Почему Python хорош для Data Science и разработки приложений
Авторизуйтесь
Почему Python хорош для Data Science и разработки приложений
Дизайн любого языка программирования предполагает компромисс. Низкоуровневые языки трудны в освоении, требуют от программиста многое делать вручную, зато позволяют проводить гибкую оптимизацию кода и обеспечивать быстродействие. Высокоуровневые языки позволяют решать те же задачи более удобным и простым способом, но имеют меньше способов и инструментов для оптимизации. Одним из таких языков является Python. В Дирекции больших данных X5 Retail Group рассказали, в чём его преимущества перед низкоуровневыми языками и для каких задач его используют в компании.

ведущий разработчик Дирекции больших данных X5 Retail Group
Дирекция больших данных X5 Retail Group существует уже больше двух лет. В ней работают специалисты по Data Science, которые обрабатывают массивы данных о покупателях и товарах, а также разработчики, которые создают программные продукты для работы с большими данными.
Когда мы только запускались, перед нами встал вопрос об инструментах, прежде всего о языках программирования. Первым желанием было взять самые совершенные средства, например Java — универсальный, производительный, постоянно развивающийся и крайне популярный язык. Однако значительная часть наших задач просто не требовала настолько навороченного инструмента. К тому же Java достаточно сложен в освоении, и для наших DS-специалистов, которые больше аналитики и математики, чем программисты, он мог стать проблемой. Нам нужен был язык, который был бы одинаково удобен для всей дирекции, поэтому мы обратили внимание на Python.
Сильные стороны
Чем Python хорош для команды, в которой есть как разработчики, так и специалисты по Data Science? Перечислю свойства этого языка, за которые мы выбрали его для наших задач.
Высокая продуктивность разработки
Язык интерпретируемый, поэтому на нём можно писать быстрее, чем, например, на C. Неявная, но строгая типизация обеспечивает меньший объём кода для решения задач, чем в Java. А лаконичный и ясный синтаксис позволяет быстро писать читабельный код. Для человека, знающего C или Java, Python вообще понятен интуитивно.
Сравните, как выглядит одна и та же функция, написанная на Java и на Python:
расчёт факториала на Java:
расчёт факториала на Python:
Низкий порог входа для изучения
То, что Python широко используется в области Big Data, частично связано со скоростью его освоения. Потребность в анализе данных чаще всего возникает у тех, кто управляет бизнесом — аналитиков, экономистов. Осваивать тяжеловесные языки типа Java или C им нецелесообразно — в отличие от Python, который можно изучить довольно быстро.

Сравнение размеров документаций к различным языкам
«Интерактивность» языка (расчёты без компиляции)
Аналитики также ценят Python за то, что благодаря встроенному интерпретатору он позволяет кодировать на ходу. В Data Science это актуально для проверки гипотез в интерактивном режиме.
Интегрированные возможности для оптимизации исходного кода
Для разработчиков встроенный интерпретатор тоже может быть полезен: так как Python предлагает неявную и динамическую типизацию данных, оценить степень оптимизаций можно только в процессе исполнения кода, для чего и пригодится интерпретатор. Он переводит исходный код в машинные инструкции, которые могут подсказать идею для оптимизации. Например, сравнив две инструкции, можно понять, почему одна работает быстрее, чем другая. Это важное преимущество для работы с Big Data, потому что помимо анализа данных здесь много работы по улучшению алгоритмов их обработки.

Различие в скорости исполнения идентичных, на первый взгляд, функций
Динамичное развитие языка
Необходимость командной проработки решений
Особенности Python делают его интересным инструментом для командной разработки. Из-за того, что интерпретатор языка скрывает детали низкоуровневых машинных вычислений, разработчикам требуется подробнее обсуждать и вникать в детали проекта.
