Mp3 vbr что это

На сегодняшний день формат MP3 является самым популярным форматом кодирования аудио файлов из всех существующих. Общепринято считать, что качество звуковой дорожки зависит от её битрейта, поэтому самый оптимальный битрейт для звуковой дорожки — 192 кбит/сек. Это утверждение, однако, является однобоким, ведь помимо битрейта качество звука зависит от кодека, в котором аудиозапись была записана.
Выделяют три основных типа кодирования MP3 файлов — это CBR, VBR и ABR.
CBR (Constant bitrate) расшифровывается как постоянный битрейт, который был задан пользователем при записи или кодировании и который не меняется в дальнейшем. То есть, независимо от типа данных (пусть даже вы записываете тишину) за 1 секунду кодируется постоянно количество бит, указанное пользователем. Такой тип кодирования идеально подходит для данных, которые пропускаются через ограниченные мультимедийные каналы, позволяя использовать все возможности данного канала. Минусом такого типа кодирования является громоздкие объемы полученных данных, которые нерационально используют дисковое пространство.
VBR (Variable bitrate) с английского переводится как изменяющийся (переменный) битрейт. При кодировке в VBR мы получаем файл, битрейт которого изменяется в зависимости от густоты потока данных (то есть, к примеру, битрейт тишины будет ниже, чем битрейт какого-либо звука). Такой тип кодирования продолжает совершенствоваться, достигая новых показателей амплитуды изменения битрейта потока данных. Основным минусом является то, что невозможно предугадать будущий размер кодируемого файла. Несмотря на это, данный минус никак не омрачит общую картину: размер файла получается меньше, чем при кодировании по типу CBR. Это получается за счёт того, что битрейт тишины или тихих звуков меньше. Последние версии Lame имеют функцию кодирования в VBR, качество которого на порядок выше ABR, а размер меньше, чем CBR.
Третьим типом кодирования является ABR (Average bitrate), который представляет собой нечто среднее между предыдущими двумя типами кодирования. Расшифровывается как средний битрейт. Пользователь имеет возможность указать битрейт, а программа Lame подгоняет канал данных под эту частоту. Единственным минусом такого вида кодирования является то, что выходной файл будет иметь ухудшенное качество (однако лучше, чем CBR и хуже чем VBR). Используя такой тип кодирования, пользователь может выбирать как битрейт файла, так и его будущий размер — это основной плюс.
Постоянный битрейт (CBR) против переменного битрейта (VBR) что выбрать?

Содержание:
Если вы хотите копировать музыку с компакт-дисков или иных носителей информации, на которых она хранится в не сжатом виде, в форматы с потерей качества, такие как MP3, WMA, AAC и другие вам нужно выбрать с каким битрейтом вы будете это делать, с постоянным (CBR) или переменным (VBR).
Метод кодирования с постоянным битрейтом (CBR)
CBR (Constant Bitrate) – при кодировании в CBR на всём протяжении музыкального файла битрейт будет оставаться неизменным и равным тому, какое значение вы выбрали.
Самыми распространёнными значениями являются следующие: 128, 192, 256, 320 кбит/с.
Преимущество кодирования CBR заключается в том, что файл будет обработан быстрее, что при кодировании, что при раскодировании. К тому же абсолютно любая программа или аппаратное средство, которые способно воспроизводить музыку из форматов MP3, WMA, AAC умеет это делать если она закодирована в CBR, чего нельзя сказать о переменном битрейте. Старое оборудование, или программы, не всегда поддерживают воспроизведение музыки с CBR.
Правда, нужно отметить, что музыка, закодированная в CBR, в итоге занимает больше памяти, чем та же музыка, но закодированная в VBR.
Чаще всего кодирование в CBR используют для тех случаев, когда она будет передаваться по сети, или когда заранее известно, что она будет воспроизводится на старом оборудовании.
Постоянный битрейт важен для музыки, которая будет передаваться по сети тем, что поток данных будет стабильным, и если он входит в рамки пропускной способности сетевого канала, то значит воспроизведение будет плавным, без рывков и прерываний. А вот если вещать музыку сжатую с переменным битрейтом, могут возникнуть трудности, когда кусок песни, который закодирован с максимальным битрейтом не будет проходить в пропускную способность канала, вызывая тем самым затыкания во время воспроизведения.
Вернуться к содержанию
Метод кодирования с переменным битрейтом (VBR)
VBR (Variable Bitrate) – при кодировании в VBR он не является константой, но постоянно меняется по мере воспроизведения.
Этот метод кодирования позволяет увеличить битрейт на сложных музыкальных участках, и уменьшать на простых, тем самым позволяя качеству оставаться примерно на одном уровне, но при этом экономя место в памяти.
VBR с успехом применяется и поддерживается большинством форматов и программного обеспечения.
Форматы, которые поддерживают VBR: MP3, WMA, OGG, AAC и другие.
Основным преимуществом переменного битрейта над постоянным заключается в экономии места в памяти для хранения музыки.
