Robots.txt для 1С-Bitrix
Битрикс является одной из самых распространенных систем администрирования в российском сегменте интернета. С учетом того, что на этой CMS, с одной стороны, нередко делают интернет-магазины и в достаточной степени нагруженные сайты, а с другой стороны, битрикс оказывается не самой быстрой системой, составление правильного файла robots.txt становится еще более актуальной задачей. Если поисковый робот индексирует только то, что нужно для продвижения, это помогает убрать лишнюю нагрузку на сайт. Как и в случае истории с robots для WordPress, в интернете почти в каждой статье присутствуют ошибки. Такие случае я укажу в самом конце статьи, чтобы было понимание, почему такие команды прописывать не нужно.
Более подробно о составлении robots.txt и значении всех его директив я писал здесь. Ниже я не буду подробно останавливаться на значении каждого правила. Ограничусь тем, что кратко прокомментирую что для чего необходимо.
Правильный Robots.txt для Bitrix
 Код для Robots, который прописан ниже, является базовым, универсальным для любого сайта на битриксе. В то же время, нужно понимать, что у вашего сайта могут быть свои индивидуальные особенности, и этот файл потребуется скорректировать в вашем конкретном случае.
Код для Robots, который прописан ниже, является базовым, универсальным для любого сайта на битриксе. В то же время, нужно понимать, что у вашего сайта могут быть свои индивидуальные особенности, и этот файл потребуется скорректировать в вашем конкретном случае.
В примере я не добавляю правило Crawl-Delay, т.к. в большинстве случаев эта директива не нужна. Однако если у вас крупный нагруженный ресурс, то использование этой директивы поможет снизить нагрузку на сайт со стороны роботов Яндекса, Mail.Ru, Bing, Yahoo и других (Google не учитывает). Подробнее про это читайте в статье Robots.txt.
Директива Host
На старых сайтах вы можете увидеть директиву Host в файле robots.txt.
Она обозначает главное зеркало сайта. Команда стала необязательной. На данный момент все основные поисковые системы команду Host не учитывают.
Долгое время Host поддерживался Яндексом. Но с 2018-го года и российский поисковик для определения главного зеркала стал учитывать только 301-редиректы (пруф).
При этом наличие этой команды в файле robots.txt ошибкой не является.
Ошибочные рекомендации других блогеров для Robots.txt на Bitrix

