Как правильно идентифицировать Android-устройства
Всем привет! Если вам нужно создать уникальный и стабильный идентификатор Android-устройства для использования внутри приложения, то вы наверняка заметили тот хаос, который присутствует в документации и в ответах на stackoverflow. Давайте рассмотрим, как решить эту задачу в 2020 году. О том, где взять идентификатор, стойкий к переустановкам вашего приложения, и какие могут быть сложности в будущем — в этом кратком обзоре. Поехали!
Зачем нужна идентификация
В последнее время обсуждения конфиденциальности пользовательских данных стремительно набирают популярность. Возможно, это спровоцировано ростом выручки рекламных гигантов. Возможно, под этими обсуждениями скрывается обеспокоенность монополиями, которые идентифицируют пользователей и их устройства. Так, Apple, борясь со слежкой и ограничивая всем разработчикам использование IDFA, в то же самое время нисколько не ограничивает его себе. Что можно сказать точно: процесс идентификации пользователя приложения для разработчиков усложнился.
В задачах, опирающихся на идентификацию, встречаются: аналитика возвратов, персонализация контента и рекламы, предотвращение мошенничества.
Среди последних можно выделить несколько актуальных проблем:
Общие аккаунты в сервисах с платной подпиской или уникальным платным контентом. Только представьте сколько теряют сервисы вроде Netflix или Coursera от того, что пользователи заводят один аккаунт на нескольких человек.
Обе проблемы ведут либо к потере выручки, либо к репутационным потерям. Надежность их решения напрямую зависит от надежности идентификации устройств.
Основные способы идентификации
Использование аппаратных идентификаторов
Устаревший и нежизнеспособный в настоящее время способ. Google хорошо поработала над тем, чтобы закрыть доступ к ним, поскольку они не меняются даже после сброса к заводским настройкам. Среди таких идентификаторов:
В настоящее время они недоступны без явного запроса разрешений. Более того, если приложению нужно ими пользоваться, оно может не попасть в Play Market. Оно должно основным функционалом опираться на эти разрешения, иначе будут трудности с прохождением ревью. Поэтому сейчас эта опция доступна приложениям для работы со звонками или голосовым ассистентам.
Такие идентификаторы не меняются после сброса к заводским настройкам, и здесь кроется неочевидный недостаток: люди могут продавать свои устройства, и в таком случае идентификатор будет указывать на другого человека.
Генерация UUID с первым запуском
Данный способ схож с использованием cookie: создаем файл со сгенерированной строкой, сохраняем его в песочнице нашего приложения (например с помощью SharedPreferences), и используем как идентификатор. Недостаток тот же, что и у cookie — вся песочница удаляется вместе с приложением. Еще она может быть очищена пользователем явно из настроек.
При наличии у приложения разрешений к хранилищу вне песочницы можно сохранить идентификатор где-то на устройстве и постараться поискать его после переустановки. Будет ли в тот момент нужное разрешение у приложения — неизвестно. Этот идентификатор можно использовать как идентификатор установки приложения (app instance ID).
Использование идентификаторов, предоставляемых системой
В документации для разработчиков представлен идентификатор ANDROID_ID. Он уникален для каждой комбинации устройства, пользователя, и ключа, которым подписано приложение. До Android 8.0 идентификатор был общим для всех приложений, после — уникален только в рамках ключа подписи. Этот вариант в целом годится для идентификации пользователей в своих приложениях (которые подписаны вашим сертификатом).
Существует и менее известный способ получить идентификатор общий для всех приложений, независимо от сертификата подписи. При первичной настройке устройства (или после сброса к заводским) сервисы Google генерируют идентификатор. Вы не найдете о нем никакой информации в документации, но тем не менее можете попробовать код ниже, он будет работать (по состоянию на конец 2020 года).
Добавляем строчку в файл манифеста нужного модуля:
И вот так достаем идентификатор:
В коде происходит следующее: мы делаем запрос к данным из определенного ContentProvider-a, что поставляется с сервисами Google. Вполне возможно, что Google закроет к нему доступ простым обновлением сервисов. И это даже не обновление самой операционки, а пакета внутри нее, т.е. доступ закроется с обычным обновлением приложений из Play Market.