При кодировании в VBR используются более сложные и ресурсоёмкие алгоритмы, поэтому воспроизведение требует больших вычислительных мощностей от устройства. По этой причине некоторое старое оборудование может вообще не воспроизводить музыку с VBR.
Вернуться к содержанию
За счёт чего достигается экономия памяти при кодировании в VBR?
Алгоритмы сжатия анализируют не только сам звук, но и его сложность, раскладывая на элементарные составляющие. Таким образом, сложные участки музыки, где одновременно звучат множество инструментов, либо звук инструмента часто меняет свою тональность и громкость, кодируются с максимальным качеством. Но если в музыке появляются простые секунды, или вообще наступает тишина, эти кусочки кодируются с гораздо меньшим битрейтом.
За счёт этого подхода и достигается экономия памяти.
Но нужно всегда помнить о том, что основным недостатком VBR является невозможность воспроизведения музыки на старом оборудовании или на старом программном обеспечении.
Вернуться к содержанию
Какой тип кодирования выбрать: переменный или постоянный?
Если вы абсолютно уверены, что закодированная вами музыка будет воспроизводиться на современном оборудовании, то я рекомендую использовать переменный битрейт.
Если же ваша музыка будет воспроизводится на очень широком спектре оборудования, лучше подстраховаться и кодировать её с постоянным битрейтом.
Все телефоны, плееры и компьютеры, которые выпущены за последние 10 лет должны без проблем поддерживать воспроизведение в VBR, поэтому в подавляющем большинстве случаев я рекомендую использовать именно VBR.
Так музыка будет занимать меньше памяти, но в то же время сохранит высокое качество.
Особенно важно использовать VBR, если музыка будет хранится на портативных устройствах, вроде mp3 плееров или телефонов. Хоть в последнее время в них и встраивают довольно серьёзное количество памяти, её, всё же, желательно использовать экономно.
Вернуться к содержанию
Внутри MP3. А как оно всё устроено?

Однажды мне понадобилось решить простенькую (как мне тогда казалось) задачу – в PHP-скрипте узнать длительность mp3-файла. Я слышал о ID3 тегах и сразу подумал, что информация о длительности хранится либо в тегах, либо в заголовках mp3-файла. Поверхностные поиски в интернете показали что за пару-тройку минут решить эту задачу не получится. Поскольку от природы я довольно любопытен а время не поджимало — решил не использовать сторонние инструменты а разобраться в одном из самых популярных форматов самостоятельно.
Если Вам интересно, что там внутри – добро пожаловать под кат (трафик).
В данной статье мы не будем подробно останавливаться на извлечении ID3v2 тегов – это можно вынести в отдельную статью, так как там есть различные нюансы. А так же на фрагментах заголовков, которые практически не используются в настоящее время (например, часть Emphasis заголовка mp3-фрейма). Так же мы не рассматриваем структуру самих аудиоданных — тех самых, которые слышим из колонок.
ID3 теги
ID3 (от англ. Identify a MP3) — формат метаданных, наиболее часто используемый в звуковых файлах в формате MP3. ID3 подпись содержит данные о названии трека, альбома, имени исполнителя и т. д., которые используются мультимедиапроигрывателями и другими программами, а также аппаратными проигрывателями, для отображения информации о файле и автоматического упорядочивания аудиоколлекции.
Существует две абсолютно разных версии ID3-данных: ID3v1 и ID3v2.
ID3v1 – имеет фиксированный размер в 128 байт, которые дописываются в конец mp3-файла. Там можно хранить: название трека, исполнитель, альбом, год, комментарий, номер трека (для версии 1.1) и жанр.
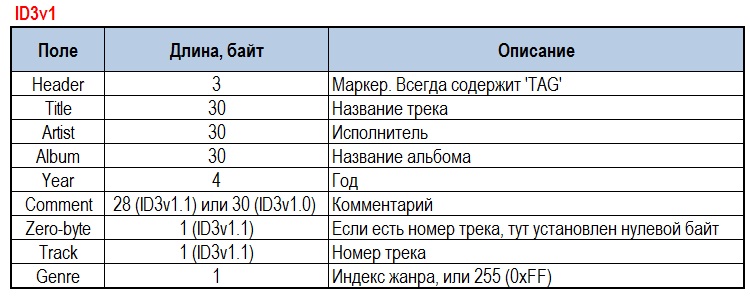
Довольно быстро всем стало понятно, что 128 байт – очень уж небольшое место для хранения таких данных. И поэтому, со временем, появилась и успешно используется вторая версия данных – ID3v2.
В отличии от первой версии, теги v2 имеют переменную длину и размещаются в начале файла, что позволяет поддерживать потоковое воспроизведение. (Формат ID3v2.4 позволяет так же хранить данные и в конце файла).
Данные ID3v2 состоят из заголовка и последующих фреймов ID3v2. Например, в версии ID3v2.3 существует более 70 типов фреймов.
