Calculate Mean Value in SQL Server
SQL programmers can calculate mean value of a numeric array in SQL Server by using SQL Server AVG() aggregate function. Transact-SQL developers or database administrators can use mean value calculation method on any numeric table column in a SQL Server database as shown in this SQL tutorial.
First of all let SQL database administrators create database table to store sample numeric values where programmers can calculate the mean value of the numeric values.
Let’s now generate sample data and populate sql table.
SQL developers and database administrators can to calculate the mean value of the values stored in this table column. Here is a SQL script which will create 5 random numbers using SQL Rand() function and insert into database table.
Here is the source codes of the SQL Select script which can be used to calculate the mean value of a numeric value list given on SQL Server.
What is important about the below SQL mean value calculation using AVG() SQL aggregate function is multiplying the values with 1.0 beforehand for decimal value result. As seen below the following two average calculations return integer values losing the decimal points return false values.
Here is a screenshot of the above mean calculation or average calculation in SQL Server.
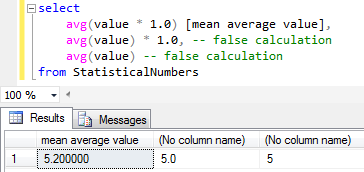
Calculate mean value of an array in SQL Server
It is also possible to create a user defined SQL function which takes the numeric values as a string input parameter formed of concatenated numeric values and returns the mean value as follows.
Since SQL aggregate function does not accept multiple values I had to create this SQL mean value calculation function.
In the Mean calculation function, a second user defined SQL function dbo.split() is used to split concatenated numeric values which are passed as input to the SQL mean function. SQL Server developers and administrators can check SQL tutorial SQL Split function for the source codes of the helper function.
And this sample SQL function can be used to calculate mean value of a numeric list or average value of items as given in the following example on SQL Server
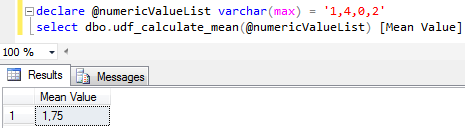
Mean value (average) calculation function for SQL Server developers
Mean Median Mode using SQL and DAX
Introduction
Let’s get started and understand the concepts within.
In this tutorial, I will consider the following series and calculate all the averages based on this only.
The mean is also known as the average of all the numbers in a given series. It is calculated by adding up all the data points in the series and then dividing those by the total number of data points.
The mathematical formula for mean is denoted as follows:
For example, let us calculate the mean of Series. When we add these values we obtain (2 + 8 + 4 + 6 + 2 + 2) = 24. Since the number of data points is 6 in this case, the mean is calculated as 24/ 6 = 4.
Thus, the mean of the Series is 4.
Median
Median is calculated by ordering all the data points from the series in ascending order and then picking out the middle data point from it. If there are two middle data points, then the median will be calculated as the mean of those two numbers.
The mathematical formula for calculating the median is as follows:
The mode is calculated as the data point which occurs most frequently in a given series. In other words, it is the most common number in a dataset. Mathematically, there is no formula mode, as it just takes into account the most frequently occurring items from the list.
In this series, the number 2 appears thrice while all the other numbers appear only once. Thus, the frequency of 2 is 3, while that of others is 1. Since 2 is the highest frequency in the series, the mode for this series is also 2.
Calculations in SQL
In the following sections, I’ll be using the same series as used in the example above to calculate all the three functions mentioned and demonstrate the scripts in SQL.
Let us first prepare our dataset on which we will be performing all the calculations.
It is the simplest of all the calculations. We just need to calculate the average of all the values in the series, which can be computed as follows.
Median
In order to calculate the median, we need to sort the series in ascending order and then divide it into two equal halves. I’ll show in a step-by-step process how it can be done using SQL.
Let us first sort the series and fetch the results.
As you can see in the image above, the series has been sorted and we have identified the first and the second halves as well.
The next step here is to consider the highest value from the first half and the lowest value from the second half. In this case, 2 from the First Half and 4 from the second half. In order to do that, we will write two select statements and fetch the results. We will be using the TOP 50 PERCENT in SQL to achieve this.
Now that we have both the resultsets ready, we need to extract the highest number from the first half and the lowest number from the second half. This can be done as follows.
Once we have both these values ready, the final step is to calculate the average of these two numbers and we will have the median value of the entire series. The overall script is as follows.
Alternatively, there is another method to easily calculate the median in T-SQL. We can leverage the PERCENTILE_CONT function and obtain the same result. This is an analytical function in SQL which helps to calculate the percentile value in a continuous distribution of data values in a table. Since median is also defined as the 50th percentile of a series, we can use this function and calculate the 50th percentile.
The syntax of this function is as below.
In this example, we will not be using the PARTITION BY clause, since we want the entire series to be considered for calcualting the median. Let’s see it in action.
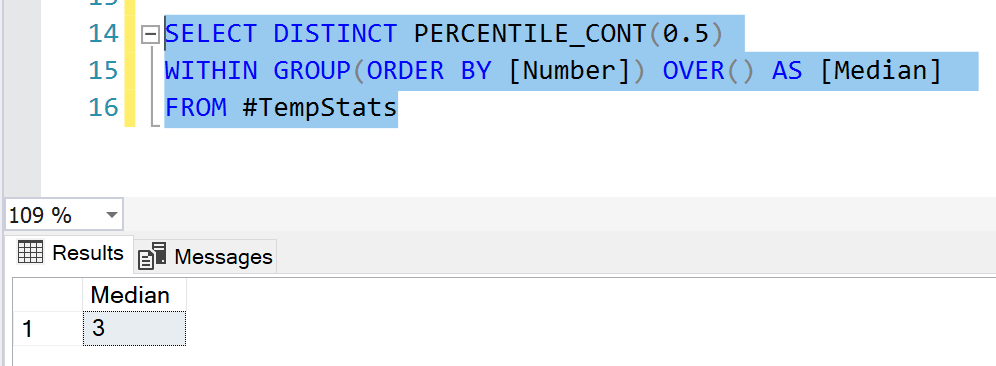
This is how the median can be calculated using SQL.
Finding out the mode is SQL is also quite easy. The first step would be to get a distinct count of all the numbers in the series which can be done as follows.
As you can see in the results above, the frequency for the number 2 is 3, whereas it is 1 for all the other numbers. So, the final step to calculate the mode is just to display the number with the highest frequency.
Sometimes, it may so happen that there are two or more than two numbers in the series which have the same highest frequencies. In such a case, it becomes essential for us to display all the numbers which have the same highest frequency.
For example, let us insert three more numbers in the same table as follows.
Now, as per the definition of mode, there should be two numbers 2 and 5 with the same frequency, i.e. 3. So, we must display both of these. This can be done by altering our previous script and adding the WITH TIES clause in SQL.
Calculations in DAX
Let us now head over to Power BI and perform the same calculations but using DAX and not SQL. I’m using the same series in PowerBI just to keep the calculations the same.
In order to calculate mean, we will just use the AVERAGE function available in DAX and create a measure for it. The script to create a measure for the mean is provided below.
Median
There is already a formula available in DAX that does all the heavy lifting while calculating the median for any given series. We can leverage the MEDIAN function for the same. The script is as below.
