Поиск информации в Web
В Интернете размещены миллионы сайтов, причем с актуальной информацией соседствует много устаревших ресурсов, мусора и недобросовестной рекламы.
Однако отсутствие единоначалия и единых требований по оформлению информации приводит к тому, что в Сети мало кто озабочен тем, чтобы избежать дублирования информации или следовать стандартам, принятым на сайте соседа. И здесь наблюдается резкий контраст с корпоративным документооборотом, описанным ранее.
Находить информацию в Интернете, вероятно, было бы очень трудно, если бы не были созданы мощные поисковые инструменты: поисковые машины (поисковики), каталоги ( рубрикаторы ), рейтинги, метапоисковые системы и тематические списки ссылок, онлайновые энциклопедии и справочники.
Как показывает практика, для поиска разного рода информации наиболее эффективными оказываются различные инструменты (рис. 4.19). Рассмотрим каждую категорию по отдельности.
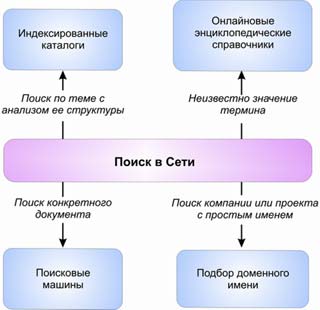
Индексированные каталоги
Каталог представляет собой данные, структурированные по темам в виде иерархических структур. Тематические разделы первого уровня определяют наиболее популярные, максимально широкие темы, такие как «спорт», «отдых», «наука», «магазины» и т.д. В каждом таком разделе есть подразделы. Таким образом, пользователь может уточнять интересующую его область, путешествуя по дереву каталога и постепенно сужая область поиска. Например, при поиске информации о ноутбуках цепочка поиска может выглядеть следующим образом:
Дойдя до нужного подкаталога, пользователь находит в нем набор ссылок.
Обычно в каталоге все ссылки являются профильными, поскольку составлением каталогов занимаются не программы, а люди. Очевидно, что если ведется поиск общей информации по некоторой широкой теме, то целесообразно обратиться к каталогу. Если же необходимо найти конкретный документ, то каталог окажется малоэффективным поисковым средством.
Иерархические структуры данных и Doctrine
Введение
Хранение иерархических данных (или попросту — деревьев) в реляционных структурах задача довольно нетривиальная и вызывает некоторые проблемы, когда разработчики сталкиваются с подобной задачей.
В первую очередь, это связано с тем, что реляционные базы не приспособлены к хранению иерархических структур (как, например, XML-файлы), структура реляционных таблиц представляет из себя простые списки. Иерархические же данные имеют связь «родитель-наследники», которая не реализована в реляционной структуре.
Тем не менее, задача «хранить деревья в базе данных» рано или поздно возникает перед любым разработчиком.
Ниже мы подробно рассмотрим, какие существуют подходы в организации хранения деревьев в реляционных БД, а также рассмотрим инструментарий, который нам предоставляет ORM Doctrine для работы с такими структурами.
Список смежных вершин (Adjacency List)
Описание структуры
Как правило, такая структура данных предполагает хранение информации о смежных вершинах нашего дерева. Давайте рассмотрим простейший граф с темя вершинами (1,2,3):

Рис. 1. Граф с тремя вершинами
Как видим каждый элемент данного графа хранит информацию о связи с другими элементами, т.е.:
Фактически, для построения дерева такой граф избыточен, т.к. для привычной ветвистой структуры нам нужно хранить только связь «родитель-наследник», т.е.:
Тогда мы получим дерево с одним корневым элементом (1) и двумя ветками (2,3):
В принципе, тот и другой графы можно, при желании, отобразить в базе данных с помощью списка смежных вершин, но, поскольку нас интересуют именно деревья, остановимся на них.
Итак, чтобы хранить в базе данных иерархическую структуру методом списка смежных вершин (Adjacency List), нам необходимо хранить информацию о связях «наследник-родитель» в таблицах с данными. Давайте рассмотрим реальный пример дерева:
Рис. 3. Древовидная структура методом смежных вершин
На рисунке квадратами обозначены узлы деревьев. У каждого узла есть имя (верхний прямоугольник внутри квадрата), идентификатор (левый нижний квадрат) и ссылка на идентификатор родителя (правый нижний квадрат). Как видно из Рис. 3, каждый наследник в такой структуре ссылается на своего предка. В терминах БД мы можем это отобразить следующим образом в виде таблицы:
Рис. 4. Таблица данных дерева, построенная методом списка смежных вершин
Следует сразу отметить, что такой алгоритм хранения деревьев обладает определенными как достоинствами, так и недостатками. В первую очередь, он не совсем удобен для чтения — и это его основной недостаток.
Проблемы с чтением из БД менее заметны, если вычитывать все дерево целиком. Это достаточно простой запрос:
Однако в дальнейшем такая выборка подразумевает достаточно емкую программную пост-обработку данных. Сначала нужно рекурсивно перестроить данные с учетом связей «предок-наследник» и лишь потом их можно будет использовать для вывода куда-либо.
Другой вариант чтения дерева целиком:
Результат в данном случае будет такой:
Хотя данные в таком виде уже более приспособлены сразу для вывода, но, как видите, главный недостаток такого подхода — необходимо достоверно знать количество уровней вложенности в вашей иерархии, кроме того, чем больше иерархия, тем больше JOIN’ов — тем ниже производительность.
Тем не менее, данный способ обладает и существенными достоинствами — в дерево легко вносить изменения, менять местами и удалять узлы.
Вывод — данный алгоритм хорошо применим, если вы оперируете с небольшими древовидными структурами, которые часто поддаются изменениям.
С другой стороны, этот алгоритм также довольно уверенно себя чувствует и с большими деревьями, если считывать их порциями вида «знаю родителя — прочитать всех наследников». Хороший пример такого случая — динамически подгружаемые деревья. В этом случае алгоритм практически оптимизирован для такого поведения.
