Онлайн тесты на тему «Математические методы в психологи (обучение)- ответы на тест Синергия»

1. Таблицы совместного распределения частот двух или более номинативных признаков, измеренных на одной группе объектов, – это таблицы …
Тип ответа: Одиночный выбор
сопряженности
распределения частот
исходных данных
сгруппированных частот
2.Статистическая гипотеза о связях двух метрических переменных проверяется в отношении коэффициента корреляции …
Тип ответа: Одиночный выбор
r-Пирсона
t-Стьюдента
r-Спирмена
t-Кендалла
3.… распределения частот – это столбиковая диаграмма, каждый столбец которой опирается на конкретное значение признака или разрядный интервал.
Тип ответа: Одиночный выбор
Гистограмма
Полигон
График
4.Эксцесс– мера плосковершинности или остроконечности графика распределения измеренного признака
5.Обычно выделяют несколько видов статистических гипотез, в частности … гипотезу.
Тип ответа: Множественный выбор
Основную
вспомогательную
сравнительную
альтернативную
6. график распределения частот имеет одну вершину.
Тип ответа: Одиночный выбор
Модальный
Симметричный
Ассиметричный
Унимодальный
7. В зависимости от типа экспериментального плана выделяют четыре основных варианта ANOVA:
однофакторный
многофакторный
с повторными измерениями
одномерный
многомерный
стандартный
8. … распределение – это симметричное распределение, у которого крайние значения встречаются редко и частота постепенно повышается от крайних к серединным значениям признака.
Равномерное
Нормальное
Правостороннее
9. В случае Q-методологии психологического исследования, которая предполагает исследование изменчивости субъекта под влиянием различных стимулов, выборкой …
являются признаки
являются свойства объектов исследования
является множество испытуемых
является множество стимулов
10. Для порядковых переменных используют корреляцию …
r-Спирмена
t-Кендалла
r-Пирсона
t-Стьюдента
11. Экстремально малые или большие значения признака – это …
размах условия
факторные оценки
«выбросы»
12. Для изучения взаимосвязи двух метрических переменных, измеренных на одной и той же выборке, применяется …
коэффициент корреляции r-Пирсона
ранговый коэффициент корреляции r-Спирмена
z-преобразование Фишера
корреляция t-Кендалла
13. Измерение в … шкале предполагает возможность применения единицы измерения (метрики), а числа отражают не только различия между объектами на уровне выраженности свойства, но и то, насколько больше или меньше выражено свойство.
абсолютной
интервальной
ранговой
номинативной
14. Число, характеризующее выборку по уровню выраженности измеренного признака, – это …
мера центральной тенденции
оценка зависимой переменной
модальный интервал признака
мода
15. В случае R-методологии психологического исследования, которая предполагает изучение изменчивости какого-либо психологического свойства под влиянием некоторого воздействия, выборкой …
являются признаки
являются объекты исследования
являются свойства объектов исследования
является множество испытуемых
16. ANOVA с повторными изменениями применяется, когда … по внутригрупповому плану.
по крайней мере один из факторов изменяется
два и более факторов изменяются
ни один из факторов не изменяется
17. Наиболее популярным и наиболее чувствительным (мощным) аналогом критерия t-Стьюдента для независимых выборок является критерий …
Т-Вилкоксона
?2-Фридмана
Н-Краскала–Уоллеса
U-Манна–Уитни
18. Статистические выборки в зависимости от процедуры их организации бывают …
зависимые и независимые
частично зависимые и частично независимые
постоянные и переменные
зависимые и частично зависимые
19. Распределение не имеет моды, когда …
распределение ассиметрично
все значения встречаются одинаково часто
два соседних значения встречаются часто и чаще, чем любое другое значение
отсутствуют выбросы
20. Главная цель факторного анализа –… исходных данных с целью их экономного описания при условии минимальных потерь исходной информации.