In order to calculate mode in PowerBI, we need to perform some calculations which will calculate the frequency of the numbers in the series during runtime, and then extract the numbers with the highest frequency. I have provided the script for the same below.
Let me explain how the calculations are performed here.
As you can see in the figure above, I have divided the calculations into 3 main parts. Let me go through each of these one-by-one.
Final Touch in Power BI
Now that all the measures are created using DAX, we can just build up a table in PowerBI and fetch data from these three calculated measures. As you can see in the image below, we have obtained the same values in Power BI as from SQL.
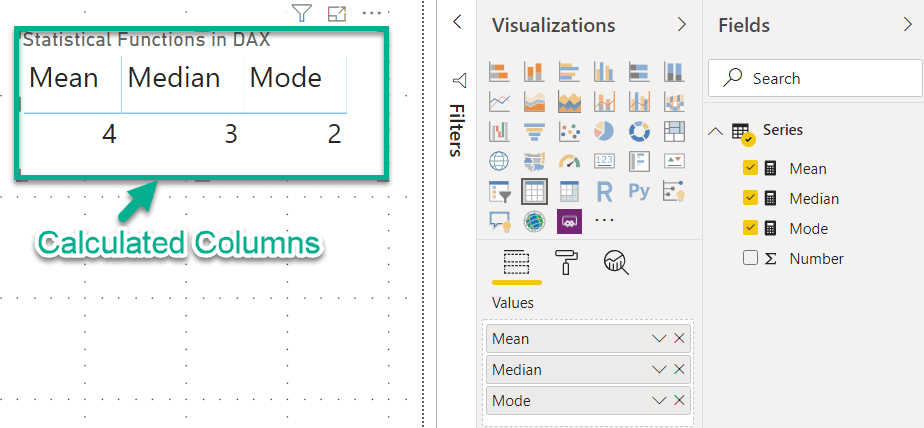
Takeaway
In this article, I have described the basic statistical functions that are very essential in any kind of data analysis using SQL and DAX. The next step would be to learn more about the uses of these functions in detail.
Mean and Mode in SQL Server
Mean is the average of the given data set calculated by dividing the total sum by the number of values in data set.
Attention reader! Don’t stop learning now. Learn SQL for interviews using SQL Course by GeeksforGeeks.
