Комплексное руководство по сверточным нейронным сетям для чайников
В сфере Искусственного интеллекта наблюдается стремительный рывок в устранении разрыва между возможностями человека и машин. И ученые, и любители, работая над многочисленными проблемами в этой области, делают удивительные вещи. Одним из многих таких направлений является Computer Vision (компьютерное зрение).
Повестка дня в этой области состоит в том, чтобы дать возможность машинам видеть мир так, как это делают люди, воспринимать его схожим образом и даже использовать знания для множества задач, таких как Распознавание Изображений и Видео, Анализ и Классификация Изображений, Восстановление Медиа, Системы Рекомендаций, Обработка Естественного языка и т.д. Достижения в области Computer Vision и Deep Learning были разрабатывались и совершенствовались с течением времени, главным образом благодаря совершенно конкретному алгоритму — Сверточной нейронной сети (Convolutional Neural Network).
Введение
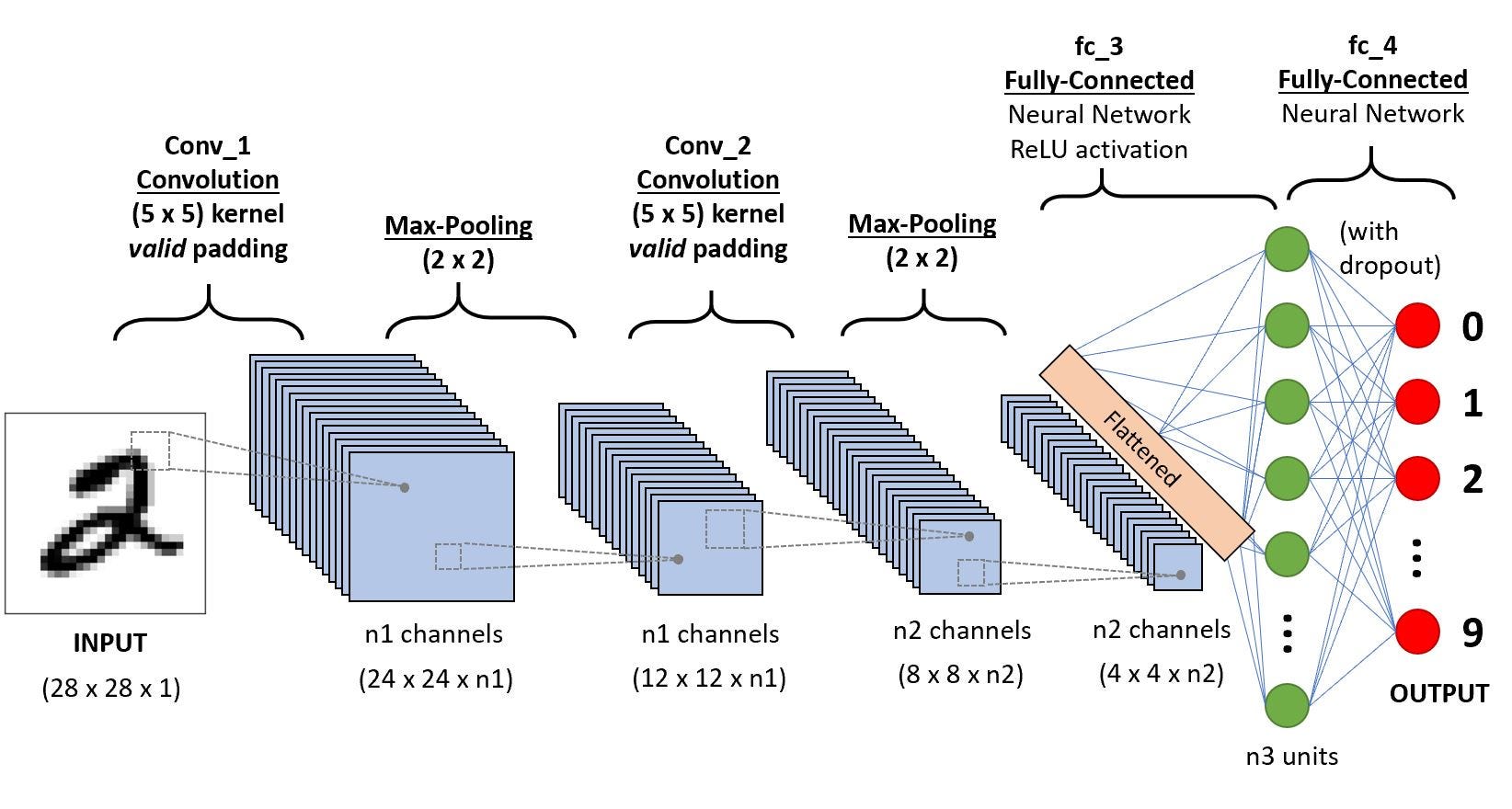 CNN-последовательность для классификации рукописных цифр
CNN-последовательность для классификации рукописных цифр
Сверточная нейронная сеть (Convolutional Neural Network — ConvNet/CNN) — это Deep Learning-алгоритм, который может принимать входное изображение, присваивать важность (усваиваемые веса и смещения) различным областям/объектам в изображении и может отличать одно от другого. Предварительной обработки в ConvNet требуется значительно меньше по сравнению с другими алгоритмами классификации. В то время как в примитивных методах фильтры сконструированы вручную, ConvNets при достаточном обучении способны изучать эти фильтры/характеристики.