Однако он плохо применим, когда нужно вычитывать какие-либо иные куски дерева, находить пути, предыдущие и следующие узлы при обходе и вычитывать ветки дерева целиком (на всю глубину).
Использование списка смежных вершин в Doctrine
Сначала хотелось бы высказать несколько вводных слов по организации шаблонов таблиц в Doctrine, с помощью которых подобные вещи в ней и реализуются. Те, кто уже знаком с этой концепцией в доктрине, может перескочить несколько абзацев вперед к более интересным вещам.
Итак, сущности, которыми мы оперируем в ORM Doctrine — это активные записи (Active Record). Т.е. объекты, которые совмещают в себе бизнес-логику и сами умеют взаимодействовать с базой данных. Но разработчики Doctrine предусмотрели расширение функциональности объектов записей не только наследованием, но и применением к этим объектам «шаблонов поведения». Это реализуется пакетом Doctrine/Template.
Т.о., если возникает необходимость воспитать активную запись до какого-либо поведения (например, Versionable — проводит аудит всех изменений, I18N — многоязычная или NestedSet — древовидная вида «вложенное множество»), то это можно сделать как раз с помощью данных шаблонов поведения.
Чтобы подключить какой-либо из существующих шаблонов, достаточно сконфигурировать должным образом нашу модель (посредством YAML или прямо в коде базовой таблицы модели).
Когда придет время, мы покажем на примерах, как это сделать.
Пока, к сожалению, или к счастью, но в виде шаблона к таблицам метод списка смежных вершин в Doctrine не реализован. При желании вы можете написать реализацию сами и даже предложить ее разработчикам Doctrine, — это уже на ваше усмотрение.
Тем не менее, основные функции, которые могут быть реализованы в рамках данной модели, можно реализовать в Doctrine и без использования шаблонов поведения. К сожалению, функций работы с деревом мы не получим, но основные задачи решать сможем.
Для этого следует сконфигурировать нашу модель должным образом. Используя YAML опишем структуру нашей таблицы:
А вот теперь самое важное — правильно описать связи в таблице. Там же со следующей строчки напишем:
Теперь соберем нашу модель, запустив команду:
Все. Модель готова. Фактически тоже самое можно было сделать в уже готовом базовом классе BaseAlTree:
Теперь пришло время насладиться результатами нашей работы. Напишем несложный код, отображающий дерево, построенное с отступами на обычной HTML-странице, используя рекурсию.
Обратите внимание, после того, как мы сконфигурировали должным образом связи у нашего объекта модели, нам стали доступны свойства Children и Parent. Однако любое первое обращение к ним на чтение порождает запрос к базе данных. Поэтому, для построения больших деревьев целиком за один проход, такой подход может оказаться довольно затратным.
Но в тоже время, реализовать динамически подгружаемое дерево таким способом — одно удовольствие!
Вложенное множество (Nested Set)
Описание структуры
Об этом алгоритме и его быстродействии, наверное, слышали все веб-разработчики. Да, этот алгоритм действительно очень хорош, когда требуется часто и много обращаться к иерархическим данным на чтение. Рассмотрим суть данного подхода.
При построении дерева на основе вложенных множеств, мы воспользуемся принципом обхода этого дерева слева-направо, как показано стрелками на Рис. 5. Для этого определим для каждого узла дерева целочисленные ключи слева (lft) и справа (rgt) (нижние квадратики внутри узла). И раздадим им во время обхода целочисленные инкрементные значения. Посмотрите что получилось.
Рис. 5. Вложенное множество (Nested Set).
Корневой элемент получил ключи 1 и 14, которые включают в себя диапазон чисел всех остальных ключей. Ветка VEGETABLE получила ключи 2 и 7, которые, в свою очередь, включают весь диапазон чисел ключей всех ее наследников и т.д. Вот они — вложенные множества. Все просто, не так ли?
Давайте воссоздадим такую же структуру в контексте таблицы БД.
Рис. 6. Таблица иерархических данных на основе метода вложенных множеств
Как видите, мы ввели дополнительно еще одно поле в таблицу — level. В нем будет храниться информация об уровне вложенности каждой ветки дерева. В принципе, это делать вовсе не обязательно — уровень вложенности может быть достаточно просто вычислен, но так как данный алгоритм оптимизирован как раз для чтения, то почему бы не выиграть в производительности за счет кеширования информации об уровне? Риторический вопрос…
Чтение дерева из БД
Результат будет таким:
Теоретически, тот же результат мы бы могли получить, вычисляя уровень вложенности на лету:
Попробуйте сравнить результат самостоятельно — он будет идентичен первому. Только сам запрос в данном случае более ресурсоемкий. А так как Nested Set — это оптимальный алгоритм чтения, то небольшая оптимизация в виде кеширования уровня вложенности рядом с остальными данными не такая уж и плохая стратегия.
Таким же, довольно несложным образом мы можем считывать целые ветки, пути из нашего дерева, обходить его узлы и т.д.
Например, если мы хотим извлечь все овощи (VEGETABLE) из нашего примера, это сделать достаточно просто:
Да, быстрое и гибкое чтение, включая агрегацию с внешними связанными данными — конек данного алгоритма.
Тем не менее, не бывает худа без добра, и в данном случае, значительные трудности начинаются когда нам необходимо внести изменения в Nested Set дерево или удалить какую-либо из его ветвей.
Это связано, в первую очередь, с тем, что при изменениях, нам будет необходимо пересчитать все ключи той части дерева, которая находится справа от изменяемого узла, а также обновить информацию об уровнях вложенности. И все это не сделать одним простым запросом.
Добавление новой ветки
Предположим, что мы хотим добавить новую ветку с именем SEA FOOD в наше дерево на одном уровне с VEGETABLES и FRUIT.
Если вы используете в MySQL таблицы MYISAM, или версию, которая не поддерживает транзакции, вы можете вместо BEGIN и COMMIT использовать блокировки на запись:
Как видите, задача на добавление новой ветки достаточно затратная и нетривиальная. Тем не менее, решаемая.
