5 видов регрессии и их свойства
Jan 16, 2019 · 5 min read
Линейная и логистическая регрессии обычно являются первыми видами регрессии, которые изучают в таких областях, как машинное обучение и наука о данных. Оба метода считаются эффективными, так как их легко понять и использовать. Однако, такая простота также имеет несколько недостатков, и во многих случаях лучше выбирать другую регрессионную модель. Существует множество видов регрессии, каждый из которых имеет свои достоинства и недостатки.
Мы познакомимся с 7 наиболее распростран е нными алгоритмами регрессии и опишем их свойства. Также мы узнаем, в каких ситуация и с какими видами данных лучше использовать тот или иной алгоритм. В конце мы расскажем о некоторых инструментах для построения регрессии и поможем лучше разобраться в регрессионных моделях в целом!
Линейная регрессия
Регрессия — это метод, используемый для моделирования и анализа отношений между переменными, а также для того, чтобы увидеть, как эти переменные вместе влияют на получение определенного результата. Линейная регрессия относится к такому виду регрессионной модели, который состоит из взаимосвязанных переменных. Начнем с простого. Парная (простая) линейная регрессия — это модель, позволяющая моделировать взаимосвязь между значениями одной входной независимой и одной выходной зависимой переменными с помощью линейной модели, например, прямой.
Более распространенной моделью является множественная линейная регрессия, которая предполагает установление линейной зависимости между множеством входных независимых и одной выходной зависимой переменных. Такая модель остается линейной по той причине, что выход является линейной комбинацией входных переменных. Мы можем построить модель множественной линейной регрессии следующим образом:
Y = a_1*X_1 + a_2*X_2 + a_3*X_3 ……. a_n*X_n + b
Несколько важных пунктов о линейной регрессии:
Полиномиальная регрессия
Для создания такой модели, которая подойдет для нелинейно разделяемых данных, можно использовать полиномиальную регрессию. В данном методе проводится кривая линия, зависимая от точек плоскости. В полиномиальной регрессии степень некоторых независимых переменных превышает 1. Например, получится что-то подобное:
Y = a_1*X_1 + (a_2)²*X_2 + (a_3)⁴*X_3 ……. a_n*X_n + b
У некоторых переменных есть степень, у других — нет. Также можно выбрать определенную степень для каждой переменной, но для этого необходимы определенные знания о том, как входные данные связаны с выходными. Сравните линейную и полиномиальную регрессии ниже.
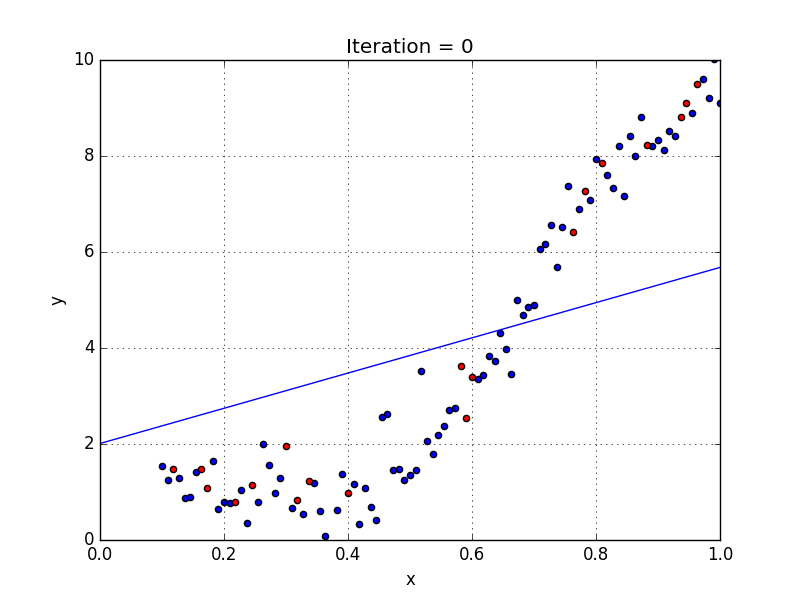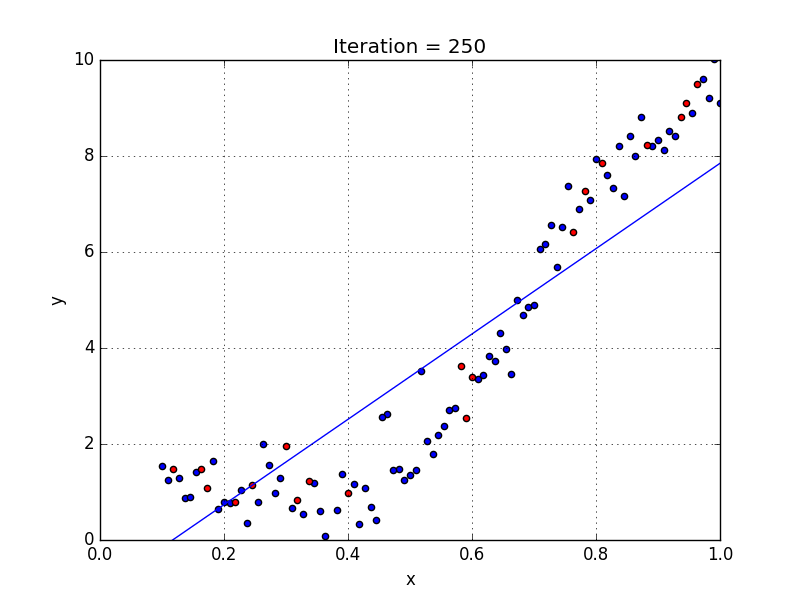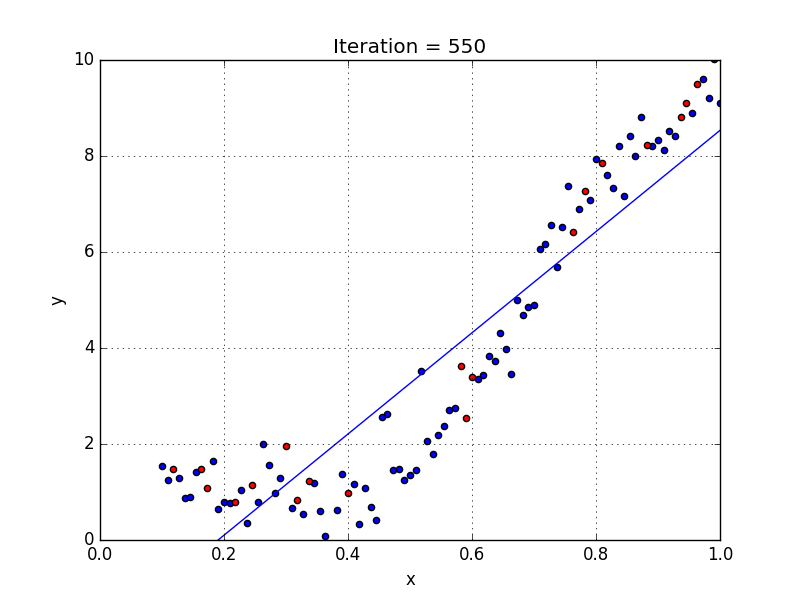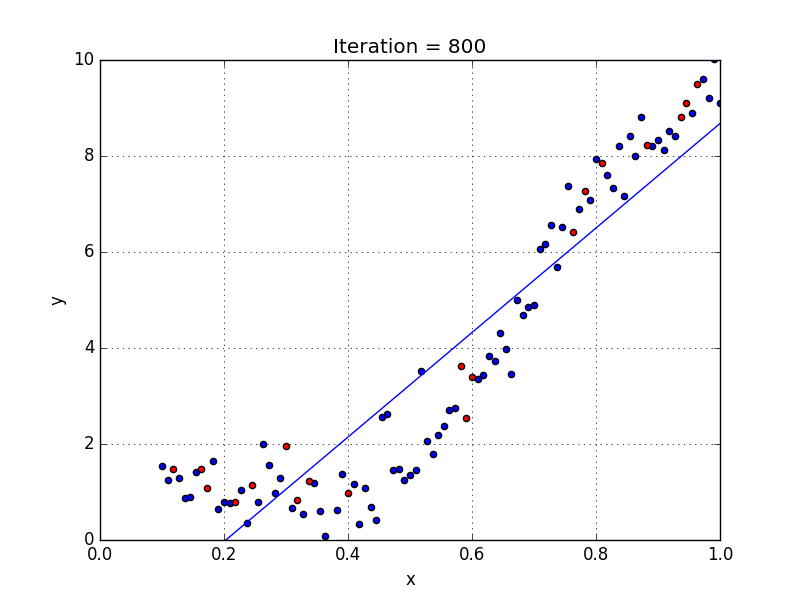