Но это не самое плохое. Самый большой недостаток в том, что такие фреймворки, как Xposed, позволяют с помощью расширений в пару кликов подменить как ANDROID_ID, так и GSF_ID. Подменить локально сохраненный идентификатор из предыдущего способа сложнее, поскольку это предполагает как минимум базовое изучение работы приложения.
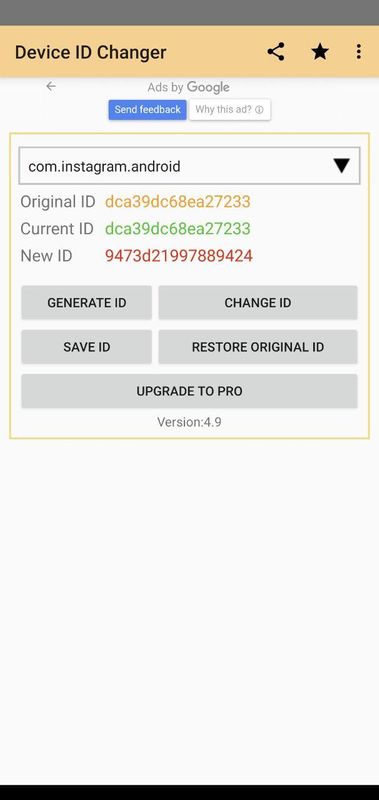 Приложение Device ID Changer в связке с Xposed позволяет подменять практически любой идентификатор. В бесплатной версии — только ANDROID_ID
Приложение Device ID Changer в связке с Xposed позволяет подменять практически любой идентификатор. В бесплатной версии — только ANDROID_ID
Создание цифрового отпечатка (fingerprint) устройства
Идея device-fingerprinting не новая, и активно используется в вебе. У самой популярной библиотеки для создания отпечатка — FingerprintJS — 13 тысяч звезд на GitHub. Она позволяет идентифицировать пользователя без использования cookie.
Рассмотрим идею на примере (цифры взяты приблизительные для иллюстрации).
Возьмем ежедневную аудиторию какого-нибудь Android-приложения. Допустим она составляет 4 миллиона. Сколько среди них устройств марки Samsung? Гораздо меньше, примерно 600 тысяч. А сколько среди устройств Samsung таких, что находятся под управлением Android 9? Уже около 150 тысяч. Выделим среди последних такие, что используют сканер отпечатков пальцев? Это множество устройств еще меньше, ведь у многих планшетов нет сканера отпечатков пальцев, а современные модели опираются на распознавание лица. Получим 25000 устройств. Добавляя больше условий и получая больше информации, можно добиться множеств малых размеров. В идеальном случае — с единственным элементом внутри, что и позволит идентифицировать пользователя. Чем больше пользователей можно различить, тем выше энтропия этой информации.
Среди основных источников информации в Android, доступных без пользовательских разрешений, можно выделить аппаратное обеспечение, прошивку, некоторые настройки устройства, установленные приложения и другие.
Обычно всю добытую информацию хешируют, получая цифровой отпечаток. Его и можно использовать в качестве идентификатора.
Из достоинств метода — его независимость от приложения (в отличие от ANDROID_ID), поскольку при одинаковых показаниях с источников отпечатки будут одинаковыми. Отсюда же вытекает первый недостаток — разные устройства с некоторой вероятностью могут иметь одинаковый отпечаток.
Еще одна особенность отпечатка — не все источники информации стабильны. Например, установленные приложения дадут много энтропии. Возьмите устройство друга, и проверьте, одинаков ли у вас набор приложений. Скорее всего — нет, к тому же приложения могут устанавливаться и удаляться почти каждый день.
Таким образом, метод будет работать при правильном соотношении стабильности и уникальности источников энтропии.
Какой метод выбрать
Итак, мы рассмотрели доступные способы идентификации. Какой же выбрать? Как и в большинстве инженерных задач, единственного правильного решения не существует. Все зависит от ваших требований к идентификатору и от требований к безопасности приложения.
