Первый видеокодек на машинном обучении кардинально превзошёл все существующие кодеки, в том числе H.265 и VP9

Примеры реконструкции фрагмента видео, сжатого разными кодеками с примерно одинаковым значением BPP (бит на пиксель). Сравнительные результаты тестирования см. под катом
Исследователи из компании WaveOne утверждают, что близки к революции в области видеокомпрессии. При обработке видео высокого разрешения 1080p их новый кодек на машинном обучении сжимает видео примерно на 20%лучше, чем самые современные традиционные видеокодеки, такие как H.265 и VP9. А на видео «стандартной чёткости» (SD/VGA, 640×480) разница достигает 60%.
Разработчики называют нынешние методы видеокомпрессии, которые реализованы в H.265 и VP9, «древними» по стандартам современных технологий: «За последние 20 лет основы существующих алгоритмов сжатия видео существенно не изменились, — пишут авторы научной работы во введении своей статьи. — Хотя они очень хорошо спроектированы и тщательно настроены, но остаются жёстко запрограммированными и как таковые не могут адаптироваться к растущему спросу и всё более разностороннему спектру применения видеоматериалов, куда входят обмен в социальные СМИ, обнаружение объектов, потоковое вещание виртуальной реальности и так далее».
Применение машинного обучения должно наконец перенести технологии видеокомпрессии в 21 век. Новый алгоритм сжатия значительно превосходит существующие видеокодеки. «Насколько нам известно, это первый метод машинного обучения, который показал такой результат», — говорят они.
Основная идея сжатия видео заключается в удалении избыточных данных и замене их более коротким описанием, которое позволяет воспроизводить видео позже. Большая часть сжатия видео происходит в два этапа.
Первый этап — сжатие движения, когда кодек ищет движущиеся объекты и пытается предсказать, где они будут в следующем кадре. Затем вместо записи пикселей, связанных с этим движущимся объектом, в каждом кадре алгоритм кодирует только форму объекта вместе с направлением движения. Действительно, некоторые алгоритмы смотрят на будущие кадры, чтобы определить движение ещё более точно, хотя это явно не сможет работать для прямых трансляций.
Второй шаг сжатия удаляет другие избыточности между одним кадром и следующим. Таким образом, вместо того, чтобы записывать цвет каждого пикселя в голубом небе, алгоритм сжатия может определить область этого цвета и указать, что он не изменяется в течение следующих нескольких кадров. Таким образом, эти пиксели остаются того же цвета, пока не сказали, чтобы изменить. Это называется остаточным сжатием.
Новый подход, который представили учёные, впервые использует машинное обучение для улучшения обоих этих методов сжатия. Так, при сжатии движения методы машинного обучения команды нашли новые избыточности на основе движения, которые обычные кодеки никогда не были в состоянии обнаружить, а тем более использовать. Например, поворот головы человека из фронтального вида в профиль всегда даёт аналогичный результат: «Традиционные кодеки не смогут предсказать профиль лица исходя из фронтального вида», — пишут авторы научной работы. Напротив, новый кодек изучает эти виды пространственно-временных шаблонов и использует их для прогнозирования будущих кадров.
Другая проблема заключается в распределении доступной полосы пропускания между движением и остаточным сжатием. В некоторых сценах более важно сжатие движения, а в других остаточное сжатие обеспечивает наибольший выигрыш. Оптимальный компромисс между ними отличается от кадра к кадру.
Традиционные алгоритмы обрабатывают оба процесса отдельно друг от друга. Это означает, что нет простого способа отдать преимущество тому или другому и найти компромисс.
Авторы обходят это путём сжатия обоих сигналов одновременно и на основе сложности кадра определяют, как распределить пропускную способность между двумя сигналами наиболее эффективным способом.
Эти и другие усовершенствования позволили исследователям создать алгоритм сжатия, который значительно превосходит традиционные кодеки (см. бенчмарки ниже).
