Анализ покрытия кода тестами в Ruby
Для начала я приведу небольшой тестовый проект из трёх классов, проанализирую его покрытие с помощью гема SimpleCov, а напоследок немного поразмышляю о том, как анализ покрытия может приносить пользу проекту, и какие есть недостатки у Coverage в Ruby.

Подопытный проект
В качестве проекта для тестирования взята небольшая история о мальчике, который может спрашивать разрешения погулять у матери и у отца.
Покрываем тестами и смотрим покрытие
Тесты намеренно покрывают не все сценарии:
SimpleCov — фактически монополист в области анализа покрытия в мире Ruby 1.9.3+. Он является удобной обёрткой над модулем Coverage из стандартной библиотеки.
Подключение сводится к двум строкам в начале файла с тестами, при этом важно, чтобы инициализация SimpleCov проводилась до подключения файлов проекта. Запускаем тесты:
Voilà! Сгенерировался файл отчёт coverage/index.html. Посмотреть его можно по ссылке, а здесь я оставлю пару скриншотов, чтобы далеко не ходить (общий отчёт используется в качестве заглавной картинки).
father.rb
Выдержка из child.rb
Бонусы от анализа coverage
Второе возможное применение — автоматическое обеспечение «качества» коммитов. CI-сервер может отбраковывать коммиты, которые приводят к снижению total coverage, резко снижая вероятность появления в репозитории непротестированного кода.
Что анализ покрытия не даёт
Во-первых, стопроцентное покрытие не обеспечивает отсутствие багов. Простой пример: если изменить класс Mother таким образом:
покрытие класса останется 100%-ым, тесты будут по-прежнему зелёными, но логика будет очевидно неверной. Для автоматического определения «отсутствующих, но нужных» тестов можно использовать гем mutant. Я ещё не пробовал его в деле, но, судя по Readme и количеству звёзд на гитхабе, библиотека действительно полезна. Впрочем, это тема для отдельного поста, до которого я как-нибудь доберусь.
Во-вторых, в Ruby на данный момент возможен анализ покрытия только по строкам, branch- и condition-coverage не поддерживается. Имеется в виду, что в однострочниках вида
есть точки ветвления, но даже если тесты пройдут только по одной возможной ветви исполнения, coverage покажет 100%. Был pull request в Ruby на эту тему, но от мейнтейнеров уже два года ничего не слышно. А жаль.
Послесловие
Я предпочитаю писать тесты сразу же после написания кода, и coverage служит мне напоминалкой о ещё не протестированных методах (частенько забываю потестить обработчики исключений). В общем, анализ покрытия вполне может приносить определённую пользу, но 100%-е покрытие не обязательно говорит о том, что тестов достаточно.
Code Coverage — хочу верить
Разработчик обязан знать свои инструменты! Знание инструментов увеличивает продуктивность, эффективность, производительность, потенцию разработчика! Не могу программировать без R#!
Подобного рода фразы можно услышать от абсолютно разных людей: фанатиков разработки, продавцов различных утилит, пользователей удобных тулз. Слышит их и мой менеджер, когда мне хочется поэкспериментировать с чем-то новеньким.
Правда, инструкция к инструменту обычно не содержит раздел «Противопоказания», не указываются ситуации когда НЕ стоит применять утилиту. Между тем, подобный раздел мог бы сэкономить тонны времени на неудачные эксперименты.
Сегодня я пошвыряю камни в огород Code Coverage (CC). Достаточно полезная метрика, под которой лежат несколько скудно документированных граблей.
«Есть ложь, есть наглая ложь
есть статистика».
Создатели SonarQube это великолепно понимают, недаром у SonarQube с десяток CC метрик. Я буду перебивать статистику используя CC от DevExpress, там метрика лишь одна.
Проблема 1. Типичный тест не того. Протестируем метод с кучей проверок аргумента:
Метод покрыт тестами на 83%, чего обычно достаточно для авто-билда. Технически спорить не о чем, большая часть кода покрыта тестами, но основной сценарий тестами не затронут. Тестами покрыта наиболее простая часть кода, не наиболее важная.
Проблема 2. Замеряем актуальный код, вместо необходимого.
Тестируемый метод не содержит проверки на null аргумент, однако покрытие — 100%. Иногда люди забывают: Code Coverage — это метрика покрытия кода, не метрика закрытия требований; если в методе не достает логики (метод недостаточно сложен для решения своей задачи) — CC это не покажет.
100% покрытия не гарантируют работоспособности программы. Доводя до абсурда: пустой метод элементарно покрывается на 100%. Непустой метод покрывается на 100% тестами без Assert-ов.
Проблема 3. Оптимизм. Немного иное проявление предыдущей проблемы. Как видно, один тест покрывает 100% кода. Попробуем переписать наш метод, избавившись от LINQ (для улучшения производительности).
