Найден секретный способ освободить до 20 Гб памяти в телефоне
Существует несколько способов очистить систему Android от мусора и освободить таким образом память устройства. Это могут быть как встроенные сервисы, так и некоторые сторонние приложения для очистки. Но что делать, если ни один способ вам не помог и телефон все равно сигнализирует о нехватке памяти? В этом случае можно прибегнуть к ручной очистке и освободить таким образом до 20 Гб памяти смартфона.
Удаление папки Telegram
В 2021 году этот кроссплатформенный мессенджер по праву стал самым популярным приложением в мире, обогнав по числу скачиваний даже такого гиганта как Tik-Tok.
Но у Telegram есть одна небольшая проблема – вся просмотренная вами информация сохраняется во внутренней памяти телефона, тем самым засоряя систему.
Если вы являетесь активным пользователем Telegram, рекомендуем периодически очищать содержимое папки с приложением. Для этого достаточно перейти в любой файловый менеджер и полностью удалить папку Telegram. Не стоит переживать, с приложением после удаления ничего не случится. Система при следующем входе автоматически создаст папку Telegram заново.
Многим пользователям, которые делают такую процедуру впервые после установки Telegram, удается очистить таким образом от 1 до 10 Гб памяти. Проверьте и убедитесь сами.
Удаление папки.Thumbnails
Следующий способ – удаление папки, которая содержится в корневом разделе DCIM (или Pictures) системы Android и содержит в себе все мини копии картинок и фотографий, которые встречаются вам при серфинге в интернете и в приложениях. Этот раздел также может занимать очень большой объем данных, если ранее вы еще не проводили подобную очистку.
Папка.Thumbnails довольно хитрая и скрыта от глаз пользователя в каталогах системы. Чтобы ее найти и удалить, необходимо сначала включить отображение скрытых папок в настройках файлового менеджера.
В некоторых случаях системный файловый менеджер также не дает увидеть эту папку. В этом случае можно попробовать установить стороннее приложение, например ES-проводник, а затем перейти в каталог DCIM (Pictures), включить отображение скрытых папок и удалить папку.Thumbnails.
Если вы больше не хотите, чтобы миниатюры засоряли вам память устройства, можно немного перехитрить систему, создав в папке DCIM новый файл с другим расширением, но с тем же названием.Thumbnails.
Система Android устроена таким образом, что никогда не позволит создать два файла с одинаковым названием, поэтому папка.Thumbnails больше не сможет там появиться. Сделать это также можно с помощью ES-проводника.
Нажимаем на три точки в верхнем правом углу приложения → «+Создать» → Файл. Называем файл.Thumbnails (обязательно ставим точку вначале).
Готово! Теперь наш созданный файл не позволит системе Android создать папку.Thumbnails, а значит система больше не будет засоряться лишними миниатюрами.
Удаление папки Data
Еще одна папка, занимающая большое количество памяти в телефоне – папка Data, которая находится внутри каталога Android. Эта папка содержит кэш, а также некоторые настройки и служебную информацию о приложениях. Но каких-либо серьезных системных данных, влияющих на работу системы в целом, она не содержит. Поэтому ее также можно удалить, освободив до 10 Гб памяти.
Удалять ее нужно только в обход корзины, так как сама корзина является вложенной в папку Data, о чем система предупреждает при попытке удалить ее стандартным путем. Поэтому нам потребуется снова воспользоваться сторонним файловым менеджером, который позволит удалить папку Data напрямую, без промежуточных инстанций.
Открываем ES проводник и переходим во внутренний каталог системы. Затем переходим в папку Android→Выделяем папку Data→ Нажимаем Удалить. Убираем галочку с пункта «Перенести в корзину» и нажимаем ОК. Нам удалось очистить таким образом почти 3 Гб внутренней памяти.
Заключение
В далеком 1981 году на пути становления IBM, Билл Гейтс произнес, ставшую сегодня забавным мемом, фразу: «В будущем 640 Кб будет достаточно для каждого». Из-за особенностей первых процессоров, никто не мог и представить, что когда-нибудь в компьютерах, а тем более в мобильных устройствах удастся разместить большее количество памяти, а главное, что кому-то может понадобиться такой объем информации.
Несмотря на то, что сегодня любой смартфон обладает памятью в десятки тысяч раз, превышающий этот объем, нехватка памяти до сих пор остается актуальной проблемой, особенно для бюджетных моделей смартфонов. Мы надеемся, что с помощью нашей инструкции вам удастся очистить ваше устройство и наконец решить данную проблему.
