hub and spokes
Смотреть что такое «hub and spokes» в других словарях:
Hub-and-Spoke — Der Begriff Hub and Spoke bzw. Nabe Speiche wird in verschiedenen Zusammenhängen benutzt. Gemeint ist damit in allen Fällen, dass die Verbindung zwischen zwei Endknoten A und B nicht direkt, sondern über einen Zentralknoten Z, den Hub (englisch:… … Deutsch Wikipedia
Hub and Spoke System — Der Begriff Hub and Spoke bzw. Nabe Speiche wird in verschiedenen Zusammenhängen benutzt. Gemeint ist damit in allen Fällen, dass die Verbindung zwischen zwei Endknoten A und B nicht direkt, sondern über einen Zentralknoten Z, den Hub (englisch:… … Deutsch Wikipedia
Hub and Spoke — Der Begriff Hub and Spoke, Speichenarchitektur bzw. Nabe Speiche wird in verschiedenen Zusammenhängen benutzt. Gemeint ist damit in allen Fällen, dass die Verbindung zwischen zwei Endknoten A und B nicht direkt, sondern über einen Zentralknoten Z … Deutsch Wikipedia
Hub and Spoke Program — (HASP) For surface mail, primarily for 2 day committed mail. The HASP includes a central point ( hub ) where mail for a group of offices ( spokes ) can be unloaded from a series of incoming trips, massed according to their intended destination,… … Glossary of postal terms
Hub And Spoke Structure — An investment structure in which several investment vehicles, while each remaining individually managed, pool their assets together by contributing to one central investment vehicle. The smaller investment vehicles are referred to as the spokes… … Investment dictionary
hub and spoke distribution — A physical distribution system developed and modeled on industry standards to provide cargo management for a theater. It is based on a “hub” moving cargo to and between several “spokes”. It is designed to increase transportation efficiencies and… … Military dictionary
Hub (Luftfahrt) — Hub and Spokes am Flughafen Frankfurt Unter einem (Luftfahrt )Drehkreuz, auch (Air )Hub (engl. air für Luft; hub für Nabe, Dreh und Angelpunkt, Schnittstelle) genannt, versteht man in der Luftverkehrswirtschaft im Unterschied zu dem umfassenderen … Deutsch Wikipedia
Hub (Transportwesen) — Hub and Spokes am Flughafen Frankfurt Unter einem (Luftfahrt )Drehkreuz, auch (Air )Hub (engl. air für Luft; hub für Nabe, Dreh und Angelpunkt, Schnittstelle) genannt, versteht man in der Luftverkehrswirtschaft im Unterschied zu dem umfassenderen … Deutsch Wikipedia
Hub gear — Sturmey Archer SX3 A Sturmey Archer AM bicycle hub gear mechanism wi … Wikipedia
hub — /hub/, n., v., hubbed, hubbing. n. 1. the central part of a wheel, as that part into which the spokes are inserted. 2. the central part or axle end from which blades or spokelike parts radiate on various devices, as on a fan or propeller. 3. a… … Universalium
Hub — Takt; Gewandtheit; Taktsignal; Drehkreuz; Umschlagpunkt; Drehscheibe * * * Hub1 〈m. 1u〉 1. Heben, Hebebewegung 2. Hin od. Herbewegung eines Maschinenteils zw. zwei Totpunkten (KolbenHub) 3. = H … Universal-Lexikon
Программная маршрутизация: история переезда с hub-n-spoke (vyatta+openvpn) на fullmesh (mikrotik+tincvpn) — часть 1

Под катом любопытного хабрачитателя ждет описание страданий людей, которые в свое время сэкономили денег на цисках с dmvpn.
А так же то, что из этого получилось.
Предистория вопроса
Несколько лет назад, когда трава была зеленее, а %company_name% только начинала свою делятельность и имела 2 филиала,
было принято решение использовать изпользовать Vyatta Network OS в качестве единой платформы маршрутизации, а статические openvpn site-to-site тоннели — в качестве решения для VPN.
