Введение
Что такое Объектная Модель Документа (DOM)?
Объектная Модель Документа (DOM) – это программный интерфейс (API) для HTML и XML документов. DOM предоставляет структурированное представление документа и определяет то, как эта структура может быть доступна из программ, которые могут изменять содержимое, стиль и структуру документа. Представление DOM состоит из структурированной группы узлов и объектов, которые имеют свойства и методы. По существу, DOM соединяет веб-страницу с языками описания сценариев либо языками программирования.
Веб-страница – это документ. Документ может быть представлен как в окне браузера, так и в самом HTML-коде. В любом случае, это один и тот же документ. DOM предоставляет другой способ представления, хранения и управления этого документа. DOM полностью поддерживает объектно-ориентированное представление веб-страницы, делая возможным её изменение при помощи языка описания сценариев наподобие JavaScript.
Стандарты W3C DOM и WHATWG DOM формируют основы DOM, реализованные в большинстве современных браузеров. Многие браузеры предлагают расширения за пределами данного стандарта, поэтому необходимо проверять работоспособность тех или иных возможностей DOM для каждого конкретного браузера.
Например: стандарт DOM описывает, что метод getElementsByTagName в коде, указанном ниже, должен возвращать список всех элементов
DOM и JavaScript
Вначале JavaScript и DOM были тесно связаны, но впоследствии они развились в различные сущности. Содержимое страницы хранится в DOM и может быть доступно и изменяться с использованием JavaScript, поэтому мы можем записать это в виде приблизительного равенства:
API (веб либо XML страница) = DOM + JS (язык описания скриптов)
DOM спроектирован таким образом, чтобы быть независимым от любого конкретного языка программирования, обеспечивая структурное представление документа согласно единому и последовательному API. Хотя мы всецело сфокусированы на JavaScript в этой справочной документации, реализация DOM может быть построена для любого языка, как в следующем примере на Python:
Для подробной информации о том, какие технологии участвуют в написании JavaScript для веб, смотрите обзорную статью JavaScript technologies overview.
Каким образом доступен DOM?
Вы не должны делать ничего особенного для работы с DOM. Различные браузеры имеют различную реализацию DOM, эти реализации показывают различную степень соответствия с действительным стандартом DOM (это тема, которую мы пытались не затрагивать в данной документации), но каждый браузер использует свой DOM, чтобы сделать веб страницы доступными для взаимодействия с языками сценариев.
При создании сценария с использованием элемента
Что такое DOM и зачем он нужен?

На этом уроке мы рассмотрим, что такое DOM, зачем он нужен, а также то, как он строится.
Что такое DOM

DOM – это объектная модель документа, которую браузер создаёт в памяти компьютера на основании HTML-кода, полученного им от сервера.
Если сказать по-простому, то HTML-код – это текст страницы, а DOM – это набор связанных объектов, созданных браузером при парсинге её текста.
В Chrome исходный код страницы, который получает браузер, можно посмотреть во вкладке «Source» на панели «Инструменты веб-разработчика».

В Chrome инструмента, с помощью которого можно было бы посмотреть созданное им DOM-дерево нет. Но есть представление этого DOM-дерева в виде HTML-кода, оно доступно на вкладке «Elements». С таким представлением DOM веб-разработчику, конечно, намного удобнее работать. Поэтому инструмента, который DOM представлял бы в виде древовидной структуры нет.