Например, когда на Java разработчик определяет тип возвращаемого значения функции, и происходит какая-то проблема с типом значения, программа просто не запускается. Программа на Python может запуститься, но будет работать некорректно, если тип значения принципиально важен. Подобные проблемы может быть сложно найти на этапе разработки, так что это приходится обсуждать. Кому-то это обстоятельство покажется скорее минусом, но коллективное обсуждение часто помогает находить наиболее удачные решения. А ещё это позволяет разработчикам чувствовать себя причастными к общему делу, что позитивно влияет на мотивацию.
Возможность быстро расширять приложения новыми функциями
Как я уже сказал, кроме дата-инженерных у нас также есть задачи по разработке веб-приложений и микросервисов. Для них Python, возможно, не самый лучший выбор: в перспективе больших нагрузок и скорости сетевого взаимодействия он может быть менее продуктивен, чем компилируемый язык со статической типизацией. Но для web-приложений средней нагруженности и на этапе MVP Python более чем удобен ввиду того, что разработка новых фич занимает меньше времени.

Топ-5 индекса TIOBE популярности языков программирования на март 2020
Python в цепочке наших задач на примере
Приведу конкретный пример, где мы используем Python.
Бизнес-задача
Обеспечить регулярный сбор и анализ информации о покупателях наших торговых сетей. На основе этих данных мы можем сегментировать аудиторию, выделив у каждого покупателя особые характеристики (атрибуты) — например, его склонность совершать премиальные покупки. Таких атрибутов много, реализовать методологию их вычисления — это работа специалиста по Data Science, но с течением времени данные обновляются, и атрибуты необходимо рассчитывать регулярно, а значит — это следует автоматизировать.
Для этого мы разработали на Python систему, которая позволяет рассчитывать эти атрибуты с заданной периодичностью. Вычисление одного атрибута занимает 4–5 часов, при этом используются десятки терабайт данных. Основная сложность заключается в том, что нам необходимо дать регулярный доступ к этим данным другим департаментам компании, которые будут их использовать для построения всевозможных маркетинговых моделей и создания отчетов. Организовать доступ к результатам этих вычислениям само по себе — интересная техническая задача.
Решение
Сами вычисления у нас реализованы на основе PySpark фреймворка в экосистеме Hadoop. В качестве планировщика вычислений используется Apache Airflow. В основе разработанного сервиса лежит микросервисная архитектура, микросервисы оркестрируются через Kubernetes.
В этом ряду примечателен Apache Airflow — открытый инструмент планирования и мониторинга процессов обработки данных. Он написан на Python, что позволяет подключить к процессу работы с проектами не только разработчиков, но и дата-аналитиков. Они заняты ETL-задачами (Extract, Transform, Load), и Airflow для этого исключительно удобен, потому что позволяет просто описывать сложные пайплайны данных.
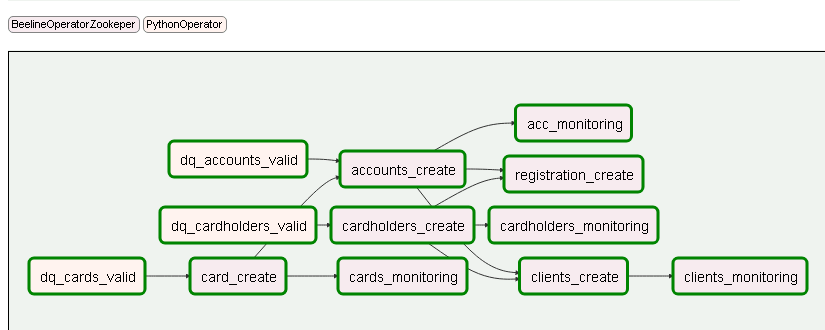
Пример пайплайна в Airflow
Были определённые трудности в том, чтобы подружить Airflow с Kubernetes. Airflow активно развивается, так что документация часто отстает от актуальной версии кода. Поддержка Kubernetes — относительно новая функция, так что многие нюансы удалось понять по коду и комментариям. А то, что Airflow написан на Python, оказалось очень кстати. Когда мало документации, крайне важно иметь возможность разобраться в коде, тем более реализация тех или иных функций может быть не всегда очевидна.
