Нужно ли нам озеро данных? А что делать с хранилищем данных?
Это статья перевод моей статьи на medium — Getting Started with Data Lake, которая оказалась довольно популярной, наверное из-за своей простоты. Поэтому я решил написать ее на русском языке и немного дополнить, чтобы простому человеку, который не является специалистом по работе с данными стало понятно, что такое хранилище данных (DW), а что такое озеро данных (Data Lake), и как они вместе уживаются.
Почему я захотел написать про озеро данных? Я работаю с данными и аналитикой больше 10 лет, и сейчас я точно работаю с большими данными в Amazon Alexa AI в Кембридже, который в Бостоне, хотя сам живу в Виктории на острове Ванкувер и часто бываю и в Бостоне, и в Сиэтле, и в Ванкувере, а иногда даже и в Москве выступаю на конференциях. Так же время от времени я пишу, но пишу в основном на английском, и написал уже несколько книг, так же у меня есть потребность делиться трендами аналитики из Северной Америке, и я иногда пишу в телеграмм.
Я всегда работал с хранилищами данных, и с 2015 года стал плотно работать с Amazon Web Services, да и вообще переключился на облачную аналитику (AWS, Azure, GCP). Я наблюдал эволюцию решений для аналитики с 2007 года и сам даже поработал в вендоре хранилищ данных Терадата и внедрял ее в Сбербанке, тогда-то и появилась Big Data с Hadoop. Все стали говорить, что прошла эра хранилищ и теперь все на Hadoop, а потом уже стали говорить про Data Lake, опять же, что теперь уж точно хранилищу данных пришел конец. Но к счастью (может для кого и к несчастью, кто зарабатывал много денег на настройке Hadoop), хранилище данных не ушло.
В этой статье мы и рассмотрим, что такое озеро данных. Статья рассчитана на людей, у которых мало опыта с хранилищами данными или вовсе нет.

На картинке озеро Блед, это одно из моих любимых озер, хотя я там был всего один раз, но запомнил его на всю жизнь. Но мы поговорим о другом типе озера — озеро данных. Возможно многие из вас уже не раз слышали про это этот термин, но еще одно определение никому не повредит.
Прежде всего вот самые популярные определения Озера Данных:
«файловое хранилище всех типов сырых данных, которые доступны для анализа кем-угодно в организации» — Мартин Фовлер.
«Если вы думаете, что витрина данных это бутылка воды — очищенной, запакованной и расфасованной для удобного употребления, то озеро данных это у нас огромный резервуар с водой в ее естественном виде. Пользователи, могу набирать воды для себя, нырять на глубину, исследовать» — Джеймс Диксон.
Теперь мы точно знаем, что озеро данных это про аналитику, оно позволяет нам хранить большие объемы данных в их первоначальной форме и у нас есть необходимый и удобный доступ к данным.
Я часто люблю упрощать вещи, если я могу рассказать сложный термин простыми словами, значит для себя я понял, как это работает и для чего это нужно. Как то, я ковырялся в iPhone в фотогалерее, и меня осенило, так это же настоящее озеро данных, я даже сделал слайд для конференций:

Все очень просто. Мы делаем фотографию на телефон, фотография сохраняется на телефон и может быть сохранено в iCloud (файловое хранилище в облаке). Также телефон собирает мета-данные фотографии: что изображено, гео метка, время. Как результат, мы может использовать удобный интерфейс iPhone, чтобы найти нашу фотографию и при этому мы даже видим показатели, например, когда я ищу фотографии со словом огонь (fire), то я нахожу 3 фотографии с изображение костра. Для меня это прям как Business Intelligence инструмент, который работает очень быстро и четко.
И конечно, нам нельзя забывать про безопасность (авторизацию и аутентификацию), иначе наши данных, могут легко попасть в открытый доступ. Очень много новостей, про крупные корпорации и стартапы, у которых данные попали в открытый доступ из-за халатности разработчиков и не соблюдения простых правил.
Даже такая простая картинка, помогает нам представить, что такое озеро данных, его отличия от традиционного хранилища данных и его основные элементы:
С другой стороны, вендор Snowflake заявляет, что вам больше не нужно думать про озеро данных, так как их платформа данных (до 2020 это было хранилище данных), позволяет вам совместить и озеро данных и хранилище данных. Я работал не много со Snowflake, и это действительно уникальный продукт, который может так делать. Конечно Snowflake стоит денег, но у крупных компаний на западе серьезные бюджеты на аналитику.