Для работы с DOM в большинстве случаев используется JavaScript, т.к. на сегодняшний день это единственный язык программирования, скрипты на котором могут выполняться в браузере.
Зачем нам нужен DOM API? Он нам нужен для того, чтобы мы могли с помощью JavaScript изменять страницу на «лету», т.е. делать её динамической и интерактивной.
DOM API предоставляет нам (разработчикам) огромное количество методов, с помощью которых мы можем менять всё что есть на странице, а также взаимодействовать с пользователем. Т.е. данный программный интерфейс позволяет нам создавать сложные интерфейсы, формы, выполнять обработку действий пользователей, добавлять и удалять различные элементы на странице, изменять их содержимое, свойства (атрибуты), и многое другое.
Сейчас в вебе практически нет сайтов в сценариях которых отсутствовала бы работа с DOM.
Из чего состоит HTML-код страницы
Перед тем, как перейти к изучению объектной модели документа необходимо сначала вспомнить, что из себя представляет исходный код веб-страницы (HTML-документа).
Исходный код веб-страницы состоит из тегов, атрибутов, комментариев и текста. Теги — это базовая синтаксическая конструкция HTML. Большинство из них являются парными. В этом случае один из них является открывающим, а другой – закрывающим. Одна такая пара тегов образует HTML-элемент. HTML-элементы могут иметь дополнительные параметры – атрибуты.
В документе для создания определённой разметки одни элементы находятся внутри других. В результате HTML-документ можно представить как множество вложенных друг в друга HTML-элементов.
В качестве примера рассмотрим следующий HTML код:
Теперь рассмотрим, как браузер на основании HTML-кода строит DOM-дерево.
Как строится DOM-дерево документа
Как уже было описано выше браузер строит дерево на основе HTML-элементов и других сущностей исходного кода страницы. При выполнении этого процесса он учитывает вложенность элементов друг в друга.
В результате браузер полученное DOM-дерево использует не только в своей работе, но также предоставляет нам API для удобной работы с ним через JavaScript.
При строительстве DOM браузер создаёт из HTML-элементов, текста, комментариев и других сущностей этого языка объекты (узлы DOM-дерева).
В большинстве случаев веб-разработчиков интересуют только объекты (узлы), образованные из HTML-элементов.
При этом браузер не просто создаёт объекты из HTML-элементов, а также связывает их между собой определёнными связями в зависимости от того, как каждый из них относится к другому в коде.
Элементы, которые находятся непосредственно в некотором элементе являются по отношению к нему детьми. А он для каждого из них является родителем. Кроме этого, все эти элементы по отношению друг к другу являются сиблингами (братьями).
Чтобы получить DOM-дерево так как его строит браузер, необходимо просто «выстроить» все элементы в зависимости от их отношения друг к другу.
Создание DOM-дерева выполняется сверху вниз.
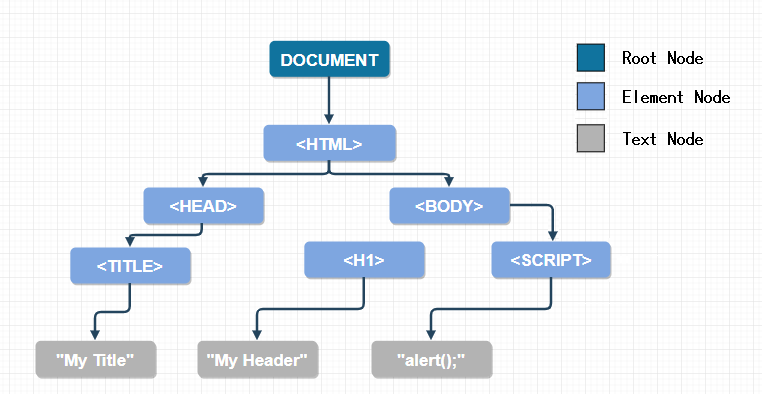
При этом корнем DOM-дерева всегда является сам документ (узел document ). Далее дерево строится в зависимости от структуры HTML кода.
Например, HTML-код, который мы рассматривали выше будет иметь следующее DOM-дерево:

Форум
Справочник
Введение. DOM в примерах.
Простейший DOM
Построим, для начала, дерево DOM для следующего документа.
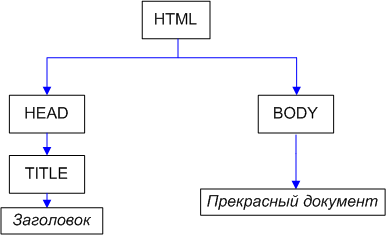
Пример посложнее
Рассмотрим теперь более жизненную страничку:

А вот так выглядит дерево, если изобразить его прямо на HTML-страничке:
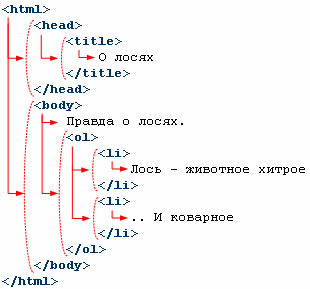
Кстати, дерево на этом рисунке не учитывает текст, состоящий из одних пробельных символов. Например, такой текстовый узел должен идти сразу после
- . DOM, не содержащий таких «пустых» узлов, называют «нормализованным».
Пример с атрибутами и DOCTYPE
Рассмотрим чуть более сложный документ.

