Hardware Prefetcher в BIOS — что это?
 Hardware Prefetcher в BIOS — опция активирующая механизм предвыборки инструкций и данных из ОЗУ для предсказания дальнейших операций, инструкции записываются в кэш 2 уровня.
Hardware Prefetcher в BIOS — опция активирующая механизм предвыборки инструкций и данных из ОЗУ для предсказания дальнейших операций, инструкции записываются в кэш 2 уровня.
ОБНОВЛЕНИЕ ИНФОРМАЦИИ: по информации в интернете опция предназначена для старых процессоров Пентиум 4. Однако также встречается информация, что Hardware Prefetcher — это предвыборка данных, которая может ускорить работу современного процессора, я находил картинки современных биосов, там эта опция есть. С другой стороны, если опция для старых процов, почему она присутствует в новых материнках? Возможно она распространяется и на новые и активация ее немного повысит производительность.
Разбираемся
Данная функция если и актуальна, то только для старых процессоров на сокете 478 или 775, потому что предназначена для моделей Pentium 4/D на архитектуре NetBurst степпинга C1 или новее. Функция включает аппаратный предварительный выборщик, который автоматически анализирует требования процессора и предварительно выбирает данные/инструкции из памяти в кэш 2 уровня, которые в ближайшем времени могут понадобиться. В результате — уменьшается задержка, связанная с чтением данных и производительность немного возрастает.
Включать нужно только тогда, когда ваш процессор подходит. В противном случае может быть аппаратная ошибка Errata O37, вызывающая повреждение данных.
Включать или нет? Если процессор подходит — включать. Подходит или нет можно узнать через специальный софт, например AIDA64, который умеет показывать степпинг. Если у вас проц на сокете 1155, 1150, 1151 и новее — функцию нет смысла включать вообще, это новые процы, для которых функция неактуальна. Только непонятно, если функция Hardware Prefetcher для старых процов — почему она присутствует в новых биосах?
Superfetch
Навигация
Официальный сайт Superfetch
Новости
22 октября, 2018
По просьбе пользователей, мы описали основные причины: Почему зависает или тормозит компьютер, и что с ним делать?
16 октября, 2018
Мы выпустили вторую версию программы superfetch.exe. Теперь можно отключить: SuperFetch, Prefetch, ReadyBoot, это возможно существенно ускорит скорость работы Вашего компьютера!
28 Сентября, 2018
Мы выпустили первую версию программы superfetch 1.00 для быстрого включения/отключения superfetch.
Ждем Ваших отзывов и предложений!
Что такое prefetch и почему его отключают?
Изначально служба prefetch разрабатывалась как отдельный компонент ОС Windows (начиная с ОС Windows XP) для ускорения запуска системы и приложений. Все это было в далеком 2001 году. Представляете конфигурацию компьютеров в те времена?

Теперь вернемся в наш 2018 год.
Проблема кэширования данных уже давно решена на аппаратном уровне и заложена в любой жесткий диск с магнитным накопителем. Где для кэширования данных есть собственная память, объем которой рассчитывается исходя из скорости вращения диска, чтобы соответсвовать максимальной пропускной способности для интерфейсов подключения (IDE, далее SATA и прочие).
Почему надо отключать эту службу? Служба prefetch (в списке служб она называется prefetcher) наблюдает за запуском приложений и создает файлы трассировки оптимизации кода. Эта сложная структура кэша исполняемого кода, которая собирается ограниченное время (10 секунд после запуска) и подставляется в память при повторном запуске приложений. Отключают эту службу потому, что время потраченное на создание трассировки, намного больше, чем время и скорость считывания данных с современных жестких дисков. Тем более появились более быстрые SSD диски.
Microsoft в принудительном порядке отключает prefetch на собственных планшетах линейки Surface.
Повышение производительности с использованием uop-кэша на Sandy Bridge+
В современных x86 процессорах Intel, конвеер можно разделить на 2 части: Front End и Back End.
Front End отвечает за загрузку кода из памяти и его декодирование в микрооперации.
Back End отвечает за выполнение микроопераций, пришедших от Front End. Поскольку эти микрооперации могут выполняться ядром не по порядку, то Back End также следит за тем, чтобы результат выполнения этих микроопераций строго соответствовал порядку в котором они идут в коде.
В большинстве случаев не эффективное использование Front End’a не оказывает заметного влияние на производительность. Пиковая пропускная способность на большинстве процессоров Intel — 4 микрооперации за такт, поэтому, например, для Memory/L3-bound кода ЦПУ не сможет полностью ее утилизировать.
