Git cat file что это
Вся информация требуемая чтобы представить историю проекта хранится в особым образом организованных файлах. Все файлы хранят ссылаются друг на друга с помощью 40-значного «имени объекта» и это имя выглядит так:
Вы увидите эти 40-значные строки повсюду в Git. В каждом случае имя вычисляется как SHA1 значение содержимого объекта. SHA1 хэш это криптографическая хэш-функция. Для нас это значит то, что практически нереально найти два разных объекта с одинаковым именем. Это дает огромную выгоду; такую как:
Объекты
Почти все в Git построено вокруг манипуляций этой простой структурой состоящей из четырех различных типов объектов. Это что-то вроде своеобразной файловой-системы надстроенной над файловой-системой компьютера.
Различия с SVN
Объект типа блоб
Блоб обычно хранит содержимое файла.
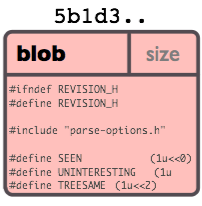
Вы можете использовать git show чтобы исследовать содержимое блоба. Предположим у нас есть SHA-значение блоба, таким образом чтобы просмотреть его содержимое выполните выполнить:
Объект «блоб» это всего лишь некоторая порция бинарных данных. Он ни на что не ссылается у него нет каких либо атрибутов, нет даже имени файла.
Поскольку блоб полностью определяется его собственным содержимым, то если два файла в директории или даже в разных версиях репозитория имеют одинаковое содержимое, они будут разделять один и тот же блоб объект. Объект полностью независит от его расположения в дереве каталогов, и переименование файла не изменит объект с которым этом файл связан.
Объект дерево

Команда git show более общая, и также может быть использована чтобы исследовать дерево объектов, но git ls-tree даст вам больше подробностей. Предположим у нас есть SHA значение дерева, тогда мы можем исследовать его следующим образом:
Как вы можете видеть, объект дерево содержит список записей. Каждая запись состоит из вида, типа объекта, SHA1 значения, и имени соответственно. Записи отсортированы по имени. Так выглядит содержимое одной директории дерева.
Ссылка на объект в дереве может быть как блобом (файлом по сути) так и деревом (поддиректорией). Поскольку имена всех объектов, деревьев и блобов, совпадает с SHA хэш-значением их содержимого, то SHA значения двух деревьев будут идентичны только если их содержимое (включая, рекурсивно, содержимое всех поддиректорий) идентично.
Это свойство позволяет git быстро найти отличия между двумя родственными объектами типа дерево, так как git может игнорировать объекты с одинаковыми именами.
Замечание: деревья могут также содержать записи коммитов. Более продробно от этом в секции Подмодули.)
Отметьте для себя, что все файлы имеют права 644 или 755: фактически git обращает внимание только на бит исполнения.
Объекты коммит
Объект «коммит» связывает физическое состояние дерева с описпнием того каким образом мы пришли к этому и почему.

Как вы можете это видеть, коммит определяется:
Объектная модель
Теперь когда мы рассмотрели 3 главных объекта (блоб, дерево и коммит), давайте теперь посмотрим как они объединяются.
Если у нас есть простой проект со след. структурой директории:
И мы выполнили коммит всего этого в репозиторий Git, это будет выглядеть след. образом:
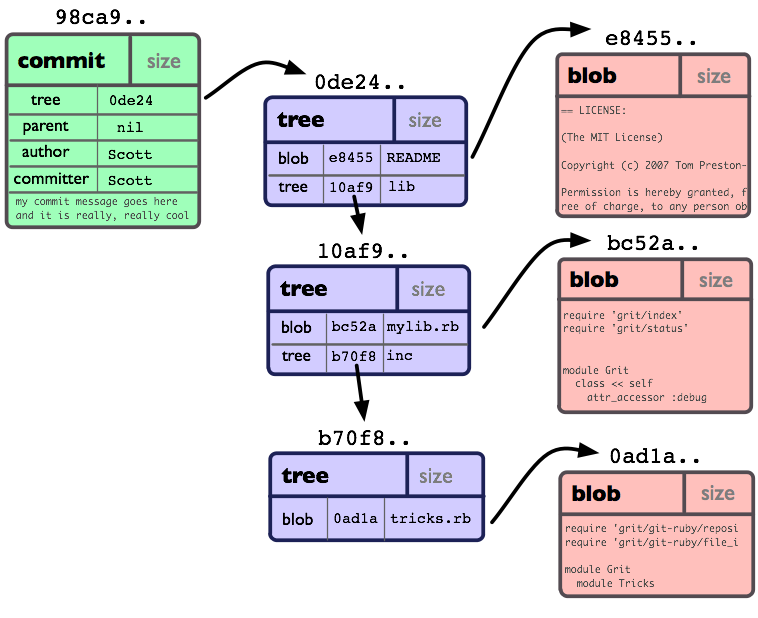
Вы можете видеть что мы создали объект дерево для каждой директории (включая корневую) и объект блоб для каждого файла. Затем, мы имеем объект коммит указывающий на кореневую директорию, и мы можем отследить как наш проект выглядел в момент коммита.
