
Доброго времени суток! Apache Kafka – очень быстрый распределенный брокер сообщений, и сегодня я расскажу как его “готовить” и реализовать с его помощью простую микросервисную архитектуру из консольных приложений. Итак, всем, кто хочет познакомиться с Apache Kafka и опробовать ее в деле, добро пожаловать под кат.
Обзорная часть
Введение
Итак, что мы в итоге создадим? Приложение, которое подскажет, как назвать своего ребенка. Для простоты, оно будет выдавать случайные мужские и женские имена из заранее составленного списка. Система будет состоять из двух консольных приложений и одной библиотеки.
Идея в том, чтобы построить не “монолитное”, а распределенное приложение. Тем самым, мы обеспечим себе задел для будущего масштабирования и множество других преимуществ, описанных, например, здесь.
Вот какая структура будет у нашей системы:
 3 синих “прямоугольника” по сторонам – это консольные приложения. По сути, те два, что внизу, это микросервисы, а MainApp – пользовательское приложение, через него мы будем запрашивать имена. NameService у нас будет универсальным сервисом, способным генерировать либо мужские, либо женские имена.
3 синих “прямоугольника” по сторонам – это консольные приложения. По сути, те два, что внизу, это микросервисы, а MainApp – пользовательское приложение, через него мы будем запрашивать имена. NameService у нас будет универсальным сервисом, способным генерировать либо мужские, либо женские имена.
Оранжевый “прямоугольник” посередине – брокер сообщений Apache Kafka. Брокер сообщений это то, что связывает все части нашей системы воедино. В нашем случае мы будем использовать Apache Kafka, но с таким же успехом могли бы воспользоваться RabbitMQ, ActiveMQ, или каким-нибудь еще.
А вот так происходит взаимодействие MainApp c Apache Kafka:
Работает это по следующей схеме:
Обратите внимание, MainApp ничего не знает о NameService, и наоборот. Все взаимодействие происходит через Apache Kafka. Но и MainApp, и NameService должны использовать одни и те же «каналы связи». На практике это означает, что, например, название топика, куда посылает сообщения MainApp, должно полностью совпадать с названием топика, из которого «слушает» сообщения NameService.
Как видите, работа Apache Kafka в нашем примере заключается в передаче сообщений между разными элементами системы. Именно этим, исключительно быстро и надежно, она и занимается. Конечно, у нее есть другие возможности, почитать о них можно на официальном сайте здесь
Что такое Apache Kafka
Apache Kafka – распределенный брокер сообщений. По сути, это система, которая может очень быстро и эффективно передавать ваши сообщения. В качестве сообщений могут выступать любые типы данных, поскольку для Kafka это всего лишь последовательность байтов. Apache Kafka может работать как на одной машине, так и на нескольких, которые вместе образуют кластер и повышают эффективность всей системы. В нашем случае мы запустим Apache Kafka локально, и для взаимодействия с ней будем использовать библиотеку от Confluent.
Важно понять то, как работает Apache Kafka. Мы можем писать в нее сообщения, и можем читать из нее. Все сообщения в Kafka принадлежат к тому или иному топику (topic). Топик – это как заглавие, и он должен быть определен для каждого сообщения, которое мы хотим передать в Apache Kafka. Точно также, если мы собираемся читать из Kafka сообщения, мы должны указать, с каким топиком будут эти сообщения.
Топик поделен на разделы, и их количество мы указываем, как правило, самостоятельно. Количество разделов в топике имеет большое значение для производительности, почитать об этом можно тут
Практическая часть
Скачиваем и запускаем Apache Kafka 0.11
На данный момент последней версией является версия 0.11. Скачайте архив с официального сайта (https://kafka.apache.org/downloads) и распакуйте в любую папку. Дальше из консоли надо запустить 2 файла (zookeeper-server.start и kafka-server-start) следующим образом.
Открываем первую консоль (если распаковали на диск С, открываем от имени Администратора, на всякий случай), переходим туда, где мы распаковали наш архив с Kafka, и вводим команду:
bin\windows\zookeeper-server-start.bat config\zookeeper.properties
После этого, если все хорошо и этот процесс не прекратился вскоре после старта, открываем так же вторую консоль, и запускаем уже саму Apache Kafka
bin\windows\kafka-server-start.bat config\server.properties
Только что мы запустили Zookeeper и Apache Kafka со стандартными настройками, указанными в zookeeper.properties и server.properties соответственно. Zookeeper – необходимый элемент, без него Apache Kafka не работает.