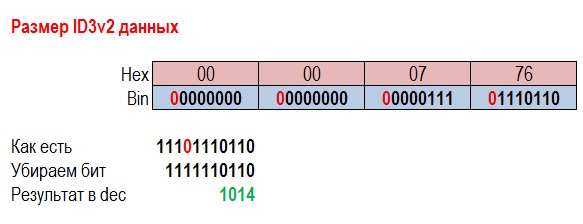
В данном случае вместе с заголовком ID3v2 (10 байт) – данные ID3v2 занимают 1024 байта.
После ID3v2-заголовка идут собственно теги. Подробный разбор чтения тегов ID3v2, как сказано выше, я решил не включать в эту статью.
Теперь у нас есть информация о наличии и длине тегов ID3 и мы можем приступать в разбору mp3-фрейма и понять-таки – где же хранится длительность. А заодно понять и всё остальное.
MP3-фрейм
Весь mp3-файл состоит из фреймов, которые можно извлекать только последовательно. Фрейм содержит в себе заголовок и аудио-данные. Поскольку мы не ставим себе целью написать прошивку для магнитофона – нас интересует именно заголовок фрейма.
О нем подробнее (куча таблиц и сухой информации)
Размер заголовка – 4 байта.
Режимы сжатия данных или какой бывает битрейт
Существует 3 режима сжатия данных:
CBR (constant bitrate) – постоянный битрейт. Не меняется на всем протяжении трека.
VBR (variable bitrate) – переменный битрейт. При этом сжатии битрейт постоянно меняется на протяжении трека.
ABR (average bitrate) – усредненный битрейт. Это понятие используется только при кодировании файла. На «выходе» получается файл с VBR.
Длительность = Размер аудиоданных / Битрейт (в битах!) * 8
Например, файл имеет размер 350670 байт. Есть ID3v1 теги (128 байт) и ID3v2 теги (1024 байта). Битрейт = 96. Следовательно размер аудиоданных равен 350670 – 128 – 1024 = 349518 байт.
Длительность = 349518 / 96000 * 8 = 29,1265 = 29 секунд
Необходимо пояснить – как определить режим сжатия. Всё просто. Если файл сжат с VBR – то добавляется VBR-заголовок. По его наличию мы и можем понять, что используется переменный битрейт.
Есть два вида заголовков: Xing и VBRI.
Xing размещается со смещением от начала первого mp3-фрейма в позиции, согласно таблице:
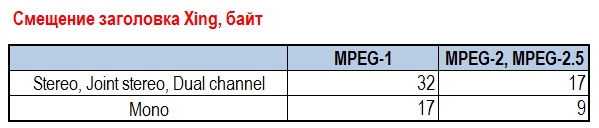
Например: у нас ID3v2 тег занимает 1024 байта. Если наш mp3-файл имеет режим канала «Стерео» — то заголовок VBR Xing будет начинаться со смещения 1024 + 32 = 1056 байт.
Заголовок VBRI всегда размещается со смещением +32 байта от начала первого mp3-фрейма.
Первые четыре байта в обоих заголовках содержат маркер ‘Xing’ или ‘Info’ для Xing. И ‘VBRI’ для VBRI.
Эти VBR заголовки имеют переменную длину и содержат различную информацию о кодировании файла. Подробнее о структуре заголовков VBR (и не только) можно почитать, например, тут.
Я же расскажу только о том, что нас интересует в данный момент. А именно – количество фреймов (Number of Frames). Это число длиной 4 байта.
В заголовке Xing оно содержится по смещению +8 байт от начала заголовка. В VBRI +14 байт от начала заголовка.
Используя таблицу Сэмплов на фрейм (Sampler Per Frame) мы можем получить длительность mp3-файла, закодированного с переменным битрейтом.
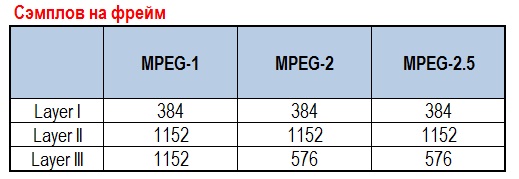
Длительность = Количество фреймов * Сэмплов на фрейм / Частоту дискретизации
Например: из заголовка VBRI получили количество фреймов 1118, сэмплов на фрейм = 1152. Частота дискретизации = 44100.
Длительность = 1118 * 1152 / 44100 = 29.204 = 29 секунд.
На этом на сегодня всё. Если был кому-то полезен — спасибо.
Для тех, кто захочет немедленно поковырять внутренности mp3 — Тут лежат скрипт на php, которые я писал для себя одновременно с данной статьей и четыре небольших mp3-файла для теста.
«Заметки на полях» (FAQ)
Часто задаваемые вопросы (и ответы) на околозвуковые темы технического характера
Кратко об истории и характеристиках стандартов MPEG.
1) Рассмотрим комплект MPEG-1. Этот комплект, в соответствии со стандартами ISO, включает в себя три алгоритма различного уровня сложности: Layer (уровень) I, Layer II и Layer III. Общая структура процесса кодирования одинакова для всех уровней. Для каждого уровня определен свой формат записи бит-потока и свой алгоритм декодирования. Алгоритмы MPEG основаны в целом на изученных свойствах восприятия звуковых сигналов слуховым аппаратом человека (то есть кодирование производится с использованием так называемой «психоакустической модели»).
