Основные функции ETL-систем
ETL – аббревиатура от Extract, Transform, Load. Это системы корпоративного класса, которые применяются, чтобы привести к одним справочникам и загрузить в DWH и EPM данные из нескольких разных учетных систем.
Вероятно, большинству интересующихся хорошо знакомы принципы работы ETL, но как таковой статьи, описывающей концепцию ETL без привязки к конкретному продукту, на я Хабре не нашел. Это и послужило поводом написать отдельный текст.
Хочу оговориться, что описание архитектуры отражает мой личный опыт работы с ETL-инструментами и мое личное понимание «нормального» применения ETL – промежуточным слоем между OLTP системами и OLAP системой или корпоративным хранилищем.
Хотя в принципе существуют ETL, который можно поставить между любыми системами, лучше интеграцию между учетными системами решать связкой MDM и ESB. Если же вам для интеграции двух зависимых учетных систем необходим функционал ETL, то это ошибка проектирования, которую надо исправлять доработкой этих систем.
Зачем нужна ETL система
Проблема, из-за которой в принципе родилась необходимость использовать решения ETL, заключается в потребностях бизнеса в получении достоверной отчетности из того бардака, который творится в данных любой ERP-системы.
Как работает ETL система
Все основные функции ETL системы умещаются в следующий процесс:
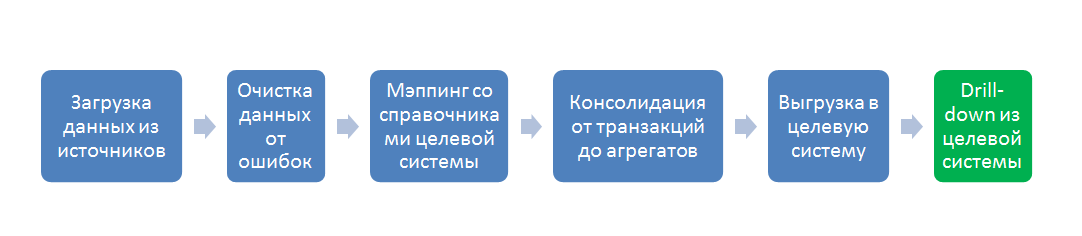
В разрезе потока данных это несколько систем-источников (обычно OLTP) и система приемник (обычно OLAP), а так же пять стадий преобразования между ними:
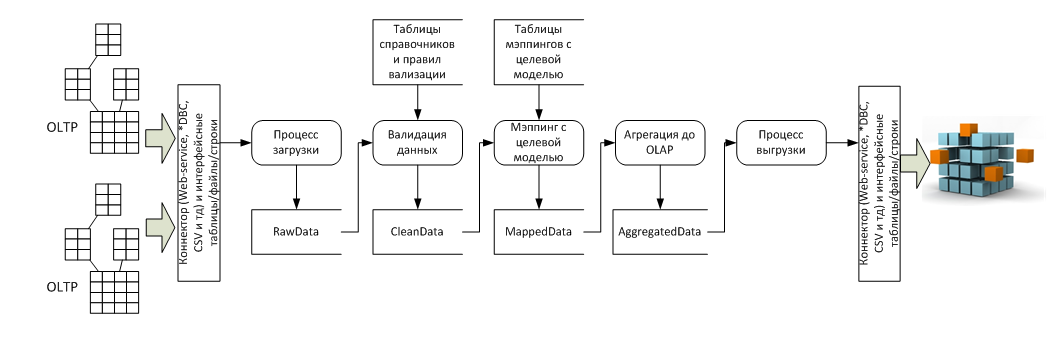
Особенности архитектуры
Реализация процессов 4 и 5 с точки зрения архитектуры тривиальна, все сложности имеют технический характер, а вот реализация процессов 1, 2 и 3 требует дополнительного пояснения.
Процесс загрузки
При проектировании процесса загрузки данных необходимо помнить о том что:
Процесс валидации
Данный процесс отвечает за выявление ошибок и пробелов в данных, переданных в ETL.
