Регулярные выражения в Python
Перевод статьи «Python Regular Expression».
Обычное использование регулярного выражения:
Основы
Регулярное выражение – это комбинация символов и метасимволов. Из метасимволов доступны следующие:
re.search()
Этот метод возвращает совпадающую часть строки и останавливается сразу же, как находит первое совпадение. Таким образом, его можно использовать для проверки выражения, а не для извлечения данных.
Синтаксис: re.search(шаблон, строка)
Давайте разберем пример: поищем в строке месяц и число.
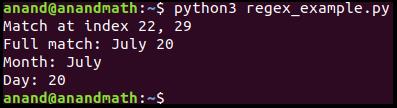
re.match()
Этот метод ищет и возвращает первое совпадение. Но надо учесть, что он проверяет соответствие только в начале строки.
Синтаксис: re.match(шаблон, строка)
Теперь давайте посмотрим на пример. Проверим, совпадает ли строка с шаблоном.
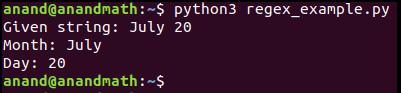
Рассмотрим другой пример. Здесь «July 20» находится не в начале строки, поэтому результатом кода будет «Not a valid date»

re.findall()
Этот метод возвращает все совпадения с шаблоном, которые встречаются в строке. При этом строка проверяется от начала до конца. Совпадения возвращаются в том порядке, в котором они идут в исходной строке.
Синтаксис: re.findall(шаблон, строка)
Возвращаемое значение может быть либо списком строк, совпавших с шаблоном, либо пустым списком, если совпадений не нашлось.
Рассмотрим пример. Используем регулярное выражение для поиска чисел в исходной строке.

Или другой пример. Теперь нам нужно найти в заданном тексте номер мобильного телефона. То есть, в данном случае, нам нужно десятизначное число.

re.compile()
С помощью этого метода регулярные выражения компилируются в объекты шаблона и могут использоваться в других методах. Рассмотрим это на примере поиска совпадений с шаблоном.
re.split()
Данный метод разделяет строку по заданному шаблону. Если шаблон найден, оставшиеся символы из строки возвращаются в виде результирующего списка. Более того, мы можем указать максимальное количество разделений для нашей строки.
Синтаксис: re.split(шаблон, строка, maxsplit = 0)
Возвращаемое значение может быть либо списком строк, на которые была разделена исходная строка, либо пустым списком, если совпадений с шаблоном не нашлось.
Рассмотрим, как работает данный метод, на примере.
re.sub()
Здесь значение «sub» — это сокращение от substring, т.е. подстрока. В данном методе исходный шаблон сопоставляется с заданной строкой и, если подстрока найдена, она заменяется параметром repl.
Синтаксис: re.sub(шаблон, repl, строка, count = 0, flags = 0)
В результате работы кода возвращается либо измененная строка, либо исходная.
Посмотрим на работу метода на следующем примере.
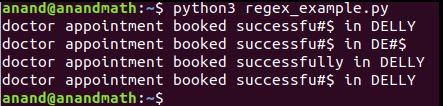
re.subn()
Синтаксис: re.subn(шаблон, repl, строка, count = 0, flags = 0)
Рассмотрим такой пример.
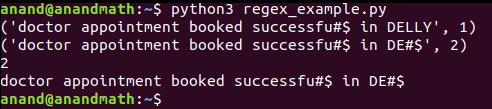
re.escape()
Этот метод возвращает строку с обратной косой чертой \ перед каждым не буквенно-числовым символом. Это полезно, если мы хотим сопоставить произвольную буквенную строку, которая может содержать метасимволы регулярного выражения.
Чтобы лучше понять принцип работы метода, рассмотрим следующий пример.

Заключение
Сегодня мы поговорили о регулярных выражениях в Python и о том, что необходимо для их понимания в любом приложении. Мы изучили различные методы и метасимволы, присутствующие в регулярных выражениях Python, на примерах.
Регулярные выражения Python для новичков: что это, зачем и для чего
За последние несколько лет машинное обучение, data science и связанные с этими направлениями отрасли очень сильно шагнули вперед. Все больше компаний и просто разработчиков используют Python и JavaScript для работы с данными.
И вот здесь-то нам как раз и нужны регулярные выражения. Парсинг всего текста или его фрагментов с веб-страниц, анализ данных Twitter или подготовка данных для анализа текста — регулярные выражения приходят на помощь.
Кстати, свои советы по некоторым функциям добавил Алексей Некрасов — лидер направления Python в МТС, программный директор направления Python в Skillbox. Чтобы было понятно, где перевод, а где — комментарии, последние мы выделим цитатой.