Что прячет Xiaomi в своих телефонах помимо фото
Наш смартфон всегда с нами. Позвонить? Пожалуйста. Посмотреть новости? Отчего бы и нет? Пообщаться с друзьями или коллегами? Он всегда к вашим услугам. Ну а про то, что он постоянно используется для съемки фотографий, даже говорить не приходится. Увы, у каждого приятного момента есть и оборотная сторона. После каждого процесса в памяти смартфона остаются следы. С течением времени они накапливаются и свободного пространства, которого вначале было много, становится все меньше и меньше.

В этой статье я остановлюсь на работе лишь одного приложения на смартфонах Xiaomi, это — «Галерея».
Как и любое другое, «Галерея» в процессе работы формирует различные файлы. Со временем они разрастаются и могут в объеме достигать многих сотен мегабайт. И этот объем может значительно превосходить объем хранимых фотографий.
Что это за файлы и нужны ли они вам? Найти их можно, выполнив задачу «Глубокая очистка», в результате которой будут показаны программы, данные которых занимают в долговременной памяти значительное место. Среди них выбираем «Галерею», а в ней – «Файлы данных» – «Просмотреть в папке».
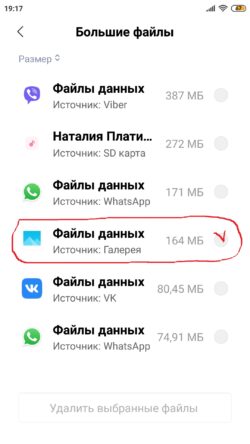
Здесь мы увидим ряд файлов, имеющих названия photo_blob.0; photo_blob.1; micro_thumbnail_blob.0; thumbnail_blob.0 и подобные.
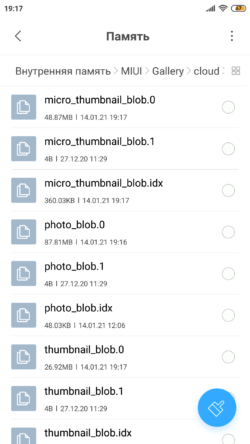
Эти файлы вы не увидите, если зайдёте в:
«Настройки» —> Моё устройство —> Хранилище
Они попадаю в раздел «Другие», а это означает, что система не может их распознать. Следовательно, к работе MIUI они отношения не имеют.
Обратим внимание на то, а в какой папке лежат эти файлы. Вот путь к ним:
В эту папку можно попасть и с помощью файлового менеджера, например, Total Commander. И он позволит дополнительно увидеть, что в этой папке лежит еще один файл — .nomedia, наличие которого определяет, что эти файлы не будут показаны в системе как мультимедийные.
Название папки говорит о том, что здесь размещены файлы, связанные с файлами, отправленными в ваш личный кабинет в «облако» Xiaomi (даже если вы этот кабинет и не создавали!). И они нужны для того, чтобы уменьшить время доступа для их просмотра (за счет кэширования). Возможно, что эти файлы могут использоваться и для просмотра изображений в Галерее. А большой объем файлов связан с тем, что система не удаляет из них сохраненные данные даже для тех изображений, которые вы удалили со своего смартфона.
Удаление этих файлов не сказалось на быстродействии устройства, а вот свободного места стало существенно больше. Понятно, что в процессе использования файлы в этой папке появятся снова, но вы уже знаете, что с ними можно делать.
Директивы файла robots.txt: синтаксис и инструкция по работе
Файл robots.txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет.
Директивы и инструкция по работе с robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
Полный список роботов Яндекс:
Синтаксис в robots.txt
Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
Пример #1
# Полностью закрывает весь сайт от индексации
Пример #2
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Пример #3
# Блокирует для скачивания страницу раздела /category2/
Пример #4
# Дает возможность сканировать весь сайт просто оставив поле пустым
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.
Allow
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
Пример #1
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site.ru/feed/.