В заключении, мое личное мнение, что нам все еще нужно хранилище данных как основной источник данных для нашей отчетности, и все, что не помещается, мы храним в озере данных. Вся роль аналитики — это предоставить удобный доступ бизнесу для принятия решений. Как ни крути, но бизнес пользователи работаю эффективней с хранилищем данных, чем озером данных, например в Amazon — есть Redshift (аналитическое хранилище данных) и есть Redshift Spectrum/Athena (SQL интерфейс для озера данных в S3 на базе Hive/Presto). Тоже самое относится к другим современным аналитическим хранилищам данных.
Давайте рассмотрим типичную архитектура хранилища данных:
Это классическое решение. У нас есть системы источники, с помощью ETL/ELT мы копируем данные в аналитическое хранилище данных и подключаем к Business Intelligence решению (мое любимое Tableau, а ваше?).
Такое решение имеет следующие недостатки:
Цель любого аналитического решения — служить бизнес пользователям. Поэтому мы всегда должны работать от требований бизнеса. (В Амазон это один из принципов — working backwards).
Работая и с хранилищем данных и с озером данных, мы можем сравнить оба решения:
Главный вывод, который можно сделать, что хранилище данных, никак не соревнуется с озером данных, а больше дополняет. Но это вам решать, что подходит для вашего случая. Всегда интересно, попробовать самому, и сделать правильные выводы.
Я хотел бы также рассказать по один из кейсов, когда я стал использовать подход озера данных. Все довольно банально, я попытался использовать инструмент ELT (у нас был Matillion ETL) и Amazon Redshift, мое решение работала, но не укладывалось в требования.
Мне необходимо было взять веб логи, трансформировать их и агрегировать, чтобы предоставить данные для 2х кейсов:
Один файл весил 1-4 мегабайта.
Но была одна трудность. У нас было 7 доменов по всему миру, и за один день создавалось 7 тысяч файлов. Это не очень больше объем, всего 50 гигабайт. Но размер нашего кластера Redshift был тоже небольшим (4 ноды). Загрузка традиционным способом одного файла занимала около минуты. То есть, в лоб задача не решалась. И это был тот случай, когда я решил использовать подход озера данных. Решение выглядело примерно так:
Оно достаточно простое (я хочу заметить, что преимущество работы в облаке это простота). Я использовал:
Совсем недавно я узнал один из недостатков озера данных — это GDPR. Проблема в том, когда клиент просит его удалить, а данные находятся в одном из файлов, мы не можем использовать Data Manipulation Language и операцию DELETE как в базе данных.
Надеюсь, статья прояснила разнице между хранилищем данных и озером данных. Если было интересно, то могу перевести еще свои статьи или статье профессионалов, которых читаю. А также рассказать про решения, с которыми работаю, и их архитектуру.
Озеро, хранилище и витрина данных
Рассмотрим три типа облачных хранилищ данных, их различия и области применения.
Озеро данных
Озеро данных (data lake) — это большой репозиторий необработанных исходных данных, как неструктурированных, так и частично структурированных. Данные собираются из различных источников и просто хранятся. Они не модифицируются под определенную цель и не преобразуются в какой-либо формат. Для анализа этих данных требуется длительная предварительная подготовка, очистка и форматирование для придания им однородности. Озера данных — отличные ресурсы для городских администраций и прочих организаций, которые хранят информацию, связанную с перебоями в работе инфраструктуры, дорожным движением, преступностью или демографией. Данные можно использовать в дальнейшем для внесения изменений в бюджет или пересмотра ресурсов, выделенных коммунальным или экстренным службам.
Хранилище данных
Хранилище данных (data warehouse) представляет собой данные, агрегированные из разных источников в единый центральный репозиторий, который унифицирует их по качеству и формату. Специалисты по работе с данными могут использовать данные из хранилища в таких сферах, как data mining, искусственный интеллект (ИИ), машинное обучение и, конечно, в бизнес-аналитике. Хранилища данных можно использовать в больших городах для сбора информации об электронных транзакциях, поступающей от различных департаментов, включая данные о штрафах за превышение скорости, уплате акцизов и т. д. Хранилища также могут использовать разработчики для сбора терабайтов данных, генерируемых автомобильными датчиками. Это поможет им принимать правильные решения при разработке технологий для автономного вождения.