Одной из причиной такого решения была богатая возможность кастомизации ISR.
В качестве одной из мер по резервированию в каждый филал устанавливалось по 2 маршрутизатора.
«звездатая» топология при таком количестве пиров считалась оправданной.
В качестве hardware appliance предполагалось использовать
— полноценные сервера с esxi — для крупных инсталляций
— сервера с atom — для мелких.
ВНЕЗАПНО, за год количество филиалов увеличилось до 10, а еще за полтора — до 28.
Постоянный поток фирчеквестов от бизнеса провоцировал рост трафика и появление новых сетевых и application сервисов.
Некоторые из них оседали на виртуалках linux-маршрутизаторов, вместо отдельных серверов.
Функционала vyatta стало не хватать, большое количество пакетов сказывалось на общей стабильности и производительности сервисов.
Также, был ряд проблем с VPN.
1. На тот момент было около 100 статических тоннелей, терминировавихся в одну точку.
2. В перспективе было еще открытие 10 филиалов.
К тому же, openvpn в текущей реализации,
1. не позволяет создавать динамически генерируемые site-to-site тоннели.
2. не является многопоточным, что на процессорах маршрутизаторов с 1-2 аплинковыми тоннелями приводит к перегрузке 1-2 ядер (из 8-16 в нашем случае) шифрованием и приводит к веселым последствиям для трафика внутри тоннеля.
3. П.2 особенно характерен для маршрутизаторов, в процессорах которых отсутствовала поддержка AES-NI.
Можно было использовать gre+ipsec, что сняло бы проблемы с производительностью — но остались бы тоннели, сотни их.
Было очень грустно, хотелось обложиться теплыми цисками с аппаратным шифрованием и употребить dmvpn.
Или уже глобальный MPLS VPN.
Чтобы не мелочиться.
Надо было что-то делать (с)
— в филиалы стали 1-2х процессорные сервера с вкусным количеством мозга и esxi на борту
— маршрутизаторы были разуплотнены и все сторонние сервисы переехали на выделенные виртуальные машины с pure linux
— после некоторых поисков в качестве платформы маршрутизации была выбрана виртулизированная x86 routeros.
Опыт эксплуатации микротика к тому времени уже был, проблем с производительностью и стабильности на наших задачах под x86 не было.
На железных решениях, особенно — на RB7** и RB2011**- было и есть веселее
Потенциально, такое решение давало прирост функционала в области
— route redistribution
— pbr + vrf
— mpls
— pim
— qos
а также некорторых других.
Проблема была в том, что routeros (как и vyatta) не поддерживает многоточечные vpn.
Опять стало грустно, начали копать в сторону чисто линуксовых fullmesh-решений.
Отдельное, кстати, спасибо хабраюзеру ValdikSS за его статью.
Были рассмотрены: peervpn,tinc, campagnol, GVPE, Neorouter, OpenNHRP, Cloudvpn, N2N
В итоге остановились на tincvpn, как на компромиссном решении.
Еще очень понравился gvpe экзотическими методами инкапсуляции, но он не позволял указать несколько IP (от разных ISP) для remote peer.
Что обидно, tinc был тоже однопоточным.
В качестве решения был использован грязный хак:
1. между каждыми двумя членами mesh поднимается не по 1, а по N тоннелей, объединяемых потом в bond-интерфейс с балансировкой исходящего трафика.
2. в результате, получаем уже N процессов, которые уже можно распределить между разными ядрами.
При использовании указанной схемы, в лабе с
— 8 tinc-интерфейсами, агреггироваными в один bond по указанной схеме
— принудительной привязкой процессов к разным ядрам
— 1 x xeon 54**, 55** (процессоры старого поколения без поддержки aes-ni)
— aes128/sha1,
— udp в качестве транспортного протокола.