Само программирование или настройка формул проверки не вызывает вопросов, главный вопрос – как вычислить возможные виды ошибок в данных, и по каким признакам их идентифицировать?
Возможные виды ошибок в данных зависят от того какого рода шкалы применимы для этих данных. (Ссылка на прекрасный пост, объясняющий, какие существуют виды шкал — http://habrahabr.ru/post/246983/).
Ближе к практике в каждом из передаваемых типов данных в 95% случаев возможны следующие ошибки:
Соответственно проверки на ошибки реализуются либо формулами, либо скриптами в редакторе конкретного ETL-инструмента.
А если вообще по большому счету, то большая часть ваших валидаций будет на соответствие справочников, а это [select * from a where a.field not in (select…) ]
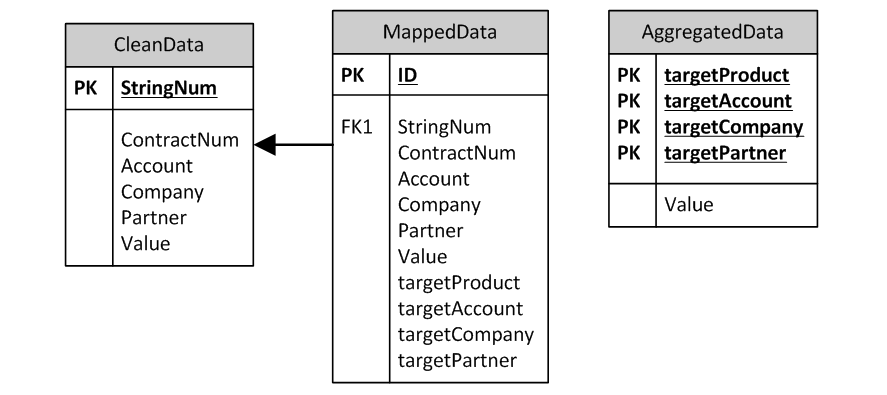
При этом для сохранения аудиторского следа разумно сохранять в системе две отдельные таблицы – rawdata и cleandata с поддержкой связи 1:1 между строками.
Процесс мэппинга
Процесс мэппинга так же реализуется с помощью соответствующих формул и скриптов, есть три хороших правила при его проектировании:
Заключение
В принципе это все архитектурные приемы, которые мне понравились в тех ETL инструментах, которыми я пользовался.
Кроме этого конечно в реальных системах есть еще сервисные процессы — авторизации, разграничения доступа к данным, автоматизированного согласования изменений, и все решения конечно являются компромиссом с требованиями производительности и предельным объемом данных.
ETL: качественные данные для принятия управленческих решений
Организационные изменения, рано или поздно происходящие в жизни любой компании, чаще всего влекут за собой необходимость интеграции различных информационных систем. Для чего нужна интеграция? Она необходима для того, чтобы разные системы могли использовать единое информационное пространство, осуществлять обмен данными, хранить, анализировать и обрабатывать их для последующего принятия управленческих и оперативных решений. Если принимать решения на основании данных, полученных только из одной системы, рано или поздно возникнет хаос, прежде всего по причине разнородного представления и детализации одних и тех же данных в различных системах, наличия ошибок, вызванных человеческим фактором и т.д. Как показывает опыт, наиболее эффективным способом хранения информации для ее последующего анализа и обработки, являются аналитические хранилища с витринами данных, на основе которых пользователь может осуществлять любые аналитические запросы и получать те или иные необходимые показатели.