Получаем лишь 73% покрытия. Функциональность не изменилась, метрика упала. Мало того, что 100% покрытия не гарантируют работоспособности программы, эти 100% могут быть фейковыми. Вывод: LINQ — г**но результаты CC могут быть завышены, старайтесь проверять покрытие в редакторе.
Следствие: Используемый инструмент может не обладать всей желаемой функциональностью. Тривиальная вещь, не менее от того верная.
Проблема 4. Передача ответственности.
Метод покрывается на 100% одним тестом. При этом покрытие OuterLib библиотеки лежит на совести того, кто её добавил. Или обновил. Года три назад, до введения CC. До увольнения.
Приходится снова констатировать факт: мало того, что 100% покрытия не гарантируют работоспособности программы, эти 100% могут быть фейковыми.
Помимо чисто кодовых моментов есть несколько претензий именно к обработке результатов CC
Претензия 0, всем известная. 100% покрытия. Нет 100% покрытия — нет одобрения билда. Проблема в том, что первые проценты покрытия получить относительно просто, а вот последние… Особенно, когда часть кода генерируется. Или недостижима (поскольку создана для Васи, который будет её юзать через два дня). Или просто теоретически достижима, а пример подбирать\высчитывать пару недель (такое бывает при работе с математикой). Короче, большинство команд (из тех кто вообще интегрирует CC в CI) останавливаются на 60\70\80 процентах необходимого покрытия.
Претензия 1, спорная. Покрытие мертвого кода. На моей памяти схожая проблема особо ярко проявилась в ходе проверки Mirand-ы коллегами из PVS. Комментарии довольно эмоциональны, но часть споров касалась мертвого кода: часть найденных диагностик указывала на (заброшенные) плагины, но не на ядро.
Возникает вопрос: нужен ли CodeCoverage для мертвого кода? С одной стороны, мертвый код это проблема, и привлечение внимания к нему приветствуется. С другой стороны, мертвый код не влияет на продакшн, так стоит ли позволять ему влиять на CC метрику?
Претензия 2. Важность кода. Расширение проблемы 1. В моем проекте есть два примечательных контроллера: «оплата» и «переговорка». «Оплата» критична для клиента, и я вполне согласен с требованием «80% покрытия», «переговоркой» же пользуются 1.5 анонимуса. В год. И она не менялась уже два года. Вопрос: для чего писать тесты к полумертвой функциональности? Лишь для получения 80% бейджа одобрения автосборки?
Претензия 3, невозможная. Метрика как ачивка. Это когда никто не проверяет что именно покрыто. Помните байки про оплату за линии кода? Мне доводилось слышать про людей, которые творили ненужный кода для лучшего покрытия.
Претензия 4. Метрика «за бесплатно». Когда руководство скидывает требование «покрывайте код на 80%», и разработчики безропотно соглашаются. Проект при этом — одноразовый. Или прототип. Или дедлайн на носу. Или имеется здоровенный макаронный легаси монстр без единого теста.
Покрытие кода тестами требует времени! Если покрытие еще и замерять — время на тесты может и возрасти (хотя может и упасть). Так что если команда не успела сдать проект в срок, но зато достигла 80% покрытия — вина может поделиться между руководством и разработчиками. Вопрос линии раздела вины поднимать не стоит, ибо холивар.
Под конец. Еще раз замечу: СС — метрика полезная, хоть и с сюрпризами. Она реально помогает с контролем кода, если нет слепого стремления к цифрам в отчетах.
Покрытие кода
Что такое покрытие кода?
Покрытие кода — это мера, которая описывает степень тестирования исходного кода программы. Это одна из форм тестирования белого ящика, которая находит области программы, которые не выполняются набором тестовых случаев. Он также создает несколько тестовых случаев для увеличения покрытия и определения количественного показателя покрытия кода.
В большинстве случаев система покрытия кода собирает информацию о работающей программе. Он также сочетает это с информацией об исходном коде для создания отчета о покрытии кода комплекта тестов.
В этом уроке вы узнаете
Зачем использовать покрытие кода?
Вот несколько основных причин использования покрытия кода:
Методы покрытия кода
Ниже приведены основные методы покрытия кода.
Заявление покрытия
Что такое покрытие заявления?
Охват операторов — это метод проектирования теста белого ящика, который включает в себя выполнение всех исполняемых операторов в исходном коде как минимум один раз. Он используется для вычисления и измерения количества операторов в исходном коде, которые могут быть выполнены с учетом требований.
Охват операторов используется для выведения сценария на основе структуры тестируемого кода.