Объект таг
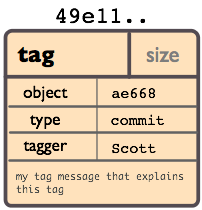
Объект таг содержит имя объекта (называетмого просто ‘объект’), тип объекта, имя тага, или разработчика («таггер») который создал таг, и сообщение, которое может содержить подпись. Это можно увидеть выполнив git cat-file:
Просмотрите документацию команды git tag чтобы изучить как создавать и проверять объекты таг. (Заметьте что git tag может также использоваться чтобы создавать «легковесные таги», которые не являеются объектами таг вообще, это просто ссылки чьи имена начинаются с «refs/tags/»).
Git cat file что это
Setup and Config
Getting and Creating Projects
Basic Snapshotting
Branching and Merging
Sharing and Updating Projects
Inspection and Comparison
Patching
Debugging
External Systems
Server Admin
Guides
Administration
Plumbing Commands
Check your version of git by running
SYNOPSIS
DESCRIPTION
You should work through gittutorial[7] before reading this tutorial.
The goal of this tutorial is to introduce two fundamental pieces of Git’s architecture—the object database and the index file—and to provide the reader with everything necessary to understand the rest of the Git documentation.
The Git object database
Let’s start a new project and create a small amount of history:
What are the 7 digits of hex that Git responded to the commit with?
We saw in part one of the tutorial that commits have names like this. It turns out that every object in the Git history is stored under a 40-digit hex name. That name is the SHA-1 hash of the object’s contents; among other things, this ensures that Git will never store the same data twice (since identical data is given an identical SHA-1 name), and that the contents of a Git object will never change (since that would change the object’s name as well). The 7 char hex strings here are simply the abbreviation of such 40 character long strings. Abbreviations can be used everywhere where the 40 character strings can be used, so long as they are unambiguous.
It is expected that the content of the commit object you created while following the example above generates a different SHA-1 hash than the one shown above because the commit object records the time when it was created and the name of the person performing the commit.
We can ask Git about this particular object with the cat-file command. Don’t copy the 40 hex digits from this example but use those from your own version. Note that you can shorten it to only a few characters to save yourself typing all 40 hex digits:
A tree can refer to one or more «blob» objects, each corresponding to a file. In addition, a tree can also refer to other tree objects, thus creating a directory hierarchy. You can examine the contents of any tree using ls-tree (remember that a long enough initial portion of the SHA-1 will also work):
Thus we see that this tree has one file in it. The SHA-1 hash is a reference to that file’s data:
A «blob» is just file data, which we can also examine with cat-file:
Note that this is the old file data; so the object that Git named in its response to the initial tree was a tree with a snapshot of the directory state that was recorded by the first commit.
All of these objects are stored under their SHA-1 names inside the Git directory:
and the contents of these files is just the compressed data plus a header identifying their length and their type. The type is either a blob, a tree, a commit, or a tag.
The «tree» object here refers to the new state of the tree:
and the «parent» object refers to the previous commit:
The tree object is the tree we examined first, and this commit is unusual in that it lacks any parent.
Most commits have only one parent, but it is also common for a commit to have multiple parents. In that case the commit represents a merge, with the parent references pointing to the heads of the merged branches.
Besides blobs, trees, and commits, the only remaining type of object is a «tag», which we won’t discuss here; refer to git-tag[1] for details.
So now we know how Git uses the object database to represent a project’s history:
«commit» objects refer to «tree» objects representing the snapshot of a directory tree at a particular point in the history, and refer to «parent» commits to show how they’re connected into the project history.
«tree» objects represent the state of a single directory, associating directory names to «blob» objects containing file data and «tree» objects containing subdirectory information.