Полную информацию о запуске и конфигурировании Kafka можно посмотреть на официальном сайте
Начинаем кодить
Наша библиотека — это “обертка” вокруг библиотеки Confluent.Kafka, она нам нужна для взаимодействия с Apache Kafka. Кроме этого, она будет использоваться каждым из наших консольных приложений.
Далее мы построим “главное” приложение MainApp, а потом наш “микросервис” NameService, который запустим после в двух экземплярах. Каждый из них будет отвечать за генерацию либо мужских, либо женских имен.
Видели много строковых readonly переменных вначале? Это названия всех топиков и сообщения, которые мы будем в них посылать. Иначе говоря, заглавия и текст сообщений. О них должны знать все сервисы, с которыми будет взаимодействовать наш MainApp, потому как названия топиков должны совпадать. Например, bTopicNameCmd — название топика для команды сервису о том, что нам надо получить мужское имя (gTopicNameCmd — аналогично). Сервис должен быть подписан на одноименный топик, чтобы получать из него сообщения и потом что-то делать.
Точно также, наш MainApp подписан на топики, в которые передают полезную информацию наши сервисы NameService. Например, переменная bTopicNameResp — это название топика, который предусмотрен для готовых мужских имен, которые сгенерировал NameService. Сервис посылает имя в этот топик, а MainApp их оттуда получает.
Далее представлен код “микросервиса” NameService. Обратите, внимание, здесь тоже надо добавить ссылку на уже созданную нами библиотеку в пространстве имен MessageBroker.Kafka.Lib
Сервис работает по следующей схеме:
Запускаем
На этом этапе у вас, по идее, уже должно быть готовое решение со всем необходимым кодом. Далее можно поступить следующим образом: настроить решение так, чтобы запускались сразу 2 приложения (MainApp и NameService), и запустить их (Только проверьте, что у вас уже запущена Apache Kafka). В NameService вводим ‘b’, или ‘g’, чтобы настроить сервис для генерирования мужских или женских имен, после чего, точно также, вводим в MainApp ‘b’ или ‘g’, но уже для получения этих самых имен. После чего в MainApp вы должны получить какое-то имя.
На данном этапе мы получаем имена только одного пола. Допустим, только мужского. Теперь мы захотели получать имена женского пола. Идем в папку, куда собрался наш проект NameService, и запускаем в консоли еще один сервис с помощью команды «dotnet NameService.dll«.
Вводим в нем команду ‘g’, и теперь, при запросе женского имени в MainApp, мы его получаем.
Кстати, таким образом можно запустить сколько угодно сущностей NameService, и в этом заключается одно из достоинств микросервисной архитектуры. Например, если один из сервисов «упадет», вся система не рухнет, т.к. у нас есть другие сервисы, которые делают точно такую же работу.
Одно но: cейчас если мы, например, запустим 5 штук NameService, то в MainApp придет 5 имен, а не одно. Это из-за настроек Apache Kafka, прописанных в файле server.properties. В рамках туториала я этого намеренно не касаюсь, чтобы не усложнять материал.
Заключение
В данной статье я хотел как можно проще и доступнее описать принцип построения микросервисной архитектуры и познакомить читателя с распределенным брокером сообщений Apache Kafka на живом примере. Надеюсь, получилось, и спасибо за внимание:)
Kafka и микросервисы: обзор
Всем привет. В этой статье я расскажу, почему мы в Авито девять месяцев назад выбрали Kafka, и что она из себя представляет. Поделюсь одним из кейсов использования — брокер сообщений. И напоследок поговорим о том, какие плюсы мы получили от применения подхода Kafka as a Service.
Проблема
Для начала немного контекста. Некоторое время назад мы начали уходить от монолитной архитектуры, и сейчас в Авито уже несколько сотен различных сервисов. Они имеют свои хранилища, свой стек технологий и отвечают за свою часть бизнес-логики.