Архитектура ConvNet схожа с архитектурой связности нейронов в человеческом мозге и была вдохновлена организацией зрительной коры. Отдельные нейроны реагируют на раздражители только в ограниченной зоне поля зрения, известной как рецептивное поле. Совокупность таких полей накладывается, чтобы покрыть всю зону поля зрения.
ConvNets или Feed-Forward Neural Nets (FF, FFNN — Нейронные сети прямого распространения)?
 Сглаживание матрицы изображения 3х3 по вектору 9х1
Сглаживание матрицы изображения 3х3 по вектору 9х1
На изображении не что иное, как матрица пиксельных значений, верно? Так почему бы просто не сгладить изображение (например, матрицу изображения 3×3 по вектору 9×1) и передать его в многослойный персептрон для классификации? Ну… Все не так просто.
В случае очень простых двоичных изображений этот метод может показывать среднюю оценку точности при прогнозировании классов, но когда речь идет о сложных изображениях, имеющих повсеместную зависимость от пикселей, ни о какой точности не может идти и речи.
ConvNet хорошо умеет захватывать пространственно-временные зависимости в изображении с помощью соответствующих фильтров. Архитектура обеспечивает лучшее совпадение с набором данных изображения благодаря уменьшению количества задействованных параметров и возможности повторного использования весов. Другими словами, сеть можно научить лучше понимать сложность изображения.
Входное изображение
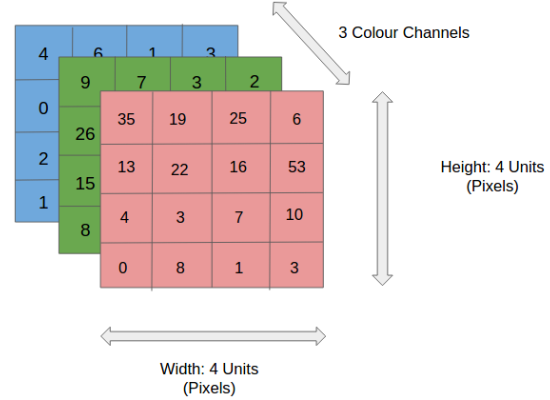 RGB-картинка 4x4x3
RGB-картинка 4x4x3
На рисунке у нас есть RGB-изображение, разделенное по трем цветовым плоскостям — красной, зеленой и синей. Существует несколько таких цветовых пространств, в которых существуют изображения: Grayscale (оттенки серого), RGB, HSV, CMYK и т.д.