уменьшение размерности
увеличение размерности
увеличение количества
21. Статистическая достоверность результатов исследования определяется при помощи …
методов статистического вывода
дискриминантного анализа
факторной оценки
шкалы достоверности
22. Многофакторная математическая модель интеллекта и процедура факторного анализа для ее верификации были предложены …
Ф. Гальтоном
Л.Терстоуном
Ч. Спирментом
Р. Кеттеллом
23. Мода – это … признака.
частота
свойство
функция
значение
24. При … распределении частот все значения встречаются одинаково либо почти одинаково часто.
равномерном
нормальном
симметричном
25. Процедура упорядочивания объектов в сравнительно однородные классы на основе попарного сравнения этих объектов по предварительно определенным и измеренным критериям – это …
параметрический анализ
классификация
дискриминантный анализ
кластерный анализ
26. Проверка гипотез о связях между переменными с использованием коэффициентов корреляции – это …
коэффициент корреляции
корреляционная матрица
частная корреляция
корреляционный анализ
27. Неверно, что тестовая методика должна содержать …
описание выборки стандартизации
наименование, характеристику стандартной шкалы
тестовые нормы – таблицы перерасчета «сырых» баллов в шкальные
характеристику распределения «сырых» баллов без указания среднего и стандартного отклонения
28. Нормальное распределение психологических свойств в генеральной совокупности характеризуется нескольким параметрами, в частности … отклонением.
Средним
переменным
постоянным
стандартным
29. … относится к методам, основанным на дистантной модели, непосредственными исходными данными для которых является информация о различных объектах.
Многомерное шкалирование
Кластерный анализ
Шкалирование предпочтений
Дискриминантный анализ
30. … – это точка на числовой оси измеренного признака, которая делит всю совокупность упорядоченных измерений на две группы с известным соотношением их численности.
Квантиль
Дисперсия
Каноническая ось
Дендрограмма
Статистика для всех
Когда вы начинали работать над курсовой, вы вместе с научным руководителем (или в одиночку) придумали тему исследования, построили гипотезы, разработали процедуру, даже провели исследование. И вот час X — подсчёт результатов исследования (если, конечно, у вас не качественное исследование, то есть без циферок).
Вот тут-то и начинается паника: что считать, как считать, зачем считать, где считать… И ещё миллион вопросов курсовика. Плюс к этому добавляется фрустрация из-за большого количества цифр. В психологии даже есть термин такой — «математическая тревожность» — страх перед большим объёмом чисел и математических формул.
Конечно, лучше заранее на этапе планирования исследования понимать что и как вы будете собирать и обрабатывать.

Но важно понимать, что НЕ ЗНАТЬ — это нормально. И ВСЕМУ МОЖНО НАУЧИТЬСЯ, главное — верить в себя, запастись терпением и попытаться разобраться в статистике и математическом анализе. Первые два пункта — требуются от вас, а с третьим мы попробуем разобраться вместе.
Перед вами ликбез по статистическому анализу результатов исследования в лёгкой и доступной форме
Что можно найти в этой статье:
Введение в математические методы и статистику. Понятие измерения
Начнём с того, зачем вообще психологам математика? Математические методы в психологии выполняют две важные функции:
• Представить данные, собранные опытным путём, в удобном для интерпретации виде
• Найти и выявить закономерности в данных
Математические методы могут помочь достичь несколько целей исследования:
1) Измерить психологические качества: обладает человек определенной психологической характеристикой или нет? У кого из группы людей данная характеристика выражена больше или меньше? Насколько сильнее или слабее выражена психологическая характеристика у разных представителей одной группы людей?
2) Оценить случайности или закономерности феноменов поведения: случайны измеренные различия / связи или характеризуют устойчивые особенности людей и их действий? Существенны ли различия между группами для того, чтобы считать их характерными особенностями? Можно ли перенести результаты с обследованной выборки на генеральную совокупность?
