Среднее значение, медиана и мода
Эти три термина являются основными показателями в статистическом анализе. Если 20 лет назад в нашей стране они интересовали только экономистов и работников статистики, то теперь почти каждый, кто имеет хоть какое-либо отношение к коммерции, следит за этими данными. Это работники банковского сектора, торговли, сервиса о больше всех брокеры.
Но в этой статье мы не будем подробно объяснять каждый из этих терминов. Их достаточно распиарили и без нас. Вместо этого остановимся на объяснении этих трех терминов: среднее значение, медиана и мода. Все три термина объясним с примерами.
Среднее значение
Часто так называют среднеарифметическое значение выборки (или множества чисел). Это, пожалуй, самый распространенный термин, из вышеперечисленных трех. Хотя бы потому, что почти каждый день мы слышим это слово в СМИ. Значение его тоже объясняет само название. Тем не менее, для тех, кому непонятен смысл этого слова, объясним “на пальцах”.
Это сумма данных чисел, деленное на количество. Если написать в виде формулы, это выглядит так.
Пример из практики
Медиана
Медиана – число, характеризующее выборку, т.е. если взять все элементы множества, то это число ровно делит множество пополам. Одна половина множества равна или больше этого число, а другая меньше или равна этому числу.
Пример из практики
Значит, среднее значение в год составляет
$(1,000,000 + 200,000 + 8,900) : 100 = 1,208,900 : 100 = 12,089$ у.е.
Зная соотношение неработающих людей, на каждого работающего, и поделив полученное на это число, получим доход на душу населения (с учетом детей, стариков и больных без пенсии).
Итак, такая статистика показывает, что народ живет припеваючи, зарабатывая примерно 1,000 у.е. в месяц, а действительность другая. Как раз, так и вычисляется доход на душу населения. Берется национальный доход и делится на численность населения. Теперь вы понимаете, почему в сводках всегда называют эту цифру, потому что она никоим образом не отображает благосостояние большинства, а только является показателем экономического благосостояния страны.
Пример из практики
Если постоять на проспекте и в течение 10 минут и посчитать все проезжающие автомобили и классифицировать их по цветам, то можно определить моду для цвета автомобилей этого города. Допустим, насчитали 95 белых, 45 черных, 12 красных, 38 серых и 70 других цветов. Значит, модой в этом городе являются автомобили белого цвета. Это хорошая информация для дистрибьюторов автомобилей.
Подробнее о среднем значении
Иногда вычисляют среднее значение для группы данных. Тогда значения разбивают на группы и вычисляют серединную точку каждой группы. Затем эти значения умножают на количество членов каждой группы (на частотность) и складывают. А результат делят на общее количество. Такое значение называют средним значением группы. Посмотрите на этот пример:
| Группа | Частота | Середина |
|---|---|---|
| 1-20 | 5 | 10.5 |
| 21-40 | 25 | 30.5 |
| 41-60 | 37 | 50.5 |
| 61-80 | 23 | 70.5 |
Умножаем эти значения на частоты и складываем, затем делим на общее количество:
Как уже показали на примере с доходом населения, экстремумы сильно влияют на среднеарифметическое значение, поэтому иногда полезно их отбрасывать. Тогда среднее значение называется урезанным средним.
В симметричном распределении (типа нормального распределения) среднее значение, медиана и мода равны или близки друг другу. В асимметричном же, они отличаются, и число, на которое отличаются эти показатели, дают информацию о “скошенности” распределения относительно нормального.
Надеемся, что нам удалось “на пальцах” объяснить значение терминов среднеарифметическое значение, медиана и мода. Если кто-то из Ваших знакомых до сих пор в недоумении, просвещайте их, поделившись данной статьей в соц. сетях.
Читайте также

Переменные потока и запасы
Все экономические переменные, которые имеют временное измерение, т.е. величины которых можно измерить по истечении времени называем переменными потока. А запас не имеет временное измерение.
Показатели вариации
Чтобы знать, насколько далеко значение совокупности простирается от центральной тенденции, вычисляют вариацию (на английском dispersion или variability, но не путайте с variation). Есть несколько показателей вариации. Это размах, межквартильный размах, среднее линейное отклонение, дисперсия и стандартное отклонение.
Типы выборки
Для расследования генеральной совокупности применяют два вида выборки. Случайную и неслучайную выборку. Простая, систематическая, стратифицированная и кластерная выборка являются случайными выборками. Стихийная, удобная и квотная выборка являются примером неслучайной выборки.

Скользящее среднее значение
Среди наиболее популярных технических индикаторов чаще всего, скользящее среднее значение используются для измерения направления текущего тренда. Самая простая формула скользящей средней, известна как Простое Скользящее Среднее значение.
Генеральная совокупность и выборка
Генеральной совокупностью называют всё исследуемое множество. На английском языке этот термин называется популяцией (population). Выборкой (на английском sample) называют некоторое случайно отобранное подмножество из генеральной совокупности.
Нулевая гипотеза
Нулевая гипотеза утверждает, что между исследуемыми данными никакой закономерности нет. Пока нулевая гипотеза не опровергнута, она в силе. Альтернативная гипотеза является обратной нулевой гипотезе.

Типы данных в статистике
Такие выражения, как минимум, максимум, медиана и процентиль имеют значение лишь для порядковых данных. Порядковые данные делятся на метрические и неметрические.

Что такое тренд?
Термины тренд и тенденция используются в различных целях. Люди часто говорят о тенденции относительно роста цен и падения курса какой-то валюты. Здесь мы раскроем статистическое значение этих терминов.
Ошибка репрезентативности
Стандартная ошибка (standard error) и ошибка репрезентативности часто употребляются, как взаимозаменяемые термины. Ошибка репрезентативности показывает, насколько результаты, полученные при выборочном наблюдении отличаются от результатов, полученных при исследовании генеральной совокупности.
Медиана в статистике
Медиана – середина упорядоченного ряда. Медиана делит этот ряд пополам таким образом, что в одной половине стоят все значения меньшие, а в другой все значения большие медианы.
© Все права защищены
Все статьи этого сайта написаны Джафаром Н.Алиевым. Перепечатывание любой статьи на стороннем ресурсе должно сопровождаться именем автора и ссылкой на данный ресурс. Сам автор следует этим правилам.
4 День 3. Описательная статистика и визуализация
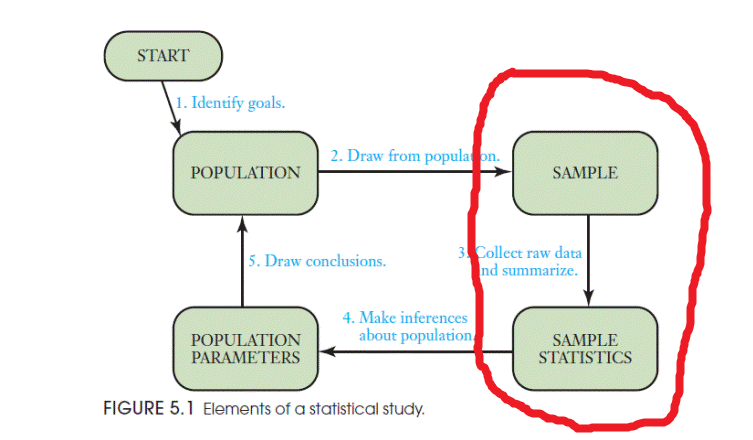
4.1 Описательная статистика
Заметьте, у выборки (sample) мы считаем статистики (statistics), а у генеральной совокупности (Population) есть параметры (Parameters). Вот такая вот мнемотехника.
“This data is from the Mayo Clinic trial in primary biliary cirrhosis (PBC) of the liver conducted between 1974 and 1984. A total of 424 PBC patients, referred to Mayo Clinic during that ten-year interval, met eligibility criteria for the randomized placebo controlled trial of the drug D-penicillamine. The first 312 cases in the data set participated in the randomized trial and contain largely complete data.”
Эти данные часто используются в качестве примера для анализа выживаемости. Они уже в достаточно упорядоченном виде и не нуждаются в предобработке (что, к сожалению, случай малореалистичный).
Пока что мы будем использовать только данные о возрасте испытуемых. Для краткости обозначим это вектором a
4.1.1 Меры центральной тенденции
4.1.1.1 Арифметическое среднее
4.1.1.2 Медиана
Разница медианы со средним не очень существенная. Это значит, что распределение довольно “симметричное”. Но бывает и по-другому.
Представьте себе, что кто-то говорит про среднюю зарплату в Москве. Но ведь эта средняя зарплата становится гораздо больше, если учитывать относительно небольшое количество мультимиллионеров и миллиардеров! А вот медианная зарплата будет гораздо меньше.
Представьте себе, что в эту клинику с циррозом печени пришел 8000-летний Король Ночи из Игры Престолов. Тогда арифметическое среднее станет гораздо больше:
А вот медиана останется почти той же.
Таким образом, экстремально большие или маленькие значения оказывают сильное влияние на арифметическое среднее, но не на медиану. Поэтому медиана считается более “робастной” оценкой, т.е. более устойчивой к выбросам и крайним значениям.
