Как автоматически подобрать параметры для модели машинного обучения? Используем GridSearchCV
Подбор параметров – одна из важных задач для построения модели машинного обучения. Изменение параметров модели может принципиально повлиять на ее качество. Например, модель может переобучиться. Перебор этих параметров вручную может занять колоссальное количество времени. Однако, существует модуль GridSearchCV.
GridSearchCV – это очень мощный инструмент для автоматического подбирания параметров для моделей машинного обучения. GridSearchCV находит наилучшие параметры, путем обычного перебора: он создает модель для каждой возможной комбинации параметров. Важно отметить, что такой подход может быть весьма времязатратным.
Перейдем к примеру.
Для начала импортируем необходимые библиотеки:
В качестве датасэта будем использовать данные о съедобности грибов.
Фрагмент нашего датафрейма:
Для создания модели нам необходимо вытащить целевой признак «Class» в переменную y_train, а оставшиеся признаки в переменную X_train:
Затем объявляем классификатор RandomForest, не внося в него никаких параметров:
Отдельно создаем словарик, в который вписываем параметры, которые будем прогонять GridSearch’ем. Для примера будем использовать следующие параметры:
n_estimators – число деревьев в лесу. Оно будет изменяться от 10 до 50 с шагом 10
max_depth – глубина дерева. Она будет изменяться от 1 до 12 с шагом в 2
min_samples_leaf – минимальное число образцов в листах. Оно будет изменяться от 1 до 7
min_samples_leaf – минимальное число образцов для сплита. Оно будет изменяться от 2 до 9.
Полученные параметры являются лучшими для нашей модели.
Старая форма оплаты Вайлдберриз, в которой отдельной строкой отображалась комиссия при оплате MasterCard была признана судом как незаконная.
Недавние ограничения китайских властей сильно ударили по майнинг-пулам. С рынка ушел один из крупнейших игроков – Huobi Pool. Это пул майнеров, входящий в десятку крупнейших майнинг-пулов по объему добычи криптовалют. Прямо сейчас ряд компаний и объединений, входящих ранее в пул, пытаются спасти средства клиентов и переходят в другие майнинговые…
GridSearchCV – помощник в выборе гиперпараметров модели
Аналитик, получив конкретную задачу, залив (сформировав датасет) и очистив данные, приступает к более глубокому анализу:
Рассмотрим детально вариант использования компонента GridSearchCV.
Для начала импортируем необходимый модуль:
Для примера возьмем только некоторые из представленных выше параметров: ‘max_iter’ и ‘learning_rate_init’– их значения и попробуем подобрать.
Перед тем как приступать к подбору, будет полезным познакомиться с методом чуть поближе.
GridSearch — поиск лучших параметров в фиксированной сетке возможных значений.
CV – перекрёстная проверка (кросс-валидация, Cross-validation), метод, который показывает, что модель не переобучилась.
Принцип работы:
2. делится на кусочки:
3. делается указанное нами (4) количество прогонов этой модели:
Где |****| – одна из частей датасета, “DDDD”- часть датасета, на которой прогоняется модель.
Таким образом модель прогоняется на 4х кусках, т.е. 4 разные модели обучаются на 4х разных выборках. Если все 4 результата хороши, значит модель не переобучена.
Параметры GridSearchCV:
estimator — модель которую хотим обучать (алгоритм);
param_grid — передаем какие параметры хотим подбирать, GridSearchCV на всех параметрах попробует сделать обучение;
CV — сколько разрезов кросс-валидации мы ходим сделать;
scoring — выбор метрики ошибки (для разных задач можно выбрать разные функции ошибки).
Познакомившись с методом, начинаем с ним работать:
ИТОГ: количество моделей которых мы обучим с помощью данного метода: 3*2*3 = 18 штук.
Обучим сетку на датасетах модели:
Смотрим результат и видим самый лучший обученный MLP-регрессор:
Исходя из полученный информации, лучший регрессор (использованная Вами модель) имеет указанные выше параметры.