Удаление ветки
Давайте теперь попробуем удалить вновь созданную ветку:
Вывод — Nested Set действительно хорош, когда нам необходимо считывать структуру деревьев из БД. При этом он одинаково хорош для деревьев любого объема.
Тем не менее, для иерархических структур, которые подвергаются частому изменению он, очевидно, не будет являться оптимальным выбором.
Использование Nested Set в Doctrine
А вот этот метод имеет отражение в Doctrine в виде реализации шаблона поведения, который мы можем привязать к нашей модели.
Сделать это довольно просто, методом конфигурации модели через YAML-конфиг или прамо в коде базового класса.
Как видите, достаточно просто указать actAs: [NestedSet] в описании класса.
Однако Doctrine предоставляет более гибкую конфигурацию NestedSet модели. Например, вы можете хранить в одной таблице несколько деревьев. Для этого, вам необходимо ввести в таблицу дополнительное поле, в котором вы будете хранить идентификатор корня дерева для каждой записи.
В этом случае конфигурацию следовало бы записать так:
Все то же самое могло бы быть проделано в существующем базовом классе модели.
Для первого случая:
Для второго случая (несколько деревьев):
Заметьте, Doctrine использует ‘root_id’ в качестве имени поля по умолчанию. Поэтому вам не обязательно указывать эту опцию, если оно совпадает с именем в вашей реальной таблице. В противном случае вы можете его задать.
Примеры работы с деревьями Nested Set в Doctrine
Извлекаем и печатаем все дерево на экран:
Посмотрите как это просто!
За дополнительными примерами и информацией вы можете обратиться к официальной документации Doctrine, разделы 8.2.4 и 8.2.5
Материализованный путь (Materialized Path)
Описание структуры
Еще один довольно интересный подход для хранения иерархических структур. Основная идея алгоритма в хранении полного пути к узлу от вершины дерева. Выглядит это примерно так:
Рис. 7. Древовидная структура, организованная по принципу «материализованый путь»
Принцип формирования таких путей достаточно прост. Глубина пути — это уровень дерева. Внутри ветки нумерация — инкрементная. Другими словами, VEGETABLE — первый ребенок FOOD, FRUIT — второй ребенок и т.д.
Проще будет взглянуть на это в виде таблицы:
Возможно, так даже более наглядно.
В базе данных все это находит следующее отражение.
Рис. 8. структура таблицы иерархических данных, организованных по принципу «материализованный путь»
В чем же преимущество такого подхода?
Во-первых, по сравнению с Nested Set, он более поддается изменениям. В то же время остается достаточно удобным для выборки деревьев целиком и их частей. Но, и он не идеален. Особенно по части поиска предков ветки.
Поиск пути к узлу:
Вычисление уровня вложенности.
Для решения этой задачи нам в принципе достаточно посчитать кол-во точек (или других разделителей, если вы используете не точку) в путях. К сожалению, MySQL не имеет подходящей функции, но мы можем ее реализовать достаточно просто своими силами:
Выбор ветки:
Обратите внимание, в данном примере мы воспользовались нашей самописной функцией и это было достаточно удобно.
Поиск родителя:
Как видите, все эти запросы не тешат максимальной производительностью (по сравнению с предыдущим методом), но, тем не менее, использование именно этого алгоритма может быть заметно удобнее, для деревьев, над которыми часто выполняются как операции чтения, так и изменения.
Насколько известно автору, алгоритм довольно уверенно себя чувствует на достаточно больших объемах данных.
Следует отметить, что наиболее неприятной в данном алгоритме будет операция вставки узла в середину уже существующей структуры (между другими узлами), т.к. это повлечет изменение всех путей в нижележащих узлах. Хотя, справедливости ради, следует сказать, что такая операция окажется нетривиальной для любой модели хранения данных. Другая тяжелая операция — это перенос одной ветки в другую.
А вот удаление, добавление в конец или изменение узла — это операции довольно простые, и, как правило, не вызывают сложностей в данной модели.
Как видно из примеров, данный алгоритм также можно несколько оптимизировать на чтение, путем введения ещё одного поля level, как это было сделано для списков смежных вершин (Nested Set). Однако это несколько усложнит операции добавления, изменения и удаления узлов дерева, т.к. уровни придется пересчитывать для всего или части дерева при каждом изменении. В конечном счете, именно разработчику решать, в какую сторону следует делать перекос производительности.
Использование в Doctrine
К сожалению, на данный момент, этот метод хранения деревьев пока не нашел своей реализации в ORM Doctrine (текущая версия на момент написания материала — 1.0.4, 1.1.0 — в альфа версии также реализации не имеет).
Тем не менее есть все предпосылки полагать, что его реализация появится в будущем, т.к. исходные коды библиотеки содержат в пакете Doctrine/Tree абстракный пустой класс с именем MaterializedPath.
Автор будет следить за событиями и обновит эту статью, как только реализация найдет свое отражение, так что можете сюда вернуться позже.
Комбинированный подход
Фактически, комбинирование подходов на уровне БД ограничивается вводом поля, хранящего ссылку на родительскую запись в таблицы списков смежности и материализованных путей:
Рис. 9. Таблицы моделей иерархических структур данных AL+MP и AL+NS
Последствия такого подхода очевидны.
AL+MP
AL+NS
Для связки AL+NS взаимовыгодность не столь очевидна. В первую очередь это объясняется тем, что недостатки от проблем изменения узлов дерева в модели NS напрочь убивают в этой сфере все достоинства AL. Это значит, что такую связку следует рассматривать лишь как качественное улучшение поиска родителей и наследников заданного узла в алгоритме NS, а также как повышение надежности самого алгоритма (ключи можно всегда перестроить в случае порчи — информацию о связях хранит AL). Утверждение о повышении надежности справедливо и для предыдущей комбинации методов. Но ведь и это качественное улучшение, хотя и не такое очевидное, не так ли?