Примеры реконструкции фрагмента, сжатого разными кодеками с примерно одинаковым значением BPP показывает заметное преимущество кодека WaveOne
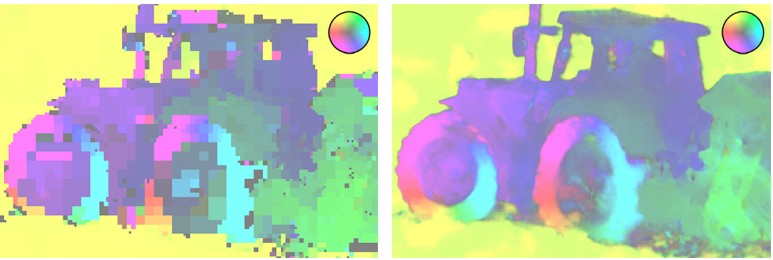
Карты оптического потока H.265 (слева) и кодека WaveOne (справа) на одинаковом битрейте
Однако новый подход не лишен некоторых недостатков, отмечает издание MIT Technology Review. Пожалуй, главным недостатком является низкая вычислительная эффективность, то есть время, необходимое для кодирования и декодирования видео. На платформе Nvidia Tesla V100 и на видео VGA-размера новый декодер работает со средней скоростью около 10 кадров в секунду, а кодер и вовсе со скоростью около 2 кадров в секунду. Такие скорости просто невозможно применить в прямых видеотрансляциях, да и при офлайновом кодировании материалов новый кодер будет иметь весьма ограниченную сферу использования.
Более того, скорости декодера недостаточно даже для просмотра видеоролика, сжатого этим кодеком, на обычном персональном компьютере. То есть для просмотра этих видеороликов даже в минимальном качестве SD в данный момент требуется целый вычислительный кластер с несколькими графическими ускорителями. А для просмотра видео в качестве HD (1080p) понадобится целая компьютерная ферма.
Остаётся надеяться только на увеличение мощности графических процессоров в будущем и на совершенствование технологии: «Текущая скорость не достаточна для развёртывания в реальном времени, но должна быть существенно улучшена в будущей работе», — пишут они.
Бенчмарки
Все кодеки проверяли на стандартной базе видеороликов в форматах SD и HD, которые часто используются для оценки алгоритмов сжатия видео. Для SD-качества использовалась библиотека видео в разрешении VGA от e Consumer Digital Video Library (CDVL). Она содержит 34 видеоролика с общей длиной 15 650 кадров. Для HD использовался набор данных Xiph 1080p: 22 видеоролика общей длиной 11 680 кадров. Все видеоролики 1080p были обрезаны по центру до высоты 1024 (в данный подход нейросеть исследователей способна обрабатывать только измерения с размерностями, кратными 32 по каждой стороне).
Различные результаты тестирования показаны на диаграммах ниже:
Результаты тестирования на наборе видеороликов низкого разрешения (SD)
Результаты тестирования на наборе видеороликов высокого разрешения (HD)
Влияние различных компонентов кодека WaveOne на качество сжатия
Не стоит удивляться такому высокому уровню сжатия и кардинальному превосходству над традиционными видеокодеками. Данная работа во многом основана на предыдущих научных статьях, где описываются различные методы сжатия статичных изображений на базе машинного зрения. Все они намного превосходят по уровню и качеству сжатия традиционные алгоритмы. Например, см. работы G. Toderici, S. M. O’Malley, S. J. Hwang, D. Vincent, D. Minnen, S. Baluja, M. Covell, R. Sukthankar. Variable rate image compression with recurrent neural networks, 2015; G. Toderici, D. Vincent, N. Johnston, S. J. Hwang, D. Minnen, J. Shor, M. Covell. Full resolution image compression with recurrent neural networks, 2016; J. Balle, V. Laparra, E. P. Simoncelli. End-to-end optimized image compression, 2016; N. Johnston, D. Vincent, D. Minnen, M. Covell, S. Singh, T. Chinen, S. J. Hwang, J. Shor, G. Toderici. Improved lossy image compression with priming and spatially adaptive bit rates for recurrent networks, 2017 и другие. В этих работах показано, как обученные нейросети заново изобретают многие техники сжатия изображений, которые были изобретены человеком и раньше вручную прописывались для применения традиционными алгоритмами сжатия.