Однако в некоторых случаях различие в производительности может быть достаточно существенно. Под катом — анализ влияния кэша микроопераций на производительность.
Содержание статьи
Окружение
Обзор Front End’a процессоров Intel
Высокоуровневая организация конвеера — публично доступная информация и опубликована в оффициальной документации Intel по оптимизации софта. Более детальное описание некоторых особенностей, которые опущены в оффициальной документации можно найти в других авторитетных источниках, таких как Agner Fog или Travis Downs. Так, например, схема конвеера для Skylake в документации Intel имеет вид:
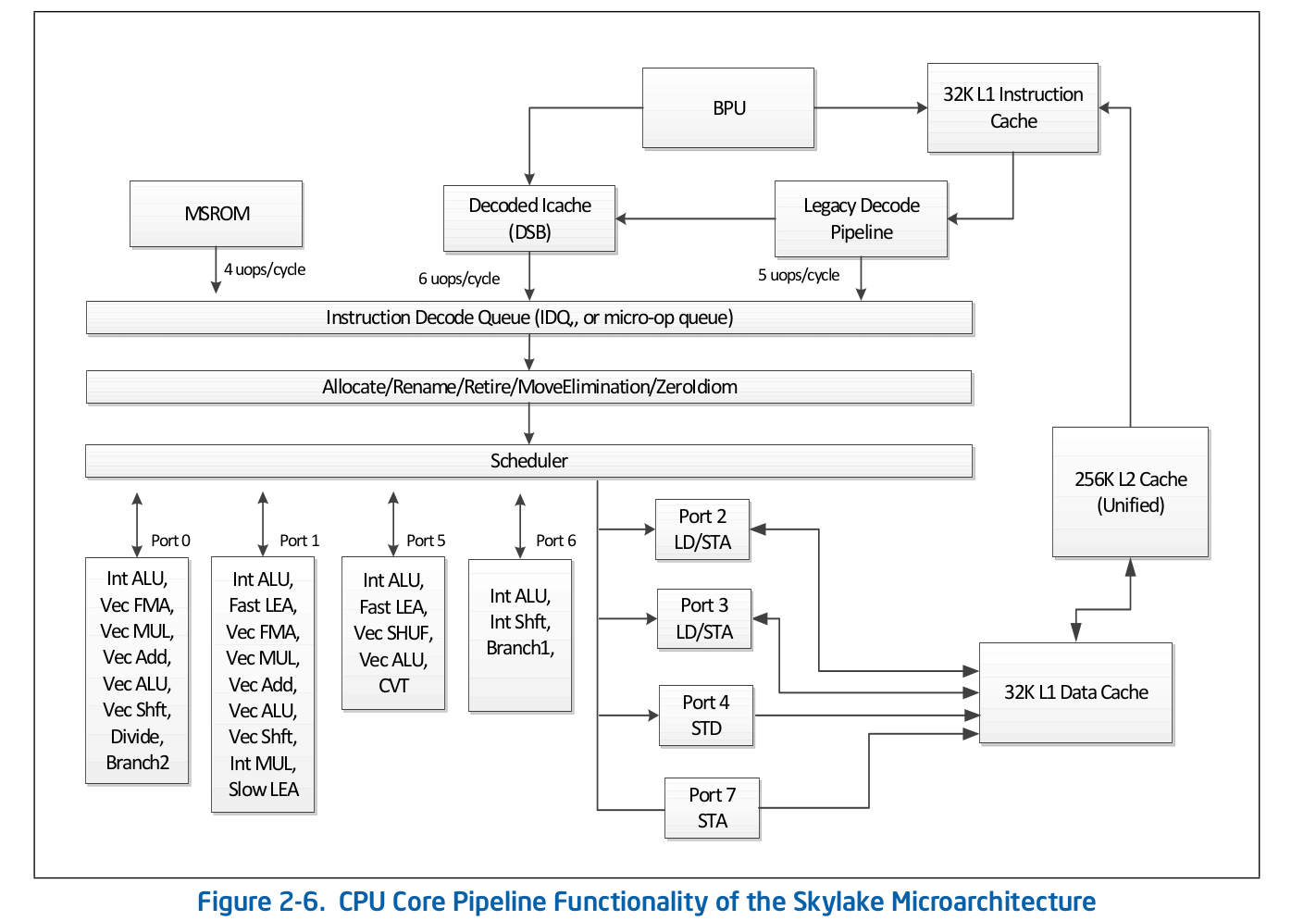
Рассмотрим подробнее верхнюю часть данной схемы — Front End.