Интеграционные методы: плюсы и минусы
Существуют различные методы интеграции информационных систем. У каждого из них свои преимущества и недостатки. Так, метод федерализации не предусматривает транспортировку данных, они остаются у владельцев, а доступ к ним осуществляется по запросу. Однако у этого подхода есть и существенные ограничения. Все федеративно распределенные базы, служащие источниками, данных должны находиться в формате одного приложения или СУБД, или требуется специальное ПО для интеграции гетерогенных сред. Кроме того, все источники должны находиться в постоянной доступности, а это не всегда осуществимо. Если обмен данными с одним из источников происходит на низкой скорости, это отразится на работе всего интеграционного механизма. Одновременный обмен данными с двумя различными источниками в момент пользовательского запроса должен осуществляться “на лету”. Это сопряжено с достаточно высокими накладными расходами, поскольку требует загрузки достаточно большого объема информации.
Другой метод интеграции, с применением универсальной шины данных (Universal Serial Bus), также имеет ряд функциональных ограничений. Это, прежде всего, пропускная способность, поскольку шина представляет собой сервис со встроенным механизмом регистрации гарантированной доставки. Если необходимо передать мегабайты данных или осуществить обмен мастер-данными, периодически синхронизировать отдельные документы, то применение универсальной шины будет целесообразно и удобно. Но когда речь идет о постоянном потоке данных, в том числе, генерируемом умными устройствами, пропускной способности шины будет явно недостаточно. К примеру, в реализованном компанией RedSys проекте по развертыванию инфраструктуры для скоростных трамваев в Санкт-Петербурге, с помощью универсальной шины данных осуществляется передача мастер-данных, а также передается информация о сотрудниках из кадровой системы в систему управления движением транспорта.
Свои ограничения накладывает и интеграционный метод на основе репликации. В первую очередь, это требование наличия единой платформы от одного и того же вендора. Для репликации в гетерогенной среде необходимо наличие специального инструментария, выбор которого зависит от используемых в организации СУБД. Разумеется, это не может не отразиться на конечной себестоимости интеграционного проекта.
Мы сегодня живем и работаем в эпоху больших данных, которые генерируют не только информационные системы, с которыми работают люди, но и умные устройства и датчики Интернета вещей, а также множество других неодушевленных машин. Для получения и обработки таких объемов данных лучше всего подходит метод интеграции ETL (Extract, Transform, Load). Он позволяет получать данные, проверять их, унифицировать, сохранять для последующей подготовки на их основе аналитической информации.
В механизме ETL-интеграции источник данных может выступать как в качестве клиента, так и в качестве сервера. Во втором случае целесообразным будет применение модулей извлечения измененных данных CDC (Change Data Capture). В тех случаях, когда источник данных одновременно занят решением других задач, либо с ним работают пользователи, использование CDC позволяет избежать дополнительных нагрузок. Источник данных может быть назначен и в качестве клиента. В этом случае система, которая служит источником данных сама переводит данные в CSV, XML или другой универсальный промышленный формат, а ETL периодически забирает эти файлы для дальнейшей обработки.
Метод ETL-интеграции характеризуется глубоким преобразованием данных. Она осуществляется в хранилище данных, которое включает в себя, в классической модели, три слоя. Первый слой представляет собой копии источников данных с добавлением специальных ключей, обеспечивающих уникальность и историчность информации. Второй слой отвечает за логическую обработку и унификацию. Он формирует из данных объектную модель в аналитическом разрезе. Третий слой осуществляет загрузку витрин данных для анализа, с приведением всех показателей к нужным разрезам, всеми необходимыми расчетами и т.д.
Когда речь идет о нескольких обширных несинхронизированных источниках данных, разрозненных справочниках НСИ, эти данные необходимо привести в унифицированный вид. Здесь на помощь приходят MDM-системы. В разветвленных холдинговых структурах, где могут работать десятки систем от различных производителей, без MDM порой очень сложно, например, подсчитать доходы и расходы по тем или иным статьям доходов и расходов. Некачественные данные способны существенно сузить ценность BI-информации, на основании анализа которой принимаются управленческие решения. Для дальнейшей поддержки качества данных необходима связь с источником, благодаря которой можно было бы передавать информацию для исправления. Также может быть сформирована специальная витрина или “корзина” низкокачественных данных, которые были по тем или иным причинам отвергнуты. Обнаружить такие данные помогают механизмы ETL.