3) Спрогнозировать поведенческие реакции: можно ли по степени выраженности определенных психологических особенностей предсказывать реакции и действия людей? Можно ли смоделировать психологические особенности людей и их реакций на основании измеренных данных?
4) Оценить эффективность методов воздействия: была ли программа коррекции эффективной или мы имеем дело с побочными влияниями? Можно ли смоделировать психологические особенности людей и их реакций на основании измеренных данных?
Чтобы достичь этих целей и ответить на поставленные вопросы психологи используют измерение — приписывание объекту численных значений в соответствии с правилом.
Пример: в своём исследовании вы хотите померить тревожность у людей. Для этого вы даёте респондентам список утверждений про тревожность и просите их отметить степень своего согласия с каждым из них по 7-балльной шкале. А далее суммируете баллы по каждому утверждению в общий балл. В таком случае вы меряете тревожность, выражая её в баллах (то есть в числовом формате). Причём, чем выше потом получится балл, тем выше уровень тревожности (более выраженное свойство), и наоборот.
Многие явления очень трудно «измерить напрямую». Например, как можно измерить беспокойство у человека? Посчитать количество подёргиваний коленкой за ограниченный промежуток времени. Так мы операционализируем понятие «беспокойство» в поведенческое проявление. Операционализация — это перевод теоретических конструктов на язык операций.
Измерение позволяет установить: проявляется ли измеряемое поведение чаще / реже, чем какое-то другое, в том числе случайное? Связано ли его появление с какими-то условиями / факторами?
Благодаря измерению мы можем более точно описывать явления и события, сопоставлять разных людей и события между собой, определять выраженность психологических показателей в исследовании и диагностике.
Шкалы
Вы поняли, какой теоретический конструкт хотите изучать, операционализировали его. Затем необходимо понять, каковы свойства чисел при измерении при помощи этой операционализации. То есть определить шкалу измерения — последовательность числовых значений.
Шкалы окружают нас повсюду: сантиметр-рулетка, шкала на градуснике и т.д.
Выделяют четыре типа шкал: номинативная, порядковая, интервальная, шкала отношений. Очень важно в них разобраться, так как от вида шкалы будет зависеть, какую статистику вам нужно будет выбрать для подсчёта.
Типы измерительных шкал:
1) Номинативная шкала — это классификация; если вы все объекты поделили на классы (категории) и каждому классу (категории) приписали какие-то цифры – вы провели измерение в номинативной шкале.
Пример: пол: 1-мужской и 2-женский пол; национальность: 1-русские, 2-американцы, 3-китайцы; профессия: 1-психологи, 2-врачи, 3-учителя и т.д.
2) Порядковая шкала (ранговая) — предполагает приписывание объектам чисел в зависимости от степени выраженности измеряемого свойства, устанавливает отношения: больше, меньше или равно. Мы можем сказать, выражено ли свойство больше или меньше, но не можем сказать на сколько именно.
Пример: 5-балльная система в школе: да, мы можем сказать, что ученик получивший 5-ку намного лучше написал контрольную, чем ученик, написавший на 4-ку, но мы не можем сказать, насколько больше знаний у одного ученика, чем у другого.
3) Интервальная — устанавливает равенство интервалов, предполагает наличие стандартной единицы измерения; элементы отличаются друг от друга на n-единиц измерения. Есть «относительный ноль» — признак не отсутствует.
Пример: шкала градусов по Цельсию — на этой шкале есть 0, но он не значит, что «температура отсутствует», а просто соответствует температуре замерзания воды, служит некоторой относительной точкой, разграничивающей положительную и отрицательную температуру. А ещё, если вчера было 10 градусов, а сегодня стало 15, то мы можем сказать, что стало теплее на 5 градусов.
4) Шкала отношений — устанавливает равенство отношений; есть единица измерения, элементы могут отличаются в n-число раз, то есть можно сказать, во сколько раз больше или меньше выражено свойство у одного объекта по сравнению с другим. Есть «абсолютный ноль».