Пример #2
# разрешает скачивание файла doc.xml
# разрешает скачивание файла doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
Пример
# Указывает карту сайта
Clean-param
Используется когда нужно указать Яндексу (в Google она не работает), что страница с GET-параметрами (например, site.ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
Пример #1
#robots.txt будет содержать:
Clean-param: s /forum/showthread.php
Пример #2
#robots.txt будет содержать:
Clean-param: sid /index.php
Подробнее о данной директиве можно прочитать здесь:
Crawl-delay
Важно! Данная директива не поддерживается в Яндексе с 22 февраля 2019 года и в Google 1 сентября 2019 года, но работает с другими роботами. Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Пример
# Допускает скачивание страницы лишь раз в 3 секунды
Как проверить работу файла robots.txt
В Яндекс.Вебмастер
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
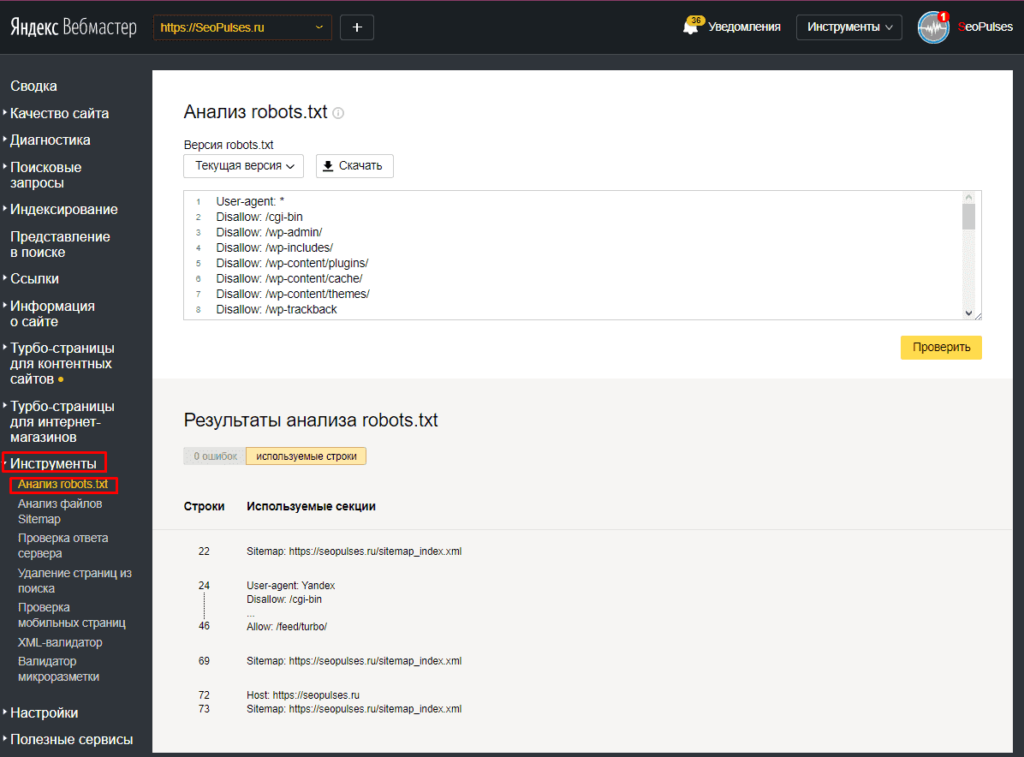
Также можно скачать другие версии файла или просто ознакомиться с ними.
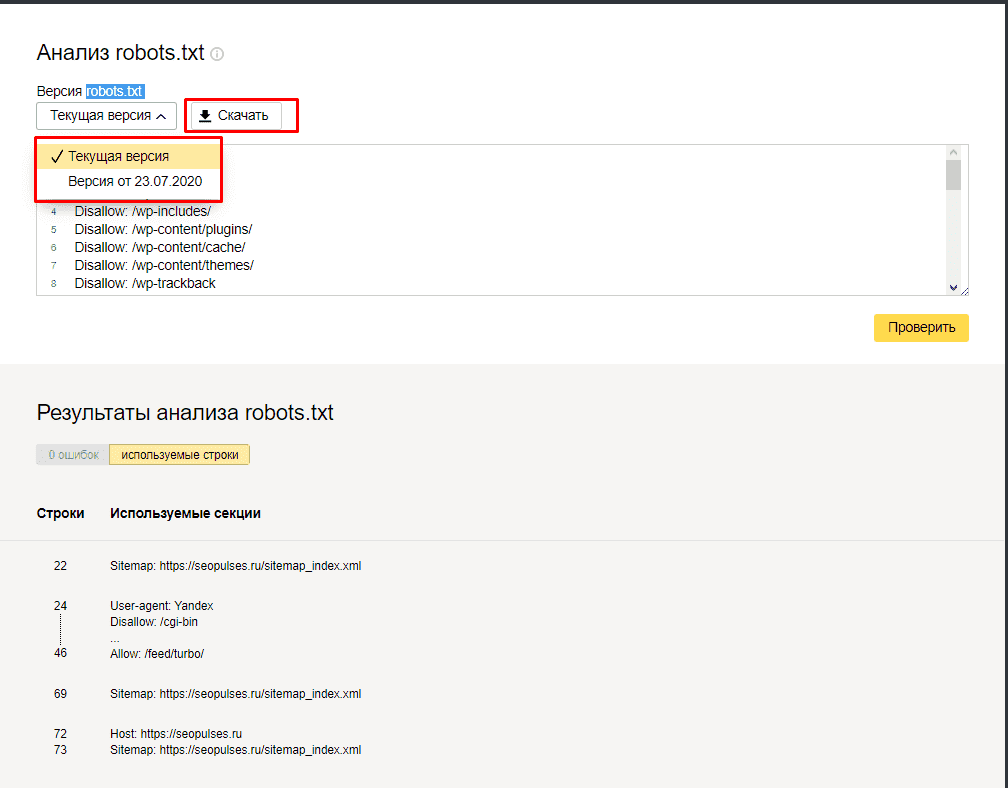
Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
В нашем случае мы проверяем эти правила.