Одна из проблем с большим числом сервисов — коммуникации. Сервис А часто хочет узнать информацию, которой располагает сервис Б. В этом случае сервис А обращается к сервису Б через синхронный API. Сервис В хочет знать, что происходит у сервисов Г и Д, а те, в свою очередь, интересуются сервисами А и Б. Когда таких «любопытных» сервисов становится много, связи между ними превращаются в запутанный клубок.
При этом в любой момент сервис А может стать недоступен. И что делать в этом случае сервису Б и всем остальным завязанным на него сервисам? А если для выполнения бизнес-операции необходимо совершить цепочку последовательных синхронных вызовов, вероятность отказа всей операции становится еще выше (и она тем выше, чем длиннее эта цепочка).
Выбор технологии
Окей, проблемы понятны. Устранить их можно, сделав централизованную систему обмена сообщениями между сервисами. Теперь каждому из сервисов достаточно знать только про эту систему обмена сообщениями. В дополнение сама система должна быть отказоустойчивой и горизонтально масштабируемой, а также в случае аварий копить в себе буфер обращения для последующей их обработки.
Давайте теперь выберем технологию, на которой будет реализована доставка сообщений. Для этого сперва поймем, чего мы от нее ожидаем:
Также нам критически важно было выбрать максимально масштабируемую и надежную систему с высокой пропускной способностью (не менее 100k сообщений по несколько килобайт в секунду).
На этом этапе мы распрощались с RabbitMQ (сложно сохранять стабильным на высоких rps), PGQ от SkyTools (недостаточно быстрый и плохо масштабируемый) и NSQ (не персистентный). Все эти технологии у нас в компании используются, но под решаемую задачу они не подошли.
Далее мы начали смотреть на новые для нас технологии — Apache Kafka, Apache Pulsar и NATS Streaming.
Первым отбросили Pulsar. Мы решили, что Kafka и Pulsar — довольно похожие между собой решения. И несмотря на то, что Pulsar проверен крупными компаниями, новее и предлагает более низкую latency (в теории), мы решили из этих двух оставить Kafka, как de facto стандарт для таких задач. Вероятно, мы вернемся к Apache Pulsar в будущем.
И вот остались два кандидата: NATS Streaming и Apache Kafka. Мы довольно подробно изучили оба решения, и оба они подошли под задачу. Но в итоге мы побоялись относительной молодости NATS Streaming (и того, что один из основных разработчиков, Tyler Treat, решил уйти из проекта и начать свой собственный — Liftbridge). При этом Clustering режим NATS Streaming не давал возможности сильного горизонтального масштабирования (вероятно, это уже не проблема после добавления partitioning режима в 2017 году).
Тем не менее, NATS Streaming – крутая технология, написанная на Go и имеющая поддержку Cloud Native Computing Foundation. В отличие от Apache Kafka, ей не нужен Zookeeper для работы (возможно, скоро можно будет сказать то же самое и о Kafka), так как внутри она реализует RAFT. При этом NATS Streaming проще в администрировании. Мы не исключаем, что в дальнейшем ещё вернемся к этой технологии.
И всё-таки на сегодняшний день нашим победителем стала Apache Kafka. На наших тестах она показала себя достаточно быстрой (более миллиона сообщений в секунду на чтение и на запись при объеме сообщений 1 килобайт), достаточно надежной, хорошо масштабируемой и проверенной опытом в проде крупными компаниями. Кроме этого, Kafka поддерживает как минимум несколько крупных коммерческих компаний (мы, например, пользуемся Confluent версией), а также Kafka имеет развитую экосистему.
Обзор Kafka
Перед тем как начать, сразу порекомендую отличную книгу — «Kafka: The Definitive Guide» (есть и в русском переводе, но термины немного ломают мозг). В ней можно найти информацию, необходимую для базового понимания Kafka и даже немного больше. Сама документация от Apache и блог от Confluent также отлично написаны и легко читаются.
Итак, давайте посмотрим на то, как устроена Kafka с высоты птичьего полета. Базовая топология Kafka состоит из producer, consumer, broker и zookeeper.
Broker
За хранение ваших данных отвечает брокер (broker). Все данные хранятся в бинарном виде, и брокер мало знает про то, что они из себя представляют, и какова их структура.