Заключение
В данной статье мы рассмотрели несколько основных методов хранения иерархических данных в реляционных БД и очертили все их достоинства и недостатки. Также мы показали на практике, какие из них доступны для использования в реализации ORM Doctrine, и как их использовать.
Очевидно, что даже выбор того или иного метода в каждом конкретном случае — задача не такая уж и простая, но автор надеется, что данный материал будет способствовать принятию осознанного и правильного решения, а также будет способствовать творческому процессу поиска новых и более оптимальных решений.
Поисковые системы
В Интернете размещены миллионы сайтов, причем наряду с современной актуальной информацией имеется много устаревших ресурсов, немало мусора и недобросовестной рекламы — сайтов, которые рекламируют себя только для того, чтобы повысить собственный рейтинг. Интернет — это наиболее демократичный источник информации, где нет единоличного управления и почти нет цензуры. Каждый может разместить в Сети собственный ресурс и высказать свое мнение. В результате мало кто озабочен тем, чтобы избежать дублирования информации или следовать стандартам, принятым на сайте соседа.
Не зря бытует мнение, что в Сети есть все, но найти там что-либо практически невозможно. Впрочем, противоположная точка зрения, взятая на вооружение поисковой системой Яндекс, гласит, что найти в Интернете можно все. Видимо, для того чтобы находить, нужно уметь искать. В настоящей статье представлен обзор инструментов поиска в сети Интернет, объясняется механизм работы поисковых систем, даются практические рекомендации по оптимизации поиска.
Инструменты поиска
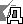 ля поиска в Интернете предназначены различные инструменты: поисковые машины (поисковики), индексированные каталоги (рубрикаторы), рейтинги и топы, метапоисковые системы и тематические списки ссылок, онлайновые энциклопедии и справочники (рис. 1). При этом для поиска разного рода информации наиболее эффективными оказываются различные инструменты. Рассмотрим каждую категорию по отдельности.
ля поиска в Интернете предназначены различные инструменты: поисковые машины (поисковики), индексированные каталоги (рубрикаторы), рейтинги и топы, метапоисковые системы и тематические списки ссылок, онлайновые энциклопедии и справочники (рис. 1). При этом для поиска разного рода информации наиболее эффективными оказываются различные инструменты. Рассмотрим каждую категорию по отдельности.
Рис. 1. Для каждого типа информации следует выбирать соответствующий инструмент поиска
Индексированные каталоги
Каталог представляет собой данные, структурированные по темам в виде иерархических структур. Тематические разделы первого уровня определяют наиболее популярные, максимально широкие темы, такие как «спорт» «отдых», «наука», «магазины» и т.д. В каждом разделе есть подразделы. Таким образом, вы можете уточнять интересующую вас область, путешествуя по дереву каталога и постепенно сужая область поиска. В качестве примера на рис. 2 показана структура классификатора учебных заведений. Из рисунка видно, что само дерево каталога позволяет составить представление об изучаемой теме. Дойдя до нужного подкаталога, вы находите в нем набор ссылок. Обычно в каталоге все ссылки являются профильными, поскольку составлением каталогов занимаются не программы, а люди. Очевидно, что если вы ищете общую информацию по некоторой широкой теме, то целесообразно обратиться к каталогу. Если же вам необходимо найти конкретный документ, то каталог окажется малоэффективным поисковым средством.
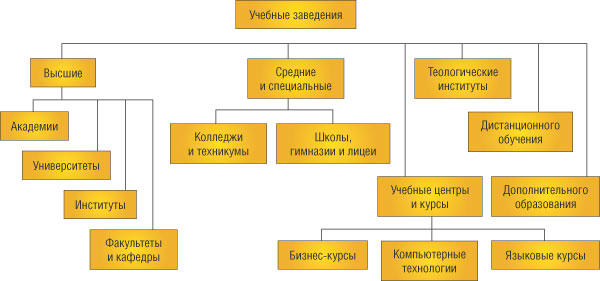
Рис. 2. Классификатор образовательных ресурсов дает наглядное представление о типах учебных заведений в системе образования
Существует огромное количество каталогов. Один из наиболее популярных каталогов в России — List.ru перекочевал в последнее время на адрес http://mail.ru/. Помимо каталогов общего профиля в Сети достаточно много специализированных каталогов. Например, по адресу www.kinder.ru можно найти прекрасный каталог, посвященный детским ресурсам. В случае если внутри отдельной темы каталога находится огромное количество ресурсов, возникает проблема выбора. В некоторых каталогах имеется сортировка по популярности, например в каталоге Яндекс сортировка идет по индексу цитирования (http://www.yandex.ru/info/ci.html).
Помимо каталогов в Сети существуют рейтинги. От каталога рейтинг отличается тем, что в нем описание ресурсов делают непосредственно их владельцы, а в каталоге — авторы, то есть редакторы каталога.
Одним из наиболее популярных рейтингов является Rambler Top 100. На рис. 3 показан рейтинг ресурсов из раздела «авто и мото». Популярность ресурса оценивается по ряду параметров, основные из которых — так называемые хосты (количество уникальных посетителей в единицу времени) и хиты (количество заходов на сайт за определенный промежуток времени).
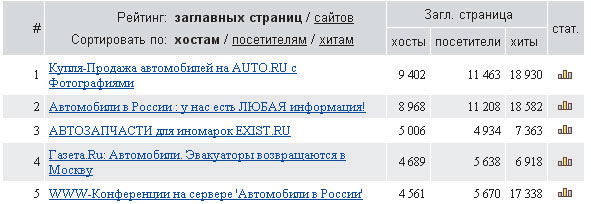
Рис. 3. Пример ранжирования ссылок в рейтинге Rambler Top 100
Тематические коллекции ссылок
Тематические коллекции ссылок — это списки, составленные группой профессионалов или коллекционерами-одиночками. Очень часто узкоспециализированная тема может быть раскрыта одним-единственным специалистом лучше, чем группой сотрудников крупного каталога. Тематических коллекций в Сети так много, что давать конкретные адреса не имеет смысла.