Данный метод хоть и работает не очень быстро, но, при этом, экономит достаточно времени по сравнению с ручным перебором тех же параметров, чем дает явное преимущество в использовании при построении моделей.
Random Forest, метод главных компонент и оптимизация гиперпараметров: пример решения задачи классификации на Python
У специалистов по обработке и анализу данных есть множество средств для создания классификационных моделей. Один из самых популярных и надёжных методов разработки таких моделей заключается в использовании алгоритма «случайный лес» (Random Forest, RF). Для того чтобы попытаться улучшить показатели модели, построенной с использованием алгоритма RF, можно воспользоваться оптимизацией гиперпараметров модели (Hyperparameter Tuning, HT).

Кроме того, распространён подход, в соответствии с которым данные, перед их передачей в модель, обрабатывают с помощью метода главных компонент (Principal Component Analysis, PCA). Но стоит ли вообще этим пользоваться? Разве основная цель алгоритма RF заключается не в том, чтобы помочь аналитику интерпретировать важность признаков?
Да, применение алгоритма PCA может привести к небольшому усложнению интерпретации каждого «признака» при анализе «важности признаков» RF-модели. Однако алгоритм PCA производит уменьшение размерности пространства признаков, что может привести к уменьшению количества признаков, которые нужно обработать RF-моделью. Обратите внимание на то, что объёмность вычислений — это один из основных минусов алгоритма «случайный лес» (то есть — выполнение модели может занять немало времени). Применение алгоритма PCA может стать весьма важной частью моделирования, особенно в тех случаях, когда работают с сотнями или даже с тысячами признаков. В результате, если самое важное — это просто создать наиболее эффективную модель, и при этом можно пожертвовать точностью определения важности признаков, тогда PCA, вполне возможно, стоит попробовать.
Теперь — к делу. Мы будем работать с набором данных по раку груди — Scikit-learn «breast cancer». Мы создадим три модели и сравним их эффективность. А именно, речь идёт о следующих моделях:
1. Импорт данных
Для начала загрузим данные и создадим датафрейм Pandas. Так как мы пользуемся предварительно очищенным «игрушечным» набором данных из Scikit-learn, то после этого мы уже сможем приступить к процессу моделирования. Но даже при использовании подобных данных рекомендуется всегда начинать работу, проведя предварительный анализ данных с использованием следующих команд, применяемых к датафрейму ( df ):

Фрагмент датафрейма с данными по раку груди. Каждая строка содержит результаты наблюдений за пациентом. Последний столбец, cancer, содержит целевую переменную, которую мы пытаемся предсказать. 0 означает «отсутствие заболевания». 1 — «наличие заболевания»
2. Разделение набора данных на учебные и проверочные данные
Например, если есть миллионы строк, можно разделить набор, выделив 90% строк на учебные данные и 10% — на проверочные. Но исследуемый набор данных содержит лишь 569 строк. А это — не так уж и много для тренировки и проверки модели. В результате для того, чтобы быть справедливыми по отношению к учебным и проверочным данным, мы разделим набор на две равные части — 50% — учебные данные и 50% — проверочные. Мы устанавливаем stratify=y для обеспечения того, чтобы и в учебном, и в проверочном наборах данных присутствовало бы то же соотношение 0 и 1, что и в исходном наборе данных.
3. Масштабирование данных
Прежде чем приступать к моделированию, нужно выполнить «центровку» и «стандартизацию» данных путём их масштабирования. Масштабирование выполняется из-за того, что разные величины выражены в разных единицах измерения. Эта процедура позволяет организовать «честную схватку» между признаками при определении их важности. Кроме того, мы конвертируем y_train из типа данных Pandas Series в массив NumPy для того чтобы позже модель смогла бы работать с соответствующими целевыми показателями.
