Настройка HADOOP для новичков

Вот уже год занимаюсь исследованием экосистемы (не побоюсь этого слова) HADOOP. Когда накопились определенные знания, решил поделиться ими с миром, так как информации в русском сегменте Интернет не так уж и много.
Операционная система заслуживает отдельного внимания. В нашем примере мы будем разворачивать кластер на виртуальных машинах с ОС Ubuntu 18.04 LTS. Почему так сложно? Да потому что для тех, кто не знаком с Linux, данная ОС будет наиболее приятна на начальном этапе и она встроена в менеджер виртуальных машин Windows 10. В реальных условиях из того, что я видел, большинство кластеров развернуты на CentOS без визуальной оболочки. Так же процесс установки HADOOP был успешно протестирован на Ubuntu 14.04 LTS и 16.04 Server. Навыки работы с командной строкой у вас тоже должны быть, если нет, постараюсь объяснить все доходчиво.
Внимание. Я не хочу никого учить работе в Linux. Сам новичок, если есть что добавить, регистрируйтесь и пишите в комментариях или в группу Вконтакте.
Итак, у вас есть домашний ПК с как минимум 4Гб оперативки, в нашем примере установлена Windows 10. Если у вас другая ОС, тогда необходимо установить менеджер виртуальных машин, например VMWareWorkstation или VirtualBox. Раньше я пользовался именно этими виртуалками, но Windows 10 меня порадовала наличием встроенного менеджера виртуальных машин Hyper-V.
Включение Hyper-V через раздел «Параметры»
1. Щелкните правой кнопкой мыши кнопку Windows и выберите пункт «Приложения и возможности».
2. Выберите программы и компоненты справа в разделе сопутствующие параметры.
3. Выберите пункт Включение или отключение компонентов Windows.
4. Выберите Hyper-V и нажмите кнопку ОК.

Теперь Hyper-V готово к работе. Для его запуска необходимо кликнуть по иконке поиска и набрать «Hyper», после чего появится приложение, смотри рисунок ниже.
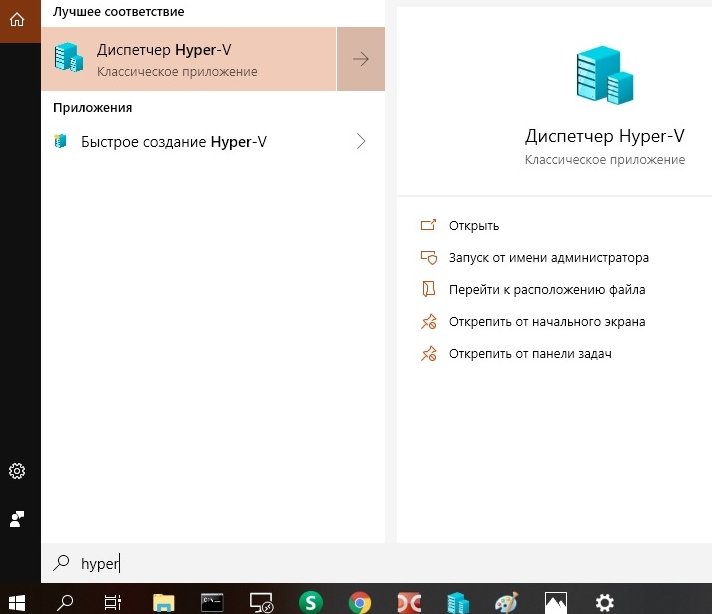
Запускаем диспетчер виртуальных машин Hyper-V, после чего видим главное окно, где в правой части можно увидеть вкладку «Быстро создать». Кликаем по ней, появляется окно выбора операционной системы, выбираем Ubuntu 18, как на рисунке ниже. В ходе установки и настройки системы особо обратить внимание на имя пользователя и пароль.

Это самый простой способ создания виртуальной машины, требующий минимума действий пользователя, в дальнейшем научимся клонировать виртуалки.
Однако данный способ создания виртуальных машин оказался не очень практичен. Настроек по умолчанию не хватает для главной машины кластера, а изменить параметры железа оказалось не такой уж и простой задачей.Так попытка увеличить объем жесткого диска привела к потере виртуалки. После этого я решил создавать виртуалки обычным способом: настройка параметров железа с дальнейшей установкой ОС из образа. Образ Ubuntu 18.04 можно найти ЗДЕСЬ.
Теперь все готово для настройки операционной системы Ubuntu.
P.S. Вот и прошло 2 года успешного использования виртуалок под Hyper-V. Все шло как по маслу, но в один прекрасный момент все виртуалки перестали загружаться. Смотрим скриншот ниже.

1. Загрузка из контрольной точки.
2. sudo apt install lightdm
Ставим, со всем соглашаемся, выбираем lightdm, ждем окончания установки.
3. sudo dpkg-reconfigure lightdm
На всякий случай, если что пошло не так.
Настройка операционной системы Ubuntu 18
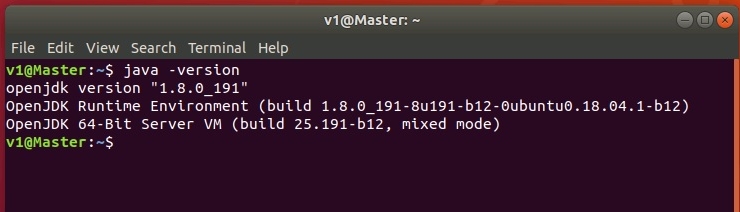
Для начала нужно установить Java, так как HADOOP является фреймворком, написанном на Яве. Поддерживаются версии Java от 5-й и выше, но как показала практика, наиболее стабильно HADOOP работает с 8-й и 9-й версией.Я предпочел установить версию 8, так как с последней 11-й было много глюков.
Для установки Java (jdk и jre) в терминале выполнить следующие команды:
sudo apt install openjdk-8-jdk-headless
sudo apt install openjdk-8-jre-headless
Создание пользователя системы для работы с HADOOP
Тут все очень просто, выполним следующие команды:
sudo addgroup hadoop
Создан пользователь hduser в группе hadoop. При создании пользователя важно запомнить пароль, остальные настройки не важны.