Подбор доменного имени
Каталог удобная система поиска, однако если вам нужно попасть на сервер компании Intel или IBM, то вы вряд ли станете обращаться к каталогу. Угадать название соответствующего сайта нетрудно: www.intel.com, www.ibm.com или www.intel.ru, www.ibm.ru сайты российских представительств этих компаний.
Если же вам необходим сайт, посвященный погоде в мире, его логично поискать на сервере www.weather.com. При этом в большинстве случаев найти сайт с ключевым словом в названии предпочтительнее, чем документ, в тексте которого это слово многократно используется. Сегодня даже мелкая компания может позволить себе содержание персонального сервера. Если такая компания (или коммерческий проект) имеет односложное название и реализует в Сети свой сервер, то его имя с большой долей вероятности укладывается в формат www.name.com, а для Рунета www.name.ru, где name имя компании или проекта. При поиске малоизвестной компании подбор адреса может успешно конкурировать с другими приемами поиска. Следует отметить, что при подобной системе поиска вы можете установить соединение с сервером, который не зарегистрирован ни в одной поисковой системе. Однако очевидно, что подобное угадывание не всегда успешно, и если вам не удается подобрать искомое имя, то придется обратиться к поисковой машине.
Поисковые машины
Прежде чем рассказать, как функционируют поисковые машины, следует ввести ряд терминов. Если бы компьютер был высокоинтеллектуальной системой, которой можно было бы легко объяснить, что вы ищете, то он выдавал бы вам два-три документа — именно те, которые вам нужны. Но это, к сожалению, не так, и в ответ на запрос вы обычно получаете длинный список документов, многие из которых не имеют никакого отношения к тому, о чем вы спрашивали. Такие документы называются нерелевантными (от англ. relevant подходящий, относящийся к делу). Таким образом, релевантный документ это документ, содержащий искомую информацию. Очевидно, что от умения грамотно делать запрос зависит процент получаемых релевантных документов. Доля релевантных документов в списке всех найденных поисковой машиной документов называется точностью поиска. Нерелевантные документы называют шумовыми. Если все найденные документы релевантны (шумовых нет), то точность поиска составляет 100%. Если найдены все релевантные документы, то полнота поиска 100%.
Таким образом, качество поиска определяется двумя параметрами: точностью и полнотой поиска. Стоит отметить, что они взаимозависимы, причем увеличение полноты снижает точность, и наоборот.
Поисковая система Яндекс
Еще в 1990 году в компании CompTek началось создание поисковой технологии Яндекс. С самого начала она задумывалась для поиска именно по массивам русских текстов, то есть с учетом морфологии русского языка. Слово «Яндекс» и первые программы с этим названием появились еще в 1993 году, а поисковая машина Яндекс (www.yandex.ru) была открыта 23 сентября 1997 года на выставке SofТool.
Возможности поисковой системы Яндекс
Поиск слова
Система позволяет находить:
Поиск нескольких слов
Поиск нескольких слов может происходить при:
Все вышеперечисленные особенности позволяют Яндексу с приемлемым качеством выполнять разнообразные запросы на естественном русском языке, даже с учетом «рваного», телеграфного стиля общения пользователей с поисковой системой.
Поиск в социальной сети
Под поиском в социальной сети понимается учет внетекстовых критериев в поиске, ранжировании и индексировании:
Дополнительные поисковые возможности
К таким возможностям относятся следующие:
Как работает поисковая машина
Поисковая машина состоит из двух частей: робота и поискового механизма. База робота в основном формируется им самим (робот сам находит ссылки на новые ресурсы) и в существенно меньшей степени — владельцами ресурсов, которые регистрируют свои сайты в поисковой машине. Помимо робота (паука, червяка), который обходит все предписанные серверы и формирует базу данных, существует программа, определяющая рейтинг найденных ссылок.
Принцип работы поисковой машины сводится к тому, что она опрашивает свой внутренний каталог (базу данных) по ключевым словам, которые пользователь указывает в поле запроса, и выдает список ссылок, ранжированный по релевантности.
Следует отметить, что поисковая система оперирует именно внутренними ресурсами (а не пускается в путешествие по Сети, как часто полагают неискушенные пользователи), а внутренние ресурсы, понятно, ограничены. Несмотря на то что база данных поисковой машины постоянно обновляется за счет опроса узловых адресов в Сети, внутренние ресурсы поисковой машины и ресурсы Сети несопоставимы, и поэтому вероятность того, что машина даст устаревший адрес или не найдет нужный ресурс, всегда больше нуля. При этом проблема состоит не только в ограниченности внутренних ресурсов, но и в том, что скорость робота ограничена. Увеличение внутренних ресурсов поисковой машины не решает проблемы в силу того, что скорость обхода конечна. При этом нельзя сказать, что поисковая машина внутри имеет копию определенной части исходных ресурсов Интернета, разложенных по каталогу. Полностью информация (исходные документы) хранится отнюдь не всегда, чаще хранится лишь ее часть — так называемый индексированный список (индекс), который гораздо компактнее текста документов.
Для построения индекса исходные данные преобразуются таким образом, чтобы объем базы был минимальным, а поиск осуществлялся очень быстро и давал максимум полезной информации. Объясняя, что такое индексированный список, можно провести параллель с его бумажным аналогом — так называемым конкордансом, то есть словарем, в котором в алфавитном порядке перечислены слова, употребляемые определенным писателем, а также указаны ссылки на них и частота их употребления в произведениях писателя.
Очевидно, что поиск ключевых слов с подобным словарем (индексом) гораздо эффективнее, чем поиск по книге. Отыскать нужное слово в конкордансе и посмотреть по ссылкам, где оно употребляется, намного проще, нежели перелистывать книгу в надежде наткнуться на это слово.