— без использования qos как изнутри так и снаружи тоннеля.
Производительность vpn составляла около 550-600 mbps на гигабитном канале.
Мы были спасены.
Что получилось:
1. Итоговое решение получило рабочее название «vpn-пара».
2. Состоит из двух виртуальных машин, расположенных на одном esxi-хосте и объединенных виртуальным интерфейсом.
1 — routeros, который занимается исключительно вопросами маршрутизации
2 — pure linux с вылизаным и слегка допилиенным tinc.
Выполняет роль vpn-моста.
Конфигурация tinc — аналогично лабораторной, при этом bond-интерфейс сбриджен с виртуальным линком на микротик.
В результате, у всех маршрутизаторов общий L2, можно поднимать ospf и наслаждаться.
3. В каждом филиале по 2 vpn-пары.
Примечания
1. В принципе, интегрировать tinc можно и в vyatta, по этому поводу даже был написан патч (для варианта с 1 интерфейсом)
Но прогнозировать поведение такой связки в аварийной ситуации (или после обновления платформы) с кастомным патчем до конца сложно и для большой сети такие эксперименты нежелательны.
2. Рассматривался также вариант «матрешка».
Он имел 2 направления:
— покупка аппаратного x86 микротика и поддержка linux-vm с vpn-мостом средствами встроенной виртуализации (KVM).
не взлетело из-за низкой производительности.
MPLS L3VPN поверх DMVPN
DMVPN является известным решением для построения топологий hub&spoke. В ряде случаев может понадобиться поддержка изолированной передачи трафика различных клиентов. Конечно, можно построить DMVPN туннель в каждом VRF; однако в реальной жизни такой подход не является достаточно масштабируемым. В такой ситуации на ум приходит MPLS, который зарекомендовал себя в корпоративных и провайдерских сетях.
GRE поддерживает инкапсуляцию различных PDU, в том числе и MPLS, поэтому, на первый взгляд, не должно возникнуть проблем на уровне передачи трафика. С управляющими протоколами, однако, ситуация обстоит несколько сложнее. LDP и RSVP должны установить соседство перед тем, как обменяться какими-либо данными. Масштабируемость этих протоколов обусловлена использованием мультикаста для обнаружения соседей и обмена с ними необходимыми параметрами протокола. Ручная настройка LDP/RSVP соседства в DMVPN сведёт на нет масштабируемость, поэтому такой сценарий статья не рассматривает. Использование же мультикаста ограничивает функциональность решения, поскольку spoke могут обмениваться такими сообщениями только с hub, что исключает наличие spoke-to-spoke связности с использованием MPLS.

Впрочем, существует третье решение, которое является достаточно масштабируемым, а также способно обеспечить MPLS-связность spoke-узлов между собой – это BGP labeled unicast (BGP LU). Существует несколько способов превратить spoke-маршрутизатор в PE (например, первый вариант – отправить пакет с VPN меткой напрямую другому spoke, аналог второй фазы DMVPN; второй вариант – hub принимает непосредственное участие в передаче пакета внутри VRF, выполняя перенаправление пакета, как в третьей фазе DMVPN); однако в определённых случаях может возникнуть необходимость разместить PE за spoke.
Как обычно, соберём лабу и итеративно построим рабочее решение. Ниже приведена используемая топология в рамках рассмотрения 2547oDMVPN:
Схема стенда
R1, R5, R7 (and R6 later) – MPLS PE;
R3 – провайдер для DMVPN;
R4, R6 – DMVPN spokes.
R1-R2, R4-R5, R6-R7 – OSPF на площадке организации;
R3 – OSPF провайдера, обеспечивающий связность между маршрутизаторами DMVPN;
R1, R5, R7 (R6) – MP-BGP VPNv4 AF;
R2, R4, R6 – MP-BGP IPv4 AF;
Loopback0 отвечает за идентификацию маршрутизатора в сети, например, за назначение OSPF RID. Loopback1 является интерфейсом, с которого маршрутизаторы устанавливают BGP LU сессии; причины такой настройки рассмотрены далее в статье. Loopback2 эмулирует клиентские сети внутри VRF.
