Проверка значимости регрессии с помощью дисперсионного анализа (F-тест)
history 26 января 2019 г.
Проведем проверку значимости простой линейной регрессии с помощью процедуры F -тест.
Disclaimer : Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей Регрессионного анализа. Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения Регрессии – плохая идея.
Проверку значимости взаимосвязи переменных в рамках модели простой линейной регрессии можно провести разными, но эквивалентными между собой, способами:
Проверку значимости взаимосвязи переменных в рамках модели простой линейной регрессии можно провести разными, но эквивалентными между собой, способами:
F -тест для проверки значимости регрессии НЕ относится к простым и интуитивно понятным процедурам. Вероятно, это связано с тем, что для проведения F -теста требуется быть знакомым с определенным количеством статистических понятий и нужно неплохо разбираться в связанных с ними статистических методах. Нам потребуются понятия из следующих разделов статистики:
Можно, конечно, рассмотреть F -тест формально:
Определения, необходимые для F -теста
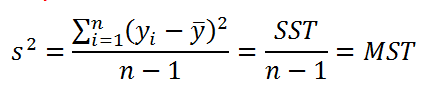
В формуле используется ряд сокращений:
Как видно из формулы, отношение величин SST и DFT обозначается как MST. Эти 3 величины обычно выдаются в таблице результатов дисперсионного анализа в различных прикладных статистических программах (в том числе и в надстройке Пакет анализа, инструмент Регрессия ).
Значение SST, характеризующую общую изменчивость переменной Y, можно разбить на 2 компоненты:
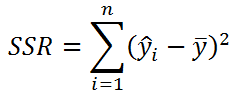
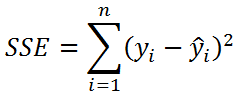
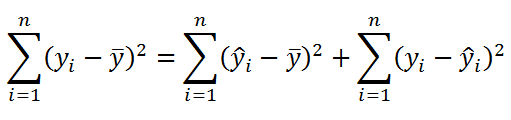
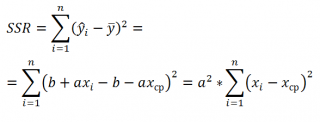
Примечание: Очевидность наличия только одной степени свободы проистекает из факта, что переменная Х – контролируемая (не является случайной величиной).
Число степеней свободы величины SSR имеет специальное обозначение: DFR (для простой регрессии DFR=1, т.к. число независимых переменных Х равно 1) . По аналогии с MST, отношение этих величин также часто обозначают MSR = SSR / DFR .
Отношение этих величин также часто обозначают MSE = SSE / DFE .
MSR и MSE имеют размерность дисперсий, хотя корректней их называть средними значениями квадратов отклонений. Тем не менее, ниже мы их будем «дисперсиями», т.к. они отображают меру разброса: MSE – меру разброса точек наблюдений относительно линии регрессии, MSR показывает насколько линия регрессии совпадает с горизонтальной линией среднего значения Y.
Число степеней свободы обладает свойством аддитивности: DFT = DFR + DFE . В этом можно убедиться, составив соответствующее равенство n -1=1+( n -2)
Процедура F -теста
Примечание : Чтобы быстрее разобраться с процедурой F -теста рекомендуется вспомнить процедуру проверки статистических гипотез о равенстве дисперсий 2-х нормальных распределений (т.е. двухвыборочный F-тест для дисперсий ).
Чтобы пояснить вышесказанное изобразим на диаграммах рассеяния 2 случая:
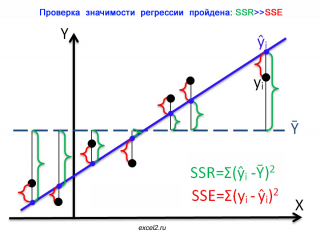
На первой диаграмме показан случай, когда регрессия значима:
Из диаграммы видно, что в случае значимой регрессии, сумма квадратов «зеленых» расстояний, гораздо больше суммы квадратов «красных». Понятно, что их отношение будет гораздо больше 1. Следовательно, и отношение дисперсий MSR и MSE будет гораздо больше 1 (не забываем, что SSE нужно разделить еще на соответствующее количество степеней свободы n-2).
Совершенно другую картину мы можем наблюдать в случае незначимой регрессии.
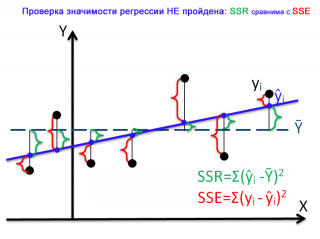
