. Распознавание товаров на уровне перечня ассортимента (SKU), цен и другой информации на фото в режиме онлайн дает новые возможности для повышения эффективности продаж. Расширенная аналитика по результатам визитов позволяет компании быстрее реагировать на изменения рынка— в том числе в задачах управления ассортиментом, качественной и количественной дистрибуцией.


2018: Встраивание технологий IBM Watson Analytics
25 июля 2018 года стало известно о том, что компания Intelligence Retail, резидент ИТ-кластера фонда «Сколково», выбрала продукт корпорации IBM для оптимизации своего основного решения, которое позволит заказчикам компании отслеживать ключевые показатели аудита розничной торговли в реальном времени.
По словам разработчиков, аналитический модуль Intelligence Retail, создаваемый на базе интеллектуальной службы бизнес-анализа и визуализации данных IBM Watson Analytics, сможет обрабатывать в режиме реального времени большие объемы данных для торгового аудита: наличие товара на полке, доля полки, цены, промоакции и т.д. Более оперативная и качественная аналитика позволит оптимизировать принятие решений по планированию продаж для каждого канала и региона торговли.
Решение Intelligence Retail позволяет превратить изображения торговых полок в содержательный источник данных торгового аудита, в то время как встроенные в него технологии IBM Watson Analytics добавят функционал выявления важных связей и выработки ценных рекомендаций для улучшения процесса торговли, отметили в компании.
Распознаем лица на фото с помощью Python и OpenCV

В этой статье я хотел бы остановиться на алгоритмах распознавания лиц, а заодно познакомить вас с очень интересной и полезной библиотекой OpenCV. Уверен, что этот материал окажется полезным для новичков в этой области.
Что нам понадобится:
• Установленный Python 2.7 с библиотеками NumPy и PIL
• OpenCV 2-й версии
Здесь ссылка на материал по установке всех необходимых компонентов. Установка всего необходимого не составит труда.
Для начала давайте разберемся, как распознать лицо на фотографии. Во-первых, нужно найти, где на фото расположено лицо человека и не спутать его с часами на стене и кактусом на подоконнике. Казалось бы, простая задача для человека, оказывается не такой простой для компьютера. Для того, чтобы найти лицо мы должны выделить его основные компоненты, такие как нос, лоб, глаза, губы и т.д. Для этого будем использовать шаблоны (они же примитивы Хаара) на подобие таких:
Если шаблоны соответствуют конкретным областям на изображении, будем считать, что на изображении есть человеческое лицо. На самом деле подобных шаблонов гораздо больше. Для каждого из них считается разность между яркостью белой и черной областей. Это значение сравнивается с эталоном и принимается решение о том, есть ли здесь часть человеческого лица или нет.
Этот метод называется методом Виолы-Джонса (так же известен как каскады Хаара). Давайте представим, что у нас на фотографии не одно большое лицо, а много мелких. Если применить шаблоны ко всей картинке мы не найдем там лиц, т.к. они будут меньше шаблонов. Для того чтобы искать на всем фото лица разных размеров используется метод скользящего окна. Именно внутри этого окна и высчитываются примитивы. Окно как бы скользит по всему изображению. После каждого прохождения изображения окно увеличивается, чтобы найти лица большего масштаба.
Наглядно демонстрацию алгоритма можно посмотреть на этом видео:
И так мы нашли лицо на фотографии, но как определить, что это лицо именно того кого мы ищем? Для решения этой задачи будем использовать алгоритм Local Binary Patterns. Суть его заключается в том, что мы разбиваем изображение на части и в каждой такой части каждый пиксель сравнивается с соседними 8 пикселями. Если значение центрального пикселя больше соседнего, то пишем 0, в противном случае 1. И так для каждого пикселя у нас получается некоторое число. Далее на основе этих чисел для всех частей, на которые мы разбивали фотографию, считается гистограмма. Все гистограммы со всех частей объединяются в один вектор характеризующий изображение в целом. Если мы хотим узнать насколько похожи два лица, нам придется вычислить для каждого из них такой вектор и сравнить их. Рисунки ниже помогут лучше понять суть алгоритма:
Ну хорошо, давайте, наконец напишем немного кода. За основу я взял код из этой статьи.