Query to find mean in the table
Creating Table: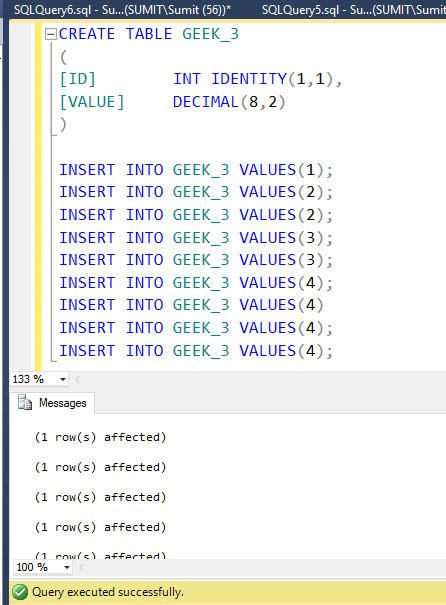
Table Content: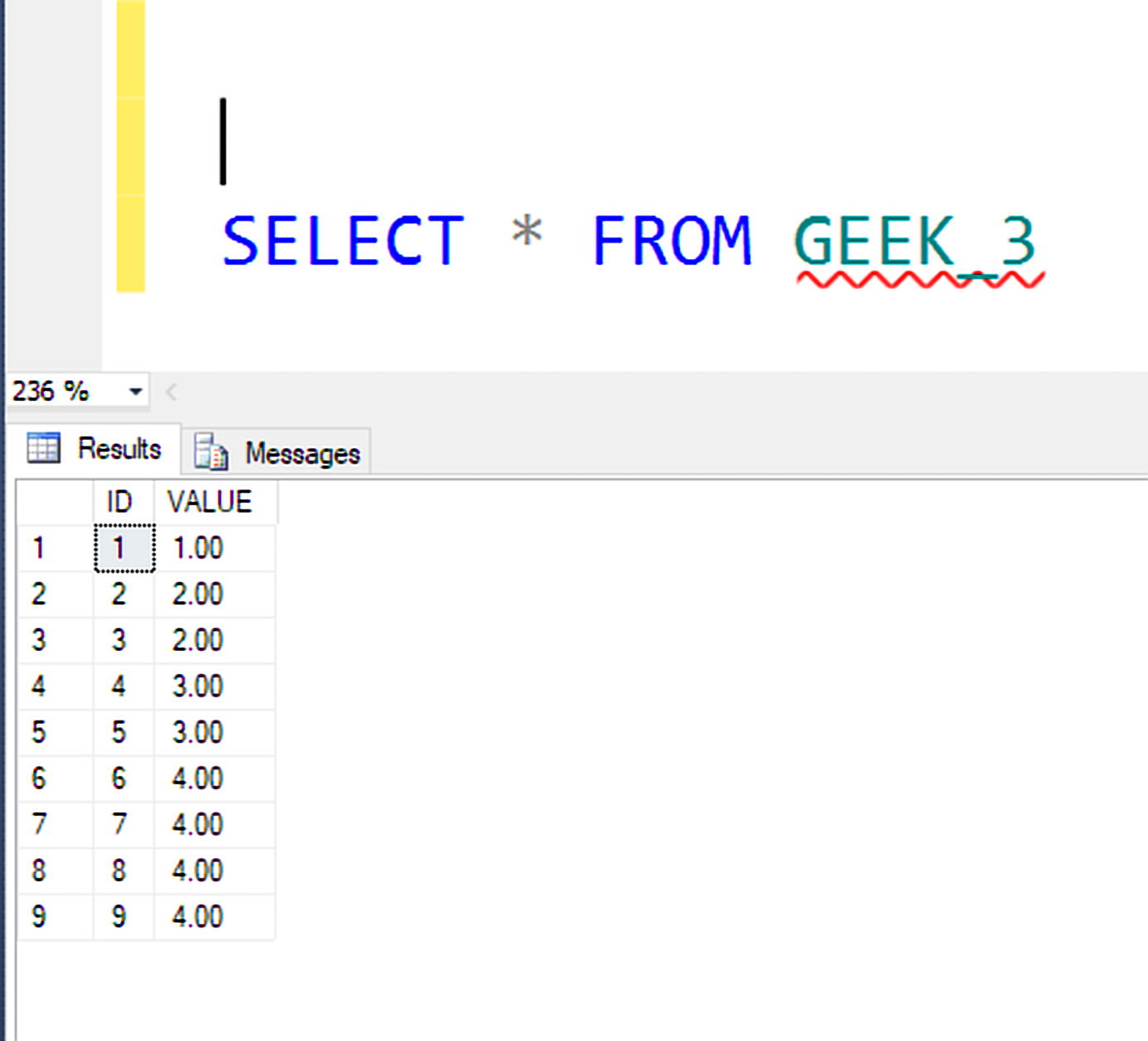
Query to find Mean: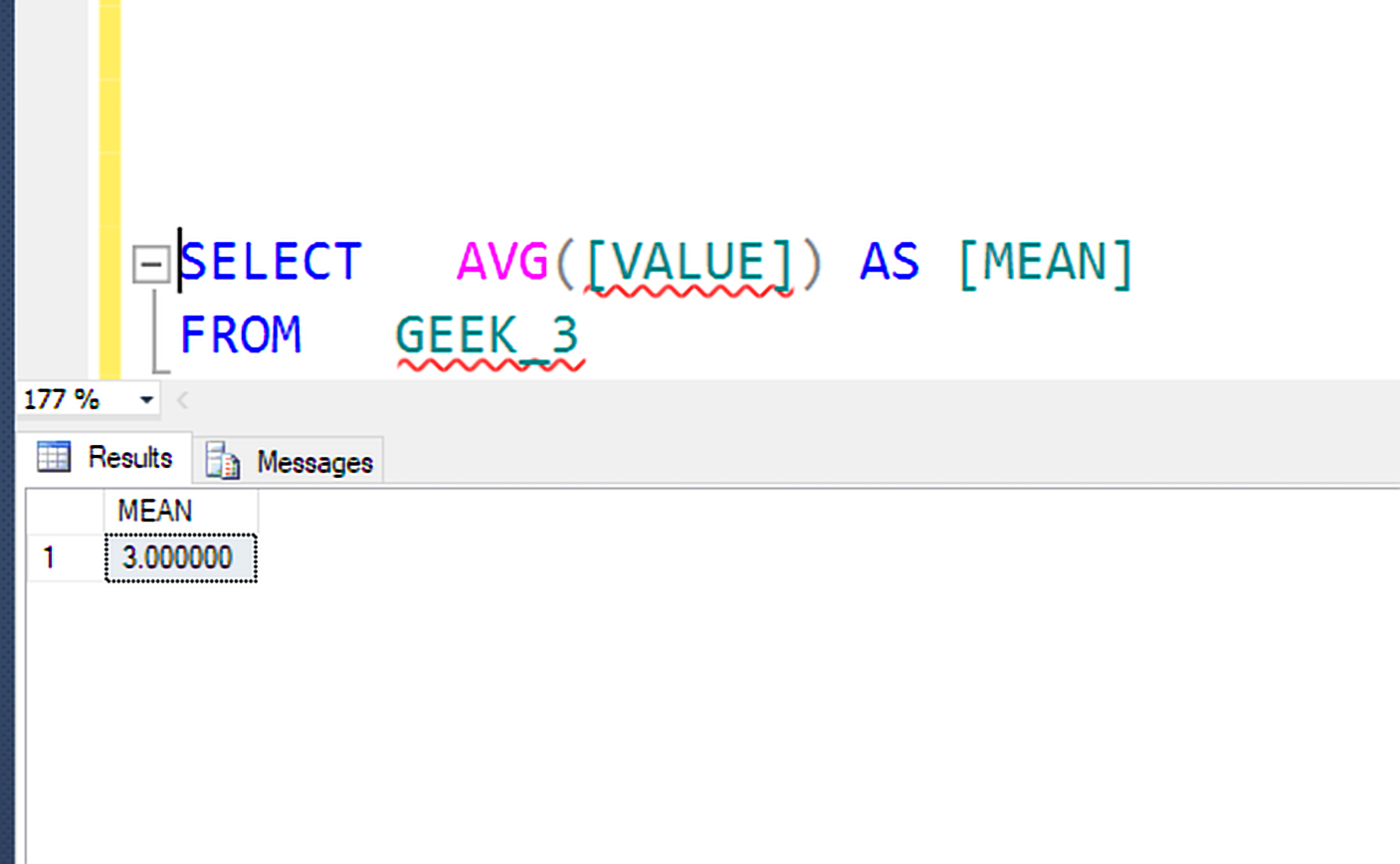
Mode of a data set is the value that appears most frequently in a series of data.
Query to find mode in the table
Creating Table: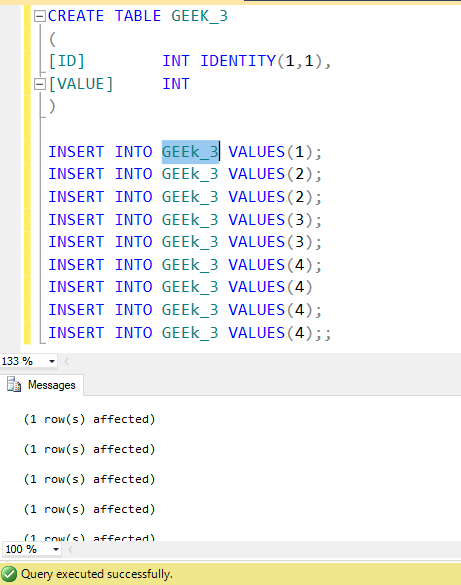
Table Content: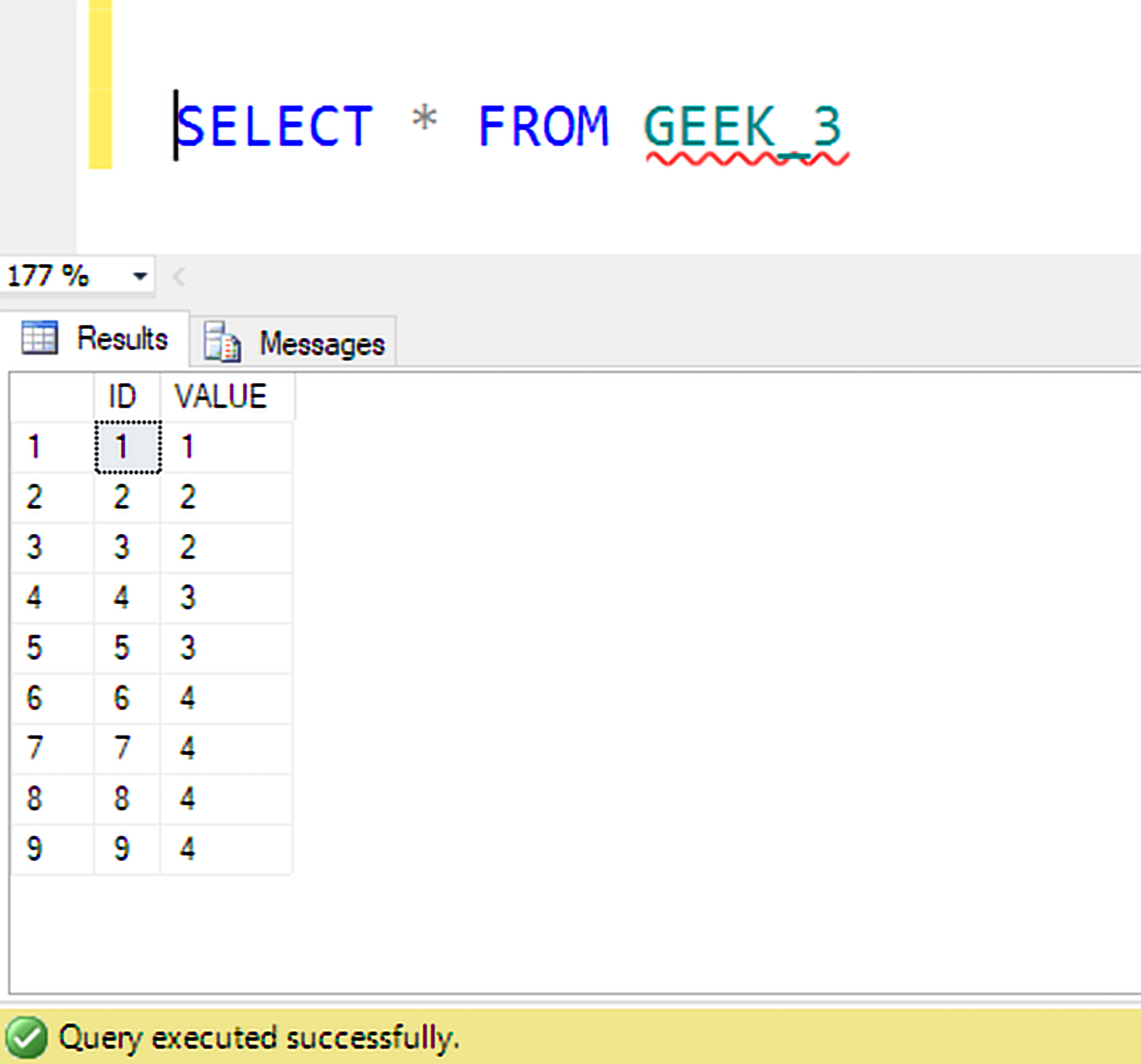
Query to find Mode: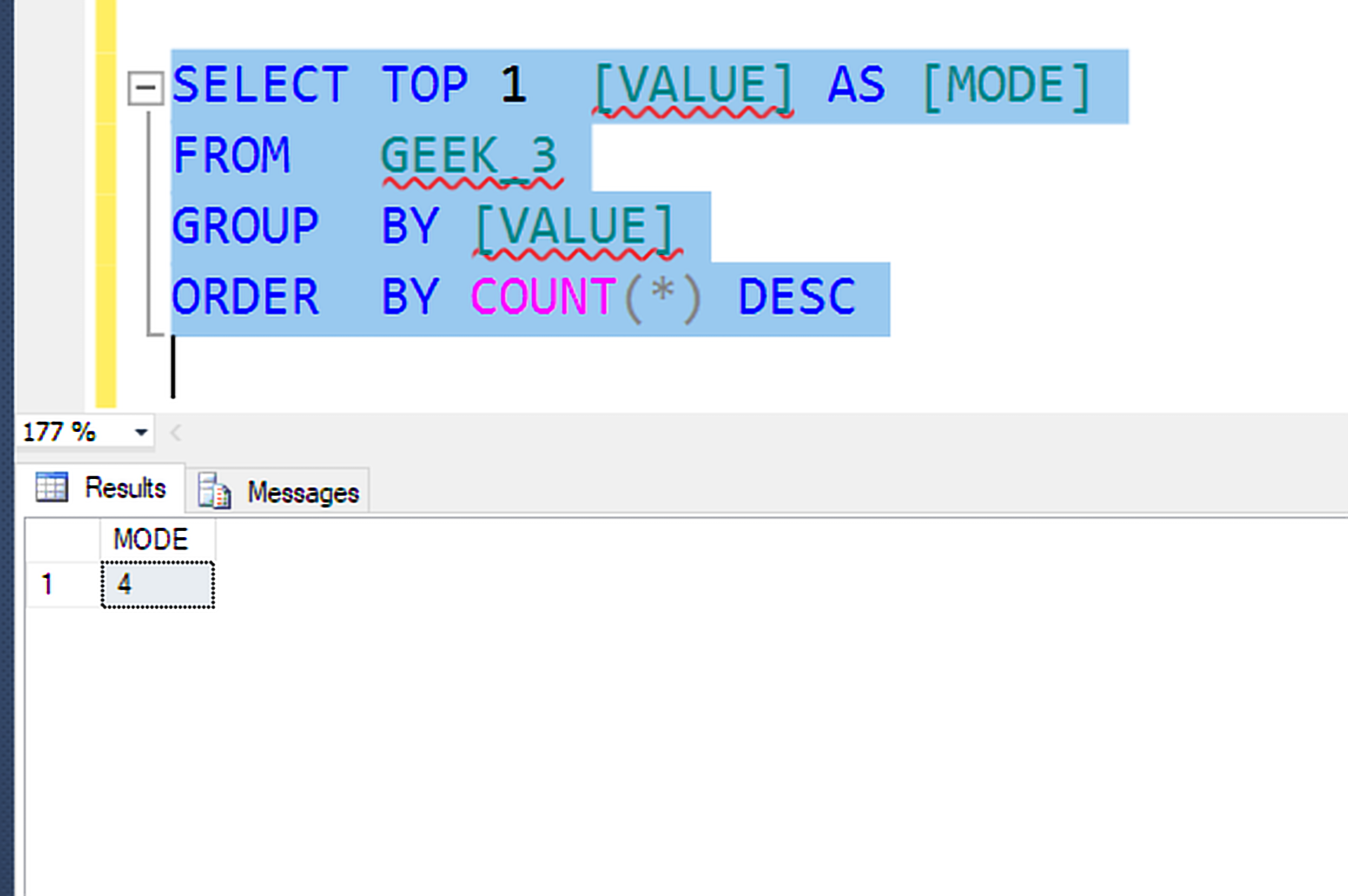
How to Calculate the Mean, Median, and Mode in Oracle
Calculating the mean, median, and mode in Oracle SQL is a task often performed by report developers or anyone else working with SQL. Learn how to calculate these three values from a range of data in this article.
What is the Mean, Median, and Mode, and Standard Deviation?
Mean, median, and mode are three kinds of average values that can be obtained from a set of data.

You might have learnt about them in high school maths (like I did) but may have forgotten what they are (like I did).
How Can I Calculate the Mean in Oracle SQL?
Let’s say we had a table of data called movie_ratings that looked like this:
| RATING |
| 11 |
| 12 |
| 15 |
| 19 |
| 12 |
| 13 |
| 16 |
| 20 |
How could we find the mean of these values?
| MEAN_RATING |
| 14.75 |
You can see the average is 14.75. This is because we added all of the numbers up (which equals 118) and then divided by the count of numbers (which is 8). 118/8 = 14.75.
How Can I Calculate the Median in Oracle SQL?
To calculate the median in Oracle SQL, we use the MEDIAN function.
The MEDIAN function returns the median of the set of provided values.
The MEDIAN is the middle value in a set of values.
So, for example, you had these five values:
The median of these would be the middle value after they have been ordered in ascending order. So, the median would be 18.
Median Function Parameters
The MEDIAN function can be used as either an analytic function or an aggregate function.
The parameters of the MEDIAN function are:
The expr value can be any numeric data type. The MEDIAN function returns the same data type as the expr value.
If you specify the OVER clause, Oracle will work out the data type with the highest precedence and return that type.
Finding the Median
The MEDIAN function looks like this:
| MEDIAN_RATING |
| 14 |
You can see that the median is 14. This is because the middle value would be 14.