Прогресс в области ML-сжатия статических изображений неизбежно привёл к появлению первых видеокодеков, основанных на машинном обучении. С увеличением производительности графических ускорителей именно реализация видеокодеков стала первым кандидатом. До настоящего момента существовала только единственная попытка создать видеокодек на машинном обучении. Она описана в работе C.-Y. Wu, N. Singhal, and P. Krahenbuhl. Video compression through image interpolation, которая опубликована в ECCV (2018). Та система сначала кодирует ключевые кадры, а затем использует иерархическую интерполяцию кадров между ними. Она демонстрирует эффективность кодирования примерно как у традиционного кодека AVC/H.264. Как видим, сейчас исследователям удалось значительно превзойти это достижение.
Статья «Выученное сжатие видео» опубликована 16 ноября 2018 года на сайте препринтов arXiv.org (arXiv:1811.06981). Авторы научной работы — Орен Риппель (Oren Rippel), Санджей Наир (Sanjay Nair), Карисса Лью (Carissa Lew), Стив Брэнсон (Steve Branson), Александер Андерсон (Alexander G. Anderson), Любомир Бурдев (Lubomir Bourdev).
Лучший комментарий Stas911:
Altaisky: Статья про видеокодек и ни одного видео. Нечего было показать?
Stas911: Они ещё декодируют первый кадр. Проявите терпение.
H264 или vp9 что лучше

Если ваша задача — получить лучшее качество при наименьшем битрейте, то тут кодек VP9 и приходит на помощь. С помощью него можно кодировать, например, 1080p видео с битрейтом 2500k (2,5 мегабита) и иметь вполне приличное качество. Если видео очень динамичное, битрейт следует поднять до 3000-4000k. Если же с таким битрейтом мы будем кодировать в кодек h264 — получим пиксельную кашу, примерно как на Ютубе. Ютуб далеко не всё видео кодирует в VP9 (webm), многие видео хранятся в кодеке h264/avc — смотреть на них больно. ![]()
Однако, кодек VP9 не идеален и есть у него небольшой изъян, связанный с цветовым пространством. Условно, два основных цветовых пространства — это TV (bt601) и PC (bt709). Чем они отличаются? Уровнями черного и белого. Цветовое пространство TV имеет более узкий диапазон цветов 16-235, где 16 — белый, а 235 — черный. Если просматривать такое видео на мониторе ПК, то оно будет блеклое, тусклое, с низким контрастом. Потому что правильное цветовое пространство для PC — 00-255, где 00 — абсолютный белый, а 255 — абсолютный черный. Простыми словами, телевизионное цветовое пространство имеет ограниченный диапазон RGB. А компьютерное — полный.
Проблема кодека VP9 состоит в том, что он умеет работать только с TV пространством, обозначаемое так же, как yuv420. Для многих современных фото и видеокамер — это не проблема, они снимают точно в таком же цветовом поле с поправкой на контраст, картинка с них вполне хорошо смотрится. Но есть старые модели фото-видео камер, которые снимают в цветовом пространстве yuvj420 (pc, bt709) и с них необработанное видео смотрится отлично, сочно, контрастно. Но вот при кодировании в VP9 подобных видео со старых камер, кодек обрезает диапазон цвета с 00-255 до 16-235 и мы получаем тусклую, неконтрастную картинку. Абсолютно черный 255 превращается в тёмно-серый 235. 
Как решать эту проблему?