Несколько важных пунктов о полиномиальной регрессии:
Гребневая (ридж) регрессия
В случае высокой коллинеарности переменных стандартная линейная и полиномиальная регрессии становятся неэффективными. Коллинеарность — это отношение независимых переменных, близкое к линейному. Наличие высокой коллинеарности можно определить несколькими путями:
Сначала можно посмотреть на функцию оптимизации стандартной линейной регрессии для лучшего понимания того, как может помочь гребневая регрессия:
Где X — это матрица переменных, w — веса, y — достоверные данные. Гребневая регрессия — это корректирующая мера для снижения коллинеарности среди предикторных переменных в регрессионной модели. Коллинеарность — это явление, в котором одна переменная во множественной регрессионной модели может быть предсказано линейно, исходя из остальных свойств со значительной степенью точности. Таким образом, из-за высокой корреляции переменных, конечная регрессионная модель сведена к минимальным пределам приближенного значения, то есть она обладает высокой дисперсией.
Гребневая регрессия добавляет небольшой фактор квадратичного смещения для уменьшения дисперсии:
Такой фактор смещения выводит коэффициенты переменных из строгих ограничений, вводя в модель небольшое смещение, но при этом значительно снижая дисперсию.
Несколько важных пунктов о гребневой регрессии:
Регрессия по методу «лассо»
В регрессии лассо, как и в гребневой, мы добавляем условие смещения в функцию оптимизации для того, чтобы уменьшить коллинеарность и, следовательно, дисперсию модели. Но вместо квадратичного смещения, мы используем смещение абсолютного значения:
Существует несколько различий между гребневой регрессией и лассо, которые восстанавливают различия в свойствах регуляризаций L2 и L1:
Регрессия «эластичная сеть»
Эластичная сеть — это гибрид методов регрессии лассо и гребневой регрессии. Она использует как L1, так и L2 регуляризации, учитывая эффективность обоих методов.
min || Xw — y ||² + z_1|| w || + z_2|| w ||²
Практическим преимуществом использования регрессии лассо и гребневой регрессии является то, что это позволяет эластичной сети наследовать некоторую стабильность гребневой регрессии при вращении.
Несколько важных пунктов о регрессии эластичной сети:
Вывод
Вот и все! 5 распространенных видов регрессии и их свойства. Все данные методы регуляризации регрессии (лассо, гребневая и эластичной сети) хорошо функционирует при высокой размерности и мультиколлинеарности среди переменных в наборе данных.
Русские Блоги
Семь регрессионных моделей
Линейная регрессия и логистическая регрессия обычно являются первыми алгоритмами, с помощью которых люди изучают прогностические модели. Из-за популярности этих двух вариантов многие аналитики считают, что они являются единственной формой регрессии. Ученые, которые знают больше, будут знать, что они являются двумя основными формами всех регрессионных моделей.
Дело в том, что существует множество типов регрессии, и каждый тип регрессии имеет свои конкретные случаи применения. В этой статье я представлю наиболее распространенные модели регрессии в 7 в простой форме. В этой статье я надеюсь помочь вам получить более широкое и всестороннее понимание регрессии, а не просто знать, как использовать линейную регрессию и логистическую регрессию для решения практических задач.
В этой статье в основном будут представлены следующие аспекты:
Что такое регрессионный анализ?
Зачем использовать регрессионный анализ?
Какие бывают виды регрессии?
Полиномиальная регрессия (Полиномиальная регрессия)
Как выбрать подходящую регрессионную модель?
1. Что такое регрессионный анализ?