Параметр cascadePath содержит имя файла с уже готовыми значениями для распознавания лиц. Этот файл можно взять из директории с OpenCV (opencv\build\etc\haarcascades\).
Далее создаем объект CascadeClassifier и объект распознавания лиц LBPHFaceRecognizer. На последнем остановимся поподробнее, точнее, на его параметрах. Первые два значения 1 и 8 характеризуют окрестности пикселя. Наглядно, что это такое можно продемонстрировать этой картинкой:
То есть первое число это радиус в котором мы выбираем пиксели, а второй число этих пикселей. Чем больше пикселей в окрестности точки мы возьмем, тем точнее будет наше распознавание.
Следующие параметры (8,8) характеризуют размеры областей на которые мы разбиваем исходное изображение с лицом. Чем оно меньше, тем больше будет таких областей и тем качественнее распознавание.
И наконец, последнее значение это параметр confidence threshold, определяющий пороговое значение для распознавания лица. Чем меньше confidence тем больше алгоритм уверен в том, что на фотографии изображено известное ему лицо. Порог означает, что когда уверенности мало алгоритм просто считает это лицо незнакомым. В данном случае порог равен 123.
Идем дальше. Напишем функцию, которая находит по определенному пути во всех фотографиях лица людей и сохраняет их.
Для примера я использовал БД лиц под названием Yale Faces. В ней есть 15 человек с разными выражениями лиц на каждой фотографии. 
Теперь давайте разберемся с параметрами функции:
image – исходное изображение
scaleFactor – определяет то, на сколько будет увеличиваться скользящее окно поиска на каждой итерации. 1.1 означает на 10%, 1.05 на 5% и т.д. Чем больше это значение, тем быстрее работает алгоритм.
minNeighbors — Чем больше это значение, тем более параноидальным будет поиск и тем чаще он будет пропускать реальные лица, считая, что это ложное срабатывание. Оптимальное значение 3-6.
minSize – минимальный размер лица на фото. 30 на 30 обычно вполне достаточно.
Ну что же, теперь мы можем создать набор лиц и соответствующих им меток. Давайте научим программу распознавать эти лица.
Указываем путь к нашим фото, получаем список с фотографиями и метками. А дальше запускаем нашу функцию тренировки с помощью алгоритма LBP. Ничего сверхъестественного в ней нет, просто передаем ей значения, полученные после запуска функции get_images(). Все остальное программа сделает сама.
И так у нас есть обученный «распознаватель» и есть набор счастливых лиц. Теперь нам необходимо попросить алгоритм распознать эти счастливые лица.
BELUGA GROUP: автоматизация торгового аудита на базе Image Recognition

Впервые на российском алкогольном рынке: нейросеть определяет SKU с точностью 96%.

Цели проекта — увеличение скорости торгового аудита и ценового мониторинга; оперативная информация о наличии товара на полках торговых сетей.
Задачи проекта — автоматизировать процесс распознавания наименований (бренд, марка и литраж SKU); определять полку, на которой размещен товар; распознавать ценники.
Предыстория
Аудит мест продаж проводят мерчандайзеры и торговые представители BELUGA GROUP: они фотографируют магазинные полки и заполняют мерчандайзинговые отчеты в приложении «ST Мобильная Торговля» (поставщик — «Системные Технологии»). Собранные данные поступают в центральный офис компании. Раньше для обработки данных требовался штат операторов. Но в 2018 году команда BELUGA GROUP проанализировала технологические инновации и предположила, что применение нейронных сетей позволит оптимизировать и ускорить процесс обработки данных.
Три пилота
Первый пилот по оцифровке категорий «Водка» и «Вино» BELUGA GROUP провела в 2018 году. Лучший результат показала система SmartMerch, но точность данных составила всего 70%.
«Мы начали с невысоких показателей. Это был первый проект в отрасли, и не было гарантий, что технологию можно адаптировать для нашего сегмента, — рассказывает менеджер проектов BELUGA GROUP Петр Кузин. — Эксперты не знали, как использовать нейросети на рынке крепкого алкоголя, и поставщики решений допускали ошибки.