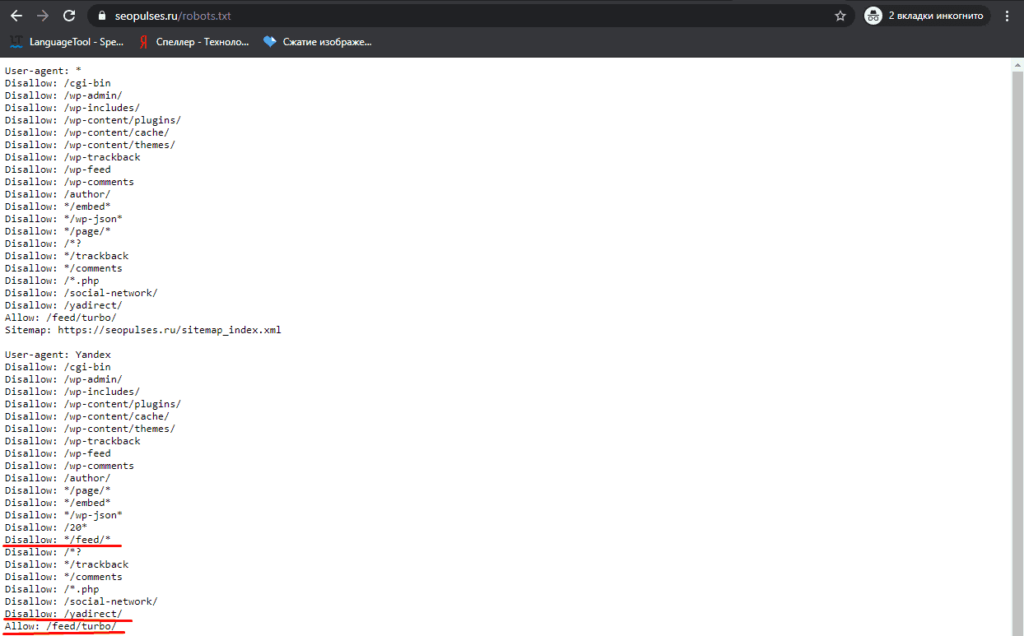
Как видим из примера все работает нормально.
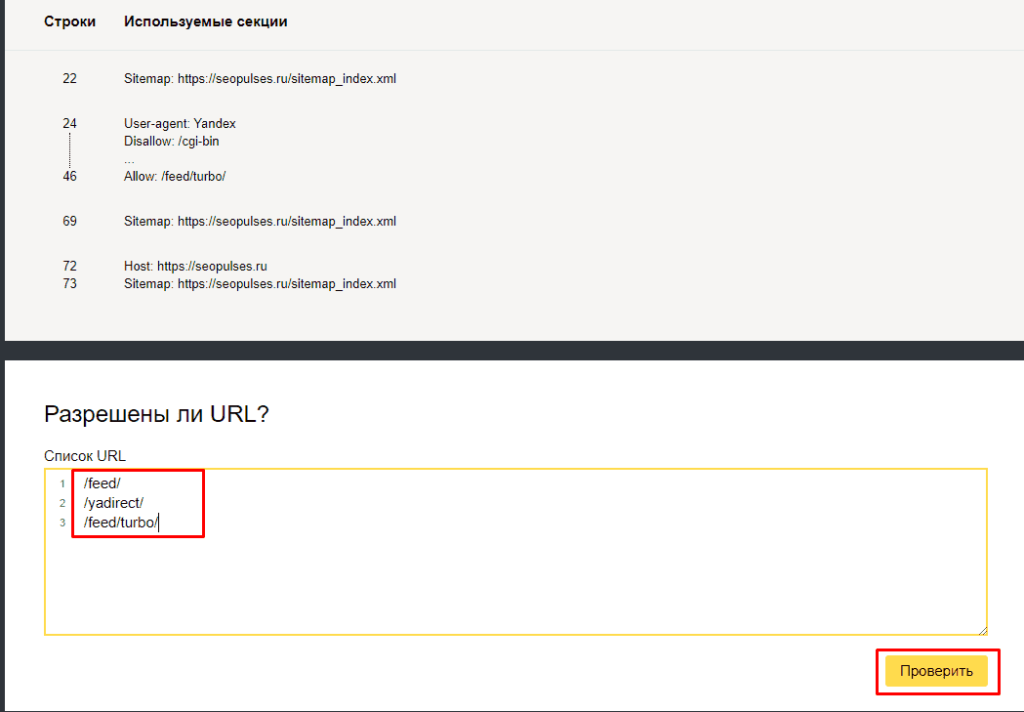
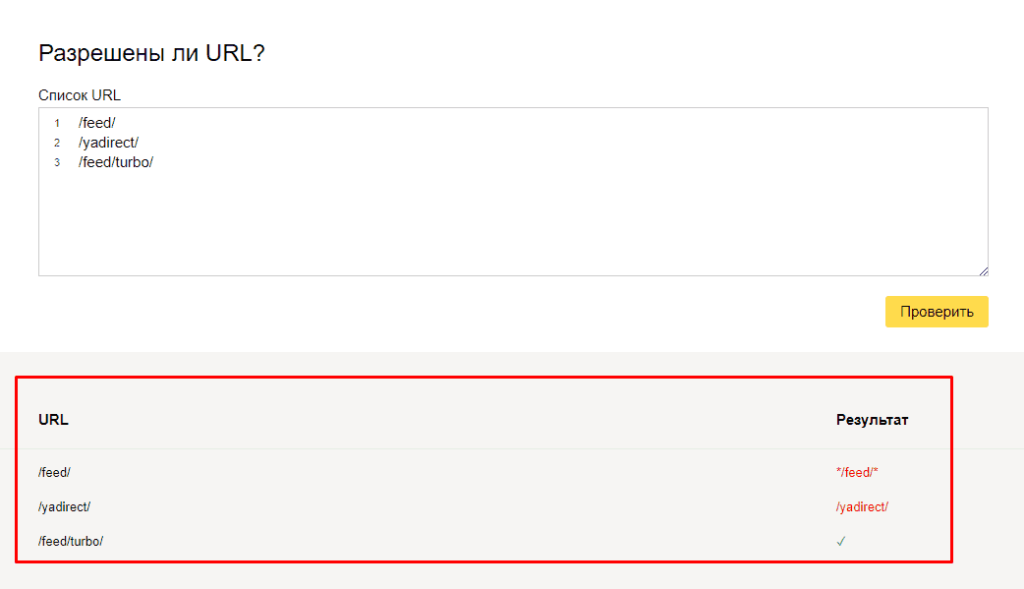
Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.
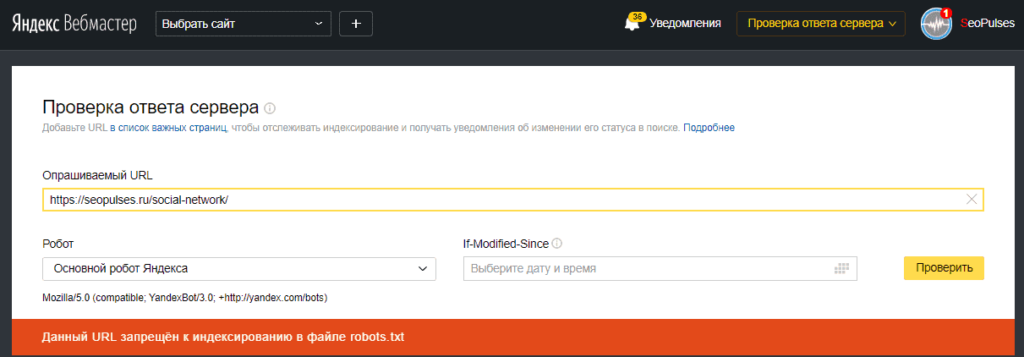
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
Важно! Ресурсы-домены в этом случае выбирать нельзя.