За декодирование кода в микрооперации отвечает Legacy Decode Pipeline. Он состоит из следующих компонентов:
Рассмотрим каждую из частей Legacy Decode Pipeline по отдельности.
Instruction Fetch Unit.
Отвечает за загрузку кода, предекодирование (определение длины инструкции и свойств типа «является ли инструкция ветвлением») и доставку в очередь пре-декодированных инструкций.
Кэш инструкций первого уровная — L1i
Для загрузки кода IFU использует L1i — кэш инструкций первого уровная и L2/LLC — кэш второго и offcore-кэш верхнего уровня, общие для кода и данных. Загрузка выполняется кусками по 16 байт, также выровненные на 16-байт. При загрузке следующего по порядку 16-байтного куска кода происходит обращение к L1i и, если соответсвующая линия не найдена, то выполняется поиск в L2 и, в случае не успеха, в LLC и памяти. До Skylake, LLC кэш был инклюзивным — каждая линия в L1(i/d) и L2 должны была содержаться в LLC. Таким образом LLC «знал» про все линии во всех ядрах и, в случае LLC промаха было известно, содержат ли кэши в других ядрах требуемую линию в состоянии Modified, а значит данная линия могла быть загружена из друго ядра. В Skylake, LLC стал не инклюзивным L2-victim кэшем, однако в 4 раза был увеличен размер L2. Мне не известно, является ли L2 инклюзивным по отношению к L1i. L2 не инклюзивный по отношению к L1d.
Кэш трансляций логических адресов инструкций — ITLB
The software-controlled prefetch is intended for prefetching data, but not for prefetching code.
Однако Travis D. упоминал, что подобный префетч может быть весьма эффектиным (и скорее всего это так и есть), но мне пока что это не очевидно и для того, чтобы в этом убедиться нужно будет отдельно исследовать этот вопрос.
Загрузка данных в кэш (L1d/i, L2, etc) происходит при обращении к незакэшированному участку памяти. Однако, если бы это происходило только при таких условия, то в результате мы бы получили не эффективное использование пропускной способности кэша. Например, на Sandy Bridge для L1d — 2 операции на чтение, 1 на запись по 16 байт за такт; для L1i — 1 операция на чтение по 16 байт, пропускная способность на запись не указана в документации, у Agner Fog также не обнаружилось. Для решения этой проблемы существуют Hardware префетчеры, которые умеют определять паттерн доступа к памяти и подтягивать нужные линии в кэш до того, как код по факту к ним обратится. Документация Intel определяет 4 префетчера: 2 для L1d, 2 для L2:
Документация Intel никак не описывает принцип работы L1i перфетчера. Все что известно — это то, что в этом процессе учавствует Branch Prediction Unit (BPU), Intel Software Optimization Manual/2.6.2:

У Agner Fog каких-либо деталей также не просматривается.
Префетч кода в L2/LLC явно определены только для Streamer. Optimization Manual/2.5.5.4 Data Prefectching:
Streamer: This prefetcher monitors read requests from the L1 cache for ascending and descending sequences of addresses. Monitored read requests include L1 DCache requests initiated by load and store operations and by the hardware prefetchers, and L1 ICache requests for code fetch.
Для Spatial префетчера это явно не прописано:
Spatial Prefetcher: This prefetcher strives to complete every cache line fetched to the L2 cache with the pair line that completes it to a 128-byte aligned chunk.
Используя данный MSR можно исследовать вопрос реакции L2 Spatial на обращения из L1i. Я сам этого не проделывал. Выключение префетчеров я использовал для исследования различий в производительности при обработки больших массивов данных, не влезающих в LLC. В данном случае отключение L2 Streamer вызывало падение производительности в среднем в 2.5 раза.
После того как очередные 16-байт кода загружены, они попадают в пре-декодер инструкций. Его задача — определить длину инструкции, декодировать префиксы и пометить, является ли соответствующая инструкция ветвлением (скорее всего еще много разных свойств, но документация о них умалчивает). Intel Software Optimization Manual/2.6.2.2:
The predecode unit accepts the sixteen bytes from the instruction cache or prefetch buffers and carries out the following tasks:
• Determine the length of the instructions.
• Decode all prefixes associated with instructions.
• Mark various properties of instructions for the decoders (for example, “is branch.”).
Очередь пре-декодированных инструкций.
Из IFU инструкции складываются в очередь предекодированных инструкций. Данная очередь появилась начиная с Nehalem, в соответвствии с документацие Intel ее размер — 18 инструкций. Agner Fog также упоминает, что в эту очередь вмещается не больше 64 байт.