Разумный вариант — использовать сторонние решения с открытыми исходниками. В этом случае за изменениями в политике конфиденциальности будет следить сообщество, вовремя поставляя нужные изменения. За столько лет существования проблемы до сих пор нет популярной библиотеки для ее решения, как это есть для веба. Но среди того, что можно найти на android-arsenal, можно выделить две, обе с открытым исходным кодом.
Android-device-identification — библиотека для получения идентификатора. Судя по коду класса, ответственного за идентификацию, используются аппаратные идентификаторы, ANDROID_ID, и цифровой отпечаток полей из класса Build. Увы, проект уже 2 года как не поддерживается, и в настоящий момент скорее неактуален. Но, возможно, у него еще будет развитие.
Fingerprint-android — совсем новая библиотека. Предоставляет 2 метода: getDeviceId и getFingerprint. Первый опирается на GSF_ID и ANDROID_ID, а второй отдает отпечаток, основанный на информации с аппаратного обеспечения, прошивки и некоторых стабильных настроек устройства. Какая точность у метода getFingerprint — пока неясно. Несмотря на это библиотека начинает набирать популярность. Она проста в интеграции, написана на Kotlin, и не несет за собой никаких зависимостей.
В случае, когда импортирование сторонних зависимостей нежелательно, подойдет вариант с использованием ANDROID_ID и GSF_ID. Но стоит следить за изменениями в обновлениях Android, чтобы быть готовым к моменту, когда доступ к ним будет ограничен.
Если у вас есть вопросы или дополнения — делитесь ими в комментариях. А на этом все, спасибо за внимание!
UUID версии 7, или как не потеряться во времени при создании идентификатора
В течение многих лет я противостоял засилью UUID как ключей в базах данных, но со временем и практикой до меня дошло. Они действительно удобны, когда речь идёт о распределённых системах. Генерировать новый идентификатор на разных концах планеты не так-то просто. Создание псевдослучайных идентификаторов решает эту проблему.
Хотя, подобные решения, не всегда хороши. В отличие от обыкновенных цифровых значений, которые легко кешировать и сортировать, UUID не так гибки в использовании. UUID версии 7 предназначен как раз для того, чтобы разобраться с подобными проблемами.
Добро пожаловать в мир отсортированных случайностей.
Сами по себе UUID это не просто набор случайных битов. Существует несколько вариантов их генерации. @AloneCoder в своей статье как генерируются UUID в подробностях описывает уже существующие форматы идентификаторов, версии с первой по пятую.
UUID в базах данных
Почему нам необходимо генерировать UUID, а не просто брать случайные данные? Ну, ответов может быть множество. Сохранение данных о хосте, который сгенерировал последовательность, сохранение времени и тому подобных значений, позволяет сделать UUID более информативными. Подобный подход можно использовать при создании распределённых вычислительных систем. Например, вместо того, чтобы грузить базу данных запросами с датой, можно просто выбрать те идентификаторы, которые содержат в себе эту дату.
Всё бы хорошо, но вот именно это и не очень-то просто. Выбирать даты из строковых значений UUID это та ещё свистопляска. Почему? Ну, давайте посмотрим на последовательность генерации UUIDv1.
Берутся младшие 32 бита текущей временной метки UTC. Это будут первые 4 байта (8 шестнадцатеричных символов) UUID [ TimeLow ].
Берутся средние 16 битов текущей временной метки UTC. Это будут следующие 2 байта (4 шестнадцатеричных символа) [ TimeMid ].
Следующие 2 байта (4 шестнадцатеричных символа) конкатенируют 4 бита версии UUID с оставшимися 12 старшими битами текущей временной метки UTC (в которой всего 60 битов) [ TimeHighAndVersion ].
Как всё замечательно запутано. На самом деле, распарсить дату из такого идентификатора достаточно просто, но парсинг это парсинг. Это не весело и нагружает процессор.
Герой дня
Основная разработка ведётся силами двух разработчиков: bradleypeabody и kyzer-davis. Хабрачеловеки и хабраалиены могут поучаствовать в обсуждении и написании формата на гитхабе https://github.com/uuid6/uuid6-ietf-draft/.