While there are 8 values and there is no middle value, the median is calculated as the point between the two middle values.
So, if we order the values they would be:
11, 12, 12, 13, 15, 16, 19, 20
The middle two values are 13 and 15, and the mid point between them is 14.
How Can I Calculate the Mode in Oracle SQL?
To calculate the mode, we need to use the STATS_MODE function.
The mode is 12 as that is the most occurring value in the table.
Show the Mean, Median and Mode All In One Query
Let’s use these examples to show the mean, median, and mode all in the same query.
| MEAN_RATING | MEDIAN_RATING | MODE_RATING |
| 14.75 | 14 | 12 |
As you can see, the values here are the same as the earlier examples.
So, that’s how you find the mean, median, and mode in Oracle SQL.
Examples of the MEDIAN Function
Here are some further examples of the MEDIAN function. I find that examples are the best way for me to learn about code, even with the explanation above.
Example 1 – aggregate
This example finds the median using it as an aggregate function.
| MEDIAN_FEES_REQ |
| 300 |
It shows the value of 300 because this is the middle value in the column after it has been ordered.
Example 2 – analytic
This example uses the MEDIAN function as an analytic function
| FIRST_NAME | LAST_NAME | ADDRESS_STATE | FEES_REQUIRED | MEDIAN_FEES_REQ |
| Mark | Anderson | California | 860 | 860 |
| Robert | Pickering | Colorado | 110 | 130 |
| Susan | Johnson | Colorado | 150 | 130 |
| Michelle | Randall | Florida | 250 | 250 |
| John | Rogers | Nevada | 210 | 280 |
| Tom | Capper | Nevada | 350 | 280 |
| Steven | Webber | New York | 100 | 500 |
| Mark | Holloway | New York | 500 | 500 |
| John | Smith | New York | 500 | 500 |
| Mary | Taylor | Oregon | 500 | 500 |
| Julie | Armstrong | Texas | 100 | 150 |
| Tanya | Hall | Texas | 150 | 150 |
| Andrew | Cooper | Texas | 800 | 150 |
| Jarrad | Winston | Utah | 700 | 700 |
This example shows the median fees_required when grouped by the home_state for each record in the table.
How to Find the Standard Deviation in Oracle
Another statistic you may want to find is the standard deviation.
This can be achieved with the STDDEV function.
The purpose of the STDDEV function is to find the standard deviation of a set of numbers.
The standard deviation is a mathematical concept, which is a number that represents how much the values in a group differ from the mean value in a group.
This function can be used as either an analytical function or an aggregate function.
Oracle STDDEV Function Syntax and Parameters
The syntax for the STDDEV function when it is used as an aggregate function is:
STDDEV ( [DISTINCT | ALL] expression )
Alternatively, the syntax when used as an analytical function is:
STDDEV ( [DISTINCT | ALL] expression ) [OVER (analytical_clause) ]
The parameters of the STDDEV function as an aggregate function are:
The parameters of the STDDEV function as an analytical function are the same, but also include:
Examples of the STDDEV Function
Here are some examples of the STDDEV function. I find that examples are the best way for me to learn about code, even with the explanation above.
Example 1
This example uses the STDDEV funiotn as an aggregate function.
| STDDEV(FEES_REQUIRED) |
| 234.7788558 |
Example 2
This example uses the STDDEV function as an aggregate function again, but I’ve used the DISTINCT keyword.
| STDDEV(DISTINCTFEES_REQUIRED) |
| 254.9322973 |
Example 3
This example uses the STDDEV function as an analytical function.
| ENROLMENT_DATE | ENROLMENT_MTH | STDEV_VAL |
| 01/Feb/15 | FEB | 282.8427125 |
| 12/Feb/15 | FEB | 282.8427125 |
| 30/Jan/15 | JAN | 176.5812911 |
| 12/Jan/15 | JAN | 176.5812911 |
| 20/Jan/15 | JAN | 176.5812911 |
| 28/Jan/15 | JAN | 176.5812911 |
| 23/Jan/15 | JAN | 176.5812911 |
| 04/Mar/15 | MAR | 234.7788558 |
| 06/Mar/15 | MAR | 234.7788558 |
| 09/Mar/15 | MAR | 234.7788558 |
You can see that for each of the enrolment_mth values that are the same, the stdev_val is the same.
So, that’s how you find the mean, median, mode, and standard deviation in Oracle SQL.
Lastly, if you enjoy the information and career advice I’ve been providing, sign up to my newsletter below to stay up-to-date on my articles. You’ll also receive a fantastic bonus. Thanks!
6 thoughts on “How to Calculate the Mean, Median, and Mode in Oracle”
Thanks for the article.
Seems the result table of the analytic MEDIAN example has wrong median values for Colorado:
Robert Pickering Colorado 110 130
Susan Johnson Colorado 150 130
The 130 are the average, but the MEDIAN should be 150. Confused me as it is the first state with >1 students in the list 🙂
Hi Rolf, yes that does seem strange. I re-ran the code to see what the value would be, and the median still shows as 130. A quick test can be run:
CREATE TABLE testval (
testnum NUMBER(4)
);
INSERT INTO testval(testnum) VALUES (110);
INSERT INTO testval(testnum) VALUES (150);
SELECT MEDIAN(testnum) FROM testval;
It seems Oracle chooses a value that would be the middle point if there is an even number of values. New York shows 500 because the values are 100,500,500 and the middle value is 500. The same thing happens for Texas which shows 100,150,800 and has a median of 150.
Hope that makes sense!
Памятка/шпаргалка по SQL

Доброго времени суток, друзья!
Изучение настоящей шпаргалки не сделает вас мастером SQL, но позволит получить общее представление об этом языке программирования и возможностях, которые он предоставляет. Рассматриваемые в шпаргалке возможности являются общими для всех или большинства диалектов SQL.
Для более полного погружения в SQL рекомендую изучить эти руководства по MySQL и PostgreSQL от Метанита. Они хороши тем, что просты в изучении и позволяют быстро начать работу с названными СУБД.
При обнаружении ошибок, опечаток и неточностей, не стесняйтесь писать мне в личку.
Содержание
Что такое SQL?
SQL — это язык структурированных запросов (Structured Query Language), позволяющий хранить, манипулировать и извлекать данные из реляционных баз данных (далее — РБД, БД).
Почему SQL?
Процесс SQL
При выполнении любой SQL-команды в любой RDBMS (Relational Database Management System — система управления РБД, СУБД, например, PostgreSQL, MySQL, MSSQL, SQLite и др.) система определяет наилучший способ выполнения запроса, а движок SQL определяет способ интерпретации задачи.
В данном процессе участвует несколького компонентов:
Классический движок обрабатывает все не-SQL-запросы, а движок SQL-запросов не обрабатывает логические файлы.