Зачем нужны регулярные выражения?
Когда регулярные выражения не нужны? Когда есть аналогичная встроенная в Python функция, а таких немало.
А что там с регулярными выражениями в Python?
Здесь есть специальный модуль re, который предназначен исключительно для работы с регулярными выражениями. Этот модуль нужно импортировать, после чего можно начинать использовать регулярки.
Что касается самых востребованных методов, предоставляемых модулем, то вот они:
Метод предназначен для поиска по заданному шаблону в начале строки. Так, если вызвать метод match() на строке «AV Analytics AV» с шаблоном «AV», то его получится успешно завершить.
Здесь мы нашли искомую подстроку. Для вывода ее содержимого используется метод group(). При этом используется «r» перед строкой шаблона, чтобы показать, что это raw-строка в Python.
Окей, теперь давайте попробуем найти «Analythics» в этой же строке. У нас ничего не получится, поскольку строка начинается на «AV», метод возвращает none:
Методы start() и end() используются для того, чтобы узнать начальную и конечную позицию найденной строки.
Все эти методы крайне полезны в ходе работы со строками.
Этот метод похож на match(), но его отличие в том, что ищет он не только в начале строки. Так, search() возвращает объект, если мы пробуем найти «Analythics».
Что касается метода search (), то он ищет по всей строке, возвращая, впрочем, лишь первое найденное совпадение.
Здесь у нас возврат всех найденных совпадений. Так, у метода findall() нет никаких ограничений на поиск в начале или конце строки. Например, если искать «AV» в строке, то мы получим возврат всех вхождений «AV». Для поиска рекомендуется использовать как раз этот метод, поскольку он умеет работать как re.search(), так и как re.match().
Этот метод разделяет строку по заданному шаблону.
В указанном примере слово «Analythics» разделено по букве «y». Метод split() здесь принимает и аргумент maxsplit со значением по умолчанию, равным 0. Таким образом он разделяет строку столько раз, сколько это возможно. Правда, если указать этот аргумент, то разделение не может быть выполнено более указанного количества раз. Вот несколько примеров:
Здесь параметр maxsplit установлен равным 1, в результате чего строка разделена на две части вместо трех.
re.sub(pattern, repl, string)
Помогает найти шаблон в строке, заменяя на указанную подстроку. Если же искомое не найдено, то строка остается неизменной.
Здесь мы можем собрать регулярное выражение в объект, который в свою очередь можно использовать для поиска. Такой вариант позволяет избежать переписывания одного и того же выражения.
До этого момента мы рассматривали вариант с поиском определенной последовательности символов? В этом случае никакого шаблона нет, набор символов требуется вернуть в порядке, соответствующему определенным правилам. Такая задача встречается часто при работе с извлечением информации из строк. И сделать это несложно, нужно лишь написать выражение с использованием спец. символов. Вот те, что встречаются чаще всего:
Несколько примеров использования регулярных выражений
Пример 1. Возвращение первого слова из строки
Давайте сначала попробуем получить каждый символ с использованием (.)
Теперь сделаем то же самое, но чтобы в конечный результат не попал пробел, используем \w вместо (.)
Ну а теперь проделаем аналогичную операцию с каждым словом. Используем при этом * или +.
Но и здесь в результате оказались пробелы. Причина — * означает «ноль или более символов». «+» поможет нам их убрать.
Теперь давайте извлечем первое слово с использованием
^:
Пример 2. Возвращаем два символа каждого слова
Здесь, как и выше, есть несколько вариантов. В первом случае, используя \w, извлекаем два последовательных символа, кроме тех, что с пробелами, из каждого слова:
Теперь пробуем извлечь два последовательных символа с использованием символа границы слова (\b):
Пример 3. Возвращение доменов из списка адресов электронной почты.