В White Box Testing тестер концентрируется на том, как работает программное обеспечение. Другими словами, тестер будет концентрироваться на внутренней работе исходного кода, касающегося управляющих потоковых диаграмм или блок-схем.
Давайте разберемся с этим на примере, как рассчитать покрытие выписки.
Сценарий для расчета покрытия оператора для данного исходного кода. Здесь мы используем два разных сценария, чтобы проверить процент покрытия выписок для каждого сценария.
Исходный код:
Сценарий 1:

Операторы, отмеченные желтым цветом, — это те операторы, которые выполняются в соответствии со сценарием.
Количество выполненных выписок = 5, Общее количество выписок = 7
Охват выписки: 5/7 = 71%

Аналогично мы увидим сценарий 2,
Сценарий 2:

Операторы, отмеченные желтым цветом, — это те операторы, которые выполняются согласно сценарию.
Количество выполненных заявлений = 6
Общее количество заявлений = 7

Охват выписки: 6/7 = 85%

Но в целом, если вы видите, все утверждения охватываются 2- м сценарием. Таким образом, мы можем сделать вывод, что общий охват отчетности составляет 100%.

Что входит в покрытие заявления?
Охват решений
Об охвате решений сообщается об истинных или ложных результатах каждого логического выражения. В этом покрытии выражения могут иногда усложняться. Поэтому очень сложно достичь 100% покрытия.
Вот почему существует много разных способов сообщения этой метрики. Все эти методы направлены на охват наиболее важных комбинаций. Это очень похоже на покрытие принятия решений, но обеспечивает лучшую чувствительность к потоку управления.

Пример покрытия решения
Рассмотрим следующий код:
Сценарий 1:

Код, выделенный желтым цветом, будет выполнен. Здесь «Нет» результат решения If (a> 5) проверяется.
Сценарий 2:
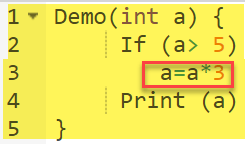
Код, выделенный желтым цветом, будет выполнен. Здесь «Да» результат решения Если (а> 5) проверяется.
| Прецедент | Значение А | Вывод | Охват решений |
| 1 | 2 | 2 | 50% |
| 2 | 6 | 18 | 50% |
Охват филиала
В зоне действия ветки проверяется каждый результат модуля кода. Например, если результаты являются бинарными, вам необходимо протестировать как истинные, так и ложные результаты.
Это помогает вам гарантировать, что каждая возможная ветвь из каждого условия решения выполняется по крайней мере один раз.
Используя метод покрытия Branch, вы также можете измерить долю независимых сегментов кода. Это также поможет вам узнать, какие разделы кода не имеют ветвей.
Формула для расчета покрытия филиала:
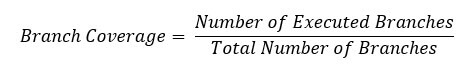
Пример покрытия филиала
Чтобы узнать охват ветвей, давайте рассмотрим тот же пример, который использовался ранее
Рассмотрим следующий код