Начнём с базовой конфигурации PE:
Следующий шаг – подключить DMVPN маршрутизаторы к локальным сегментам сети:
Наконец последний этап подготовки к рассмотрению BGP LU – настройка DMVPN. В статье использован подход front-door VRF, чтобы уменьшить объём посторонней информации в глобальной таблице маршрутизации:
Время заняться делом. Необходимым условием для L3VPN является наличие рабочего LSP между PE. Поскольку ни LDP, ни RSVP в рамках DMVPN для этой задачи не подходят, используем MP-BGP для передачи следующей информации:
соответствующие им MPLS метки.
Звучит довольно просто. Что насчёт поддержки MPLS на интерфейсах?
На Tunnel0 MPLS пока не работает. Нам нужно разрешить только поддержку MPLS пакетов, не включая LDP, поэтому команда “mpls ip” не подходит. Впрочем, существует ещё одна менее известная команда, отвечающая нашей задаче:
После выполнения этой команды на всех spoke можно приступать к настройке BGP. В этой статье мы используем iBGP между hub и spoke; hub выполняет роль route-reflector и принимает входящие BGP-соединения:
Проверим, есть ли IP-связность между PE:
Достаточно ли этого для связности внутри VRF?
К сожалению, решение несколько сложнее, чем могло бы показаться на первый взгляд. Причина отсутствия связности – нерабочий LSP между PE:
Если быть точным, место отказа – R4:
Впрочем, является ли R4 местом возникновения проблемы? Разве R2 не должен был послать R4 префикс вместе с меткой?
Важное наблюдение: 1.1.1.1/32 не имеет сопутствующей MPLS метки, однако 2.2.2.2/32 ведёт себя так, как и было задумано. Также стоит обратить внимание на next-hop для 1.1.1.1/32 – это адрес R1, а не R2. R2 импортировал маршрут в BGP, сохранив оригинальный next-hop из таблицы маршрутизации. Поскольку сессия между R2 и R4 – iBGP, значение next-hop для 1.1.1.1/32 не меняется. Для 2.2.2.2/32 значение next-hop – адрес R2. Это тонкое отличие, однако, является ключевым: BGP назначает префиксу MPLS метку только в том случае, когда BGP маршрутизатор является next-hop’ом для этого префикса, т.е. входит в LSP.
В нашем случае нужно назначать метку только префиксам, импортированным локально, и не менять информацию от spoke:
Эта команда – довольно хитрая. По умолчанию она заставляет R2 изменять next-hop для маршрутов, которые импортированы локально или получены через eBGP; если нужно изменить next-hop для всех префиксов, включая те, которые получены по iBGP, нужно добавить ключевое слово “all”. Появилась ли связность?
Мы добились работы L3VPN поверх DMVPN. Впрочем, внимательный читатель, который повторял описанные шаги в собственной лабе, мог заметить следующее предупреждение, возникающее при настройке BGP LU:
Несмотря на то, что сообщение намекает на потенциальные проблемы, в нашей топологии они остались незамеченными. Рассмотрим следующую схему:
В рамках этого примера R1 устанавливает BGP сессию со своего интерфейса f0/0 до loopback интерфейса на R3, повторяя схему DMVPN. Control plane в данном случае будет работать без ошибок, тогда как связность на data plane – LSP – будет нарушена. Причина – PHP, penultimate hop popping. Интерфейс f0/0 лежит в directly connected сети для R2, который анонсирует её с меткой implicit-null. Рассмотрим, что происходит с пакетом, который R3 отправит на R1:
R3 добавляет VPN метку (например, 16) к пакету;
R3 добавляет транспортную метку (implicit-null) к полученному MPLS кадру;
R3 отправляет полученный кадр в сторону R2, при этом VPN метка находится на вершине стека.