Правильный robots.txt
Пример правильного и оптимального robots.txt для 1С Битрикс, с учетом параметров, css, js, постраничной навигации и т.д.
Подробный разбор правил robots.txt
Это означает, что данные правила применяются ко всем поисковым роботам.
Запрещает индексировать новую постраничную навигацию D7.
Данный набор правил запрещает индексировать всякие служебные папки движка, админку, загрузки, модули, результаты поиска, сравнение, персональный раздел, авторизацию, статистику хоста, десктопное приложение, аяксы, тестовые разделы, ошибку 404, т.е. всякий ненужный в результатах поиска мусор.
Разрешаем индексировать в публичной, доступной всем части сайта: компоненты, шаблоны, изображения, кэш, css, js и т.д.
Тут обратите внимание, выше папки /bitrix/ + /local/ полностью запрещено индексировать, но правилами ниже по коду можно переопределять или дополнять разрешения, т.к. в них есть как служебные, так и публичные данные, необходимые и поисковиками и пользователям.
Здесь аналогично, выше папка /upload/ полностью запрещена для индексации, а ниже по коду открываем для робота отдельные, необходимые папки, это изображения главного модуля, модуля инфоблоки, медиабиблиотека и динамический ресайз превьюшек.
Данные параметры вопросов и отзывов относятся к моим решениям, они лишь для примера, в каком месте нужно добавлять параметры для индексации своего проекта, их лучше удалить.
Обратите внимание, выше мы закрывали все параметры директивой Disallow: /*?* в этом месте добавляйте только необходимые параметры, которые должны быть разрешены для индексации, все остальные параметры необходимо закрывать, это все мусор, который замедляет индексацию, лишние итерации поисковика и нагрузка на сайт, вплоть до падения сервера.
Это разрешает индексировать все публичные css и js, это важно при проверке проекта на Удобство просмотра на мобильных устройствах или в Google PageSpeed Insights может всплыть закрытый стиль, из-за которого у проекта могут быть проблемы.
Здесь указываем хост проекта, для https именно так, с указанием протокола.
Здесь указываем путь к карте сайта проекта, обратите внимание, нужно отступить одну строку.
Постраничная навигация/пагинация
Очень спорный момент, вы часто можете встретить правила типа:
Порядок в коде
Еще хочу сказать, как например мне удобно ориентироваться в карте и копировать ее из проекта в проект, ежегодно что-то добавлять в нужное место, не копаясь в сотнях строк непонятных правил.
1-й пример, все запрещающие правила для проекта я добавляю выше строки Disallow: /bitrix/
2-й пример: все разрешающие правила для параметров проекта я добавляю внизу перед Allow: /*.css
Два параметра для вопросов и отзывов у себя можете удалить, две строчки, я пока еще с ними экспериментирую, их и не так много, парочка параметров обычно максимум набирается.
Советы
Все закрытые, системные, административные скрипты и папки закрывайте формой входа на сайт, правила в файле robots.txt все равно не запрещают роботу ходить по сайту и сканировать все что доступно по ссылке, просканирует и загрузит в базу вообще все, хоть всю админку, а в результатах поиска будет показывать что в robots.txt разрешено показывать, но может и всплыть когда-нибудь дамп вашей базы или файл сброса пароля админа ✌😊
Закрывайте от индексации все порты на сервере, все ссылки, которыми мы в Яндекс.Почте обмениваемся, индексируются поисковиком, стоило один раз скинуть клиенту лично на почту ссылку с портом, как через неделю весь сайт на порту был проиндексирован, а исходный сайт был исключен из результатов поиска, как дубль.
Disallow bitrix что значит
Современный сайт имеет смысл только если о нём знает достаточно большое количество пользователей Интернета.