4.1.1.3 Усеченное среднее (trimmed mean)
Если про среднее и медиану слышали все, то про усеченное (тримленное) среднее известно гораздо меньше. Тем не менее, на практике это довольно удобная штука, потому что представляет собой некий компромисс между арифметическим средним и медианой.
В усеченном среднем значения ранжируются так же, как и для медианы, но отбрасывается только какой-то процент крайних значений. Усеченное среднее можно посчитать с помощью обычной функции mean(), поставив нужное значение параметра trim = :
4.1.1.4 Мода
4.1.2 Меры рассеяния
Начинающий статистик пытался перейти в брод реку, средняя глубина которой 1 метр. И утонул.
В чем была его ошибка? Он не учитывал разброс значений глубины!
Мер центральной тенденции недостаточно, чтобы описать выборку. Необходимо знать ее вариабельность.
4.1.2.1 Размах
Осталось посчитать разницу между ними:
Естественно, крайние значения очень сильно влияют на этот размах, поэтому на практике он не очень-то используется.
4.1.2.2 Дисперсия
Дисперсия (variance) вычисляется по следующей формуле:
4.1.2.3 Стандартное отклонение
Если вы заметили, значение дисперсии очень большое. Чтобы вернуться к единицам измерения, соответствующих нашим данным используется корень из дисперсии, то есть стандартное отклонение (standard deviation):
Для этого есть функция sd() :
Что то же самое, что и:
4.1.2.4 Медианное абсолютное отклонение
\[mad= median(|x_ — median(x)|)\]
Для этого есть функция mad() :
4.1.2.5 Межквартильный размах
4.1.3 Ассиметрия и эксцесс
4.1.3.1 Ассиметрия
Ассиметрия (skewness) измеряет симметричность распределения. Положительный показатель ассиметрии (“Right-skewed” или positive skewness) означает, что хвосты с правой части распределения длиннее. Негативный показатель ассиметрии (“Left-skewed” или negative skewness) означает, что левый хвост длиннее.
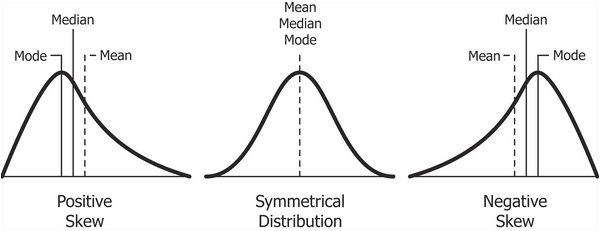
4.1.3.2 Эксцесс
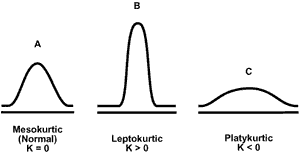
4.1.3.3 Ассиметрия и эксцесс в R
К сожалению, в базовом R нет функций для ассиметрии и эксцесса. Зато есть замечательный пакет psych (да-да, специально для психологов).
В нем есть функции skew() и kurtosi() :
4.1.4 А теперь все вместе!
Даже усеченное (trimmed) среднее есть (с trim = 0.1 )! Все кроме se мы уже знаем. А про этот se узнаем через позже.
Эта функция прекрасно работает в data.table в сочетании с by = :
4.1.5 Описательных статистик недостаточно
Я в тайне от Вас загрузил данные в переменную xxx (можете найти этот набор данных здесь, если интересно). Выглядят они примерно так:
Применим разные функции, которые мы выучили:
Похоже, расброс по у несколько больше, верно?
Похоже, оба распределения немного право-ассиметричны и довольно “плоские”.
Корреляция очень близка к нулю (делайте выводы и представляйте).
Давайте напоследок воспользуемся функцией describe() из psych:
Готовы узнать, как выглядят эти данные на самом деле?!
Жмите сюда если готовы!
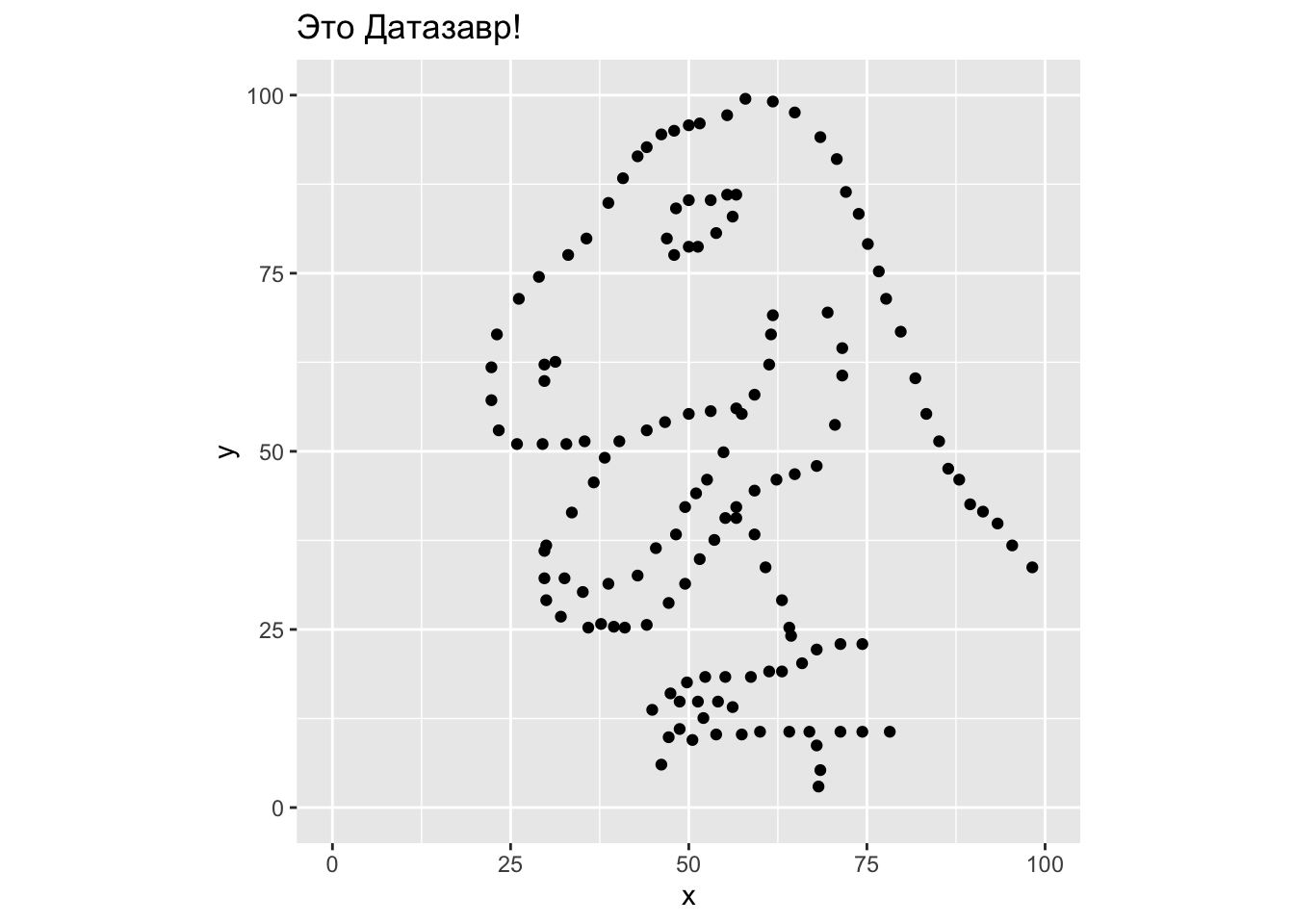
Из этого можно сделать важный вывод: не стоит слепо доверять описательным статистикам. Нужно визуализировать данные, иначе можно попасть в такую ситуацию в реальности. Все следующее занятие будет посвящено визуализации данных.