Каждый логический тип событий обычно находится в своем отдельном топике (topic). Например, событие создания объявления может попадать в топик item.created, а событие его изменения — в item.changed. Топики можно рассматривать как классификаторы событий. На уровне топика можно задать такие конфигурационные параметры, как:
В свою очередь, каждый топик разбивается на одну и более партицию (partition). Именно в партиции в итоге попадают события. Если в кластере более одного брокера, то партиции будут распределены по всем брокерам равномерно (насколько это возможно), что позволит масштабировать нагрузку на запись и чтение в один топик сразу на несколько брокеров.
На диске данные для каждой партиции хранятся в виде файлов сегментов, по умолчанию равных одному гигабайту (контролируется через log.segment.bytes). Важная особенность — удаление данных из партиций (при срабатывании retention) происходит как раз сегментами (нельзя удалить одно событие из партиции, можно удалить только целый сегмент, причем только неактивный).
Zookeeper
Zookeeper выполняет роль хранилища метаданных и координатора. Именно он способен сказать, живы ли брокеры (посмотреть на это глазами zookeeper можно через zookeeper-shell командой ls /brokers/ids ), какой из брокеров является контроллером ( get /controller ), находятся ли партиции в синхронном состоянии со своими репликами ( get /brokers/topics/topic_name/partitions/partition_number/state ). Также именно к zookeeper сперва пойдут producer и consumer, чтобы узнать, на каком брокере какие топики и партиции хранятся. В случаях, когда для топика задан replication factor больше 1, zookeeper укажет, какие партиции являются лидерами (в них будет производиться запись и из них же будет идти чтение). В случае падения брокера именно в zookeeper будет записана информация о новых лидер-партициях (с версии 1.1.0 асинхронно, и это важно).
В более старых версиях Kafka zookeeper отвечал и за хранение оффсетов, но сейчас они хранятся в специальном топике __consumer_offsets на брокере (хотя вы можете по-прежнему использовать zookeeper для этих целей).
Самым простым способом превратить ваши данные в тыкву является как раз потеря информации с zookeeper. В таком сценарии понять, что и откуда нужно читать, будет очень сложно.
Producer
Producer — это чаще всего сервис, осуществляющий непосредственную запись данных в Apache Kafka. Producer выбирает topic, в котором будут храниться его тематические сообщения, и начинает записывать в него информацию. Например, producer’ом может быть сервис объявлений. В таком случае он будет отправлять в тематические топики такие события, как «объявление создано», «объявление обновлено», «объявление удалено» и т.д. Каждое событие при этом представляет собой пару ключ-значение.
По умолчанию все события распределяются по партициям топика round-robin`ом, если ключ не задан (теряя упорядоченность), и через MurmurHash (ключ), если ключ присутствует (упорядоченность в рамках одной партиции).
Здесь сразу стоит отметить, что Kafka гарантирует порядок событий только в рамках одной партиции. Но на самом деле часто это не является проблемой. Например, можно гарантированно добавлять все изменения одного и того же объявления в одну партицию (тем самым сохраняя порядок этих изменений в рамках объявления). Также можно передавать порядковый номер в одном из полей события.
Consumer
Consumer отвечает за получение данных из Apache Kafka. Если вернуться к примеру выше, consumer’ом может быть сервис модерации. Этот сервис будет подписан на топик сервиса объявлений, и при появлении нового объявления будет получать его и анализировать на соответствие некоторым заданным политикам.
Apache Kafka запоминает, какие последние события получил consumer (для этого используется служебный топик __consumer__offsets ), тем самым гарантируя, что при успешном чтении consumer не получит одно и то же сообщение дважды. Тем не менее, если использовать опцию enable.auto.commit = true и полностью отдать работу по отслеживанию положения consumer’а в топике на откуп Кафке, можно потерять данные. В продакшен коде чаще всего положение консьюмера контролируется вручную (разработчик управляет моментом, когда обязательно должен произойти commit прочитанного события).
В тех случаях, когда одного consumer недостаточно (например, поток новых событий очень большой), можно добавить еще несколько consumer, связав их вместе в consumer group. Consumer group логически представляет из себя точно такой же consumer, но с распределением данных между участниками группы. Это позволяет каждому из участников взять свою долю сообщений, тем самым масштабируя скорость чтения.