4. Обучение базовой модели (модель №1, RF)
Сейчас создадим модель №1. В ней, напомним, применяется только алгоритм Random Forest. Она использует все признаки и настроена с использованием значений, задаваемых по умолчанию (подробности об этих настройках можно найти в документации к sklearn.ensemble.RandomForestClassifier). Сначала инициализируем модель. После этого обучим её на масштабированных данных. Точность модели можно измерить на учебных данных:
Если нам интересно узнать о том, какие признаки являются самыми важными для RF-модели в деле предсказания рака груди, мы можем визуализировать и квантифицировать показатели важности признаков, обратившись к атрибуту feature_importances_ :
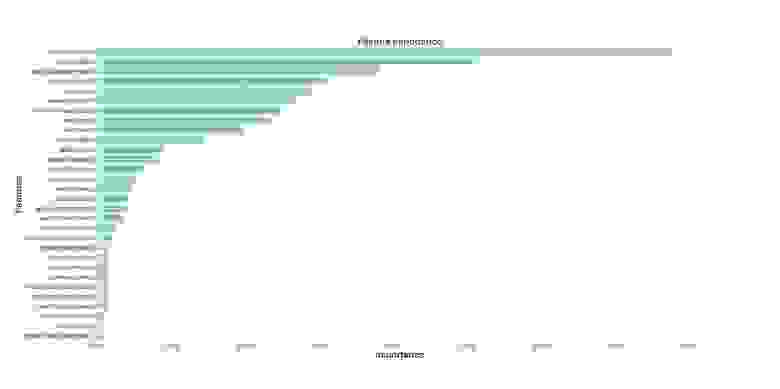
Визуализация «важности» признаков
Показатели важности признаков
5. Метод главных компонент

После того, как число используемых компонент превышает 10, рост их количества не очень сильно повышает объяснённую дисперсию
Этот датафрейм содержит такие показатели, как Cumulative Variance Ratio (кумулятивный размер объяснённой дисперсии данных) и Explained Variance Ratio (вклад каждой компоненты в общий объём объяснённой дисперсии)
Каждая компонента — это линейная комбинация исходных переменных с соответствующими «весами». Мы можем видеть эти «веса» для каждой компоненты, создав датафрейм.
Датафрейм со сведениями по компонентам
6. Обучение базовой RF-модели после применения к данным метода главных компонент (модель №2, RF + PCA)
Теперь мы можем передать в ещё одну базовую RF-модель данные X_train_scaled_pca и y_train и можем узнать о том, есть ли улучшения в точности предсказаний, выдаваемых моделью.
Модели сравним ниже.
7. Оптимизация гиперпараметров. Раунд 1: RandomizedSearchCV
После обработки данных с использованием метода главных компонент можно попытаться воспользоваться оптимизацией гиперпараметров модели для того чтобы улучшить качество предсказаний, выдаваемых RF-моделью. Гиперпараметры можно рассматривать как что-то вроде «настроек» модели. Настройки, которые отлично подходят для одного набора данных, для другого не подойдут — поэтому и нужно заниматься их оптимизацией.
Начать можно с алгоритма RandomizedSearchCV, который позволяет довольно грубо исследовать широкие диапазоны значений. Описания всех гиперпараметров для RF-моделей можно найти здесь.
Мы будем заниматься подбором следующих гиперпараметров:
Результаты работы алгоритма RandomizedSearchCV
Теперь создадим столбчатые графики, на которых, по оси Х, расположены значения гиперпараметров, а по оси Y — средние значения, показываемые моделями. Это позволит понять то, какие значения гиперпараметров, в среднем, лучше всего себя показывают.

Анализ значений гиперпараметров
Если проанализировать вышеприведённые графики, то можно заметить некоторые интересные вещи, говорящие о том, как, в среднем, каждое значение гиперпараметра влияет на модель.