Можете представить, что станет с вычислительными ресурсами, когда изображения достигнут размеров, скажем, 8K (7680 × 4320). ConvNet нужен, чтобы преобразовать изображения в ту форму, которую легче обрабатывать без потери характеристик, которые имеют решающую роль для получения хорошего прогноза. Это важно, когда мы хотим разработать архитектуру, которая будет не просто хороша в обучении, но еще и масштабируема для массивных наборов данных.
Сверточный слой — Кернел (the kernel)
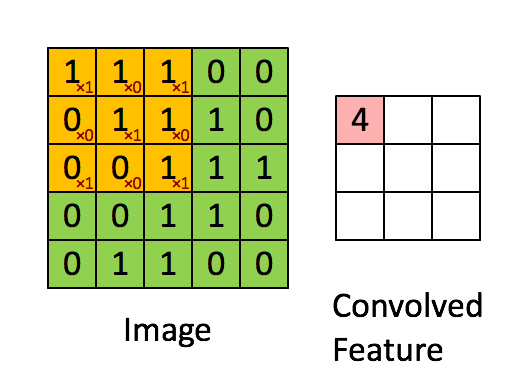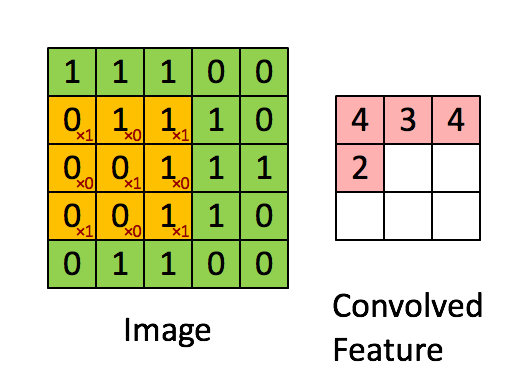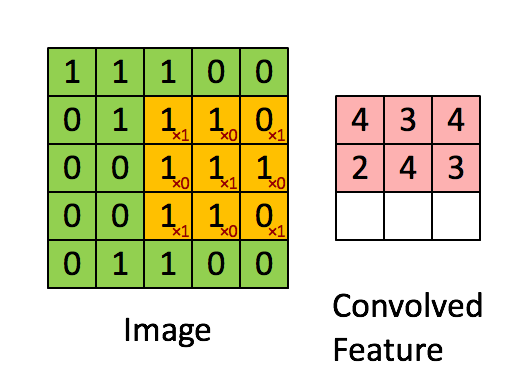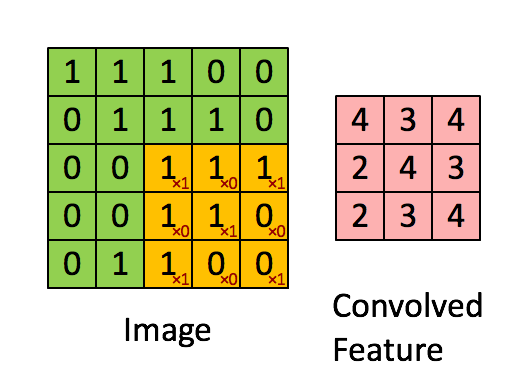 Свертывание изображения 5x5x1 с кернелом размерностью 3x3x1 для получения свернутой функции 3x3x1
Свертывание изображения 5x5x1 с кернелом размерностью 3x3x1 для получения свернутой функции 3x3x1
Размеры изображения = 5 (высота) x 5 (ширина) x 1 (количество каналов, например, RGB)
На гифке выше видно, что зеленая часть напоминает наше входное изображение 5x5x1, I. Элемент, участвующий в выполнении операции свертки в первой части сверточного слоя, называется кернелом/фильтром, K, показан желтым цветом. Мы выбрали K в качестве матрицы 3x3x1.