2. Зачем использовать регрессионный анализ?
Как упоминалось выше, регрессионный анализ может оценить взаимосвязь между двумя или более переменными. Давайте разберемся на простом примере:
Например, вы хотите оценить рост продаж компании на основе текущей экономической ситуации. У вас есть последние данные по компании, и эти данные показывают, что рост продаж примерно в 2,5 раза превышает экономический рост. Используя это понимание, мы можем предсказать будущие продажи компании на основе текущей и прошлой информации.
Использование регрессионных моделей дает множество преимуществ, например:
Выявляет значимую взаимосвязь между зависимыми и независимыми переменными
Выявить степень влияния нескольких независимых переменных на зависимую переменную
Регрессионный анализ также позволяет нам сравнивать влияние переменных, измеряемых в разных масштабах, таких как влияние изменений цен и количество рекламных мероприятий. Преимущество этого заключается в том, что он может помочь исследователям рынка / аналитикам данных / исследователям данных оценить и выбрать лучший набор переменных для построения прогнозных моделей.
3. Какие бывают типы регрессии?
Существует множество методов регрессии, которые можно использовать для прогнозирования. Эти методы регрессии в основном основаны на трех показателях (количество независимых переменных, типы переменных измерения и форма линии регрессии). Мы обсудим это подробно в следующих главах.

Для творческих людей вы можете комбинировать вышеуказанные параметры и даже создавать новые регрессии. Но перед этим рассмотрим наиболее распространенные типы регрессий.
1) Линейная регрессия
Линейная регрессия устанавливает связь между зависимой переменной (Y) и одной или несколькими независимыми переменными (X) с помощью наилучшей прямой линии (также называемой линией регрессии).

Разница между унарной линейной регрессией и множественной линейной регрессией состоит в том, что множественная линейная регрессия имеет более одной независимой переменной, тогда как унарная линейная регрессия имеет только одну независимую переменную. Следующий вопрос: «Как получить наиболее подходящую прямую?»
Как получить наиболее подходящую прямую (определить значения a и b)?


Мы можем использовать индикатор R-квадрат, чтобы оценить производительность модели.
Фокус:
Независимая переменная и зависимая переменная должны соответствовать линейной зависимости.
Множественная регрессия имеет множественную коллинеарность, автокорреляцию и гетероскедастичность.
Линейная регрессия очень чувствительна к выбросам. Выбросы серьезно повлияют на линию регрессии и окончательное прогнозируемое значение.
Мультиколлинеарность увеличивает дисперсию оценок коэффициентов и делает оценки очень чувствительными к небольшим изменениям в модели. В результате оценки коэффициентов нестабильны.
В случае нескольких независимых переменных мы можем использовать методы прямого выбора, обратного исключения и пошагового выбора, чтобы выбрать наиболее важную независимую переменную.
2) Логистическая регрессия
Логистическая регрессия используется для расчета вероятности успеха или неудачи события (неудачи). Когда зависимая переменная является двоичной (0/1, Истина / Ложь, Да / Нет), следует использовать логистическую регрессию. Здесь диапазон значений Y составляет [0,1], что может быть выражено следующим уравнением.
Из-за того, что мы используем биномиальное распределение (зависимая переменная), нам нужно выбрать подходящую функцию активации для отображения вывода между [0,1], и функция Logit соответствует требованиям. В приведенном выше уравнении наилучшие параметры получаются путем использования оценки максимального правдоподобия вместо использования линейной регрессии для минимизации квадратичной ошибки.

Фокус:
Логистическая регрессия широко используется для задач классификации.
Логистическая регрессия не требует линейной связи между зависимой переменной и независимой переменной. Она может обрабатывать несколько типов отношений, поскольку выполняет нелинейное преобразование журнала для предсказанных выходных данных.
Чем больше количество обучающих выборок, тем лучше, потому что, если количество выборок невелико, эффект оценки максимального правдоподобия будет хуже, чем у метода наименьших квадратов.
Независимые переменные не должны коррелироваться, то есть мультиколлинеарность отсутствует. Однако при анализе и моделировании мы можем выбрать включение эффектов взаимодействия категориальных переменных.
Если значение зависимой переменной является порядковым, это называется порядковой логистической регрессией.
Если зависимая переменная является мульти-категориальной, это называется множественной логистической регрессией.
3) Полиномиальная регрессия
В соответствии с уравнением регрессии, если индекс независимой переменной больше 1, то это уравнение полиномиальной регрессии, как показано ниже:
В полиномиальной регрессии наиболее подходящей линией является не прямая линия, а кривая, которая соответствует точкам данных.

Фокус:

Обратите особое внимание на два конца кривой, чтобы увидеть, имеют ли смысл эти формы и тенденции. Полиномы более высокого порядка могут приводить к странным результатам вывода.
4) Пошаговая регрессия
Когда мы имеем дело с несколькими независимыми переменными, используется пошаговая регрессия. В этом методе выбор независимых переменных осуществляется в автоматическом режиме без ручного вмешательства.
Пошаговая регрессия заключается в наблюдении статистических значений, таких как R-квадрат, t-статистика и индикаторы AIC, для определения важных переменных. На основе определенных критериев регрессионная модель постепенно настраивается путем добавления / удаления ковариатов. Распространенные методы пошаговой регрессии следующие:
Стандартная пошаговая регрессия выполняет две функции: на каждом шаге добавляются или удаляются независимые переменные.
Прямой отбор начинается с наиболее важной независимой переменной в модели, а затем на каждом этапе добавляются переменные.
Обратное исключение начинается со всех независимых переменных в модели, а затем на каждом шаге удаляется наименее значимая переменная.
5) Хребтовая регрессия
Ранее мы ввели уравнение линейной регрессии следующим образом:
Это уравнение также имеет погрешность, и полное уравнение может быть выражено как:
Риджевая регрессия решает проблему мультиколлинеарности за счет уменьшения параметра λ (лямбда). Рассмотрим следующее уравнение:

Фокус:
Если не предполагается нормальность, все предположения регрессии гребня и регрессии наименьших квадратов одинаковы.
Регрессия гребня уменьшила значение коэффициента, но не достигла нуля, что указывает на отсутствие функции выбора признаков.
Это метод регуляризации, использующий регуляризацию L2.
6) Регрессия лассо
Подобно гребневой регрессии, штраф за регрессию оператора наименьшей абсолютной усадки и выбора является абсолютным значением коэффициента регрессии. Кроме того, это может уменьшить изменчивость и повысить точность моделей линейной регрессии. Рассмотрим следующее уравнение:

Регрессия лассо отличается от регрессии гребня: функция штрафа использует сумму абсолютных значений коэффициентов вместо квадратов. Это приводит к штрафному члену (или эквиваленту суммы абсолютных значений оценок ограничений), так что некоторые оценки коэффициентов регрессии в точности равны нулю. Чем больше наложенный штраф, тем ближе оценка к нулю. Осознайте, что нужно выбирать из n переменных.
Фокус:
Если не предполагается нормальность, все предположения регрессии лассо и регрессии наименьших квадратов одинаковы.
Регрессия лассо уменьшает коэффициент до нуля (ровно до нуля), что помогает при выборе признаков.
Это метод регуляризации, который использует регуляризацию L1.
Если набор независимых переменных сильно коррелирован, то регрессия лассо выберет только одну из них, а остальные уменьшит до нуля.
7) Эластичная чистая регрессия