8. Оптимизация гиперпараметров. Раунд 2: GridSearchCV (окончательная подготовка параметров для модели №3, RF + PCA + HT)
После применения алгоритма RandomizedSearchCV воспользуемся алгоритмом GridSearchCV для проведения более точного поиска наилучшей комбинации гиперпараметров. Здесь исследуются те же гиперпараметры, но теперь мы применяем более «обстоятельный» поиск их наилучшей комбинации. При использовании алгоритма GridSearchCV исследуется каждая комбинация гиперпараметров. Это требует гораздо больших вычислительных ресурсов, чем использование алгоритма RandomizedSearchCV, когда мы самостоятельно задаём число итераций поиска. Например, исследование 10 значений для каждого из 6 гиперпараметров с кросс-валидацией по 3 блокам потребует 10⁶ x 3, или 3000000 сеансов обучения модели. Именно поэтому мы и используем алгоритм GridSearchCV после того, как, применив RandomizedSearchCV, сузили диапазоны значений исследуемых параметров.
Итак, используя то, что мы выяснили с помощью RandomizedSearchCV, исследуем значения гиперпараметров, которые лучше всего себя показали:
Здесь мы применяем кросс-валидацию по 3 блокам для 540 (3 x 1 x 5 x 6 x 6 x 1) сеансов обучения модели, что даёт 1620 сеансов обучения модели. И уже теперь, после того, как мы воспользовались RandomizedSearchCV и GridSearchCV, мы можем обратиться к атрибуту best_params_ для того чтобы узнать о том, какие значения гиперпараметров позволяют модели наилучшим образом работать с исследуемым набором данных (эти значения можно видеть в нижней части предыдущего блока кода). Эти параметры используются при создании модели №3.
9. Оценка качества работы моделей на проверочных данных
Теперь можно оценить созданные модели на проверочных данных. А именно, речь идёт о тех трёх моделях, описанных в самом начале материала.
Проверим эти модели:
Создадим матрицы ошибок для моделей и узнаем о том, как хорошо каждая из них способна предсказывать рак груди:
Результаты работы трёх моделей
Здесь оценивается метрика «полнота» (recall). Дело в том, что мы имеем дело с диагнозом рака. Поэтому нас чрезвычайно интересует минимизация ложноотрицательных прогнозов, выдаваемых моделями.
Учитывая это, можно сделать вывод о том, что базовая RF-модель дала наилучшие результаты. Её показатель полноты составил 94.97%. В проверочном наборе данных была запись о 179 пациентах, у которых есть рак. Модель нашла 170 из них.
Итоги
Это исследование позволяет сделать важное наблюдение. Иногда RF-модель, в которой используется метод главных компонент и широкомасштабная оптимизация гиперпараметров, может работать не так хорошо, как самая обыкновенная модель со стандартными настройками. Но это — не повод для того, чтобы ограничивать себя лишь простейшими моделями. Не попробовав разные модели, нельзя сказать о том, какая из них покажет наилучший результат. А в случае с моделями, которые используются для предсказания наличия у пациентов рака, можно сказать, что чем лучше модель — тем больше жизней может быть спасено.
Уважаемые читатели! Какие задачи вы решаете, привлекая методы машинного обучения?
Exhaustive search over specified parameter values for an estimator.
Important members are fit, predict.
GridSearchCV implements a “fit” and a “score” method. It also implements “score_samples”, “predict”, “predict_proba”, “decision_function”, “transform” and “inverse_transform” if they are implemented in the estimator used.
The parameters of the estimator used to apply these methods are optimized by cross-validated grid-search over a parameter grid.
Parameters estimator estimator object
This is assumed to implement the scikit-learn estimator interface. Either estimator needs to provide a score function, or scoring must be passed.
param_grid dict or list of dictionaries
Dictionary with parameters names ( str ) as keys and lists of parameter settings to try as values, or a list of such dictionaries, in which case the grids spanned by each dictionary in the list are explored. This enables searching over any sequence of parameter settings.
scoring str, callable, list, tuple or dict, default=None
Strategy to evaluate the performance of the cross-validated model on the test set.
If scoring represents a single score, one can use:
If scoring represents multiple scores, one can use:
a list or tuple of unique strings;
a callable returning a dictionary where the keys are the metric names and the values are the metric scores;
a dictionary with metric names as keys and callables a values.
n_jobs int, default=None
Changed in version v0.20: n_jobs default changed from 1 to None
Refit an estimator using the best found parameters on the whole dataset.