4.2 Визуализация данных в R
4.2.1 Базовые функции для графики
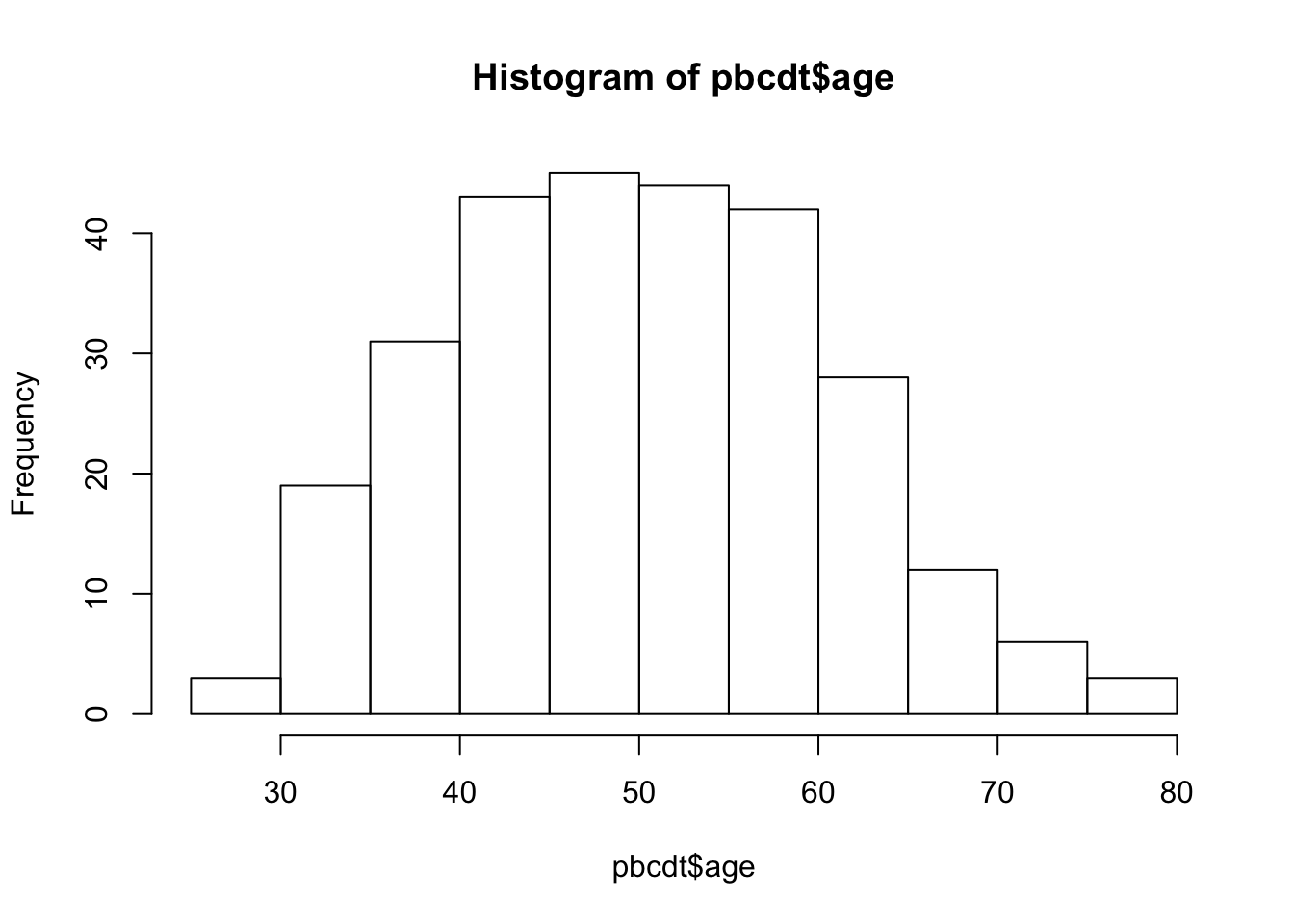
Для примера возьмем из дататейбла pbcdt уровень холистерина и возраст:
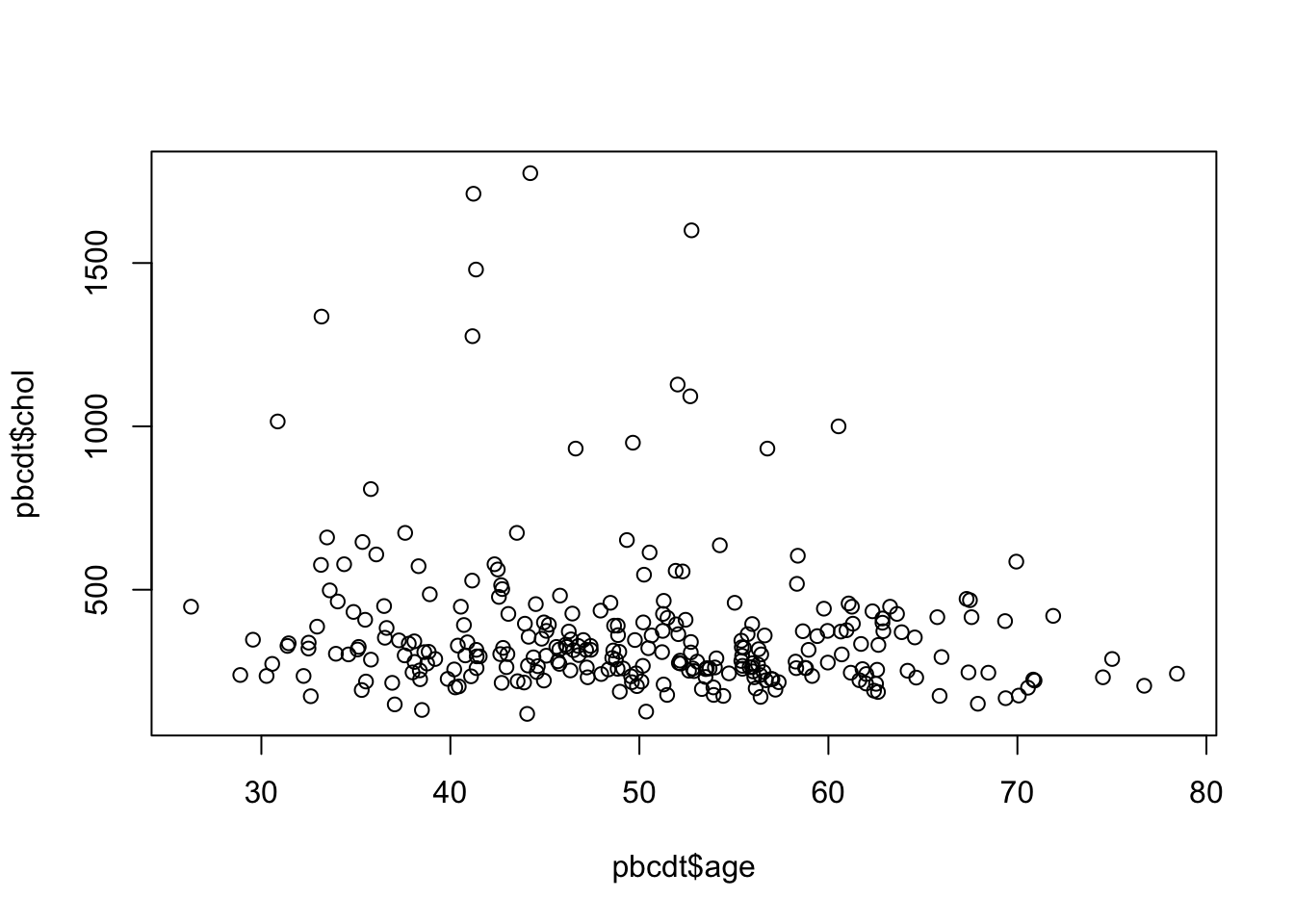
Ну и закончим на суперзвезде прошлого века под названием “ящик с усами”(boxplot with whiskers):
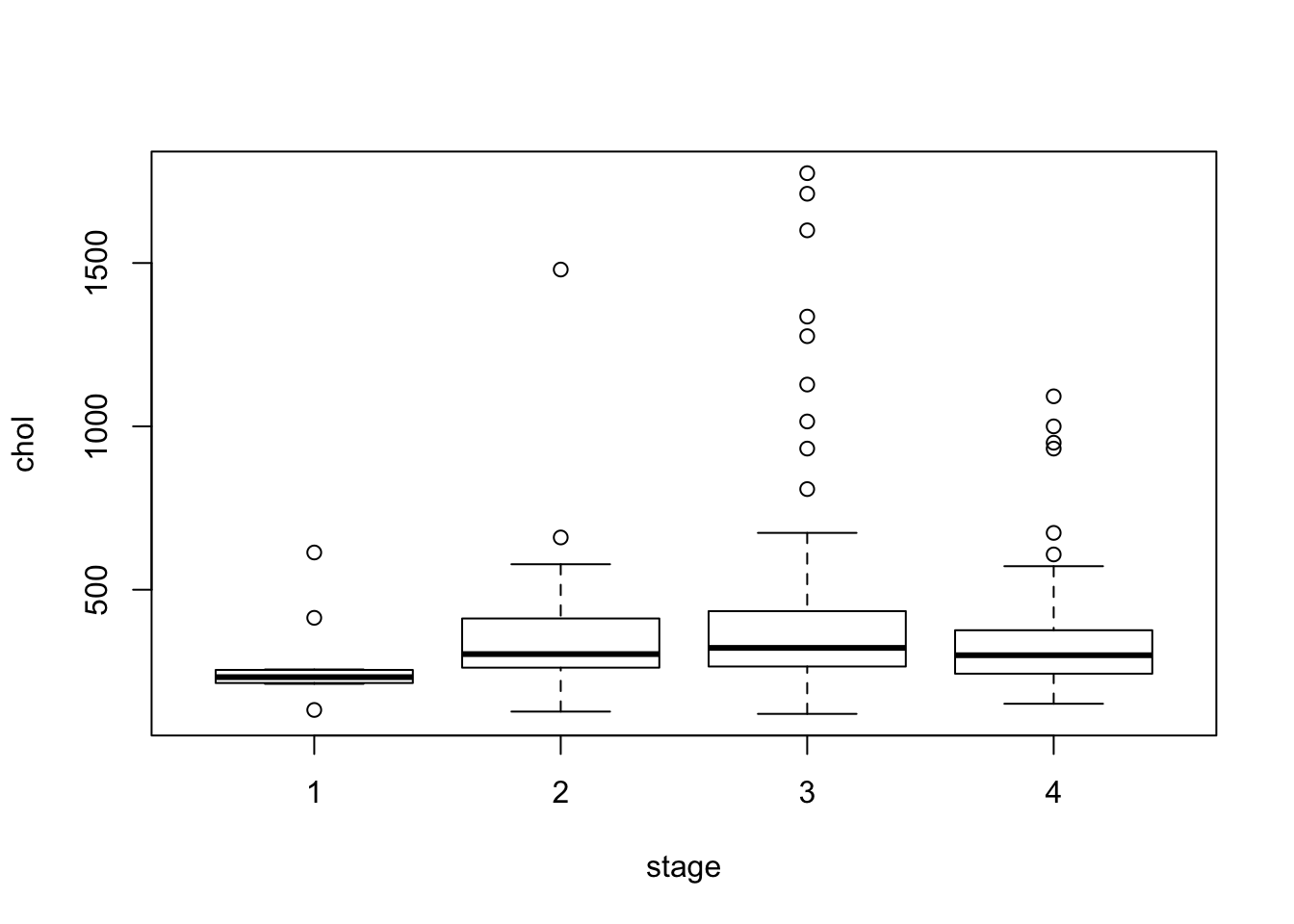
Здесь мы использовали уже знакомый нам класс формул. Они еще будут нам встречаться дальше, обычно они используются следующим образом: слева от
4.2.2 ggplot2
4.2.2.1 Layered Grammar of Graphics
Основные элементы Layered Grammar of Graphics
4.2.2.2 Пример 0: Круговая диаграмма
Чтобы продемонстрировать суть “графической грамматики” Уилкинсон в своей книге приводит в качестве примера круговую диаграмму. Да-да, тот самый злополучный пирог, которым все так плюются! Тем не менее, этот пример перевернет Ваше понимание графиков с ног на голову.