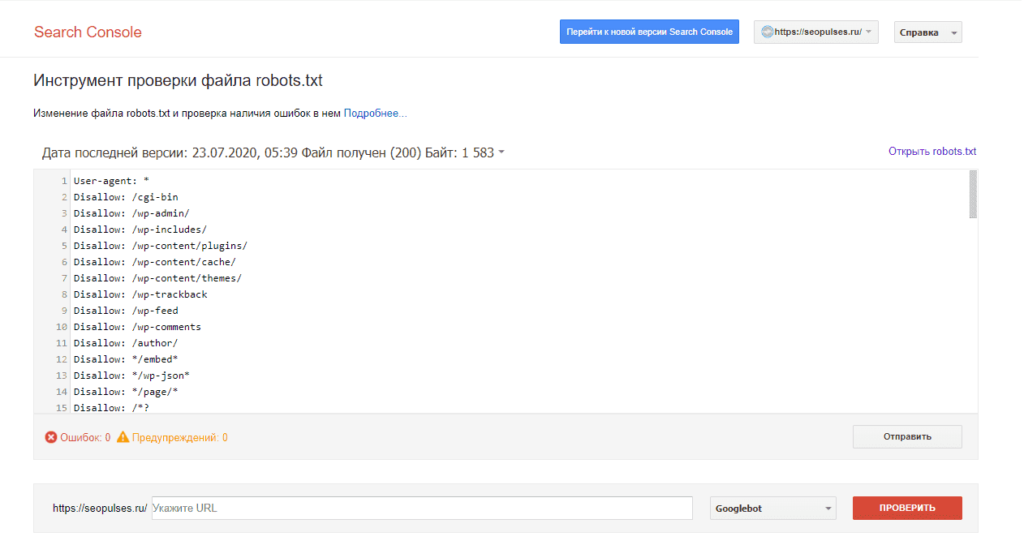
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
Что такое robots.txt [Основы для новичков]

Подробно о правилах составления файла в полном руководстве «Как составить robots.txt самостоятельно».
А в этом материале основы для начинающих, которые хотят быть в курсе профессиональных терминов.
Что такое robots.txt
Поисковый робот, придя к вам на сайт, первым делом пытается отыскать robots.txt. Если робот не нашел файл или он составлен неправильно, бот будет изучать сайт по своему собственному усмотрению. Далеко не факт, что он начнет с тех страниц, которые нужно вводить в поиск в первую очередь (новые статьи, обзоры, фотоотчеты и так далее). Индексация нового сайта может затянуться. Поэтому веб-мастеру нужно вовремя позаботиться о создании правильного файла robots.txt.
На некоторых конструкторах сайтов файл формируется сам. Например, Wix автоматически создает robots.txt. Чтобы посмотреть файл, добавьте к домену «/robots.txt». Если вы увидите там странные элементы типа «noflashhtml» и «backhtml», не пугайтесь: они относятся к структуре сайтов на платформе и не влияют на отношение поисковых систем.
Зачем нужен robots.txt
Казалось бы, зачем запрещать индексировать какое-то содержимое сайта? Далеко не весь контент, из которого состоит сайт, нужен поисковым роботам. Есть системные файлы, есть дубликаты страниц, есть рубрики ключевых слов и много чего еще есть, что вовсе не обязательно индексировать. Есть одно но:
Содержимое файла robots.txt — это рекомендации для ботов, а не жесткие правила. Рекомендации боты могут проигнорировать.
Google предупреждает, что через robots.txt нельзя заблокировать страницы для показа в Google. Даже если вы закроете доступ к странице в robots.txt, если на какой-то другой странице будет ссылка на эту, она может попасть в индекс. Лучше использовать и ограничения в robots, и другие методы запрета:
Тем не менее, без robots.txt больше вероятность, что информация, которая должна быть скрыта, попадет в выдачу, а это бывает чревато раскрытием персональных данных и другими проблемами.
Из чего состоит robots.txt
Файл должен называться только «robots.txt» строчными буквами и никак иначе. Его размещают в корневом каталоге — https://site.com/robots.txt в единственном экземпляре. В ответ на запрос он должен отдавать HTTP-код со статусом 200 ОК. Вес файла не должен превышать 32 КБ. Это максимум, который будет воспринимать Яндекс, для Google robots может весить до 500 КБ.
Внутри все должно быть на латинице, все русские названия нужно перевести с помощью любого Punycode-конвертера. Каждый префикс URL нужно писать на отдельной строке.
В robots.txt с помощью специальных терминов прописываются директивы (команды или инструкции). Кратко о директивах для поисковых ботах:
«Us-agent:» — основная директива robots.txt
Используется для конкретизации поискового робота, которому будут давать указания. Например, User-agent: Googlebot или User-agent: Yandex.
В файле robots.txt можно обратиться ко всем остальным поисковым системам сразу. Команда в этом случае будет выглядеть так: User-agent: *. Под специальным символом «*» принято понимать «любой текст».
После основной директивы «User-agent:» следуют конкретные команды.
Команда «Disallow:» — запрет индексации в robots.txt
При помощи этой команды поисковому роботу можно запретить индексировать веб-ресурс целиком или какую-то его часть. Все зависит от того, какое расширение у нее будет.