Команды SQL
| N | Команда | Описание |
|---|---|---|
| 1 | CREATE | Создает новую таблицу, представление таблицы или другой объект в БД |
| 2 | ALTER | Модифицирует существующий в БД объект, такой как таблица |
| 3 | DROP | Удаляет существующую таблицу, представление таблицы или другой объект в БД |
| N | Команда | Описание |
|---|---|---|
| 1 | SELECT | Извлекает записи из одной или нескольких таблиц |
| 2 | INSERT | Создает записи |
| 3 | UPDATE | Модифицирует записи |
| 4 | DELETE | Удаляет записи |
| N | Команда | Описание |
|---|---|---|
| 1 | GRANT | Наделяет пользователя правами |
| 1 | REVOKE | Отменяет права пользователя |
Обратите внимание: использование верхнего регистра в названиях команд SQL — это всего лишь соглашение, большинство СУБД нечувствительны к регистру. Тем не менее, форма записи инструкций, когда названия команд пишутся большими буквами, а названия таблиц, колонок и др. — маленькими, позволяет быстро определять назначение производимой с данными операции.
Что такое таблица?
Данные в СУБД хранятся в объектах БД, называемых таблицами (tables). Таблица, как правило, представляет собой коллекцию связанных между собой данных и состоит из определенного количества колонок и строк.
Таблица — это самая распространенная и простая форма хранения данных в РБД. Вот пример таблицы с пользователями (users):
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 25 | Moscow | active |
| 2 | Vika | 26 | Ekaterinburg | inactive |
| 3 | Elena | 27 | Ekaterinburg | active |
| 4 | Oleg | 28 | Moscow | inactive |
Что такое поле?
Каждая таблица состоит из небольших частей — полей (fields). Полями в таблице users являются userId, userName, age, city и status. Поле — это колонка таблицы, предназначенная для хранения определенной информации о каждой записи в таблице.
Что такое запись или строка?
Запись или строка (record/row) — это любое единичное вхождение (entry), существующее в таблице. В таблице users 5 записей. Проще говоря, запись — это горизонтальное вхождение в таблице.
Что такое колонка?
Что такое нулевое значение?
Ограничения
Ограничения (constraints) — это правила, применяемые к данным. Они используются для ограничения данных, которые могут быть записаны в таблицу. Это обеспечивает точность и достоверность данных в БД.
Ограничения могут устанавливаться как на уровне колонки, так и на уровне таблицы.
Среди наиболее распространенных ограничений можно назвать следующие:
Любое ограничение может быть удалено с помощью команды ALTER TABLE и DROP CONSTRAINT + название ограничения. Некоторые реализации предоставляют сокращения для удаления ограничений и возможность отключать ограничения вместо их удаления.
Целостность данных
В каждой СУБД существуют следующие категории целостности данных:
Нормализация БД
Нормализация — это процесс эффективной организации данных в БД. Существует две главных причины, обуславливающих необходимость нормализации:
Нормализация предполагает соблюдение нескольких форм. Форма — это формат структурирования БД. Существует три главных формы: первая, вторая и, соответственно, третья. Я не буду вдаваться в подробности об этих формах, при желании, вы без труда найдете необходимую информацию.
Синтаксис SQL
Примеры синтаксиса
Типы данных
Каждая колонка, переменная и выражение в SQL имеют определенный тип данных (data type). Основные категории типов данных:
Точные числовые
Приблизительные числовые
| Тип данных | От | До |
|---|---|---|
| float | -1.79E + 308 | 1.79E + 308 |
| real | -3.40E + 38 | 3.40E + 38 |
Дата и время
| Тип данных | От | До |
|---|---|---|
| datetime | Jan 1, 1753 | Dec 31, 9999 |
| smalldatetime | Jan 1, 1900 | Jun 6, 2079 |
| date | Дата сохраняется в виде June 30, 1991 | |
| time | Время сохраняется в виде 12:30 P.M. |
Строковые символьные
| N | Тип данных | Описание |
|---|---|---|
| 1 | char | Строка длиной до 8,000 символов (не-юникод символы, фиксированной длины) |
| 2 | varchar | Строка длиной до 8,000 символов (не-юникод символы, переменной длины) |
| 3 | text | Не-юникод данные переменной длины, длиной до 2,147,483,647 символов |
Строковые символьные (юникод)
| N | Тип данных | Описание |
|---|---|---|
| 1 | nchar | Строка длиной до 4,000 символов (юникод символы, фиксированной длины) |
| 2 | nvarchar | Строка длиной до 4,000 символов (юникод символы, переменной длины) |
| 3 | ntext | Юникод данные переменной длины, длиной до 1,073,741,823 символов |
Бинарные
| N | Тип данных | Описание |
|---|---|---|
| 1 | binary | Данные размером до 8,000 байт (фиксированной длины) |
| 2 | varbinary | Данные размером до 8,000 байт (переменной длины) |
| 3 | image | Данные размером до 2,147,483,647 байт (переменной длины) |
Смешанные
| N | Тип данных | Описание |
|---|---|---|
| 1 | timestamp | Уникальные числа, обновляющиеся при каждом изменении строки |
| 2 | uniqueidentifier | Глобально-уникальный идентификатор (GUID) |
| 3 | cursor | Объект курсора |
| 4 | table | Промежуточный результат, предназначенный для дальнейшей обработки |
Операторы
Оператор (operators) — это ключевое слово или символ, которые, в основном, используются в инструкциях WHERE для выполнения каких-либо операций. Они используются как для определения условий, так и для объединения нескольких условий в инструкции.
Арифметические
| Оператор | Описание | Пример |
|---|---|---|
| + (сложение) | Сложение значений | a + b = 30 |
| — (вычитание) | Вычитание правого операнда из левого | b — a = 10 |
| * (умножение) | Умножение значений | a * b = 200 |
| / (деление) | Деление левого операнда на правый | b / a = 2 |
| % (деление с остатком/по модулю) | Деление левого операнда на правый с остатком (возвращается остаток) | b % a = 0 |
Операторы сравнения
Логические операторы
| N | Оператор | Описание |
|---|---|---|
| 1 | ALL | Сравнивает все значения |
| 2 | AND | Объединяет условия (все условия должны совпадать) |
| 3 | ANY | Сравнивает одно значение с другим, если последнее совпадает с условием |
| 4 | BETWEEN | Проверяет вхождение значения в диапазон от минимального до максимального |
| 5 | EXISTS | Определяет наличие строки, соответствующей определенному критерию |
| 6 | IN | Выполняет поиск значения в списке значений |
| 7 | LIKE | Сравнивает значение с похожими с помощью операторов подстановки |
| 8 | NOT | Инвертирует (меняет на противоположное) смысл других логических операторов, например, NOT EXISTS, NOT IN и т.д. |
| 9 | OR | Комбинирует условия (одно из условий должно совпадать) |
| 10 | IS NULL | Определяет, является ли значение нулевым |
| 11 | UNIQUE | Определяет уникальность строки |
Выражения
Выражение (expression) — это комбинация значений, операторов и функций для оценки (вычисления) значения. Выражения похожи на формулы, написанные на языке запросов. Они могут использоваться для извлечения из БД определенного набора данных.
Базовый синтаксис выражения выглядит так:
Существуют различные типы выражений: логические, числовые и выражения для работы с датами.
Логические
Логические выражения извлекают данные на основе совпадения с единичным значением.