Какую бы направленность ни имел сайт: интернет-магазин или простой сайт с информацией по интересам владельца, его нужно «раскрутить», то есть добиться достаточно высокого положения в выдаче поисковых машин по ключевым словам тематики сайта. Технически сделать это не сложно: «1С-Битрикс: Управление сайтом» предоставляет все инструменты для продвижения сайта. Успех в бо́льшей степени зависит от того как Контент-менеджер пользуется этими инструментами.
Для кого этот курс?
Курс Продвижение сайта и Маркетинг адресован тем кто занимается продвижением сайтов и маркетологов, работающих в интернет-магазинах, созданных на основе «1С-Битрикс: Управление сайтом». Изучение этого курса без ознакомления с курсом Контент-менеджер будет сложным, поэтому рекомендуем начать именно с начального курса для Контент-менеджер.
Начальные требования
Необходимый минимум знаний для изучения курса:
У нас часто спрашивают, сколько нужно заплатить
Ещё у нас есть Академия 1С-Битрикс, где можно обучиться на платной основе на курсах нашей компании либо наших партнёров.
Баллы опыта
 уроке.
уроке.
Практика и тесты
После изучения курса пройдите тесты на сертификацию. При успешной сдаче последовательности тестов со страницы Моё обучение скачайте сертификат об успешном прохождении курса в формате PDF.
Если нет интернета
 Скачать материалы курса в формате EPUB. Файлы формата EPUB Чем открыть файл на
Скачать материалы курса в формате EPUB. Файлы формата EPUB Чем открыть файл на
Android:
EPUB Reader
CoolReader
FBReader
Moon+ Reader
eBoox
iPhone:
FBReader
CoolReader
iBook
Bookmate
Windows:
Calibre
FBReader
Icecream Ebook Reader
Плагины для браузеров:
EpuBReader – для Firefox
Readium – для Google Chrome
Как проходить учебный курс?
Как составить правильный robots.txt для Яндекса и Google [инструкция]
Примеры готового файла robots.txt. Решения для сайтов на WordPress, Битрикс, OpenCart и Joomla.
Вебмастер может направить поисковых ботов на страницы, которые считает обязательными для индексирования, и скрыть те, которых в выдаче быть не должно. Для этого предназначен файл robots.txt. Команда сервиса для анализа сайта PR-CY составила гайд об этом файле: для чего он нужен, из каких команд состоит, как составить его по правилам и проверить.
Зачем нужен robots.txt
С помощью этого файла можно повлиять на поведение ботов Яндекса и Google. Файл robots.txt содержит указания для краулеров, предназначенных для индексирования сайта. Он состоит из списка команд, которые рекомендуют либо просканировать, либо пропустить конкретные страницы или целые разделы сайта. Если боты «прислушаются» к этим пожеланиям, то не будут посещать закрытые страницы или индексировать определенный тип контента.
Закрывают обычно дублирующие страницы, служебные, неинформативные, страницы с GET-параметрами или просто неважные для пользователей.
Как надежно закрыть страницу от ботов
Поисковики не воспринимают robots.txt как список жестких правил, это только рекомендации. Даже если в robots стоит запрет, страница может появиться в выдаче, если на нее ведет внешняя или внутренняя ссылка.
Страница, доступ к которой запретили только в robots.txt, может попасть в выдачу и будет выглядеть так:
 Главная страница сайта в выдаче, но описание бот составить не смог
Главная страница сайта в выдаче, но описание бот составить не смог
Если вы точно не хотите, чтобы страница попала в индекс, недостаточно запретить сканирование в файле robots.txt. Один из вариантов, подходящий для служебных страниц, — запаролить ее. Бот не сможет просканировать содержимое страницы, если она доступна только пользователям, авторизованным через логин и пароль.
Если страницы нельзя закрыть паролем, но не хочется показывать их ботам, есть вариант применить директивы «noindex» и «nofollow». Для этого нужно добавить их в секцию HTML-кода страницы:
Чтобы робот правильно интерпретировал «noindex» и «nofollow» и не добавил страницу в индекс, не закрывайте одновременно доступ к ней в файле robots.txt. Так бот не получит доступа к странице и не увидит запрещающих директив.