«blob» objects contain file data without any other structure.
Note, by the way, that lots of commands take a tree as an argument. But as we can see above, a tree can be referred to in many different ways—by the SHA-1 name for that tree, by the name of a commit that refers to the tree, by the name of a branch whose head refers to that tree, etc.—and most such commands can accept any of these names.
In command synopses, the word «tree-ish» is sometimes used to designate such an argument.
The index file
If we look at the way commits are created under the cover, we’ll see that there are more flexible ways creating commits.
Continuing with our test-project, let’s modify file.txt again:
but this time instead of immediately making the commit, let’s take an intermediate step, and ask for diffs along the way to keep track of what’s happening:
The last diff is empty, but no new commits have been made, and the head still doesn’t contain the new line:
So what our git add did was store a new blob and then put a reference to it in the index file. If we modify the file again, we’ll see that the new modifications are reflected in the git diff output:
With the right arguments, git diff can also show us the difference between the working directory and the last commit, or between the index and the last commit:
At any time, we can create a new commit using git commit (without the «-a» option), and verify that the state committed only includes the changes stored in the index file, not the additional change that is still only in our working tree:
So by default git commit uses the index to create the commit, not the working tree; the «-a» option to commit tells it to first update the index with all changes in the working tree.
Finally, it’s worth looking at the effect of git add on the index file:
The effect of the git add was to add one entry to the index file:
And, as you can see with cat-file, this new entry refers to the current contents of the file:
The «status» command is a useful way to get a quick summary of the situation:
Since the current state of closing.txt is cached in the index file, it is listed as «Changes to be committed». Since file.txt has changes in the working directory that aren’t reflected in the index, it is marked «changed but not updated». At this point, running «git commit» would create a commit that added closing.txt (with its new contents), but that didn’t modify file.txt.
Also, note that a bare git diff shows the changes to file.txt, but not the addition of closing.txt, because the version of closing.txt in the index file is identical to the one in the working directory.
In addition to being the staging area for new commits, the index file is also populated from the object database when checking out a branch, and is used to hold the trees involved in a merge operation. See gitcore-tutorial[7] and the relevant man pages for details.
What next?
At this point you should know everything necessary to read the man pages for any of the git commands; one good place to start would be with the commands mentioned in giteveryday[7]. You should be able to find any unknown jargon in gitglossary[7].
The Git User’s Manual provides a more comprehensive introduction to Git.
gitcvs-migration[7] explains how to import a CVS repository into Git, and shows how to use Git in a CVS-like way.
For some interesting examples of Git use, see the howtos.
For Git developers, gitcore-tutorial[7] goes into detail on the lower-level Git mechanisms involved in, for example, creating a new commit.
Git и Github. Простые рецепты
При разработке собственного проекта, рано или поздно, приходится задуматься о том, где хранить исходный код и как поддерживать работу с несколькими версиями. В случае работы на компанию, обычно это решается за вас и необходимо только поддерживать принятые правила. Есть несколько общеупотребимых систем контроля версий, и мы рассмотрим одну из самых популярных — это Git и сервис Github.
Система Git появилась, как средство управления исходными текстами в операционной системе Linux и завоевала множество поклонников в среде Open Source.
Сервис Github предоставляет хостинг (хранение) исходных текстов как на платной, так и на бесплатной основе. Это одна из крупнейших систем, которую любят Open Source пользователи. Основное отличие платной версии — это возможность создания частных репозиториев (хранилищ) исходных текстов и если вам скрывать нечего, то можете спокойно пользоваться бесплатной версией.
После того, как вы начали работу над проектом и написали какой-то работающий прототип, у вас появится желание сохранить результаты работы. Это так же может быть полезно в случае, если вы захотите продолжить работу на другом компьютере. Самое простое решение — это сохранить все на флешке. Этот вариант неплохо работает, но если есть подключение к интернету (а сейчас у кого его нет), то удобно воспользоваться системами Git/Github.
В этой статье будут описаны базовые сценарии использования систем Git/Github при работе над проектом в среде Linux с помощью командной строки. Все примеры проверялись на системе с Linux Ubuntu 14.04 и Git 1.9.1. Если вы пользуетесь другим дистрибутивом, то возможны отличия.
Создание локального репозитория
Предположим, что ваш проект находится в папке /home/user/project. Перед тем, как сохранять исходники, можно посмотреть, нет ли временных файлов в папке с проектом и по возможности их удалить.