Очевидно, что в этом случае, сумма квадратов «зеленых» расстояний, примерно соответствует сумме квадратов «красных». Это означает, что объясненная дисперсия примерно соответствует величине необъясненной дисперсии (MSR/MSE будет близко к 1).
Если ответ о значимости регрессии практически очевиден для 2-х вышеуказанных крайних ситуаций, то как сделать правильное заключение для промежуточных углов наклона линии регрессии?
По умолчанию принимается, что нулевая гипотеза верна – связи между переменными нет. Если это так, то:
Ниже приведен график плотности вероятности F-распределения со степенями свободы 1 (в числителе) и 59 (знаменателе). 59=61-2, 61 наблюдение минус 2 степени свободы.
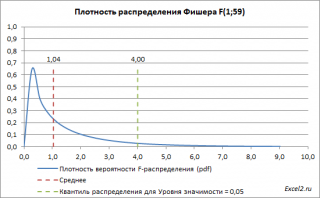
Значение статистики F0 может быть вычислено на основании выборки:
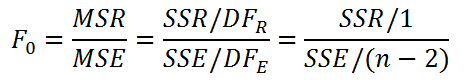
Вычисления в MS EXCEL
Таким образом, при значении статистики F0> F1-альфа, 1, n-2 мы имеем основание для отклонения нулевой гипотезы.
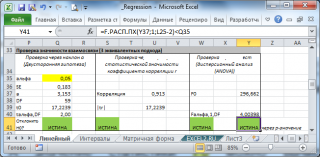
Значение F 0 можно вычислить на основании значений выборки по вышеуказанной формуле или с помощью функции ЛИНЕЙН() :
Проверка статистической значимости уравнения регрессии и его параметров
а) проверка статистической значимости уравнения:
Проверка значимости (существенности) уравнения регрессии позволяет установить, существенна ли связь включенных в уравнение признаков (Y и X), соответствует ли математическая модель, выражающая зависимость Y и X, фактическим данным и достаточно ли включенных в уравнение объясняющих переменных Х для описания зависимой переменной Y. Иными словами оценка значимости уравнения регрессии позволяет узнать пригодно ли оно для практического использования (например, для прогнозирования) или нет.
Оценка значимости уравнения регрессии проводится с помощью F-критерия Фишера:
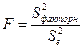
или в терминах коэффициента детерминации
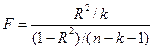 ,
,
где n – длина совокупностей данных, k – количество факторов, включенных в модель (в уравнении парной регрессии k=1).
Уравнение регрессии статистически значимо, если
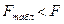 .
.
1) 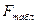 определяется максимальной величиной отношения дисперсий
определяется максимальной величиной отношения дисперсий 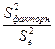 , которая может иметь место при случайном их расхождении для данного уровня вероятности наличия нулевой гипотезы (нулевая гипотеза о незначимости уравнения в целом);
, которая может иметь место при случайном их расхождении для данного уровня вероятности наличия нулевой гипотезы (нулевая гипотеза о незначимости уравнения в целом);
2) для определения можно использовать статистическую функцию FРАСПОБР, предварительно задав три параметра 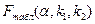 , где
, где 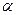 – заданный уровень значимости проверки или уровень вероятности ( связано с вероятностью Р формулой
– заданный уровень значимости проверки или уровень вероятности ( связано с вероятностью Р формулой 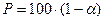 );
); 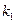 – число степеней свободы числителя, равное количеству k факторов, включенных в модель;
– число степеней свободы числителя, равное количеству k факторов, включенных в модель; 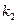 – число степеней свободы знаменателя (n-k-1). Таким образом, зависит от заданной вероятности, числа уровней в совокупностях данных и вида уравнения регрессии.
– число степеней свободы знаменателя (n-k-1). Таким образом, зависит от заданной вероятности, числа уровней в совокупностях данных и вида уравнения регрессии.
Пример (продолжение).
