Твоя Data такая большая: Введение в Spark на Java
Apache Spark – универсальный инструмент для процессинга больших данных, с которым можно писать в Hadoop с различных СУБД, стримить всякие источники в реальном времени, параллельно делать с данными какую-нибудь сложную обработку, и все это не при помощи каких-то батчей, скриптов и SQL-запросов, а при помощи функционального подхода.

Про Spark ходит несколько мифов:
Миф 1. Spark не работает без Hadoop
Что такое Hadoop? Грубо говоря, это распределенная файловая система, хранилище данных с набором API для процессинга этих самых данных. И, как ни странно, будет правильнее сказать что Hadoop нуждается в Spark, а не наоборот!
Дело в том, что стандартный инструментарий Hadoop’а не позволяет процессить имеющиеся данные с высокой скоростью, а Spark – позволяет. И вот вопрос, нужен ли Spark’у Hadoop? Давайте посмотрим на то, что такое Spark:
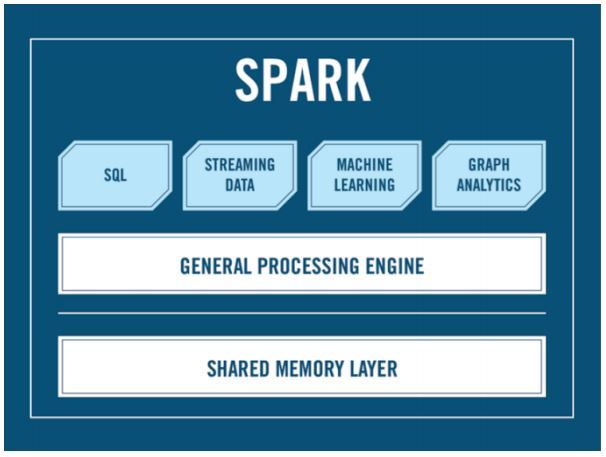
Как видите, здесь нет Hadoop’a: есть API, есть SQL, есть стриминг и многое другое. А Hadoop не обязателен. А Cluster manager, спросите вы? Кто будет запускать ваш Spark на кластер? Александр Сергеевич? Вот именно из этого вопроса и растут ноги у нашего мифа: чаще всего для распределения job’ов Спарка по кластеру используется YARN под Hadoop, однако есть и альтернативы: Apache Mesos, например, который вы можете использовать, если по какой-то причине не любите Hadoop.
Миф 2. Spark написан на Scala, значит под него тоже надо писать на Scala
Со Spark можно работать и под Java, и под Scala, при этом второй вариант многими считается лучшим по нескольким причинам:

Синтаксис отдельная история – если почитать любой холивар Java vs. Scala, вы встретите примерно вот такие примеры (как вы видите, код просто суммирует длины строк):
Год назад даже в документации Spark примеры выглядели именно так. Однако давайте посмотрим на код на Java 8:
Выглядит вполне неплохо, не так ли? В любом случае, нужно понимать еще и то, что Java это знакомый нам мир: Spring, дизайн паттерны, концепции и многое другое. На Scala джависту придется столкнуться с совершенно иным миром и здесь стоит задуматься, готовы ли вы или ваш заказчик на такой риск.
Все примеры взяты из доклада Евгения EvgenyBorisov Борисова о Spark, который прозвучал на JPoint 2016, став, кстати лучшим докладом конференции. Хотите продолжения: RDD, тестирования, примеров и live-кодинга? Смотрите видео:
Больше Spark богам BigData
А если после просмотра доклада Евгения вы пережили экзистенциальный катарсис, осознав, что со Spark’ом надо познакомиться плотнее, можно сделать это вживую вместе с Евгением уже через месяц:
12-13 октября в Санкт-Петербурге состоится большой двухдневный тренинг «Welcome to Spark».
Обсудим проблемы и решения, с которыми поначалу сталкиваются неопытные Spark-разработчики. Разберемся с синтаксисом и всякими хитростями, а главное посмотрим, как можно писать Spark на Java при помощи известных вам фрэймворков, инструментов и концепций, таких как Inversion of Control, design patterns, Spring framework, Maven/Gradle, Junit. Все они могут помочь сделать ваше Spark-приложение более элегантным, читабельным и привычным.
Будет много заданий, live coding-а и в конечном итоге вы выйдете с этого тренинга с достаточными знаниями, чтобы начать самостоятельно работать на Spark-e в привычном мире Java.
Подробную программу выкладывать сюда большого смысла нет, кто захочет, найдет на странице тренинга.
ЕВГЕНИЙ БОРИСОВ
Naya Technologies 
Евгений Борисов разрабатывает на Java с 2001 года и принял участие в большом количестве Enterprise-проектов. Пройдя путь от простого программиста до архитектора и устав от рутины, он вышел в свободные художники. Сегодня пишет и проводит курсы, семинары и мастер классы для различной аудитории: live-курсы по J2EE для офицеров израильской армии. Spring — по WebEx’у для румын, Hibernate через GoToMeeting для канадцев, Troubleshooting и Design Patterns для украинцев.
Apache Spark: гайд для новичков