Итак, создадим объект ggplot с данными и каким-нибудь мэппингом по умолчанию (пока не обращайте внимания на него). Если мы попробуем это отрисовать, то получим пустой экран.

Как нам из этого получить круговую диаграмму? Надо поменять декартову систему координат на полярную (круговую)!
В качестве финального штриха мы можем максимально упростить тему:
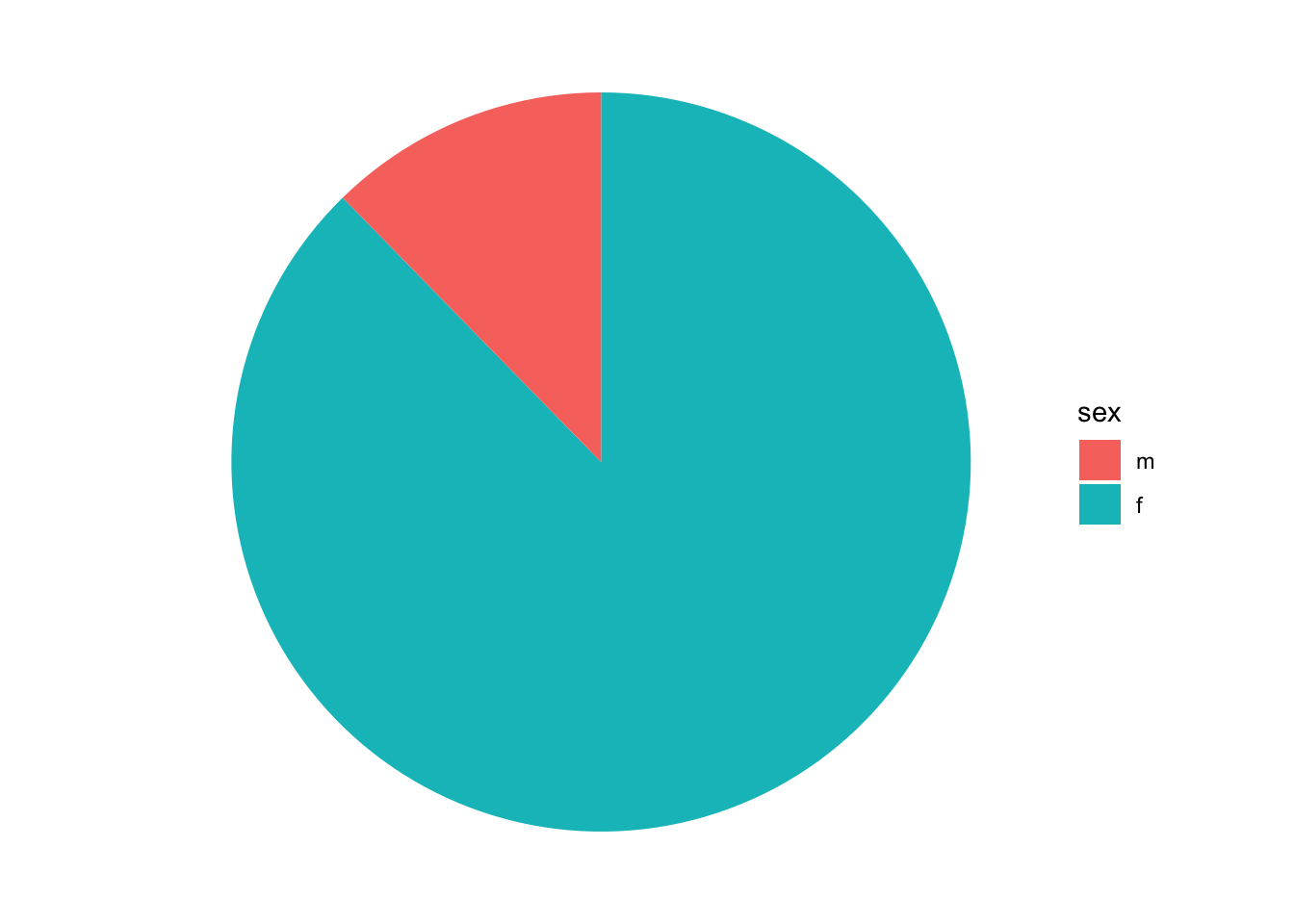
То есть пай-чарт можно рассматривать не как отдельный вид графика, а как столбчатую диаграмму в полярной системе координат. То же верно и для многих других графиков, которые можно представить с помощью ограниченного количества геомов и других элементов грамматики графики. Подумайте над этим!
4.2.2.3 Пример 1: Диаграмма рассеяния
Для начала создадим объект ggplot с помощью ggplot() команды. Для нее можно указать данные и мэппинг по умолчанию с помощью аргументов data = и mapping = aes()
В качестве примера мы сделаем диаграмму рассеяния с возрастом по х и уровнем холестирина по у:
На самом деле, название параметров data = и mapping = можно опустить.