For multiple metric evaluation, this needs to be a str denoting the scorer that would be used to find the best parameters for refitting the estimator at the end.
The refitted estimator is made available at the best_estimator_ attribute and permits using predict directly on this GridSearchCV instance.
See scoring parameter to know more about multiple metric evaluation.
Changed in version 0.20: Support for callable added.
Determines the cross-validation splitting strategy. Possible inputs for cv are:
None, to use the default 5-fold cross validation,
An iterable yielding (train, test) splits as arrays of indices.
For integer/None inputs, if the estimator is a classifier and y is either binary or multiclass, StratifiedKFold is used. In all other cases, KFold is used. These splitters are instantiated with shuffle=False so the splits will be the same across calls.
Refer User Guide for the various cross-validation strategies that can be used here.
Changed in version 0.22: cv default value if None changed from 3-fold to 5-fold.
Controls the verbosity: the higher, the more messages.
>1 : the computation time for each fold and parameter candidate is displayed;
>2 : the score is also displayed;
>3 : the fold and candidate parameter indexes are also displayed together with the starting time of the computation.
pre_dispatch int, or str, default=’2*n_jobs’
Controls the number of jobs that get dispatched during parallel execution. Reducing this number can be useful to avoid an explosion of memory consumption when more jobs get dispatched than CPUs can process. This parameter can be:
None, in which case all the jobs are immediately created and spawned. Use this for lightweight and fast-running jobs, to avoid delays due to on-demand spawning of the jobs
An int, giving the exact number of total jobs that are spawned
A str, giving an expression as a function of n_jobs, as in ‘2*n_jobs’
Value to assign to the score if an error occurs in estimator fitting. If set to ‘raise’, the error is raised. If a numeric value is given, FitFailedWarning is raised. This parameter does not affect the refit step, which will always raise the error.
return_train_score bool, default=False
New in version 0.19.
Changed in version 0.21: Default value was changed from True to False
Русские Блоги
Заметки о машинном обучении Python GridSearchCV
Заметки о машинном обучении Python Grid SearchCV (Grid Search)
1. Анализ принципа Grid SearchCV
1. Почему это называется GridSearchCV?
Имя GridSearchCV на самом деле можно разделить на две части, GridSearch и CV, а именно поиск по сетке и перекрестную проверку. Оба имени очень легко понять. Поиск по сетке, поиск параметров, то есть в пределах указанного диапазона параметров, настройка параметров в последовательности в соответствии с длиной шага, использование настроенных параметров для обучения учащегося и поиск параметра с наивысшей точностью на проверочном наборе из всех параметров. Это на самом деле Процесс обучения и сравнения.
2. Что такое поиск по сетке?
Таким образом, поиск по сетке подходит для трех или четырех (или менее) гиперпараметров (при увеличении количества гиперпараметров вычислительная сложность поиска по сетке будет экспоненциально возрастать, в этом случае используется случайный поиск), пользователь перечисляет один Меньший диапазон гиперпараметров, декартово произведение (перестановка и комбинация) этих гиперпараметров представляет собой группу гиперпараметров. Алгоритм поиска по сетке использует каждый набор гиперпараметров для обучения модели и выбирает комбинацию гиперпараметров с наименьшей ошибкой набора для проверки.
2.1, возьмите случайный лес в качестве примера, чтобы проиллюстрировать поиск по сетке GridSearch.
Если GridSearchCV инициализируется с помощью refit = True (значение инициализации по умолчанию), во время перекрестной проверки, как только будет найдена лучшая модель (оценка), она будет повторно обучена на всем обучающем наборе. Обычно это хорошая идея, потому что Чем больше наборов данных, тем выше производительность модели.