Построение индекса
Схема построения индекса показана на рис. 4. Сетевые агенты, или роботы-пауки, ползают по Сети, анализируют содержимое Web-страниц и собирают информацию о том, что и на какой странице было обнаружено. При нахождении очередной HTML-страницы большинство поисковых систем фиксирует слова, картинки, ссылки, скрипты и другие элементы (в разных поисковых системах по-разному), содержащиеся на ней. При отслеживании слов на странице фиксируется не только их наличие, но и местоположение, то есть где эти слова находятся: в заголовке (title), подзаголовке (subtitles), в метатэгах (meta tags) или в других местах. При этом обычно фиксируются значимые слова, а союзы и междометия вроде «а», «но», «или» игнорируются. Метатэги позволяют владельцам страниц определить ключевые слова и тематику, по которым индексируется страница. Это особенно актуально в случае, когда ключевые слова имеют несколько значений. Метатэги могут сориентировать поисковую систему при выборе из нескольких значений слова единственно правильное. Однако метатэги работают надежно только в том случае, когда заполняются честными владельцами сайта. Недобросовестные владельцы Web-сайтов помещают в свои метатэги наиболее популярные в Сети слова, не имеющие ничего общего с темой сайта. В результате посетители попадают на незапрашиваемые сайты, повышая тем самым их рейтинг. Исключение из поиска подобных сайтов — это еще одна задача, которую должна решать хорошая поисковая система. Каждый робот поддерживает свой собственный список ресурсов, наказанных за недобросовестную рекламу.
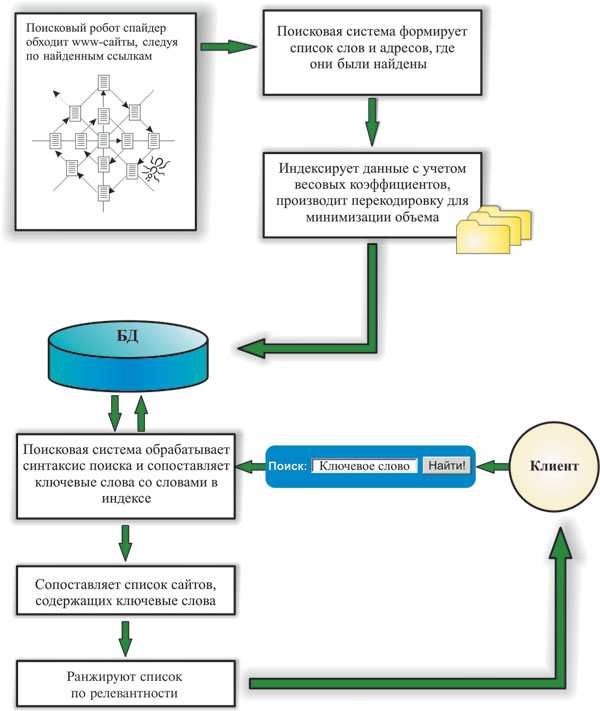
Рис. 4. Роботы-пауки просматривают информационное наполнение Web-страниц и создают индексированную базу поиска по ключевым словам, а затем по запросу пользователя выдают ранжированный по релевантности список сайтов
Очевидно, что если вы ищете сайты по ключевому слову «собака», то поисковый механизм должен найти не просто все страницы, где используется слово «собака», а те, где это слово имеет отношение к теме сайта. Для того чтобы определить, насколько то или иное слово имеет отношение к профилю некоторой Web-страницы, необходимо оценить, насколько часто оно встречается на странице, есть ли по данному слову линки на другие страницы или нет. Короче говоря, необходимо ранжировать найденные на странице слова по степени важности. Словам присваиваются весовые коэффициенты в зависимости от того, сколько раз и где они встречаются (в заголовке страницы, в начале или в конце страницы, в ссылке, в метатэге и т.п.). Каждый поисковый механизм имеет свой алгоритм присваивания весовых коэффициентов — это одна из причин, по которой поисковые машины по одному и тому же ключевому слову выдадут вам различные списки ресурсов. Поскольку страницы постоянно обновляются, то и процесс индексирования должен выполняться постоянно. Роботы-пауки путешествуют по ссылкам и формируют файл, содержащий индекс, который может быть довольно большим. Для уменьшения его размеров прибегают к минимизации объема информации и сжатию файла. Прежние поисковые системы хранили индексы нескольких тысяч документов и получали несколько тысяч запросов в день. Сегодня мощные поисковые машины хранят сотни миллионов страниц и получают десятки миллионов запросов ежедневно. Имея несколько роботов, поисковая система может обрабатывать сотни страниц в секунду. Для того чтобы снизить время обращения к внешним DNS-серверам, организация, осуществляющая поиск, имеет собственный DNS-сервер, который для ускорения процесса переводит имена в IP-адреса.
При построении индекса решается также задача снижения количества дубликатов — задача нетривиальная, особенно если учитывать, что для корректного сравнения нужно сначала определить кодировку документа. Еще более сложной задачей является отделение очень похожих документов (их называют «почти дубликаты»), например таких, которые различаются лишь заголовками, а текст дублируется. Подобных документов в Сети очень много — например, кто-то списал реферат и выдал его на сайте за своей подписью. Современные поисковые системы позволяют решать все эти проблемы.
Поиск по индексу
Поиск по индексу заключается в том, что пользователь формирует запрос и передает его поисковой машине. В случае когда у пользователя имеется несколько ключевых слов, весьма полезно использование булевых операторов.
Наиболее часто используемые булевы операторы:
Текст, в пределах которого проверяется логическая комбинация, называется единицей поиска. Это может быть предложение, абзац или весь документ. В разных поисковых системах могут использоваться различные единицы поиска. Например, вы можете искать документы, в которых два слова — «электрический» и «счетчик» — находятся одновременно в пределах предложения или в пределах всего документа. Соответственно поиск в пределах предложения возможен для тех систем, которые имеют в индексе подробный адрес.
После того как пользователь передал запрос поисковой системе, она обрабатывает синтаксис запроса и сравнивает ключевые слова со словами в индексе. После этого составляется список сайтов, отвечающих запросу, они ранжируются по релевантности и формируется результат поиска, который и выдается пользователю.