Также в Core2 данная очередь использовалась как кэш циклов (loop cache). Если все микрооперации из цикла содержатся в очереди, то в ряде случаев можно было бы избежать затраты на загрузку и предекодирование. Loop Stream Detector (LSD) может доставлять инструкции, которые уже есть в очереди до тех пор, пока BPU не просигналит, что цикл закончился. У Agner Fog есть ряд интересных замечаний касательно LSD на Core2:
Начиная с Sandy Bridge, данный кэш циклов переехал из очереди пре-декодировнных инструкций обратно в IDQ.
Декодеры пре-декодированных инструкций в микрооперации
Из очереди пре-декодированных инструкций код поступает на декодирование в микрооперации. За декодирование отвечают декодеры — всего их 4. В соответствии с документацией Intel, один из декодеров умеет декодировать инструкции, состоящие из 4-х микроопераций и менее. Остальные декодируют инструкции состоящие из одной микрооперации (micro/macro fused), Intel Software Optimization Manual/2.5.2.1:
There are four decoding units that decode instruction into micro-ops. The first can decode all IA-32 and Intel 64 instructions up to four micro-ops in size. The remaining three decoding units handle single-micro-op instructions. All four decoding units support the common cases of single micro-op flows including micro-fusion and macro-fusion.
Инструкции, декодируемые в большое количество микрооперация (напр. rep movsb, используемая в реализации memcpy в libc на определенных размерах копируемой памяти) поступают из Microcode Sequencer (MS ROM). Пиковая пропускная способность секвенсера — 4 микрооперации за такт.
Как можно видеть на схеме конвеера, Legacy Decode Pipeline может декодировать до 5 микроопераций за такт на Skylake. На Broadwell и старше пиковая пропускная способность Legacy Decode Pipeline’a была 4 микрооперации за такт.
После того, как инструкции декодированы в микрооперации, из Legacy Decode Pipeline они попадают в специальную очередь микроопераций — Instruction Decode Queue (IDQ), а также в так называемый кэш микроопераций (Decoded ICache, µop cache). Кэш микроопераций изначально появился в Sandy Bridge и используется для того, чтобы избежать фетчинга и декодирования инструкций в микрооперации, повышая тем самым пропускную способность доставки микроопераций в IDQ — до 6 за такт. После попадания в IDQ, микрооперации уходят в Back End на выполнение с пиковой пропускной способностью — 4 микрооперации за такт.
В соответствии с документацией Intel, кэш микроопераций состоит из 32-х сетов, каждый сет содержит по 8 линий, каждая линия может кэшировать до 6 микроопераций (micro/macro fused), позволяя в общей сложности кэшировать до 32 * 8 * 6 = 1536 микроопераций. Кэширование микроопераций происходит с гранулярностью в 32 байта, т.е. микрооперации, которые соответствуют инструкциям из разных 32-байтных регионов не могут попасть в одну линию. Тем не менее, одному 32-байтному региону может соответствовать до 3-х различных линий кэша. Таким образом каждому 32-байтному региону может соответствовать до 18 микроопераций в µop cache.
The Decoded ICache consists of 32 sets. Each set contains eight Ways. Each Way can hold up to six micro-ops. The Decoded ICache can ideally hold up to 1536 micro-ops. The following are some of the rules how the Decoded ICache is filled with micro-ops:
• All micro-ops in a Way represent instructions which are statically contiguous in the code and have their EIPs within the same aligned 32-byte region.
• Up to three Ways may be dedicated to the same 32-byte aligned chunk, allowing a total of 18 micro-ops to be cached per 32-byte region of the original IA program.
• A multi micro-op instruction cannot be split across Ways.
• Up to two branches are allowed per Way.
• An instruction which turns on the MSROM consumes an entire Way.
• A non-conditional branch is the last micro-op in a Way.
• Micro-fused micro-ops (load+op and stores) are kept as one micro-op.
• A pair of macro-fused instructions is kept as one micro-op.
• Instructions with 64-bit immediate require two slots to hold the immediate.
Agner Fog также упоминает, что за такт может быть загружены микрооперации только из одной линии (явно не прописано в документации Intel, хотя и легко проверяется в ручную).
Для тестирования пропускной способности объявим функцию
с реализацией на nasm :
align 32
test_decoded_icache:
;nop’ы, от 0 до 23 включительно
dec rdi
ja test_decoded_icache
ret
Для замеров нам понадобятся следующие perf эвенты:
1. uops_issued.any — Используется для подсчета микроопераций которые Renamer забирает из IDQ.