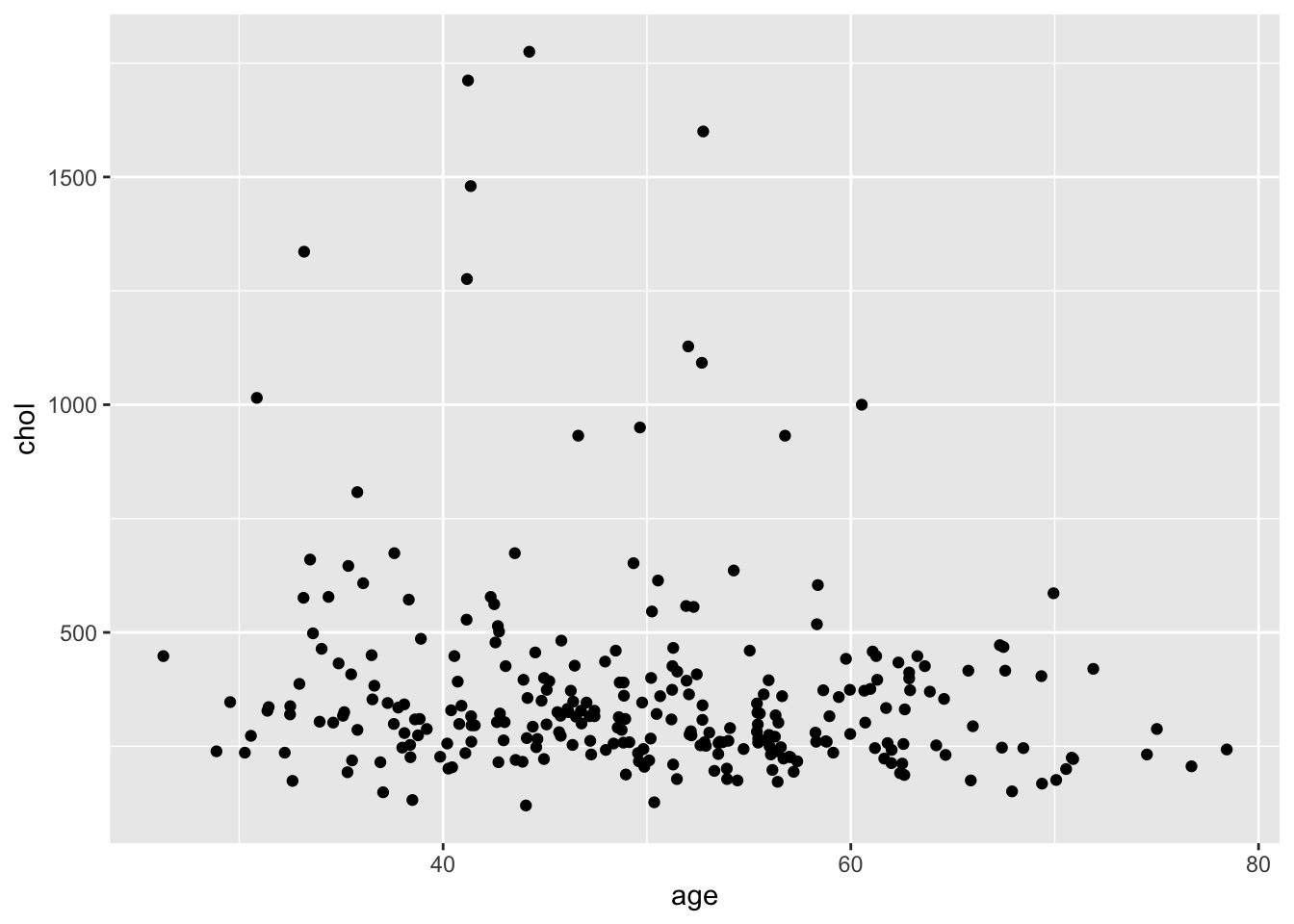
4.2.2.3.1 Фиксированные параметры vs mapping aesthetics
Теперь нам хотелось бы как-то разнообразить график. Изменить цвет, форму, размер точек:
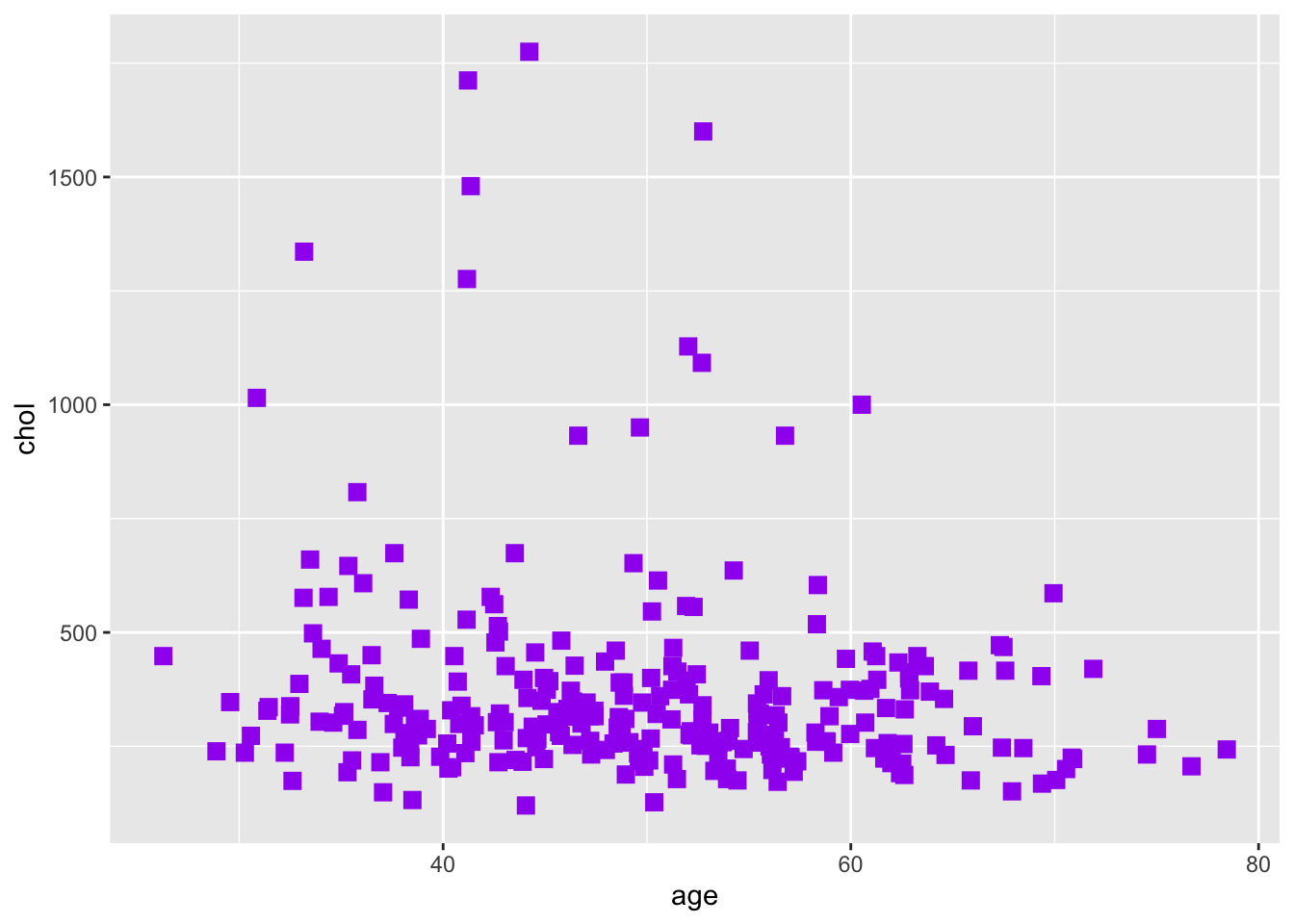
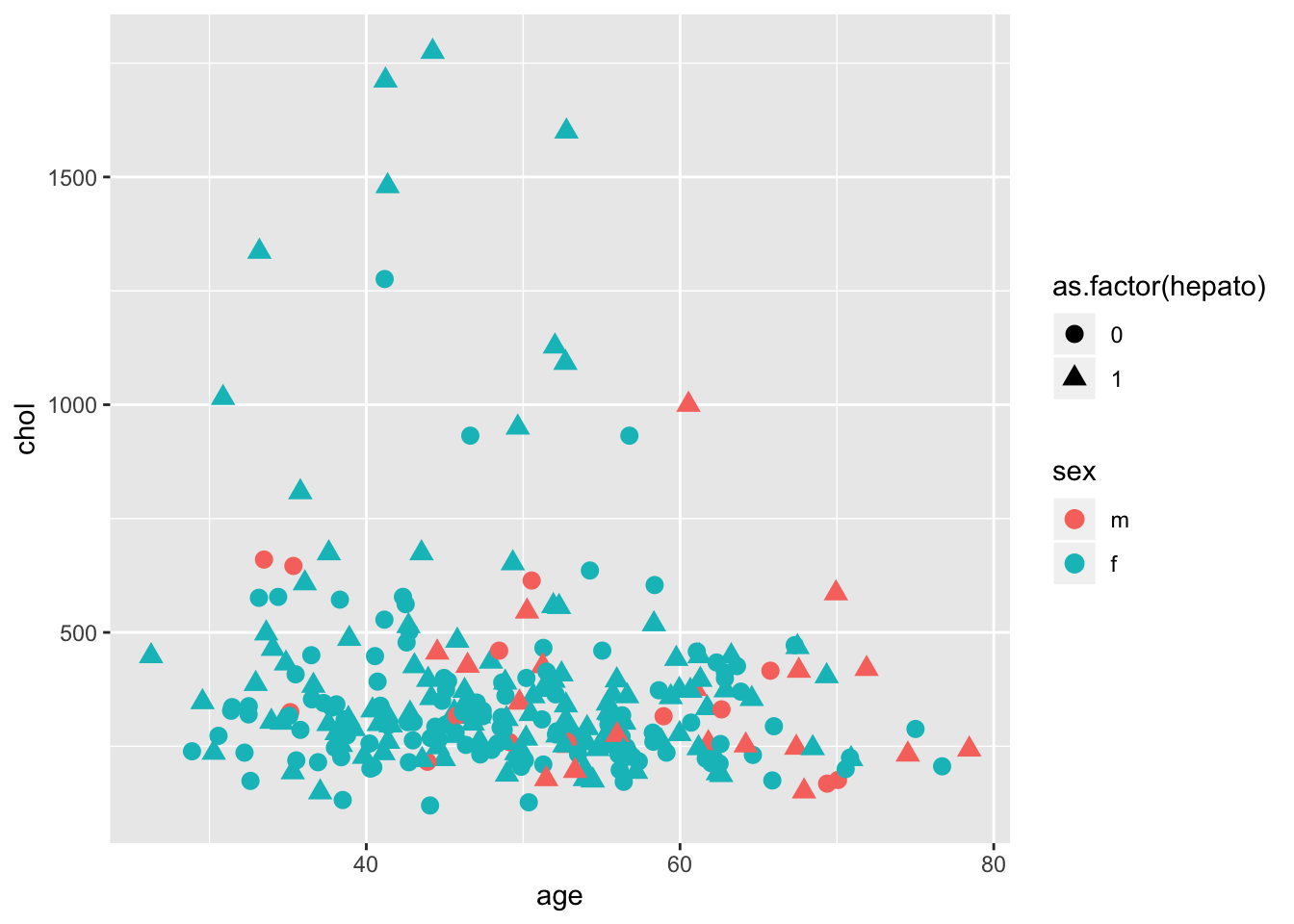
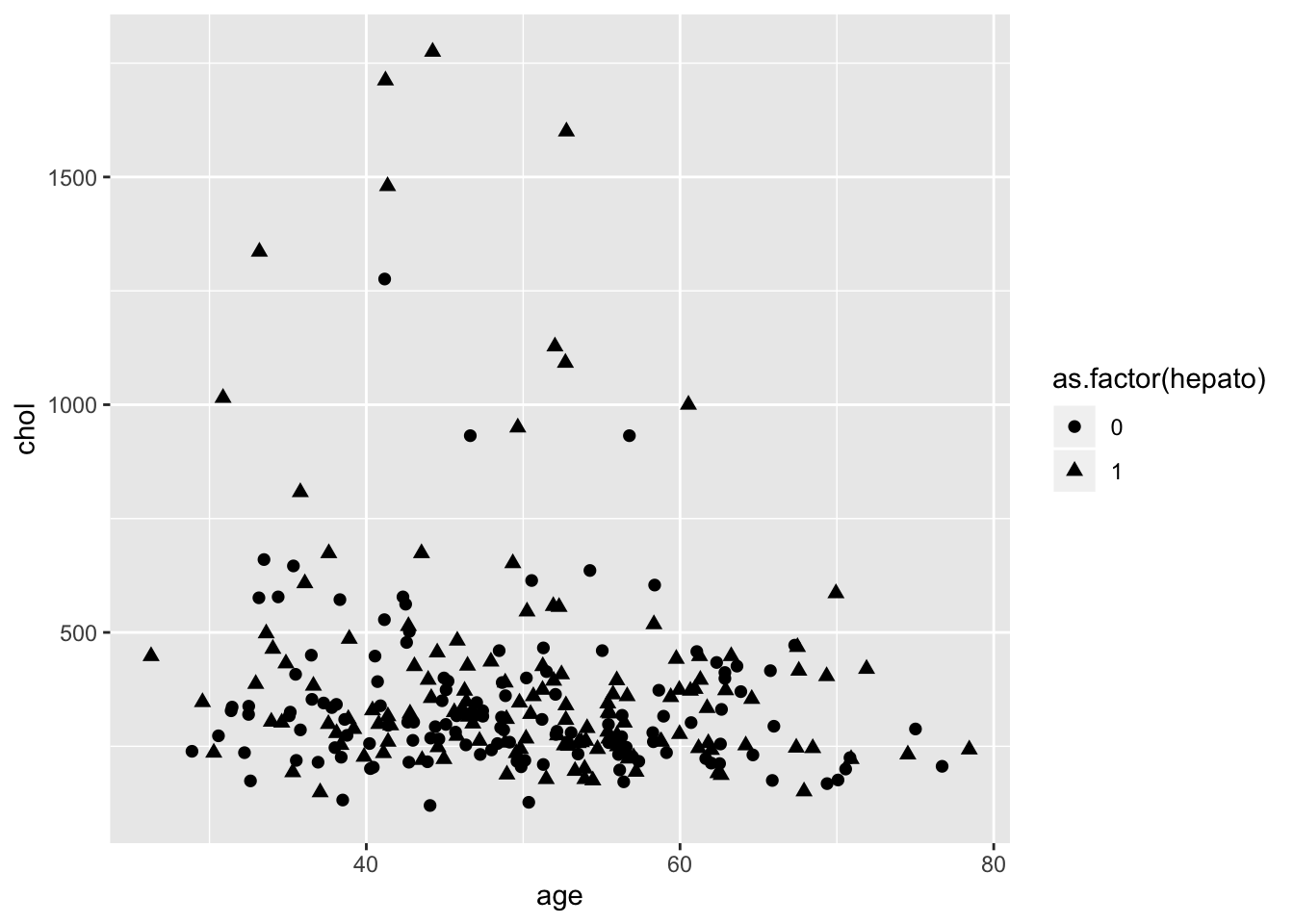
У использования цветов на графиков есть 3 основные функции:
Для различения групп
Для кодирования информации
Если на диаграмме рассеяния у нас есть и мэппинг формы, и мэппинг цвета, то победа