Предположим, что в таблице users имеются следующие записи:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 25 | Moscow | active |
| 2 | Vika | 26 | Ekaterinburg | inactive |
| 3 | Elena | 27 | Ekaterinburg | active |
| 4 | Oleg | 28 | Moscow | inactive |
Выполняем поиск активных пользователей:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 25 | Moscow | active |
| 3 | Elena | 27 | Ekaterinburg | active |
Числовые
Используются для выполнения арифметических операций в запросе.
Простой пример использования числового выражения:
Также существует несколько встроенных функций для работы со строками:
Выражения для работы с датами
Эти выражения, как правило, возвращают текущую дату и время.
Другие функции для получения текущей даты и времени:
Функции для разбора даты и времени:
Функции для манипулирования датами:
Создание БД
Условие IF NOT EXISTS позволяет избежать получения ошибки при попытке создания БД, которая уже существует.
Название БД должно быть уникальным в пределах СУБД.
Получаем список БД:
Удаление БД
Условие IF EXISTS позволяет избежать получения ошибки при попытке удаления несуществующей БД.
Обратите внимание: при удалении БД уничтожаются все данные, которые в ней хранятся, так что будьте предельно внимательны при использовании данной команды.
Проверяем, что БД удалена:
Выбор БД
Создание таблицы
Проверяем, что таблица была создана:
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| userId | int(11) | NO | PRI | ||
| userName | varchar(20) | NO | |||
| age | int(11) | NO | |||
| city | varchar(20) | NO | |||
| status | varchar(8) | YES | NULL |
Удаление таблицы
Обратите внимание: при удалении таблицы, навсегда удаляются все хранящиеся в ней данные, индексы, триггеры, ограничения и разрешения, так что будьте предельно внимательны при использовании данной команды.
Удаляем таблицу users :
Добавление колонок
Названия колонок можно не указывать, однако, в этом случае значения должны перечисляться в правильном порядке.
Во избежание ошибок, рекомендуется всегда перечислять названия колонок.
В таблицу можно добавлять несколько строк за один раз.
Также, как было отмечено, при добавлении строки названия полей можно опускать:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 25 | Moscow | active |
| 2 | Vika | 26 | Ekaterinburg | inactive |
| 3 | Elena | 27 | Ekaterinburg | active |
| 4 | Oleg | 28 | Moscow | inactive |
Заполнение таблицы с помощью другой таблицы
Выборка полей
Для выборки всех полей используется такой синтаксис:
| userId | userName | age |
|---|---|---|
| 1 | Igor | 25 |
| 2 | Vika | 26 |
| 3 | Elena | 27 |
| 4 | Oleg | 28 |
Предложение WHERE
Обратите внимание: строки в предложении WHERE должны быть обернуты в одинарные кавычки ( » ), а числа, напротив, указываются как есть.
Операторы AND и OR
Конъюнктивный оператор AND и дизъюнктивный оператор OR используются для соединения нескольких условий при фильтрации данных.
Возвращаемые записи должны удовлетворять всем указанным условиям.
Возвращаемые записи должны удовлетворять хотя бы одному условию.
Сделаем выборку тех же полей неактивных пользователей или пользователей, младше 27 лет:
Обновление полей
Обновим возраст пользователя с именем Igor :
Удаление записей
Удалим неактивных пользователей:
Предложения LIKE и REGEX
LIKE
Предложение LIKE используется для сравнения значений с помощью операторов с подстановочными знаками. Существует два вида таких операторов:
% означает 0, 1 или более символов. _ означает точно 1 символ.
| N | Инструкция | Результат |
|---|---|---|
| 1 | WHERE col LIKE ‘foo%’ | Любые значения, начинающиеся с foo |
| 2 | WHERE col LIKE ‘%foo%’ | Любые значения, содержащие foo |
| 3 | WHERE col LIKE ‘_oo%’ | Любые значения, содержащие oo на второй и третьей позициях |
| 4 | WHERE col LIKE ‘f%%’ | Любые значения, начинающиеся с f и состоящие как минимум из 1 символа |
| 5 | WHERE col LIKE ‘%oo’ | Любые значения, оканчивающиеся на oo |
| 6 | WHERE col LIKE ‘_o%o’ | Любые значения, содержащие o на второй позиции и оканчивающиеся на o |
| 7 | WHERE col LIKE ‘f_o’ | Любые значения, содержащие f и o на первой и третьей позициях, соответственно, и состоящие из трех символов |
Сделаем выборку неактивных пользователей:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 2 | Vika | 26 | Ekaterinburg | inactive |
| 4 | Oleg | 28 | Moscow | inactive |
Сделаем выборку пользователей 30 лет и старше:
REGEX
Предложение REGEX позволяет определять регулярное выражение, которому должна соответствовать запись.
В регулярное выражении могут использоваться следующие специальные символы:
Сделаем выборку пользователей с именами Igor и Vika :
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 30 | Moscow | active |
| 2 | Vika | 26 | Ekaterinburg | inactive |
Предложение TOP / LIMIT / ROWNUM
Данные предложения позволяют извлекать указанное количество или процент записей с начала таблицы. Разные СУБД поддерживают разные предложения.
Сделаем выборку первых трех пользователей:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 30 | Moscow | active |
| 2 | Vika | 26 | Ekaterinburg | inactive |
| 3 | Elena | 27 | Ekaterinburg | active |
Параметр offset (смещение) определяет количество пропускаемых записей. Например, так можно извлечь первых двух пользователей, начиная с третьего:
Предложения ORDER BY и GROUP BY
ORDER BY
Предложение ORDER BY используется для сортировки данных по возрастанию ( ASC ) или убыванию ( DESC ). Многие СУБД по умолчанию выполняют сортировку по возрастанию.
Обратите внимание: колонки для сортировки должны быть указаны в списке колонок для выборки.
Сделаем выборку пользователей, отсортировав их по городу и возрасту:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 2 | Vika | 26 | Ekaterinburg | inactive |
| 3 | Elena | 27 | Ekaterinburg | active |
| 1 | Igor | 25 | Moscow | active |
| 4 | Oleg | 28 | Moscow | inactive |
Теперь выполним сортировку по убыванию:
Определим собственный порядок сортировки по убыванию:
GROUP BY
Сгруппируем активных пользователей по городам:
Ключевое слово DISTINCT
Ключевое слово DISTINCT используется совместно с инструкцией SELECT для возврата только уникальных записей (без дубликатов).
Сделаем выборку городов проживания пользователей:
Соединения
Соединения (joins) используются для комбинации записей двух и более таблиц.
| orderId | date | userId | amount |
|---|---|---|---|
| 101 | 2021-06-21 00:00:00 | 2 | 3000 |
| 102 | 2021-06-20 00:00:00 | 2 | 1500 |
| 103 | 2021-06-19 00:00:00 | 3 | 2000 |
| 104 | 2021-06-18 00:00:00 | 3 | 1000 |
| userId | userName | age | amount |
|---|---|---|---|
| 2 | Vika | 26 | 3000 |
| 2 | Vika | 26 | 1500 |
| 3 | Elena | 27 | 2000 |
| 3 | Elena | 27 | 1000 |
Существуют разные типы объединений:
Предложение UNION
Однако, они могут быть разной длины.