Intel System Programming Guide документирует этот эвент как количество микроопераций, которые Renamer кладет в Reservation Station:
Counts the number of uops that the Resource Allocation Table (RAT) issues to the Reservation Station (RS).
2. uops_retired.retire_slots — итоговое количество retired микроопераций с учетом micro/macro-fusion
3. uops_retired.stall_cycles — количество тактов, за которые не было ни одной retired микрооперации
4. resource_stalls.any — количество тактов простаивания конвеера по причине недоступности любого из ресурсов Back End
В Intel Software Optimization Manual/B.4.1 приведена содеражательная схема, которая характеризует описанные выше эвенты:

5. idq.all_dsb_cycles_4_uops — количество тактов, за которые из µop cache было доставлено по 4 (и более) инструкции.
То, что данная метрику учитывает доставку более 4х микроопераций за такт — не прописано в документации Intel, однако очень хорошо согласуется с экспериментами.
6. idq.all_dsb_cycles_any_uops — количество тактов, за которые доставлялась хотя бы одна микрооперация.
7. idq.dsb_cycles — Итоговое количество тактов, при которых была доставка из µop cache
8. idq_uops_not_delivered.cycles_le_N_uop_deliv.core — Количество тактов, за которые Renamer забирал по N или меньше микроопераций и не было простоя на стороне Back End, N — 1, 2, 3.

Что сразу бросается в глаза, так это проседание пропускной способности retirement’a при размере цикла в 7 микроопераций. Для того, чтобы понять в чем дело, рассмотрим как меняется средняя скорость доставки из µop cache — idq.all_dsb_cycles_any_uops / idq.dsb_cycles :

и как связаны общее количество тактов и тактов за которые µop cache доставлял в IDQ:

Таким образом можно заметить, что при цикле из 6 микроопераций мы получаем эффективное использование пропускной способности µop cache — 6 микроопераций за такт. В силу того, что Renamer не может забрать столько, сколько доставляет µop cache, то часть тактов µop cache ничего не доставляет, что хорошо видно на предыдущем графике.
При цикле из 7 микроопераций мы получаем резкое падение пропускной способности µop cache — 3.5 микрооперации за такт. При этом, как видно из предыдущего графика, µop cache постоянно находится в работе. Таким оразом, при цикле размером в 7 микроопераций мы получаем не эффективную утилизацию пропускной способности µop cache. Дело в том, что, как было отмечено ранее, µop cache за такт может доставлять микрооперации только из одной линии. В случае, если микроопераций 7 — первые 6 попадают в одну линию, а оставшаяся 7я — в другую. Такими образом и получаем 7 микроопераций за 2 такта, или же 3.5 микрооперации за такт.
Рассмотрим теперь каким образом Renamer забирает микрооперации из IDQ. Для этого нам понадобятся idq_uops_not_delivered.core и idq_uops_not_delivered.cycles_le_N_uop_deliv.core :

Можно заметить, что при 7-ми микрооперациях, половину тактов Renamer забирает только 3 микрооперации за раз. Отсюда мы и получаем пропускную способность retirement’а в среднем 3.5 микрооперации за такт.
Другой интересный момент, связанный с данным примером можно увидеть, если рассмотреть эффективную пропускную способность retirement’а. Т.е. не учитывая uops_retired.stall_cycles :

Можно заметить, что при 7-ми микрооперациях, каждые 7 тактов выполняется retirement 4-х микроопераций, а каждый 8-й такт происходит простаивании с отсутствием retired микроопераций (retirement stall). Проведя ряд экспериментов, удалось обнаружить, что такое поведение наблюдалось всегда при 7-ми микрооперациях, вне зависимости от их компоновки 1-6, 6-1, 2-5, 5-2, 3-4, 4-3. Мне не известно, почему происходит именно так, а не, например за один такт выполняется retirement 3-х микроопераций, за следующий — 4-х. Agner Fog упоминал, что переходы по ветвлениям могут использовать только часть слотов retirement station. Может быть это ограничение и есть причина такого поведения retirement’а.
Пример
Даны два массива unsigned ‘ов. Необходимо накопить сумму средних арифметических для каждого индекса и записать ее в третий массив.
Пример реализации может выглядеть следующим образом:
Скомпилируем с gcc-флагами
-Werror
-Wextra
-Wall
-pedantic
-Wno-stack-protector
-g3
-O3
-Wno-unused-result
-Wno-unused-parameter
Вполне очевидно, что функция arithmetic_mean не будет присутствовать в коде и будет вставлена напрямую в main :
(gdb) disas main
Dump of assembler code for function main:
#.