Результаты тестирования
Здесь не буду писать много пояснительного текста, просто поделюсь полученными результатами. Тестирование проводилось на 3 физических машинах (12 CPU, 384GB RAM, 15k SAS DISK, 10GBit/s Net), брокеры и zookeeper были развернуты в lxc.
Тестирование производительности
В ходе тестирования были получены следующие результаты.
Тестирование отказоустойчивости
В ходе тестирования были получены следующие результаты (3 брокера, 3 zookeeper).
Kafka as a service

Мы убедились, что Kafka — отличная технология, которая позволяет решить поставленную перед нами задачу (реализацию брокера сообщений). Тем не менее, мы решили запретить сервисам напрямую обращаться к Kafka и закрыли ее сверху сервисом data-bus. Зачем мы это сделали? На самом деле есть целых несколько причин.
Data-bus забрал на себя все задачи, связанные с интеграцией с Kafka (реализация и настройка consumer’ов и producer’ов, мониторинг, алертинг, логирование, масштабирование и т.д.). Таким образом, интеграция с брокером сообщений происходит максимально просто.
Data-bus позволил абстрагироваться от конкретного языка или библиотеки для работы с Kafka.
Data-bus позволил другим сервисам абстрагироваться от слоя хранения. Может быть, в какой-то момент мы поменяем Kafka на Pulsar, и при этом никто ничего не заметит (все сервисы знают только про API data-bus).
Data-bus взял на себя валидацию схем событий.
С помощью data-bus реализована аутентификация.
Под прикрытием data-bus мы можем без даунтайма, незаметно обновлять версии Kafka, централизованно вести конфигурации producer’ов, consumer’ов, брокеров и т.д.
Data-bus позволил добавлять необходимые нам фичи, которых нет в Kafka (такие как аудит топиков, контроль за аномалиями в кластере, создание DLQ и т.д.).
Data-bus позволяет реализовать failover централизованно для всех сервисов.
На данный момент для начала отправки событий в брокер сообщений достаточно подключить небольшую библиотеку в код своего сервиса. Это всё. У вас появляется возможность писать, читать и масштабироваться одной строчкой кода. Вся реализация скрыта от вас, наружу торчит только несколько ручек типа размера батча. Под капотом сервис data-bus поднимает в Kubernetes нужное количество инстансов producer’ов и consumer’ов и подкладывает им нужную конфигурацию, но все это для вашего сервиса прозрачно.
Конечно, серебряной пули не бывает, и у такого подхода есть свои ограничения.
В нашем случае плюсы перевесили минусы, и решение прикрыть брокер сообщений отдельным сервисом оправдалось. За год эксплуатации у нас не было никаких серьезных аварий и проблем.
What is Confluent Platform?В¶
Sign up for Confluent Cloud or download Confluent Platform to get started.
Confluent Platform is a full-scale data streaming platform that enables you to easily access, store, and manage data as continuous, real-time streams. Built by the original creators of Apache Kafka®, Confluent expands the benefits of Kafka with enterprise-grade features while removing the burden of Kafka management or monitoring. Today, over 80% of the Fortune 100 are powered by data streaming technology – and the majority of those leverage Confluent.
Why Confluent?В¶
By integrating historical and real-time data into a single, central source of truth, Confluent makes it easy to build an entirely new category of modern, event-driven applications, gain a universal data pipeline, and unlock powerful new use cases with full scalability, performance, and reliability.
What is Confluent Used For?В¶
Confluent Platform lets you focus on how to derive business value from your data rather than worrying about the underlying mechanics, such as how data is being transported or integrated between disparate systems. Specifically, Confluent Platform simplifies connecting data sources to Kafka, building streaming applications, as well as securing, monitoring, and managing your Kafka infrastructure. Today, Confluent Platform is used for a wide array of use cases across numerous industries, from financial services, omnichannel retail, and autonomous cars, to fraud detection, microservices, and IoT.