Основная трудность — научить нейросеть распознавать объем SKU. Бутылки водки разного литража, например, 0,5 и 1 литр, на фото часто выглядят одинаково. Если они стоят рядом, то система может сравнить размеры и сделать выводы. А если нет? Во время „пилота“ мы проверили несколько подходов к повышению качества данных, один из которых: высчитывать площадь бутылки и сравнивать ее с окружающими объектами».

Вторая итерация состоялась в 2019 году на ограниченной выборке: в процессе распознавания участвовал не весь ассортимент, а несколько позиций. SmartMerch вновь показал лучший результат: качество приблизилось к 90%. Но оставался вопрос — удастся ли сохранить такой высокий уровень на полном ассортименте. В это же время BELUGA GROUP провела дополнительный пилот по выбору новых устройств для «полевых» сотрудников.
Роллаут
В июле-августе модуль SmartMerch заработает на устройствах мерчандайзеров в Москве и Санкт-Петербурге. Осенью планируется запустить проект на территории всей России. Переход на цифровой мониторинг приведет к переосмыслению доли полки BELUGA GROUP в торговых сетях.
При ручном аудите:
информация о ситуации в торговой точке, в том числе об аутофстоках, поступает с задержкой до 5 дней;
нет гарантии, что операторы исследуют все фотографии;
при расчете используются предустановленные значения для определенных категорий торговых точек.
После внедрения цифромерча:
сформированный отчет приходит уже к 8 утра следующего дня;
система гарантированно обрабатывает все загруженные снимки;
доля полки рассчитывается исходя из текущей ситуации в конкретной торговой точке — компания получает данные о ситуации «здесь и сейчас».
Изменятся стандарты фотоотчетности — как, что и под каким углом фотографировать. При ручном аудите оператор распознавал даже плохо выставленные SKU. А SmartMerch может не определить бутылку, которая повернута боком, что приведет к фиксации „ложного“ аутофстока. Значит, сотрудники должны делать мерчандайзинг тщательнее, чтобы получать правильную картинку ситуации на полке».
Отзыв о команде SmartMerch
«Мы всегда 10 раз отмерим, прежде чем идти в проект, — говорит Петр. — На пилотах у нас был опыт сотрудничества с несколькими партнерами: кто-то вышел из проекта после первого пилота, кто-то бился до финала. Но именно SmartMerch проявил себя как стойкий, надежный и самоотверженный партнер. За 2 года команда проделала огромную работу для достижения высокого уровня качества данных. Мы довольны своим выбором».
Участники проекта:
BELUGA GROUP — крупнейшая алкогольная компания России, лидер по производству водки и ликеро-водочных изделий на этом рынке, а также один из главных импортеров крепкого алкоголя в стране. Группе принадлежат шесть производственных площадок, одно винное хозяйство, собственная система дистрибуции и сеть розничных магазинов «ВинЛаб».
Ключевые собственные бренды: суперпремиальная водка Beluga, водки «Беленькая», «Архангельская», «Белая Сова», «Медная Лошадка», «Мягков», тихое вино Golubitskoe Estate, игристое вино Tête de Cheval, российское шампанское VOGUE, бренди «Золотой Резерв» и «Бастион», джин Green Baboon, виски Fox & Dogs, Troublemaker и Eagle’s Rock.
Кроме того, группа является эксклюзивным дистрибьютором William Grant & Sons и представляет в России всемирно известные бренды этой компании. Также BELUGA GROUP дистрибутирует продукцию французского коньячного дома Camus, ром Barcelo, бренди Torres, армянский коньяк «Ной», кальвадос Berneroy, портвейны Sandeman, а также линию бальзамов Latvijas Balzams. Группа эксклюзивно представляет в России вина мировых производителей и брендов из Италии, Франции, Испании, Чили, Германии, Португалии и других стран, а также является эксклюзивным дистрибьютором австрийского производителя премиальных бокалов и стекла RIEDEL.
BELUGA GROUP успешно поставляет свою продукцию на более 100 зарубежных рынков и входит в тройку крупнейших экспортеров российской водки, занимая лидирующие позиции в России по экспорту этого продукта в суперпремиальном сегменте.