Одно из преимуществ взвешивания регрессии гребня и регрессии лассо состоит в том, что оно позволяет эластичной регрессии унаследовать некоторую стабильность регрессии гребня во вращающемся состоянии.
Фокус:
В случае сильно коррелированных переменных он поддерживает групповые эффекты.
Не имеет ограничений на количество выбранных переменных
Он имеет два коэффициента усадки λ1 и λ2.
В дополнение к этим 7 наиболее часто используемым методам регрессии вы также можете изучить другие модели, такие как байесовская, экологическая и робастная регрессия.
4. Как выбрать подходящую регрессионную модель?
Когда вы знаете только одну или две техники, жизнь обычно проста. Одна знакомая мне учебная организация сказала своим студентам: если результат непрерывен, используйте линейную регрессию; если результат двоичный, используйте логистическую регрессию! Однако чем больше вариантов доступно, тем сложнее выбрать правильный ответ. Аналогичная ситуация возникает и при выборе регрессионной модели.
В различных типах регрессионных моделей важно выбрать наиболее подходящий метод, основанный на типах независимых и зависимых переменных, измерениях данных и других существенных характеристиках данных. Вот несколько советов о том, как выбрать подходящую регрессионную модель:
Если набор данных содержит несколько смешанных переменных, вам не следует использовать метод автоматического выбора модели, потому что вы не хотите помещать эти смешанные переменные в модель одновременно.
Это также зависит от ваших целей. По сравнению с моделями с высокой статистической значимостью простые модели легче реализовать.
Вывод:
В этой статье я обсудил 7 типов методов регрессии и ключевые моменты, связанные с каждой регрессией. Как новичок в этой отрасли, я предлагаю вам изучить эти методы и реализовать эти модели в практических приложениях.
5 видов регрессии и их свойства