Пример: скорость движения автомобилей (можно сказать, во сколько раз один автомобиль движется быстрее другого; а 0 на спидометре будет обозначать, что автомобиль не движется — в этот момент у него нет «признака скорости»).
Также, шкалы разделяют на
— метрические (если есть и может быть установлена единица измерения: интервальная шкала и шкала отношений);
— неметрические (если единицы измерения не могут быть установлены: номинативная и порядковые шкалы).
Когда вы будете работать в статистических программах, не забудьте указать у каждой переменной тип шкалы! От этого зависят способы обработки, и иногда статпакеты могут отказываться что-то считать для «не тех» типов шкал


Виды исследований
Одним из важнейших этапов любого научного (или в нашем случае учебного) исследования является сбор данных. Важно понимать, что собираемые данные могут быть «объективными», а могут и не быть.
Существует три основных вида собираемых данных:
— L-данные (Life record data) — данные, которые получаем в ходе регистрации поведения человека в реальной жизни (через наблюдение). Эти данные защищены от искажений со стороны испытуемого, но являются неполными (наблюдение не может производиться 24/7). Также при сборе этих данных могут возникать ошибки со стороны исследователей.
— Q-данные (Questionnaire data) — данные, получаемые с помощью разных форм самоотчёта (опросники, тесты, интервью, анкеты, вопросники). Главным минусом самоотчётных данных является то, что испытуемые могут отвечать в соответствии с тем, чтобы их ответы были социально желательными, либо просто отвечать необъективно, поскольку просто не замечают за собой каких-то особенностей в поведении и реакциях.
— T-данные (objective test data) — те данные, которые получаем в результате объективного измерения параметров поведения. Для того, чтобы получить эти данные, создаются условия, которые способствуют проявлению нужного поведения или свойств личности (экспериментальные условия). Предполагается, что информация, полученная в ходе исследования лишена искажений, которым подвержены самоотчёные данные.
Однако, ситуации, аналогичные экспериментальным условиям, редко встречаются в жизни, поэтому у данных, собранных таким способом есть свой минус — испытуемые знают о том, что участвуют в исследовании, что может сказаться на их поведении и реакциях.
Для того, чтобы проверять выдвинутые в начале исследования гипотезы, в психологии используются эмпирические методы (или методы сбора данных).
Задачи эмпирического исследования в психологии:
Классификация методов по наличию воздействия экспериментатора на испытуемых:
Описательные методы — проводятся на основе наблюдения и опроса (исследователь никак не влияет на испытуемых и не вмешивается в ход исследования). Цель исследователя — наиболее точная регистрация поведения испытуемых. На основе описательных методов можно строить гипотезы о психологических закономерностях, но никак не делать выводы о причинах поведения или предсказывать его изменение.
Пример: даём человеку послушать какую-то музыку и после спрашиваем о его самочувствии.
Эксперимент — исследовательский метод, в котором исследователь воздействует на поведение испытуемых. Цель исследователя — выделить единственное воздействие при сведении остальных к минимуму. Это единственный вид исследования, по результатам которого психологом имеет право делать выводы о наличии причинно-следственной связи между событием и психологической реакцией.
Пример: исследование об эффективности зрительного поиска в сходном и различном окружении. В исследовании принимают участие две экспериментальные группы: одна ищет указанный символ в сходном окружении, другая — в различном. Воздействием в данном исследовании является предлагаемый фон, другие воздействия (побочные переменные) ликвидируются за счёт устранения мешающих факторов (других людей в помещении, резких звуков, разговоров экспериментатора и т.д.).
Квазиэксперимент — исследовательский метод, в котором исследователь непосредственно не воздействует на испытуемых, но с помощью разнообразных методик фиксирует результаты таких воздействий, которые сам оказать не может.
Отличие от истинного эксперимента — здесь используются реально существующие группы, то есть не проводится рандомизация или отсутствует контрольная группа.