Облазив огромное количество интернет-сайтов, как российских, так и зарубежных, я не нашел практически никакой полезной информации. И вывод напрашивается сам собой: раз кодек не поддерживает yuvj420 (pc, bt709), то и бороться с потерей цвета никак нельзя. Тем не менее, я нашел небольшую уловку, которая работает в актуальных версиях ffmpeg (4.2) и позволяет с помощью фильтра подкрутить контраст на 10%. Вероятно, Ютуб пользуется подобными методами, так как конвертировать PC-стандарт (yuvj420) в TV (yuv420) и не потерять часть цвета — невозможно. Делюсь командой для ffmpeg под Linux, чтобы закодировать видео yuvj420 и не лишиться контраста. Конечно, это лишь уловка, но закодированное видео в yuv420 практически не будет визуально отличаться от исходника и большинство вообще не заметит никакой разницы.
Решение:
-i — входной файл
MVI_9360.MOV — название входного файла, включая расширение
-c:v vp9 — кодек видео VP9
-vf «eq=contrast=1.1:brightness=0:saturation=1» — видеофильтр, контраст, яркость, насыщенность. Единица — это 100%.
-b:v 2000k — примерный битрейт видео установлен в 2000 килобит/c
-c:a libopus — кодек аудиодорожки, кроме libopus может использоваться libvorbis
-b:a 256k — битрейт аудиодорожки установлен в 256 килобит/c
-y — означает yes, полезно в случае перезаписи существующего в каталоге файла с тем же названием.
По поводу кодирования различных видеофайлов с помощью ffmpeg я как-нибудь напишу отдельный пост. А пока, на этом всё. Спасибо за внимание 🙂
На правах автора хочу напомнить, что у нас есть группа вк и телеграм-чат, где можно пообщаться на компьютерную и сетевую тематику.
VP8, VP9 и H265. Аппаратное ускорение кодирования и декодирования видео в процессорах 6-го поколения Skylake
Встроенная графика 9-го поколения HD Graphics 530 в процессоре Intel Core i7 6700K с 24 блоками выполнения команд (EU), организованными в три фрагмента по 8 блоков.
Удивительно, но Intel сумела обойти и AMD, и Nvidia в реализации аппаратного ускорения кодирования видео: похожие технологии AMD Video Codec Engine и Nvidia NVENC в видеокартах AMD и Nvidia появились со значительным опозданием (алгоритмы компрессии требуют серьёзной адаптации под процессоры видеокарт). Вот почему идея и разработка QSV хранились в секрете пять лет.
Сказать, что QSV была востребована — значит, ничего не сказать. Воспроизведение (декодирование) видео с аппаратной поддержкой стало гораздо меньше отнимать ресурсов у других задач в ОС, меньше нагревать CPU и потреблять меньше электроэнергии.
К тому же, в последние годы кодирование видео стало одной из самых ресурсоёмких задач на ПК. Популярность YouTube превратила миллионы человек в операторов и режиссёров. А тут ещё и повсеместное распространение смартфонов, для которых требуется транскодирование с DVD в сжатый AVC MP4/H.264. В результате, практически каждый ПК стал видеостудией. Массово распространились IPTV и потоковые видеотрансляции в интернете. Компьютер начал выполнять роль телевизора. Видео стало вездесущим и превратилось в один из самых популярных видов контента на ПК. Оно кодируется и транскодируется постоянно и везде: на разные битрейты, в зависимости от типа устройства, размера экрана и скорости интернета. В такой ситуации возможность быстрого кодирования и декодирования видео в процессорах напрашивалась сама собой. Так в Intel GPU встроили аппаратный кодер/декодер.
Современный кодек обрабатывает каждый кадр в отдельности, но также анализирует последовательность кадров на предмет повторений во времени (между кадрами) и пространстве (внутри одного кадра). Это сложная вычислительная задача. Ниже показан пример кадра из видео, который закодирован новейшим кодеком HEVC. Для конкретного участка возле уха зайца показано, как именно были закодированы различные участки кадра. Также показано положение и тип кадра в общей структуре видеопотока. Не углубляясь в детали алгоритмов видеокомпрессии, это даёт общее представление, насколько много информации требуется анализировать, чтобы эффективно кодировать и декодировать видео.