Для входа в систему под новым пользователем необходимо ввести команду sudo su hduser, для входа нужно ввести пароль для текущей учетной записи:

Теперь пользователю hduser необходимо добавить права для выполнения команд типа от рута (sudo).
Для этого необходимо сменить текущего пользователя hduser на созданного при установке системы v1 c помощью команды: su v1 и ввести пароль этого пользователя.
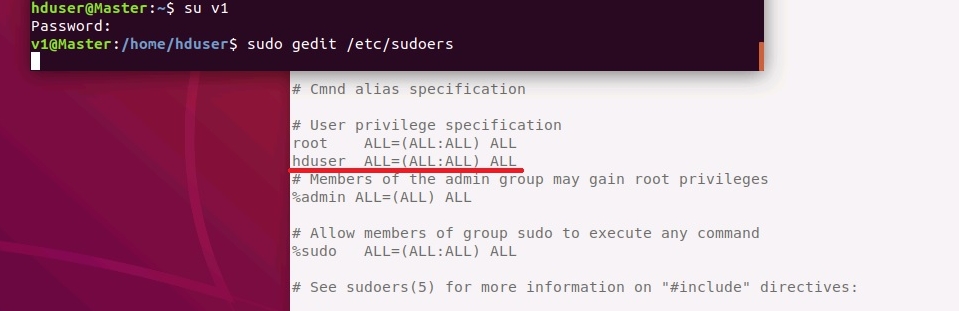
После этого необходимо добавить пользователя hduser в файл /etc/sudoers для чего открыть данный файл в редакторе c помощью команды:
sudo gedit hadoop /etc/sudoers
В текстовом редакторе сразу после пользователя root добавить созданного пользователя hduser, как показано на рисунке ниже.
Далее необходимо установить и настроить SSH. Установка SSH-сервера:
sudo apt-get install openssh-server
Далее зайти под пользователем hduser и сгенерировать SSH-ключи.
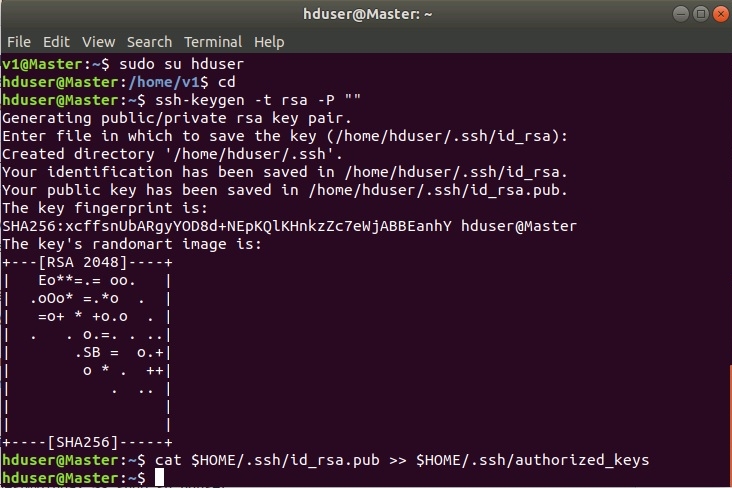
Установка и настройка HADOOP.
Качаем архив HADOOP ОТСЮДА, я выбрал версию 2.9.1.
Загрузить архив можно либо через команду wget в консоли, но у нас есть интерфейс и браузер. Поэтому упрощаем себе жизнь и качаем в браузере. Архив загружается в в каталог Downloads текущего пользователя системы. Тут же можно и разархивировать скачанный файл.
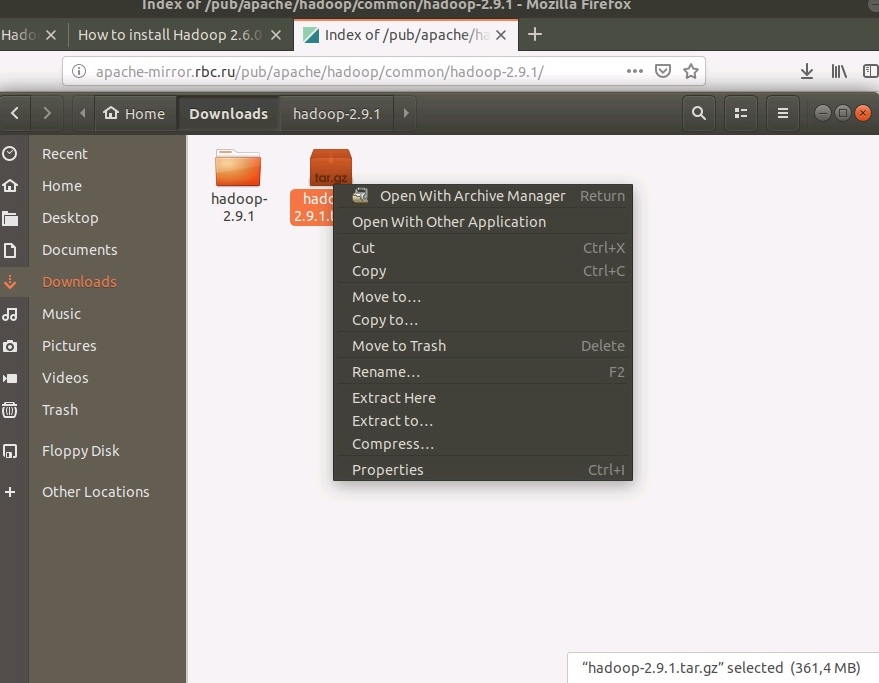