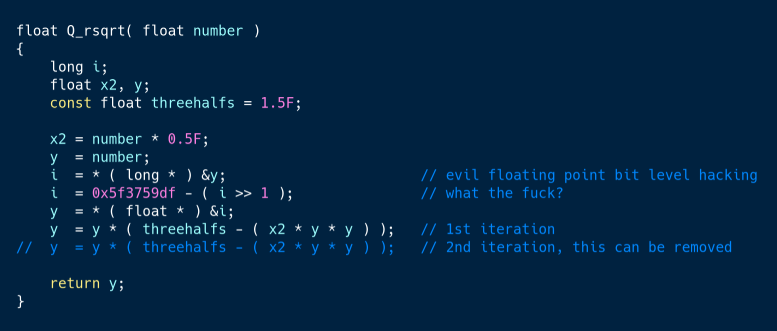
Пример кода с комментариями. Функции вычисления обратного корня в исходном С коде Quake 3
В целом, наш сервис состоит из двух частей: одна планирует расчёты посредством Airflow, а вторая отвечает за наполнение конечных витрин данными. Там с помощью брокера сообщений Kafka организован последовательный процесс наполнения витрин результатами расчётов, которые могут происходить параллельно. Обе части сервиса используют Python: в первой части это Airflow с пайплайнами, во второй — система интеграционных микросервисов.
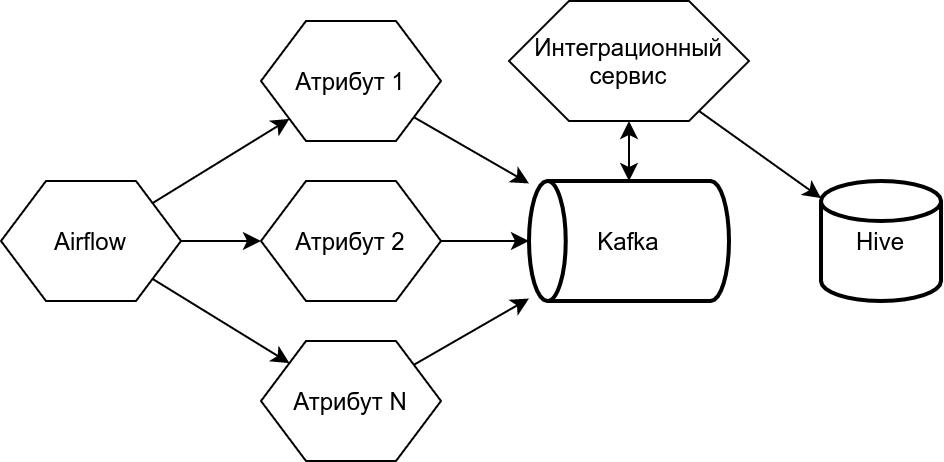
Общая схема системы
Результат
Разработанная система позволяет автоматизировать и планировать регулярные расчёты 45 атрибутов покупательского поведения (часть рассчитывается раз в неделю, часть — раз в месяц). Объём данных, накопленных в результате этих расчётов за три года, составляет 4,5 терабайт, и другие департаменты компании имеют возможность легко обращаться к ним и использовать их для своей работы. При этом система ориентирована на расширение своих функций и реализацию новых.
Таким образом, Python позволяет решать самые разноплановые задачи. Он объединяет в проекте разработчиков и специалистов, для которых программирование не является профильным навыком — бизнес-аналитиков, дата-аналитиков, дата-сайентистов. Отлично подходит для Agile-разработки, для гибкой оптимизации. Для компании, у которой много разноуровневых задач и ведётся работа с большими данными, Python является отличным дополнением к компетенциям в низкоуровневых языках.
Python vs. R: что выбрать для Data Science начинающему специалисту?
Авторизуйтесь
Python vs. R: что выбрать для Data Science начинающему специалисту?