Инструментарий и специалисты
Что касается инструментов для ETL-интеграции, то здесь достаточно широкое поле для выбора. Существуют как специализированные решения для конкретных СУБД, разработанные чаще всего их же разработчиками (Oracle Data Integrator, IBM DataStage, Informatica PC, Integration Services (SSIS) в составе MS SQL Server), а есть универсальные продукты. Лидером “магического квадранта” Gartner в сегменте решений для ETL-интеграции считается компания Informatica с ее продуктами. Все это системы промышленного уровня, которые умеют динамически распределять нагрузку между источниками и BI-хранилищем, поддерживают параллелизм выполнения операций и обладают целым рядом других функций. Как правило, платформа хранилища данных у заказчика уже определена, поэтому целесообразно будет использовать ETL-решение от разработчика платформы, используемой в хранилище. Решения компании Informatica весьма дорогостоящие, однако по техническим возможностям они же и являются наиболее продвинутыми, наиболее производительными и масштабируемыми. Их можно применять интегрировать с хранилищем данных на любой платформе.
В основе реализованного компанией RedSys проекта по построению хранилища данных в Пенсионном Фонде РФ лежат решения компании IBM, а в качестве ETL-инструментария используется IBM DataStage. Для поддержки интеграционных ETL-проектов в организации необходимо наличие трех категорий специалистов: архитекторов, в чьи обязанности входит проектирование хранилища данных; аналитики, как бизнес, так и системные, компетенции которых заключаются в сборе данных и требований бизнеса, составлении спецификаций, а также программисты, занимающиеся отладкой ETL-процессов.
Выгоды для бизнеса
Что дает ETL-интеграция бизнесу? Выгоду можно охарактеризовать двумя словами: “дорого, но эффективно”. Конечно, это весьма затратная составляющая комплексного проекта по построению аналитического хранилища данных. Поэтому все преимущества нужно рассматривать именно в разрезе наличия или отсутствия единого BI-хранилища в компании. Его отсутствие ведет к тому, что бизнес просто не получит оперативно ответы на стратегически важные вопросы. Единый взгляд на картину производства и продажи продуктов и услуг, их доходность и себестоимость, позволяет, в том числе минимизировать разногласия между производственными и финансовыми подразделениями компании, а в случае необходимости — перераспределить ресурсы в пользу более выгодных и эффективных направлений. Нельзя забывать и о снижении затрат. Вместо отдельных департаментов и сотрудников, собирающих данные в рамках своих бизнес-единиц, данные собираются в автоматизированном режиме и гораздо быстрее, при этом их качество несравнимо выше. Наконец, использование ETL-интеграции позволяет заказчику сосредоточить усилия на организационной, а не технической составляющей BI-проекта.
Введение в Data Engineering. ETL, схема «звезды» и Airflow
Способность data scientist-а извлекать ценность из данных тесно связана с тем, насколько развита инфраструктура хранения и обработки данных в компании. Это значит, что аналитик должен не только уметь строить модели, но и обладать достаточными навыками в области data engineering, чтобы соответствовать потребностям компании и браться за все более амбициозные проекты.
При этом, несмотря на всю важность, образование в сфере data engineering продолжает оставаться весьма ограниченным. Мне повезло, поскольку я успел поработать со многими инженерами, которые терпеливо объясняли мне каждый аспект работы с данными, но не все обладают такой возможностью. Именно поэтому я решил написать эту статью — введение в data engineering, в которой я расскажу о том, что такое ETL, разнице между SQL- и JVM-ориентированными ETL, нормализации и партиционировании данных и, наконец, рассмотрим пример запроса в Airflow.
Data Engineering
Maxime Beauchemin, один из разработчиков Airflow, так охарактеризовал data engineering: «Это область, которую можно рассматривать как смесь бизнес-аналитики и баз данных, которая привносит больше элементов программирования. Эта сфера включает в себя специализацию по работе с распределенными системами больших данных, расширенной экосистемой Hadoop и масштабируемыми вычислениями».