Кратко об алгоритме кодирования. Входной цифровой сигнал сначала раскладывается на частотные составляющие спектра. Затем этот спектр очищается от заведомо неслышных составляющих – низкочастотных шумов и наивысших гармоник, то есть фактически фильтруется. На следующем этапе производится значительно более сложный психоакустический анализ слышимого спектра частот. Это делается в том числе с целью выявления и удаления «замаскированных» частот (частот, которые не воспринимаются слуховым аппаратом в виду их приглушения другими частотами). После всех этих манипуляций из цифрового аудио сигнала исключается больше половины информации. Затем, в зависимости от уровня сложности используемого алгоритма, может быть также произведен анализ предсказуемости сигнала. Кроме этого, базируясь на том, что человеческое ухо способно различать направление звучания только средних частот, то в случае, когда кодируется стерео сигнал, его можно превратить в совмещенный стерео (joint stereo). Это значит, что фактически происходит отделение верхних и нижних частот и их кодирование в моно варианте (средние частоты остаются в режиме стерео). Далее, в случае появления, например, «тишины» в одном из каналов, «пустующее» место заполняется информацией либо повышающей качество другого канала, либо просто не поместившейся до этого. В довершение ко всему проводится сжатие уже готового бит-потока упрощенным аналогом алгоритма Хаффмана (Huffman), что позволяет также значительно уменьшить занимаемый потоком объем.
Комплект MPEG-1 предусмотрен для кодирования сигналов, оцифрованных с частотой дискретизации 32, 44.1 и 48 КГц. Как было указано выше, комплект MPEG-1 имеет три уровня (Layer I, II и III). Эти уровни имеют различия в обеспечиваемом коэффициенте сжатия и качестве звучания получаемых потоков. Layer I позволяет сигналы 44.1 КГц / 16 бит хранить без ощутимых потерь качества при скорости потока 384 Кбит/с, что составляет 4-х кратный выигрыш в занимаемом объеме; Layer II обеспечивает такое же качество при 194 Кбит/с, а Layer III – при 128 (или 112). Выигрыш Layer III очевиден, но скорость компрессии при его использовании самая низкая (надо отметить, что при современных скоростях процессоров это ограничение уже не заметно). Фактически, Layer III позволяет сжимать информацию в 10-12 раз без ощутимых потерь в качестве.
2) Стандарт MPEG-2 был специально разработан для кодирования ТВ сигналов вещательного телевидения, поэтому на рассмотрении MPEG-2 мы бы не останавливались, если бы в апреле 1997 этот комплект не получил «продолжение» в виде алгоритма MPEG-2 AAC (MPEG-2 Advanced Audio Coding – продвинутое аудио кодирование). Стандарт MPEG-2 AAC стал результатом кооперации усилий института Fraunhofer, компаний Sony, NEC и Dolby. MPEG-2 AAC является технологическим приемником MPEG-1. Существует несколько разновидностей этого алгоритма: Homeboy AAC, AT&T a2b AAC, Liquifier AAC, Astrid/Quartex AAC и Mayah AAC. Наиболее высокое качество звучания по сравнению c MPEG-1 Layer III обеспечивают две предпоследние реализации. Все приведенные разновидности алгоритма AAC не являются совместимыми между собой.
Также, как и в комплекте аудио стандартов кодирования MPEG-1, в основе алгоритма AAC лежит психоакустический анализ сигнала. Вместе с тем, алгоритм AAC имеет в своем механизме множество дополнений, направленных на улучшение качества выходного аудио сигнала. В частности, используется другой тип преобразований, улучшена обработка шумов, изменен банк фильтров, а также улучшен способ записи выходного бит-потока. Кроме того, AAC позволяет хранить в закодированном аудиосигнале т.н. «водяные знаки» (watermarks) – информацию об авторских правах. Эта информация встраивается в бит-поток при кодировании таким образом, что уничтожить ее становится невозможно не разрушив целостность аудиоданных. Эта технология (в рамках Multimedia Protection Protocol) позволяет контролировать распространение аудиоданных (что, кстати, является препятствием на пути распространения самого алгоритма и файлов, созданных с помощью него). Следует отметить, что алгоритм AAC не является обратно совместимым (NBC – non backwards compatible) с уровнями MPEG-1 несмотря на то, что он представляет собой продолжение (доработку) MPEG-1 Layer I, II, III.
MPEG-2 AAC предусматривает три различных профиля кодирования: Main, LC (Low Complexity) и SSR (Scaleable Sampling Rate). В зависимости от того, какой профиль используется во время кодирования, изменяется время кодирования и качество получаемого цифрового потока. Наивысшее качество звучания (при самой медленной скорости компрессии) обеспечивает основной Main профиль. Это связано с тем, что профиль Main включает в себя все механизмы анализа и обработки входного потока. Профиль LC упрощен, что сказывается на качестве звучания получаемого потока, сильно отражается на скорости компрессии и, что более важно, декомпрессии. Профиль SSR также представляет собой упрощенный вариант профиля Main.