Далее возможны два исхода: R2 не знает, что делать с кадром (VPN метка отсутствует в LFIB), и отбрасывает его, или же R2 шлёт кадр в неверном направлении (случайное совпадение VPN метки в кадре и транспортной метки в LFIB). В любом случае шансы R1 на получение кадра ничтожно малы. Стоит отметить, что использование explicit-null не решит проблему, поскольку для передачи кадра всё так же будет использована нижележащая VPN метка.
Впрочем, какое это имеет отношение к нашей изначальной топологии? Описанная проблема относится к некорректно настроенным PE-маршрутизаторам. Однако эта проблема становится актуальной и в нашей топологии, если spoke превратить в PE, поскольку BGP использует Tunnel0 для установления сессии. Можно попробовать перенастроить BGP на использование loopback, хотя это ни к чему хорошему не приведёт: LSP будет разорван, т.к. некому анонсировать метки для самих loopback – обычно это задача LSP/RSVP. Впрочем, решение довольно простое: можно использовать loopback только для VPNv4 AF сессий и анонсировать соответствующие метки с помощью BGP LU:
Теперь R6 участвует в L3VPN, и можно проверить наличие связности внутри VRF:
Наконец-то L3VPN поверх DMVPN работает так, как мы ожидали. Мне кажется, сложности описанной конструкции заключаются в следующем:
обладание тайным знанием о существовании BGP LU;
назначение MPLS метки только в том случае, если маршрутизатор является next-hop’ом для префикса;
понимание, в каких случаях PHP способен сломать LSP.
В этой статье мы обсудили настройку MPLS L3VPN поверх DMVPN (2547oDMVPN) с использованием iBGP LU для распространения MPLS меток в рамках опорной сети. Отличие от документированных способов – это возможность разместить PE-маршрутизатор за hub/spokes без нарушения spoke-to-spoke связности поверх DMVPN. Что касается настройки с помощью eBGP, я бы хотел оставить её как домашнее задание для любознательных читателей.
Спасибо за рецензию: Анастасии Куралевой, Максиму Климанову
Звездообразная топология сети
HUB и лучевой — это модель сети для эффективного управления общими требованиями к взаимодействию или безопасности. Она также позволяет избежать ограничений подписки Azure. В этой модели уделяется особое внимание следующим вопросам.
Экономия затрат и эффективное управление: Централизация служб, которые могут совместно использоваться несколькими рабочими нагрузками, такими как сетевые виртуальные устройства (NVA) и DNS-серверы. С одним расположением для служб это может максимально сэкономить избыточные ресурсы и усилия по управлению.
Ограничения лимита подписки: При работе с большими облачными рабочими нагрузками может потребоваться больше ресурсов, чем в одной подписке Azure. Пиринг рабочей нагрузки виртуальных сетей из различных подписок в центральный концентратор может преодолеть эти ограничения. Дополнительные сведения см. в статье ограничения подписки Azure.
Разделение проблем: Вы можете развертывать отдельные рабочие нагрузки между центральными группами ИТ и группами рабочей нагрузки.
Небольшие облачные инфраструктуры могут не воспользоваться преимуществами дополнительной структуры и возможностями, которые предлагает эта модель. Но в сценарии больших внедрений облачных технологий следует рассмотреть возможность применения сетевой звездообразной архитектуры, если у команд есть какие-либо вопросы, перечисленные ранее.
На сайте эталонные архитектуры Azure содержатся примеры шаблонов, которые можно использовать в качестве базиса для реализации собственных сетей hub-and-лучевой сети.