Пример: исследуем связь уровня интеллекта с уровнем дохода (даём испытуемым тест Айзенка на уровень интеллекта и узнаём их доход — отсутствует воздействие на испытуемых).
В рамках написания курсовой работы студенты могут проводить как корреляционные и квазиэкспериментальные исследования, так и экспериментальные. Важно понимать различия в выдвигаемых гипотезах и, как следствие, в формулировке выводов.
Статистические ряды




![]()
![]()
Особую форму группировки данных представляют так называемые статистические ряды, или числовые значения признака, расположенного в определенном порядке. В зависимости от того, какие признаки изучаются, статистические ряды делят на атрибутивные, вариационные, ряды динамики, регрессии, ряды ранжированных значений признаков и ряды накопленных частот. Наиболее часто в психологии используются вариационные ряды, ряды регрессии и ряды ранжированных значений признаков.
Вариационным рядом распределения называют двойной ряд чисел, показывающий, каким образом числовые значения признака связаны с их повторяемостью в данной выборке. Например, психолог провел тестирование интеллекта по тесту Векслера у 25 школьников, и сырые баллы по второму субтесту оказались следующими: 6, 9, 5, 7, 10, 8, 9, 10, 8, 11, 9, 12, 9, 8, 10, 11, 9, 10, 8, 10, 7, 9, 10, 9, 11. Как видим, некоторые цифры попадаются в данном ряду по несколько раз. Следовательно, учитывая число повторений, данные ряд можно представить в более удобной, компактной форме:
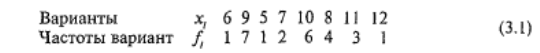
Это и есть вариационный ряд. Числа, показывающие, сколько раз отдельные варианты встречаются в данной совокупности, называются частотами, или весами, вариант. Они обозначаются строчной буквой латинского алфавита.fi и имеют индекс “i”, соответствующий номеру переменной в вариационном ряду.

Процентное представление частот полезно в тех случаях, когда приходится сравнивать вариационные ряды, сильно различающиеся по объемам. Например, при тестировании школьной готовности детей города, поселка городского типа и села были обследованы выборки детей численностью 1000, 300 и 100 человека соответственно. Различие в объемах выборок очевидно. Поэтому сравнение результатов тестирования лучше проводить, используя проценты частот.
Приведенный выше ряд (3.1) можно представить по другому. Если элементы ряда расположить в возрастающем порядке, то получится так называемый ранжированный вариационный ряд:
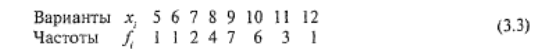
Подобная форма представления (3.3) более предпочтительна, чем (3.1), поскольку лучше иллюстрирует закономерность варьирования признака.
Частоты, характеризующие ранжированный вариационный ряд, можно складывать, или накапливать. Накопленные частоты получаются последовательным суммированием значений частот от первой частоты до последней.
В качестве примера вновь обратимся к ряду 3.3. Преобразуем его в ряд 3.4 в котором введем дополнительную строчку и назовем ее «кумуляты частот»:

Рассмотрим подробно как получилась последняя строчка. В начале ряда частот стоит 1. В кумулятивном ряду на втором месте стоит 2 — это сумма первой и второй частоты, т.е. 1 + 1, на третьем месте стоит 4 это сумма второй (уже накопленной частоты) и третьей частоты, т.е. 2 + 2, на четвертом 8 = 4 + 4 и т.д.
Размах (иногда эту величину называют разбросом) выборки обозначается буквой R. Это самый простой показатель, который можно получить для выборки — разность между максимальной и минимальной величинами данного конкретного вариационного ряда, т.е.
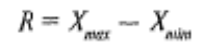
Понятно, что чем сильнее варьирует измеряемый признак, тем больше величина R, и наоборот.
