Взаимно обратные функции, основные определения, свойства, графики
Понятие обратной функции
Для чего вообще нам нужно понятие обратных функций?
Нахождение взаимно обратных функций
Обратными по отношению друг к другу будут, например, функции арккосинуса и косинуса.
Разберем несколько задач на нахождение функций, обратных заданным.
Решение
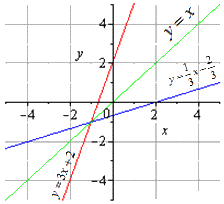
Обе взаимно обратные функции можно отобразить на графике следующим образом:
Возьмем пример, в котором нужно найти логарифмическую функцию, обратную заданной показательной.
Решение
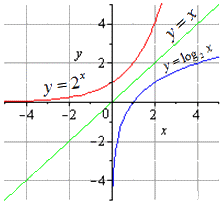
В итоге у нас вышли показательная и логарифмическая функции, которые будут взаимно обратными друг другу на всей области определения.
На графике обе функции будут выглядеть так:
Основные свойства взаимно обратных функций
a r c sin sin 7 π 3 = a r c sin sin 2 π + π 3 = = п о ф о р м у л е п р и в и д е н и я = a r c sin sin π 3 = π 3
Графики взаимно обратных функций
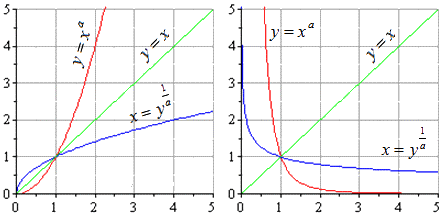
На графике они будут выглядеть следующим образом (случаи с положительным и отрицательным коэффициентом a):
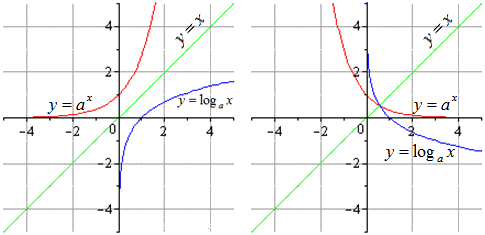
Графики для функций с a > 1 и a 1 будут выглядеть так:
Если нам нужно построить график главной ветви синуса и арксинуса, он будет выглядеть следующим образом (показан выделенной светлой областью):
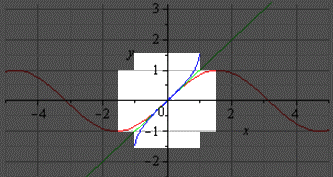
График главной ветви косинуса и арккосинуса выглядит так:
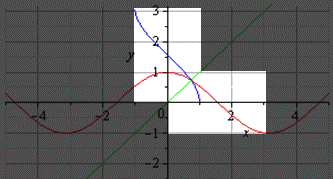
График главной ветви арктангенса и тангенса:
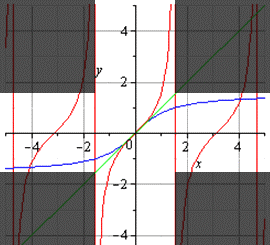
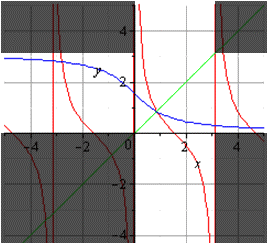
График главной ветви арккотангенса и котангенса будет таким:
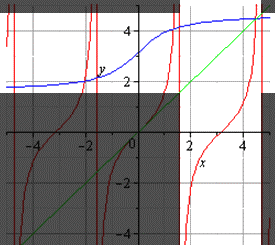
Это все свойства обратных функций, о которых мы хотели бы вам рассказать.
Что дальше? Или как правильно выбрать фичи для разработки
Грамотно и вовремя выбирать фичи для разработки и не прогадать – это про искусство приоритизации. Как найти критерии оценки, необходимые для своего продукта, вырастить стратегические показатели, предложить клиентам еще больше ценности, наладить все внутренние процессы в команде и добиться других наглядных показателей с помощью качественной приоритизации?

Эта статья написана по материалам доклада “Что дальше? Или искусство приоритизации”, с которым я выступил 26 июня на конференции BDS. Marketing.