Скриншот открытого видео в программе Elecard StreamEye, 1920×1040
Аппаратная поддержка кодирования и декодирования означает, что непосредственно в процессоре реализованы интегральные схемы, специализированные для конкретных задач кодирования и декодирования. Например, дискретное косинусное преобразования (DCT) выполняется при кодировании, а обратное дискретное косинусное преобразования — при декодировании.
За прошедшие пять лет технология Intel QSV значительно продвинулась вперёд. Добавлена поддержка свободных видеокодеков VP8 и VP9, обновлены драйверы под Linux и т.д.
Технология улучшалась с каждым новым поколением Intel Core, вплоть до нынешнего 6-го поколения Skylake.
Микроархитектура GPU 9-го поколения
Последняя версия QSV 5.0 вышла вместе с микроархитектурой ядра шестого поколения Skylake. Данная версия GPU в официальной документации Intel классифицируется как Gen9, то есть графика 9-го поколения.

Процессор Intel Core i7 6700K для настольных компьютеров содержит 4 ядра CPU и встроенную графику 9-го поколения HD Graphics 530
С каждой новой микроархитектурой в GPU увеличивалось количество блоков выполнения команд (EU). Оно выросло с 6 в Sandy Bridge до 72 в топовой графике Iris Pro Graphics 580 на кристаллах Skylake. В том числе за счёт этого производительность GPU увеличилась десятикратно без увеличения тактовой частоты. Во всей графике последнего поколения Iris и Iris Pro имеется встроенный кэш Level 4 на 64 или 128 МБ.
▍Микроархитектура блоков выполнения команд (EU)
Базовым строительным блоком микроархитектуры Gen9 является блок выполнения команд (EU). Каждый EU сочетает в себе одновременную многопоточность (SMT) и тщательно настроенную чередующуюся многопоточность (IMT). Здесь работают арифметическо-логические устройства с одиночным потоком команд, множественным потоком данных (SIMD ALU). Они выстроены по конвейерам многочисленных тредов для высокоскоростного проведения вычислений с плавающей запятой и целочисленных операций.
Суть чередующейся многопоточности в EU состоит в том, чтобы гарантировать непрерывный поток готовых для выполнения инструкций, но в то же время ставить в очередь с минимальной задержкой более сложные операции, такие как размещение векторов в памяти, запросы семплеров или другие системные коммуникации.
Блок выполнения команд (EU)
Каждый тред в блоке выполнения команд Gen9 содержит 128 регистров общего назначения. В каждом из регистров 32 байта памяти, доступной в виде 8-элементного вектора SIMD или 32-битных элементов данных. Таким образом, на каждый тред приходится 4 КБ файла реестра общего назначения (GRF). Всего на один EU приходится 7 тредов с общим количеством 28 КБ GRF на EU. Гибкая система адресации позволяет адресовать несколько регистров вместе. Состояние треда в текущий момент сохраняется в отдельном файле архитектуры реестра (ARF).
В зависимости от нагрузки, аппаратные треды в EU могут выполнять параллельно один код от одного вычислительного ядра либо могут выполнять код от совершенно разных вычислительных ядер. Состояние выполнения в каждом треде, в том числе его собственные указатели инструкций, хранятся в его независимом ARF. На каждом цикле EU может выдавать до четырёх различных инструкций, которые должны быть от четырёх различных тредов. Специальный арбитр тредов (Thread Arbiter) отправляет эти инструкции в один из четырёх функциональных блоков для выполнения. Обычно арбитр может выбирать из разнородных инструкций, чтобы одновременно загружать все функциональные блоки и, таким образом, обеспечивать параллелизм на уровне инструкций.