Кернел смещается 9 раз, так как длина страйда (Stride) = 1, каждый раз выполняя операцию умножения матриц между K и частью P изображения, над которым кернел зависает.
 Передвижение кернела
Передвижение кернела
Фильтр двигается вправо с определенным значением страйда до тех пор, пока он не проанализирует всю ширину. Двигаясь дальше, он переходит к началу (слева) изображения с тем же значением шага и повторяет процесс до тех пор, пока не будет пройдено все изображение.
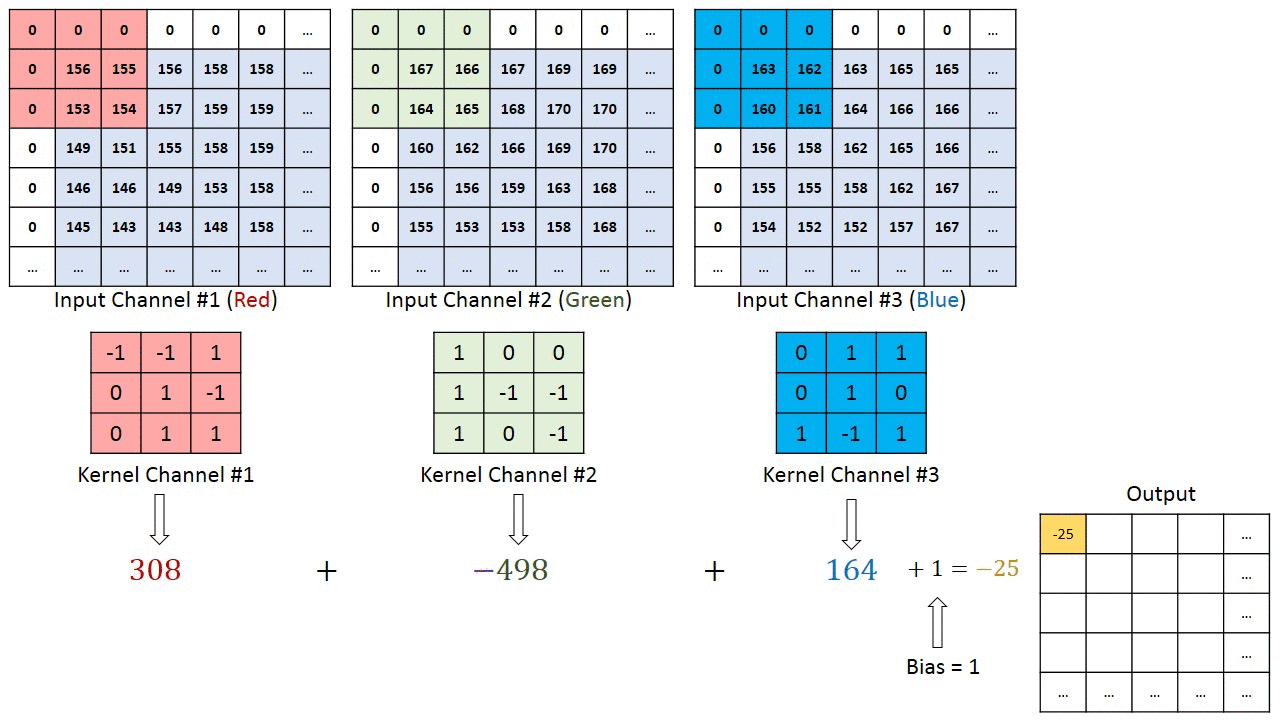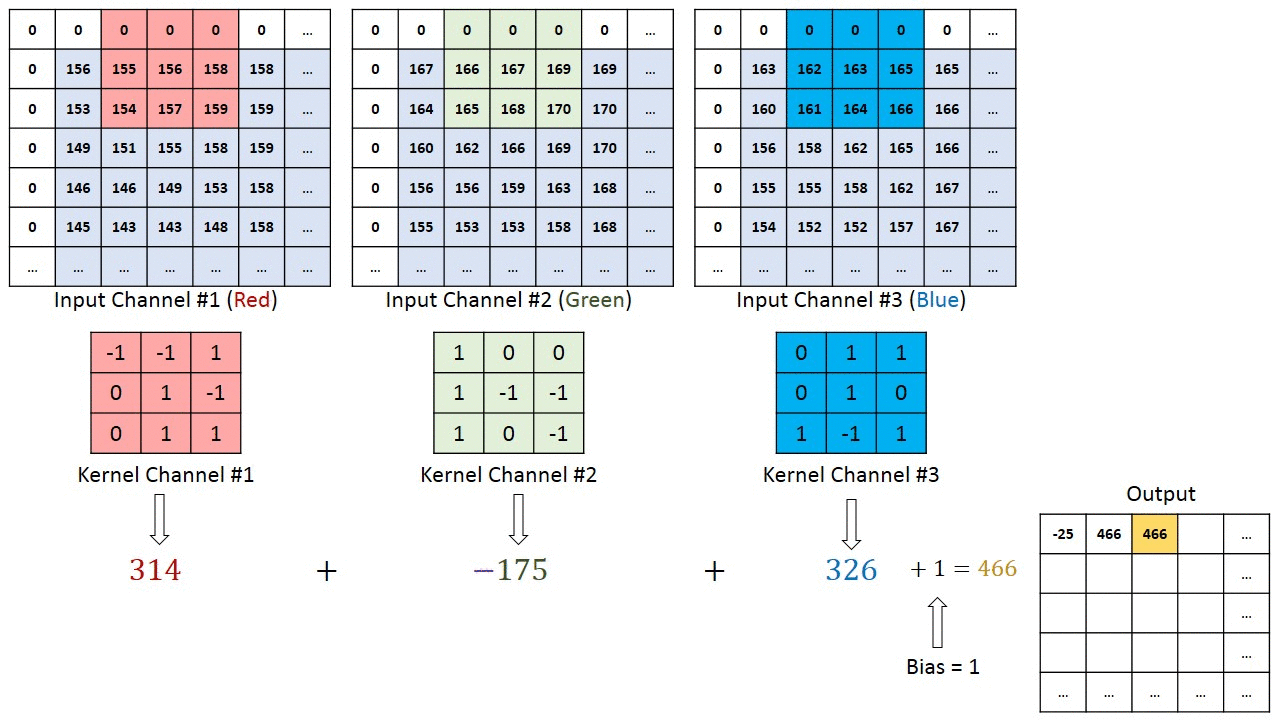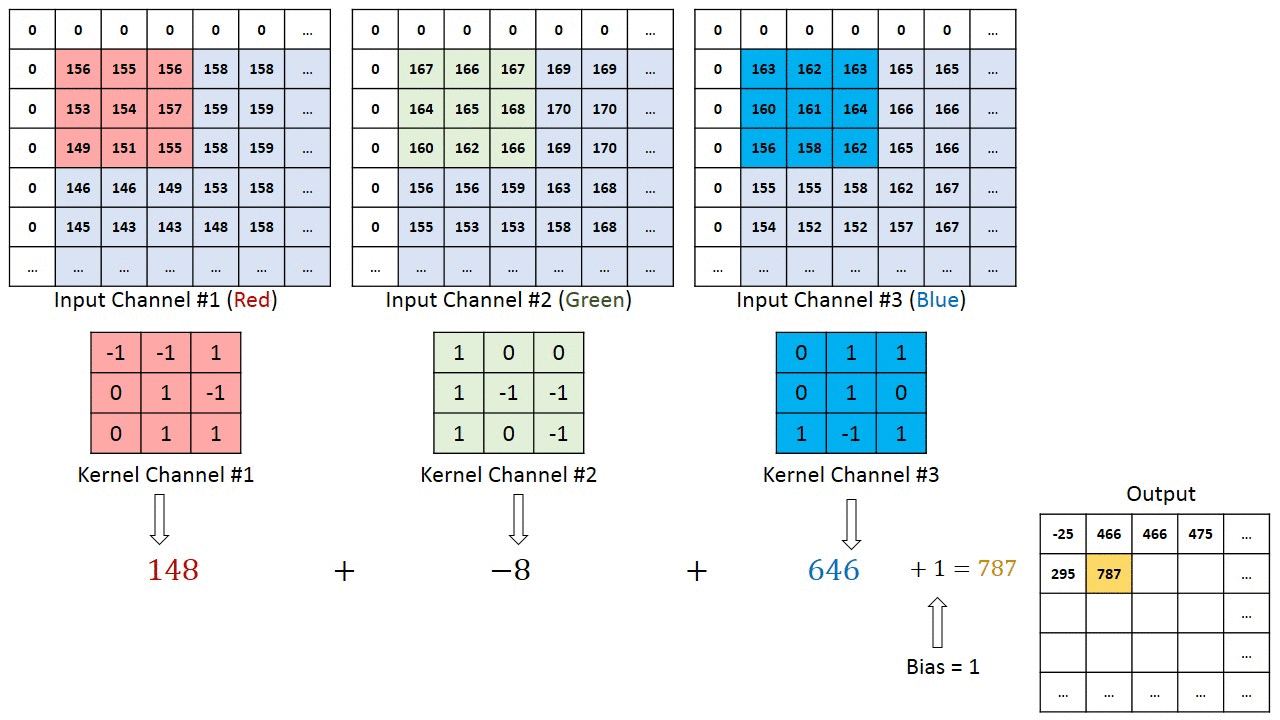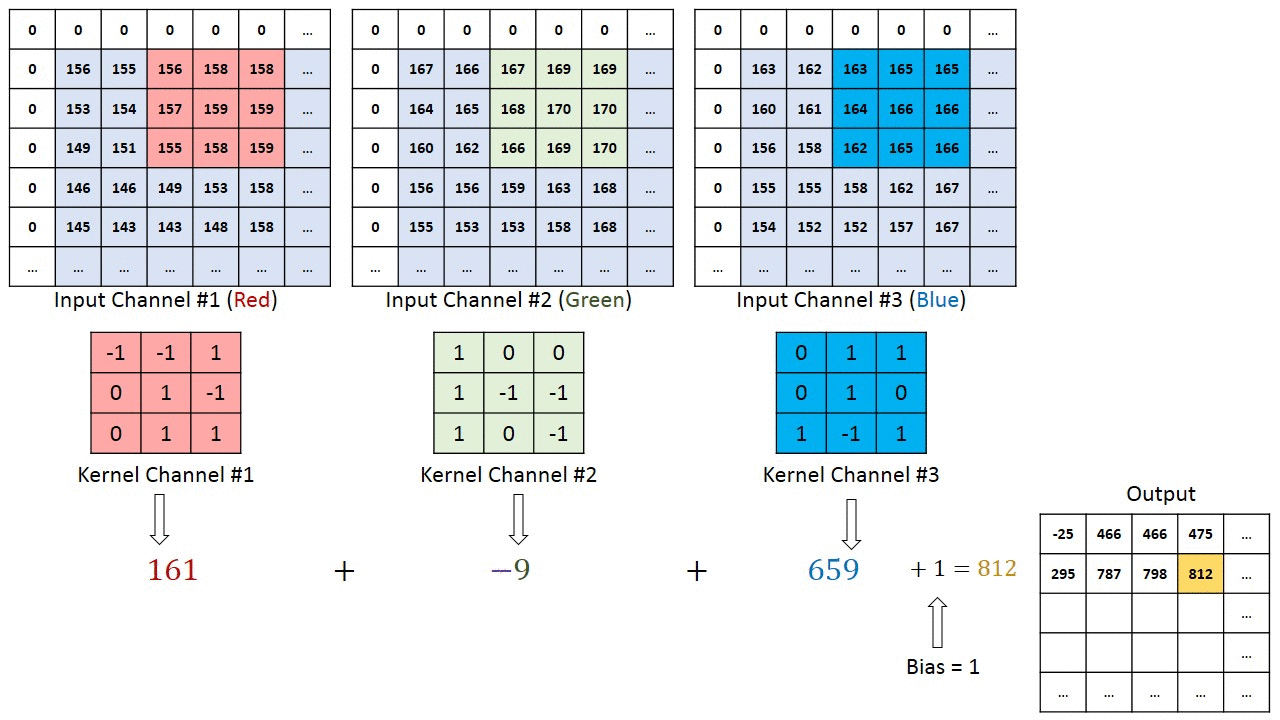 Операция свертки на матрице изображения MxNx3 с кернелом размерностью 3x3x3
Операция свертки на матрице изображения MxNx3 с кернелом размерностью 3x3x3
В случае, когда у изображения несколько каналов (например, RGB), кернел имеет ту же глубину, что и входное изображение. Матричное