0x00000000000005dc : nop DWORD PTR [rax+0x0]
0x00000000000005e0 : mov edx,DWORD PTR [rdi+rax*4]
0x00000000000005e3 : add edx,DWORD PTR [r8+rax*4]
0x00000000000005e7 : shr edx,1
0x00000000000005e9 : add ecx,edx
0x00000000000005eb : mov DWORD PTR [rsi+rax*4],ecx
0x00000000000005ee : add rax,0x1
0x00000000000005f2 : cmp rax,0x80
0x00000000000005f8 : jne 0x5e0
0x00000000000005fa : sub r9,0x1
0x00000000000005fe : jne 0x5d8
#.
Заметим, что компилятор выравнил код цикла на 32 байта ( nop DWORD PTR [rax+0x0] ), а это как раз то, что нам нужно. Убедившись в отсутствии resource_stalls.any на Back End (все замеры выполнены с учетом прогретого L1d кэша) можно приступать к рассмотрению каунтеров, связанных с доставкой в IDQ:
Performance counter stats for ‘./test_decoded_icache’:
2 273 343 251 idq.all_dsb_cycles_4_uops (15,94%)
4 458 322 025 idq.all_dsb_cycles_any_uops (16,26%)
15 473 065 238 idq.dsb_uops (16,59%)
4 358 690 532 idq.dsb_cycles (16,91%)
2 528 373 243 idq_uops_not_delivered.core (16,93%)
73 728 040 idq_uops_not_delivered.cycles_0_uops_deliv.core (16,93%)
107 262 304 idq_uops_not_delivered.cycles_le_1_uop_deliv.core (16,93%)
108 454 043 idq_uops_not_delivered.cycles_le_2_uop_deliv.core (16,65%)
2 248 557 762 idq_uops_not_delivered.cycles_le_3_uop_deliv.core (16,32%)
2 385 493 805 idq_uops_not_delivered.cycles_fe_was_ok (16,00%)
15 147 004 678 uops_retired.retire_slots
4 724 790 623 uops_retired.total_cycles
1,228684264 seconds time elapsed
Заметим, что retirement badwidth в данном случае = 15147004678 / 4724790623 = 3.20585733562, а также, что половину тактов Renamer забирает только по 3 микрооперации.
Добавим теперь ручную раскрутку цикла в реализацию:
Получившиеся перф каунтеры имеют вид:
Performance counter stats for ‘./test_decoded_icache’:
2 152 818 549 idq.all_dsb_cycles_4_uops (14,79%)
3 207 203 856 idq.all_dsb_cycles_any_uops (15,25%)
12 855 932 240 idq.dsb_uops (15,70%)
3 184 814 613 idq.dsb_cycles (16,15%)
24 946 367 idq_uops_not_delivered.core (16,24%)
3 011 119 idq_uops_not_delivered.cycles_0_uops_deliv.core (16,24%)
5 239 222 idq_uops_not_delivered.cycles_le_1_uop_deliv.core (16,24%)
7 373 563 idq_uops_not_delivered.cycles_le_2_uop_deliv.core (16,24%)
7 837 764 idq_uops_not_delivered.cycles_le_3_uop_deliv.core (16,24%)
3 418 529 799 idq_uops_not_delivered.cycles_fe_was_ok (16,24%)
3 444 833 440 uops_retired.total_cycles (18,18%)
13 037 919 196 uops_retired.retire_slots (18,17%)
0,871040207 seconds time elapsed
В данном случае имеем retirement bandwidth = 13037919196 / 3444833440 = 3.78477491672, а также эффективную утилизацию пропускной способности Renamer.
Таким образом мы не только избавились от одного ветвления и одной операции инкремента в цикле, но и увеличили retirement bandwidth используя эффективную утилизацию пропускной способности кэша микроопераций, что дало итоговые 28% прироста к производительности.
Заметим, что только лишь сокращение одного ветвления и операции инкремента дает прирост производительности в среднем на 9%.
Небольшое замечание
На ЦПУ, который использовался для выполнения данных экспериментов, выключен LSD. Кажется, что LSD мог бы обработать такую ситуацию. Для ЦПУ со включенным LSD подобные случаи нужно будет исследовать отдельно.
Ускорение сайта с помощью браузера
Скорость загрузки сайта – важный пункт технической оптимизации сайта.
Ранее мы уже рассказывали о 12 способах, как увеличить этот показатель в данной статье. В случае если все рекомендации выполнены, а скорость сайта желает лучшего, можно воспользоваться специальными директивами и ресурсными подсказками для браузеров (Resource Hints), чтобы увеличить показатели скорости вашего сайта.