Витрина данных
Витрина данных (data mart) — это хранилище данных, предназначенное для определенного круга пользователей в компании или ее подразделении. Витрина данных может использоваться отделом маркетинга производственной компании для определения целевой аудитории при разработке маркетинговых планов. Также производственный отдел может применять ее для анализа производительности и количества ошибок, чтобы создать условия для непрерывного совершенствования процессов. Наборы данных в витрине данных часто используются в режиме реального времени для аналитики и получения практических результатов.
Озеро, хранилище и витрина данных: ключевые различия
Все упомянутые репозитории используются для хранения данных, но между ними есть существенные различия. Например, хранилище и озеро данных — крупные репозитории, однако озеро обычно более рентабельно с точки зрения затрат на внедрение и обслуживание, поскольку в нем по большей части хранятся неструктурированные данные.
За последние несколько лет архитектура озер данных эволюционировала, и теперь способна поддерживать бо́льшие объемы данных и облачные вычисления. Большие объемы данных поступают от разных источников в централизованный репозиторий.
Хранилище данных можно организовать одним из трех способов:
Витрина данных содержит небольшой по сравнению с хранилищем и озером объем данных, которые разбиты на категории для применения конкретной группой людей или подразделением компании. Витрина данных может быть представлена в виде различных схем (звезды, снежинки или свода), которые определяются логической структурой данных. Формат свода данных (data vault) является самым гибким, универсальным и масштабируемым.
Существует три типа витрин данных:
IBM предлагает различные решения для облачного хранения и интеллектуального анализа данных.
Data Lake – от теории к практике. Сказ про то, как мы строим ETL на Hadoop
В этой статье я хочу рассказать про следующий этап развития DWH в Тинькофф Банке и о переходе от парадигмы классического DWH к парадигме Data Lake.
Свой рассказ я хочу начать с такой вот веселой картинки:

Да, ещё несколько лет назад картинка была актуальной. Но сейчас, с развитием технологий, входящих в эко-систему Hadoop и развитием ETL платформ правомерно утверждать то, что ETL на Hadoop не просто существует но и то, что ETL на Hadoop ждет большое будущее. Далее в статье расскажу про то, как мы строим ETL на Hadoop в Тинькофф Банке.
От задачи к реализации
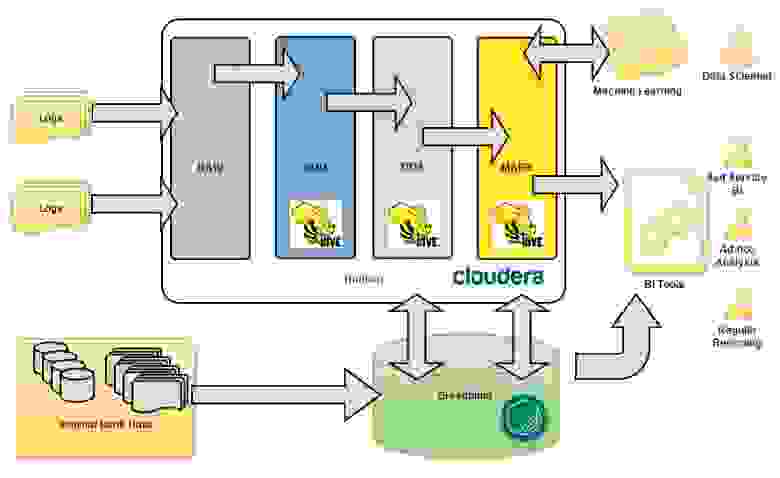
Перед управлением DWH была поставлена большая задача – анализировать интересы и поведение интернет посетителей сайта банка. У DWH образовалось два новых источника данных, больших данных – это clickstream с портала (www.tinkoff.ru) и RTB (Real-Time Bidding) платформа банка. Два источника порождают колоссальный объём текстовых полуструктурированных данных, что конечно для традиционного DWH, построенного в банке на массивно параллельной СУБД Greenplum, совсем не подходит. В банке был развернут кластер Hadoop, на основе дистрибутива Cloudera, он то и лег в основу целевого хранилища данных, а точнее озера данных, для внешних данных.
Концепция построения озера
Важно было на начальных этапах продумать и зафиксировали концептуальную архитектуру, которой нужно будет придерживаться в ходе моделирования новых структур для хранения данных и работы по загрузке данных. Мы очень не хотели превратить наше озеро в болото данных 🙂 Как и в классическом DWH, мы выделили основные концептуальные слои данных (см. Рис. 1).