4) Проверить значимость уравнения регрессии с помощью F-критерия Фишера ( =0,05)
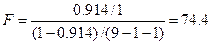
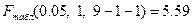
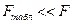
вывод: уравнение регрессии статистически значимо, связь включенных в него признаков существенна;
Значение F-критерия можно получить также в таблице «Дисперсионный анализ» отчета по работе с инструментом регрессия (рис. 13).
| Дисперсионный анализ | |||
| df | SS | MS | F |
| Регрессия | 2834.50 | 2834.50 | 74.2 |
| Остаток | 267.50 | 38.21 | |
| Итого | 3102.00 |
Рис. 13. Фрагмент регрессионного анализа
а) проверка статистической значимости параметров уравнения:
В линейной регрессии обычно оценивается значимость не только уравнения регрессии, но и отдельных его параметров. Для этого применяется t-критерий Стьюдента:
1) рассчитывают стандартные ошибки (среднеквадратические отклонения) 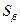 и
и 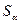 каждого из параметров уравнения
каждого из параметров уравнения 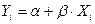 по формулам
по формулам
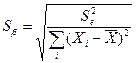 ,
, 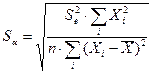 ,
,
где 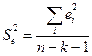 –остаточная дисперсия, k – число факторов в уравнении регрессии (в нашем случае k=1);
–остаточная дисперсия, k – число факторов в уравнении регрессии (в нашем случае k=1);
2) определяют расчетные значения t-критерия Стьюдента:
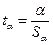 ,
, 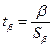 ;
;
3) определяют табличное значение t-критерия 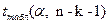 с помощью статистической функции СТЬЮДРАСПОБР по двум параметрам: заданному уровню значимости и одной степени свободы (n-k-1);
с помощью статистической функции СТЬЮДРАСПОБР по двум параметрам: заданному уровню значимости и одной степени свободы (n-k-1);
4) параметры уравнения регрессии будут статистически значимы, если выполняются неравенства:
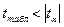 ,
, 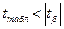 .
.
Замечания:
1) статистическая значимость (незначимость) коэффициента регрессии 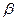 означает одновременно статистическую значимость (незначимость) фактора Х, включенного в уравнение; статистически незначимый (или несущественный) фактор должен быть устранен из модели или заменен другим;
означает одновременно статистическую значимость (незначимость) фактора Х, включенного в уравнение; статистически незначимый (или несущественный) фактор должен быть устранен из модели или заменен другим;
2) статистическая значимость (незначимость) параметра уравнения означает верную (неверную) спецификацию модели; под спецификацией понимают:
а) выбор вида уравнения;
б) определение независимых факторов для включения в модель;
3) t-критерий можно использовать также для определения интервальных оценок параметров модели:
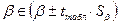 ,
,
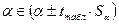 .
.
Поскольку коэффициент регрессии в эконометрических исследованиях имеет четкую экономическую интерпретацию, доверительные границы интервала для коэффициента регрессии не должны содержать противоречивых результатов, то есть не должны содержать одновременно положительные и отрицательные величины и даже нуль.
Пример (продолжение).
4) осуществить проверку значимости параметров уравнения регрессии по t-критерию Стьюдента ( =0,05)
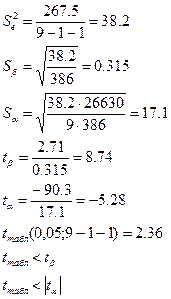
Вывод: оба параметра модели статистически значимы.
Дополнение: интервальные оценки параметров
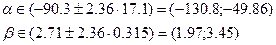