Пять дней назад эта спецификация вызвала оживлённую дискуссию на hackernews.
При разработке спецификаций, были рассмотрены следующие форматы генерации UUID:
И так, что же такого особого в UUIDv7 и чем он отличается от предыдущих версий?
Эта версия идентификатора бинарно-сортируемая. То есть, вам больше не нужно конвертировать значения UUID в какой-либо другой формат, чтобы понять какое из них больше и меньше.
Ну а нам-то какая разница? Можно же сделать select id, creation_date order by creation_date и жить себе спокойно.
Вы не поняли вопроса.
Тут дело не в том, как вам, программисту, удобнее делать SELECT. Вопрос в том, как база данных хранит индексы. Созданные последовательно, UUIDv4 будут выглядеть случайными. Соответственно, при записи значений этих индексов в базу данных, даже если значения были созданы в один и тот же промежуток времени, кластеризация будет нагружать индексы при записи.
Представьте, у вас есть высоконагруженная система. 100 серверов генерируют новые записи с UUID несколько раз в секунду, и всё это летит в Redis, которые грузит эти данные в Postgresql.
Ага. Вот тут вот жизнь с UUIDv7 становится проще. Значения индексов не настолько разбросаны и следить за ними намного проще.
Плюс, значения ключей можно очень просто и быстро отсортировать в бинарном формате. Возьмите первые 64 бита идентификатора, и сравните их как int64 с другим идентификатором, и вы уже знаете, какой был создан раньше.
Но, как же это работает?
Ок, в отношении самой даты — тут всё просто. Запишите число, как unix timestamp и у вас есть что-то бинарно-сортируемое. Только я вас прошу, не стоит записывать эту дату кусками, в разнобой. Просто и понятно, первые 36 битов содержат в себе одно число. Но, если вы пытаетесь записать миллисекунды, то всё становится сложнее.
Давайте поговорим о математике. О приближении и лимитах. Любимая тема, а? Давайте посмотрим на следующую запись секунды: 05,625. Пять целых, шестьсот двадцать пять секунд. Отбрасываем 5, поскольку это будет записано в unix timestamp.
Если вы будете сохранять это значение в float, то выглядеть это будет страшно, с бинарной точки зрения. А если мы применим немного матана? Для начала разложим единицу в следующий ряд.

Достаточно, просто, правда? Если сложить все числа в этом ряду, то вы получите единицу. А что если складывать не каждый? Ну, с этим можно что-то сделать. Давайте присвоим каждому числу из этого ряда один бит. Каждый бит будет показывать, если этот член присутствует в ряду или нет.
Берём нашу суб-секундную точность, 0,625 и начинаем записывать эту точность с помощью битов.
Первое число 1/2, то есть 0,5. Если наше значение точности больше этого числа, то выставляем битовое значение в 1 и вычитаем это число из нашего текущего значения точности. В итоге получаем, битовую последовательность 1 и 0,125 в остатке.

Что самое приятное, в этой системе, так это то, что если вы урезаете количество бит с конца, то вы будете терять точность, но всё-же сохраните более или менее приближенное значение.
Значение сохраняется, и при этом, вы можете играть с количеством битов, которые вы расходуете на его запись. И — что самое главное — подобная запись производит бинарно-сортируемые значения.
Более того, существует очень простой математический способ выполнения этой операции. Для того чтобы закодировать любое число, сделайте следующее:
Ну и, понятное дело, для того, чтобы раскодировать, нужно сделать обратное.
Что мы получаем в итоге? Возможность сохранения времени с суб-секундной точностью в бинарно-сортируемом формате.
А в случае коллизий?
Если вы генерируете значения на одном узле, то существует вероятность, что даже при наличии суб-секундной точности вы можете создать два идентификатора в один промежуток времени.
Для этого стандарт предусматривает наличие счётчика произвольной длинны, который должен монотонно увеличиваться, если даты совпадают.
И в дополнение, можно задать произвольное количество битов, которые будут идентифицировать компьютер, сгенерировавший значение. (Записывать MAC адрес в это поле не стоит, ибо уж слишком часто это вызывало вопросы с точки зрения безопасности).