Data Vault и как мы его готовим
Проанализировав тренды развития технологий Hadoop, мы решили использовать этот подход и засучив рукава принялись моделировать Data Vault для выше озвученной задачи.
Собственно, хочу рассказать несколько концептов, которые мы используем. Например, в загрузке визитов интернет-пользователей по страницам мы не сохраняем каждый раз URL визита. Все URL-ы мы выделили, в терминах Data Vault, в отдельный хаб (см. Рис. 2). Такой подход позволяет значительно сэкономить место в HDFS и более гибко работать с URL-ами на этапе загрузки и дальнейшей обработки данных.
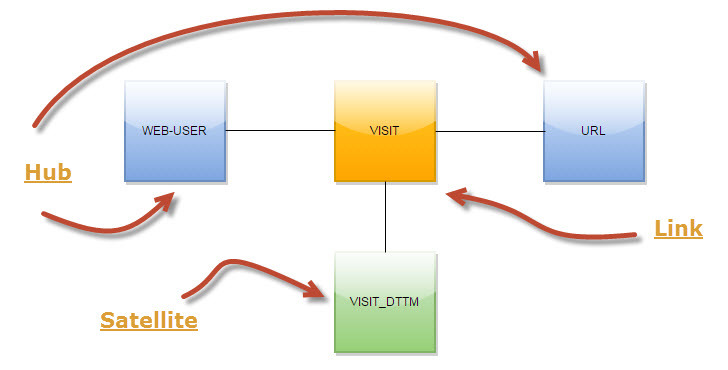
Рис.2 Data Vault для визитов
Ещё один концепт относится к области загрузки интернет пользователей. Мы не получаем на этапе загрузки в DDS единого интернет пользователя, а загружаем данные в разрезе систем источников. Таким образом загрузки в Data Vault из разных источников не зависят друг от друга.
Реки ETL в озере данных
Вот и подошли к самому интересному. Концепцию продумали, моделирование провели, создали структуры данных, теперь хорошо бы было бы это все наполнить данными.
Для того что бы обеспечить стабильный поток данных (файлов) в слой RAW мы используем Apache Flume. Для обеспечения отказоустойчивости и независимости от кластера Hadoop мы разместили Flume на отдельном сервере – получили такой как бы File Gate, перед кластером Hadoop. Ниже приведу пример настройки агента Flume для передачи портального syslog:
Таким образом, мы получили стабильный поток данных в слой RAW. Дальше нужно разложить эти данные в модель, наполнить Data Vault, ну короче нужен ETL на Hadoop.
Барабанная дробь, гаснет свет, на сцену выходит Informatica Big Data Edition. Не буду в красках и много рассказывать про этот ETL инструмент, постараюсь коротко и по делу.
Лирическое отступление. Хочется сразу отметить, что Informatica Platform (в которую входит BDE), это не та всем знакомая Informatica PowerCenter. Это принципиально новая платформа интеграции данных от корпорации Informatica, на которую сейчас постепенно переносят весь тот большой набор полезных функций из старого и всеми любимого PowerCenter.
Теперь по делу. Informatica BDE позволяет достаточно быстро разрабатывать ETL процедуры (маппинги), среда очень удобная и не требует длительного обучения. Маппинг транслируется в HiveQL и выполняется на кластере Hadoop, Informatica обеспечивает удобный мониторинг, последовательность запуска ETL процессов, обработку ветвлений и исключительных ситуаций.
Например, вот так выглядит маппинг, который наполняет хаб интернет юзеров нашего портала (см. Рис. 3).
Оптимизатор Informatica BDE транслирует этот маппинг в HiveQL и сам определяет шаги исполнения (см. Рис. 4).

Рис.4 План выполнения
Informatica BDE позволяет гибко управлять параметрами среды выполнения. Например, мы у себя настроили следующие параметры:
Маппинги можно объединять в потоки. Например, у нас данные из отдельных систем источников загружаются в отдельных потоках (см. Рис. 5).

Рис.5 Поток загрузки данных
Informatica BDE обладает удобным инструментом администрирования и мониторинга (см. Рис. 6).
Рис.6 Мониторинг исполнения потока данных
Из преимуществ Informatica BDE можно выделить следующее:
Из недостатков можно выделить следующее:
В целом инструмент Informatica BDE весьма хорошо показал себя при работе с Hadoop и у нас на него дальше очень большие планы в части ETL на Hadoop. Думаю, в скором времени напишем ещё более предметные статьи о реализации ETL на Hadoop на Informatica BDE.