Требования поисковых систем к файлу robots.txt
Каким должен быть файл, как его оформить и куда размещать — в этом и Яндекс, и Google солидарны:
Подробные рекомендации для robots.txt от Яндекса читайте здесь, от Google — здесь.
Дальше рассмотрим, каким образом можно давать рекомендации ботам.
Как правильно составить robots.txt
Файл состоит из списка команд (директив) с указанием страниц, на которые они распространяются, и адресатов — имён ботов, к которым команды относятся.
Директиву Clean-param воспринимают только боты Яндекса, а в остальном в 2021 году команды для ботов Google и Яндекса одинаковы.
Основные обозначения файла
User-agent — какой бот должен прореагировать на команду. После двоеточия указывают либо конкретного бота, либо обобщают всех с помощью символа *.
Пример. User-agent: * — все существующие роботы, User-agent: Googlebot — только бот Google.
Disallow — запрет сканирования. После косого слэша указывают, на что распространяется команда запрета.
Пустое поле в Disallow означает разрешение на сканирование всего сайта:
А эта запись запрещает всем роботом сканировать весь сайт:
Если речь идет о новом сайте, проследите, чтобы в файле robots.txt не осталась эта запись, после того как разработчики выложат сайт на рабочий домен.
Эта запись разрешает сканирование боту Google, а всем остальным запрещает:
Отдельно прописывать разрешения необязательно. Доступным считается всё, что вы не закрыли.
В записях важен закрывающий косой слэш, его наличие или отсутствие меняет смысл:
Disallow: /about/ — запись закрывает раздел «О нас», доступный по ссылке https://example.com/about/
Disallow: /about — закрывает все ссылки, которые начинаются с «/about», включая раздел https://example.com/about/, страницу https://example.com/about/company/ и другие.
Каждому запрету соответствует своя строка, нельзя перечислить несколько правил сразу. Вот неправильный вариант записи:
Правильно оформить их раздельно, каждый с новой строки и своим Disallow:
Allow означает разрешение сканирования, с помощью этой команды удобно прописывать исключения. Для примера запись запрещает всем ботам сканировать весь альбом, но делает исключение для одного фото:
А вот и отдельная команда для Яндекса — Clean-param. Директиву используют, чтобы исключить дубли страниц, которые могут появляться из-за GET-параметров или UTM-меток. Clean-param распознают только боты Яндекса. Вместо нее можно использовать Disallow, эту команду понимают в том числе и гуглоботы.
Допустим, на сайте есть страница page=1 и у нее могут быть такие параметры:
Каждый образовавшийся адрес в индексе не нужен, достаточно, чтобы там была общая основная страница. В этом случае в robots нужно задать Clean-param и указать, что ссылки с дополнениями после «sid» в страницах на «/index.php» индексировать не нужно:
Clean-param: sid /index.php
Если параметров несколько, перечислите их через амперсанд:
Clean-param: sid&utm&ref /index.php
Строки не должны быть длиннее 500 символов. Такие длинные строки — редкость, но из-за перечисления параметров такое может случиться. Если указание получилось сложным и длинным, его можно разделить на несколько. Примеры найдете в Справке Яндекса.
Sitemap — ссылка на карту сайта. Если карты сайта нет, запись не нужна. Сама по себе карта не обязательна, но если сайт большой, то лучше ее создать и дать ссылку в robots, чтобы ботам было проще разобраться в структуре.
Обозначим также два важных спецсимвола, которые используются в robots:
* — предполагает любую последовательность символов после этого знака;
$ — указывает на то, что на этом элементе необходимо остановиться.
Пример. Такая запись:
запрещает роботу индексировать страницу site.com/catalog/category1, но не запрещает индексировать страницу site.com/catalog/category1/product1.