Среди множества навыков инженера данных можно выделить один, который является наиболее важным — способность разрабатывать, строить и поддерживать хранилища данных. Отсутствие качественной инфраструктуры хранения данных приводит к тому, что любая активность, связанная с анализом данных, либо слишком дорога, либо немасштабируема.
ETL: Extract, Transform, Load
Extract, Transform и Load — это 3 концептуально важных шага, определяющих, каким образом устроены большинство современных пайплайнов данных. На сегодняшний день это базовая модель того, как сырые данные сделать готовыми для анализа.
Extract. Это шаг, на котором датчики принимают на вход данные из различных источников (логов пользователей, копии реляционной БД, внешнего набора данных и т.д.), а затем передают их дальше для последующих преобразований.
Transform. Это «сердце» любого ETL, этап, когда мы применяем бизнес-логику и делаем фильтрацию, группировку и агрегирование, чтобы преобразовать сырые данные в готовый к анализу датасет. Эта процедура требует понимания бизнес задач и наличия базовых знаний в области.
Load. Наконец, мы загружаем обработанные данные и отправляем их в место конечного использования. Полученный набор данных может быть использован конечными пользователями, а может являться входным потоком к еще одному ETL.
Какой ETL-фреймворк выбрать?
В мире batch-обработки данных есть несколько платформ с открытым исходным кодом, с которыми можно попробовать поиграть. Некоторые из них: Azkaban — open-source воркфлоу менеджер от Linkedin, особенностью которого является облегченное управление зависимостями в Hadoop, Luigi — фреймворк от Spotify, базирующийся на Python и Airflow, который также основан на Python, от Airbnb.
У каждой платформы есть свои плюсы и минусы, многие эксперты пытаются их сравнивать (смотрите тут и тут). Выбирая тот или иной фреймворк, важно учитывать следующие характеристики:
Конфигурация. ETL-ы по своей природе довольно сложны, поэтому важно, как именно пользователь фреймворка будет их конструировать. Основан ли он на пользовательском интерфейсе или же запросы создаются на каком-либо языке программирования? Сегодня все большую популярность набирает именно второй способ, поскольку программирование пайплайнов делает их более гибкими, позволяя изменять любую деталь.
Мониторинг ошибок и оповещения. Объемные и долгие batch запросы рано или поздно падают с ошибкой, даже если в самой джобе багов нет. Как следствие, мониторинг и оповещения об ошибках выходят на первый план. Насколько хорошо фреймворк визуализирует прогресс запроса? Приходят ли оповещения вовремя?
Обратное заполнение данных (backfilling). Часто после построения готового пайплайна нам требуется вернуться назад и заново обработать исторические данных. В идеале нам бы не хотелось строить две независимые джобы: одну для обратного а исторических данных, а вторую для текущей деятельности. Насколько легко осуществлять backfilling c помощью данного фреймворка? Масштабируемо и эффективно ли полученное решение?
2 парадигмы: SQL против JVM
Как мы выяснили, у компаний есть огромный выбор того, какие инструменты использовать для ETL, и для начинающего data scientist-а не всегда понятно, какому именно фреймворку посвятить время. Это как раз про меня: в Washington Post Labs очередность джобов осуществлялась примитивно, с помощью Cron, в Twitter ETL джобы строились в Pig, а сейчас в Airbnb мы пишем пайплайны в Hive через Airflow. Поэтому перед тем, как пойти в ту или иную компанию, постарайтесь узнать, как именно организованы ETL в них. Упрощенно, можно выделить две основные парадигмы: SQL и JVM-ориентированные ETL.
JVM-ориентированные ETL обычно написаны на JVM-ориентированном языке (Java или Scala). Построение пайплайнов данных на таких языках означает задавать преобразования данных через пары «ключ-значение», однако писать пользовательские функции и тестировать джобы становится легче, поскольку не требуется использовать для этого другой язык программирования. Эта парадигма весьма популярна среди инженеров.