Python и R давно стали стандартом для Data Science. Суть их противостояния в том, что оба языка прекрасно подходят для работы со статистикой. В то время как Python характеризуется понятным синтаксисом и большим количеством библиотек, язык R разрабатывался целенаправленно для специалистов по статистике, а посему оснащён качественной визуализацией данных. Особняком стоит SQL — потому что, если данные уже лежат в таблицах, то это скорее везение, чем повод для расстройств, — и Scala — в основном благодаря тому, что на ней написан популярнейший фреймворк распределённой обработки данных Spark.
Чтобы провести первичный анализ данных и принять решение о дальнейшей судьбе фичи, достаточно средств одного только SQL и командной строки, ведь data science — это, в первую очередь, не про библиотеки с броскими названиями, а про подход. Тем не менее, такой минимализм имеет свой предел (а новичка вообще может отпугнуть), и в какой-то момент всё же придётся обратиться к более продвинутым инструментам исследования.
В этой статье мы вместе со SkillFactory разобрали для вас преимущества и недостатки R и Python в качестве первых языков в карьере data scientist’а. Разработчикам, желающим добавить строчку с полезным навыком в резюме, тоже будет интересно.
Python
Совершенно незаметно подкралось тридцатилетие Python. За свою уже немалую историю Python несколько раз перерождался, теряя обратную совместимость, но всегда оставался популярен как среди разработчиков в общем, так, в частности, и среди data scientist’ов. На это есть несколько причин.
Преимущества Python в Data Science
При всём своём великолепии, Python не лишён и минусов. Его часто (и иногда заслуженно) называют медленным, ему всё ещё не хватает удобных средств ORM, а написание действительного крупного проекта на нём — довольно тяжёлый труд, требующий хорошей дисциплины. Но как и с любым другим инструментом, важно просто знать, как им пользоваться. Кстати об инструментах.
Python-инструменты для data scientist
Как уже упоминалось ранее, Python примечателен своим обширным набором библиотек и инструментов. Говоря о data science, нужно в первую очередь упомянуть следующие:
Кстати, именно Python — основный язык курса «Профессия Data Scientist» от SkillFactory. При этом знать его не обязательно: вы освоите его в процессе обучения на примере реальных задач.
В 2020 году язык R остаётся одним из самых популярных для Data Science и статистики, стабильно завоёвывая всё большую долю просмотров в соответствующих разделах StackOverflow. При этом, со значительным перевесом лидируют вопросы академического характера: в первую очередь, R — это язык с богатым набором библиотек по машинному обучению и статистике, что особенно важно в исследовательских целях.
Преимущества R в Data Science
R-инструменты для data scientist
Поговорим об упомянутых библиотечных богатствах R. Вот некоторые из базовых, но мощных библиотек, вооружившись которыми можно провести обширный рисерч или занять хорошие места в Kaggle:
Python vs. R в Data Science: что лучше?
Оба языка обладают своими достоинствами и недостатками. Подойти может любой из них, всё зависит от ваших задач. Вот некоторые моменты, которые могут помочь с выбором:
Если вы пока не знаете ни Python, ни R, но при этом хотите работать в IT, начать вам может помочь курс «Профессия Data Scientist» от SkillFactory. Там вы сможете за 2 года стать middle Data scientist с нуля. Курс ориентирован на практические задачи и его можно совмещать с работой или учёбой.
Галопом по Python: языковой минимум, необходимый начинающему дата-сайентисту
Для первых шагов в науку о данных достаточно самых основ «змеиного» языка. Разбираемся, каких именно.


Python (он же пайтон, питон, питончик) — основной язык программирования в Data Science, без него просто никуда. Он несложен в изучении, имеет ясный и читаемый код. Для языка создано огромное количество дополнений-библиотек, вокруг него сформировалось многочисленное сообщество, которое не даст пропасть новичку.