В докладе я рассказал о том, как мы приоритизируем фичи в компании Hygger.io — системе управления проектами для продуктовых команд.
Прежде чем перейти к описанию нашего процесса, хочу кратко напомнить о том, почему приоритизация так важна.
Почему без приоритизации не выжить?
«Управление продуктом» означает принятие решения о том, что мы делаем для продукта, а затем его реализацию.
Райан Сингер, продуктовая стратегия Basecamp
Управление продуктом состоит из трех больших блоков:
И не будем кривить душой — я думаю, что многие product managers кайфуют от такой «лепки». От возможности влиять на то, каким будет продукт.
Отвлекающие факторы буквально убивают стартапы. Строительство ради строительства подобно самоубийству. Поэтому наличие строгого и честного процесса приоритизации для разработки функций имеет решающее значение для контроля внимания и устранения лишнего.
Бен Йосковитц, автор Lean Analytics, инвестор и стартап ментор.
Легко взять и потратить бесценное время команды на разработку фич, которые никому не нужны. Особенно эта проблема актуальна для стартапов, время и бюджет которых очень сильно ограничены.
Заблуждается тот, кто считает, что новая добавленная фича сразу заставит людей захотеть использовать весь продукт.
Джошуа Портер, UX директор в HubSpot
Стоит вспомнить интуицию — нашего лучшего «помощника», который постоянно «шепчет» нам на ухо: «Вот эта фича ну точно всех порвет!» И в другое ухо: «А вот эта фича догонит и порвет всех, кого не порвала первая фича».
Мы делаем такие фичи и потом удивляемся, почему вообще ничего не изменилось в продукте.
Известный в Силиконовой долине Marty Cagan в своей книге Inspired выделил три типа менеджеров продукта:
Процесс приоритизации в Hygger
Теперь я хочу рассказать о процессе, который помогает нам в Hygger выбирать будущие фичи и делать продукт все лучше и лучше.
На самом деле, все просто: мы ставим себе цели на 2 месяца, выбираем метрики для контроля, собираем и отбираем идеи, которые могут улучшить эти метрики. Далее мы проводим бережливую приоритизацию идей, делаем скоринг фич, и, наконец, пишем ТЗ на фичи, которые выиграли. Вот и все — фичи готовы к разработке.
Если все это систематизировать:
Формулируем Цели
У нас в продукте есть 2-х недельный trial. Мы хотим увеличить число компаний, которые после триала покупают платную подписку. Это наша основная цель на ближайшие 2 месяца. Также нам нужно отстроиться от конкурентов, ибо на рынке порядка 500 систем для управления проектами.
Выбираем Метрики
У нас есть основная метрика и вспомогательные. Важно, что все эти метрики находятся в нашей зоне влияния.
Основная метрика — конверсия trial-to-paid.
У каждого продукта своя ценность. Например, в Tinder это успешный обмен сообщениями, в Facebook — просмотр непустой ленты в течение какого-то времени.
Пользователей, которые прочувствовали эту ценность мы называем активированными. Наша задача увеличить число таких пользователей. В Facebook посчитали и выяснили, что на активацию влияет число друзей — чем больше друзей, тем больше лента и тем больше времени юзер зависает в ленте и больше рекламы смотрит.
Собираем идеи
Вот главные источники обратной связи для нашего продукта:
Организуем идеи
Так как фидбэка у нас очень много, то мы постоянно наводим порядок в нашем продуктовом бэклоге. Это помогает нам быстро находить нужные вещи и не отвлекаться на ненужные.
Как мы структурируем наш product backlog:
Делаем Lean-приоритизацию
Периодически, по мере накопления новых идей мы оцениваем их с помощью метода Lean Prioritization. Это простая матрица 2×2 c двумя осями — сложность и ценность:
1) Улучшают метрики конверсии trial-to-paid (metrics movers)
2) Помогают привлечь новых пользователей (aha-момент)
Это фичи, которые помогают нам зацепить новых пользователей во время онбординга. Но не нужно забывать про то, что большинство юзеров «отвалиться» уже на второй день. Например, в SaaS отличным показателем для day 1 retention считается 15%. То есть 85% людей попросту уходят на второй день. Поэтому здесь следует думать про фичи, которые увидит как можно больше новых пользователей как можно ближе к моменту регистрации.