Однако может случиться так, что у двух выборочных рядов и средние, и размах совпадают, однако характер варьирования этих рядов будет различный. Например, даны две выборки:
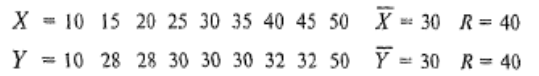
При равенстве средних и разбросов для этих двух выборочных рядов характер их варьирования различен. Для того чтобы более четко представлять характер варьирования выборок, следует обратиться к их распределениям.
Таблицы и графики распределения частот
Как правило, анализ данных начинается с изучения того, как часто встречаются те или иные значения интересующего исследователя признака (переменной) в имеющемся множестве наблюдений. Для этого строятся таблицы и графики распределения частот. Нередко они являются основой для получения ценных содержательных выводов исследования.
Если признак принимает всего лишь несколько возможных значений (до 10-15), то таблица распределения частот показывает частоту встречаемости каждого значения признака. Если указывается, сколько раз встречается каждое значение признака, то это — таблица абсолютных частот распределения, если указывается доля наблюдений, приходящихся на то или иное значение признака, то говорят об относительных частотах распределения.

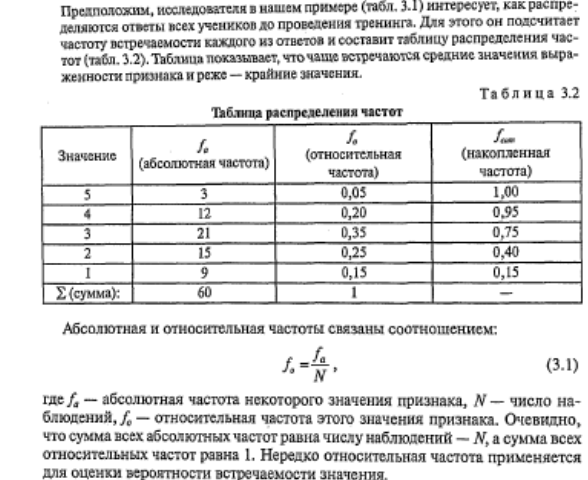
Во многих случаях признак может принимать множество различных значений, например, если мы измеряем время решения тестовой задачи. В этом случае о распределении признака позволяет судить таблица сгруппированных частот, в которых частоты группируются по разрядам или интервалам значений признака.
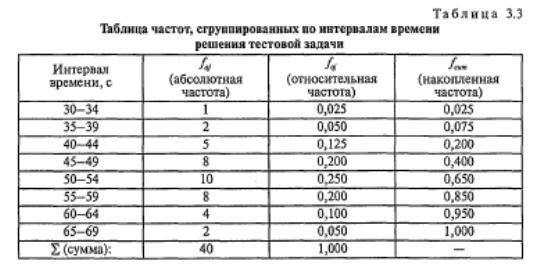
Еще одной разновидностью таблиц распределения являются таблицы распределения накопленных частот. Они показывают, как накапливаются частоты по мере возрастания значений признака. Напротив каждого значения (интервала) указывается сумма частот встречаемости всех тех наблюдений, величина признака у которых не превышает данного значения (меньше верхней границы данного интервала). Накопленные частоты содержатся в правых столбцах табл. 3.2 и 3.3.
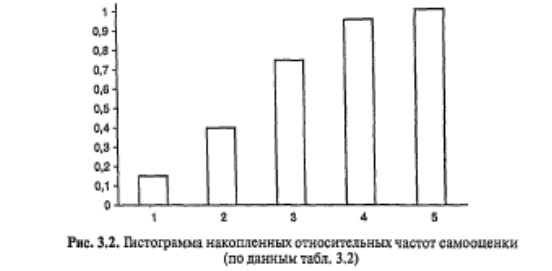
Для более наглядного представления строится график распределения частот или график накопленных частот — гистограмма или сглаженная кривая распределения.