Расчетные значения t-критерия, а также интервальные оценки параметров можно найти в отчете по результатам работы с инструментом Регрессия (рис. 14).
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | |
| Y | -90.33 | 17.12 | -5.28 | 0.00 | -130.80 | -49.86 |
| X | 2.71 | 0.31 | 8.61 | 0.00 | 1.97 | 3.45 |
Рис. 14. Фрагмент регрессионного анализа
2.4. Экономический прогноз
Рассматриваемая модель 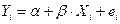 может быть использована для определения прогнозных оценок исследуемой величины. При прогнозировании на основе регрессионных моделей можно выделить три основных этапа:
может быть использована для определения прогнозных оценок исследуемой величины. При прогнозировании на основе регрессионных моделей можно выделить три основных этапа:
1) точечный прогноз фактора Х;
2) точечный прогноз показателя Y;
3) интервальный прогноз показателя Y.
Рассмотрим содержание этих этапов подробнее.
1) точечный прогноз фактора Хв зависимости от специфики исходных данных и условия задачи можно определить одним из следующих способов:
а) если исходные данные являются временными рядами, то для прогноза фактора можно воспользоваться методами экстраполяции и использовать наиболее подходящую модель временного ряда
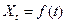 .
.
Тогда прогноз фактора на k шагов вперед определяется по формуле
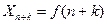 .
.
б)вслучае временных рядов 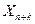 можно найти также с помощью среднего абсолютного прироста (САП) по формуле
можно найти также с помощью среднего абсолютного прироста (САП) по формуле
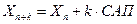 ,
, 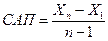 .
.
в)если исходные данные являются пространственными, то, очевидно, в задаче будет задано правило для определения 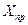 . Например, если прогнозное значение фактора составляет 80 % от его среднего значения, то
. Например, если прогнозное значение фактора составляет 80 % от его среднего значения, то 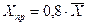 .
.
2) точечный прогноз показателя Yнаходят подстановкой в модель прогнозных значений фактора:
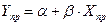 – в случае пространственных данных,
– в случае пространственных данных,
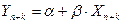 – в случае временных рядов.
– в случае временных рядов.
3) интервальный прогноз показателя Y:
вначале находят ошибку прогнозирования
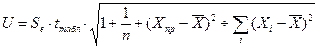 ,
,
которая зависит от стандартной ошибки модели 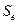 , удаления от своего среднего значения, количества наблюдений n, заданного уровня вероятности попадания в интервал прогноза (он определяет величину
, удаления от своего среднего значения, количества наблюдений n, заданного уровня вероятности попадания в интервал прогноза (он определяет величину 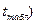 ;
;
затем находят сам доверительный интервал прогноза:
нижняя граница интервала – 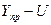 ,
,
верхняя граница интервала – 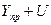 .
.
Пример (продолжение).
5) осуществить прогнозирование среднего значения показателя Y при уровне значимости =0,1, если прогнозное значение фактора Х составит 117 % от его максимального значения
1) точечный прогноз фактора Х
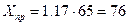 ,
,
2) точечный прогноз показателя Y
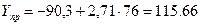
3) интервальный прогноз показателя Y
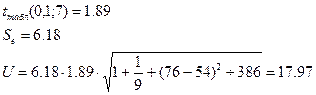
Нижняя граница интервала: 115,66-17,97=97,69
Верхняя граница интервала: 115,66+17,97=133,63.