SmartMerch — российский сервис для автоматизации торгового аудита на базе нейронных сетей и машинного обучения. Позволяет минимизировать влияние человеческого фактора на оценку полочного пространства и сократить время на проведение аудитов, увеличив их качество и достоверность.
«Системные Технологии» — поставщик решений для управления каналами дистрибуции в России, Восточной Европе и Средней Азии. Основная специализация — автоматизация компаний, использующих технологии предварительного сбора заказа и мерчандайзинга.
Как работает фотораспознавание в мерчандайзинге – Круглый стол агентств
Фотораспознавание как сервис на рынке мерчандайзинга, определенно, становится рабочим инструментом. Точность и скорость распознавания значительно выросли, а технологии и стоимость стали доступнее, чем, например, 3-5 лет назад.
Мерчандайзинговые агентства предлагают клиентам эту услугу для экономии временных и финансовых затрат, связанных с проведением ритейл-аудита, а реализованные проекты позволяют говорить о высокой точности распознавания.
Эксперты круглого стола поделились своими наблюдениями и цифрами из практики (сокращение времени визита, скорость и точность распознавания), рассказали о существующих барьерах для внедрения со стороны клиентов, об отношении полевого персонала к технологии и о том, на какие детали обратить внимание при выборе подрядчика для проекта по фотораспознаванию (ФР).
Александр Царев, креативный директор, Ace Target
В последние два года мы видим существенный прогресс, связанный с повышением качества фотораспознавания. На большинстве проектов регулярная точность достигает 93-95%. Это достаточно для того, чтобы говорить о работоспособности технологии.
Наибольшую сложность для нас представляют проекты, когда клиент хочет не просто определить SKU или посчитать фейсинги продукции, а оценить долю полки в категории. Вмешиваются различные технические сложности. Например, нижние ряды часто распознаются хуже, чем верхние и средние. В случае использования фирменного оборудования и большого вертикального блока выкладки задача еще усложняется.
До сих пор есть категории, для работы с которыми не имеет смысла использовать ФР. Например, колбасные изделия или продукцию, выложенную горизонтально в холодильнике, проще считать вручную.
Полевые сотрудники, на мой взгляд, уже смирились с тем, что практически каждый шаг их работы автоматизирован. Наибольшее сопротивление у них вызвало внедрение систем полевого контроля. На этом фоне автоматическое фотораспознавание для мерчандайзеров – это скорее полезный инструмент. Он сокращает время рутинной работы, уменьшает количество ошибок. И еще бонус – в значительной степени освобождает сотрудника от ответственности. Мерчандайзеру не нужно думать, правильно ли выставлена продукция, ему достаточно научиться выстраивать кадр и фотографировать на базовом уровне.
Барьеры клиентов для применения фотораспознавания связаны с относительной сложностью внедрения и стоимостью проекта. Клиенты опасаются, что для использования ФР требуется оборудование (телефоны, планшеты) с более высокими характеристиками. Многих клиентов пугает увеличение объема аналитики, вопросы организации хранения данных. Тем не менее снижение стоимости технологии и повышение качества распознавания привели к тому, что из крупных клиентов ФР используют уже две трети.
При выборе подрядчика важно оценить стоимость и скорость внедрения, финальную стоимость проекта, требования к оборудованию у полевого персонала, точность распознавания, возможность интеграции решения в информационные системы компании.
Для большинства клиентов важны кейсы исполнителя в определённом сегменте, так как наличие у подрядчика базы данных изображений для определенной товарной категории ускоряет и упрощает процесс запуска, и количество ошибок на старте будет минимальным.
Дмитрий Целищев, руководитель департамента мерчандайзинга, BeeTL
Система фотораспознавания действительно помогает оптимизировать временные и финансовые затраты на мерчандайзинг. Например, в 2019 году мы реализовали кейс с компанией Heineken – в торговых точках формата гипермаркет, с широкой ассортиментной линейкой. Нам удалось сравнить результаты применения двух SFA-систем – c функцией ФР и без нее.