В этой статье будут рассмотрены следующие директивы и ресурсные подсказки для браузеров:
С помощью этих подсказок мы сообщаем браузеру о ресурсах, которые посетитель сайта может использовать в ближайшее время. Браузер можно обучить обрабатывать указанные ресурсы и сохранять их в локальный кеш. В случае, если это произойдет, процесс загрузки на стороне пользователя будет намного быстрее.
Сразу обозначу, что это не является для браузера прямой инструкцией, а имеет рекомендательный характер.
В случае, если все ресурсы браузера заняты более важным процессом, он спокойно проигнорирует такие подсказки.
Второй важный момент: стоит понимать, что благодаря этим подсказкам скорость по Google PageSpeed не увеличится в разы.
Эти подсказки помогут скорее посетителю сайта и практически не повлияют на оценочные баллы PageSpeed.
Данные директивы относительно недавно появились, поэтому на старых версиях браузеров они не поддерживаются. Если вы хотите их использовать, следует обновить свой браузер.
Версии браузеров, поддерживающие те или иные ресурсные подсказки, можно посмотреть по ссылкам:
Разберемся с директивами по очереди. Предлагаю начать с dns-prefetch.
Dns-prefetch
Сейчас почти на всех сайтах используются сторонние ресурсы, такие как системы аналитики, онлайн-консультанты и прочие. Обработка и поиск нужного Dns браузером занимает какое-то время. Браузер начинает обрабатывать эту информацию в момент обнаружения внешнего ресурса в html-коде страницы.
В такой ситуации нам и поможет подсказка dns-prefetch, с ее помощью мы заранее сообщим браузеру о том, что в дальнейшем будет использоваться внешний ресурс, и вот его адрес. То есть браузер заранее будет знать, к какому dns необходимо обратиться во время загрузки нужного скрипта, что ускорит весь процесс.
Обработка dns-prefetch происходит в фоновом режиме во время просмотра пользователем страницы сайта.
Например, так мы сообщим о том, что надо проверить связь с dns Яндекса.
Следующая директива preconnect.
Preconnect
Отвечает за предварительное соединение. С ее помощью браузером устанавливается соединение до того, как отправлен HTTP-запрос.
TCP (Transmission Control Protocol, протокол управления передачей) – один из основных протоколов передачи данных интернета. Представляет собой поток данных с предварительной установкой соединения. Осуществляет повторный запрос данных в случае их потери, а также устраняет дублирование при получении двух копий одного пакета, гарантируя тем самым целостность передаваемых данных.
TLS (англ. transport layer security – протокол защиты транспортного уровня) – протокол, обеспечивающий защищённую передачу данных между узлами в сети Интернет.
Данный протокол широко используется в приложениях, работающих с сетью Интернет, таких как веб-браузеры, работа с электронной почтой, обмен мгновенными сообщениями и IP-телефонии.
Рассмотрим пример использования preconnect для Яндекс.Метрики:
Практическое сравнение preconnect и dns-prefetch
Скорость сайта без использования подсказок, TLS-соединение:

Скорость сайта без использования подсказок, TCP-соединение:
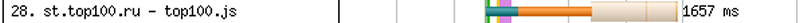
Добавим к TLS-соединению подсказки и получим вот такую картину.
TLS-соединение с использованием preconnect:

TLS-соединение с использованием dns-prefetch:

Теперь можно наглядно увидеть различие между dns-prefetch и preconnect: для второго вместе с обращением к dns сразу выполняется обмен пакетами для установки TCP- или TLS-соединения. И в дальнейшем, когда происходит непосредственно обработка скрипта в коде, из цепочки загрузки исключаются эти этапы, что сокращает скорость загрузки.
Как видно из графиков, с помощью подсказок мы заранее сообщаем браузеру о том, что в дальнейшем мы будем использовать внешний ресурс Яндекса, и нужно сразу получить информацию о его dns.
Стоит учесть, что это усредненное значение из выборки тестов, были единичные случаи, когда загрузка происходит быстрее, а также наоборот.
Prefetch
Эта подсказка сообщает браузеру о том, что указанный ресурс может понадобиться пользователю в будущем при перемещении по сайту. Браузер начнет загружать этот ресурс во время простоя, то есть тогда, когда страница уже полностью загрузилась – после загрузки ресурс сохранится в кеше браузера.
Prefetch имеет низкий приоритет среди остальных подсказок, его стоит использовать для ресурсов, которые понадобятся в будущем.