2.2, возьмите Xgboost в качестве примера, чтобы проиллюстрировать поиск по сетке GridSearch
Давайте возьмем набор данных рекламных рекомендаций Ali IJCAI и классификатор XgboostClassifier в качестве примера, чтобы проиллюстрировать использование GridSearchCV в sklearn в форме кода. (Здесь есть ссылка на код этого небольшого случая:Пожалуйста, нажмите меня)
Теперь посмотрим на определенную нами оценочную функцию:
После того, как определение сделано, его можно перенести в функцию GridSearchCV.
Вот более важные параметры, которые необходимо настроить для часто используемых алгоритмов интегрированного обучения:

2.3, возьмите SVR в качестве примера, чтобы проиллюстрировать поиск по сетке GridSearch
В качестве примера возьмем процесс настройки двух параметров:
2.4 Какие проблемы возникают с указанными выше параметрами настройки?
2.5 Какое решение?
Обучающий набор снова делится на обучающий набор и проверочный набор. Результатом этого деления является: исходные данные делятся на 3 части, а именно: обучающий набор, набор проверки и набор тестов; обучающий набор используется для обучения модели, Набор для проверки используется для настройки параметров, а набор для тестирования используется для измерения производительности модели.

Однако конечная производительность этого простого метода поиска по сетке во многом зависит от результатов первичного разделения данных.Чтобы справиться с этой ситуацией, мы используем перекрестную проверку для уменьшения непредвиденных обстоятельств.
2.6, улучшенный код SVM для перекрестной проверки (поиск по сетке с перекрестной проверкой)
Перекрестная проверка часто сочетается с поиском в Интернете в качестве метода оценки параметров. Этот метод называется поиском по сетке с перекрестной проверкой.
Поэтому sklearn разработал такой класс GridSearchCV, который реализует методы соответствия, прогнозирования, оценки и другие методы. В качестве оценщика, используя метод подгонки, в процессе:
Так называемая конфигурация модели обычно называется гиперпараметрами модели, такими как значение K в алгоритме KNN и различные функции ядра (Kernal) в SVM. В большинстве случаев такие параметры, как гиперпараметры, не ограничены. В течение ограниченного времени, помимо проверки нескольких искусственно заданных комбинаций гиперпараметров, можно также использовать методы эвристического поиска для оптимизации комбинаций гиперпараметров. Назовите этот эвристический метод поиска гиперпараметров поиском по сетке.
Когда мы ищем гиперпараметры, если количество гиперпараметров невелико (три, четыре или меньше), мы можем использовать поиск по сетке, метод исчерпывающего поиска. Но когда количество гиперпараметров относительно велико, мы по-прежнему используем поиск по сетке, поэтому время поиска будет увеличиваться в геометрической прогрессии.
Поэтому некоторые люди предложили метод случайного поиска, который случайным образом ищет сотни точек в пространстве гиперпараметров, среди которых могут быть относительно небольшие значения. Этот подход быстрее, чем описанный выше подход с разреженной сеткой, и эксперименты показали, что метод случайного поиска дает несколько лучшие результаты, чем метод разреженной сетки.
Метод RandomizedSearchCV очень похож на класс GridSearchCV, но вместо того, чтобы пробовать все возможные комбинации, он выбирает определенное количество случайных комбинаций случайного значения для каждого гиперпараметра. Этот метод имеет два преимущества:
Использование RandomizedSearchCV на самом деле то же, что и GridSearchCV, но оно заменяет GridSearchCV поиск параметров по сетке случайной выборкой в пространстве параметров. Для параметров с непрерывными переменными RandomizedSearchCV будет выбирать его как распределение. Это то, что не может сделать поиск по сетке.Его возможность поиска зависит от набора параметров n_iter, и код также указан.

4. Поиск по сетке гиперпараметров и код параллельного поиска
5. Сравнение случайного поиска и поиска по сетке для оценки гиперпараметров.
Используемый набор данных представляет собой небольшой набор данных. Набор данных рукописных цифр load_digits () Размер данных классификации 5620 * 64 (небольшие данные в sklearn можно использовать напрямую, а большие наборы данных будут автоматически загружены при первом использовании)
Сравните случайный поиск и поиск по сетке при оптимизации гиперпараметров случайного леса. Все параметры, влияющие на обучение, ищутся одновременно (за исключением количества оценок, которое приведет к компромиссу между временем и качеством).