Плюс, всё пространство, которое не используется для времени, счётчика и номера компьютера (порядка 54х бит) необходимо заполнять случайными значениями для предотвращения каких-либо совпадений на разных узлах.
Про uuid-ы, первичные ключи и базы данных

Статья посвящена альтернативным версиям Qt-драйверов для работы с базами данных. По большому счету отличий от нативных Qt-драйверов не так много, всего пара: 1) Поддержка типа UUID; 2) Работа с сущностью «Транзакция» как с самостоятельным объектом. Но эти отличия привели к существенному пересмотру кодовой реализации исходных Qt-решений и изменили подход к написанию рабочего кода.
Первичный ключ: UUID или Integer?
Впервые с идеей использовать UUID в качестве первичного ключа я познакомился в 2003 году, работая в команде дельфистов. Мы разрабатывали программу для автоматизации технологических процессов на производстве. СУБД в проекте отводилась существенная роль. На тот момент это была FireBird версии 1.5. По мере усложнения проекта появились трудности с использованием целочисленных идентификаторов в качестве первичных ключей. Опишу пару сложностей:
Проблема архитектурная: периодически заказчики присылали справочные данные с целью включения их в новую версию дистрибутива. Иногда справочники содержали первичные ключи уже имеющиеся в нашей базе. Приходилось устранять коллизии в процессе агрегирования данных. На этом проблемы не заканчивались: при разворачивании нового дистрибутива периодически возникали обратные коллизии.
Проблема программная: чтобы получить доступ к вставленной записи нужно было выполнить дополнительный SELECT-запрос, который возвращал максимальное значение первичного ключа (значение для только что вставленной записи). Причем этот процесс должен был проходить в пределах одной транзакции. Далее можно было обновлять или корректировать запись. Это сейчас я знаю, что некоторые драйверы БД возвращают значение первичного ключа для вставленной записи, но в 2003 году мы такими знаниями не обладали, да и не припомню что бы Делфи-компоненты возвращали что-то подобное.
Использование UUID-ов в качестве первичных ключей сводило к минимуму архитектурную проблему, и полностью решало программную. UUID-ключ генерировался перед началом вставки записи на стороне программы, а не в недрах сервера БД, таким образом дополнительный SELECT-запрос стал не нужен, и требование единой транзакции утратило актуальность. FireBird версии 1.5 не имел нативной поддержки UUID-ов, поэтому использовались строковые поля длинной в 32 символа (дефисы из UUID-ов удалялись). Факт использования строковых полей в качестве первичных ключей нисколько не смущал, нам не терпелось опробовать новый подход при работе с данными.
У UUID-ов есть свои минусы: 1) Существенный объем; 2) Более низкая скорость работы по сравнению с целочисленными идентификаторами. В рамках проекта достоинства оказались более значимы, чем указанные недостатки. В целом, опыт оказался положительным, поэтому в последующих решениях при создании реляционных связей предпочтение отдавалось именно UUID-ам.
Примечание: Более подробный анализ UUID vs Integer для СУБД MS SQL можно посмотреть в статье «Первичный ключ – GUID или автоинкремент?»
Первый драйвер для FireBird
В 2012 году мне снова довелось поработать с FireBird. Нужно было создать небольшую программу по анализу данных. Разработка велась с использованием QtFramework. Примерно в это же время у FireBird вышла версия 2.5 с нативной поддержкой UUID-ов. Я подумал: «Почему бы не добавить в Qt-драйвер для FireBird поддержку типа QUuid?» Так появилась первая версия Qt-драйвера с поддержкой UUID-ов. Этот вариант не сильно отличался от оригинальной версии драйвера и, в основном, был ориентирован на использование в однопоточных приложениях.
Появление сущности «Транзакция»
Следующая модификация Qt-драйвера для FireBird произошла в конце 2018 года. Наша фирма взялась за разработку проекта по анализу данных большого объема. Для фирмы выросшей из стартап-а эта работа была очень важна, как с финансовой, так и с репутацио́нной точек зрения. Сроки исполнения были весьма жесткие. В качестве СУБД была выбрана FireBird, несмотря на определенные сомнения в ее пригодности. Хорошим вариантом могла бы стать PostgreSQL, но у нашей команды на тот момент отсутствовал опыт эксплуатации данной СУБД.