Однако, в веб-программировании в эти дебри обычно не лезут, и считают атрибуты просто свойствами DOM-узла, которые, как мы увидим в дальнейшем, можно устанавливать и менять по желанию программиста.
Вообще-то это секрет, но DOCTYPE тоже является DOM-узлом, и находится в дереве DOM слева от HTML (на рисунке этот факт скрыт).
Нормализация в различных браузерах
При разборе HTML Internet Explorer сразу создает нормализованный DOM, в котором не создаются узлы из пустого текста.
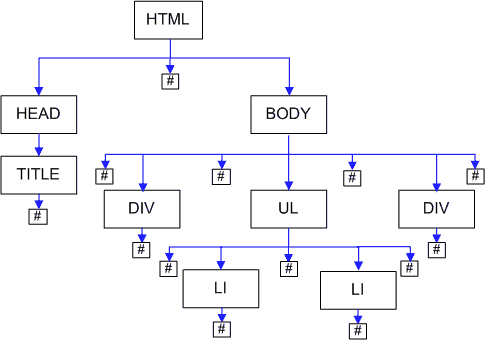
На рисунке для краткости текстовые узлы обозначены просто решеткой. У body вместо 3 появилось 7 детей.
Opera тоже имеет чем похвастаться. Она может добавить лишний пустой элемент «просто от себя».
У меня получается 3 для IE, 7 для Firefox и 8 (!?) для Opera.
На практике эта несовместимость не создает больших проблем, но нужно о ней помнить. Например, разница может проявить себя в случае перебора узлов дерева.
Возможности, которые дает DOM
Зачем, кроме красивых рисунков, нужна иерархическая модель DOM?
Каждый DOM-элемент является объектом и предоставляет свойства для манипуляции своим содержимым, для доступа к родителям и потомкам.
В современных скриптах этот метод почти не используется, случаи его правильного применения можно пересчитать по пальцам.
Разберем подробнее способы доступа и свойства элементов DOM.
Доступ к элементам
Начнем с вершины дерева.
document.documentElement
document.body
Типы DOM-элементов
У каждого элемента в DOM-модели есть тип. Его номер хранится в атрибуте elem.nodeType
Всего в DOM различают 12 типов элементов.
Остальные типы в javascript программировании не используются.
Пример
Например, вот так выглядел бы в браузере документ из примера выше, если каждый видимый элемент обвести рамкой с цифрой nodeType в правом верхнем углу.

Дочерние элементы


Этих свойств вполне хватает для удобного обращения к соседям.
Свойства элементов
Рассмотрим здесь еще некоторые (не все) свойства элементов, полезные при работе с DOM.
tagName
Атрибут есть у элементов-тегов и содержит имя тега в верхнем регистре, только для чтения.
style
Это свойство управляет стилем. Оно аналогично установке стиля в CSS.
Например, можно установить element.style.width :
Исходный код этой кнопки:
Например, для установки свойства z-index в 1000, нужно поставить:
innerHTML
Когда-то это свойство поддерживалось только в IE. Теперь его поддерживают все современные браузеры.
Оно содержит весь HTML-код внутри узла, и его можно менять.
Свойство innerHTML применяется, в основном, для динамического изменения содержания страницы, например:
className
Это свойство задает класс элемента. Оно полностью аналогично html-атрибуту «class».
Шпаргалка по JS-методам для работы с DOM