SQL-ориентированные ETL чаще всего пишутся на SQL, Presto или Hive. В них почти все крутится вокруг SQL и таблиц, что весьма удобно. В то же время написание пользовательских функций может быть проблематично, поскольку требует использования другого языка (к примеру, Java или Python). Такой подход популярен среди data scientist-ов.
Поработав с обеими парадигмами, я все-таки предпочитаю SQL-ориентированные ETL, поскольку, будучи начинающим data scientist-ом, намного легче выучить SQL, чем Java или Scala (если, конечно, вы еще с ними не знакомы) и сконцентрироваться на изучении новых практик, чем накладывать это поверх изучения нового языка.
Моделирование данных, нормализация и схема «звезды»
В процессе построения качественной аналитической платформы, главная цель дизайнера системы — сделать так, чтобы аналитические запросы было легко писать, а различные статистики считались эффективно. Для этого в первую очередь нужно определить модель данных.
В качестве одного из первых этапов моделирования данных необходимо понять, в какой степени таблицы должны быть нормализованы. В общем случае нормализованные таблицы отличаются более простыми схемами, более стандартизированными данными, а также исключают некоторые типы избыточности. В то же время использование таких таблиц приводит к тому, что для установления взаимоотношений между таблицами требуется больше аккуратности и усердия, запросы становятся сложнее (больше JOIN-ов), а также требуется поддерживать больше ETL джобов.
С другой стороны, гораздо легче писать запросы к денормализованным таблицам, поскольку все измерения и метрики уже соединены. Однако, учитывая больший размер таблиц, обработка данных становится медленнее (“Тут можно поспорить, ведь все зависит от того, как хранятся данные и какие запросы бывают. Можно, к примеру, хранить большие таблицы в Hbase и обращаться к отдельным колонкам, тогда запросы будут быстрыми” — прим. пер.).
Среди всех моделей данных, которые пытаются найти идеальный баланс между двумя подходами, одной из наиболее популярных (мы используем ее в Airbnb) является схема «звезды». Данная схема основана на построении нормализованных таблиц (таблиц фактов и таблиц измерений), из которых, в случае чего, могут быть получены денормализованные таблицы. В результате такой дизайн пытается найти баланс между легкостью аналитики и сложностью поддержки ETL.
Таблицы фактов и таблицы измерений
Чтобы лучше понять, как строить денормализованные таблицы из таблиц фактов и таблиц измерений, обсудим роли каждой из них:
Таблицы фактов чаще всего содержат транзакционные данные в определенные моменты времени. Каждая строка в таблице может быть чрезвычайно простой и чаще всего является одной транзакцией. У нас в Airbnb есть множество таблиц фактов, которые хранят данные по типу транзакций: бронирования, оформления заказов, отмены и т.д.
Таблицы измерений содержат медленно меняющиеся атрибуты определенных ключей из таблицы фактов, и их можно соединить с ней по этим ключам. Сами атрибуты могут быть организованы в рамках иерархической структуры. В Airbnb, к примеру, есть таблицы измерений с пользователями, заказами и рынками, которые помогают нам детально анализировать данные.
Ниже представлен простой пример того, как таблицы фактов и таблицы измерений (нормализованные) могут быть соединены, чтобы ответить на простой вопрос: сколько бронирований было сделано за последнюю неделю по каждому из рынков?
Партиционирование данных по временной метке
Сейчас, когда стоимость хранения данных очень мала, компании могут себе позволить хранить исторические данные в своих хранилищах, вместо того, чтобы выбрасывать. Обратная сторона такого тренда в том, что с накоплением количества данных аналитические запросы становятся неэффективными и медленными. Наряду с такими принципами SQL как «фильтровать данные чаще и раньше» и «использовать только те поля, которые нужны», можно выделить еще один, позволяющий увеличить эффективность запросов: партиционирование данных.
Основная идея партиционирования весьма проста — вместо того, чтобы хранить данные одним куском, разделим их на несколько независимых частей. Все части сохраняют первичный ключ из исходного куска, поэтому получить доступ к любым данным можно достаточно быстро.