Новая концепция не нуждалась в сущности «транзакция», как в самостоятельной единице, тем не менее, я не стал ее упразднять. Дальнейшая эксплуатация показала, что наличие объекта «транзакция» делает работу с базой данных более гибкой, дает больше инвариантов при написании кода. Например, разработчик может передать объект «Транзакция» в функцию в качестве параметра, явно говоря таким образом, что внутри нужно работать в контексте указанной транзакции. В функции можно проверить активна транзакция или нет, можно выполнить COMMIT или ROLLBACK. Для вспомогательных операций можно создавать альтернативную транзакцию, не затрагивающую основную. Таких возможностей нет у нативных Qt-драйверов.
Ниже приведен пример с тремя функциями, которые последовательно вызываю друг друга. Каждая функция запрашивает объект подключения к базе данных (Driver) у пула коннектов. Так как функции вызываются в одном потоке, они получают объект коннекта, ссылающийся на одно и тоже подключение к БД. Далее в каждой функции создается собственный независимый объект транзакции и все последующие запросы будут выполняются в его контексте.
Приведенный пример не будет работать с нативным Qt-драйвером, причина описана выше: ограничение на одно подключение и одну транзакцию
В примере экземпляры транзакций (1-3) созданы для наглядности. В рабочем коде их можно опустить. В этом случае транзакции будут создаваться неявно внутри объекта QSqlQuery. Неявные транзакции всегда завершаются ROLLBACK-ом для SELECT-запросов и попыткой COMMIT-а для всех остальных.
Ниже показано как можно использовать одну транзакцию для трех sql-запросов. Подтвердить или откатить транзакцию можно в любой из трех функций.
Драйвер для PostgreSQL
Драйвер для MS SQL
Чего нет в классе Driver
Описываемые здесь драйверы не повторяют один в один функционал Qt-решений. В классе оставлены следующие методы:
С введением сущности «Транзакция» они утратили актуальность и нужны исключительно для отладки и диагностирования их вызовов из Qt-компонентов.
Ряд функций не используются нами в работе, поэтому они либо не реализованы, либо реализованы и помечены внутри программными точками останова, то есть разработчику при первом вызове придется их отладить. Вот эти функции:
Заморожена поддержка механизма событий. Обсудив с коллегами этот функционал, мы пришли к заключению, что на данном этапе в нем нет необходимости. Возможно, в будущем решение будет пересмотрено, но пока у нас нет серьезных доводов в пользу событийного механизма.
Новые функции
Лицензионные ограничения
Зависимости
В реализации драйверов используется система логирования ALog, которая является составной частью библиотеки общего назначения SharedTools.
Демо-примеры
Специально для этой статьи был создан демонстрационный проект. Он содержит примеры работы с тремя СУБД: FireBird, PostgreSQL, MS SQL. Репозиторий с драйверами расположен здесь, он подключен в проект как субмодуль. Библиотека SharedTools так же подключена как субмодуль.
Проект создан с использованием QtCreator, сборочная система QBS. Есть четыре сборочных сценария:
Драйвера в первую очередь разрабатывались для работы в Linux, поэтому эксплуатационное тестирование выполнялось именно для этой ОС. В Windows будет работать FireBird-драйвер (проверено), для остальных драйверов тестирование не проводилось.
Демо-примеры записывают следующие логи:
При первом запуске, примеры проверяют наличие тестовой базы данных. Если базы не обнаружено, в лог-файл будет выведен скрипт для ее создания.
Заключение
Черновой вариант статьи не предполагал наличие этого раздела, за что старый товарищ и, по совместительству, корректор подверг меня критике: «Мол, непонятна мотивация, целеполагание неясно. Зачем ты вообще писал эту статью?!» Что ж, исправляюсь!