Покрытие филиала также будет учитывать безусловное отделение
| Прецедент | Значение А | Вывод | Охват решений | Охват филиала |
| 1 | 2 | 2 | 50% | 33% |
| 2 | 6 | 18 | 50% | 67% |
Преимущества покрытия филиала:
Тестирование покрытия филиала предлагает следующие преимущества:
Состояние покрытия
Условное покрытие или покрытие выражений покажет, как оцениваются переменные или подвыражения в условном выражении. В этом покрытии рассматриваются только выражения с логическими операндами.
Например, если в выражении есть логические операции, такие как AND, OR, XOR, которые указывают общие возможности.
Условное покрытие обеспечивает лучшую чувствительность к потоку управления, чем покрытие принятия решения. Условие покрытия не дает гарантии о полном покрытии решения
Формула для расчета покрытия условий:


Для приведенного выше выражения у нас есть 4 возможных комбинации
Рассмотрим следующий вход
Состояние покрытия = 25%
Покрытие конечного автомата
Покрытие конечного автомата, безусловно, является наиболее сложным методом покрытия кода. Это потому, что это работает на поведение дизайна. В этом методе покрытия вам нужно посмотреть, сколько посещений, определенных для времени состояний, прошло. Он также проверяет, сколько последовательностей включено в конечный автомат.
Какой тип покрытия кода выбрать
Это, безусловно, самый сложный ответ. Чтобы выбрать метод покрытия, тестер должен проверить, что
Чем выше вероятность того, что дефекты повлекут за собой дорогостоящие производственные сбои, тем серьезнее уровень покрытия, который вам нужно выбрать.
Покрытие кода против функционального покрытия
| Покрытие кода | Функциональное покрытие |
| Покрытие кода говорит вам, насколько хорошо исходный код был использован вашим тестовым стендом. | Функциональный охват измеряет, насколько хорошо функциональность проекта была охвачена вашим испытательным стендом. |
| Никогда не используйте спецификацию проекта | Используйте проектную спецификацию |
| Сделано разработчиками | Сделано тестерами |
Инструменты покрытия кода
Вот список важных инструментов покрытия кода:
Полное покрытие кода
Инструмент тестирования nose
Изначальный пример кода
#!/usr/bin/env python
import operator
Код работает только на Python 2.6 и не совместим с Python 3. Код сохранен в файле main.py.
Юнит-тесты
Начнем с простых тестов:
import unittest
from main import factorial
OK
Добавим еще один класс для стопроцентного покрытия:
class FakeStream :
def readline ( self ):
return ‘5’
Выводы
Адаптация под Python 3
#!/usr/bin/env python
import operator
Теперь программу можно запускать:
$ python3 main.py
Enter the positive number: 0
0! = 1
Значит ли это, что программа рабочая? Нет! Она рабочая только до вызова reduce, что нам и показывают тесты:
$ nosetests3
E. E
======================================================================
ERROR: test_calculation (tests.TestFactorial)
———————————————————————-
Traceback (most recent call last):
File «/home/nuald/workspace/factorial/tests.py», line 9, in test_calculation
self.assertEqual(720, factorial(6))
File «/home/nuald/workspace/factorial/main.py», line 12, in factorial
return reduce(operator.mul, range(1, n + 1))
NameError: global name ‘reduce’ is not defined
FAILED (errors=2)
В данном примере все это можно было обнаружить и ручным тестированием. Однако на больших проектах только юнит-тестирование поможет обнаружить такого рода ошибки. И только полное покрытие кода может гарантировать что практически все несоответствия кода и API были устранены.
Ну и собственно, рабочий код, полностью совместимый между Python 2.6 и Python 3:
#!/usr/bin/env python
import operator
from functools import reduce
import sys
import unittest
from main import factorial
class FakeStream :
def readline ( self ):
return ‘5’
Проблемы тестирования: почему 100% покрытие кода это плохо