Пара модулей FPU на схеме на самом деле выполняет и операции с плавающей запятой, и целочисленные вычисления. В Gen9 эти модули способы обработать за цикл не только до четырёх операций с 32-битными числами, но и до восьми операций с 16-битными. Операции сложения и умножения выполняются одновременно, то есть блок EU способен выполнить максимум до 16 операций с 32-битными числами за один цикл: 2 FPU по 4 операции × 2 (сложение+умножение).
Генерацией SPMD-кода для многопоточной загрузки EU занимаются соответствующие компиляторы, такие как RenderScript, OpenCL, Microsoft DirectX Compute Shader, OpenGL Compute и C++AMP. Компилятор сам эвристически выбирает режим загрузки тредов (SIMD-width): SIMD-8, SIMD-16 или SIMD-32. Так, в случае SIMD-16 на одном EU могут одновременно исполняться 112 (16×7) потоков.
Обмен данными в рамках одной инструкции внутри блока EU может составлять, например, 96 байтов на чтение и 32 байтов на запись. При масштабировании на весь GPU с учётом нескольких уровней иерархии памяти получается, что максимальный теоретический лимит обмена данными между FPU и GRF достигает нескольких терабайт в секунду.
▍Масштабируемость
Микроархитектура GPU обладает масштабируемостью на всех уровнях. Масштабируемость на уровне тредов переходит в масштабируемость на уровне блоков выполнения команд. В свою очередь, эти блоки выполнения команд объединятся в группы по восемь штук (8 EU = 1 subslice).
На каждом уровне масштабирования имеются локальные модули, работающие только здесь. Например, для каждой группы из 8 блоков EU предназначен свой локальный диспетчер тредов, порт данных и семплер для текстур.
Группа из 8 блоков EU (subslice)
В свою очередь группы из 8 EU объединяются в группы по 24 EU (3 sublices = 1 slice). Эти срезы по 24 блока, в свою очередь, тоже масштабируются: существующая графика Gen9 содержит 24, 48 или 72 EU.
В графике Gen9 увеличен объём кэша третьего уровня L3 до 768 КБ на каждую группу из 24 EU. У всех семплеров и портов данных свой собственный интерфейс доступа к L3, позволяющий считать и записать по 64 байта за цикл. Таким образом, на группу из 24 EU приходится три порта данных с полосой передачи данных к кэшу L3 192 байта за цикл. Если в кэше нет данных по запросу, то данные запрашиваются или направляется для записи в системную память, тоже по 64 байта за цикл.
Микроархитектура Gen9 из двух групп по 24 (3×8) EU
Такая масштабируемость позволяет эффективно снижать энергопотребление, отключая те модули, которые не задействованы в данный момент.
Что умеет QSV в Skylake
В Gen9 появилась полная поддержка аппаратного ускорения при кодировании и декодировании H.265/HEVC, частичная поддержка аппаратного кодирования и декодирования свободным кодеком VP9. Произведены значительные улучшения в технологии QSV. Они повысили качество и эффективность кодирования и декодирования, а также производительность фильтров в программах для транскодирования и видеоредактирования, которые используют аппаратное ускорение.
Интегрированная графика Skylake поддерживает стандарты DirectX 12 Feature Level 12_1, OpenGL 4.4 и OpenCL 2.0. Решено полностью отказаться от мониторов VGA, зато Skylake GPU поддерживают до трёх мониторов c интерфейсами HDMI 1.4, DisplayPort 1.2 или Embedded DisplayPort (eDP) 1.3.
Аппаратное ускорение декодирования видео доступно графическому драйверу через интерфейсы Direct3D Video API (DXVA2), Direct3d11 Video API или Intel Media SDK, а также через фильтры MFT (Media Foundation Transform).
В графике Gen9 поддерживается аппаратное ускорение декодирования AVC, VC1, MPEG2, HEVC (8 бит), VP8, VP9 и JPEG.