Линейная и логистическая регрессии обычно являются первыми видами регрессии, которые изучают в таких областях, как машинное обучение и наука о данных. Оба метода считаются эффективными, так как их легко понять и использовать. Однако, такая простота также имеет несколько недостатков, и во многих случаях лучше выбирать другую регрессионную модель. Существует множество видов регрессии, каждый из которых имеет свои достоинства и недостатки.
Мы познакомимся с 7 наиболее распространенными алгоритмами регрессии и опишем их свойства. Также мы узнаем, в каких ситуация и с какими видами данных лучше использовать тот или иной алгоритм. В конце мы расскажем о некоторых инструментах для построения регрессии и поможем лучше разобраться в регрессионных моделях в целом!
Линейная регрессия
Регрессия — это метод, используемый для моделирования и анализа отношений между переменными, а также для того, чтобы увидеть, как эти переменные вместе влияют на получение определенного результата. Линейная регрессия относится к такому виду регрессионной модели, который состоит из взаимосвязанных переменных. Начнем с простого. Парная (простая) линейная регрессия — это модель, позволяющая моделировать взаимосвязь между значениями одной входной независимой и одной выходной зависимой переменными с помощью линейной модели, например, прямой.
Более распространенной моделью является множественная линейная регрессия, которая предполагает установление линейной зависимости между множеством входных независимых и одной выходной зависимой переменных. Такая модель остается линейной по той причине, что выход является линейной комбинацией входных переменных. Мы можем построить модель множественной линейной регрессии следующим образом:
Y = a_1*X_1 + a_2*X_2 + a_3*X_3 ……. a_n*X_n + b
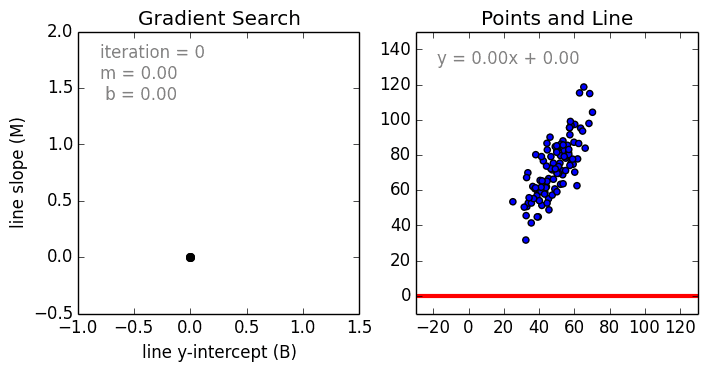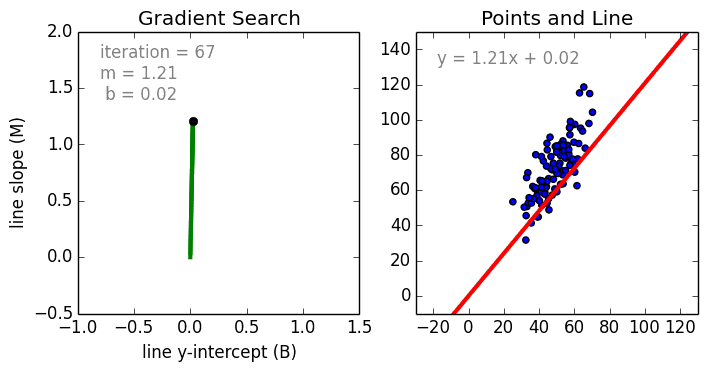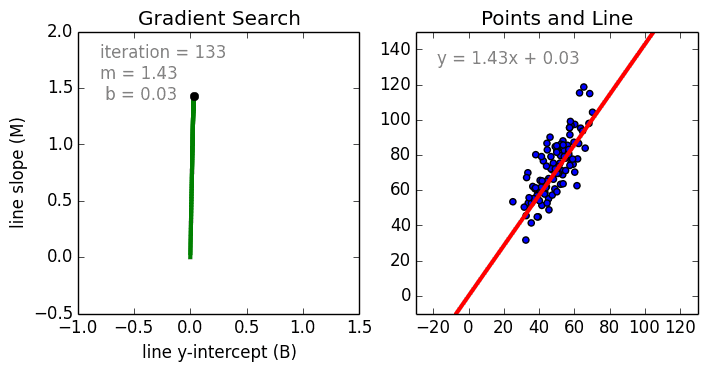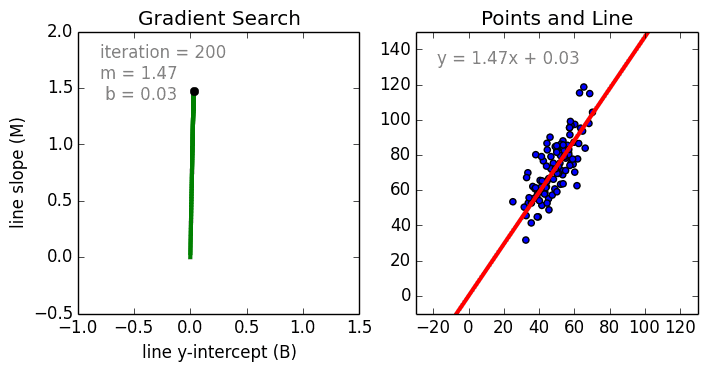
Несколько важных пунктов о линейной регрессии:
Полиномиальная регрессия
Для создания такой модели, которая подойдет для нелинейно разделяемых данных, можно использовать полиномиальную регрессию. В данном методе проводится кривая линия, зависимая от точек плоскости. В полиномиальной регрессии степень некоторых независимых переменных превышает 1. Например, получится что-то подобное:
Y = a_1*X_1 + (a_2)²*X_2 + (a_3)⁴*X_3 ……. a_n*X_n + b
У некоторых переменных есть степень, у других — нет. Также можно выбрать определенную степень для каждой переменной, но для этого необходимы определенные знания о том, как входные данные связаны с выходными. Сравните линейную и полиномиальную регрессии ниже.
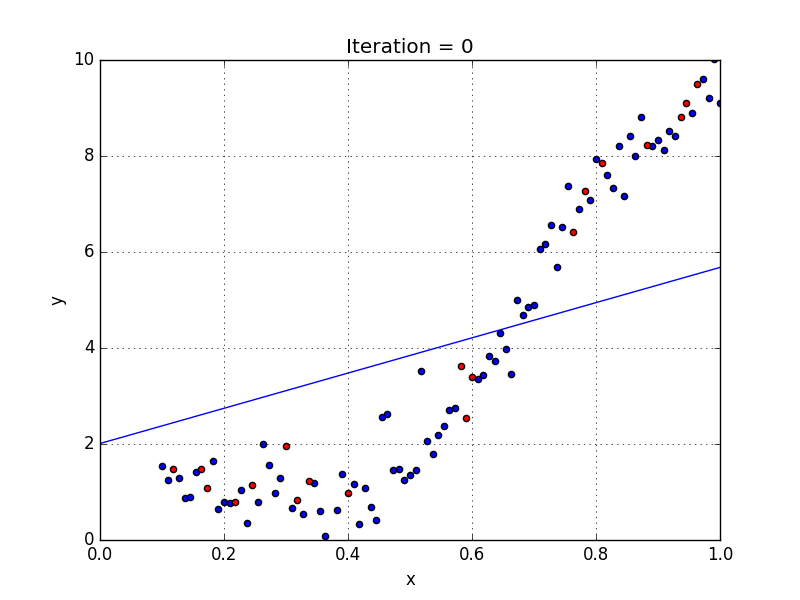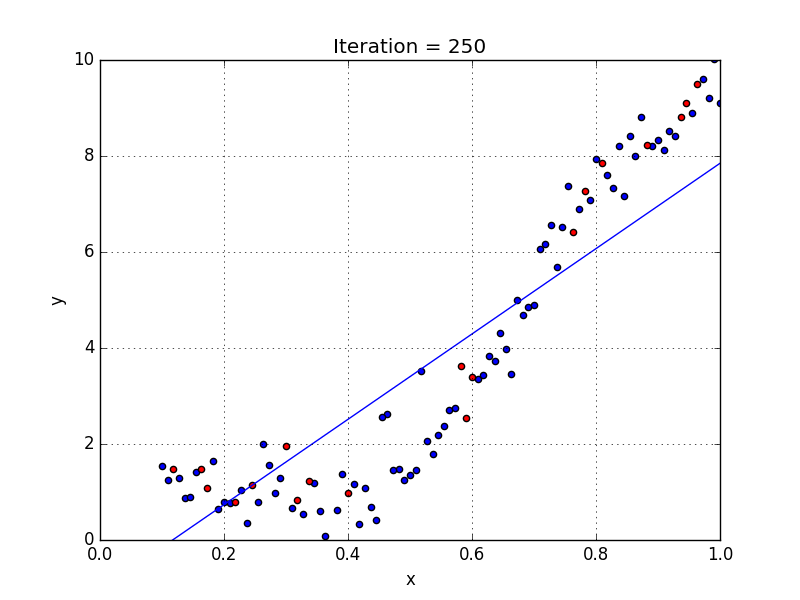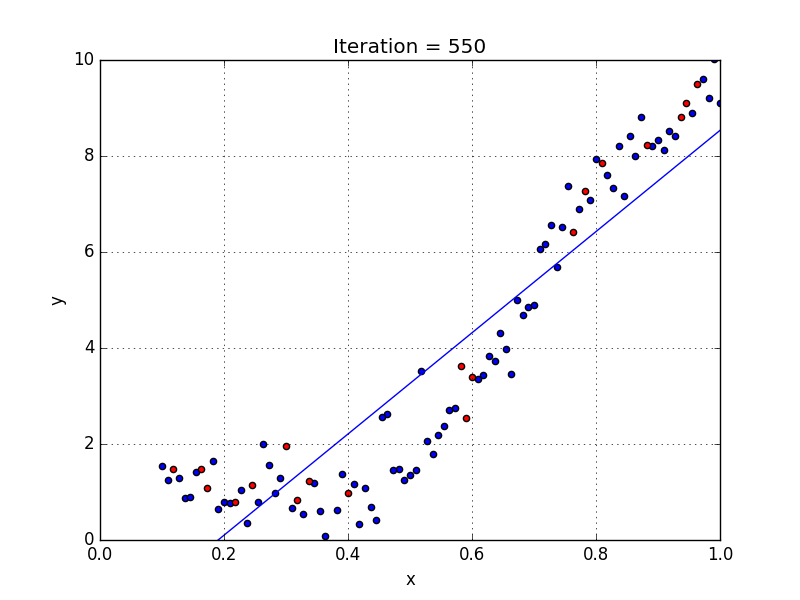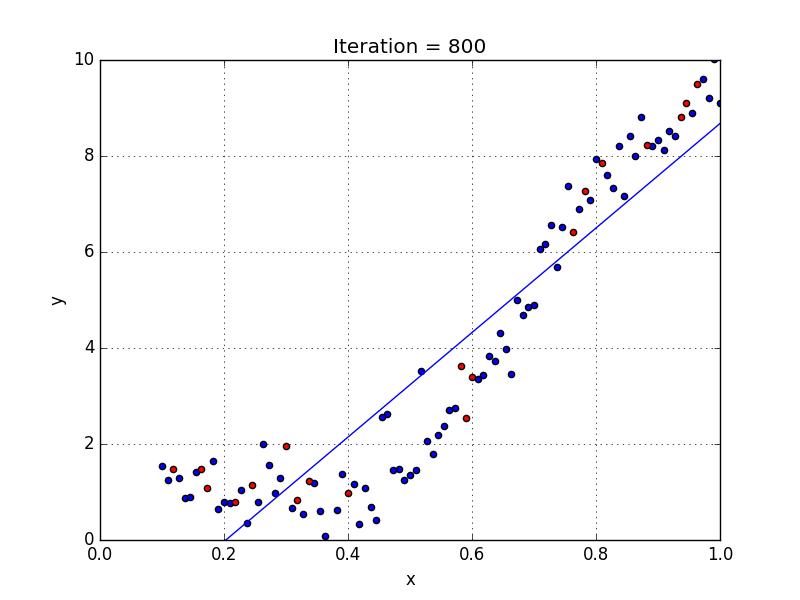
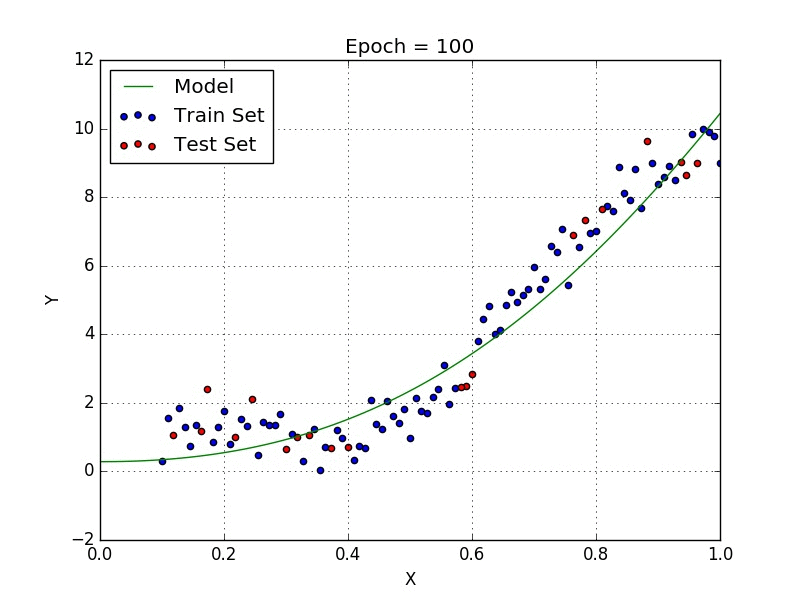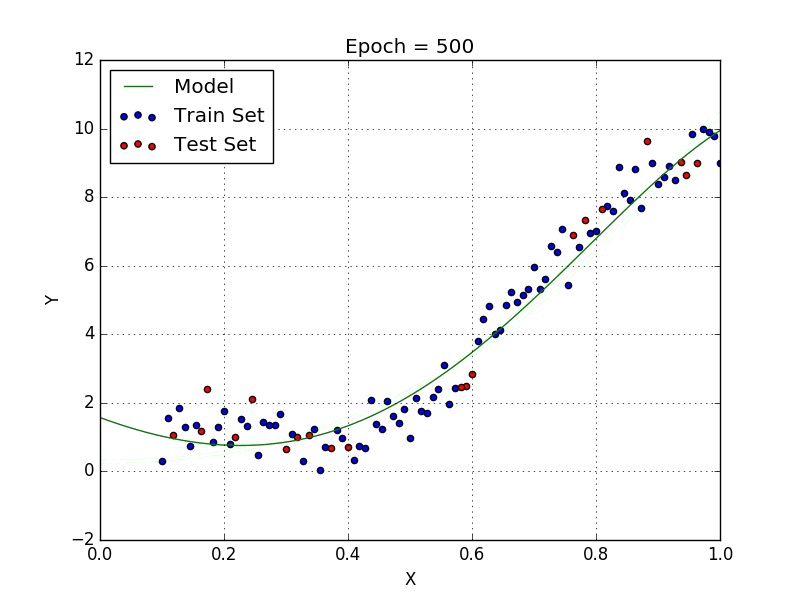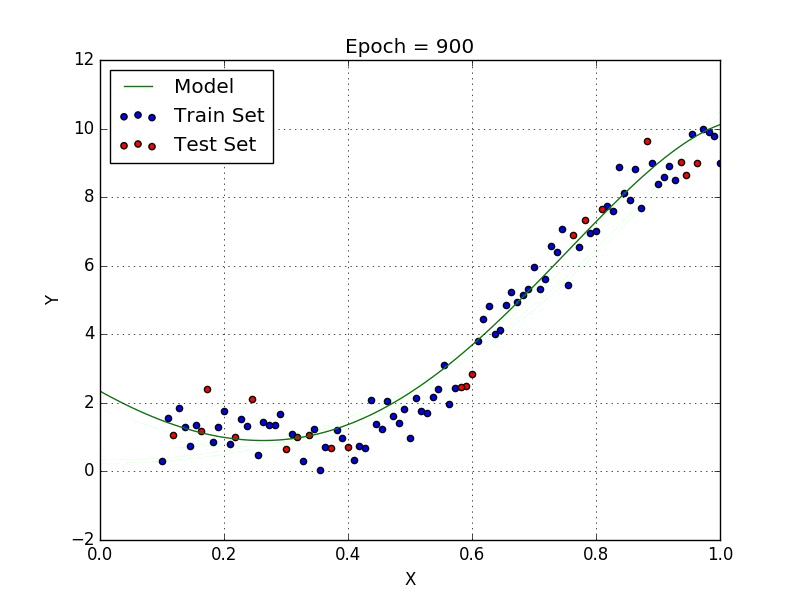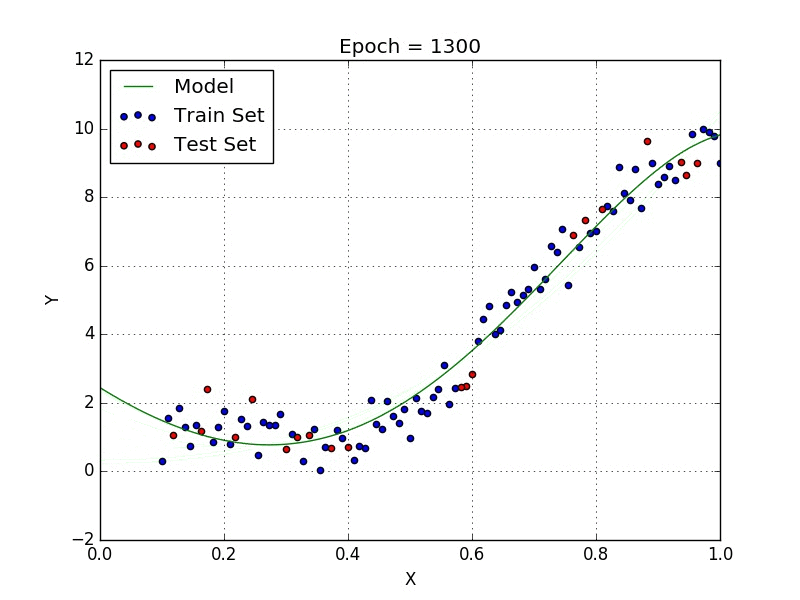