Результаты
100Gb текстовых логов и получаем в Data Vault примерно на порядок меньше данных, на основе которых собираются витрины данных. Загрузка в модель происходит на ночном регламенте, загружается дневной инкремент данных. Длительность загрузки составляет
2 часа. С этими данными, выполняя Ad-hoc запросы, работают аналитики через Hue и IPython.
Что такое озера данных и почему в них дешевле хранить big data
Сейчас все вокруг твердят про пользу big data. В итоге бизнес пытается работать с масштабными базами данных, но сталкивается с проблемой — все данные разнородные и неструктурированные, перед загрузкой в базы их нужно долго обрабатывать. В итоге работа с big data оказывается слишком сложной и дорогой, а часть данных теряется, хотя могла бы принести пользу в будущем.
Помочь с этим могут data lake — озера данных, которые помогают быстро и недорого работать с большими объемами неструктурированных данных. Расскажем о их особенностях, ключевых отличиях озер от обычных баз данных и о сферах, в которых они будут наиболее полезны.
Что такое data lake
На русский язык data lake переводится как «озеро данных». Оно представляет собой огромное хранилище, в котором разные данные хранятся в «сыром», то есть неупорядоченном и необработанном виде. Данные в data lake как рыба в озере, которая попала туда из реки, — вы точно не знаете, какая именно там рыба и где она находится. А чтобы «приготовить» рыбу, то есть обработать данные, ее нужно еще поймать.
Мы в своей жизни чаще всего сталкиваемся именно с неструктурированными данными. Видеоролики, книги, журналы, документы Word и PDF, аудиозаписи и фотографии — все это неструктурированные данные, и все они могут хранится в Data Lake.
Как работает озеро данных
Data lake — это огромное хранилище, которое принимает любые файлы всех форматов. Источник данных тоже не имеет никакого значения. Озеро данных может принимать данные из CRM- или ERP-систем, продуктовых каталогов, банковских программ, датчиков или умных устройств — любых систем, которые использует бизнес.
Уже потом, когда данные сохранены, с ними можно работать — извлекать по определенному шаблону в классические базы данных или анализировать и обрабатывать прямо внутри data lake.
Для этого можно использовать Hadoop — программное обеспечение, позволяющее обрабатывать большие объемы данных различных типов и структур. С его помощью собранные данные можно распределить и структурировать, настроить аналитику для построения моделей и проверки предположений, использовать машинное обучение.
Еще одним примером инструмента обработки данных в data lake являются BI-системы, помогающие бизнесу решать задачи углубленной аналитики (data mining), прогнозного моделирования, а также визуализировать полученные результаты. Область использования многогранна — от финансового менеджмента до управления рисками и маркетинга.
Чем озера данных отличаются от обычных баз данных
Ключевое отличие озер данных от обычных баз данных — структура. В базах данных хранятся только четко структурированные данные, а в озерах — неструктурированные, никак не систематизированные и неупорядоченные.
Пример: представим, что есть вольное художественное описание вашей целевой аудитории: «Девушки возрастом 20–30 лет, незамужние, обычно без детей, работающие на низких руководящих должностях. И мужчины 18–25 лет, женатые, без детей, без четкого места работы». Такое описание — неструктурированные данные, которые можно загрузить в data lake.
Чтобы эти данные о целевой аудитории стали структурированными, их нужно обработать и преобразовать в таблицу:
| Пол | Возраст | Семейный статус | Дети | Работа | |
| Портрет 1 | женский | 20–30 | в браке | нет | низкая руководящая должность |
| Портрет 2 | мужской | 18–25 | в браке | нет | любая |
В классической базе данных вы должны определить тип данных, проанализировать их, структурировать — и только потом записать в четко определенное место базы данных. Мы можем создать алгоритм, который работает с конкретными ячейками, потому что четко знаем, что хранится в этих ячейках.
В случае с озером данных информацию структурируют на выходе, когда вам понадобится извлечь данные или проанализировать их. При этом процесс анализа не влияет на сами данные в озере — они так и остаются неструктурированными, чтобы их было также удобно хранить и использовать для других целей.
Есть и другие различия между базами данных и озерами данных:
Полезность данных. В базах данных все данные полезны и актуальны для компании прямо сейчас. Данные, которые пока кажутся бесполезными, отсеиваются и теряются навсегда.
В озерах хранятся в том числе и бесполезные данные, которые могут пригодиться в будущем или не понадобиться никогда.