будет за цветом, причем обычно с большим перевесом. Разные формы будут только отвлекать, поэтому и смысла в них особого не будет. Впрочем, при достаточно большом количестве точек даже при одинаковом цвете формы точек дадут какое-то представление только если эти точки довольно сильно обособляются в отдельные паттерны.
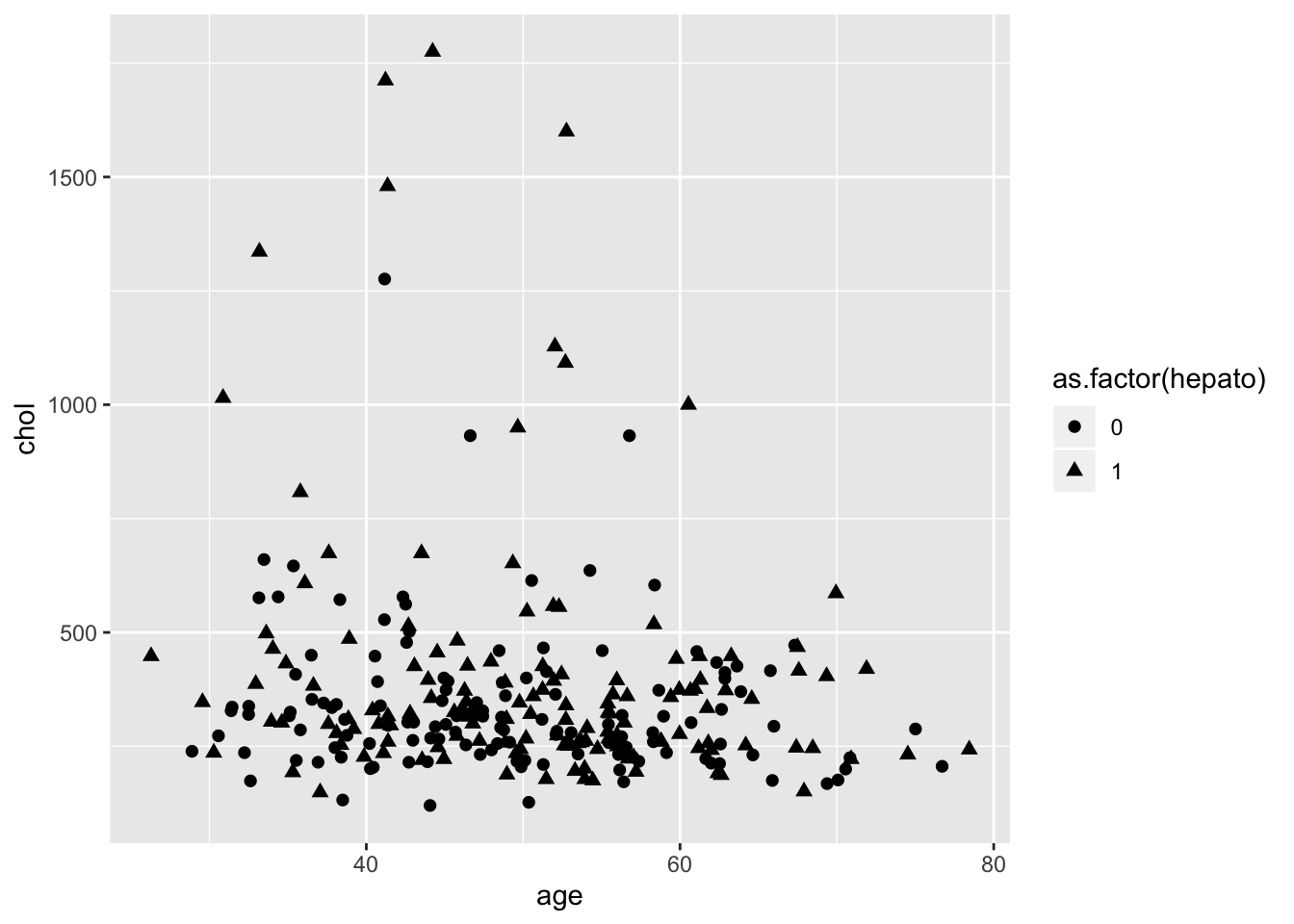
4.2.2.3.2 Overplotting и position
Данная проблема получила название оверплоттинга (overplotting). Решить ее можно разными способами.