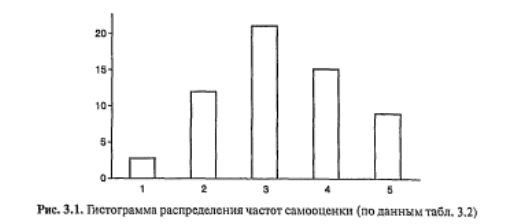
Гистограмма накошенных частот отличается от гистограммы распределения тем, что высота каждого столбика пропорциональна частоте, накопленной к данному значению (интервалу). На рис. 3.2 изображена гистограмма накопленных частот для данных табл. 3.2.
Построение полигона распределения частот напоминает построение гистограммы. В гистограмме вершина каждого столбца, соответствующая частоте встречаемости данного значения (интервала) признака, — отрезок прямой. А для полигона отмечается точка, соответствующая середине этого отрезка. Далее все точки соединяются ломаной линией (рис. 3.3). Вместо гистограммы или полигона часто изображают сглаженную кривую распределения частот. На рис. 3.4 изображена гистограмма распределения для примера из табл. 3.3 (столбики) и сглаженная кривая того же распределения частот.
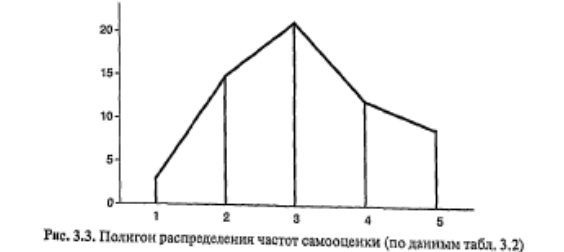
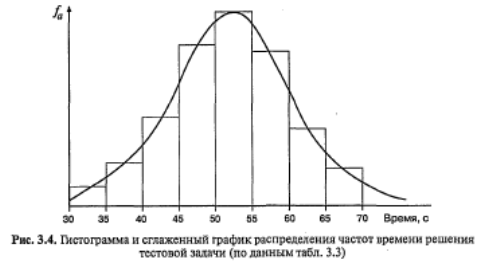
Таблицы и графики распределения частот дают важную предварительную информацию о форме распределения признака: о том, какие значения встречаются реже, а какие чаще, насколько выражена изменчивость признака. Обычно выделяют следующие типичные формы распределения. Равномерное распределение – когда все значения встречаются одинаково (или почти одинаково) часто. Симметричное распределение — когда одинаково часто встречаются крайние значения. Нормальное распределение — симметричное распределение, у которого крайние значения встречаются редко и частота постепенно повышается от крайних к серединным значениям признака. Асимметричные распределения — левосторонние (с преобладанием частот малых значений), правосторонние (с преобладанием частот больших значений).
Уже сами по себе таблицы и графики распределения признака позволяют делать некоторые содержательные выводы при сравнении групп испытуемых между собой. Сравнивая распределения, мы можем не только судить о том, какие значения встречаются чаще в той или иной группе, но и сравнивать группы по степени выраженности индивидуальных различий — изменчивости по данному признаку.
Таблицы и графики накопленных частот позволяют быстро получить дополнительную информацию о том, сколько испытуемых (или какая их доля) имеют выраженность признака не выше определенного значения.
Раздел 4. Описательные статистики
(Статистическое распределение и его числовые характеристики)
Переменная может принимать много значений. На начальном этапе обработки данных вместо того, чтобы рассматривать все значения переменной, рекомендуется проанализировать т. к. описательные статистики. Они дают общее представление о значениях или разбросе значений, которые принимает переменная.
К первичным описательным статистикам (Descriptive Statistics) обычно относят числовые характеристики распределения измеренного на выборке признака. Каждая такая характеристика отражает в одном числовом значении свойство распределения множества результатов измерения: с точки зрения их расположения на числовой оси либо с точки зрения их изменчивости. Основное назначение каждой из первичных описательных статистик — замена множества значений признака, измеренного на выборке, одним числом (например, средним значением как мерой центральной тенденции). Компактное описание группы при помощи первичных статистик позволяет интерпретировать результаты измерений, в частности, путем сравнения первичных статистик разных групп.