Существует огромное количество поисковых систем. Наиболее популярная западная поисковая система — Google (www.google.com). В частности, всемирно популярный каталог Yahoo! в качестве поисковой системы использует именно Google. В Рунете самыми популярными поисковыми системами являются Яндекс (www.yandex.ru) и Рамблер (www.rambler.ru).
Метапоисковые системы
Интернет развивается стремительными темпами — каждый день появляются сотни тысяч новых документов. Рост количества документов происходит быстрее, чем поисковые системы успевают их проиндексировать. Отсюда следует неутешительный вывод, что даже если в Сети и есть то, что вы ищете, вовсе не обязательно, что об этом знает поисковая машина, к которой вы обратились. Поисковых систем в мире сотни, и велика вероятность, что нужный вам документ не попал в ваш поисковик, но проиндексирован другой поисковой системой. Поэтому существуют службы, позволяющие транслировать ваш запрос сразу в несколько поисковых систем, — это метапоисковые системы. Однако пользоваться ими во всех случаях не следует. Если документов по теме много, то метапоиск не нужен и, возможно, даже вреден, поскольку смешивает разные логики ранжирования. Но если документов по теме мало, то метапоиск может быть полезен именно благодаря тому, что объединяет большое число поисковиков. Весьма удобной является отечественная программа ДИСКо Искатель, о которой стоит рассказать подробнее.
ДИСКо Искатель
Разработчик: фирма «ДИСКо» (www.disco.ru), права на распространение продукта принадлежат компании «Арсеналъ» (www.ars.ru).
ДИСКо Искатель (рис. 5) это метапоисковая система, инструмент для поиска информации на нескольких поисковых серверах одновременно. Главной особенностью этой программы является возможность запоминать как параметры поиска, так и его результаты и использовать их впоследствии.
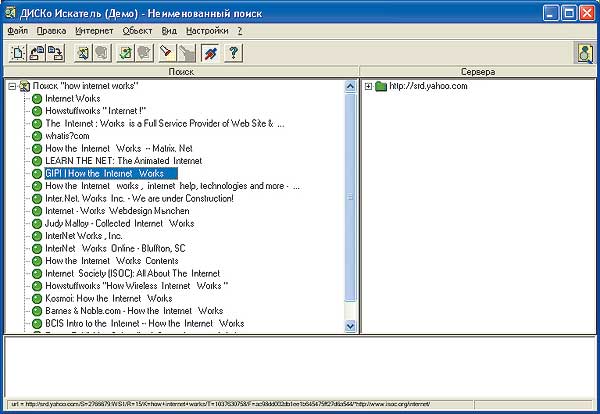
Рис. 5. Метапоисковая система ДИСКо Искатель
Двойным щелчком на любую ссылку вы можете вызвать свой Интернет-браузер для просмотра этой страницы. Выбрав любое подмножество страниц, можно потребовать создать HTML-страницы со ссылками на все эти страницы. ДИСКо Искатель запускает одновременно несколько соединений со всеми указанными поисковыми серверами, что существенно ускоряет время поиска. Оперативная информация о соединениях выводится в окно соединения. Вы можете сохранить параметры и результаты поиска в файле с расширением dio, чтобы в следующий раз снова запустить этот же поиск или внимательнее просмотреть его результаты.
Есть два способа экспорта подмножества страниц из дерева поиска: в закладки (избранное) Интернет-проводника и в HTML-страницу для последующего вызова ее из браузера.
Онлайновые энциклопедии и справочники
Очень часто нужно найти не документ, содержащий то или иное ключевое слово, а именно толкование искомого слова. Можно, конечно, поискать незнакомый вам термин с помощью поисковой машины, но в этом случае вы рискуете получить целый ряд статей, в которых этот термин используется, и при этом так и не узнать, что же он все-таки обозначает. В данном случае лучше обратиться к онлайновым энциклопедиям.
Одной из крупнейших онлайновых энциклопедий является ресурс «Яндекс.Энциклопедии» (http://encycl.yandex.ru/) этот проект содержит 219 968 статей из 14 энциклопедий, в том числе из БСЭ и «Энциклопедии Брокгауза и Ефрона». К крупным относится и «Энциклопедия Кирилла и Мефодия», которую можно найти по адресу www.km.ru.
Особенно актуальным является поиск толкований терминов по информационным технологиям, которые развиваются так быстро, что уследить за появлением новых IT-терминов очень сложно. Увы, большинство словарей из данной категории — англоязычные. Единственный ресурс на русском языке, который можно назвать компьютерным энциклопедическим словарем, — это проект «Компьютерная энциклопедия Кирилла и Мефодия» (http://www.megakm.ru/pc/), предусматривающая поиск не только по термину, но и по тематической структуре. Однако для словаря терминов объем в 700 статей явно недостаточен.
А вот объем англоязычного словаря FOLDOC (Free On-line Dictionary Of Computing; http://wombat.doc.ic.ac.uk/foldoc/index.html) весьма убедителен более 13 тыс. терминов.
FOLDOC это классический онлайновый словарь компьютерных терминов, в том числе акронимов, жаргонизмов, терминов языков программирования, а также всех слов, имеющих отношение к компьютерам. Однако не следует думать, что достаточно одного словаря, пусть даже и самого большого. Дело в том, что большинство крупных словарей построено по принципу обратной связи: не найдя термин в словаре, клиент делает запрос, и термин в базе со временем появляется. Таким образом, каждый ресурс развивается на основе своей клиентской базы, и не обнаружив термин в одном словаре, его можно найти в другом. Можно порекомендовать еще как минимум два онлайновых словаря: Webopedia и WhatIs.com.
Webopedia (www.pcwebopaedia.com) это серьезный ресурс с большим количеством слов и постоянным пополнением базы. Помимо традиционного словаря ресурс имеет массу специализированных сервисов, например: «Кто есть кто в компьютерных технологиях», «Сравнительная таблица микропроцессоров», «История развития компьютерных технологий» и др.