▍Аппаратное ускорение декодирования видео
| Кодек | Профиль | Уровень | Максимальное разрешение |
| MPEG2 | Main | Main High | 1080p |
| VC1/WMV9 | Advanced Main Simple | L3 High Simple | 3840×3840 |
| AVC/H264 | High Main MVC & stereo | L5.1 | 2160p(4K) |
| VP8 | 0 | Unified level | 1080p |
| JPEG/MJPEG | Baseline | Unified level | 16k × 16k |
| HEVC/H265 | Main | L5.1 | 2160(4K) |
| VP9 | 0 (4:2:0 Chroma 8-bit) | Unified level | ULT, 4k 24fps @15Mbps ULX, 1080p 30fps @10Mbps |
Источник: 6th Generation Intel Processor Datasheet for S-Platforms
Расчётная производительность декодирования видео при аппаратном ускорении составляет более 16 одновременных потоков видео 1080p. Реальная производительность зависит от модели GPU, битрейта и тактовой частоты. Аппаратное декодирование H264 SVC не поддерживается в Skylake.
Аппаратное ускорение кодирования доступно только через интерфейсы Intel Media SDK, а также через фильтры MFT (Media Foundation Transform).
▍Аппаратное ускорение кодирования видео
| Кодек | Профиль | Уровень | Максимальное разрешение |
| MPEG2 | Main | High | 1080p |
| AVC/H264 | Main High | L5.1 | 2160p(4K) |
| VP8 | Unified profile | Unified level | — |
| JPEG | Baseline | — | 16K×16K |
| HEVC/H265 | Main | L5.1 | 2160p(4K) |
| VP9 | 8-bit 4:2:0 BT2020 | — | — |
Источник: 6th Generation Intel Processor Datasheet for S-Platforms
Кроме аппаратного ускорения кодирования и декодирования, в графике Gen9 реализовано аппаратное ускорение обработки видео, в том числе следующих функций: деинтерлейсинг, определение каденции, масштабирование видео (Advanced Video Scaler), улучшение детализации, стабилизация изображения, сжатие охвата цветовой гаммы (gamut compression), адаптивное улучшение контраста HD, улучшение оттенков кожи, контроль цветопередачи, шумоподавление в цветовой составляющей канала (chroma de-noise), преобразование SFC (Scalar and Format Conversion), сжатие памяти, LACE (Localized Adaptive Contrast Enhancement), пространственное шумоподавление, Out-Of-Loop De-blocking (для декодера AVC) и др.
Аппаратный транскодер Gen9 поддерживает следующие специфические функции транскодирования:
Источник: 6th Generation Intel Processor Datasheet for S-Platforms
В Gen9 реализована аппаратная поддержка обработки видео с цифровых камер (Camera Processing Pipeline), в том числе отдельные функции этой обработки: баланс белого, восстановление полноцветного изображения с массива цветных фильтров на сенсоре камеры (de-mosaic), коррекция дефективных пикселей, исправление уровня чёрного, гамма-коррекция, устранение виньетирования, конвертер цветового пространства (Front end Color Space Converter, CSC), улучшение цветопередачи (Image Enhancement Color Processing, IECP).
Как программы используют аппаратное ускорение
Чтобы использовать аппаратное ускорение, каждая программа должна явно реализовать поддержку специфических функций Gen9. Многие делают это. Компания Intel публикует в открытом доступе Media SDK 2.0, так что поддержку аппаратного ускорения кодирования и декодирования можно внедрить в любую программу. Кроме того, существуют готовые приложения для транскодирования лайв видео на кодеках Intel, такие как Элекард CodecWorks 990. В отличие от SDK, CodecWorks 990 не требует участия программистов для применения в реальных задачах, уже содержит наиболее популярные профили транскодирования и работать с ним инженеру-не программисту в целом гораздо проще, чем с SDK. Как работают программные транскодеры с аппаратным ускорением — мы расскажем в следующей части.