Mar 13, 2020 · 8 min read

Что такое Apache Spark?
Специалисты компании Databricks, основанной создателями Spark, собрали лучшее о функционале Apache Spark в своей книге Gentle Intro to Apache Spark ( очень рекомендую прочитать):
“Apache Spark — это целостная вычислительная система с набором библиотек для п араллельной обработки данных на кластерах компьютеров. На данный момент Spark считается самым активно разрабатываемым средством с открытым кодом для решения подобных задач, что позволяет ему быть полезным инструментом для любого разработчика или исследователя-специалиста, заинтересованного в больших данных. Spark поддерживает множество широко используемых языков программирования (Python, Java, Scala и R), а также библиотеки для различных задач, начиная от SQL и заканчивая стримингом и машинным обучением, а запустить его можно как с ноутбука, так и с кластера, состоящего из тысячи серверов. Благодаря этому Apache Spark и является удобной системой для начала самостоятельной работы, перетекающей в обработку больших данных в невероятно огромных масштабах.”
Что такое большие данные?
Посмотрим-ка на популярное определение больших данных по Гартнеру. Это поможет разобраться в том, как Spark способен решить множество интересных задач, которые связаны с работой с большими данными в реальном времени:
“Большие данные — это информационные активы, которые характеризуются большим объёмом, высокой скоростью и/или многообразием, а также требуют экономически эффективных инновационных форм обработки информации, что приводит к усиленному пониманию, улучшению принятия решений и автоматизации процессов.”

Заметка: Ключевой вывод — слово “большие” в больших данных относится не только к объёму. Вы не просто получаете много данных, они поступают в реальном времени очень быстро и в различных комплексных форматах, а ещё — из большого многообразия источников. Вот откуда появились 3-V больших данных: Volume (Объём), Velocity (Скорость), Variety (Многообразие).
Причины использовать Spark
Основываясь на самостоятельном предварительном исследовании этого вопроса, я пришёл к выводу, что у Apache Spark есть три главных компонента, которые делают его лидером в эффективной работе с большими данными, а это мотивирует многие крупные компании работать с большими наборами неструктурированных данных, чтобы Apache Spark входил в их технологический стек.
Apache Spark или Hadoop MapReduce…Что вам подходит больше?
Если отвечать коротко, то выбор зависит от конкретных потребностей вашего бизнеса, естественно. Подытоживая свои исследования, скажу, что Spark выбирают в 7-ми из 10-ти случаев. Линейная обработка огромных датасетов — преимущество Hadoop MapReduce. Ну а Spark знаменит своей быстрой производительностью, итеративной обработкой, аналитикой в режиме реального времени, обработкой графов, машинным обучением и это ещё не всё.
Хорошие новости в том, что Spark полностью совместим с экосистемой Hadoop и работает замечательно с Hadoop Distributed File System (HDFS — Распределённая файловая система Hadoop), а также с Apache Hive и другими похожими системами. Так что, когда объёмы данных слишком огромные для того, чтобы Spark мог удержать их в памяти, Hadoop может помочь преодолеть это затруднение при помощи возможностей его файловой системы. Привожу ниже пример того, как эти две системы могут работать вместе:

Это изображение наглядно показывает, как Spark использует в работе лучшее от Hadoop: HDFS для чтения и хранения данных, MapReduce — для дополнительной обработки и YARN — для распределения ресурсов.
Дальше я пробую сосредоточиться на множестве преимуществ Spark перед Hadoop MapReduce. Для этого я сделаю краткое поверхностное сравнение.