Случайный поиск и поиск по сетке исследуют одно и то же пространство параметров. Результаты настройки параметров очень похожи, а время выполнения случайного поиска намного меньше.
Производительность случайного поиска немного хуже, но это, скорее всего, шумовой эффект и не будет продолжаться на внешнем тестовом наборе.
Примечание. На практике люди не будут использовать поиск по сетке для одновременного поиска стольких различных параметров, а будут выбирать только те параметры, которые считаются наиболее важными.
2. Обзор библиотеки Scikit-learn GridSearch
Адрес официального сайта sklearn’s Grid Search:Пожалуйста, нажмите меня
1. Введение в GridSearchCV
Обычно алгоритм недостаточно хорош, необходимо отладить параметры. Например, штрафной коэффициент C SVM, ядро функции ядра, параметр гаммы и т. Д. Используют разные параметры для разных данных, результат может быть на 1
5 пунктов хуже, sklearn специально отлаживает функцию grid_search для наших параметров.
2. Описание параметра GridSearchCV
3. Общие методы и атрибуты прогнозирования
4. Описание атрибута GridSearchCV.
В DataFrame можно импортировать dict с ключами в качестве заголовков столбцов и значениями в виде столбцов. Обратите внимание, что клавиша «params» используется для хранения списка настроек всех параметров-кандидатов.
best_score_: float оценка best_estimator
best_parmas_: настройки параметров dict, которые дают наилучшие результаты для сохраненных данных
best_index_: int, соответствующий индексу настройки параметра лучшего кандидата (cv_results_array) _
Scorer function used on the held out data to choose the best parameters for the model.
The number of cross-validation splits (folds/iterations).
5. Примеры использования деревьев решений для прогнозирования рака груди (оптимизация алгоритма поиска по сетке)
5.1 Алгоритм поиска по сетке и теоретические знания K-кратной перекрестной проверки
Возьмем в качестве примера дерево решений.Когда мы решаем использовать алгоритм дерева решений, чтобы иметь возможность лучше соответствовать и предсказывать, нам необходимо настроить его параметры. В алгоритме дерева решений обычно выбирается параметр максимальной глубины дерева решений.
Итак, ниже мы дадим серию значений максимальной глубины, например <‘max_depth’: [1,2,3,4,5]>, мы включим наилучшую максимальную глубину, насколько это возможно.
Но как узнать, какая модель с наибольшей глубиной лучше? Нам нужен надежный метод скоринга для оценки каждой модели дерева решений с максимальной глубиной. Одним из самых классических методов является перекрестная проверка. Давайте рассмотрим K-кратную перекрестную проверку в качестве примера, чтобы подробно описать ее алгоритм. процесс.
Во-первых, давайте посмотрим, как делится набор данных.Полученный исходный набор данных сначала будет разделен на обучающий набор и тестовый набор в соответствии с определенным соотношением. Например, на следующем рисунке набор данных разделен на 8: 2:

Обучающий набор используется для обучения нашей модели. Его функции аналогичны упражнениям, которые мы обычно выполняем; набор тестов используется для оценки производительности нашей обученной модели. Модель не может увидеть его заранее.

Для max_depth = 2, 3, 4 и 5 выполните тот же процесс перекрестной проверки, что и max_depth = 1, чтобы получить их окончательные оценки проверки, а затем мы можем выполнить окончательные оценки проверки 5 самых больших деревьев решений глубины. Для сравнения, модель с наивысшим баллом является оптимальной максимальной глубиной.Мы используем оптимальные параметры для обучения новой модели на всех обучающих наборах, и вся модель является оптимальной моделью.
5.2 Простые примеры использования деревьев решений для прогнозирования рака груди
6. Возникла проблема
Вопрос 1: AttributeError: объект «GridSearchCV» не имеет атрибута «grid_scores_»