Еженедельно мы проводили встречи с клиентом и анализировали каждый визит мерчандайзера, проверяя релевантность заполненной таблицы и фотографий. Процент анкет с ошибками на старте составлял 30%. После запуска системы ФР процент некорректно заполненных анкет сократился до 2%.
Система фотораспознавания помогла сократить время визита на 30% и, как следствие, сэкономить бюджет. Показатель экономии 50% пока кажется недостижимым на практике, так как значительную часть времени визита «съедает» составление отчетности, это занимает около 25 минут.
Точность ФР даже в сложных категориях может составлять порядка 90%. В нашей практике есть успешные кейсы по работе с «проблемными» категориями, которые это подтверждают. Например, бренд «Коровка из Кореновки» компании «Ренна».
В работе с ассортиментной группой «молочки» и мороженого главная проблема – это хранение в холодильной камере, где SKU располагаются хаотично. Проведя ряд экспериментов и замеров, мы убедились, что эффективная работа с категорией заморозки тоже возможна: процент фотораспознавания после работы мерчандайзера составил 93%.
Что касается барьеров внедрения ФР, я бы выделил 3 основных: первый опыт внедрения на российском рынке, стоимость и человеческий фактор.
Две лидирующие иностранные компании на рынке фотораспознавания – Planorama и Trax – не смогли при выходе на российский рынок обеспечить должную поддержку пользователей. Тестирование стоило дорого, а уровень сервиса был недостаточным для эффективной работы. В результате первый опыт взаимодействия с мировыми лидерами сформировал негативное отношение со стороны клиентов к технологии в целом.
Но с 2019 года в России появились несколько сильных игроков с поддержкой внутри страны, такие как Intelligence Retail и Inspector Cloud. Это меняет ситуацию с сервисом в лучшую сторону.
Второй барьер – стоимость внедрения. Для запуска проекта необходимы инвестиции. На этапе обучения системы (2-3 месяца) расходы могут составить от 150 до 300 тыс. руб. Для полного запуска потребуется около 1 млн рублей. Не каждая компания может себе это позволить.
Также при внедрении системы ФР могут обнаружиться слабые места бизнес-процессов, связанные с человеческим фактором. Система «вскрывает» недоработки, ставит под сомнение объективность показателей и может даже разрушить репутацию отдельных сотрудников. Есть ряд компаний, которые не готовы доверить системе даже часть работы с точками.
Дмитрий Кашкаров, директор по маркетингу, группа компаний POS Management
При предоставлении качественных фотографий все подрядчики готовы обеспечить точность распознавания выше 95%. Но именно это требование и является «узким» местом: как бы супервайзеры ни старались, бракованные фотографии на практике встречаются очень часто.
При старте проекта или найме новых сотрудников показатель некачественных фото составляет порядка 40%, в дальнейшем цифра падает до 5-10%.
Что касается сокращения времени визита после внедрения технологии Image Recognition, то в нашей практике этот показатель составляет в среднем 20-30%.
В сегменте DIY достаточно много «сложных» для фотораспознавания товарных групп – например, те же розетки. Отличить по фотографии розетку с подсветкой от розетки без подсветки сложно, так как габариты и форма упаковки одинаковы. Чтобы решить проблему, потребовалась привязка к ценникам. Мерчандайзеру нужно было проверить выкладку на соответствие планограмме и сфотографировать полку с ценником. По результатам мы увидели не сокращение времени на предоставление отчёта, а увеличение, поэтому проект был признан неперспективным и завершён.
Без реальной демонстрации возможностей компьютерного зрения клиенты слабо представляют, каким образом дополнительные расходы на внедрение технологии приводят к экономии. Первое время мы и сами не верили, что такие затраты могут окупиться. Но всё изменил один проект.
Клиент сам предложил использовать возможности нейронных сетей, и по результатам тестового периода мы увидели сокращение затрат на мерчандайзинг до 10% лишь за счёт ускорения работы визитного мерчандайзера в точках продаж. Плюс сократилось время составления и проверки отчётов. Результатами «эксперимента» остались довольны и полевые сотрудники, и менеджерский состав.