Однако в режиме простоя браузер не будет находиться вечно. Из этого вытекает вопрос, что будет с ресурсами, для которых указана директива prefetch, после того как пользователь перейдет на другую страницу и прервет режим простоя?
Ответ прост: браузер сохранит в кэше загруженную часть и вернется к дальнейшей загрузке снова, используя заголовок Content-Range, когда страница будет полностью загружена.
С помощью атрибута as указывается тип ресурса. Это помогает браузеру выбрать приоритет загрузки для предварительной выборки.
Также позволяет браузеру понять, совместим ли запрос с политикой безопасности контента в соответствии с атрибутом as. С помощью этого атрибута браузер может посылать подходящие заголовки accept, основываясь на типе ресурса.
Атрибут as может иметь следующие значения:
Нужно иметь в виду, что данная директива во время простоя браузера потребляет трафик. И если пользователь в итоге не обратится к данному ресурсу, этот трафик будет потрачен зря.
Пример из практики использования Prefetch
Допустим, мы знаем, что логотип сайта точно будет использоваться при дальнейшем просмотре. Давайте добавим в код подсказу браузеру о том, что нужно сохранить в кэш это изображение.
Добавим в код страницы:
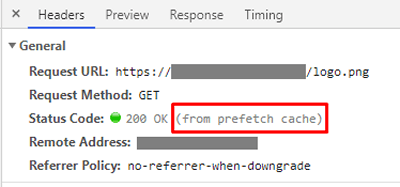
Проверим в браузере Google Chrome. Нужно открыть вкладку сеть (network) и найти там соответствующее изображение.
В строке Status Code увидим надпись (from prefetch cache), это означает что изображение закэшировалось и, соответственно, загрузилось из специального Prefetch-кеша.
Preload
Эта подсказка так же, как и Prefetch, служит для предварительной загрузки ресурсов, но имеет более высокий приоритет и используется для текущей навигации пользователя. То есть эта подсказка работает не для будущих страниц, а для страницы, на которой находится пользователь.
Ресурсы, для которых прописана директива Preload, имеют средний приоритет для браузера, и будут загружаться раньше, чем к ним обратится пользователь.
Это полезно для загрузки скриптов и таблиц стилей.
Если необходима предварительная загрузка связей с разрешенными CORS-ресурсами, необходимо добавить атрибут crossorigin.
Cross-origin resource sharing (CORS; с англ. – «совместное использование ресурсов между разными источниками») – технология современных браузеров, которая позволяет предоставить веб-странице доступ к ресурсам другого домена.
Так же, как и Prefetch, имеет атрибут As, используется для тех же целей.
По истечении 3 секунд после загрузки ресурса, если он не используется, Google Chrome выведет соответствующее предупреждение:

Не стоит использовать Preload для большого количества ресурсов, я бы рекомендовал применять его для предварительной загрузки шрифтов, и не более четырех раз. Чрезмерное использование этой подсказки может негативно влиять на загруженность сервера и соответственно скорость.
Prerender
И в завершении подсказка Prerender. С ее помощью можно предварительно загрузить в кэш браузера целую страницу. Нужно быть уверенным в том, что пользователь точно посетит указанную страницу, так как Prerender является одной из наиболее ресурсопотребляемых директив и может послужить причиной падения пропускной способности, особенно при использовании мобильных устройств.
Происходит следующее: строится полноценная html-страница, затем строится структура DOM-элементов с загрузкой всех скриптов и таблицами стилей. В связи с этим страница при открытии загружается очень быстро.
DOM (от англ. Document Object Model – «объектная модель документа») – это не зависящий от платформы и языка программный интерфейс, позволяющий программам и скриптам получить доступ к содержимому HTML-, XHTML- и XML-документов, а также изменять содержимое, структуру и оформление таких документов.
К сожалению, эту подсказку пока поддерживает наименьшее количество браузеров – Google Chrome и Microsoft Edge последних версий.
Добавление такой подсказки может быть полезно, например, в случае разбиения статей на несколько частей.
Также можно использовать для страниц акций, скидок.
Заключение
С помощью использования ресурсных подсказок и директив можно повысить скорость загрузки сайта на стороне пользователя.
Эти подсказки не создадут существенного прироста по параметрам Google PageSpeed, однако могут быть полезны для пользователей.
Важно понимать, что нет нужды добавлять все подряд в предзагрузку, так как есть вероятность, что предзагруженный ресурс не будет использован, и тем самым вы только усложните код. Нужно иметь четкое представление о том, как пользователь будет себя вести на определенной странице, это поможет правильно использовать подсказку.