Говоря о качестве звука, можно сказать, что поток AAC (Main) 96 Кбит/с обеспечивает качество звучания, аналогичное потоку MPEG-1 Layer III 128 Кбит/с. При компрессии AAC 128 Кбит/с, качество звучания ощутимо превосходит MPEG-1 Layer III 128 Кбит/с.
4) Стандарт MPEG-7, разработка которого еще не окончена, вообще в корне отличается от всех иных стандартов MPEG. Стандарт разрабатывается не для установления каких-то рамок для передачи данных или типизации и описания данных какого-то конкретно рода. Стандарт предусмотрен как описательный, предназначенный для регламентации характеристик данных любого типа, вплоть до аналоговых. Использование MPEG-7 предполагается в тесной связи с MPEG-4. Выпуск в свет MPEG-7 намечен на 2001 год.
Для удобства обращения со сжатыми потоками, все алгоритмы MPEG разработаны таким образом, что позволяют осуществлять декомпрессию (восстановление) и воспроизведение потока одновременно с его получением (download) – потоковая декомпрессия «на лету» (stream playback). Эта возможность очень широко используются в интернете, где скорость передачи информации ограничена, а с использованием подобных алгоритмов появляется возможность обрабатывать информацию прямо во время ее получения не дожидаясь окончания передачи.
Что такое CBR и VBR?
Как известно, результатом кодирования сигнала с помощью такого алгоритма, как, например, MPEG-1 Layer III (MP3) (или некоторых других алгоритмов), является бит-поток с фреймовой (блочной) структурой. Это объясняется тем, что кодирование исходного потока производится не целиком, а по частям. То есть фактически исходный поток разделяется на блоки определенной фиксированной длины, затем каждый блок (фрейм) в отдельности подвергается кодированию и результат (кодированный блок информации) направляется в результирующий поток (будь то файл или поток данных).
Каковы отличия режимов CBR, VBR и ABR? (применительно к кодеру Lame)
Прежде чем начать разговор, уточним две детали:
1. Кодирование в MP3 происходит поблочно: кодируемый файл разбивается на фреймы (кадры) с одинаковым интервалом, каждый кадр кодируется и записывается в выходной поток; таким образом, выходной поток также имеет кадровую структуру.
2. Фреймы могут быть закодированы не на любом битрейте, а только на одном из входящих в таблицу стандартных для MPEG1 Layer III битрейтов: 32, 40, 48, 56, 64, 80, 96, 112, 128, 160, 192, 224, 256, 320. Кодирование на любых промежуточных битрейтах («freeformat») стандартом не предусмотрено.
Люди, использующие VBR в Lame, обычно аргументируют это фразой: «я хочу получать постоянное качество, а не постоянный битрейт». Действительно, ведь в музыке бывают простые пассажи, на которые вполне хватает и 128 Кбит/сек (например паузы между песнями), а бывают и сложные, на которых человек с хорошим слухом, хорошей аудио картой и прочей аудиоаппаратурой услышит дефекты компрессии даже на 320 Кбит/сек. На самом деле такой аргумент не совсем равомочен.
Даже в режиме CBR, mp3-кодер может перераспределять биты во времени, выделяя большее или меньшее количество бит во время сложного или простого пассажей, что позволяет в целом улучшить качество звучания. Такое перераспределение бит делается за счёт так называемого резервуара бит: во время кодирования простых пассажей кодер тратит на них не весь заданный пользователем битрейт, а лишь около 90%, около 10% экономится в резервуаре для кодирования сложных мест (изначально резервуар пуст). При кодировании сложных пассажей кодер будет использовать все 100% указанного битрейта и добавлять дополнительные биты из резервуара (если таковые имеются, то есть если резервуар не пуст). К сожалению, в соответствии со стандартом, размер резервуара ограничен. Это означает, что если простой сигнал продолжается достаточно долго, резервуар накапливает свой объем до определенных максимально допустимых пределов и далее кодирование идёт уже с использованием всех 100% битрейта. И обратная ситуация: если сложный сигнал продолжается достаточно долго, из резервуара (постепенно) забираются все сэкономленные биты и далее кодирование идёт с использованием уже теперь всех 100% битрейта.
Главное отличие ABR от CBR в том, что в CBR все фреймы обязаны быть одного размера (то есть битрейт для всех фреймов должен быть одинаков), в ABR же это ограничение снято, соответственно, существует возможность вместо стандартного весьма ограниченного по размеру резервуара использовать практически бесконечный «виртуальный» резервуар. Выглядит это приблизительно следующим образом.
Простые пассажи кодируются меньшим количеством бит, на них берётся примерно 95% от указанного битрейта B, но теперь остаток не откладывается в резервуар, кодер просто берёт фрейм с меньшим битрейтом. Возникающая разница (оставшиеся биты) записывается в стандартный резервуар (не выбрасывать же оставшиеся биты. ). Пример. Допустим пришел «простой» пассаж. Тогда кодер берет все биты (если таковые есть) в резервуаре (настоящем), потом ищет ближайший стандартный битрейт, при котором суммарное количество бит, получившееся для этого фрейма (все биты из резервуара + взятый битрейт), составит 95% от заданного пользователем битрейта B, производит кодирование, а лишние биты (если они остались) снова сохраняет в резервуаре.