Такого рода запись в файле robots.txt означает, что поисковому роботу Яндекса вообще не позволено индексировать данный сайт, так как запрещающий знак «/» не сопровождается какими-то уточнениями.
На этот раз уточнения имеются и касаются они системной папки wp-admin в CMS WordPress. То есть индексирующему роботу рекомендовано отказаться от индексации всей этой папки.
Команда «Allow:» — разрешение индексации в robots.txt
Антипод предыдущей директивы. При помощи тех же самых уточняющих элементов, но используя данную команду в файле robots.txt, можно разрешить индексирующему роботу вносить нужные вам элементы сайта в поисковую базу.
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено.
На практике «Allow:» используется не так уж и часто. В ней нет надобности, поскольку она применяется автоматически. В robots «разрешено все, что не запрещено». Владельцу сайта достаточно воспользоваться директивой «Disallow:», запретив к индексации какое-то содержимое, а весь остальной контент ресурса воспринимается поисковым роботом как доступный для индексации.
Директива «Sitemap:» — указание на карту сайта
« Sitemap:» указывает индексирующему роботу правильный путь к так Карте сайта — файлам sitemap.xml и sitemap.xml.gz в случае с CMS WordPress.
Прописывание команды в файле robots.txt поможет поисковому роботу быстрее проиндексировать Карту сайта. Это ускорит процесс попадания страниц ресурса в выдачу.
Файл robots.txt готов — что дальше
Итак, вы создали текстовый документ robots.txt с учетом особенностей вашего сайта. Его можно сделать автоматически, к примеру, с помощью нашего инструмента.
«Вкалывают роботы»: что такое robots.txt и как его настроить

Знание о том, что такое robots.txt, и умение с ним работать больше относится к профессии вебмастера. Однако SEO-специалист — это универсальный мастер, который должен обладать знаниями из разных профессий в сфере IT. Поэтому сегодня разбираемся в предназначении и настройке файла robots.txt.
По факту robots.txt — это текстовый файл, который управляет доступом к содержимому сайтов. Редактировать его можно на своем компьютере в программе Notepad++ или непосредственно на хостинге.
Что такое robots.txt
Представим robots.txt в виде настоящего робота. Когда в гости к вашему сайту приходят поисковые роботы, они общаются именно с robots.txt. Он их встречает и рассказывает, куда можно заходить, а куда нельзя. Если вы дадите команду, чтобы он никого не пускал, так и произойдет, т.е. сайт не будет допущен к индексации.
Если на сайте нет этого файла, создаем его и загружаем на сервер. Его несложно найти, ведь его место в корне сайта. Допишите к адресу сайта /robots.txt и вы увидите его.
Зачем нам нужен этот файл
Если на сайте нет robots.txt, то роботы из поисковых систем блуждают по сайту как им вздумается. Роботы могут залезть в корзину с мусором, после чего у них создастся впечатление, что на вашем сайте очень грязно. robots.txt скрывает от индексации:
Правильно заполненный файл robots.txt создает иллюзию, что на сайте всегда чисто и убрано.
Настройка директивов robots.txt
Директивы — это правила для роботов. И эти правила пишем мы.
User-agent
Пример:
Данное правило смогут понять только те роботы, которые работают в Яндексе. В последнее время эту строчку я заполняю так:
Правило понимает Яндекс и Гугл. Доля трафика с других поисковиков очень мала, и продвигаться в них не стоит затраченных усилий.
Disallow и Allow
С помощью Disallow мы скрываем каталоги от индексации, а, прописывая правило с директивой Allow, даем разрешение на индексацию.
Пример:
Даем рекомендацию, чтобы индексировались категории.
А вот так от индексации будет закрыт весь сайт.
Также существуют операторы, которые помогают уточнить наши правила.
Sitemap
Пример:
Директива host уже устарела, поэтому о ней говорить не будем.
Crawl-delay
Если сайт небольшой, то директиву Crawl-delay заполнять нет необходимости. Эта директива нужна, чтобы задать периодичность скачивания документов с сайта.
Пример:
Это правило означает, что документы с сайта будут скачиваться с интервалом в 10 секунд.
Clean-param
Директива Clean-param закрывает от индексации дубли страниц с разными адресами. Например, если вы продвигаетесь через контекстную рекламу, на сайте будут появляться страницы с utm-метками. Чтобы подобные страницы не плодили дубли, мы можем закрыть их с помощью данной директивы.
Пример:
Как закрыть сайт от индексации
Чтобы полностью закрыть сайт от индексации, достаточно прописать в файле следующее:
Если требуется закрыть от поисковиков поддомен, то нужно помнить, что каждому поддомену требуется свой robots.txt. Добавляем файл, если он отсутствует, и прописываем магические символы.