4.2.2.3.3 Двумерные гистограммы
В теории, мы могли бы сами агррегировать данные, использовать точки определенного цвета и размера и отрисовать двумерные гистограммы как точки или маленькие прямоугольники, просто в ggplot2 есть геомы, которые все это немного упрощают.
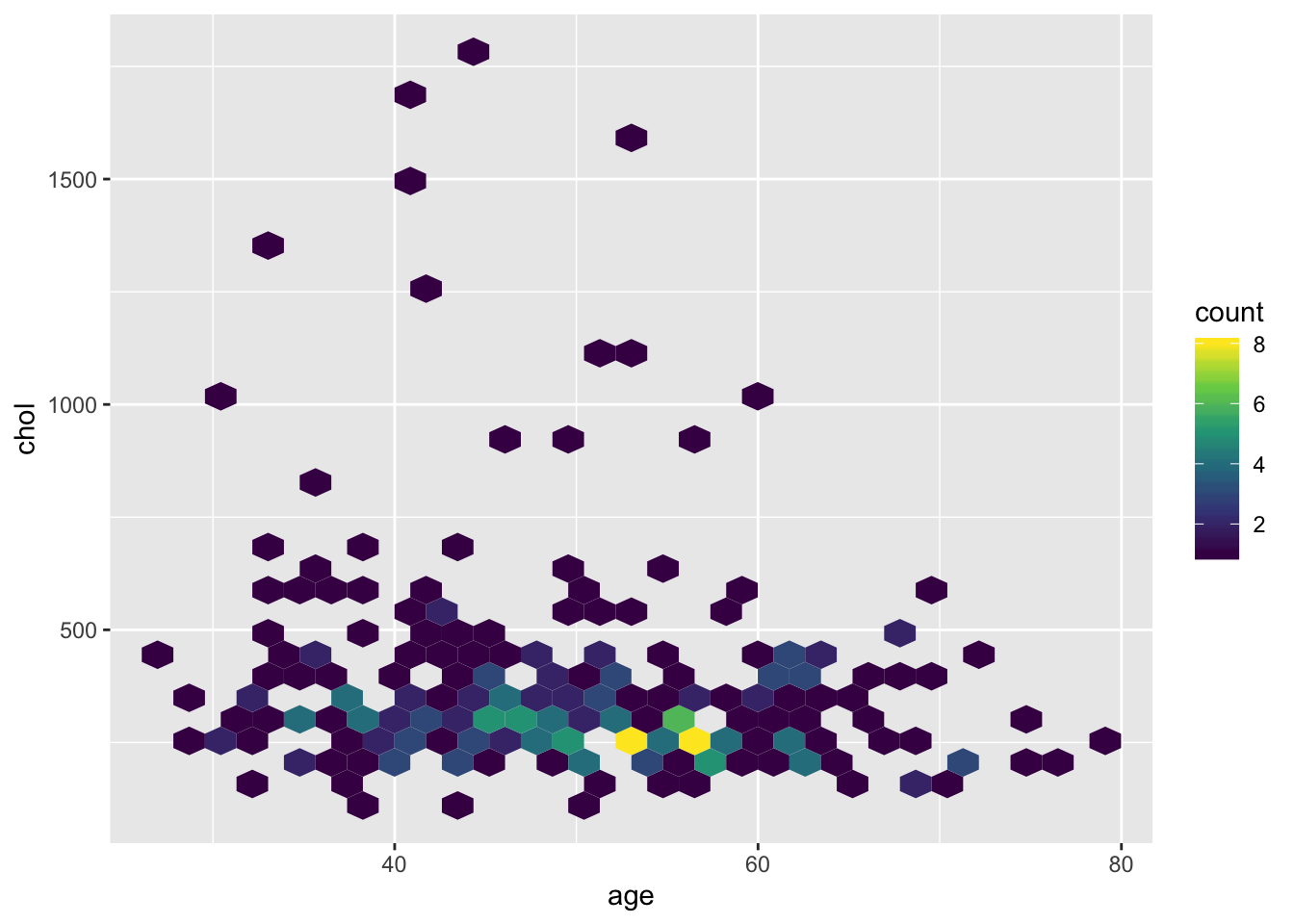
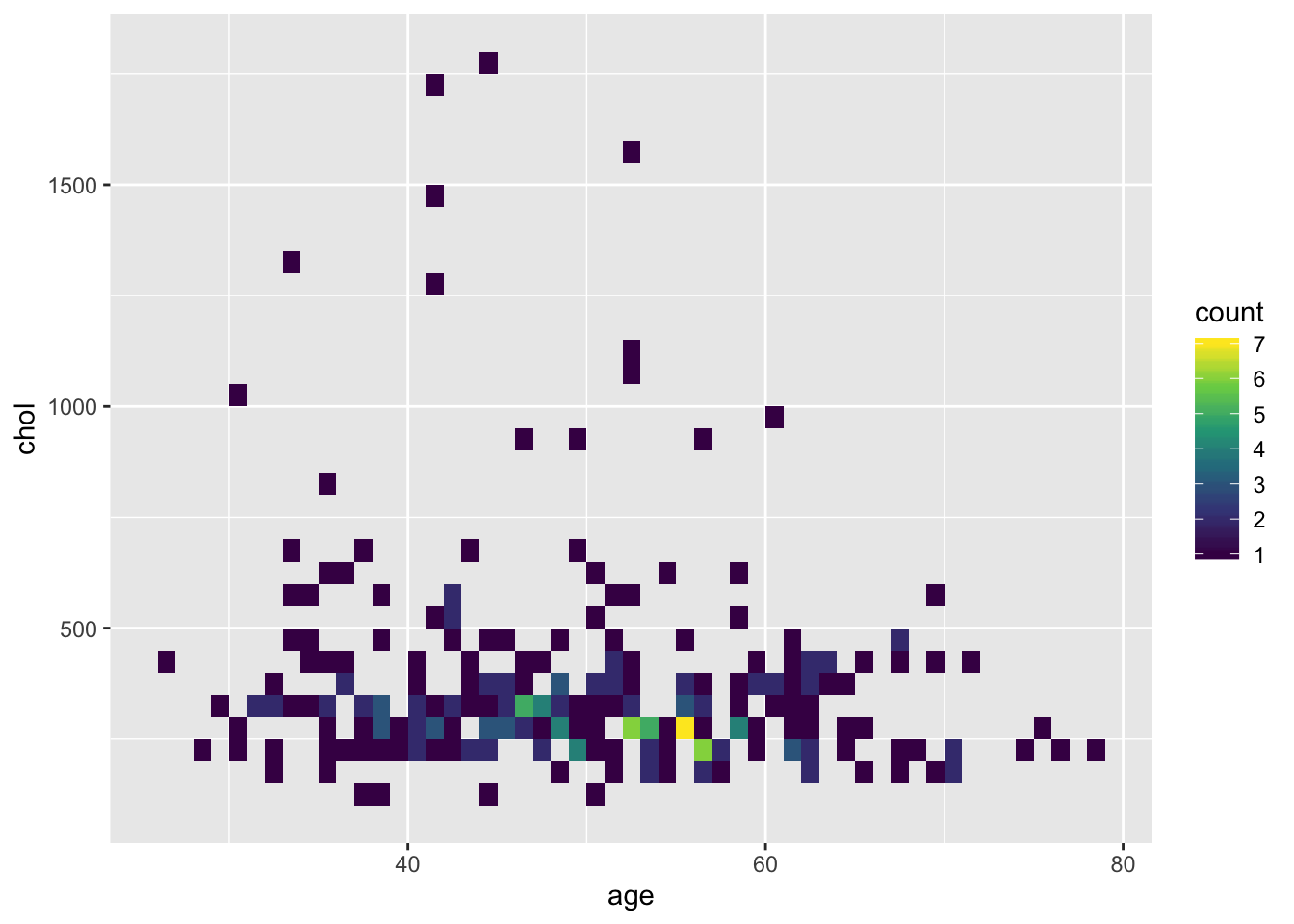
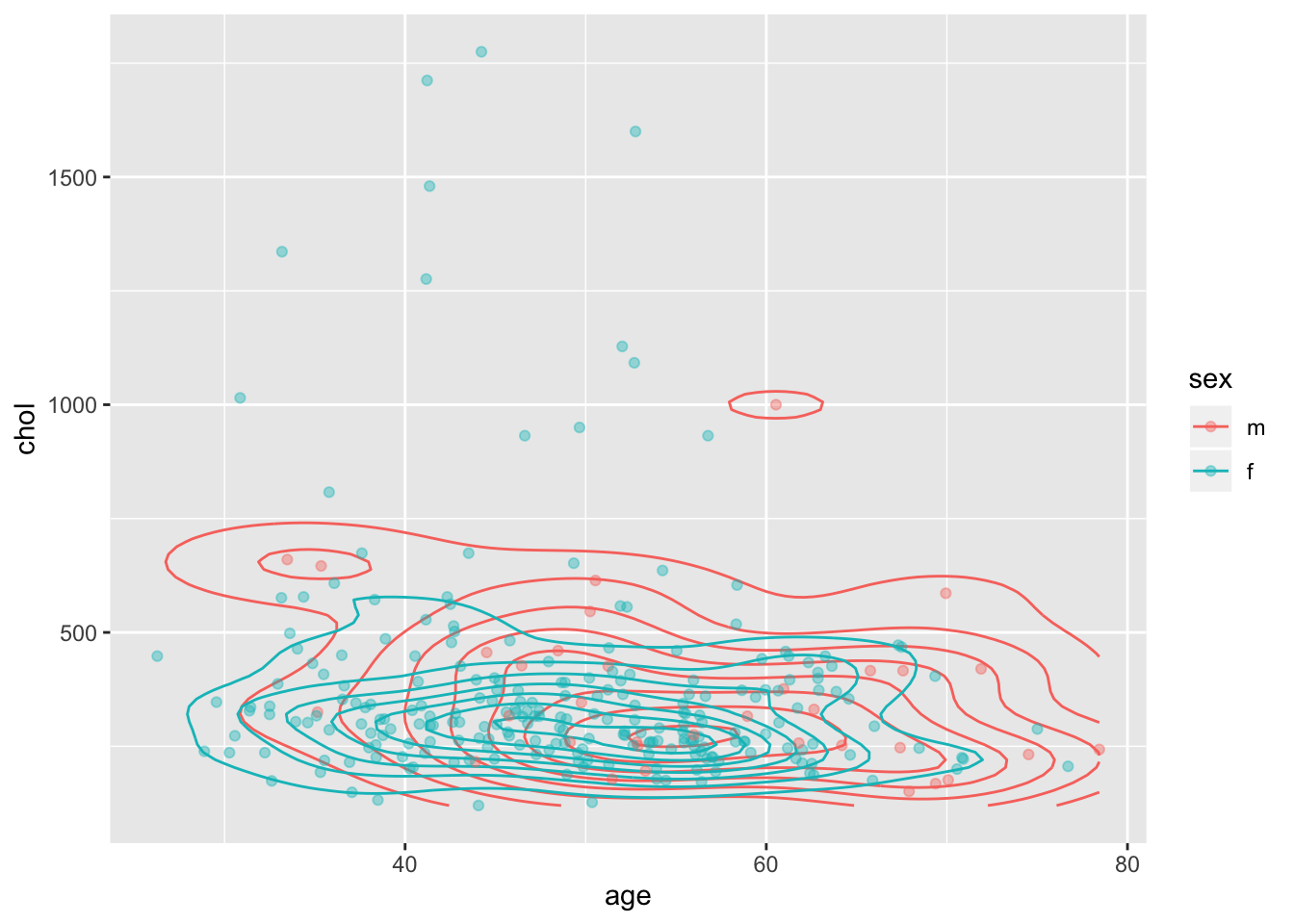
Мы можем наложить два слоя с разными геомами друг на друга. Таким образом можно создавать совершенно новые графики!
Медиана в статистике
Центральную тенденцию данных можно рассматривать не только, как значение с нулевым суммарным отклонением (среднее арифметическое) или максимальную частоту (мода), но и как некоторую отметку (значение в совокупности), делящую ранжированные данные (отсортированные по возрастанию или убыванию) на две равные части. Половина исходных данных меньше этой отметки, а половина – больше. Это и есть медиана.
Итак, медиана в статистике – это уровень показателя, который делит набор данных на две равные половины. Значения в одной половине меньше, а в другой больше медианы. В качестве примера обратимся к набору нормально распределенных случайных чисел.

Очевидно, что при симметричном распределении середина, делящая совокупность пополам, будет находиться в самом центре – там же, где средняя арифметическая (и мода). Это, так сказать, идеальная ситуация, когда мода, медиана и средняя арифметическая совпадают и все их свойства приходятся на одну точку – максимальная частота, деление пополам, нулевая сумма отклонений – все в одном месте. Однако, жизнь не так симметрична, как нормальное распределение.
Допустим, мы имеем дело с техническими замерами отклонений от ожидаемой величины чего-нибудь (содержания элементов, расстояния, уровня, массы и т.д. и т.п.). Если все ОК, то отклонения, скорее всего, будут распределены по закону, близкому к нормальному, примерно, как на рисунке выше. Но если в процессе присутствует важный и неконтролируемый фактор, то могут появиться аномальные значения, которые в значительной мере повлияют на среднюю арифметическую, но при этом почти не затронут медиану.
Медиана выборки – это альтернатива средней арифметической, т.к. она устойчива к аномальным отклонениям (выбросам).
Математическим свойством медианы является то, что сумма абсолютных (по модулю) отклонений от медианного значения дает минимально возможное значение, если сравнивать с отклонениями от любой другой величины. Даже меньше, чем от средней арифметической, о как! Данный факт находит свое применение, например, при решении транспортных задач, когда нужно рассчитать место строительства объектов около дороги таким образом, чтобы суммарная длина рейсов до него из разных мест была минимальной (остановки, заправки, склады и т.д. и т.п.).
Формула медианы
Формула медианы в статистике для дискретных данных чем-то напоминает формулу моды. А именно тем, что формулы как таковой нет. Медианное значение выбирают из имеющихся данных и только, если это невозможно, проводят несложный расчет.
Первым делом данные ранжируют (сортируют по убыванию). Далее есть два варианта. Если количество значений нечетно, то медиана будет соответствовать центральному значению ряда, номер которого можно определить по формуле:

№Me – номер значения, соответствующего медиане,
N – количество значений в совокупности данных.
Тогда медиана обозначается, как