Как генерируются UUID

Вы наверняка уже использовали в своих проектах UUID и полагали, что они уникальны. Давайте рассмотрим основные аспекты реализации и разберёмся, почему UUID практически уникальны, поскольку существует мизерная возможность возникновения одинаковых значений.
Современную реализацию UUID можно проследить до RFC 4122, в котором описано пять разных подходов к генерированию этих идентификаторов. Мы рассмотрим каждый из них и пройдёмся по реализации версии 1 и версии 4.
Теория
UUID (universally unique IDentifier) — это 128-битное число, которое в разработке ПО используется в качестве уникального идентификатора элементов. Его классическое текстовое представление является серией из 32 шестнадцатеричных символов, разделённых дефисами на пять групп по схеме 8-4-4-4-12.
Информация о реализации UUID встроена в эту, казалось бы, случайную последовательность символов:
Значения на позициях M и N определяют соответственно версию и вариант UUID.
Версия
Номер версии определяется четырьмя старшими битами на позиции М. На сегодняшний день существуют такие версии:

Вариант
Это поле определяет шаблон информации, встроенной в UUID. Интерпретация всех остальных битов в UUID зависит от значения варианта.
Мы определяем его по первым 1-3 старшим битам на позиции N.
1 0 0 0 = 8
1 0 0 1 = 9
1 0 1 0 = A
1 0 1 1 = B
Так что если вы видите UUID с такими значениями на позиции N, то это идентификатор в варианте 1.
Версия 1 (время + уникальный или случайный идентификатор хоста)
В этом случае UUID генерируется так: к текущему времени добавляется какое-то идентифицирующее свойство устройства, которое генерирует UUID, чаще всего это MAC-адрес (также известный как ID узла).
Идентификатор получают с помощью конкатенации 48-битного МАС-адреса, 60-битной временной метки, 14-битной «уникализированной» тактовой последовательности, а также 6 битов, зарезервированных под версию и вариант UUID.
Тактовая последовательность — это просто значение, инкрементируемое при каждом изменении часов.
Временная метка, которая используется в этой версии, представляет собой количество 100-наносекундных интервалов с 15 октября 1582 года — даты возникновения григорианского календаря.
Возможно, вы знакомы с принятым в Unix-системах исчислением времени с начала эпохи. Это просто другая разновидность Нулевого дня. В сети есть сервисы, которые помогут вам преобразовать одно временное представление в другое, так что не будем на этом останавливаться.
Хотя эта реализация выглядит достаточно простой и надёжной, однако использование MAC-адреса машины, на которой генерируется идентификатор, не позволяет считать этот метод универсальным. Особенно, когда главным критерием является безопасность. Поэтому в некоторых реализациях вместо идентификатора узла используется 6 случайных байтов, взятых из криптографически защищённого генератора случайных чисел.
Сборка UUID версии 1 происходит так:
Поскольку эта реализация зависит от часов, нам нужно обрабатывать пограничные ситуации. Во-первых, для минимизации коррелирования между системами по умолчанию тактовая последовательность берётся как случайное число — так делается лишь один раз за весь жизненный цикл системы. Это даёт нам дополнительное преимущество: поддержку идентификаторов узлов, которые можно переносить между системами, поскольку начальное значение тактовой последовательности совершенно не зависит от идентификатора узла.
Помните, что главная цель использования тактовой последовательности — внести долю случайности в наше уравнение. Биты тактовой последовательности помогают расширить временную метку и учитывать ситуации, когда несколько UUID генерируются ещё до того, как изменяются процессорные часы. Так мы избегаем создания одинаковых идентификаторов, когда часы переводятся назад (устройство выключено) или меняется идентификатор узла. Если часы переведены назад, или могли быть переведены назад (например, пока система была отключена), и UUID-генератор не может убедиться, что идентификаторы сгенерированы с более поздними временными метками по сравнению с заданным значением часов, тогда нужно изменить тактовую последовательность. Если нам известно её предыдущее значение, его можно просто увеличить; в противном случае его нужно задать случайным образом или с помощью высококачественного ГПСЧ.