умножение выполняется между стэками Kn и In ([K1, I1]; [K2, I2]; [K3, I3]), и все результаты суммируются со смещением, чтобы выдать нам сжатый выходной сигнал одной глубины.
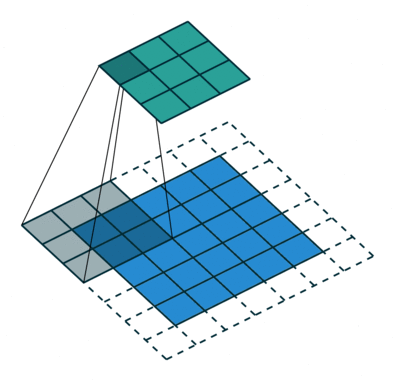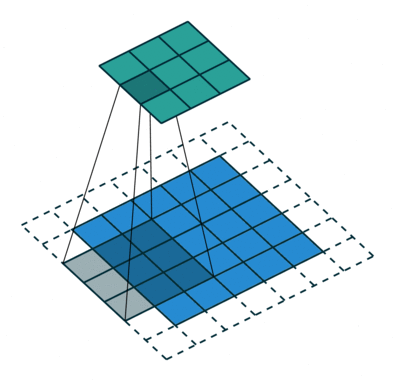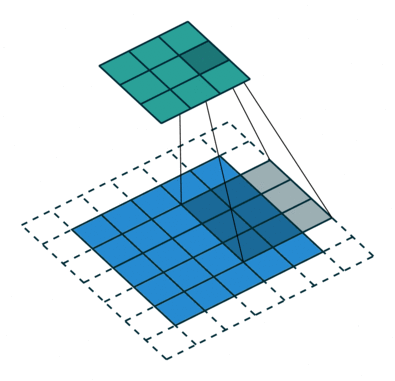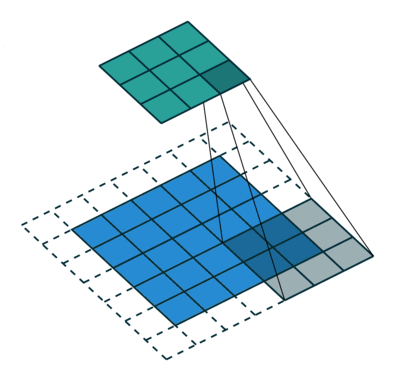 Операция свертки с длиной страйда = 2
Операция свертки с длиной страйда = 2
Цель операции свертки — извлечь из входного изображения высокоуровневые признаки, например, линии, края. ConvNets вовсе не обязательно должны быть ограничены только одним сверточным слоем. Традиционно, первый ConvLayer отвечает за захват низкоуровневых признаков, таких как края, цвет, градиентная ориентация и т.д. Благодаря добавленным слоям архитектура адаптируется также к высокоуровневым признакам, выдавая нам сеть, которая имеет столь же здравое понимание изображений в наборе данных, что и мы.