Для просмотра папки удобно воспользоваться командой tree, которая покажет не только содержимое каждой папки, но и древовидную структуру директорий.
Часто временные файлы содержат специфические суффиксы, по которым их легко обнаружить и в последствии удалить. Для поиска таких файлов можно воспользоваться командой find. В качестве примера посмотрим, как найти все файлы, которые генерируются компилятором Python и имеют расширение .pyc
Переходим в папку с проектом /home/user/project:
И показываем список файлов с расширением .pyc:
Эта команда выведет список всех файлов с расширением .pyc в текущей директории и в ее поддиректориях. Для удаления найденных файлов, достаточно добавить ключ -delete к этой команде:
Очень рекомендуется не спешить и сразу ключ этот не добавлять. Первый раз вызвать команду для просмотра файлов и только убедившись, что в список не попало ничего полезного добавить ключ удаления.
Создадим локальный репозиторий в папке с проектом:
После выполнения этой команды появится новая папка с именем .git. В ней будет несколько файлов и поддиректориев. На данный момент система управления версиями еще не видит наших файлов.
Добавление файлов в локальный репозиторий
Для добавления файлов используется команда:
После выполнения команды, файл readme будет добавлен в систему управления версий (конечно если он уже был то этого в проекте). При добавлении файла генерируется хеш значение, которое выглядит примерно так:
Добавленные файлы хранятся в папке .git/objects/xx/yyyyyyyy, при этом первые 2 цифры хеша ипользуются для указания директории, а остальное хеш значение является именем файла. Наш добавленный файл будет находится здесь:
Что легко увидеть с помощью команды:
Сам файл является архивом, который легко распаковать и вывести на экран, указав полное значение хеша.
Для того, чтобы добавить все файлы из текущей директории введите:
Если нужно добавить файлы из текущей директории и из всех поддиректориев, то используйте:
Для того, чтобы в систему не попадали временные файлы, можно их занести в файл .gitignore, который нужно создать самостоятельно и разместить в корневом каталоге проекта (на том же уровне, что и .git директория).
Например, если в в файл .gitignore добавить следующую строчку *.pyc, то все файлы с расширением .pyc не будут добавляться в репозиторий.
После добавления файлов, все изменения находятся в так называемой staging (или cached) area. Это некоторое временнное хранилище, которое используется для накопления изменений и из которого создаются собственно версии проектов (commit).
Для просмотра текущего состояния можно воспользоваться командой:
После выполнения команды мы увидим, что в stage area находится наш файл:
Если вы продолжите вносить изменения в файл readme, то после вызова команды git status вы увидите две версии файла.
Чтобы добавить новые изменения достаточно повторить команду. Команда git add не только добавляет новые файлы, но и все изменения файлов, которые были добавлены ранее.
Можно отменить добавления файла readme в staging area с помощью команды:
После выполнения команды, файл readme отметится, как неизмененный системой.
Создание версии проекта
После того, как мы добавили нужные файлы в staging area мы можем создать версию проекта. С помощью команды:
Каждая новая версия сопровождается комментарием.
После коммита, мы сможем найти два новых объекта внутри .git репозитория.
Посмотрим, что внутри:
Ключ -t показывает тип объекта. В результате мы видим:
Для второго объекта:
Для самого первого файла:
Если мы будем дальше изучать содержимое этих файлов, то обнаружим древовидную структуру. От каждого коммита можно по ссылкам пройти по всем измененным файлам. Для практического применения это не очень нужно, но возможно так будет легче понять, что происходит при работе с системой Git.
Самую первую версию отменить нельзя. Ее можно только исправить. Если вы хотите добавить изменения в последнюю версию, то после выполнения команды commit, добавляете необходимые изменения и вызываете:
Ключ —no-edit нужен, чтобы не вводить заново комментарий.
Можно просмотреть изменения, которые вы внесли последним коммитом:
Ключ —name-only нужен, чтобы показывать только имена измененный файлов. Без него по каждому измененнному файлу будет выдан список всех изменений.
Если вы продолжили работать и изменили только те файлы, которые были уже добавлены в систему командой git add, вы можете сделать коммит одной командой:
Для просмотра списка всех коммитов, воспользуйтесь командой:
Ключ —oneline нужен, чтобы уменьшить количество информации выдаваемой на экран. С этим ключем каждый коммит показывается в одну строчку. Например:
Для того, чтобы просмотреть изменения по конкретному коммиту, достаточно в команду git show добавить хеш значение коммита, которое можно получить с помощью предыдущей команды.