Общие сведения
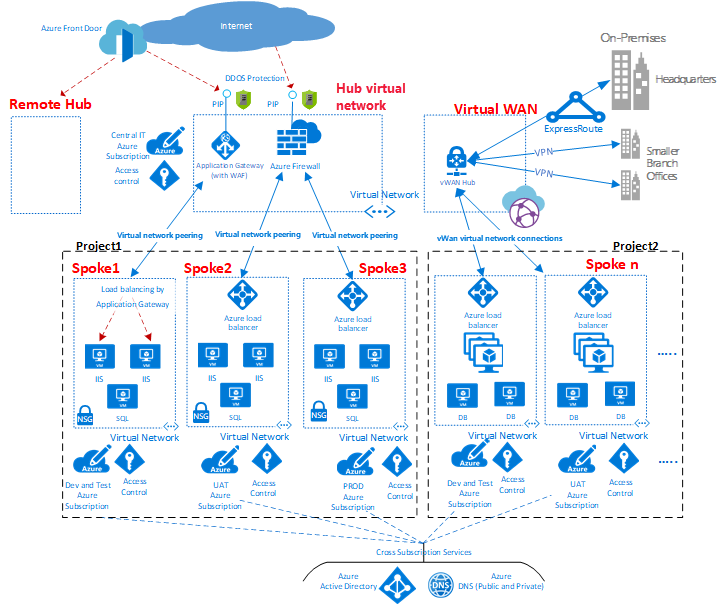
Рис. 1. Пример топологии сети типа «звезда».
Как показано на диаграмме, среда Azure поддерживает два типа звездообразного проектирования. Первый тип поддерживает связь, общие ресурсы и централизованную политику безопасности. Этот тип помечен как концентратор виртуальной сети на схеме. Второй тип основан на виртуальной глобальной сети Azure, которая помечена как Виртуальная глобальная сеть в схеме. Этот тип предназначен для крупномасштабного обмена данными между ветвями и ветвями и Azure.
Центральная зона (концентратор) контролирует и проверяет входящий и исходящий трафик между зонами, включая Интернет, а также локальные периферийные зоны. Звездообразная топология позволяет ИТ-отделу применять политики безопасности в центральном расположении, одновременно минимизируя уязвимости и ошибки в конфигурации.
В концентраторе часто содержатся общие компоненты службы, используемые периферийными зонами. Примеры распространенных основных служб:
Вы можете минимизировать избыточность, упростить управление и снизить общую стоимость, используя общую инфраструктуру концентратора для поддержки нескольких периферийных зон.
Роль каждой периферийной зоны может заключаться в размещении различных типов рабочих нагрузок. Использование периферийных зон также позволяют реализовать модульный подход для повторяемых развертываний одних и тех же рабочих нагрузок Примеры: Разработка и тестирование, приемочное тестирование пользователя, промежуточное хранение и Рабочая среда.
Также эти зоны можно использовать для разделения и включения различных групп в пределах организации, например, групп DevOps в Azure. В пределах периферийной зоны можно развернуть базовую рабочую нагрузку или сложные многоуровневые рабочие нагрузки с управлением трафиком между уровнями.
Шлюз приложений, показанный на приведенной выше схеме, может жить в своей работе с приложением, которое оно обслуживает для улучшения управления и масштабирования. Однако корпоративная политика может зависеть от размещения шлюза приложений в центре для централизованного управления и разделения полномочий.
Ограничения подписки и несколько центральных зон
В Azure каждый тип компонента развертывается в подписке Azure. Изоляция компонентов Azure в разных подписках Azure позволяет выполнять требования различных бизнес-приложений, например настройку дифференцированных уровней доступа и авторизации.
Единая реализация hub-and-лучевой может масштабироваться до большого количества периферийных серверов, но, как и в случае с каждой ИТ-системой, существуют ограничения платформы. Развертывание концентратора привязано к определенной подписке Azure, которая имеет ограничения, Одним из примеров может быть максимальное число пиринга виртуальных сетей. Дополнительные сведения см. в статье Подписка Azure и ограничения службы.