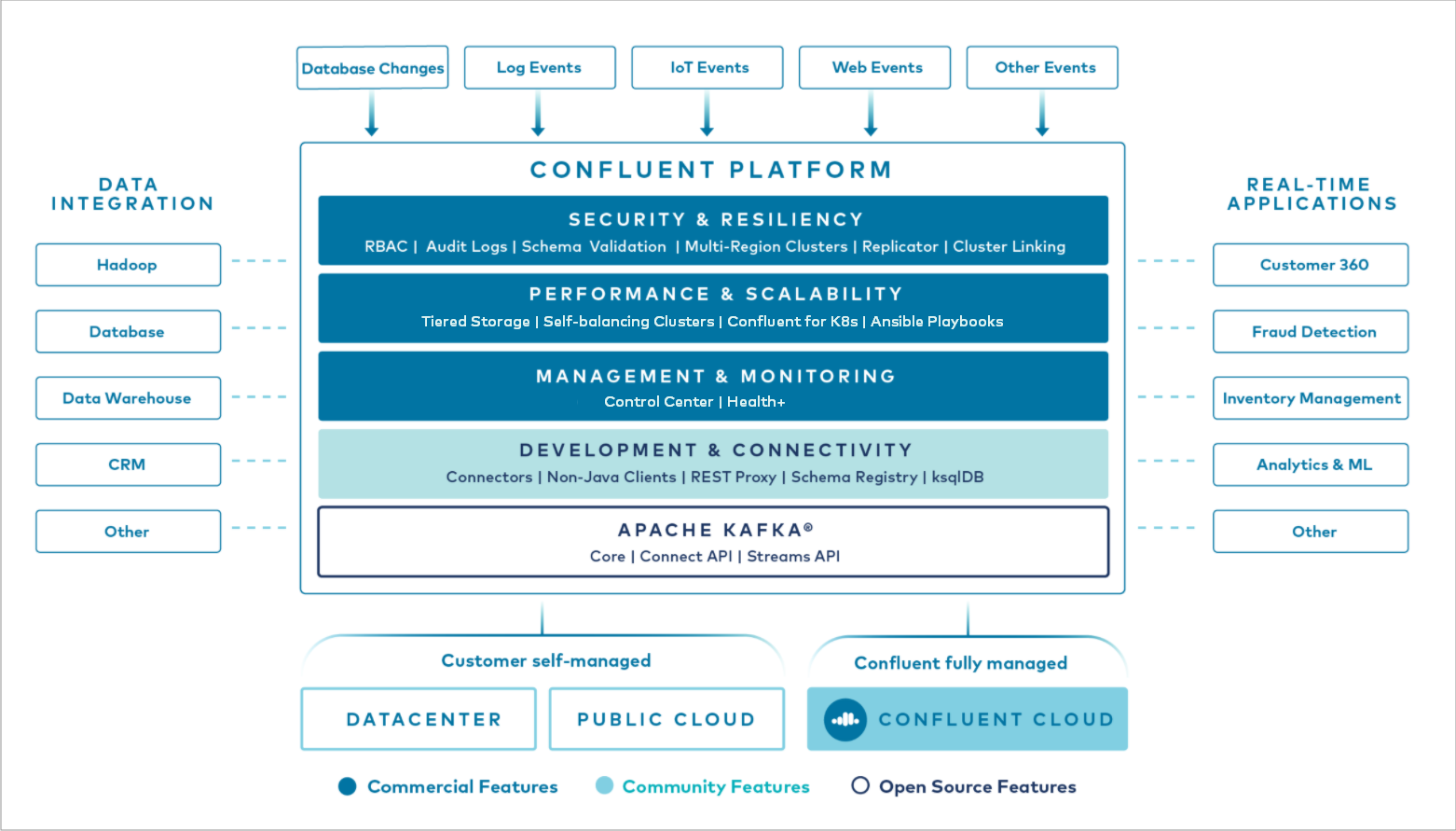
Confluent Platform Components В¶
Overview of Confluent’s Event Streaming Technology¶
At the core of Confluent Platform is Apache Kafka, the most popular open source distributed streaming platform. The key capabilities of Kafka are:
Out of the box, Confluent Platform also includes Schema Registry, REST Proxy, a total of 100+ pre-built Kafka connectors, and ksqlDB.
Why Kafka?В¶
Kafka is used by 60% of Fortune 500 companies for a variety of use cases, including collecting user activity data, system logs, application metrics, stock ticker data, and device instrumentation signals.
The key components of the Kafka open source project are Kafka Brokers and Kafka Java Client APIs.
Each release of Confluent Platform includes the latest release of Kafka and additional tools and services that make it easier to build and manage an Event Streaming Platform. Confluent Platform delivers both community and commercially licensed features that complement and enhance your Kafka deployment.