Несколько важных пунктов о полиномиальной регрессии:
Гребневая (ридж) регрессия
В случае высокой коллинеарности переменных стандартная линейная и полиномиальная регрессии становятся неэффективными. Коллинеарность — это отношение независимых переменных, близкое к линейному. Наличие высокой коллинеарности можно определить несколькими путями:
Сначала можно посмотреть на функцию оптимизации стандартной линейной регрессии для лучшего понимания того, как может помочь гребневая регрессия:
Где X — это матрица переменных, w — веса, y — достоверные данные. Гребневая регрессия — это корректирующая мера для снижения коллинеарности среди предикторных переменных в регрессионной модели. Коллинеарность — это явление, в котором одна переменная во множественной регрессионной модели может быть предсказано линейно, исходя из остальных свойств со значительной степенью точности. Таким образом, из-за высокой корреляции переменных, конечная регрессионная модель сведена к минимальным пределам приближенного значения, то есть она обладает высокой дисперсией.
Гребневая регрессия добавляет небольшой фактор квадратичного смещения для уменьшения дисперсии:
Такой фактор смещения выводит коэффициенты переменных из строгих ограничений, вводя в модель небольшое смещение, но при этом значительно снижая дисперсию.
Несколько важных пунктов о гребневой регрессии:
Регрессия по методу «лассо»
В регрессии лассо, как и в гребневой, мы добавляем условие смещения в функцию оптимизации для того, чтобы уменьшить коллинеарность и, следовательно, дисперсию модели. Но вместо квадратичного смещения, мы используем смещение абсолютного значения:
Существует несколько различий между гребневой регрессией и лассо, которые восстанавливают различия в свойствах регуляризаций L2 и L1:
Регрессия «эластичная сеть»
Эластичная сеть — это гибрид методов регрессии лассо и гребневой регрессии. Она использует как L1, так и L2 регуляризации, учитывая эффективность обоих методов.
min || Xw — y ||² + z_1|| w || + z_2|| w ||²
Практическим преимуществом использования регрессии лассо и гребневой регрессии является то, что это позволяет эластичной сети наследовать некоторую стабильность гребневой регрессии при вращении.
Несколько важных пунктов о регрессии эластичной сети:
Вывод
Вот и все! 5 распространенных видов регрессии и их свойства. Все данные методы регуляризации регрессии (лассо, гребневая и эластичной сети) хорошо функционирует при высокой размерности и мультиколлинеарности среди переменных в наборе данных.
R — значит регрессия
Статистика в последнее время получила мощную PR поддержку со стороны более новых и шумных дисциплин — Машинного Обучения и Больших Данных. Тем, кто стремится оседлать эту волну необходимо подружится с уравнениями регрессии. Желательно при этом не только усвоить 2-3 приемчика и сдать экзамен, а уметь решать проблемы из повседневной жизни: найти зависимость между переменными, а в идеале — уметь отличить сигнал от шума.