Далее необходимо переместить распакованный каталог в рабочий каталог с помощью команды mv, в нашем случае это каталог /usr/local. Следует отметить, что команда mv создаёт несуществующие каталоги, в нашем примере это hadoop/hadoop-2.9.1 :
sudo mv hadoop-2.9.1 /usr/local/hadoop/hadoop-2.9.1
Создадим рабочие каталоги для HDFS (NameNode и DataNode) и назначим владельца каталога hadoop (пользователь hduser):
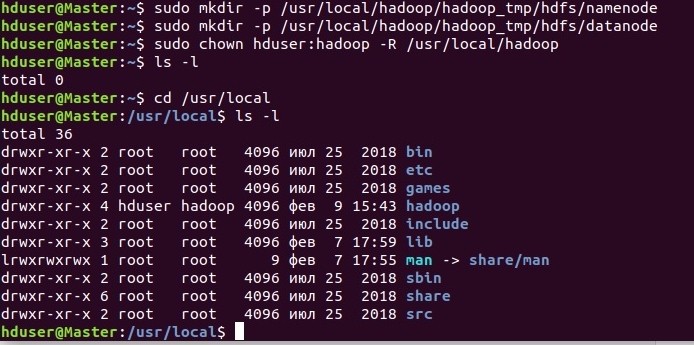
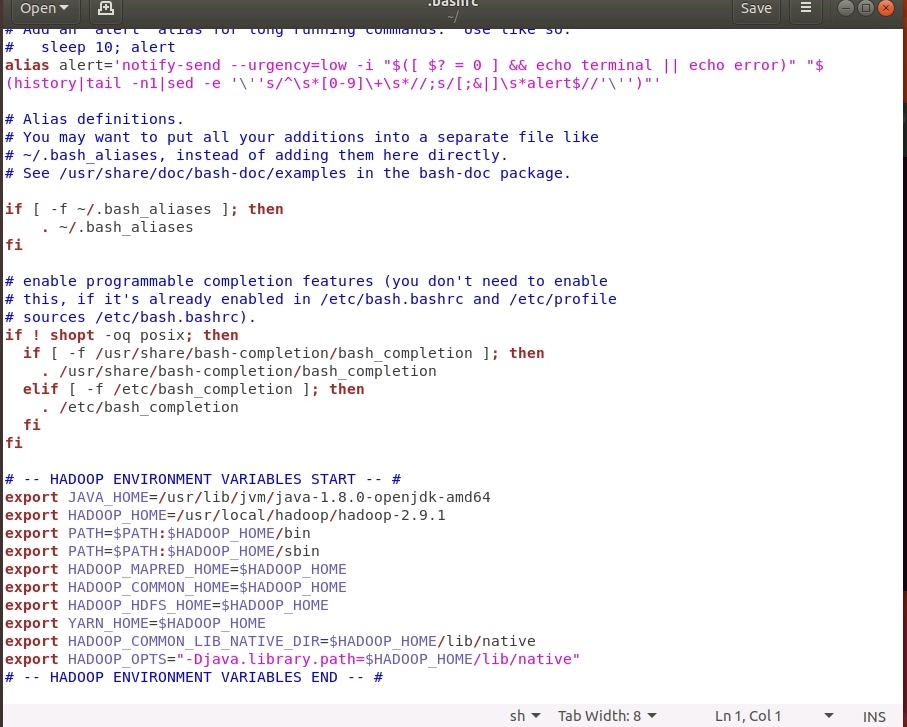
Теперь необходимо настроить переменные окружения:
В текстовом редакторе в конец файла вставить следующие строки:
Настраиваем HADOOP. Необходимо отметить, что все конфигурационные файлы находятся по следующему пути (в нашей конфигурации): /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/
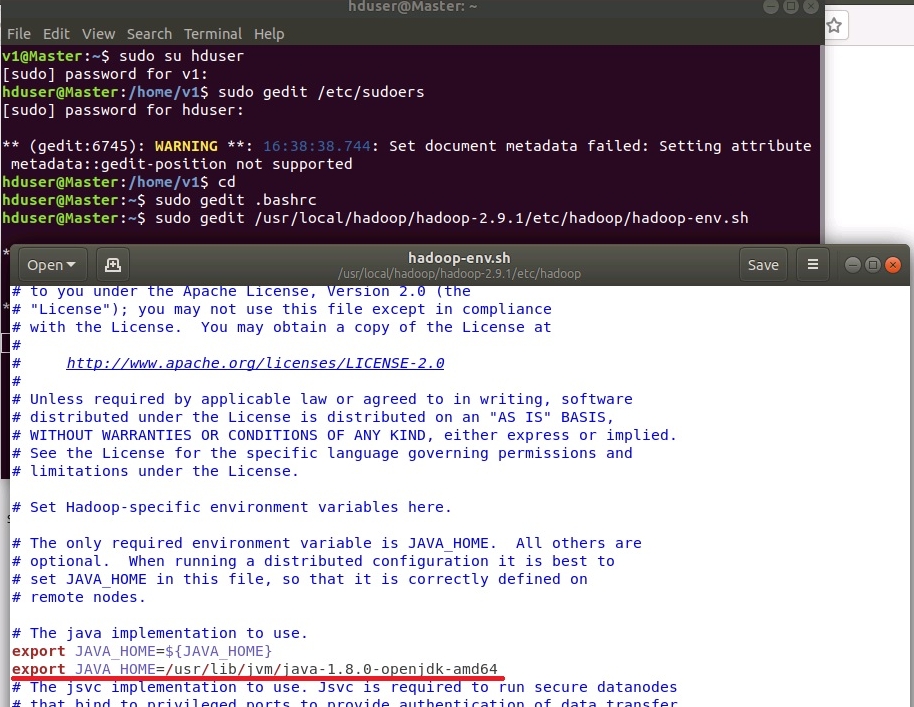
Добавить переменную JAVA_HOME в файл /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/hadoop-env.sh
sudo gedit /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/hadoop-env.sh
Настройка файла core-site.xml. Для этого открыть файл в редакторе с помощью команды
sudo gedit /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/core-site.xml
И прописать следующие строки:
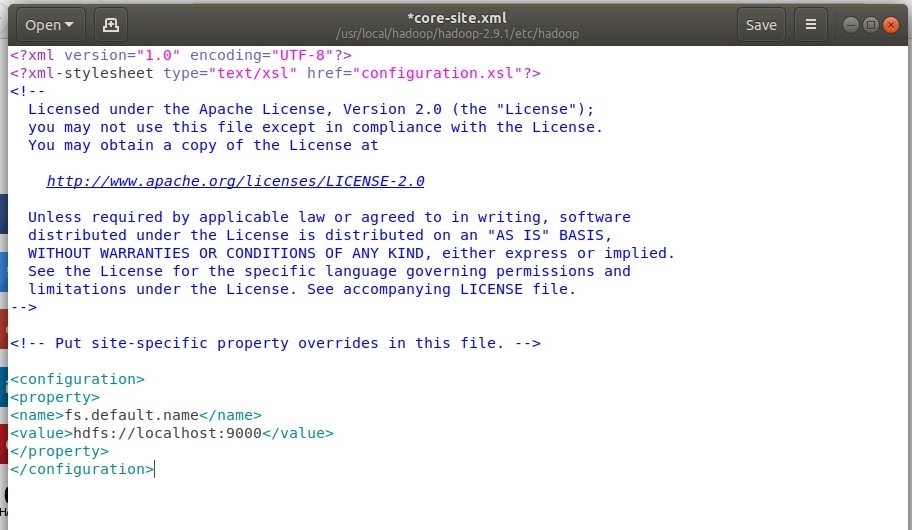
Настройка файла hdfs-site.xml. Для этого открыть файл в редакторе с помощью команды