В частности, использование временной метки в качестве ключа, по которому проходит партиционирование, имеет ряд преимуществ. Во-первых, в хранилищах типа S3 сырые данные часто сортированы по временной метке и хранятся в директориях, также отмеченных метками. Во-вторых, обычно batch-ETL джоб проходит примерно за один день, то есть новые партиции данных создаются каждый день для каждого джоба. Наконец, многие аналитические запросы включают в себя подсчет количества событий, произошедших за определенный временной промежуток, поэтому партиционирование по времени здесь очень кстати.
Обратное заполнение (backfilling) исторических данных
Еще одно важное преимущество использования временной метки в качестве ключа партиционирования — легкость обратного заполнения данных. Если ETL-пайплайн уже построен, то он рассчитывает метрики и измерения наперед, а не ретроспективно. Часто нам бы хотелось посмотреть на сложившиеся тренды путем расчета измерений в прошлом — этот процесс и называется backfilling.
Backfilling настолько распространен, что в Hive есть встроенная возможность динамического партиционирования, чтобы выполнять одни и те же SQL запросы по нескольким партициям сразу. Проиллюстрируем эту идею на примере: пусть требуется заполнить количество бронирований по каждому рынку для дашборда, начиная с earliest_ds и заканчивая latest_ds. Одно из возможных решений выглядит примерно так:
Такой запрос возможен, однако он слишком громоздкий, поскольку мы выполняем одну и ту же операцию, только над разными партициями. Используя динамическое партиционирование мы можем все упростить до одного запроса:
Отметим, что мы добавили ds в SELECT и GROUP BY выражения, расширили диапазон в операции WHERE и изменили синтаксис с PARTITION (ds= ‘<
Теперь, рассмотрим все изученные концепции на примере ETL джобы в Airflow.
Направленный ациклический граф (DAG)
Казалось бы, с точки зрения идеи ETL джобы очень просты, однако на деле они часто очень запутаны и состоят из множества комбинаций Extract, Transform и Load операций. В этом случае очень полезно бывает визуализировать весь поток данных, используя граф, в котором узел отображает операцию, а стрелка — взаимосвязь между операциями. Учитывая, что каждая операция выполняется единожды, а данные идут дальше по графу, то он является направленным и ациклическим, отсюда и название.
Одна из особенностей интерфейса Airflow — это наличие механизма, который позволяет визуализировать пайплайн данных через DAG. Автор пайплайна должен задать взаимосвязи между операциями, чтобы Airflow записал спецификацию ETL джоба в отдельный файл.
При этом помимо DAG-ов, которые определяют порядок запуска операций, в Airflow есть операторы, которые задают, что необходимо выполнить в рамках пайплайна. Обычно есть 3 вида операторов, каждый из которых имитирует один из этапов ETL-процесса:
Простой пример
Ниже представлен простой пример того, как объявить DAG-файл и определить структуру графа, используя операторы в Airflow, которые мы обсудили выше:
Когда граф будет построен, можно увидеть следующую картинку:
Итак, надеюсь, что в данной статье мне удалось максимально быстро и эффективно погрузить вас в интересную и многообразную сферу — Data Engineering. Мы изучили, что такое ETL, преимущества и недостатки различных ETL-платформ. Затем обсудили моделирование данных и схему «звезды», в частности, а также рассмотрели отличия таблиц фактов от таблиц измерений. Наконец, рассмотрев такие концепции как партиционирование данных и backfilling, мы перешли к примеру небольшого ETL джоба в Airflow. Теперь вы можете самостоятельно изучать работу с данными, наращивая багаж своих знаний. Еще увидимся!
Роберт отмечает недостаточное количество программ по data engineering в мире, однако мы таковую проводим, и уже не в первый раз. В октябре у нас стартует Data Engineer 3.0, регистрируйтесь и расширяйте свои профессиональные возможности!