Для этой цели мы будем использовать язык программирования и среду разработки R, который как нельзя лучше приспособлен к таким задачам. Заодно, проверим от чего зависят рейтинг Хабрапоста на статистике собственных статей.
Введение в регрессионный анализ
Основу регрессионного анализа составляет метод наименьших квадратов (МНК), в соответствии с которым в качестве уравнения регресии берется функция  такая, что сумма квадратов разностей
такая, что сумма квадратов разностей  минимальна.
минимальна.
Карл Гаусс открыл, или точнее воссоздал, МНК в возрасте 18 лет, однако впервые результаты были опубликованы Лежандром в 1805 г. По непроверенным данным метод был известен еще в древнем Китае, откуда он перекочевал в Японию и только затем попал в Европу. Европейцы не стали делать из этого секрета и успешно запустили в производство, обнаружив с его помощью траекторию карликовой планеты Церес в 1801 г.
Вид функции , как правило, определен заранее, а с помощью МНК подбираются оптимальные значения неизвестных параметров. Метрикой рассеяния значений  вокруг регрессии
вокруг регрессии  является дисперсия.
является дисперсия.

Линейная регрессия
Уравнения линейной регрессии можно записать в виде

В матричном виде это выгладит

Случайная величина может быть интерпретирована как сумма из двух слагаемых:

Ограничения линейной регрессии
Для того, чтобы использовать модель линейной регрессии необходимы некоторые допущения относительно распределения и свойств переменных.
Как обнаружить, что перечисленные выше условия не соблюдены? Ну, во первых довольно часто это видно невооруженным глазом на графике.
Неоднородность дисперсии
При возрастании дисперсии с ростом независимой переменной имеем график в форме воронки.
Нелинейную регрессии в некоторых случая также модно увидеть на графике довольно наглядно.
Тем не менее есть и вполне строгие формальные способы определить соблюдены ли условия линейной регрессии, или нарушены.