Типы данных. В базах хранятся таблицы с конкретными цифрами и текстом, распределенными по четкой структуре.
В озерах лежат любые данные: картинки, видео, звук, файлы, документы, разнородные таблицы.
Гибкость. У базы данных гибкость низкая — еще на старте нужно определить актуальные для нее типы данных и структуру. Если появятся данные новых форматов — базу придется перестраивать.
У озер гибкость максимальная, потому что ничего не нужно определять заранее. Если вы вдруг решите записывать новые данные, например, видео с камер для распознавания лиц, озеро не придется перестраивать.
Стоимость. Базы данных стоят дороже, особенно если требуется хранить много данных. Нужно организовывать сложную инфраструктуру и фильтрацию, все это требует денег.
Озеро данных стоит намного дешевле — вы платите исключительно за занятые гигабайты.
Понятность и доступность данных. Данные в базе легко смогут прочитать и понять любые сотрудники компании, с ними могут работать бизнес-аналитики.
Чтобы структурировать данные в озере требуются технические специалисты, например Data Scientist.
Сценарии использования. Базы данных идеальны для хранения важной информации, которая всегда должна быть под рукой, либо для основной аналитики.
В озерах данных хорошо хранить архивы неочищенной информации, которая может пригодиться в будущем. Еще там хорошо создавать большую базу для масштабной аналитики.
Кому и зачем нужны озера данных
Озера данных можно использовать в любом бизнесе, который собирает данные. Маркетинг, ритейл, IT, производство, логистика — во всех этих сферах можно собирать big data и загружать их в data lake для дальнейшей работы или анализа.
Часто озера используют для хранения важной информации, которая пока не используется в аналитике. Или даже для данных, которые кажутся бесполезными, но, вероятно, пригодятся компании в будущем.
Например, вы используете на производстве сложное оборудование, которое часто ломается. Вы внедряете IoT, интернет вещей — установили датчики для контроля за состоянием оборудования. Данные с этих датчиков можно собирать в Data Lake без фильтрации. Когда данных накопится достаточно, вы сможете их проанализировать и понять, из-за чего случаются поломки и как их предотвратить.
Или можно использовать data lake в маркетинге. Например, в ритейле и e-commerce можно хранить в data lake разрозненную информацию о клиентах: время, проведенное на сайте, активность в группе в соцсетях, тон голоса при звонках менеджеру и регулярность покупок. Потом эту информацию можно использовать для глобальной и масштабной аналитики и прогнозирования поведения клиентов.
Таким образом, озера данных нужны для гибкого анализа данных и построения гипотез. Они позволяют собрать как можно больше данных, чтобы потом с помощью инструментов машинного обучения и аналитики сопоставлять разные факты, делать невероятные прогнозы, анализировать информацию с разных сторон и извлекать из данных все больше пользы.
Исследование ANGLING FOR INSIGHT IN TODAY’S DATA LAKE показывает, что компании, внедрившие Data Lake, на 9% опережают своих конкурентов по выручке. Так что можно сказать, что озера данных нужны компаниям, которые хотят зарабатывать больше, используя для этого анализ собственных данных.
Чем опасны data lake
У озер данных есть одна серьезная проблема. Любые данные, попадающие в data lake, попадают туда практически бесконтрольно. Это значит, что определить их качество невозможно. Если у компании нет четкой модели данных, то есть понимания типов структур данных и методов их обработки, плохо организовано управление озером, в нем быстро накапливаются огромные объемы неконтролируемых данных, чаще всего бесполезных. Уже непонятно, откуда и когда они пришли, насколько релевантны, можно ли их использовать для аналитики.
В итоге наше озеро превращается в болото данных — бесполезное, пожирающее ресурсы компании и не приносящее пользы. Все, что с ним можно сделать, — полностью стереть и начать собирать данные заново.
Чтобы озеро не стало болотом, нужно наладить в компании процесс управления данными — data governance. Главная составляющая этого процесса — определение достоверности и качества данных еще до загрузки в data lake. Есть несколько способов это сделать:
Настроить такую фильтрацию проще, чем каждый раз структурировать данные для загрузки в базу данных. Если процесс налажен, в data lake попадут только актуальные данные, а значит, и сама база будет достоверной.
Управление данными — это не факультативная, а приоритетная задача. В компании должен быть отдельный сотрудник, ответственный за data governance. Обычно это Chief Data Officer, CDO.