Методы оценки сложности сигнала
Таким образом, основное отличие CBR, ABR и VBR, как вы уже наверное поняли из сказанного выше, состоит в использовании разных методов подсчёта необходимого для кодирования каждого фрейма количества бит.
Методы оценки сложности сигнала: метод 1 (VBR)
Первый метод основан на вычислении «психоакустической маскировки» и «ошибки кодирования». Этот метод используется в VBR и теоретически должен был бы давать максимальное качество если бы психоакустическая модель Lame’а была идеальна. В основе этого метода лежит очень простая идея: на кодирование выделяется минимальное количество бит, необходимое для выполнения условия: [ошибка_кодирования] Какие методы кодирования стерео информации используются в алгоритмах MPEG (и других)?
Существует несколько методов кодирования стерео аудио информации в стандарте ISO11172-3 (MPEG-1 Layer 1,2,3).
Dual Channel. Этот режим предполагает кодирование стерео каналов, как абсолютно независимых. Иными словами, в этом режиме кодирование аудио информации происходит отдельно в каждом канале без использования корреляций между ними. Как и следует из названия, этот режим главным образом предназначен для кодирования двух параллельных но различных каналов (например, речь на английском и немецком языках), а не стерео (т.е. не два канала, несущих информацию о стерео картине). Этот режим не рекомендуется использовать для кодирования стерео сигнала, так как существуют проигрыватели (например, madplay), проигрывающие по умолчанию только один канал если поток помечен как Dual Channel.
Stereo. Этот режим отличается от предыдущего только тем, что в режиме Dual Stereo во время кодирования для каждого канала используется свой резервуар (об этом в обсуждении вопроса об отличиях ABR/VBR/CBR), а в этом режиме оба канала кодируются с использованием общего резервуара. Иных различий между режимами нет.
При кодировании в MPEG-1 имеются две разновидности этого метода.
Intensity Stereo. В этом режиме в верхнем частотном диапазоне так же происходит кодирование общей составляющей обоих каналов, как и в случае MS Stereo, но вместо кодирования разностной составляющей в верхнем диапазоне частот происходит просто регистрация и запись мощностей сигналов в левом и правом каналах в каждой частотной полосе начиная с некоторой определенной. Иными словами весь сигнал разбивается на полосы, фактическому кодированию подвергается только нижний диапазон частот side-канала, а в верхнем частотном диапазоне начиная с определенной полосы происходит не кодирование сигнала в каждой полосе, а лишь регистрация мощностей сигнала в каждой полосе. Кодирование стерео сигнала в нижнем частотном диапазоне осуществляется в режиме MS Stereo или просто Stereo.
Таким образом, в режиме Joint Stereo фактически происходит кодирование лишь общей составляющей каналов, а стерео на высоких частотах «воссоздается» (если такой термин здесь уместен, а лучше «синтезируется») в соответствующем канале путем умножения общего сигнала на известные (сохраненные при кодировании) значения мощностей частотных участков в соответствующем канале.
Можно предположить, что приблизительно аналогичные методы кодирования стерео аудио информации применяются и в других алгоритмах компрессии аудио.
Какие параметры предпочтительны при кодировании MP3?
Этот вопрос не имеет однозначного ответа. Каждый человек подбирает себе параметры кодирования в зависимости от конкретной задачи. Если речь идет о кодировании голоса или другой звуковой информации при малых требованиях к качеству, то кодирование можно производить на минимальных битрейтах, вплоть до 8 Кбит/с (при данном битрейте полоса частот ограничивается 2,5 КГц, что сравнимо с телефонной линией).
Если же стоит вопрос о кодировании аудио данных с CD (44.1 KГц / 16 бит / стерео), то на этот счет существует масса мнений. Большинство пользователей почему-то убеждено, что битрейта 128 Кбит/c достаточно для кодирования аудио CD-качеcтва без потерь. На самом деле это не так. В этом легко убедиться, если прослушать (даже на аппаратуре среднего качества) сначала оригинал, а затем полученный MP3. MP3 будет отличаться как минимум «сухостью» звучания, не говоря уже о появлении некоторых посторонних «позвякиваний», скрежета и других помех.. Это обусловлено тем, что используемая при кодировании психоакустическая модель оставляет только «жизненно необходимые» частоты, отфильтровывая замаскированные и слабослышимые. Причем это проявляется тем больше, чем с меньшим битрейтом производится кодирование. Основываясь на опыте можно предположить, что битрейт, достаточный для «точной» передачи CD-звучания, лежит в пределах от 192 до 320 Кбит/с (в зависимости от кодируемого аудио сигнала и, конечно, самого слушателя). Безусловно, при таком кодировании объем, занимаемый полученным MP3-потоком, увеличивается пропорционально поднятию битрейта.