sudo gedit /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/hdfs-site.xml
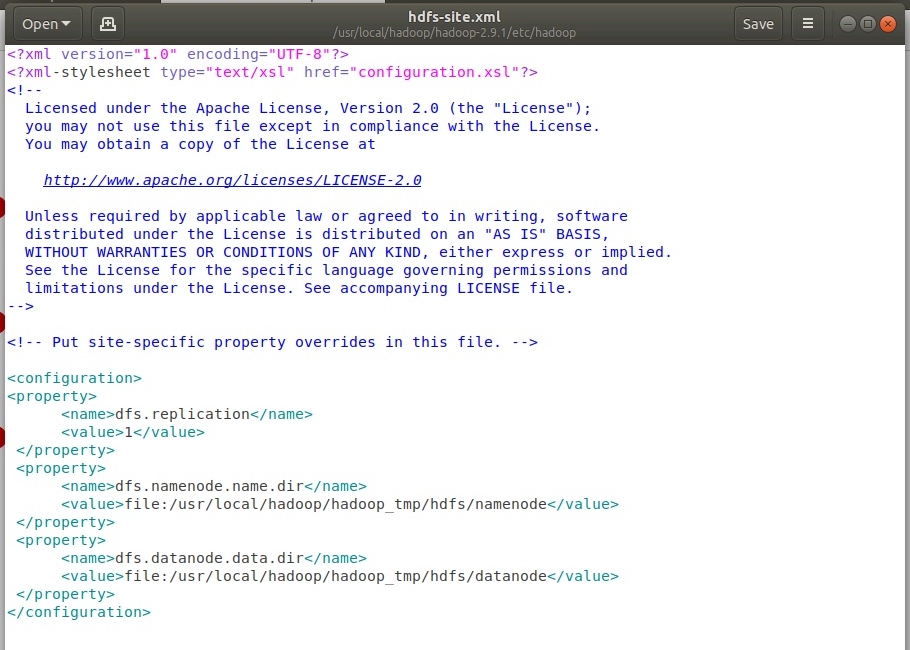
Настройка yarn-site.xml. Для этого открыть файл в редакторе с помощью команды
sudo gedit /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/yarn-site.xml

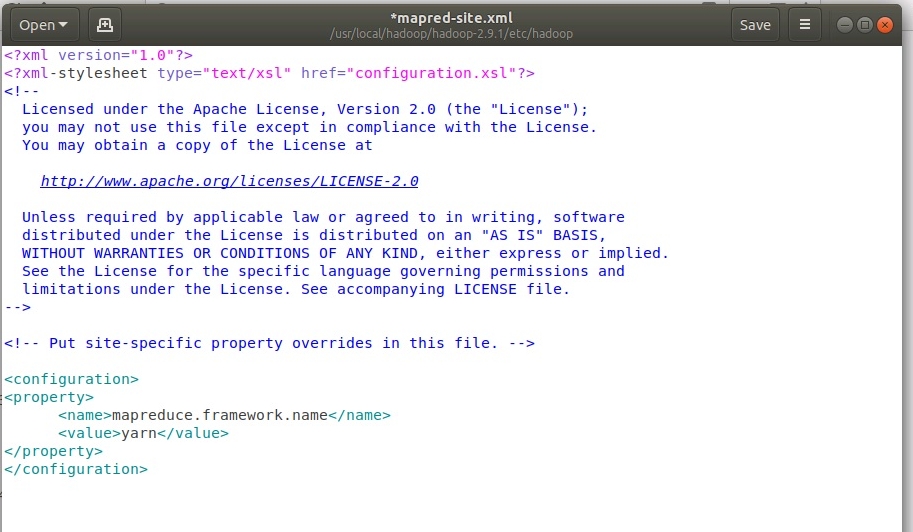
Настройка mapred-site.xml. Файл изначально не существует, есть шаблон, который нужно скопировать командой:
cp /usr/local/hadoop//hadoop-2.9.1/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/mapred-site.xml
Открыть и отредактировать созданный файл
sudo gedit /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/mapred-site.xml
На этом настройка закончена, перезагружаем систему и форматируем HDFS от пользователя hduser с помощью команды:
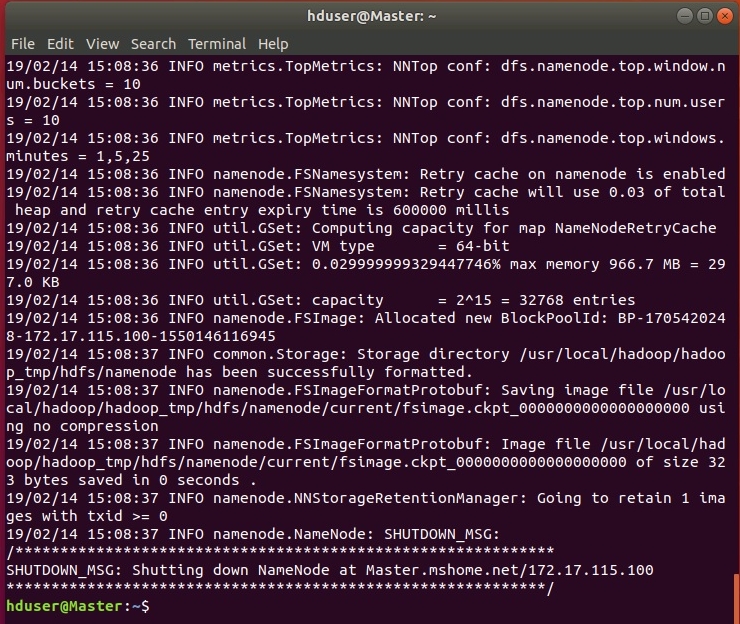
В ходе форматирования в терминале будут отображены логи:
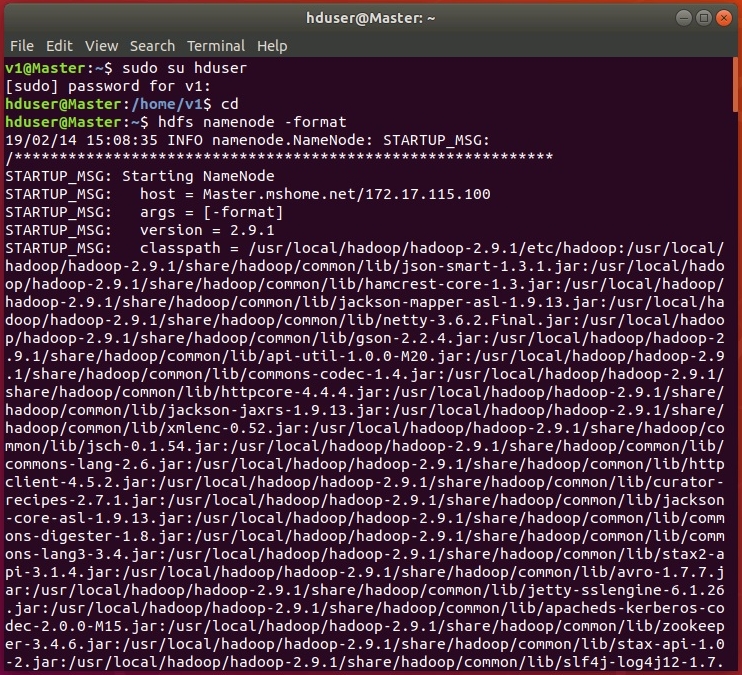
Если все настроено правильно, в логах не должно быть записей, содержащих ERROR, WARN допускаются. При удачном форматировании конец логов должен выглядеть приблизительно так:
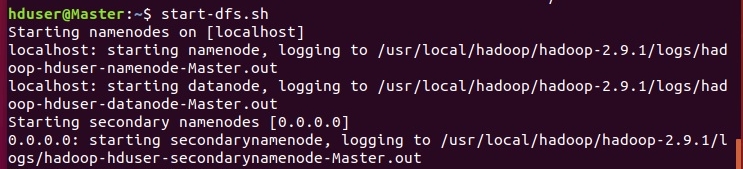
Теперь осталось запустить HADOOP!
Запуск HADOOP заключается в запуске менеджеров HDFS и YARN. Для этого необходимо запустить два скрипта.

Успешность запуска всех демонов HADOOP можно проверить с помощью команды jps.
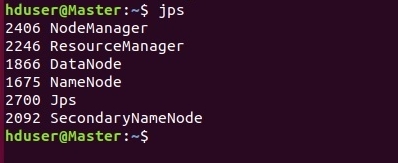