Overview of Confluent Platform’s Enterprise Features¶
Confluent Control Center¶
Confluent Control Center is a GUI-based system for managing and monitoring Kafka. It allows you to easily manage Kafka Connect, to create, edit, and manage connections to other systems. It also allows you to monitor data streams from producer to consumer, assuring that every message is delivered, and measuring how long it takes to deliver messages. Using Control Center, you can build a production data pipeline based on Kafka without writing a line of code. Control Center also has the capability to define alerts on the latency and completeness statistics of data streams, which can be delivered by email or queried from a centralized alerting system.
Confluent for Kubernetes¶
Confluent for Kubernetes is a Kubernetes operator. Kubernetes operators extend the orchestration capabilities of Kubernetes by providing the unique features and requirements for a specific platform application. For Confluent Platform, this includes greatly simplifying the deployment process of Kafka on Kubernetes and automating typical infrastructure lifecycle tasks.
Confluent Connectors to Kafka¶
Connectors leverage the Kafka Connect API to connect Kafka to other systems such as databases, key-value stores, search indexes, and file systems.
Confluent Hub has downloadable connectors for the most popular data sources and sinks. These include fully tested and supported versions of these connectors with Confluent Platform. See the following documentation for more information:
Confluent provides both commercial and Community licensed connectors. See Confluent Hub for details, and to download connectors.
Self-Balancing Clusters¶
Self-Balancing Clusters provides automated load balancing, failure detection and self-healing. It provides support for adding or decommissioning brokers as needed, with no manual tuning. Self-Balancing is the next iteration of Auto Data Balancer in that Self-Balancing auto-monitors clusters for imbalances, and automatically triggers rebalances based on your configurations. (You can choose to auto-balance Only when brokers are added or Anytime.)
Partition reassignment plans and execution are taken care of for you.
Confluent Cluster Linking¶
Cluster Linking directly connects clusters together and mirrors topics from one cluster to another over a link bridge. Cluster Linking simplifies setup of multi-datacenter, multi-cluster, and hybrid cloud deployments.
Confluent Auto Data Balancer¶
As clusters grow, topics and partitions grow at different rates, brokers are added and removed and over time this leads to unbalanced workload across datacenter resources. Some brokers are not doing much at all, while others are heavily taxed with large or many partitions, slowing down message delivery. When executed, Confluent Auto Data Balancer monitors your cluster for number of brokers, size of partitions, number of partitions and number of leaders within the cluster. It allows you to shift data to create an even workload across your cluster, while throttling rebalance traffic to minimize impact on production workloads while rebalancing.
Confluent Replicator¶
Replicator makes it easier than ever to maintain multiple Kafka clusters in multiple data centers. Managing replication of data and topic configuration between data centers enables use-cases such as:
Tiered Storage¶
Tiered Storage provides options for storing large volumes of Kafka data using your favorite cloud provider, thereby reducing operational burden and cost. With Tiered Storage, you can keep data on cost-effective object storage, and scale brokers only when you need more compute resources.
Confluent JMS Client¶
Confluent Platform includes a JMS-compatible client for Kafka. This Kafka client implements the JMS 1.1 standard API, using Kafka brokers as the backend. This is useful if you have legacy applications using JMS, and you would like to replace the existing JMS message broker with Kafka. By replacing the legacy JMS message broker with Kafka, existing applications can integrate with your modern streaming platform without a major rewrite of the application.
Confluent MQTT Proxy¶
Provides a way to to publish data directly Kafka from MQTT devices and gateways without the need for a MQTT Broker in the middle.
Confluent Security Plugins¶
Confluent Security Plugins are used to add security capabilities to various Confluent Platform tools and products.