Поперечные профили набережных и береговой полосы: На городских территориях берегоукрепление проектируют с учетом технических и экономических требований, но особое значение придают эстетическим.

Организация стока поверхностных вод: Наибольшее количество влаги на земном шаре испаряется с поверхности морей и океанов (88‰).

R — значит регрессия
Статистика в последнее время получила мощную PR поддержку со стороны более новых и шумных дисциплин — Машинного Обучения и Больших Данных. Тем, кто стремится оседлать эту волну необходимо подружится с уравнениями регрессии. Желательно при этом не только усвоить 2-3 приемчика и сдать экзамен, а уметь решать проблемы из повседневной жизни: найти зависимость между переменными, а в идеале — уметь отличить сигнал от шума.

Для этой цели мы будем использовать язык программирования и среду разработки R, который как нельзя лучше приспособлен к таким задачам. Заодно, проверим от чего зависят рейтинг Хабрапоста на статистике собственных статей.
Введение в регрессионный анализ
Основу регрессионного анализа составляет метод наименьших квадратов (МНК), в соответствии с которым в качестве уравнения регресии берется функция  такая, что сумма квадратов разностей
такая, что сумма квадратов разностей  минимальна.
минимальна.
Карл Гаусс открыл, или точнее воссоздал, МНК в возрасте 18 лет, однако впервые результаты были опубликованы Лежандром в 1805 г. По непроверенным данным метод был известен еще в древнем Китае, откуда он перекочевал в Японию и только затем попал в Европу. Европейцы не стали делать из этого секрета и успешно запустили в производство, обнаружив с его помощью траекторию карликовой планеты Церес в 1801 г.
Вид функции , как правило, определен заранее, а с помощью МНК подбираются оптимальные значения неизвестных параметров. Метрикой рассеяния значений  вокруг регрессии
вокруг регрессии  является дисперсия.
является дисперсия.

Линейная регрессия
Уравнения линейной регрессии можно записать в виде

В матричном виде это выгладит

Случайная величина может быть интерпретирована как сумма из двух слагаемых:

Ограничения линейной регрессии
Для того, чтобы использовать модель линейной регрессии необходимы некоторые допущения относительно распределения и свойств переменных.
Как обнаружить, что перечисленные выше условия не соблюдены? Ну, во первых довольно часто это видно невооруженным глазом на графике.
Неоднородность дисперсии
При возрастании дисперсии с ростом независимой переменной имеем график в форме воронки.
Нелинейную регрессии в некоторых случая также модно увидеть на графике довольно наглядно.
Тем не менее есть и вполне строгие формальные способы определить соблюдены ли условия линейной регрессии, или нарушены.

В этой формуле  — коэффициент взаимной детерминации между
— коэффициент взаимной детерминации между  и остальными факторами. Если хотя бы один из VIF-ов > 10, вполне резонно предположить наличие мультиколлинеарности.
и остальными факторами. Если хотя бы один из VIF-ов > 10, вполне резонно предположить наличие мультиколлинеарности.
Почему нам так важно соблюдение всех выше перечисленных условий? Все дело в Теореме Гаусса-Маркова, согласно которой оценка МНК является точной и эффективной лишь при соблюдении этих ограничений.
Как преодолеть эти ограничения
Нарушения одной или нескольких ограничений еще не приговор.
К сожалению, не все нарушения условий и дефекты линейной регрессии можно устранить с помощью натурального логарифма. Если имеет место автокорреляция возмущений к примеру, то лучше отступить на шаг назад и построить новую и лучшую модель.
Линейная регрессия плюсов на Хабре
Итак, довольно теоретического багажа и можно строить саму модель.
Мне давно было любопытно от чего зависит та самая зелененькая цифра, что указывает на рейтинг поста на Хабре. Собрав всю доступную статистику собственных постов, я решил прогнать ее через модель линейно регрессии.
Загружает данные из tsv файла.
Вопреки моим ожиданиям наибольшая отдача не от количества просмотров статьи, а от комментариев и публикаций в социальных сетях. Я также полагал, что число просмотров и комментариев будет иметь более сильную корреляцию, однако зависимость вполне умеренная — нет надобности исключать ни одну из независимых переменных.
В первой строке мы задаем параметры линейной регрессии. Строка points
. определяет зависимую переменную points и все остальные переменные в качестве регрессоров. Можно определить одну единственную независимую переменную через points
Перейдем теперь к расшифровке полученных результатов.

Можно попытаться несколько улучшить модель, сглаживая нелинейные факторы: комментарии и посты в социальных сетях. Заменим значения переменных fb и comm их степенями.
Проверим значения параметров линейной регрессии.
Проверим, соблюдены ли условия применимости модели линейной регрессии? Тест Дарбина-Уотсона проверяет наличие автокорреляции возмущений.
И напоследок проверка неоднородности дисперсии с помощью теста Бройша-Пагана.
В заключение
Конечно наша модель линейной регрессии рейтинга Хабра-топиков получилось не самой удачной. Нам удалось объяснить не более, чем половину вариативности данных. Факторы надо чинить, чтобы избавляться от неоднородной дисперсии, с автокорреляцией тоже непонятно. Вообще данных маловато для сколь-нибудь серьезной оценки.
Но с другой стороны, это и хорошо. Иначе любой наспех написанный тролль-пост на Хабре автоматически набирал бы высокий рейтинг, а это к счастью не так.