Итак, начинающему дата-сайентисту для старта достаточно знать:
Кажется, немного. Но этих знаний хватит, чтобы закодить несложную модель машинного обучения (например, Random Forest) для рекомендательной системы в туризме, предсказания курса доллара или прогноза цены недвижимости.
Питонить удобнее всего в Google Colaboratory. Это бесплатная веб-среда корпорации Google для вычислений и анализа данных. Чтобы получить к ней доступ, требуется лишь почта на Gmail — всё работает прямо в браузере, на компьютер ничего устанавливать не нужно.

С некоторых пор утверждает, что он data scientist. В предыдущих сезонах выдавал себя за математика, звукорежиссёра, радиоведущего, переводчика, писателя. Кандидат наук, но не точных. Бесстрашно пишет о Data Science и программировании на Python.
Числа, строки, списки
Числа (целые и дробные), строки и списки — это самые фундаментальные типы данных в Python. Первые примеры кода практически во всех руководствах связаны именно с ними.
Для начала достаточно запомнить, что дробные числа, в отличие от целых, пишутся через точку: 23.0 — это дробное число для Python, а 23 — целое. Строки состоят из букв, символов и цифр и заключены в одинарные или двойные кавычки, а списки — это несколько элементов через запятую в квадратных скобках.
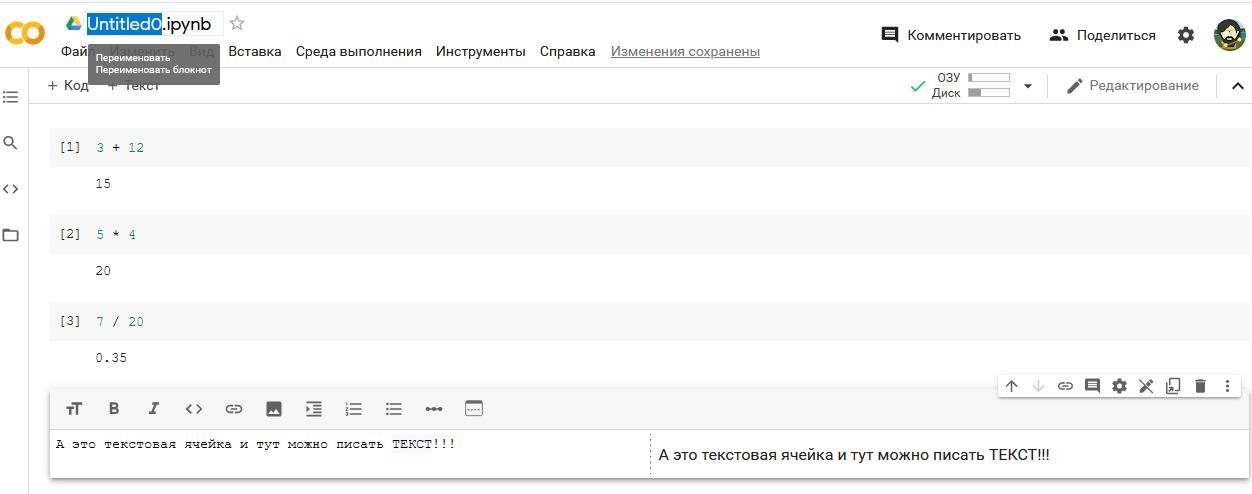
Код и текст в ячейках
Традиционно начнём с вывода строки Hello, Skillbox. В ячейке своего ноутбука Colab наберите:
И в том, и в другом случае код в ячейке запустится на выполнение. В нашем случае код из ячейки ноутбука говорит: «Напечатай на экране строку Hello, Skillbox». Должно получиться что-то вроде:
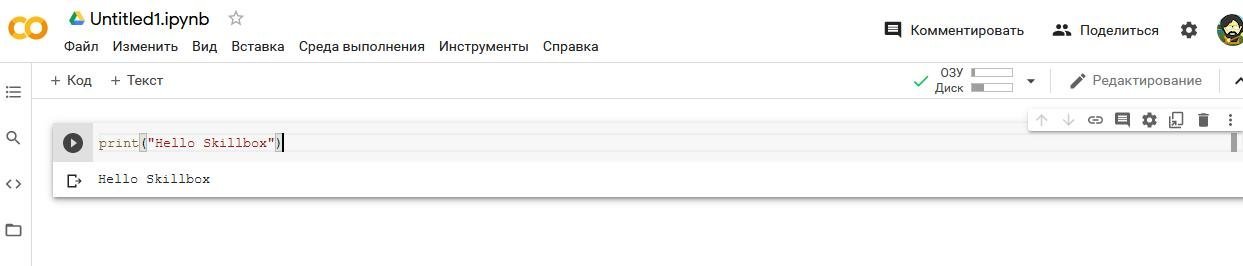
В ноутбуках два основных вида ячеек: «код» и текст». Ту, что с кодом, мы только что запустили. Ячейки текстового типа нужны для пояснений, создания заголовков или оглавлений ноутбуков. В ячейках используется так называемая маркдаун-разметка: здесь подробная шпаргалка по ней.