Лучше не заниматься сбором команд вручную, для этого есть сервисы, которые работают онлайн и бесплатно. Инструмент для генерации robots.txt бесплатно соберет нужные команды: открыть или закрыть сайт для ботов, указать путь к sitemap, настроить ограничение на посещение избранных страниц, установить задержку посещений.
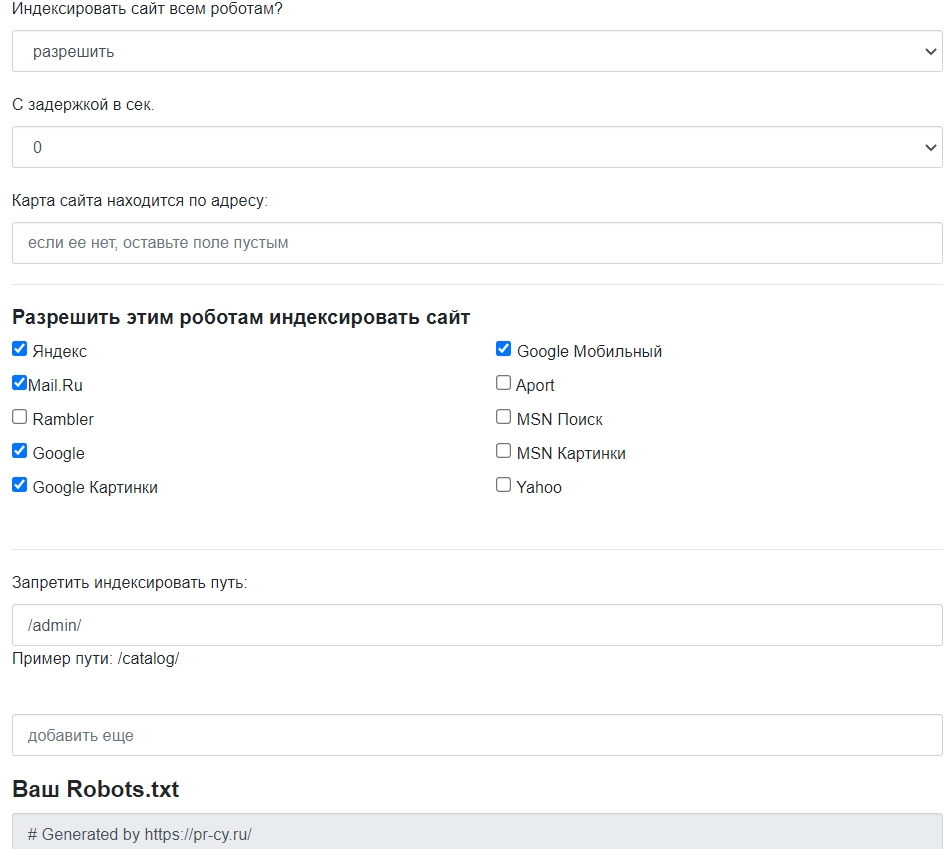 Настройки файла в инструменте
Настройки файла в инструменте
Есть и другие бесплатные генераторы файла, которые позволят быстро создать robots и избежать ошибок. У популярных движков есть плагины, с ними собирать файл еще проще. О них расскажем ниже.
Как проверить правильность robots.txt
После создания файла и добавления в корневой каталог будет не лишним проверить, видят ли его боты и нет ли ошибок в записи. У поисковых систем есть свои инструменты:
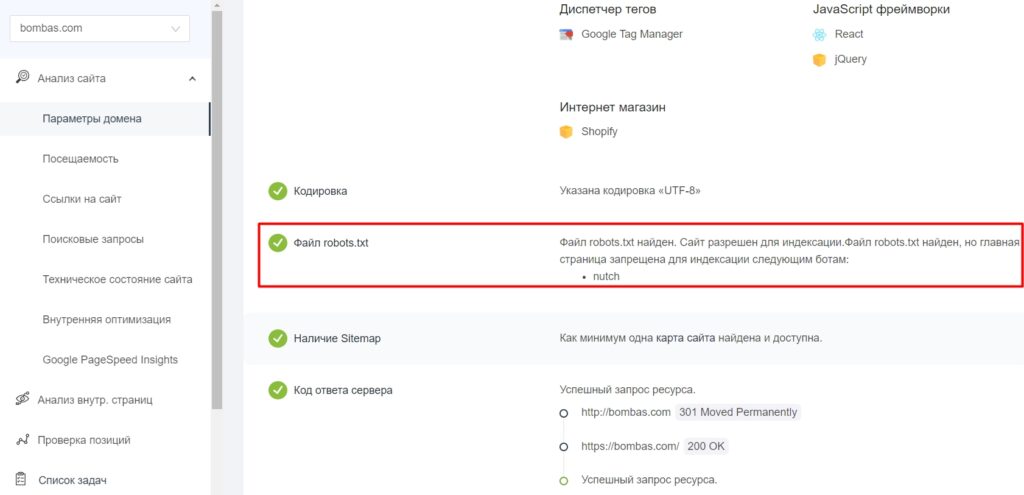 Фрагмент проверки сайта сервисом pr-cy.ru/analysis
Фрагмент проверки сайта сервисом pr-cy.ru/analysis
В «Важных событиях» отобразятся даты изменения файла.
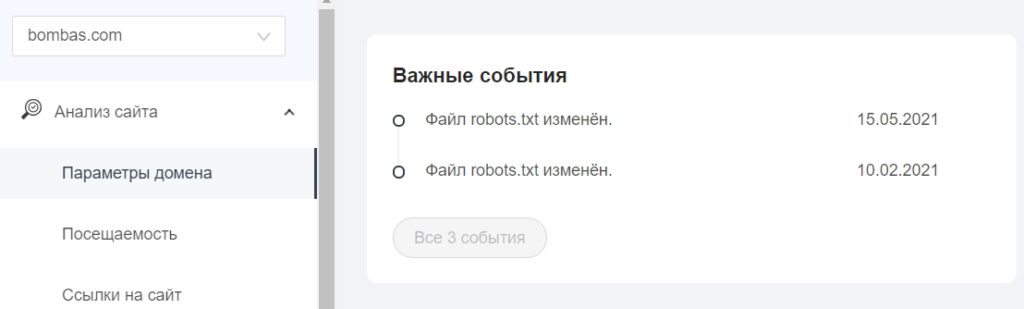 Оповещения в интерфейсе
Оповещения в интерфейсе
Правильный robots.txt для разных CMS: примеры готового файла
Файл robots.txt находится в корневой папке сайта. Чтобы создать или редактировать его, нужно подключиться к сайту по FTP-доступу. Некоторые системы управления (например, Битрикс) предоставляют возможность редактировать файл в административной панели.
Посмотрим, какие возможности для редактирования файла есть в популярных CMS.
WordPress
У WP много бесплатных плагинов, которые формируют robots.txt. Эта опция предусмотрена в составе общих SEO-плагинов Yoast SEO и All in One SEO, но есть и отдельные, которые отвечают за создание и редактирование файла, например:
Пример robots.txt для контентного проекта на WordPress
Это вариант файла для блогов и других проектов без функции личного кабинета и корзины.
User-agent: * # установили общие правила для роботов
Disallow: /cgi-bin # закрыли системную папку, которая находится на хостинге
Disallow: /? # обобщили все параметры запроса на главной странице сайта
Disallow: /wp— # все специальные WordPress-файлы: /wp-json/, /wp-content/plugins, /wp-includes
Disallow: *?s= # здесь и далее перечисление запросов поиска
Disallow: */trackback # закрыли трекбеки — уведомления о появлении ссылки на статью
Disallow: */feed # новостные ленты полностью
Disallow: */rss # rss-ленты
Disallow: */embed # все встраивания
Disallow: /xmlrpc.php # файл API WP
Disallow: *utm*= # все ссылки, у которых прописаны UTM-метки
Disallow: *openstat= # все ссылки, у которых прописаны openstat-метки
Allow: */uploads # открыли доступ к папке с файлами uploads
Allow: /*/*.js # открыли доступ к js-скриптам внутри /wp-, уточнили /*/ для приоритета
Allow: /*/*.css # доступ к css-файлам внутри /wp-, также уточнили /*/ для приоритета
Allow: /wp-*.png # доступ к картинкам в плагинах, папке cache и других в формате png
Allow: /wp-*.jpg # то же самое для формата jpg
Allow: /wp-*.jpeg # для формата jpeg
Allow: /wp-*.gif # и для анимаций в gif
Allow: /wp-admin/admin-ajax.php # открыли доступ к этому файлу, чтобы не блокировать JS и CSS для плагинов
Sitemap: https://example.com/sitemap.xml # указали ссылку на карту сайта (вместо https://example.com нужно подставить сой домен)
Пример robots.txt для интернет-магазина на WordPress
Похожий файл, но со спецификой интернет-магазина на платформе WooCommerce на базе WordPress. Закрываем то же самое, что в предыдущем примере, плюс страницу корзины, а также отдельные страницы добавления в корзину и оформления заказа пользователем.
SEO и robots.txt в 14 версии 1С-Битрикс Управления Сайтом
Разбирать принципы работы мы будем на работающем проекте, на который были установлены последние обновления: http://teatome.ru
Модуль: Поисковая оптимизация (SEO) – версия 14.0.2
В разделе « Сервисы » появился новый пункт « Поисковая оптимизация », в котором собраны возможности по SEO, влияющие на весь сайт:


Мы продолжаем применять новый функционал на работающем магазине, видим в правой части скриншота содержимое файла robots.txt, который используется в данный момент. Подведя курсор к строке, вы увидите крестик и сможете удалить строку.
Удаляем файл robots.txt, который используется в данный момент, и входим в настройку заново:

У нас нет файла, 1С-Битрикс предлагает нам его создать. Справа у нас есть кнопочки с действиями, которые нам помогут. Давайте разберём их:


Добавим несколько папок и файлов в исключения, для поисковых роботов:

Сохраняем и видим, что в конце списка добавились новые записи:



Нажатие на « Сохранить » добавляет запись в файл robots.txt:

Настройки, сделанные на вкладке « Общие правила », действуют для всех поисковых систем (ботов).

Но вы можете задать определённые правила для определённых поисковых систем и их ботов, например Яндекса:

На скриншоте показан список ботов, для которых вы можете задавать специальные правила, разбирать подробно этот момент мы не будем, можно почитать документацию, указанную внизу страницы:

Вы можете дописать нужные команды и строки вручную, перейдя на вкладку « Редактировать »:

Все изменения или настройки, которые мы осуществляли, делались только на экране и не были записаны в файл. Мы внесли все нужные изменения, жмём на « Сохранить », и у нас создаётся файл со всеми настройками:

Набрав в браузере: http://www.teatome.ru/robots.txt вы должны увидеть файл, который вы сохранили:
Спасибо, ждём вопросов и замечаний по новому функционалу.