Если все настроено правильно, должно быть запущено 5 процессов HADOOP: NodeManager, NameNode, DataNode, ResourceManager, SecondaryNameNode.
Для облегчения процедуры запуска HADOOP можно создать простой скриптик, для этого перейдем в домашний каталог пользователя hduser с помощью команды cd.
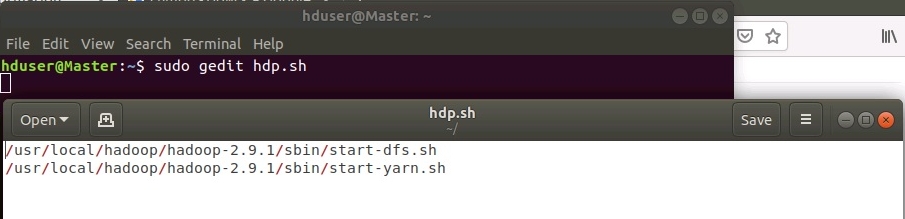
Создадим файл hdp.sh и отредактируем его с помощью команды:
Добавим в редакторе следующие строки:
Сохраняем и выходим. Теперь нужно дать права на исполнения для файла hdp.sh. Это делается командой:
sudo chmod 777 hdp.sh
Запускаем наш скрипт:
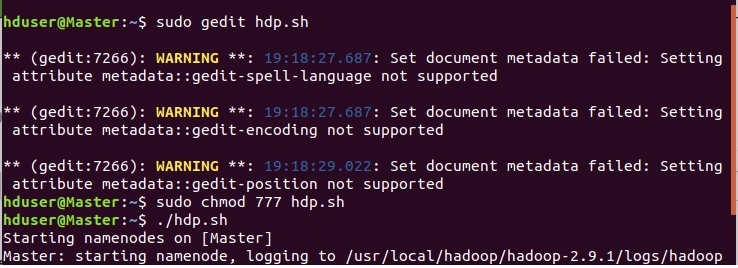
Вот мы и настроили однонодовый кластер HADOOP. В следующей статье будет представлена настройка многонодового кластера.
Комментарии

За статьи по Hadoop большое спасибо, они у вас все классные!!
Комментировать могуть только зарегистрированные пользователи
Big Data от А до Я. Часть 2: Hadoop
Привет, Хабр! В предыдущей статье мы рассмотрели парадигму параллельных вычислений MapReduce. В этой статье мы перейдём от теории к практике и рассмотрим Hadoop – мощный инструментарий для работы с большими данными от Apache foundation.
В статье описано, какие инструменты и средства включает в себя Hadoop, каким образом установить Hadoop у себя, приведены инструкции и примеры разработки MapReduce-программ под Hadoop.