3) Помогают удержать старых пользователей
Клиенты купили подписку и теперь просят сделать какую-то фичу. Мы не «бросаемся» слепо делать все подряд. Мы накапливаем статистику по каждой фиче — сколько клиентов ее просили. И потом делаем самые востребованные фичи.
4) Добавляют ценности продукту и отстраивают нас от конкурентов
На рынке порядка 500 систем управления проектами. Чтобы выжить и преуспеть, нам нужно делать что-то совершенно новое, желательно кратно улучшающее жизнь пользователей или кратно сокращающее издержки.
Здесь мы ищем фичи, которые могут дать нам конкурентное преимущество, то есть создадут причину, из-за которой клиенты конкурентов придут к нам. Это конкурентное преимущество должно быть уникально, трудно повторимо и, в идеале, не воспроизводимо.
Planning Poker
Для оценки идей мы используем Planning Poker:
Техники приоритизации
Daniel Zacarias собрал в коллекцию 20 техник приоритизации и сгруппировал их по двум свойствам — внешняя/внутренняя и количественная/качественная техника.
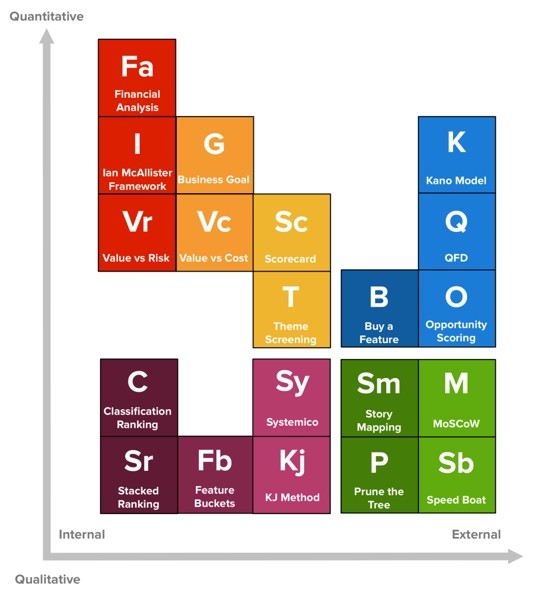
Пример внешней количественной техники — модель Кано, где мы даем опросник пользователям. А пример внутренней количественной техники — Lean Prioritization (или Value vs Cost). Я описал этот метод выше.
Скоринг Фичей
Скорим мы не все фичи, а только те, которые выиграли в Lean Prioritization, потому что скоринг — трудозатратная операция.
Мы оцениваем каждую фичу по выбранным критериям, по шкале от 0 до 10. Далее эти значения умножаем на веса и получаем некую финальную числовую оценку, которая позволяет нам сравнивать фичи между собой.

Критерии для скоринга
Вот различные критерии, которые можно использовать для скоринга:
Результаты
Итак, какие результаты принес нам этот процесс:
Оценка важности «фичей» для нелинейных моделей

Задачи, которые сегодня решает машинное обучение, зачастую являются комплексными и включают в себя большое количество признаков (фичей). Из-за сложности и многообразия исходных данных применение простых моделей машинного обучения часто не позволяет достигнуть необходимых результатов, поэтому в реальных бизнес-кейсах применяют сложные, нелинейные модели. У таких моделей есть существенный недостаток: из-за их сложности практически невозможно увидеть логику, по которой модель присвоила именно этот класс операции по счету. Особенно большое значение интерпретируемость модели играет, когда результаты ее работы необходимо представить заказчику — он скорее всего захочет узнать, на основе каких критериев принимаются решения для его бизнеса.
В стандартных пакетах для машинного обучения, таких как sklearn, xgboost, lightGBM существуют методы для оценки важности влияния на конечный результат той или иной фичи (параметра). Однако эти метрики важности не дают представление о том, как именно эти признаки влияют на предсказания модели. Например, как время проведенной операции указывает на то, была ли сделка мошеннической? Или как сильно адрес прописки владельца карты смещает предсказание модели? Для ответа на эти вопросы необходимо найти комплексное решение, которое помогло бы повысить интерпретируемость нелинейных моделей. Таким инструментом является библиотека SHAP. В библиотеке SHAP для оценки вклада фичей в итоговое предсказание моделей рассчитываются значения Шэпли. Для оценки важности фичи происходит оценка предсказаний модели, которая была обучена на основе датасета с и без данной фичи.