Скорость
Просто пользоваться
Обработка больших наборов данных
Функциональность
Apache Spark — неизменный победитель в этой категории. Ниже я даю список основных задач по анализу больших данных, в которых Spark опережает Hadoop по производительности:
Машинное обучение. В Spark есть MLlib — встроенная библиотека машинного обучения, а вот Hadoop нужна третья сторона для такого же функционала. MLlib имеет алгоритмы “out-of-the-box” (возможность подключения устройства сразу после того, как его достали из коробки, без необходимости устанавливать дополнительное ПО, драйверы и т.д.), которые также реализуются в памяти.
А вот и визуальный итог множества возможностей Spark и его совместимости с другими инструментами обработки больших данных и языками программирования:

Заключение
Вместе со всем этим массовым распространением больших данных и экспоненциально растущей скоростью вычислительных мощностей инструменты вроде Apache Spark и других программ, анализирующих большие данные, скоро будут незаменимы в работе исследователей данных и быстро станут стандартом в индустрии реализации аналитики больших данных и решении сложных бизнес-задач в реальном времени.
Для тех, кому интересно погрузиться глубоко в технологию, которая стоит за всеми этими внешними функциями, почитайте книгу Databricks — “ A Gentle Intro to Apache Spark” или “ Big Data Analytics on Apache Spark”.
Spark
Описание термина: Apache Spark или просто Spark — это фреймворк (ПО, объединяющее готовые компоненты большого программного проекта), который используют для параллельной обработки неструктурированных или слабоструктурированных данных.
Например, если нужно обработать данные о годовых продажах одного магазина, то программисту хватит одного компьютера и кода на Python, чтобы произвести расчет. Но если обрабатываются данные от тысяч магазинов из нескольких стран, причем они поступают в реальном времени, содержат пропуски, повторы, ошибки, тогда стоит использовать мощности нескольких компьютеров и Spark. Группа компьютеров, одновременно обрабатывающая данные, называется кластером, поэтому Spark также называют фреймворком для кластерных вычислений.
Зачем нужен Spark
Области использования Spark — это Big Data и технологии машинного обучения, поэтому им пользуются специалисты, работающие с данными, например дата-инженеры, дата-сайентисты и аналитики данных.
Примеры задач, которые можно решить с помощью Spark:
Spark поддерживает языки программирования Scala, Java, Python, R и SQL. Сначала популярными были только первые два, так как на Scala фреймворк был написан, а на Java позже была дописана часть кода. С ростом Python-сообщества этим языком тоже стали пользоваться активнее, правда обновления и новые фичи в первую очередь доступны для Scala-разработчиков. Реже всего для работы со Spark используют язык R.
Data Scientist с нуля
Всего за год вы получите перспективную профессию, пополните портфолио рекомендательной системой и нейросетями, примете участие в соревнованиях на Kaggle и в хакатонах.
В структуру Spark входят ядро для обработки данных и набор расширений:
Как работает Spark
Спарк интегрирован в Hadoop — экосистему инструментов с открытым доступом, в которую входят библиотеки, система управления кластером (Yet Another Resource Negotiator), технология хранения файлов на различных серверах (Hadoop Distributed File System) и система вычислений MapReduce. Классическую модель Hadoop MapReduce и Spark постоянно сравнивают, когда речь заходит об обработке больших данных.
Принципиальные отличия Spark и MapReduce
Пакетная обработка данных
Хранит данные на диске
В 100 раз быстрее, чем MapReduce
Обработка данных в реальном времени
Хранит данные в оперативной памяти
Пакетная обработка в MapReduce проходит на нескольких компьютерах (их также называют узлами) в два этапа: на первом головной узел обрабатывает данные и распределяет их между рабочими узлами, на втором рабочие узлы сворачивают данные и отправляют обратно в головной. Второй шаг пакетной обработки не начнется, пока не завершится первый.
Читайте также: Какой язык учить аналитику данных?
Обработка данных в реальном времени с помощью Spark Streaming — это переход на микропакетный принцип, когда данные постоянно обрабатываются небольшими группами.