Проверка файла robots
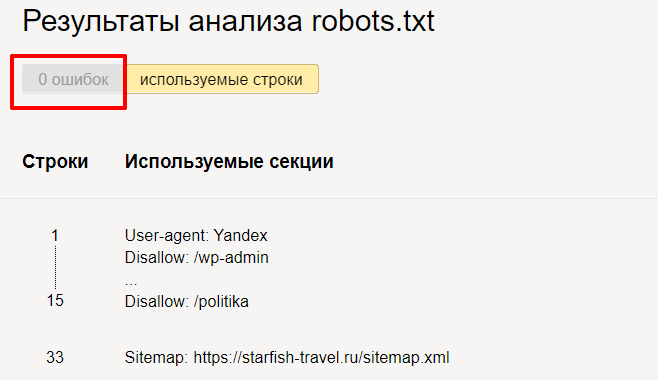
Переходим в инструмент, вводим домен и содержимое вашего файла.

Нажимаем « Проверить » и получаем результаты анализа. Здесь мы можем увидеть, есть ли ошибки в нашем robots.txt.
Но на этом функции инструмента не заканчиваются. Вы можете проверить, разрешены ли определенные страницы сайта для индексации или нет.
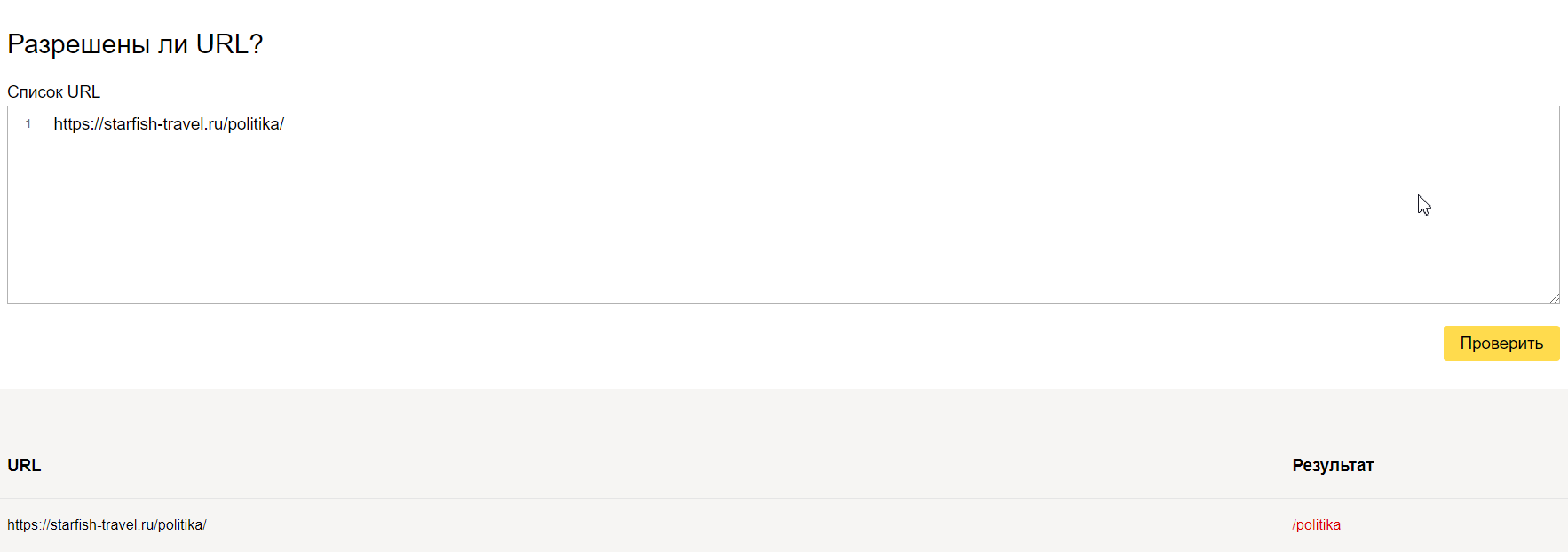
Здесь вас ждет простор для творчества. Пользуйтесь звездочкой или знаком доллара и закрывайте от индексации страницы, которые не несут пользы для посетителей. Будьте внимательны – проверяйте, не закрыли ли вы от индексации важные страницы.
Правильный robots.txt для WordPress
Кстати, если вы поставите #, то сможете оставлять комментарии, которые не будут учитываться роботами.
Правильный robots.txt для Joomla
Здесь указаны другие названия директорий, но суть одна: закрыть мусорные и служебные страницы, чтобы показать поисковиками только то, что они хотят увидеть.