В этой формуле  — коэффициент взаимной детерминации между
— коэффициент взаимной детерминации между  и остальными факторами. Если хотя бы один из VIF-ов > 10, вполне резонно предположить наличие мультиколлинеарности.
и остальными факторами. Если хотя бы один из VIF-ов > 10, вполне резонно предположить наличие мультиколлинеарности.
Почему нам так важно соблюдение всех выше перечисленных условий? Все дело в Теореме Гаусса-Маркова, согласно которой оценка МНК является точной и эффективной лишь при соблюдении этих ограничений.
Как преодолеть эти ограничения
Нарушения одной или нескольких ограничений еще не приговор.
К сожалению, не все нарушения условий и дефекты линейной регрессии можно устранить с помощью натурального логарифма. Если имеет место автокорреляция возмущений к примеру, то лучше отступить на шаг назад и построить новую и лучшую модель.
Линейная регрессия плюсов на Хабре
Итак, довольно теоретического багажа и можно строить саму модель.
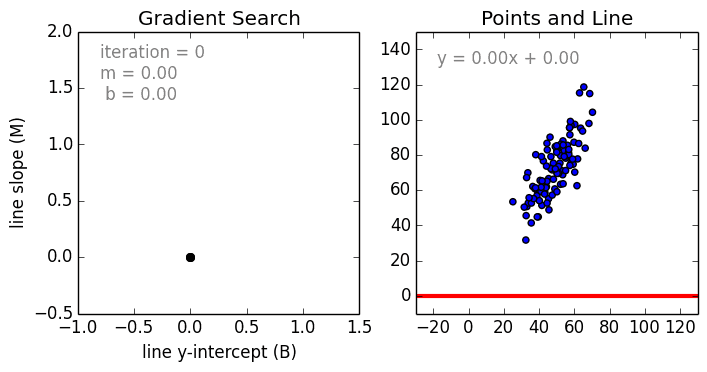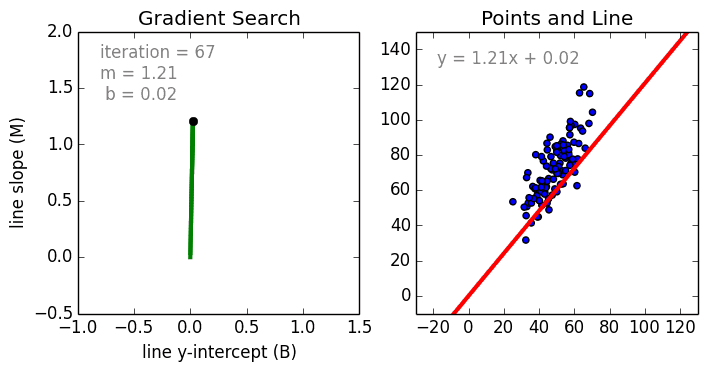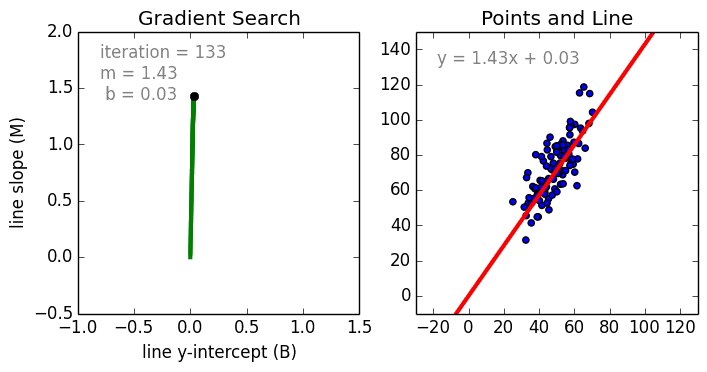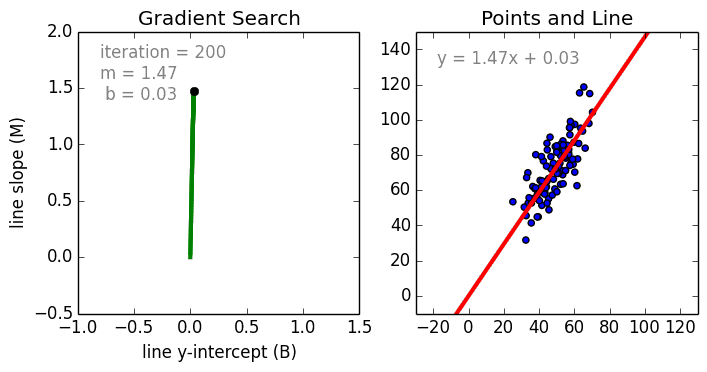
Мне давно было любопытно от чего зависит та самая зелененькая цифра, что указывает на рейтинг поста на Хабре. Собрав всю доступную статистику собственных постов, я решил прогнать ее через модель линейно регрессии.
Загружает данные из tsv файла.
Вопреки моим ожиданиям наибольшая отдача не от количества просмотров статьи, а от комментариев и публикаций в социальных сетях. Я также полагал, что число просмотров и комментариев будет иметь более сильную корреляцию, однако зависимость вполне умеренная — нет надобности исключать ни одну из независимых переменных.
В первой строке мы задаем параметры линейной регрессии. Строка points
. определяет зависимую переменную points и все остальные переменные в качестве регрессоров. Можно определить одну единственную независимую переменную через points
Перейдем теперь к расшифровке полученных результатов.

Можно попытаться несколько улучшить модель, сглаживая нелинейные факторы: комментарии и посты в социальных сетях. Заменим значения переменных fb и comm их степенями.
Проверим значения параметров линейной регрессии.
Проверим, соблюдены ли условия применимости модели линейной регрессии? Тест Дарбина-Уотсона проверяет наличие автокорреляции возмущений.
И напоследок проверка неоднородности дисперсии с помощью теста Бройша-Пагана.
В заключение
Конечно наша модель линейной регрессии рейтинга Хабра-топиков получилось не самой удачной. Нам удалось объяснить не более, чем половину вариативности данных. Факторы надо чинить, чтобы избавляться от неоднородной дисперсии, с автокорреляцией тоже непонятно. Вообще данных маловато для сколь-нибудь серьезной оценки.
Но с другой стороны, это и хорошо. Иначе любой наспех написанный тролль-пост на Хабре автоматически набирал бы высокий рейтинг, а это к счастью не так.