Объединим наши таблицы users и orders :
| userId | userName | amount | date |
|---|---|---|---|
| 1 | Igor | NULL | NULL |
| 2 | Vika | 3000 | 2021-06-21 00:00:00 |
| 2 | Vika | 1500 | 2021-06-20 00:00:00 |
| 3 | Elena | 2000 | 2021-06-19 00:00:00 |
| 3 | Elena | 1000 | 2021-06-18 00:00:00 |
| 4 | Alex | NULL | NULL |
Предложение UNION ALL
Существует еще два предложения, похожих на UNION :
Синонимы
Синонимы (aliases) позволяют временно изменять названия таблиц и колонок. «Временно» означает, что новое название используется только в текущем запросе, в БД название остается прежним.
Синтаксис синонима таблицы:
Синтаксис синонима колонки:
Пример использования синонимов таблиц:
| userId | userName | age | amount |
|---|---|---|---|
| 2 | Vika | 26 | 3000 |
| 2 | Vika | 26 | 1500 |
| 3 | Elena | 27 | 2000 |
| 3 | Elena | 27 | 1000 |
Пример использования синонимов колонок:
Индексы
Создание индексов
Индексы — это специальные поисковые таблицы (lookup tables), которые используются движком БД в целях более быстрого извлечения данных. Проще говоря, индекс — это указатель или ссылка на данные в таблице.
К индексам можно применять ограничение UNIQUE для того, чтобы обеспечить их уникальность.
Синтаксис создания индекса:
Синтаксис создания индекса для одной колонки:
Синтакис создания уникальных индексов (такие индексы используются не только для повышения производительности, но и для обеспечения согласованности данных):
Синтаксис создания индексов для нескольких колонок (композиционный индекс):
Решение о создании индексов для одной или нескольких колонок следует принимать на основе того, какие колонки будут часто использоваться в запросе WHERE в качестве условия для сортировки строк.
Для ограничений PRIMARY KEY и UNIQUE автоматически создаются неявные индексы.
Удаление индексов
Для удаления индексов используется инструкция DROP INDEX :
Несмотря на то, что индексы предназначены для повышения производительности БД, существуют ситуации, в которых их использования лучше избегать.
К таким ситуациям относится следующее:
Обновление таблицы
Команда ALTER TABLE используется для добавления, удаления и модификации колонок существующей таблицы. Также эта команда используется для добавления и удаления ограничений.
Добавляем в таблицу users новую колонку — пол пользователя:
Удаляем эту колонку:
Очистка таблицы
Команда TRUNCATE TABLE используется для очистки таблицы. Ее отличие от DROP TABLE состоит в том, что сохраняется структура таблицы ( DROP TABLE полностью удаляет таблицу и все ее данные).
Очищаем таблицу users :
Проверяем, что users пустая:
Представления
Представление (view) — это не что иное, как инструкция, записанная в БД под определенным названием. Другими словами, представление — это композиция таблицы в форме предварительно определенного запроса.
Представления могут содержать все или только некоторые строки таблицы. Представление может быть создано на основе одной или нескольких таблиц (это зависит от запроса для создания представления).
Представления — это виртутальные таблицы, позволяющие делать следующее:
Создание представления
Создаем представление для имен и возраста пользователей:
Получаем данные с помощью представления:
WITH CHECK OPTION
Если условие не удовлетворяется, выбрасывается исключение.
Обновление представления
Представление может быть обновлено при соблюдении следующих условий:
Пример обновления возраста пользователя с именем Igor в представлении:
Обратите внимание: обновление строки в представлении приводит к ее обновлению в базовой таблице.
С помощью команды DELETE можно удалять строки из представления.
Удаляем из представления пользователя, возраст которого составляет 26 лет:
Обратите внимание: удаление строки в представлении приводит к ее удалению в базовой таблице.
Удаление представления
Для удаления представления используется инструкция DROP VIEW :
Удаляем представление usersView :
HAVING
Транзакции
Транзакция — это единица работы или операции, выполняемой над БД. Это последовательность операций, выполняемых в логическом порядке. Эти операции могут запускаться как пользователем, так и какой-либо программой, функционирующей в БД.
Транзакция — это применение одного или более изменения к БД. Например, при создании/обновлении/удалении записи мы выполняем транзакцию. Важно контролировать выполнение таких операций в целях обеспечения согласованности данных и обработки возможных ошибок.
На практике, запросы, как правило, не отправляются в БД по одному, они группируются и выполняются как часть транзакции.
Свойства транзакции
Транзакции имеют 4 стандартных свойства (ACID):
Управление транзакцией
Для управления транзакцией используются следующие команды:
Удаляем пользователя, возраст которого составляет 26 лет, и отправляем изменения в БД:
Удаляем пользователя с именем Oleg и отменяем эту операцию:
Контрольные точки создаются с помощью такого синтаксиса:
Возврат к контрольной точке выполняется так:
Делаем выборку пользователей:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 31 | Moscow | active |
| 3 | Elena | 27 | Ekaterinburg | active |
| 4 | Oleg | 28 | Moscow | inactive |
Как видим, из таблицы был удален только пользователь с возрастом 26 лет.
Команда SET TRANSACTION используется для инициализации транзакции, т.е. начала ее выполнения. При этом, можно определять некоторые характеристики транзакции. Например, так можно определить уровень доступа транзакции (доступна только для чтения или для записи тоже):
Временные таблицы
Некоторые СУБД поддерживают так называемые временные таблицы (temporary tables). Такие таблицы позволяют хранить и обрабатывать промежуточные результаты с помощью таких же запросов, как и при работе с обычными таблицами.
Временные таблицы могут быть очень полезными при необходимости хранения временных данных. Одной из главных особенностей таких таблиц является то, что они удаляются по завершении текущей сессии. При запуске скрипта временная таблица удаляется после завершения выполнения этого скрипта. При доступе к БД с помощью клиентской программы, такая таблица будет удалена после закрытия этой программы.
Клонирование таблицы
Может возникнуть ситуация, когда потребуется получить точную копию существующей таблицы, а CREATE TABLE или SELECT окажется недостаточно в силу того, что мы хотим получить не только идентичную структуру, но также индексы, значения по умолчанию и т.д. копируемой таблицы.
Подзапросы
Подзапрос — это внутренний (вложенный) запрос другого запроса, встроенный (вставленный) с помощью WHERE или других инструкций.
Подзапрос используется для получения данных, которые будут использованы основным запросом в качестве условия для фильтрации возвращаемых записей.
Правила использования подзапросов:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 30 | Moscow | active |
| 3 | Elena | 27 | Ekaterinburg | active |
Данные, возвращаемые подзапросом, могут использоваться и для удаления записей.
Последовательности
Последовательность — это набор целых чисел (1, 2, 3 и т.д.), генерируемых автоматически. Последовательности часто используются в БД, поскольку многие приложения нуждаются в уникальных значениях, используемых для идентификации строк.
Простейшим способом определения последовательности является использование AUTO_INCREMENT при создании таблицы:
Для того, чтобы заново пронумеровать строки с помощью автоматически генерируемых значений (например, при удалении большого количества строк), можно удалить колонку, содержащую такие значения и создать ее заново. Обратите внимание: такая таблица не должна быть частью объединения.