Это первый вариант, когда в данных есть одно центральное значение. Второй вариант наступает тогда, когда количество данных четно, то есть вместо одного есть два центральных значения. Выход прост: берется средняя арифметическая из двух центральных значений:

В интервальных данных выбрать конкретное значение не представляется возможным. Медиану рассчитывают по определенному правилу.
Для начала (после ранжирования данных) находят медианный интервал. Это такой интервал, через который проходит искомое медианное значение. Определяется с помощью накопленной доли ранжированных интервалов. Где накопленная доля впервые перевалила через 50% всех значений, там и медианный интервал.
Не знаю, кто придумал формулу медианы, но исходили явно из того предположения, что распределение данных внутри медианного интервала равномерное (т.е. 30% ширины интервала – это 30% значений, 80% ширины – 80% значений и т.д.). Отсюда, зная количество значений от начала медианного интервала до 50% всех значений совокупности (разница между половиной количества всех значений и накопленной частотой предмедианного интервала), можно найти, какую долю они занимают во всем медианном интервале. Вот эта доля аккурат переносится на ширину медианного интервала, указывая на конкретное значение, именуемое впоследствии медианой.
Обратимся к наглядной схеме.

Немного громоздко получилось, но теперь, надеюсь, все наглядно и понятно. Чтобы при расчете каждый раз не рисовать такой график, можно воспользоваться готовой формулой. Формула медианы имеет следующий вид:

где xMe — нижняя граница медианного интервала;
iMe — ширина медианного интервала;
∑f/2 — количество всех значений, деленное на 2 (два);
S(Me-1)— суммарное количество наблюдений, которое было накоплено до начала медианного интервала, т.е. накопленная частота предмедианного интервала;
fMe — число наблюдений в медианном интервале.
Как нетрудно заметить, формула медианы состоит из двух слагаемых: 1 – значение начала медианного интервала и 2 – та самая часть, которая пропорциональна недостающей накопленной доли до 50%.
Для примера рассчитаем медиану по следующим данным.

Требуется найти медианную цену, то есть ту цену, дешевле и дороже которой по половине количества товаров. Для начала произведем вспомогательные расчеты накопленной частоты, накопленной доли, общего количества товаров.

По последней колонке «Накопленная доля» определяем медианный интервал – 300-400 руб (накопленная доля впервые более 50%). Ширина интервала – 100 руб. Теперь остается подставить данные в приведенную выше формулу и рассчитать медиану.

То есть у одной половины товаров цена ниже, чем 350 руб., у другой половины – выше. Все просто. Средняя арифметическая, рассчитанная по этим же данным, равна 355 руб. Отличие не значительное, но оно есть.
Расчет медианы в Excel
Медиану для числовых данных легко найти, используя функцию Excel, которая так и называется — МЕДИАНА. Другое дело интервальные данные. Соответствующей функции в Excel нет. Поэтому нужно задействовать приведенную выше формулу. Что поделаешь? Но это не очень трагично, так как расчет медианы по интервальным данным – редкий случай. Можно и на калькуляторе разок посчитать.
Напоследок предлагаю задачку. Имеется набор данных. 15, 5, 20, 5, 10. Каково среднее значение? Четыре варианта:
Мода, медиана и среднее значение выборки – это разный способ определить центральную тенденцию в выборке.
Ниже видеоролик о том, как рассчитать медиану в Excel.