Общая информация о Hadoop
Как известно парадигму MapReduce предложила компания Google в 2004 году в своей статье MapReduce: Simplified Data Processing on Large Clusters. Поскольку предложенная статья содержала описание парадигмы, но реализация отсутствовала – несколько программистов из Yahoo предложили свою реализацию в рамках работ над web-краулером nutch. Более подробно историю Hadoop можно почитать в статье The history of Hadoop: From 4 nodes to the future of data
Изначально Hadoop был, в первую очередь, инструментом для хранения данных и запуска MapReduce-задач, сейчас же Hadoop представляет собой большой стек технологий, так или иначе связанных с обработкой больших данных (не только при помощи MapReduce).
Основными (core) компонентами Hadoop являются:
Некоторым из перечисленных компонент будут посвящены отдельные статьи этого цикла материалов, а пока разберём, каким образом можно начать работать с Hadoop и применять его на практике.
Установка Hadoop на кластер при помощи Cloudera Manager
Раньше установка Hadoop представляла собой достаточно тяжёлое занятие – нужно было по отдельности конфигурировать каждую машину в кластере, следить за тем, что ничего не забыто, аккуратно настраивать мониторинги. С ростом популярности Hadoop появились компании (такие как Cloudera, Hortonworks, MapR), которые предоставляют собственные сборки Hadoop и мощные средства для управления Hadoop-кластером. В нашем цикле материалов мы будем пользоваться сборкой Hadoop от компании Cloudera.
Для того чтобы установить Hadoop на свой кластер, нужно проделать несколько простых шагов:
После установки вы получите консоль управления кластером, где можно смотреть установленные сервисы, добавлять/удалять сервисы, следить за состоянием кластера, редактировать конфигурацию кластера:
Более подробно с процессом установки Hadoop на кластер при помощи cloudera manager можно ознакомиться по ссылке в разделе Quick Start.
Если же Hadoop планируется использовать для «попробовать» – можно не заморачиваться с приобретением дорогого железа и настройкой Hadoop на нём, а просто скачать преднастроенную виртуальную машину по ссылке и пользоваться настроенным hadoop’ом.
Запуск MapReduce программ на Hadoop
Теперь покажем как запустить MapReduce-задачу на Hadoop. В качестве задачи воспользуемся классическим примером WordCount, который был разобран в предыдущей статье цикла. Для того, чтобы экспериментировать на реальных данных, я подготовил архив из случайных новостей с сайта lenta.ru. Скачать архив можно по ссылке.
Напомню формулировку задачи: имеется набор документов. Необходимо для каждого слова, встречающегося в наборе документов, посчитать, сколько раз встречается слово в наборе.
Решение:
Map разбивает документ на слова и возвращает множество пар (word, 1).
Reduce суммирует вхождения каждого слова:
Теперь задача запрограммировать это решение в виде кода, который можно будет исполнить на Hadoop и запустить.
Способ №1. Hadoop Streaming
Самый простой способ запустить MapReduce-программу на Hadoop – воспользоваться streaming-интерфейсом Hadoop. Streaming-интерфейс предполагает, что map и reduce реализованы в виде программ, которые принимают данные с stdin и выдают результат на stdout.
Программа, которая исполняет функцию map называется mapper. Программа, которая выполняет reduce, называется, соответственно, reducer.
Streaming интерфейс предполагает по умолчанию, что одна входящая строка в mapper или reducer соответствует одной входящей записи для map.
Вывод mapper’a попадает на вход reducer’у в виде пар (ключ, значение), при этом все пары соответствующие одному ключу:
Данные, которые будет обрабатывать Hadoop должны храниться на HDFS. Загрузим наши статьи и положим на HDFS. Для этого нужно воспользоваться командой hadoop fs:
Утилита hadoop fs поддерживает большое количество методов для манипуляций с файловой системой, многие из которых один в один повторяют стандартные утилиты linux. Подробнее с её возможностями можно ознакомиться по ссылке.
Теперь запустим streaming-задачу:
Утилита yarn служит для запуска и управления различными приложениями (в том числе map-reduce based) на кластере. Hadoop-streaming.jar – это как раз один из примеров такого yarn-приложения.
Дальше идут параметры запуска:
В интерфейсе доступном по этому URL можно узнать более детальный статус выполнения задачи, посмотреть логи каждого маппера и редьюсера (что очень полезно в случае упавших задач).
Сам результат можно получить следующим образом:
Способ №2
Сам по себе hadoop написан на java, и нативный интерфейс у hadoop-a тоже java-based. Покажем, как выглядит нативное java-приложение для wordcount:
Этот класс делает абсолютно то же самое, что наш пример на Python. Мы создаём классы TokenizerMapper и IntSumReducer, наследуя их от классов Mapper и Reducer соответсвенно. Классы, передаваемые в качестве параметров шаблона, указывают типы входных и выходных значений. Нативный API подразумевает, что функции map на вход подаётся пара ключ-значение. Поскольку в нашем случае ключ пустой – в качестве типа ключа мы определяем просто Object.
В методе Main мы заводим mapreduce-задачу и определяем её параметры – имя, mapper и reducer, путь в HDFS, где находятся входные данные и куда положить результат.
Для компиляции нам потребуются hadoop-овские библиотеки. Я использую для сборки Maven, для которого у cloudera есть репозиторий. Инструкции по его настройке можно найти по ссылке. В итоге файл pom.xmp (который используется maven’ом для описания сборки проекта) у меня получился следующий):
Соберём проект в jar-пакет:
После сборки проекта в jar-файл запуск происходит похожим образом, как и в случае streaming-интерфейса:
Дожидаемся выполнения и проверяем результат:
Как нетрудно догадаться, результат выполнения нашего нативного приложения совпадает с результатом streaming-приложения, которое мы запустили предыдущим способом.
Резюме
В статье мы рассмотрели Hadoop – программный стек для работы с большими данными, описали процесс установки Hadoop на примере дистрибутива cloudera, показали, как писать mapreduce-программы, используя streaming-интерфейс и нативный API Hadoop’a.
В следующих статьях цикла мы рассмотрим более детально архитектуру отдельных компонент Hadoop и Hadoop-related ПО, покажем более сложные варианты MapReduce-программ, разберём способы упрощения работы с MapReduce, а также ограничения MapReduce и как эти ограничения обходить.