Основные источники
Введение
JavaScript предоставляет множество методов для работы с Document Object Model или сокращенно DOM (объектной моделью документа): одни из них являются более полезными, чем другие; одни используются часто, другие почти никогда; одни являются относительно новыми, другие признаны устаревшими.
Я постараюсь дать вам исчерпывающее представление об этих методах, а также покажу парочку полезных приемов, которые сделают вашу жизнь веб-разработчика немного легче.
Размышляя над подачей материала, я пришел к выводу, что оптимальным будет следование спецификациям с промежуточными и заключительными выводами, сопряженными с небольшими лирическими отступлениями.
Сильно погружаться в теорию мы не будем. Вместо этого, мы сосредоточимся на практической составляющей.
Для того, чтобы получить максимальную пользу от данной шпаргалки, пишите код вместе со мной и внимательно следите за тем, что происходит в консоли инструментов разработчика и на странице.
Вот как будет выглядеть наша начальная разметка:
У нас есть список ( ul ) с тремя элементами ( li ). Список и каждый элемент имеют идентификатор ( id ) и CSS-класс ( class ). id и class — это атрибуты элемента. Существует множество других атрибутов: одни из них являются глобальными, т.е. могут добавляться к любому элементу, другие — локальными, т.е. могут добавляться только к определенным элементам.
Мы часто будем выводить данные в консоль, поэтому создадим такую «утилиту»:
Миксин NonElementParentNode
Данный миксин предназначен для обработки (браузером) родительских узлов, которые не являются элементами.
В чем разница между узлами (nodes) и элементами (elements)? Если кратко, то «узлы» — это более общее понятие, чем «элементы». Узел может быть представлен элементом, текстом, комментарием и т.д. Элемент — это узел, представленный разметкой (HTML-тегами (открывающим и закрывающим) или, соответственно, одним тегом).
Небольшая оговорка: разумеется, мы могли бы создать список и элементы программным способом.
Для создания элементов используется метод createElement(tag) объекта Document :
Одним из основных способов получения элемента (точнее, ссылки на элемент) является метод getElementById(id) объекта Document :
Почему идентификаторы должны быть уникальными в пределах приложения (страницы)? Потому что элемент с id становится значением одноименного свойства глобального объекта window :
Миксин ParentNode
Данный миксин предназначен для обработки родительских элементов (предков), т.е. элементов, содержащих одного и более потомка (дочерних элементов).
Такая структура называется коллекцией HTML и представляет собой массивоподобный объект (псевдомассив). Существует еще одна похожая структура — список узлов (NodeList ).
Для дальнейших манипуляций нам потребуется периодически создавать новые элементы, поэтому создадим еще одну утилиту:
Наша утилита принимает 4 аргумента: идентификатор, текст, название тега и CSS-класс. 2 аргумента (тег и класс) имеют значения по умолчанию. Функция возвращает готовый к работе элемент. Впоследствии, мы реализуем более универсальный вариант данной утилиты.
Одной из интересных особенностей HTMLCollection является то, что она является «живой», т.е. элементы, возвращаемые по ссылке, и их количество обновляются автоматически. Однако, эту особенность нельзя использовать, например, для автоматического добавления обработчиков событий.
Создадим универсальную утилиту для получения элементов:
Наша утилита принимает 3 аргумента: CSS-селектор, родительский элемент и индикатор количества элементов (один или все). 2 аргумента (предок и индикатор) имеют значения по умолчанию. Функция возвращает либо один, либо все элементы (в виде обычного массива), совпадающие с селектором, в зависимости от значения индикатора:
Миксин NonDocumentTypeChildNode
Миксин ChildNode
Данный миксин предназначен для обработки дочерних элементов, т.е. элементов, являющихся потомками других элементов.
Интерфейс Node
Данный интерфейс предназначен для обработки узлов.
Интерфейс Document
Фрагменты позволяют избежать создания лишних элементов. Они часто используются при работе с разметкой, скрытой от пользователя с помощью тега template (метод cloneNode() возвращает DocumentFragment ).
createTextNode(data) — создает текст
createComment(data) — создает комментарий
importNode(existingNode, deep) — создает новый узел на основе существующего
Интерфейсы NodeIterator и TreeWalker
Интерфейсы NodeIterator и TreeWalker предназначены для обхода (traverse) деревьев узлов. Я не сталкивался с примерами их практического использования, поэтому ограничусь парочкой примеров:
Интерфейс Element
Данный интерфейс предназначен для обработки элементов.
Работа с classList
Работа с атрибутами
insertAdjacentElement(where, newElement) — универсальный метод для вставки новых элементов перед/в начало/в конец/после текущего элемента. Аргумент where определяет место вставки. Возможные значения:
insertAdjacentText(where, data) — универсальный метод для вставки текста
Text — конструктор для создания текста
Comment — конструктор для создания комментария
Объект Document
Свойства объекта location :
reload() — перезагружает текущую локацию
replace() — заменяет текущую локацию на новую
title — заголовок документа
head — метаданные документа
body — тело документа
images — псевдомассив ( HTMLCollection ), содержащий все изображения, имеющиеся в документе
Следующие методы и свойство считаются устаревшими:
Миксин InnerHTML
Геттер/сеттер innerHTML позволяет извлекать/записывать разметку в элемент. Для подготовки разметки удобно пользоваться шаблонными литералами:
Расширения интерфейса Element
Вот несколько полезных ссылок, с которых можно начать изучение этих замечательных инструментов:
Иногда требуется создать элемент на основе шаблонной строки. Как это можно сделать? Вот соответствующая утилита:
Существует более экзотический способ создания элемента на основе шаблонной строки. Он предполагает использование конструктора DOMParser() :
Еще более экзотический, но при этом самый короткий способ предполагает использование расширения для объекта Range — метода createContextualFragment() :
В завершение, как и обещал, универсальная утилита для создания элементов:
Заключение
Разумеется, шпаргалка — это всего лишь карманный справочник, памятка для быстрого восстановления забытого материала, предполагающая наличие определенного багажа знаний.
VDS от Маклауд быстрые и безопасные.
Зарегистрируйтесь по ссылке выше или кликнув на баннер и получите 10% скидку на первый месяц аренды сервера любой конфигурации!
Основы JavaScript: Изучаем работу с DOM! (Часть 1)
Дата публикации: 2019-03-22