При выборе подрядчика в первую очередь нужно учитывать, имеет ли поставщик опыт работы именно с вашей категорией товара. Во вторую очередь обязательно надо тестировать приложение в полях, то есть самим съездить на объекты и сделать отчёты. Только так можно оценить реальное удобство и скорость работы приложения, получить аргументы для работы с возражениями полевых сотрудников и соотнести всё это со стоимостью.
Павел Мальцев, Руководитель службы ИТ и финансового контроля, TR-Project
Точность фотораспознавания действительно высока, но она сильно зависит от степени обученности нейросети и от ассортимента. На одном ассортименте (например, товары в твердой упаковке/бутылках) распознавание работает эффективно. В других случаях (мягкая упаковка, мелкий товар) – показатель распознавания будет ниже.
Но даже в проблемных случаях ФР позволяет добиваться высокой точности, если учитывать дополнительные параметры. Например, при распознавании стиральных порошков в мягкой упаковке мы столкнулись со сложностью различить упаковки весом 6 кг и 9 кг. Благодаря тому, что дополнительно «считывается» цена товара и анализируется ассортиментная матрица конкретной торговой точки, нам удалось справиться с этой проблемой.
Стандартные задачи наших клиентов, которые решаются с помощью ФР: контроль OOS, мониторинг цен (собственных и конкурентов), контроль промо. Также клиентов интересует контроль соблюдения планограмм.
На текущий момент технология Image Recognition не способна заменить мерчандайзера. Сотрудники это понимают и воспринимают ФР скорее как инструмент, который помогает эффективнее решить поставленные задачи.
Например, в мобильном приложении TRmobile есть функция обратной связи. Это позволяет по результатам распознавания получить оценку качества выполненной работы, узнать, что сделано неправильно, какие показатели не соответствуют целевым значениям. Получение этой информации во время визита помогает мерчандайзеру исправить ситуацию и улучшить свои показатели.
Что касается требований к кандидатам на позицию мерчандайзера, то они не снижаются. Автоматизация диктует более высокие требования к квалификации мерчандайзера, требует от него навыков работы со специализированными мобильными приложениями, навыков фотографирования, склейки и т.п.
В основе большинства решений по ФР лежит технология машинного обучения на основе искусственных нейронных сетей. И при выборе подрядчика важно учесть, как будет построен процесс обучения, чьими силами он будет выполняться (на стороне подрядчика или заказчика), сколько времени займет обучение, какое качество распознавания гарантирует подрядчик.
Другой важный фактор – скорость распознавания, возможность предоставления результатов мерчандайзеру в онлайн-режиме. Она зависит от того, где выполняется ФР: на стороне мобильного устройства или на сервере.
Также следует обратить внимание на анализируемые показатели, стоимость услуги и способ тарификации (за визит или за фото).
Сложными, с точки зрения технологии распознавания изображений, являются категории товара в прикассовой зоне и товары с небольшой площадью упаковки. В прикассовой зоне сложно определить количество фейсов товара, и точно можно определить только наличие товара на полке. В случае небольшой площади упаковки на одной фотографии получается очень много SKU, поэтому для достижения удовлетворительного результата нужны фотографии хорошего качества.
Обычно клиенты внедряют фотораспознавание в контексте отчетности: зафиксировать результат работы в торговом зале, финализировать визит. Кроме того, ФР помогает собирать информацию о состоянии торгового пространства, сравнивать ситуацию до начала выкладки товара и после окончания работы с полкой. Это позволяет собирать информацию о полочном пространстве, чтобы в дальнейшем повышать эффективность мерчандайзинга и влиять на продажи товара.
Основная работа мерчандайзера – это работа с товаром, на нее уходит до 85% рабочего времени. Небольшую оптимизацию по времени, которую дает использование технологии ФР, мы направляем на дополнительную работу с товаром, а не на сокращение времени визита. Требования к кандидатам остаются прежними.
Основная проблема при внедрении ФР – это достаточно длительный процесс «обучения системы» (2-3 месяца) и относительная дороговизна. Технология предполагает сбор большого количества фотографий для обучения системы, определенные требования к оборудованию и техническое сопровождение системы.
При выборе подрядчика лучше обращать внимание на те компании, у которых был опыт работы с товарами интересующей вас категории, оценивать стоимость услуги и сроки реализации проекта.