Рассмотрим работу данной библиотеки на примере определения мошеннических операций. Рассмотрим поля, которые есть в нашей таблице. В таблице содержится 213 столбцов, что довольно много для ручного перебора с помощью метода обучения модели без каждого признака поочередно для выявления важности каждой из фич.
Приведенный ниже код взят с kaggle и доработан для демонстрации функций рассматриваемого инструмента.
Загрузим наши датасеты:

В данном датасете представлена информация о времени транзакции, времени последней транзакции, домены электронных почт продавца и покупателя, временной промежуток между последней и предыдущей транзакцией и другие параметры, смысл некоторых был скрыт из соображений конфиденциальности.
Для решения поставленной задачи, которая заключается в обнаружении подозрительных (мошеннических) банковских транзакций, необходимо провести предобработку данных, так как данные весьма разнородны. Необходимо заменить категориальные переменные, нормализовать числовые значения, заполнить пропуски, а также создать новые признаки для модели.
После обучения модели на обработанных данных была получена следующая картина важности признаков.
Сделаем график важности фичей:
Исходя из этого видно, что большую значимость на определение мошеннических действий влияют дополнительные признаки, которые не имеют детального описания. Возникает вопрос: каким образом влияют эти признаки на работу классификатора? В таком формате информативность таблицы оценки важности признаков очень мала. Мы точно не знаем, что это за признак и мы абсолютно не знаем, как он влияет на конечный результат. Для того, чтобы получить интерпретируемый результат, применим библиотеку SHAP. В результате получим график, который показывает влияние признаков на то, какой вердикт сделает модель: была ли транзакция мошеннической или вы действительно покупаете моющие средства на сумму 20 тыс. рублей или 50 арбузов.
Сделаем график важности признаков для нашей нелинейной функции:
На графике присутствует информация о том, как сильно каждый параметр влияет на результат предсказания модели. Сам график разделен на 2 части вертикальной чертой. Слева от него находится класс «0», а справа класс «1». Толщина линии на графике напротив параметра показывает нам, как много элементов присутствует в выборке с данным значением конкретного параметра. Чем краснее точки на графике, тем большее значение имеет фича в ней. Исходя из легенды, которую предоставляют нам разработчики, библиотеки и получившегося графика, можно сделать вывод: чем выше была сумма транзакции, тем выше вероятность, что она была мошеннической. Также на предсказание модели сильно влияет адрес владельца карты, а также его домен email.
На основе полученных данных можно облегчать модель, то есть оставлять только параметры, которые оказывают значимое влияние на результаты предсказания нашей модели. Кроме того, появляется возможность оценить важность фичей для отдельных подгрупп данных, например, клиенты из разных регионов, транзакции в разное время суток и т. д. Кроме того, данный инструмент можно применять для анализа отдельных случаев, например, для анализа «выбросов» и экстремальных значений. Также SHAP может помочь в поиске западающих зон при классификации негативных явлений. Данный инструмент в комплексе с другими подходами позволит сделать модели более легкими, качественными, а результаты интерпретируемыми.
О том, какими бывают фичи, и как они создаются, будет рассказано в данной статье.

Виды и задачи фич
Чаще всего различные фичи используются:
в игровой индустрии. Фичами в играх могут быть необычные поведение персонажей или система диалога, конструкторы или внезапные сюжетные ходы;
в ПО основной фичей является кардинально новое оформление интерфейса;
В концепции продукта фича решает следующие задачи:
формирует механизм возвращения. Фичи должны быть привлекательными для пользователей и вырабатывать у них привычку к использованию функций сайта или приложения;
дает возможность измерять активацию пользователей продукта с помощью специальных метрик;
служит для повышения числа возвращений, вовлечений и для повышения монетизации продукта.
Кроме того, фичи должны «работать» на формирование положительного пользовательского опыта (UX). Это важно для успешности релиза, который должен иметь, благодаря внедрению тех или иных фич, высокие метрики. Фичи, которые делают продукт компании уникальным и отсутствуют в продуктах конкурентов, называются киллер-фичами.