Какие альтернативные MPEG-1 Layer III (MP3) алгоритмы компрессии существуют?
Действительно, на MP3 свет клином не сошелся. Параллельно MP3 появляются и развиваются не менее, а иногда, и более прогрессивные алгоритмы компрессии звука. Перечислять все алгоритмы нет надобности. Следует отметить только, что существуют алгоритмы по своим возможностям и качеству во многом превосходящие MP3. Один из таких алгоритмов это MPEG-2 AAC.
MPEG-2 AAC. MPEG-2 Advanced Audio Coding – продвинутое аудио кодирование) стал результатом кооперации усилий института Fraunhofer, компаний Sony, NEC и Dolby. MPEG-2 AAC является технологическим приемником MPEG-1. Существует несколько разновидностей этого алгоритма: Homeboy AAC, AT&T a2b AAC, Liquifier AAC, Astrid/Quartex AAC и Mayah AAC. Наиболее высокое качество звучания по сравнению c MPEG-1 Layer III обеспечивают две предпоследние реализации. Все приведенные разновидности алгоритма AAC не являются совместимыми между собой.
Так же, как и в комплекте аудио стандартов кодирования MPEG-1, в основе алгоритма AAC лежит психоакустический анализ сигнала. Вместе с тем, алгоритм AAC имеет в своем механизме множество дополнений, направленных на улучшение качества выходного аудио сигнала. В частности, используется другой тип преобразований, улучшена обработка шумов, изменен банк фильтров, а также улучшен способ записи выходного бит-потока. Кроме того, AAC позволяет хранить в закодированном аудио сигнале т.н. «водяные знаки» (watermarks) – информацию об авторских правах. Эта информация встраивается в бит-поток при кодировании таким образом, что уничтожить ее становится невозможно не разрушив целостность аудио данных. Эта технология (в рамках Multimedia Protection Protocol) позволяет контролировать распространение аудиоданных (что, кстати, является препятствием на пути распространения самого алгоритма и файлов, созданных с помощью него). Следует отметить, что алгоритм AAC не является обратно совместимым (NBC – non backwards compatible) с уровнями MPEG-1 не смотря на то, что он представляет собой продолжение (доработку) MPEG-1 Layer I, II, III.
Говоря о качестве звука, можно сказать, что поток AAC 96 Кбит/с обеспечивает качество звучания, аналогичное потоку MPEG-1 Layer III 128 Кбит/с. При компрессии AAC 128 Кбит/с, качество звучания ощутимо превосходит MPEG-1 Layer III 128 Кбит/с.
Несколько слов необходимо сказать и о другом прогрессивном алгоритме TwinVQ(Transform-domain Weighted Interleave Vector Quanization), разработанном фирмой Nippon Telegraph and Telephone Corp. (NTT) в Human Interface Laboratories и лицензированном фирмой Yamaha (продукты от Yamaha, основанные на TwinVQ, распространяются под торговой маркой SoundVQ). Этот метод позволяет сжимать цифровые потоки с коэффициентом компрессия до 1:20. При этом качество звучания потока TwinVQ при 96 Кбит/с практически идентично качеству звучания потока MPEG-1 Layer III (при 128 Кбит/с) и MPEG-2 AAC (при 96 Кбит/с). Алгоритм TwinVQ позволяет кодировать данные во всем диапазоне слышимых частот (до 22 КГц) и, также как и MPEG, производить декодирование и воспроизведение потока одновременно с его получением (stream playback). Кстати, говоря об алгоритме TwinVQ следует сказать также, что трудоемкость этого алгоритма намного выше трудоемкости, например, алгоритма MPEG-1 Layer III, так что программы-компрессоры, основанные на алгоритме TwinVQ работают в 5-10 раз медленнее, чем Layer III-компрессоры. Следует сказать также, что наработки TwinVQ используются в стандарте MPEG-4. По различным оценкам, TwinVQ в нижнем диапазоне частот превосходит по качеству MPEG-1 Layer III, уступая ему на верхних частотах. TwinVQ поддерживает кодирование с переменным битрейтом (VBR), а также имеет поддержку т.н. несимметричного битрейта, когда разные каналы кодируются с отличными битрейтами.
Алгоритм PAC (Perspective Audio Coding) от Bell Labs & Lucent Technologies. По различным данным обеспечивает аналогичное (или выше) MPEG-1 Layer III 128 Кбит/с качество звучания при 64 Кбит/с. Поддерживаются также 96 и 128 Кбит/с. Алгоритм позволяет потоковое воспроизведение (stream playback). Имеет встроенный механизм защиты. Обладает высокой скоростью компрессии.
Можно ли осуществить преобразование из одного потокового формата аудио данных в другой?
Можно ли осуществить преобразование WAV в MIDI, WAV в трекерный модуль?