На первом этапе возвращаем все символы после @:
В итоге части «.com», «.in» и т. д. не попадают в результат. Чтобы исправить это, нужно поменять код:
Второй вариант решения той же проблемы — извлечение лишь домена верхнего уровня с использованием «()»:
Пример 4. Получение даты из строки
Для этого необходимо использовать \d
Для того, чтобы извлечь только год, помогают скобки:
Пример 5. Извлечение слов, начинающихся на гласную
На первом этапе нужно вернуть все слова:
После этого лишь те, что начинаются на определенные буквы, с использованием «[]»:
В полученном примере есть два укороченные слова, это «argest» и «ommunity». Для того, чтобы убрать их, нужно воспользоваться \b, что необходимо для обозначения границы слова:
Кроме того, можно использовать и ^ внутри квадратных скобок, что помогает инвертировать группы:
Теперь нужно убрать слова с пробелом, для чего пробел включаем в диапазон в квадратных скобках:
Пример 6. Проверка формата телефонного номера
В нашем примере длина номера — 10 знаков, начинается он с 8 или 9. Для проверки списка телефонных номеров используем:
Пример 7. Разбиваем строку по нескольким разделителям
Здесь у нас несколько вариантов решения. Вот первое:
Кроме того, можно использовать метод re.sub() для замены всех разделителей пробелами:
Пример 8. Извлекаем данные из html-файла
Для того, чтобы решить эту задачу, выполняем следующую операцию:
При написании любых regex в коде придерживаться следующих правил:
Используйте named capture group для всех capture group, если их больше чем одна (?P. ). (даже если одна capture, тоже лучше использовать).
regex101.com отличный сайт для дебага и проверки regex
При разработке регулярного выражения, нужно не забывать и про его сложность выполнения иначе можно наступить на те же грабли, что и относительно недавно наступила Cloudflare.
Синтаксис регулярных выражений в Python.
Поведение и применение символов регулярных выражений.
Синтаксис регулярных выражений в Python немного отличается от синтаксиса регулярных выражений в языке программирования PERL.
Содержание:
Специальные символы:
Специальный символ ‘^’ соответствует началу строки, а при включенном флаге re.MULTILINE также соответствует положению сразу после каждой новой строки.
Если не использовать необработанную строку r» в написании шаблона регулярного выражения, то необходимо помнить, что Python также использует обратную косую черту в качестве escape-последовательности в строковых литералах. Если escape-последовательность не распознается синтаксическим анализатором Python, обратная косая черта и последующий символ включаются в полученную строку. Если Python распознает полученную последовательность, обратный слеш должен повторяться дважды. Это сложно и трудно понять, поэтому настоятельно рекомендуется использовать необработанные строки r» для всех, кроме самых простых регулярных выражений.
Конструкция ‘[]’ используется для обозначения символьного класса:
Расширения регулярных выражений:
— ‘(?aiLmsux)’
— ‘(?aiLmsux-imsx. )’
— ‘(?P=name)’
Конструкция ‘(?#. )’ обозначает комментарий. Содержимое скобок просто игнорируется.
Этот пример ищет слово после дефиса:
— ‘(?(id/name)yes-pattern|no-pattern)’
Специальные последовательности:
— ‘\number’
Специальная последовательность ‘\A’ совпадает только с положением начала строки.
Для шаблонов байтовых строк: специальная последовательность ‘\d’ соответствует любой десятичной цифре, эквивалентно символьному классу 1.
Специальная последовательность ‘\Z’ совпадает только с положением конца строки.
Большинство стандартных экранирований, поддерживаемых строковыми литералами Python, также принимаются анализатором регулярных выражений:
Обратите внимание, что \b используется для представления границ слов и означает «возврат» только внутри классов символов.
Применение регулярных выражений в Python
Регулярные выражения можно определить как последовательность символов, которые используются для поиска шаблона в строке. Модуль re обеспечивает поддержку использования регулярных выражений в программе Python. Модуль re выдает исключение, если при использовании регулярного выражения произошла ошибка.
Чтобы использовать функции регулярных выражений в Python, необходимо импортировать модуль re.
Функции регулярных выражений
В Python используются следующие функции регулярных выражений.
| Функция | Описание | |
|---|---|---|
| 1 | match | Этот метод сопоставляет шаблон регулярного выражения в строке с необязательным флагом. Он возвращает истину, если в строке найдено совпадение, в противном случае возвращает ложь. |
| 2 | search | Этот метод возвращает объект соответствия, если в строке найдено совпадение. |
| 3 | findall | Он возвращает список, содержащий все совпадения шаблона в строке. |
| 4 | split | Возвращает список, в котором строка была разделена при каждом совпадении. |
| 5 | sub | Заменить одно или несколько совпадений в строке. |
Формирование регулярного выражения
Регулярное выражение можно сформировать, используя сочетание метасимволов, специальных последовательностей и наборов.