Кроме этого, вычисления MapReduce производятся на диске, а Spark производит их в оперативной памяти, и за счет этого его производительность возрастает в 100 раз. Однако специалисты предупреждают, что заявленная «молниеносная скорость работы» Spark не всегда способна решить задачу. Если потребуется обработать больше 10 Тб данных, классический MapReduce доведет вычисление до конца, а вот у Spark может не хватить памяти для такого вычисления.
Но даже сбой в работе кластера не спровоцирует потерю данных. Основу Spark составляют устойчивые распределенные наборы данных (Resilient Distributed Dataset, RDD). Это значит, что каждый датасет хранится на нескольких узлах одновременно и это защищает весь массив.
Освойте самую перспективную профессию 2021 года. После обучения вы будете обладать навыками middle-специалиста и рассчитывать на среднюю зарплату по отрасли.
Разработчики говорят, что до выхода версии Spark 2.0 платформа работала нестабильно, постоянно падала, ей не хватало памяти, и проблемы решались многочисленными обновлениями. Но в 2021 году специалисты уже не сталкиваются с этим, а обновления в основном направлены на расширение функционала и поддержку новых языков.
✅ «Наша компания использует Spark для прогнозирования финансовых рисков»
❌ «Я учусь работать в программе Spark»
Apache Spark: что там под капотом?
Вступление
Небольшая предыстория:
Spark — проект лаборатории UC Berkeley, который зародился примерно в 2009г. Основатели Спарка — известные ученые из области баз данных, и по философии своей Spark в каком-то роде ответ на MapReduce. Сейчас Spark находится под «крышей» Apache, но идеологи и основные разработчики — те же люди.
Spoiler: Spark в 2-х словах
Spark можно описать одной фразой так — это внутренности движка массивно-параллельной СУБД. То есть Spark не продвигает свое хранилище, а живет сверх других (HDFS — распределенная файловая система Hadoop File System, HBase, JDBC, Cassandra,… ). Правда стоит сразу отметить проект IndexedRDD — key/value хранилище для Spark, которое наверное скоро будет интегрировано в проект.Также Spark не заботится о транзакциях, но в остальном это именно движок MPP DBMS.
RDD — основная концепция Spark
Ключ к пониманию Spark — это RDD: Resilient Distributed Dataset. По сути это надежная распределенная таблица (на самом деле RDD содержит произвольную коллекцию, но удобнее всего работать с кортежами, как в реляционной таблице). RDD может быть полностью виртуальной и просто знать, как она породилась, чтобы, например, в случае сбоя узла, восстановиться. А может быть и материализована — распределенно, в памяти или на диске (или в памяти с вытеснением на диск). Также, внутри, RDD разбита на партиции — это минимальный объем RDD, который будет обработан каждым рабочим узлом.
Ну и уже исходя из этого понимания следует Spark рассматривать как параллельную среду для сложных аналитических банч заданий, где есть мастер, который координирует задание, и куча рабочих узлов, которые участвуют в выполнении.
Давайте рассмотрим такое простое приложение в деталях (напишем его на Scala — вот и повод изучить этот модный язык):
Пример Spark приложения (не все включено, например include)
Мы отдельно разберем, что происходит на каждом шаге.
А что же там происходит?
Теперь пробежимся по этой программе и посмотрим что происходит.
Ну во-первых программа запускается на мастере кластера, и прежде чем пойдет какая-нибудь параллельная обработка данные есть возможность что-то поделать спокойно в одном потоке. Далее — как уже наверное заметно — каждая операция над RDD создает другой RDD (кроме saveAsTextFile). При этом RDD все создаются лениво, только когда мы просим или записать в файл, или например выгрузить в память на мастер — начинается выполнение. То есть выполнение происходит как в плане запроса, конвеером, где элемент конвеера — это партиция.
Что происходит с самой первой RDD, которую мы сделали из файла HDFS? Spark хорошо синтегрирован с Hadoop, поэтому на каждом рабочем узле будет закачиваться свое подмножество данных, и закачиваться будет по партициям (которые в случае HDFS совпадают с блоками). То есть все узлы закачали первый блок, и пошло выполнение дальше по плану.
После чтения с диска у нас map — он выполняется тривиально на каждом рабочем узле.
Дальше идет groupBy. Это уже не простая конвеерная операция, а настоящая распределенная группировка. По хорошему, лучше этот оператор избегать, так как пока он реализован не слишком умно — плохо отслеживает локальность данных и по производительности будет сравним с распределенной сортировкой. Ну это уже информация к размышлению.
Давайте задумаемся о состоянии дел в момент выполнения groupBy. Все RDD до этого были конвеерными, то есть они ничего нигде не сохраняли. В случае сбоя, они опять бы вытащили недостающие данные из HDFS и пропустили через конвеер. Но groupBy нарушает конвеерность и в результате мы получим закэшированный RDD. В случае потери теперь мы вынуждены будем переделать все RDD до groupBy полностью.
Чтобы избежать ситуации, когда из-за сбоев в сложном приложении для Spark приходится пересчитывать весь конвеер, Spark позволяет пользователю контролировать кэширование оператором persist. Он умеет кэшировать в память (в этом случае идет пересчет при потере данных в памяти — она может случится при переполнении кэша), на диск (не всегда достаточно быстро), или в память с выбросом на диск в случае переполнения кэша.
После, у нас опять map и запись в HDFS.
Ну вот, теперь более менее понятно что происходит внутри Spark на простом уровне.
А как же подробности?
Например хочется знать как именно работает операция groupBy. Или операция reduceByKey, и почему она намного эфективнее, чем groupBy. Или как работает join и leftOuterJoin. К сожалению большинство подробностей пока легче всего узнать только из исходников Spark или задав вопрос на их mailing list (кстати, рекомендую подписаться на него, если будете что-то серьезное или нестандартное делать на Spark).
Еще хуже с понимаем, что творится в различных коннекторах к Spark. И насколько ими вообще можно пользоваться. Например нам на время пришлось отказаться от идеи интегрироваться с Cassandra из-за их непонятной поддержки коннектора к Spark. Но надежда есть что документация качественная в скором будущем появится.
Анализ больших данных: Spark и Hadoop