От автора: объектная модель документа, или «DOM», определяет логическую структуру документов HTML и по существу выступает в качестве интерфейса для веб-страниц. Благодаря использованию языков программирования, таких как JavaScript, мы можем получить доступ к DOM, чтобы управлять веб-сайтами и делать их интерактивными.
В этой статье мы рассмотрим объект document, дерево DOM и узлы. Мы также узнаем все о том, как получить доступ к элементам и, в целом, как происходит работа с DOM JavaScript. Давайте начнем!
Что такое DOM?
По своей сути веб-сайт должен состоять из HTML-документа index.html. Используя браузер, мы просматриваем веб-сайт, который отображает HTML-файлы и любые CSS-файлы, которые добавляют правила стиля и макета.
Браузер также создает представление этого документа, известное как объектная модель документа. Благодаря использованию DOM JavaScript может получать доступ и изменять содержимое и элементы веб-сайта.
Чтобы просмотреть DOM с помощью веб-браузера, кликните правой кнопкой мыши в любом месте страницы и выберите «Просмотреть код». Будут открыты Инструменты разработчика:

JavaScript. Быстрый старт
Изучите основы JavaScript на практическом примере по созданию веб-приложения
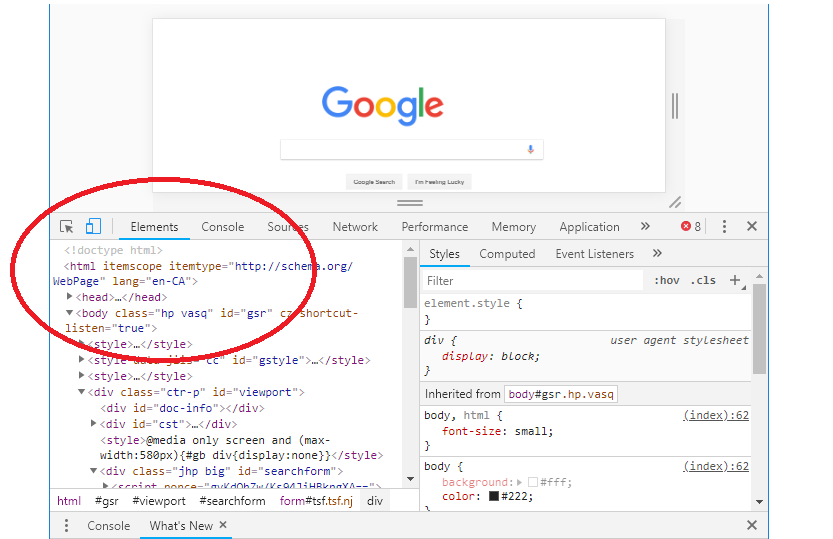
DOM отображается на вкладке Элементы. Вы также можете просмотреть его, выбрав вкладку «Консоль» и введя «document».
Объект document
Объект document является встроенным объектом, содержащим множество свойств и методов. Мы обращаемся к этому объекту и манипулируем им с помощью JavaScript. А манипулируя DOM, мы можем сделать веб-страницы интерактивными! Поскольку мы больше не ограничены только созданием статических сайтов со стилизованным HTML-контентом.
Теперь мы можем создавать приложения, которые обновляют данные страницы без необходимости обновления страницы, мы можем дать пользователям возможность настраивать макет страницы, мы можем создавать элементы перетаскивания, браузерные игры, часы, таймеры и сложную анимацию. Работа с DOM открывает множество возможностей!
Итак, давайте выполним нашу первую манипуляцию с DOM… Перейдите на сайт www.google.com и откройте Инструменты разработчика. Затем выберите вкладку Консоль и введите следующее:
Нажмите Enter, и вы увидите, что цвет фона теперь изменился на оранжевый. Конечно, вы не редактировали исходный код Google (!), но вы изменили способ отображения содержимого локально в вашем браузере, манипулируя объектом document.
document является объектом, свойство body которого мы выбрали для редактирования путем доступа к атрибуту style и изменения значения свойства backgroundColor на orange.
Обратите внимание, что в JavaScript мы используем способ написания имен backgroundColor, а не background-color, как в CSS. Любое свойство CSS через дефис будет записано в JavaScript в camelCase. Вы можете увидеть настройки DOM в разделе элемента body на вкладке Elements или набрав document.body в консоли.
Поскольку мы работаем в браузере напрямую с DOM, мы фактически не меняем исходный код. Если вы обновите браузер, все вернется в исходное состояние.
Дерево DOM и узлы
Во многом из-за структуры DOM, его часто называют Дерево DOM.