Спасибо за внимание, готовы ответить на ваши вопросы.
Поговорим за Hadoop
Введение
Как человеку с не очень устойчивой психикой, мне достаточно одного взгляда на картинку, подобную этой, для начала панической атаки. Но я решил, что страдать буду только сам. Цель статьи — сделать так, чтобы Hadoop выглядел не таким страшным.
Что будет в этой статье:
Чего не будет в этой статье:
Что такое Hadoop и зачем он нужен
Hadoop не так уж сложен, ядро состоит из файловой системы HDFS и MapReduce фреймворка для обработки данных из этой файловой системы.
Если смотреть на вопрос «зачем нам нужен Hadoop?» с точки зрения использования в крупном энтерпрайзе, то ответов достаточно много, причем варьируются они от «сильно за» до «очень против». Я рекомендую просмотреть статью ThoughtWorks.
Если смотреть на этот же вопрос уже с технической точки зрения — для каких задач нам есть смысл использовать Hadoop — тут тоже не все так просто. В мануалах в первую очередь разбираются два основных примера: word count и анализ логов. Ну хорошо, а если у меня не word count и не анализ логов?
Хорошо бы еще и определить ответ как-нибудь просто. Например, SQL — нужно использовать, если у вас есть очень много структурированных данных и вам очень хочется с данными поговорить. Задать как можно больше вопросов заранее неизвестной природы и формата.
Длинный ответ —просмотреть какое-то количество существующих решений и собрать неявным образом в подкорке условия, для которых нужен Hadoop. Можно ковыряться в блогах, могу еще посоветовать прочитать книгу Mahmoud Parsian «Data Algorithms: Recipes for Scaling up with Hadoop and Spark».
Попробую ответить короче. Hadoop следует использовать, если:
Архитектура HDFS и типичный Hadoop кластер
HDFS подобна другим традиционным файловым системам: файлы хранятся в виде блоков, существует маппинг между блоками и именами файлов, поддерживается древовидная структура, поддерживается модель доступа к файлам основанная на правах и т. п.
Hadoop-кластер состоит из нод трех типов: NameNode, Secondary NameNode, Datanode.
Namenode — мозг системы. Как правило, одна нода на кластер (больше в случае Namenode Federation, но мы этот случай оставляем за бортом). Хранит в себе все метаданные системы — непосредственно маппинг между файлами и блоками. Если нода 1 то она же и является Single Point of Failure. Эта проблема решена во второй версии Hadoop с помощью Namenode Federation.
Secondary NameNode — 1 нода на кластер. Принято говорить, что «Secondary NameNode» — это одно из самых неудачных названий за всю историю программ. Действительно, Secondary NameNode не является репликой NameNode. Состояние файловой системы хранится непосредственно в файле fsimage и в лог файле edits, содержащим последние изменения файловой системы (похоже на лог транзакций в мире РСУБД). Работа Secondary NameNode заключается в периодическом мерже fsimage и edits — Secondary NameNode поддерживает размер edits в разумных пределах. Secondary NameNode необходима для быстрого ручного восстанавления NameNode в случае выхода NameNode из строя.
В реальном кластере NameNode и Secondary NameNode — отдельные сервера, требовательные к памяти и к жесткому диску. А заявленное “commodity hardware” — уже случай DataNode.
DataNode — Таких нод в кластере очень много. Они хранят непосредственно блоки файлов. Нода регулярно отправляет NameNode свой статус (показывает, что еще жива) и ежечасно — репорт, информацию обо всех хранимых на этой ноде блоках. Это необходимо для поддержания нужного уровня репликации.
Посмотрим, как происходит запись данных в HDFS:
Клиент продолжает записывать блоки, если сумеет записать успешно блок хотя бы на одну ноду, т. е. репликация будет работать по хорошо известному принципу «eventual», в дальнейшем NameNode обязуется компенсировать и таки достичь желаемого уровня репликации.
Завершая обзор HDFS и кластера, обратим внимание на еще одну замечательную особенность Hadoop’а — rack awareness. Кластер можно сконфигурировать так, чтобы NameNode имел представление, какие ноды на каких rack’ах находятся, тем самым обеспечив лучшую защиту от сбоев.
MapReduce
Единица работы job — набор map (параллельная обработка данных) и reduce (объединение выводов из map) задач. Map-задачи выполняют mapper’ы, reduce — reducer’ы. Job состоит минимум из одного mapper’а, reducer’ы опциональны. Здесь разобран вопрос разбиения задачи на map’ы и reduce’ы. Если слова «map» и «reduce» вам совсем непонятны, можно посмотреть классическую статью на эту тему.
Модель MapReduce
Посмотрим на архитектуру MapReduce 1. Для начала расширим представление о hadoop-кластере, добавив в кластер два новых элемента — JobTracker и TaskTracker. JobTracker непосредственно запросы от клиентов и управляет map/reduce тасками на TaskTracker’ах. JobTracker и NameNode разносится на разные машины, тогда как DataNode и TaskTracker находятся на одной машине.
Взаимодействие клиента и кластера выглядит следующим образом:
1. Клиент отправляет job на JobTracker. Job представляет из себя jar-файл.
2. JobTracker ищет TaskTracker’ы с учетом локальности данных, т.е. предпочитая те, которые уже хранят данные из HDFS. JobTracker назначает map и reduce задачи TaskTracker’ам
3. TaskTracker’ы отправляют отчет о выполнении работы JobTracker’у.
Неудачное выполнение задачи — ожидаемое поведение, провалившиеся таски автоматически перезапускаются на других машинах.
В Map/Reduce 2 (Apache YARN) больше не используется терминология «JobTracker/TaskTracker». JobTracker разделен на ResourceManager — управление ресурсами и Application Master — управление приложениями (одним из которых и является непосредственно MapReduce). MapReduce v2 использует новое API
Настройка окружения
На рынке существуют несколько разных дистрибутивов Hadoop: Cloudera, HortonWorks, MapR — в порядке популярности. Однако мы заострять внимание на выборе конкретного дистрибутива не будем. Подробный анализ дистрибутивов можно найти здесь.