Если ограничения могут быть проблемой, можно увеличить масштаб архитектуры, расширив модель до кластера узлов и периферийных серверов. Вы можете подключить несколько концентраторов в одном или нескольких регионах Azure с помощью:
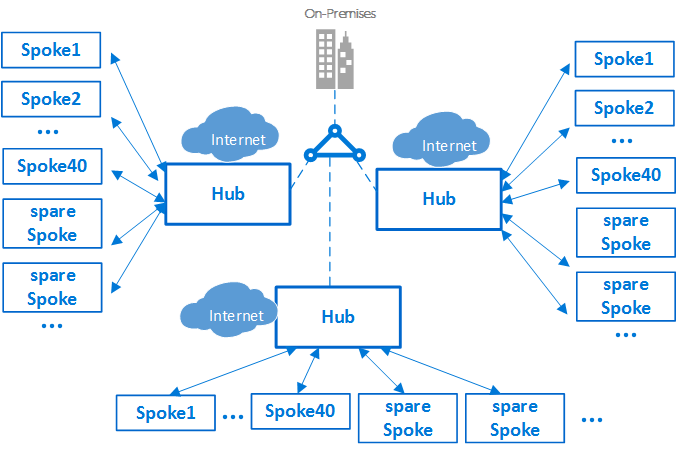
Рис. 2. кластер концентраторов и периферийных серверов.
Включение нескольких концентраторов приводит к увеличению затрат и накладных расходов на управление. Это увеличение выравнивается только по следующим параметрам:
В сценариях, требующих использования нескольких концентраторов, все концентраторы должны предоставлять один и тот же набор служб для простоты в работе.
Взаимодействие между периферийными зонами
В пределах отдельной периферийной зоны можно реализовать сложные многоуровневые рабочие нагрузки. Вы можете реализовать многоуровневые конфигурации, используя подсети (по одной для каждого уровня) в одной виртуальной сети, а также используя группы безопасности сети для фильтрации потоков.
Архитектор может развертывать многоуровневые рабочие нагрузки в нескольких виртуальных сетях. Используя пиринг между виртуальными сетями, периферийные зоны могут подключаться к другим периферийным зонам в пределах одного или нескольких концентраторов.
Типичным примером такого сценария является случай, когда серверы обработки приложения располагаются в одной периферийной зоне или виртуальной сети, а база данных развернута в другой периферийной зоне или виртуальной сети. В этом случае периферийные зоны могут легко обмениваться данными через пиринговые виртуальные сети, не используя при этом концентратор. Выполните тщательную проверку архитектуры и безопасности, чтобы обойти центр не обойти важные точки безопасности или аудита, которые находятся только в концентраторе.
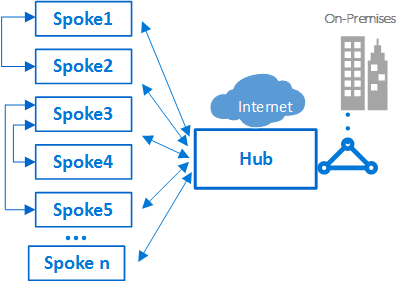
Рис. 3. пример периферийных серверов, соединяющихся друг с другом и концентратором.
Периферийные зоны могут также взаимодействовать с периферийной зоной, выполняющей функции концентратора. При таком подходе создается иерархия из двух уровней: спица на более высоком уровне, уровень 0, превращается в концентратор младших периферийных единиц или уровень 1 иерархии. Периферийные серверы должны пересылать трафик в Центральный концентратор. Это требование заключается в том, что трафик может переноситься в место назначения в локальной сети или в общедоступном Интернете. Такая архитектура концентратора представляет сложную маршрутизацию, что сводит на нет преимущества отдельной звездообразной связи.
Дальнейшие действия
Теперь, когда вы изучили рекомендации по работе с сетью, Узнайте, как подходить к управлению удостоверениями и доступом.