Метасимволы
Метасимвол – это символ с указанным значением.
| Метасимвол | Описание | Пример |
|---|---|---|
| [] | Представляет собой набор символов. | “[[a-z]” |
| \ | Он представляет собой особую последовательность. | “\r” |
| . | Сигнализирует о том, что какой-либо символ присутствует в определенном месте. | “Ja.v.” |
| ^ | Он представляет собой образец, присутствующий в начале строки. | «^ Java» |
| $ | Присутствует в конце строки. | “point” |
| * | Представляет собой ноль или более вхождений шаблона в строку. | “hello*” |
| + | Он представляет собой одно или несколько вхождений шаблона в строку. | “hello+” |
| <> | Указанное количество вхождений шаблона в строку. | “java<2>” |
| | | Он представляет собой присутствие того или иного символа. | “java|point” |
| () | Объединение и группировка. |
Особые последовательности
Специальные последовательности – это последовательности, которые содержат (либо за которыми следует) один из символов.
| Символ | Описание |
|---|---|
| \A | Он возвращает совпадение, если указанные символы присутствуют в начале строки. |
| \b | Возвращает совпадение, если указанные символы присутствуют в начале или в конце строки. |
| \B | Он возвращает совпадение, если символы присутствуют в начале строки, но не в конце. |
| \d | Возвращает совпадение, если строка содержит цифры 3. |
| \D | Строка не содержит цифр 5. |
| \s | Строка содержит какой-либо символ пробела. |
| \S | Строка не содержит пробелов. |
| \w | Строка содержит какие-либо символы слова. |
| \W | Строка не содержит ни одного слова. |
| \Z | Возвращает совпадение, если указанные символы находятся в конце строки. |
Наборы
Набор – это группа символов, заключенная в квадратные скобки. Он представляет особый смысл.
| Набор | Описание | |
|---|---|---|
| 1 | [arn] | Возвращает совпадение, если строка содержит любой из указанных символов в наборе. |
| 2 | [an] | Возвращает совпадение, если строка содержит любой из символов от a до n. |
| 3 | [^ arn] | Строка содержит символы, кроме a, r и n. |
| 4 | [0123] | Строка содержит любую из указанных цифр. |
| 5 | 1 | Строка содержит любую цифру от 0 до 9. |
| 6 | 4 8 | Строка содержит любую цифру от 00 до 59. |
| 10 | [a-zA-Z] | Возвращает совпадение, если строка содержит буквы алфавита(в нижнем или верхнем регистре). |
Функция findall()
Этот метод возвращает список, содержащий все совпадения шаблона в строке. Он возвращает шаблоны в том порядке, в котором они были найдены. Если совпадений нет, возвращается пустой список.
Рассмотрим следующий пример:
Объект соответствия
Объект соответствия содержит информацию о поиске и выводе. Если совпадений не найдено, возвращается объект None.
Методы объекта Match
С объектом Match связаны следующие методы.
Примеры применения регулярных выражений в Python
Регулярные выражения, также называемые regex, синтаксис или, скорее, язык для поиска, извлечения и работы с определенными текстовыми шаблонами большего текста. Он широко используется в проектах, которые включают проверку текста, NLP (Обработка естественного языка) и интеллектуальную обработку текста.
Введение в регулярные выражения
Эта статья разделена на 2 части.
Что такое шаблон регулярного выражения и как его скомпилировать?
Шаблон регулярного выражения представляет собой специальный язык, используемый для представления общего текста, цифр или символов, извлечения текстов, соответствующих этому шаблону.
В конце этой статьи вы найдете больший список шаблонов регулярных выражений. Но прежде чем дойти до этого, давайте посмотрим, как компилировать и работать с регулярными выражениями.
Вышеупомянутый код импортирует модуль re и компилирует шаблон регулярного выражения, который соответствует хотя бы одному или нескольким символам пробела.
Как разбить строку, разделенную регулярным выражением?
Рассмотрим следующий фрагмент текста.
У меня есть три курса в формате “[Номер курса] [Код курса] [Название курса]”. Интервал между словами разный.
Передо мной стоит задача разбить эти три предмета курса на отдельные единицы чисел и слов. Как это сделать?
Их можно разбить двумя способами:
Оба эти метода работают. Но какой же следует использовать на практике?
Если вы намерены использовать определенный шаблон несколько раз, вам лучше скомпилировать регулярное выражение, а не использовать re.split множество раз.
Поиск совпадений с использованием findall, search и match
Предположим, вы хотите извлечь все номера курсов, то есть 100, 213 и 156 из приведенного выше текста. Как это сделать?
Что делает re.findall()?
В приведенном выше коде специальный символ \ d является регулярным выражением, которое соответствует любой цифре. В этой статье вы узнаете больше о таких шаблонах.
Добавление к нему символа + означает наличие по крайней мере 1 числа.
В итоге, метод findall извлекает все вхождения 1 или более номеров из текста и возвращает их в список.
re.search() против re.match()
Аналогично, regex.match() также возвращает объект соответствия. Но разница в том, что он требует, чтобы шаблон находился в начале самого текста.