Для отмены последнего коммита (кроме самого первого) можно воспользоваться следующей командой:
Для того чтобы удалить все файлы в папке, которые не относятся к проекту и не сохранены в репозитории, можно воспользоваться командой:
Создание репозитория на Github
До текущего момента мы работали с локальным репозиторием, который сохранялся в папке на компьютере. Если мы хотим иметь возможность сохранения проекта в интернете, создадим репозиторий на Github. Для начала нужно зарегистрироваться на сайте github.com под именем myuser (в вашем случае это может быть любое другое имя).
После регистрации нажимаем кнопочку «+» и вводим название репозитория. Выбираем тип Public (репозиторий всегда Public для бесплатной версии) и нажимаем Create.
В результате мы создали репозиторий на сайте Github. На экране мы увидим инструкцию, как соединить наш локальный репозиторий со вновь созданным. Часть команд нам уже знакома.
Добавляем удаленный репозиторий (по протоколу SSH) под именем origin (вместо origin можно использовать любое другое имя).
Можем просмотреть результат добавления с помощью команды:
Если все было правильно сделано, то увидим:
Для того, чтобы отменить регистрацию удаленного репозитария введите:
Это может понадобиться, если вы захотите поменять SSH доступ на HTTPS. После этого можно добавить его опять, например под именем github и протоколом HTTPS.
Следующей командой вы занесете все изменения, которые были сделаны в локальном репозитории на Github.
Ключ -u используется для того, чтобы установить связь между удаленным репозиторием github и вашей веткой master. Все дальнейшие изменения вы можете переносить на удаленный репозиторий упрощенной командой.
Перенос репозитория на другой компьютер
После того, как репозиторий был создан на Github, его можно скопировать на любой другой компьютер. Для этого применяется команда:
Результатом выполнения этой команды будет создание папки project в текущем каталоге. Эта папка также будет содержать локальный репозиторий (то есть папку .git).
Так же можно добавить название папки, в которой вы хотите разместить локальный репозиторий.
Работа с одним репозиторием с разных компьютеров
С одним репозиторием с разных компьютеров может работать несколько разработчиков или вы сами, если например работаете над одним и тем же проектом дома и на работе.
Для получения обновлений с удаленного репозитория воспользуйтесь командой:
Если вы изменили ваши локальные файлы, то команда git pull выдаст ошибку. Если вы уверены, что хотите перезаписать локальные файлы, файлами из удаленного репозитория то выполните команды:
Как мы уже знаем, для того чтобы изменения выложить на удаленный репозиторий используется команда:
В случае, если в удаленном репозитории лежат файлы с версией более новой, чем у вас в локальном, то команда git push выдаст ошибку. Если вы уверены, что хотите перезаписать файлы в удаленном репозитории несмотря на конфликт версий, то воспользуйтесь командой:
Иногда возникает необходимость отложить ваши текущие изменения и поработать над файлами, которые находятся в удаленном репозитории. Для этого отложите текущие изменения командой:
После выполнения этой команды ваша локальная директория будет содержать файлы такие же, как и при последнем коммите. Вы можете загрузить новые файлы из удаленного репозитория командой git pull и после этого вернуть ваши изменения которые вы отложили командой:
Русские Блоги
Git Learning 5 Краткое использование общих команд Git
Эта команда может выполнять операции фиксации для всех локально измененных файлов (включая локальные измененные и удаленные файлы), но не включает файлы, которые не отслеживаются репозиторием.
Дополнительные инструкции для команд git
Показать расположение рабочего места
Отредактируйте глобальный файл конфигурации
Удалите конфигурацию user.name из глобального файла конфигурации
Просмотр конфигурации глобального файла конфигурации user.name
Пустое представление(Если файл в рабочей области не изменен, по умолчанию его нельзя отправить)
Изменить последнюю отправленную информацию
Установить псевдонимы для команд
Просмотр идентификатора отправки, соответствующего ссылке
Просмотр последних локальных и исторических коммитов
Отобразите хеш-значение SHA1, соответствующее ссылке на удаленный репозиторий (источник здесь)
Запретить отправку без ускоренной перемотки вперед
Вывод краткой информации о состоянии
Отследить источник файла README
Переименуйте файл welcome.txt в README
Проверить размер файла рабочего пространства
Посмотреть подробный вывод журнала
Просмотр веток удаленного репозитория