Потренируйтесь: самостоятельно создайте и удалите ячейки с кодом и текстом. Попробуйте использовать кодовые ячейки как калькулятор — наберите выражение, например, 2 + 2, 3 * 5 (звёздочка означает умножение) или 5 / 20, и запустите ячейку на выполнение. И, наконец, переименуйте ноутбук из Untitled0.ipynb в The_Greatest_DS_Project_Ever.ipynb или что-нибудь поскромнее.
Переменные и их вывод
Переменные в Python — это именованные сущности, в которые мы, как в коробочку с надписью, кладём какие-то значения или данные. Значения переменным задаются с помощью оператора присваивания: =.
Этот код, запущенный в ячейке, сначала присвоит переменной а_chislo значение 20, затем выдаст его нам с помощью функции print().
Старайтесь использовать осмысленные, говорящие названия переменных. Эта привычка сбережёт вам дни и недели, если не месяцы жизни — без преувеличения. Используйте маленькие латинские буквы, символ подчёркивания и цифры.
В переменные можно класть и строки:
Можно сочетать переменные прямо внутри скобок функции print через запятую:
Python понимает и одинарные, и двойные кавычки. Главное правило: не закрывать одинарные кавычки двойными, и наоборот. Двойные кавычки закрывают двойные, одинарные — одинарные. Машины, порядок, красота!
Более продвинутый способ вывода использует форматированные строки,
или f-strings:
В скобках прямо перед кавычками ставится f, и Python понимает, что строка будет форматированной. Внутрь основной строки с помощью фигурных скобок можно вставлять переменные и целые выражения из них.
Кстати, если переносите код в ячейку прямо из текста этой статьи копипастом (а кто из нас без греха), то Python может выдать ошибку. Причина — кавычки и другие специальные символы. Они могут быть немного другими, в зависимости от настроек шрифта в вашем браузере. Надёжнее всего перепечатать код вручную.
F-строки удобны тем, что не надо постоянно лезть внутрь скобок функции print(), чтобы изменить вывод: достаточно изменить переменную.
Python-пакеты для Data Science
Python — это один из самых распространённых языков программирования. Хотя стандартные возможности Python достаточно скромны, существует огромное количество пакетов, которые позволяют решать с помощью этого языка самые разные задачи. Пожалуй, именно поэтому Python и пользуется такой популярностью среди программистов. Можно наугад назвать какую-нибудь сферу деятельности и в экосистеме Python, почти гарантированно, найдутся отличные инструменты для решения специфических задач из этой сферы. В наше время весьма востребованы наука о данных (Data Science, DS) и машинное обучение (Machine Learning, ML). И там и там Python показывает себя наилучшим образом.
Помимо Python в DS-проектах часто используют язык программирования R. R быстрее Python и имеет больше статистических и вычислительных библиотек. Но в этом материале мы будем говорить исключительно о библиотеках (пакетах) для Python, о которых стоит знать каждому, кто хочет добраться до профессиональных вершин Data Science.