WhatIs.com (http://whatis.com/index.htm) толковый энциклопедический словарь по информационным технологиям и в первую очередь по терминам, связанным с ПК и Интернетом. Ресурс содержит более 2 тыс. энциклопедических статей, а также дает несколько Интернет-ссылок на каждый термин. Все статьи взаимосвязаны и содержат около 12 тыс. гипертекстовых ссылок.
Будущее поисковых систем
 есмотря на то что человеку всегда проще объяснить, что вы ищете, нельзя сказать, что современные поисковые машины — это примитивные системы, которые, кроме как найти некоторую последовательность символов, ничего не могут. Напротив, они решают целый ряд проблем, связанных с поиском, например проблему словоизменения (это далеко не простая задача). Если мы ищем документ по ключевому слову «стол», то вполне вероятно, что документ, содержащий фразу «столы для кухни», — это то, что нам нужно. Однако «стол» и «столы» для системы, осуществляющей формальное сравнение, — это разные слова. Поиск, учитывающий словоизменения, называется морфологическим. Большинство современных поисковых систем умеют осуществлять морфологический поиск.
есмотря на то что человеку всегда проще объяснить, что вы ищете, нельзя сказать, что современные поисковые машины — это примитивные системы, которые, кроме как найти некоторую последовательность символов, ничего не могут. Напротив, они решают целый ряд проблем, связанных с поиском, например проблему словоизменения (это далеко не простая задача). Если мы ищем документ по ключевому слову «стол», то вполне вероятно, что документ, содержащий фразу «столы для кухни», — это то, что нам нужно. Однако «стол» и «столы» для системы, осуществляющей формальное сравнение, — это разные слова. Поиск, учитывающий словоизменения, называется морфологическим. Большинство современных поисковых систем умеют осуществлять морфологический поиск.
Тем не менее морфологический поиск не решает проблему в том случае, когда слово имеет несколько значений. Например, слово «лук» может обозначать как растение, так и орудие для стрельбы. В этом случае необходим поиск, при котором поисковик «понимал» бы, о чем идет речь. В последнее время подобное направление (concept-based searching) развивается.
Один из таких сайтов находится по адресу AskJeeves.com (www.askjeeves. com). На нем запросы к системе выполняются в неформализованном виде (без использования булевых операторов), то есть так, как мы формулируем вопрос, когда задаем его человеку. Служба AskJeeves.com предоставляет надежные и высокорелевантные ответы на миллионы вопросов, задаваемых ежедневно, используя обработку запросов натуральных языков (Natural Language Processing, NLP). В основе службы лежит поисковый движок Teoma Search Technology. Вместо ранжирования результатов на основании мест с наибольшим количеством ключевых слов Teoma анализирует содержимое Web на основе предметно-содержательных групп, что позволяет выбрать наиболее релевантный документ. Мы протестировали данную систему и убедились в ее эффективности.
На рис. 6 показано, как обработана фраза «Where was John Lenon born». Поисковик предположил, что фамилия была напечатана неправильно, и спросил: «Did you mean Where was John Lennon born» — и тут же, предполагая, что вопрос был задан с ошибкой, выдал ответ: «John Lennon was born in Liverpool England on October 9, 1940».
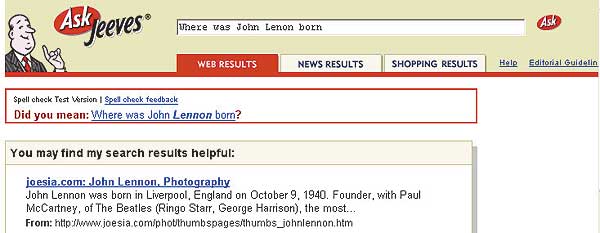
Рис. 6. Поисковая система AskJeeves
Глоссарий
Анализ социальных сетей разновидность структурного подхода, концентрирующего внимание на анализе возникающих в ходе социального взаимодействия связей (сетей), рассматриваемых в качестве структурных образований. Поведение личности или группы объясняется как производное от социальных сетей, элементами которых оно выступает. Метод получил широкое распространение при изучении процессов коммуникации в различных социальных группах. Всемирная паутина ярчайший пример социальной сети.
Булева модель, булевая, двоичная (boolean) — модель поиска, опирающаяся на операции пересечения, объединения и вычитания множеств.
Дубликаты (duplicates) разные документы с идентичным, с точки зрения пользователя, содержанием; приблизительные дубликаты, почти дубликаты (near duplicates), в отличие от точных дубликатов, содержат незначительные отличия.
Единица поиска текст, в пределах которого проверяется логическая комбинация.
Конкорданс словарь, в котором в алфавитном порядке перечислены слова, употребляемые писателем, а также указаны их адрес и частота употребления.
Индекс цитирования (citation index) число упоминаний (цитирований) научной статьи, в традиционной библиографии рассчитывается за промежуток времени, например за год.
Индексирование, индексация (indexing) процесс составления или приписывания индекса (указателя) служебной структуры данных, необходимой для последующего поиска.
Поиск похожих документов (similar document search) — задача информационного поиска, в которой в качестве запроса выступает сам документ и необходимо найти документы, максимально напоминающие данный.
Поисковая система, информационно-поисковая система (ИПС), поисковая машина, машина поиска, поисковик, «искалка» (search engine, SE) — программа, предназначенная для поиска информации.
Полнота, охват (recall) доля релевантного материала, заключенного в ответе поисковой системы, по отношению ко всему релевантному материалу в коллекции.
Релевантность (relevance, relevancy) соответствие документа запросу.
Словоизменение (inflection) образование определенной грамматической формы слова, обычно обязательной в определенном контексте.
Стоп-слова (stop-words) союзы, предлоги и другие частотные слова, которые поисковая система исключила из процесса индексирования и поиска для повышения своей производительности и/или точности поиска.
Точность (precision) доля релевантного материала в ответе поисковой системы.
Хиты количество заходов на сайт за определенный промежуток времени.
Хосты количество уникальных посетителей в единицу времени.