В качестве альтернативы вы можете получить тот же результат, используя метод group() для объекта соответствия.
Как заменить один текст на другой, используя регулярные выражения?
Из вышеприведенного текста я хочу удалить все лишние пробелы и записать все слова в одну строку.
Предположим, вы хотите избавиться от лишних пробелов и выводить записи курса с новой строки. Чтобы это сделать, используйте регулярное выражение, которое пропускает символ новой строки, но учитывает все другие пробелы.
Группы регулярных выражений
Группы регулярных выражений — функция, позволяющая извлекать нужные объекты соответствия как отдельные элементы.
Предположим, что я хочу извлечь номер курса, код и имя как отдельные элементы. Не имея групп мне придется написать что-то вроде этого.
Давайте посмотрим, что получилось.
Я скомпилировал 3 отдельных регулярных выражения по одному для соответствия номерам курса, коду и названию.
Для номера курса, шаблон 4+ указывает на соответствие всем числам от 0 до 9. Добавление символа + в конце заставляет найти по крайней мере 1 соответствие цифрам 0-9. Если вы уверены, что номер курса, будет иметь ровно 3 цифры, шаблон мог бы быть 3 <3>.
Для кода курса, как вы могли догадаться, [А-ЯЁ] <3>будет совпадать с 3 большими буквами алфавита А-Я подряд (буква “ё” не включена в общий диапазон букв).
Для названий курса, [а-яА-ЯёЁ] <4,>будем искать а-я верхнего и нижнего регистра, предполагая, что имена всех курсов будут иметь как минимум 4 символа.
Можете ли вы догадаться, каков будет шаблон, если максимальный предел символов в названии курса, скажем, 20?
Теперь мне нужно написать 3 отдельные строки, чтобы разделить предметы. Но есть лучший способ. Группы регулярных выражений.
Поскольку все записи имеют один и тот же шаблон, вы можете создать единый шаблон для всех записей курса и внести данные, которые хотите извлечь из пары скобок ().
Что такое “жадное” соответствие в регулярных выражениях?
По умолчанию, регулярные выражения должны быть жадными. Это означает, что они пытаются извлечь как можно больше, пока соответствуют шаблону, даже если требуется меньше.
Давайте рассмотрим пример фрагмента HTML, где нам необходимо получить тэг HTML.
Вместо совпадения до первого появления ‘>’, которое, должно было произойти в конце первого тэга тела, он извлек всю строку. Это по умолчанию “жадное” соответствие, присущее регулярным выражениям.
Наиболее распространенный синтаксис и шаблоны регулярных выражений
Теперь, когда вы знаете как пользоваться модулем re, давайте рассмотрим некоторые обычно используемые шаблоны подстановок.
Основной синтаксис
Модификаторы
| $ | Конец строки |
| ^ | Начало строки |
| ab|cd | Соответствует ab или de. |
| [ab-d] | Один символ: a, b, c, d |
| [^ab-d] | Любой символ, кроме: a, b, c, d |
| () | Извлечение элементов в скобках |
| (a(bc)) | Извлечение элементов в скобках второго уровня |
Повторы
| [ab] | 2 непрерывных появления a или b |
| [ab] | от 2 до 5 непрерывных появления a или b |
| [ab] | 2 и больше непрерывных появления a или b |
| + | одно или больше |
| * | 0 или больше |
| ? | 0 или 1 |
Примеры регулярных выражений
Любой символ кроме новой строки
Точки в строке
Любая цифра
Все, кроме цифры
Любая буква или цифра
Все, кроме букв и цифр
Только буквы
Соответствие заданное количество раз
1 и более вхождений
Любое количество вхождений (0 или более раз)
0 или 1 вхождение
Граница слова
Границы слов \b обычно используются для обнаружения и сопоставления началу или концу слова. То есть, одна сторона является символом слова, а другая сторона является пробелом и наоборот.
Практические упражнения
Давайте немного попрактикуемся. Пришло время открыть вашу консоль. (Варианты ответов здесь)
1. Извлеките никнейм пользователя, имя домена и суффикс из данных email адресов.
2. Извлеките все слова, начинающиеся с ‘b’ или ‘B’ из данного текста.
3. Уберите все символы пунктуации из предложения
4. Очистите следующий твит, чтобы он содержал только одно сообщение пользователя. То есть, удалите все URL, хэштеги, упоминания, пунктуацию, RT и CC.
Ответы
Надеемся, информация была вам полезна. Стояла цель — познакомить вас с примерами регулярных выражений легким и доступным для запоминания способом.