Версия 2 (безопасность распределённой вычислительной среды)
Главное отличие этой версии от предыдущей в том, что вместо «случайности» в виде младших битов тактовой последовательности здесь используется идентификатор, характерный для системы. Часто это просто идентификатор текущего пользователя. Версия 2 используется реже, она очень мало отличается от версии 1, так что идём дальше.
Версия 3 (имя + MD5-хэш)
Если нужны уникальные идентификаторы для информации, связанной с именами или наименованием, то для этого обычно используют UUID версии 3 или версии 5.
Они кодируют любые «именуемые» сущности (сайты, DNS, простой текст и т.д.) в UUID-значение. Самое важное — для одного и того же namespace или текста будет сгенерирован такой же UUID.
Обратите внимание, что namespace сам по себе является UUID.
В этой реализации UUID namespace преобразуется в строку байтов, конкатенированных с входным именем, затем хэшируется с помощью MD5, и получается 128 битов для UUID. Затем мы переписываем некоторые биты, чтобы точно воспроизвести информацию о версии и варианте, а остальное оставляем нетронутым.
Важно понимать, что ни namespace, ни входное имя не могут быть вычислены на основе UUID. Это необратимая операция. Единственное исключение — брутфорс, когда одно из значений (namespace или текст) уже известно атакующему.
При одних и тех же входных данных генерируемые UUID версий 3 и 5 будут детерминированными.
Версия 4 (ГПСЧ)
Самая простая реализация.
6 битов зарезервированы под версию и вариант, остаётся ещё 122 бита. В этой версии просто генерируется 128 случайных битов, а потом 6 из них заменяется данными о версии и варианте.
Такие UUID полностью зависят от качества ГПСЧ (генератора псевдослучайных чисел). Если его алгоритм слишком прост, или ему не хватает начальных значений, то вероятность повторения идентификаторов возрастает.
В современных языках чаще всего используются UUID версии 4.
Её реализация достаточно простая:
Версия 5 (имя + SHA-1-хэш)
Единственное отличие от версии 3 в том, что мы используем алгоритм хэширования SHA-1 вместо MD5. Эта версия предпочтительнее третьей (SHA-1 > MD5).
Практика
Одним из важных достоинств UUID является то, что их уникальность не зависит от центрального авторизующего органа или от координации между разными системами. Кто угодно может создать UUID с определённой уверенностью в том, что в обозримом будущем это значение больше никем не будет сгенерировано.
Это позволяет комбинировать в одной БД идентификаторы, созданные разными участниками, или перемещать идентификаторы между базами с ничтожной вероятностью коллизии.
UUID можно использовать в качестве первичных ключей в базах данных, в качестве уникальных имён загружаемых файлов, уникальных имён любых веб-источников. Для их генерирования вам не нужен центральный авторизующий орган. Но это обоюдоострое решение. Из-за отсутствия контролёра невозможно отслеживать сгенерированные UUID.
Есть и ещё несколько недостатков, которые нужно устранить. Неотъемлемая случайность повышает защищённость, однако она усложняет отладку. Кроме того, UUID может быть избыточным в некоторых ситуациях. Скажем, не имеет смысла использовать 128 битов для уникальной идентификации данных, общий размер которых меньше 128 битов.
Уникальность
Может показаться, что если у вас будет достаточно времени, то вы сможете повторить какое-то значение. Особенно в случае с версией 4. Но в реальности это не так. Если бы вы генерировали один миллиард UUID в секунду в течение 100 лет, то вероятность повторения одного из значений была бы около 50 %. Это с учётом того, что ГПСЧ обеспечивает достаточное количество энтропии (истинная случайность), иначе вероятность появления дубля будет выше. Более наглядный пример: если бы вы сгенерировали 10 триллионов UUID, то вероятность появления двух одинаковых значений равна 0,00000006 %.
А в случае с версией 1 часы обнулятся только в 3603 году. Так что если вы не планируете поддерживать работу своего сервиса ещё 1583 года, то вы в безопасности.
Впрочем, вероятность появления дубля остаётся, и в некоторых системах стараются это учитывать. Но в подавляющем большинстве случаев UUID можно считать полностью уникальными. Если вам нужно больше доказательств, вот простая визуализация вероятности коллизии на практике.