Недавно в нашем блоге мы рассказывали об использовании предметно-ориентированных языков для решения конкретных задач разработки с помощью Python. Сегодня речь пойдет о тестировании — в частности, о том, почему стопроцентное покрытие тестами кода это на самом деле плохо.
Материал подготовлен на основе выступления разработчика Positive Technologies Ивана Цыганова на конференции Moscow Python Conf (слайды, видео).
Зачем мы пишем тесты
ИБ-эксперты Positive Technologies проводят более 200 аудитов информационной безопасности в год, но мы прежде всего продуктовая компания. Один из наших продуктов — система контроля защищенности и соответствия стандартам MaxPatrol.
Продукт состоит из трех больших подсистем:
Нужно ли 100% покрытие
Здесь есть интересный момент — многие специалисты считают, что проверка покрытия тестами говорит о качестве тестирования. На самом деле это совершенно не так. Да, это хорошая ачивка («у нас 100% coverage!»), но это не означает того, что проект полностью протестирован. Стопроцентное покрытие говорит лишь о стопроцентном покрытии кода тестами, и ни о чем больше.
Для Python де-факто стандартом проверки покрытия является библиотека coverage.py. Она позволяет проверить покрытие кода тестами, у нее есть плагин для pytest. В основном, библиотека работает, но не всегда.
Пример — код ниже покрыт тестами на 100%. И в этом примере претензий к работе coverage.py нет.
Но на более сложной функции один тест дает 100% покрытие, при этом функция остается не протестированной. Мы не проверяем ситуацию, когда единственный ‘if’ функции обернется в False.
У библиотеки есть еще один режим работы, который позволяет отслеживать покрытие ветвей исполнения кода. Если запустить проверку в этом режиме, то будет видно, что не покрыт переход из третей в пятую строку кода. Это означает, что на всех запусках тестов мы никогда не попадали из третьей строки сразу в пятую, а всегда попадали в четвертую, то есть “if” на всех тестовых данных оборачивался в True.
Как считается покрытие
Существует простая формула для расчета покрытия кода тестами:
Coverage.py работает по такой схеме — сначала библиотека берет все исходники и прогоняет через собственный анализатор для получения списка инструкций. Этот анализатор обходит все токены и отмечает «интересные» с его точки зрения факты, затем компилирует код, обходит получившийся code-object и сохраняет номера строк. При обходе токенов он запоминает определения классов, «сворачивает» многострочные выражения и исключает комментарии.
Переходы между строками считаются примерно так же:
Опять берется исходный код и анализируется классом AstArcAnalyzer для получения пары значений — из какой строки в какую возможен переход. AstArcAnalyzer обходит AST-дерево исходников с корневой ноды, при этом каждый тип нод отрабатывается отдельно.
Далее нужно каким-то образом получить информацию о реально выполненных строках — для этого в coverage.py используется функция settrace. Она позволяет нам установить свою функцию трассировки, которая будет вызываться при наступлении некоторых событий.
Например, при наступлении события “call” мы понимаем, что была вызвана функция или мы вошли в генератор… В этом случае библиотека сохраняет данные предыдущего контекста, начинает собирать данные нового контекста, учитывая особенности генераторов. Еще одно интересующее нас событие — событие “line”. В этом случае запоминается выполняемая строка и переход между строками. Событие return отмечает выход из контекста — тут важно помнить, что yield также вызывает наступление события “return”.
После этого строится отчет. К этому моменту у нас есть данные о том, что выполнялось, а также что должно было выполняться — по этим данным можно сделать выводы о покрытии кода тестами.
Все эти сложности с обходом байткода, AST-деревьев позволяют проверить покрытие очень сложного кода и получить корректный отчет. Казалось бы, вот она серебряная пуля, все просто отлично. Но на самом деле все не так хорошо.
Что может пойти не так
Рассмотрим простой пример — вызов некоторой функции с условием при передаче параметров.