Community Features¶
ksqlDB¶
ksqlDB is the streaming SQL engine for Kafka. It provides an easy-to-use yet powerful interactive SQL interface for stream processing on Kafka, without the need to write code in a programming language such as Java or Python. ksqlDB is scalable, elastic, fault-tolerant, and real-time. It supports a wide range of streaming operations, including data filtering, transformations, aggregations, joins, windowing, and sessionization.
ksqlDB supports these use cases:
Streaming ETL Kafka is a popular choice for powering data pipelines. ksqlDB makes it simple to transform data within the pipeline, readying messages to cleanly land in another system. Materialized cache / views A materialized view is a query result that is precomputed (before a user or app actually runs the query) and stored for faster read access. ksqlDB supports the building of materialized views in Kafka as event streams for distributed materializations. Complexity is reduced by using Kafka for storage and ksqlDB for computation. Event-driven Microservices Provides support for modeling stateless, event-driven microservices in Kafka. Stateful stream processing is managed on a cluster of servers, while side-effects run inside your stateless microservice, which reads events from a Kafka topic and takes action as needed.
Confluent Connectors to Kafka¶
Connectors leverage the Kafka Connect API to connect Kafka to other systems such as databases, key-value stores, search indexes, and file systems. Confluent Hub has downloadable connectors for the most popular data sources and sinks.
Confluent provides both commercial and Community licensed connectors. See Confluent Hub for details, and to download connectors.
Confluent Clients¶
C/C++ Client Library¶
The library librdkafka is the C/C++ implementation of the Kafka protocol, containing both Producer and Consumer support. It was designed with message delivery, reliability and high performance in mind. Current benchmarking figures exceed 800,000 messages per second for the producer and 3 million messages per second for the consumer. This library includes support for many new features of Kafka 0.10, including message security. It also integrates easily with libserdes, our C/C++ library for Avro data serialization (supporting Schema Registry).
For more information, see the Kafka Clients documentation.
Python Client Library¶
A high-performance client for Python.
For more information, see the Kafka Clients documentation.
Go Client Library¶
Confluent Platform includes of a full-featured, high-performance client for Go.
For more information, see the Kafka Clients documentation.
.NET Client Library¶
For more information, see the Kafka Clients documentation.
Confluent Schema Registry¶
One of the most difficult challenges with loosely coupled systems is ensuring compatibility of data and code as the system grows and evolves. With a messaging service like Kafka, services that interact with each other must agree on a common format, called a schema, for messages. In many systems, these formats are ad hoc, only implicitly defined by the code, and often are duplicated across each system that uses that message type.
As requirements change, it becomes necessary to evolve these formats. With only an ad-hoc definition, it is very difficult for developers to determine what the impact of their change might be.
Schema Registry also includes plugins for Kafka clients that handle schema storage and retrieval for Kafka messages that are sent in the Avro format. This integration is seamless – if you are already using Kafka with Avro data, using Schema Registry only requires including the serializers with your application and changing one setting.
Confluent REST Proxy¶
Kafka and Confluent provide native clients for Java, C, C++, and Python that make it fast and easy to produce and consume messages through Kafka. These clients are usually the easiest, fastest, and most secure way to communicate directly with Kafka.
But sometimes, it isn’t practical to write and maintain an application that uses the native clients. For example, an organization might want to connect a legacy application written in PHP to Kafka. Or suppose that a company is running point-of-sale software that runs on cash registers, written in C# and running on Windows NT 4.0, maintained by contractors, and needs to post data across the public internet. To help with these cases, Confluent Platform includes a REST Proxy. The REST Proxy addresses these problems.
The Confluent REST Proxy makes it easy to work with Kafka from any language by providing a RESTful HTTP service for interacting with Kafka clusters. The REST Proxy supports all the core functionality: sending messages to Kafka, reading messages, both individually and as part of a consumer group, and inspecting cluster metadata, such as the list of topics and their settings. You can get the full benefits of the high quality, officially maintained Java clients from any language.
The REST Proxy also integrates with Schema Registry. It can read and write Avro data, registering and looking up schemas in Schema Registry. Because it automatically translates JSON data to and from Avro, you can get all the benefits of centralized schema management from any language using only HTTP and JSON.
Docker images of Confluent Platform¶
Docker images of Confluent Platform are available on Docker Hub, and detailed in the Confluent documentation on the Docker Image Reference page. Some of these images contain proprietary components that require a Confluent commercial license. These are identified cp-enterprise-$
Confluent CLI and other Command Line Tools¶
Confluent Platform ships a number of command line interface (CLI) tools, including the Confluent CLI. These are all listed under CLI Tools for Confluent Platform in the Confluent documentation, including both Confluent provided and Kafka utilities.