Прежде чем переходить к обзору библиотек, остановимся на том, что это такое — «наука о данных», и на том, почему в этой сфере стоит пользоваться языком Python.
Обзор Data Science
В наши дни данные в бизнесе ценятся буквально на вес золота. Мы живём во времена больших данных, каждую секунду в мире появляются огромные объёмы информации. Крупные организации пользуются этими данными ради укрепления и расширения своего бизнеса.
Применяя DS и другие подобных технологии, мы извлекаем из данных ценные сведения, которые позволяют решать сложные реальные задачи и строить прогнозные модели. Data Science — это не инструмент или технология. Это — навык, который можно развить, освоив некоторые инструменты и программные пакеты.
Почему Python используется в сфере Data Science?
Python считается одним из ведущих языков программирования, используемых для построения DS- и ML-моделей.
Обсудим основные причины, по которым разработчики и дата-сайентисты предпочитают использовать в своих проектах Python, а не другие языки программирования.
▍Простота изучения
Это — очевидная причина выбора из множества существующих языков программирования именно Python. В этом языке используется простой и понятный синтаксис, писать Python-код совсем несложно. Этот процесс напоминает написание инструкций на обычном английском языке.
▍Для решения сложных задач требуется писать сравнительно небольшие объёмы кода
Алгоритмы из сфер DS и ML весьма сложны. Поэтому для их реализации желательно использовать такой язык программирования, который позволяет кратко и ёмко выражать идеи разработчика. Python, благодаря его синтаксису и чёткой структуре кода, отлично подходит для решения подобных задач. Это помогает программистам создавать компактные и мощные программы.
▍Библиотеки
Главные ресурсы Python-программиста — это дополнительные библиотеки. Создано множество Python-пакетов, ориентированных на сферу Data Science. В них имеются реализации сложных алгоритмов, что позволяет тем, кому нужны эти алгоритмы, не писать код с нуля.
▍Кроссплатформенность
Python-программы могут работать на различных платформах. В частности — на Windows, Linux, macOS. Код, написанный для некоей платформы, может, без изменений, запускаться на других платформах.
▍Большое сообщество
Вокруг Python сформировалось огромное сообщество. Существует множество онлайн-площадок, на которых разработчики обсуждают возникшие у них проблемы и помогают друг другу в их решении.
Python-пакеты для Data Science
Мы поговорили о том, что такое Data Science, и о том, почему Python популярен в этой сфере. Теперь давайте рассмотрим некоторые полезные Python-пакеты. В частности, речь пойдёт о следующих пакетах:
▍1. NumPy
NumPy — это один из самых широко используемых Python-пакетов. Название пакета, NumPy, расшифровывается как Numerical Python. Здесь реализовано множество вычислительных механизмов, пакет поддерживает специализированные структуры данных, в том числе — одномерные и многомерные массивы, значительно расширяющие возможности Python по выполнению различных вычислений. Возможности структур данных, которые поддерживает Python, уступают возможностям структур данных NumPy.
Особенности NumPy
▍2. SciPy
Пакет SciPy построен на основе NumPy, в нём используются и некоторые другие вспомогательные пакеты. Он широко используется для выполнения статистических расчётов. В SciPy можно работать с теми же данными, что и в NumPy. Поэтому SciPy часто используют для решения задач, которые нельзя решить с использованием стандартных механизмов NumPy. SkiPy — это инструмент, которому доверяет огромное количество учёных во всём мире.
Особенности SciPy
▍3. Pandas
Pandas — это, после NumPy, второй по известности Python-пакет, используемый в Data Science. Его применяют в самых разных местах, например, в сферах статистики, финансов, экономики, анализа данных. Он основан на NumPy, в частности, поддерживает преобразование структур данных NumPy в собственные структуры данных и обратные преобразования. Пакет Pandas часто используют для обработки больших объёмов данных. В ходе обработки данных Pandas прибегает к некоторым возможностям NumPy, в нём применимы и возможности SciPy, например, средства проведения статистических вычислений. Фактически, для проведения DS-вычислений обычно используются все три пакета — Pandas, NumPy и SciPy.