Оператор if будет покрыт всегда. И мы никогда не узнаем, что это условие всегда оборачивалось в false.
Проблема возникнет и при использовании lambda — внутрь этой функции coverage.py не заглядывает и не скажет нам о том, что внутри что-то не покрыто. Не сможет библиотека разобраться и с list, dict, set-comprehensions.
Все эти случаи имеют кое-что общее. Как мы выяснили выше, coverage.py использует парсер и получает список инструкций. В итоге результатом работы библиотеки является покрытие инструкций, а не строк кода.
Делаем мир лучше
Возьмем простой пример непокрываемого кода:

Допустим, мы хотим покрыть его и знать, когда не срабатывало условие “or c”. Ни один режим coverage.py не позволит этого сделать. Что можно попробовать сделать в этом случае?
Можно установить собственную функцию трассировки, посмотреть на результат ее работы и сделать выводы. То есть, фактически, повторить то, что делает coverage.py. Этот вариант не подходит, поскольку мы имеем ограниченное количество событий: call, line, return, exception. Маленькие частички оператора if мы никогда не увидим.
Другой вариант — использовать модуль ast.NodeTransformer. С его помощью мы можем обойти дерево, обернуть в «нечто» каждую ноду, запустить и посмотреть, что выполнялось. Проблема здесь в том, что на уровне AST очень сложно обернуть ноду в “нечто”, не изменив при этом логику исполнения. Да и в целом, далеко не все ноды можно обернуть. Этот метод тоже подходит.
Но можно использовать и другой подход. Что если, во время импорта перехватить контроль, обойти байткод импортируемого модуля, добавить внутрь байткода вызов своей функции трассировки, собрать code-object и посмотрим, что получилось. Именно эта идея реализована в прототипе библиотеки OpTrace.
Как работает OpTrace
Прежде всего нужно установить Import.Hook— здесь все довольно просто. В нем есть Finder, который пропускает неинтересные нам модули, создав для нужных Loader. В свою очередь, этот класс получает байт-код модуля, строки его исходного кода, модифицирует байт-код и возвращает измененный байткод в качестве импортируемого модуля.
Работает все это так. Создается wrapper, внутри которого «пробрасываются» две функции — первая нужна для того, чтобы отметить опкод, как уже посещенный (visitor). Задача второй — просто отметить, что такой опкод существует в исходнике (marker).
В Python есть ряд инструментов для работы с байткодом. Прежде всего, это модуль dis и его одноименный метод позволяет увидеть байткод в красивом виде.
Подобное представление удобно просматривать, но не обрабатывать. Существует и другой метод — get_instructions. Он принимает на вход code-object и возвращает список инструкций.
На этом методе и строится работы прототипа библиотеки. С помощью этого метода обходится весь байткод. Чтобы отметить существование опкода вызывается проброшенная ранее функция marker.
С трассировкой дело обстоит несколько сложнее. Нельзя просто так взять и поместить в байткод вызов каких-то нужных нам методов. У CodeObject есть атрибут consts — это доступные внутри него константы. В них можно поместить lambda-функцию и “замкнуть” в нее текущую инструкцию в качестве параметра по-умолчанию. Таким образом, вызвав эту лямбду из констант без параметров, мы сможем трассировать выполнение конкретных опкодов. Далее нужно лишь сгенерировать код для вызова константы.
Важно не забыть про оригинальный опкод — нужно его тоже добавить — и его параметры, при этом необходимо учитывать смещение в последующих опкодах. После оборачивания байткода он будет выглядеть примерно так:
Болдом на скриншоте подсвечен оригинальный трассируемый байткод. После модификации байткода необходимо запустить тесты. Так мы выясним, какая часть кода выполнялась, а какая нет. Возникает вопрос, а что делать с непокрытыми опкодами? В проекте на 50 000 строк их перечисление может занять несколько страниц.
На самом деле способа однозначно перевести любой опкод к строке кода не существует, но можно попытаться его найти. У некоторых опкодов есть информация о строке, в которой они находятся. Значит при обходе мы можем сохранять текущую строку — до момента пока не встретим упоминания другой строки будем считать, что строка не менялась. Именно эта информация будет включаться в отчет. Теперь он выглядит гораздо лучше, уже понятно что и где произошло.
Допустим, что строки у нас всегда вычисляются корректно. Теперь можно попробовать вычислить позицию в строке для каждого пропущенного опкода. Рассмотрим несложный пример с опкодом LOAD_FAST. Его параметры говорят о том, что мы имеем дело с загрузкой некоей переменной. Мы можем попробовать в известной нам строке найти ее имя.

Покрыв примерно 70 типов опкодов удалось получить вменяемый отчет. Но многие опкоды покрыть невозможно. Новый отчет выглядит так:
Удивительно, но это работает. Например, мы четко видим, что не сработал LOAD_FAST для переменной c.
OpTrace: минусы и плюсы
При работе с прототипом имеется ряд проблем.
Заключение
Одной из целей этого исследования и разработки была демонстрация факта того, что не существует идеальных библиотек. Coverage.py хорош, но не идеален — слепо верить его отчетам нельзя. Поэтому необходимо всегда разбираться с тем, как работает библиотека и изучать как она работает “изнутри”.
Еще один ключевой тезис — coverage в 100% расслабляет команду. Раз результатам работы библиотек нельзя полностью доверять, то полное покрытие — это просто ачивка, за которой могут скрываться реальные проблемы.