Есть два способа безболезненно и с минимальными трудозатратами попробовать Hadoop:
1. Amazon Cluster — полноценный кластер, но этот вариант будет стоить денег.
2. Скачать виртуальную машину (мануал №1 или мануал №2). В этом случае минусом будет, что все сервера кластера крутятся на одной машине.
Перейдем к способам болезненным. Hadoop первой версии в Windows потребует установки Cygwin. Плюсом здесь будет отличная интеграция со средами разработки (IntellijIDEA и Eclipse). Подробнее в этом замечательном мануале.
Начиная со второй версии, Hadoop поддерживает и серверные редакции Windows. Однако я бы не советовал пытаться использовать Hadoop и Windows не только в production’e, но и вообще где-то за пределами компьютера разработчика, хотя для этого и существуют специальные дистрибутивы. Windows 7 и 8 в настоящий момент вендоры не поддерживают, однако люди, которые любят вызов, могут попробовать это сделать руками.
Отмечу еще, что для фанатов Spring существует фреймворк Spring for Apache Hadoop.
Мы пойдем путем простым и установим Hadoop на виртуальную машину. Для начала скачаем дистрибутив CDH-5.1 для виртуальной машины (VMWare или VirtualBox). Размер дистрибутива порядка 3,5 гб. Cкачали, распаковали, загрузили в VM и на этом все. У нас все есть. Самое время написать всеми любимый WordCount!
Конкретный пример
Нам понадобится сэмпл данных. Я предлагаю скачать любой словарь для bruteforce’а паролей. Мой файл будет называться john.txt.
Теперь открываем Eclipse, и у нас уже есть пресозданный проект training. Проект уже содержитя все необходимые библиотеки для разработки. Давайте выкинем весь заботливо положенный ребятами из Clouder код и скопипастим следующее:
Получим примерно такой результат:
Нажимаем Apply, а затем Run. Работа успешно выполнится:
А где же результаты? Для этого обновляем проект в Eclipse (кнопкой F5):
В папке output можно увидеть два файла: _SUCCESS, который говорит, что работа была выполнена успешно, и part-00000 непосредственно с результатами.
Этот код, разумеется, можно дебажить и т. п. Завершим же разговор обзором unit-тестов. Собственно, пока для написания unit-тестов в Hadoop есть только фреймворк MRUnit (https://mrunit.apache.org/), за Hadoop он опаздывает: сейчас поддерживаются версии вплоть до 2.3.0, хотя последняя стабильная версия Hadoop — 2.5.0
Блиц-обзор экосистемы: Hive, Pig, Oozie, Sqoop, Flume
В двух словах и обо всем.
Hive & Pig. В большинстве случаев писать Map/Reduce job’ы на чистой Java — слишком трудоемкое и неподъемное занятие, имеющее смысл, как правило, лишь чтобы вытащить всю возможную производительность. Hive и Pig — два инструмента на этот случай. Hive любят в Facebook, Pig любят Yahoo. У Hive — SQL-подобный синтаксис (сходства и отличия с SQL-92). В лагерь Big Data перешло много людей с опытом в бизнес-анализе, а также DBA — для них Hive часто инструмент выбора. Pig фокусируется на ETL.
Oozie — workflow-движок для jobs. Позволяет компоновать jobs на разных платформах: Java, Hive, Pig и т. д.
Наконец, фреймворки, обеспечивающие непосредственно ввод данных в систему. Совсем коротко. Sqoop — интеграция со структурированными данными (РСУБД), Flume — с неструктурированными.
Обзор литературы и видеокурсов
Литературы по Hadoop пока не так уж много. Что касается второй версии, мне попадалась только одна книга, которая концентрировалась бы именно на ней — Hadoop 2 Essentials: An End-to-End Approach. К сожалению, книгу никак не получить в электронном формате, и ознакомиться с ней не получилось.
Я не рассматриваю литературу по отдельным компонентам экосистемы — Hive, Pig, Sqoop — потому что она несколько устарела, а главное, такие книги вряд ли кто-то будет читать от корки до корки, скорее, они будут использоваться как reference guide. Да и то всегда можно обойдись документацией.
Hadoop: The Definitive Guide — книга в топе Амазона и имеет много позитивных отзывов. Материал устаревший: 2012 года и описывает Hadoop 1. В плюс идет много положительных ревью и достаточно широкое покрытие всей экосистемы.
Lublinskiy B. Professional Hadoop Solution — книга, из которой взято много материала для этой статьи. Несколько сложновата, однако очень много реальных практических примеров —внимания уделено конкретным нюансам построения решений. Куда приятнее, чем просто читать описание фич продукта.
Sammer E. Hadoop Operations — около половины книги отведено описанию конфигурации Hadoop. Учитывая, что книга 2012 г., устареет очень скоро. Предназначена она в первую очередь, конечно же, для devOps. Но я придерживаюсь мнения, что невозможно понять и прочувствовать систему, если ее только разрабатывать и не эксплуатировать. Мне книга показалось полезной за счет того, что разобраны стандартные проблемы бэкапа, мониторинга и бенчмаркинга кластера.
Parsian M. «Data Algorithms: Recipes for Scaling up with Hadoop and Spark» — основной упор идет на дизайн Map-Reduce-приложений. Сильный уклон в научную сторону. Полезно для всестороннего и глубокого понимания и применения MapReduce.
Owens J. Hadoop Real World Solutions Cookbook — как и многие другие книги издательства Packt со словом “Cookbook” в заголовке, представляет собой техническую документацию, которую нарезали на вопросы и ответы. Это тоже не так просто. Попробуйте сами. Стоит прочитать для широкого обзора, ну, и использовать как справочник.
Стоит обратить внимание и на два видеокурса от O’Reilly.
Learning Hadoop — 8 часов. Показался слишком поверхностным. Но для меня некую ценность представили доп. материалы, потому что хочется поиграть с Hadoop, но нужны какие-то живые данные. И вот он — замечательный источник данных.
Building Hadoop Clusters — 2,5 часа. Как понятно из заголовка, здесь упор на построение кластеров на Амазоне. Мне курс очень понравился — коротко и ясно.
Надеюсь, что мой скромный вклад поможет тем, кто только начинает освоение Hadoop.