Особенности Pandas
▍4. StatsModels
Пает StatsModels основан на пакетах NumPy и SciPy. Он широко используется для анализа данных, для создания статистических моделей, для выполнения статистических исследований. Данный пакет весьма популярен благодаря своим возможностям в сфере статистических вычислений. Он хорошо интегрируется, например, с Pandas. В других подобных пакетах, в SciPy, например, выполнять статистические вычисления достаточно сложно. StatsModels упрощает решение подобных задач.
Особенности StatsModels
▍5. Matplotlib
Matplotlib — это известнейший Python-пакет для визуализации данных. Его, пожалуй, можно включить в набор основных пакетов, которые нужно освоить тому, кто пользуется Python в сфере Data Science. Он поддерживает множество стандартных средств для визуализации данных, представленных различными графиками и диаграммами.
Этот пакет может работать вместе с другими Python-пакетами, вроде уже известных нам NumPy и SciPy. Он, кроме того, поддерживает API, который позволяет встраивать создаваемые им графические объекты в различные приложения.
Особенности Matplotlib
▍6. Seaborn
Seaborn — это расширение для Matplotlib, которое направлено на то, чтобы сделать графики Matplotlib привлекательнее и упростить создание сложных визуализаций. Этот пакет, кроме того, содержит API, направленный на изучение взаимоотношений между переменными. В целом, Seaborn можно назвать «улучшенным Matplotlib».
Особенности Seaborn
▍7. Plotly
Plotly — это ещё один известный Python-пакет для визуализации данных. Он даёт в наше распоряжение интерактивные графики, позволяющие исследовать взаимоотношения переменных. Plotly, помимо сферы статистики, используется в финансах, в экономике, в науке. Plotly отличается от Matplotlib гораздо более продвинутыми возможностями по построению трёхмерных графиков.
Особенности Plotly
▍8. Bokeh
Bokeh — это пакет, предназначенный для визуализации данных в веб-приложениях. Его можно легко интегрировать с любым Python-фреймворком, с таким, как Flask или Django. Он поддерживает множество видов графиков. Этим пакетом просто и удобно пользоваться. В частности, речь идёт о том, что создавать с его помощью интерактивные графики можно, написав буквально несколько строк кода.
Особенности Bokeh
▍9. Scikit-Learn
Scikit-Learn — это Python-пакет для машинного обучения. Он включает в себя практически всё, что нужно дата-сайентисту. Этот проект появился на мероприятии Google Summer of Code. В нём имеются различные встроенные модули, которые дают возможность работать с множеством популярных алгоритмов машинного обучения. Это, например, алгоритм «случайный лес», алгоритм спектральной кластеризации, алгоритм кросс-валидации, метод k-средних и многие другие. Этот пакет можно использовать для создания моделей машинного обучения с учителем и без учителя.
Особенности Scikit-Learn
▍10. Keras
Keras — это пакет, реализующий механизмы глубокого обучения (Deep Learning, DL), который широко используется при создании нейросетевых моделей. Это — одна из самых мощных опенсорсных Python-библиотек, которая способна работать с самыми разными видами данных, например — с текстами и с изображениями. Существуют и другие надёжные DL-решения, предназначенные для Python-разработчиков, но Keras выгодно отличается от них тем, что упрощает работу со сложными моделями глубокого обучения.
Особенности Keras
Итоги
Все Python-пакеты, о которых мы рассказали, пользуются серьёзной популярностью в среде дата-сайентистов. Есть, конечно, и другие подобные библиотеки. И вам, если вы хотите построить карьеру в сфере Data Science, понадобится разобраться со многими из них, а не только с теми, о которых мы говорили сегодня.
Какими Python-пакетами из сферы Data Science вы пользуетесь чаще всего?