По данным Forbes, каждый день генерируется около 2,5 квинтиллионов байтов данных. Тем не менее, согласно прогнозам, это число будет постоянно увеличиваться, стоит отметить, что 90% хранимых в настоящее время данных было получено в течение последних двух лет.
Рассмотрим введение в большие данные и различные методы, используемые для их обработки, такие как MapReduce, Apache Spark и Hadoop.
Что отличает большие данные от любого другого большого объема данных, хранящихся в реляционных базах данных, — это их неоднородность. Данные поступают из разных источников и записываются в разных форматах.
Обычно используются три различных способа форматирования данных:
Большие данные определяются тремя свойствами:
Большие данные могут быть проанализированы с использованием двух различных методов обработки:
Большие данные могут быть обработаны с использованием различных инструментов, таких как MapReduce, Spark, Hadoop, Pig, Hive, Cassandra и Kafka. Каждый из этих различных инструментов имеет свои преимущества и недостатки, которые определяют, как компании могут принять решение использовать их.

Анализ больших данных в настоящее время широко используется многими компаниями для прогнозирования рыночных тенденций, персонализации взаимодействия с клиентами, ускорения работы компаний и т. д.
MapReduce
При работе с большим объемом данных, когда у нас заканчиваются ресурсы, есть два возможных решения: горизонтальное или вертикальное масштабирование.
Вертикальное масштабирование проще в управлении и контроле, чем горизонтальное, и доказано, что оно эффективно при работе с проблемами сравнительно небольшого размера. Хотя горизонтальное масштабирование обычно дешевле и быстрее вертикального масштабирования при работе с большой проблемой.
MapReduce основан на горизонтальном масштабировании. В MapReduce кластер компьютеров используется для распараллеливания, что упрощает обработку больших данных.
В MapReduce мы берем входные данные и делим их на множество частей. Каждая часть затем отправляется на другой компьютер для обработки и наконец, агрегирования в соответствии с заданной функцией groupby.

Apache Spark
Платформа Apache Spark была разработана в качестве усовершенствования MapReduce. Что выделяет Spark среди конкурентов, так это скорость выполнения, которая примерно в 100 раз выше, чем у MapReduce (промежуточные результаты не сохраняются и все выполняется в памяти).
Apache Spark обычно используется для:

Apache Spark можно использовать с такими языками программирования, как Python, R и Scala. Для запуска Spark обычно используются облачные приложения, такие как Amazon Web Services, Microsoft Azure и Databricks (который предоставляет бесплатную версию сообщества).
При использовании Spark наши большие данные распараллеливаются с использованием эластичных распределенных наборов данных (RDDs ). RDDs являются основной абстракцией Apache Spark, которая берет наши исходные данные и распределяет их по различным кластерам (работникам ). RRD являются отказоустойчивыми, что означает, что они могут восстановить потерянные данные в случае сбоя любого из узлов.
RDDs можно использовать для выполнения двух типов операций в Spark: преобразования и действия

Hadoop
Hadoop — это набор программ с открытым исходным кодом, написанных на Java, которые можно использовать для выполнения операций с большим объемом данных. Hadoop — это масштабируемая, распределенная и отказоустойчивая экосистема. Основными компонентами Hadoop являются:

Традиционно Hadoop была первой системой, которая сделала MapReduce доступной в большом масштабе, хотя Apache Spark в настоящее время является основой предпочтений многих компаний благодаря более высокой скорости выполнения.
Заключение
Термин «большие данные» изначально был придуман для описания проблемы: генерируя большие данные, чем их можем реально обработать. После многих лет исследований и технологических достижений большие данные вместо этого теперь рассматриваются как возможность. Благодаря Big Data последние достижения в области искусственного интеллекта и глубокого обучения стали возможными, что позволило машинам выполнять задачи, которые казались невозможными всего несколько лет назад.