Как фичи внедряются в продукт
Как правило, создание фич происходит обособленно от разработки общего продукта и включает следующие этапы:
формулирование основных целей, которых поможет достичь внедрение фич в проект (например, увеличение числа пользователей, приобретающих платную подписку, или отрыв от конкурентов);
выбор основных и вспомогательных метрик (ими могут быть количество посетителей, которые зарегистрировались на сайте, активация пользователей, понимающих ценность фичи, удержание пользователей);
сбор идей с помощью интервью, опросов, А/В-тестирования, записей на видео пользовательских сессий, UX-тестирования, продуктовой аналитики и анализа конкурентов;
расстановка приоритетов создания фич. Фичи оцениваются по их ценности (вкладу в продукт) и по трудозатратам на их реализацию. В зависимости от этих критериев фичи делятся на: Quick Wins (дающие большую ценность и наиболее быстро создаваемые), Big Bets (ценные, но труднореализуемые), Maybes (те, что легко реализуются, не имеют большой ценности и могут быть разработаны позже), Time Sinks (фичи не в приоритете);
отбор (скоринг) фич по критериям и их оценка по шкале от 0 до 10. Сравнение проводится по целевым метрикам, увеличению прибыли, привлечению и удержанию клиентов, по стратегической ценности и по иным параметрам;
внедрение фич в продукт и тестирование результатов. На этом этапе устраняются фичи, блокирующие развитие продукта, а также может быть создан новый альтернативный функционал.
ЦРК БИ (ЦЕНТР РАЗВИТИЯ КОМПЕТЕНЦИЙ В БИЗНЕС-ИНФОРМАТИКЕ) НИУ ВШЭ приглашает всех желающих пройти обучение по созданию успешных и ценных фич для различных направлений IT. Записаться на данные курсы можно на нашем сайте.
Составление требований к разработке фичей: Курс «Создание программного продукта и управление его развитием»
Привет, Хабр! Продолжая серию публикаций по продуктовому менеджменту, сегодня мы обсуждаем требования к разработке. В этом посте речь пойдет о том, как продуктовый менеджер взаимодействует с разработчиками из R&D, зачем нужны требования, как правильно их сформулировать, и какие выводы из требований к разработке должны делать различные специалисты, включая самих разработчиков, менеджеров, QA и так далее. С другой стороны будущие и уже состоявшиеся разработчики узнают, что может (и вообще-то должен) предоставлять вам менеджер продукта. Все подробности — под катом.
Оглавление курса
Как читают Feature Description?
Каждая категория пользователей может почерпнуть из требований полезную информацию для себя. И поэтому очень важно иметь в виду, что требования будут читать разные люди:
При составлении документа нужно быть максимально краткими и не оставлять непонятных мест. Requirements в любом случае будут занимать несколько страниц. Его должны прочитать много человек, и нужно, чтобы он был читабельным.
Руководствуйтесь простым правилом: начинайте с главного и только потом добавляйте детали. Кроме этого нужно получить обратную связь от QA, Developers, DevOps и других заинтересованных лиц. Скорее всего, Feature Description обрастет новыми деталями после общения со стейкхолдерами.
Постарайтесь подумать над неочевидными сценариями. Желательно сразу определить, что должно делать ваше приложение в нештатных ситуациях. Подумайте, какие внешние компоненты влияют на вашу фичу. А когда все уже будет готово, еще раз задайтесь вопросом: “Что еще можно протестировать кроме шагов, описанных в пользовательских сценариях?”
Заключение
В следующем материале мы поговорим о бизнес-плане и ценообразовании для нового продукта.
А пока делитесь в комментариях вашим опытом работы с требованиями, как со стороны менеджера, так и исполнителя. Расскажите, был ли в вашей практике пример, когда функциональный заказчик хотел одного, а в итоге получилось совсем другое из-за непонимания?
Лекция про дорожную карту и требования для разработки:
Разговариваете со своими разработчиками на разном языке? Сроки все время едут? Качество продукта оставляет желать лучшего? Пишите в личку, обсудим что с этим можно сделать.