Таким образом, для того, чтобы, скажем, преобразовать оцифрованную музыку в формат MIDI необходимо качественно проанализировать весь исходный цифровой поток и однозначно определить, звучание каких инструментов необходимо будет задействовать в выходном MIDI-файле. То есть, фактически необходимо точно идентифицировать инструменты, входящие в композицию. Однако эта проблема, по крайней мере на сегодняшний день, почти не решаема. Посудите сами: для того, чтобы правильно определить звучание какого инструмента происходит в данный момент, нужно, грубо говоря, однозначно знать спектры всех возможных инструментов. И затем, сравнивая спектр звучащего инструмента с набором спектров известных инструментов, определить звучание какого инструмента мы слышим. Но в тоже время мы знаем, что спектр одного и того же инструмента может сильно измениться даже при небольшом изменении силы воздействия на него, а это в свою очередь означает, что однозначно получить спектр мы не можем. Но все сказанное касалось звучания только одного инструмента. А что же будет со спектром сигнала, если в него входит звучание сразу нескольких инструментов? Спектр изменится коренным образом! Вы скажете, что можно, наверное, определить звучание по формантным областям. Да, это возможно, однако говорить все же о точности определения не приходится. Да и проблема-то не заканчивается точной идентификацией инструментов. В дальнейшем придется точно определять тональности звучания, расстановку во времени и тому подобное. По этой причине можно сделать однозначный вывод: качественное преобразование цифровых потоков в MIDI невозможно в принципе.
Справедливости ради нужно сказать, что существует некоторое количество программ, которые позволяют переводить простые одноголосые композиции в MIDI-партитуру.
Можно ли перевести цифровой поток в трекерный модуль? Нет, нельзя по приведенным выше причинам. Более того, так как в трекерных модулях (в отличие от MIDI) хранятся кроме команд и сами используемые в композиции инструменты, то для того, чтобы перевести поток в трекерный модуль, из него нужно вычленить звучание отдельных инструментов. А эта задача равносильна вычленению, например, голоса из песни (караоке). То есть, это возможно в какой-то мере, но вычленение несомненно будет крайне некачественным, так как спектры инструментов чаще всего наложены друг на друга.
Можно ли выделить из аудио потока звучание конкретного инструмента или голоса?
Что же касается вычленения звучания каких-то инструментов, то этот вопрос аналогичен предыдущему (точнее, третий абзац предыдущего вопроса).
Таких способов много. Попробуем их перечислить.
Какой метод сравнения двух аудио сигналов можно признать наиболее точным?
Сначала договоримся, что речь идет о сравнении двух сложных непериодических сигналов, представленных в цифровом виде. Далее все зависит от стоящей перед экспериментатором задачи. Вероятно, все сводится к двум вариантам: физическое сравнение двух сигналов (то есть сравнение точности совпадения форм сигналов) и субъективное сравнение, когда целью является оценка «похожести» звучания двух сигналов.
Второй вариант, целью которого является субъективное сравнение разницы в звучании двух сигналов, очень часто применим при оценке качества алгоритмов компрессии аудио. Вообще, целью большинства аудио кодеков (за исключением специализированных, например, вокодеров или кодеков для передачи ограниченного спектра частот) является в максимально меньшем объеме данных сохранить аудио информацию как можно более приближенную по качеству к оригинальному звучанию. Другими словами, задача сводится к обеспечению субъективно сходного с оригиналом качества звучания и никак ни объективного физического сходства форм (огибающих) оригинального и декодированного сжатого сигналов. В этом случае, применимость описанных выше методов сравнения может быть очень спорна, так как форма сигналов может совпадать очень слабо, а субъективное качество звучания оригинального и восстановленного сжатого сигналов при этом почти не изменится. Тогда для сравнения сигналов можно воспользоваться несколькими разновидностями спектрального анализа, каждый из которых, тем не менее, имеет массу недостатков.
Первый заключается в графическом сравнении результирующих АЧХ оригинального и восстановленного сжатого сигналов за какой-то промежуток времени. Под понятием «результирующая АЧХ» подразумевается график зафиксированных пиковых значений амплитуд частотных составляющих сигнала за некоторый промежуток времени. Таким образом, взяв два одинаковых промежутка сравниваемых сигналов и построив их результирующие АЧХ, по совпадению (не совпадению) графиков АЧХ можно приблизительно оценить уровень потерянных частотных составляющих в сжатом сигнале, а также увидеть полосы частот, где эти потери наиболее выражены. Однако этот метод является статичным, то есть он абсолютно не учитывает изменение сигналов в динамике, что является очень важным, так как часто встречаются случаи, когда результирующие АЧХ сигналов почти совпадают, однако звучание сравниваемых промежутков сигналов отличается коренным образом даже на слух.
Третий метод представляет собой более конкретизированный предыдущий, он заключается в построении АЧХ для каждого сканируемого окна БПФ. Однако эта задача не лишена тех же проблем, что и предыдущий метод, и, кроме того, производить сравнение графически крайне неудобно, даже если представить всю обсчитанную спектральную картину сигнала в трехмерном виде.
Очевидно, что идеального метода сравнения сигналов не существует. Поэтому в каждом конкретном случае пользуются наиболее подходящим по точности и удобству методом сравнения, руководствуясь только соображениями целесообразности.