Эта операция может давать два типа результатов: один, в котором свернутый признак имеет меньшую размерность по сравнению с входным, в другом же размерность либо увеличивается, либо остается неизменной. Это делается путем применения паддинга без дополнения (Valid Padding) в случае первого или паддинга с дополнением нулями (Same Padding) в случае последнего.
 Same-паддинг: изображение 5x5x1 дополняется (is padded) нулями, чтобы создать изображение 6x6x1
Same-паддинг: изображение 5x5x1 дополняется (is padded) нулями, чтобы создать изображение 6x6x1
Когда мы преобразуем изображение 5x5x1 в изображение 6x6x1, а затем применяем к нему кернел размерностью 3x3x1, мы обнаруживаем, что размер свернутой матрицы — 5x5x1. Отсюда и название — Same-паддинг.
В то же время если мы выполним ту же операцию без паддинга, мы получим матрицу, которая имеет размеры самого кернела (3x3x1) — Valid-паддинг.
В данном репозитории хранится множество таких GIF-файлов, которые помогут вам лучше понять, как взаимодействуют паддинг и длина страйда для достижения результатов, соответствующих нашим потребностям.
Пулинговый слой (Pooling Layer)
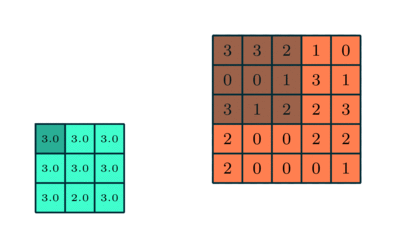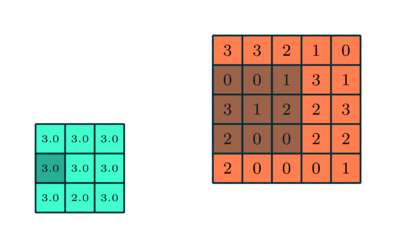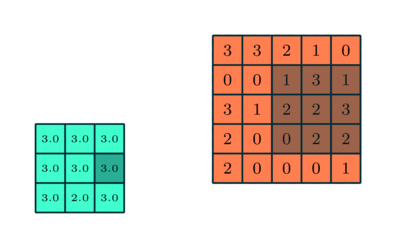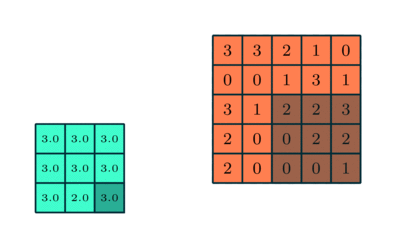 3×3 преобразуется с помощью пулинга в сложную функцию 5×5
3×3 преобразуется с помощью пулинга в сложную функцию 5×5
Подобно сверточному слою, пулинговый слой необходим для уменьшения размера свернутого элемента в пространстве. Это помогает уменьшить вычислительную мощность, необходимую для обработки данных, за счет уменьшения размерности. Кроме того, это важно и для извлечения доминирующих признаков, инвариантных вращения и позиционирования, таким образом поддерживая процесс эффективного обучения модели.
Существует два типа пулинга: максимальный (Max Pooling) и средний (Average Pooling). Максимальный пулинг возвращает максимальное значение из части изображения, покрываемой кернелом. А Средний пулинг возвращает среднее всех значений из части изображения, покрываемой кернелом.
Максимальный пулинг также выступает в роли шумоподавителя (Noise Suppressant). Он полностью исключает шумовые сигналы, а также совмещает подавление шума с уменьшением размерности. Средний же пулинг просто использует уменьшение размерности как способ подавления шума. То есть можно сказать, что Max Pooling работает намного лучше, чем Average Pooling.
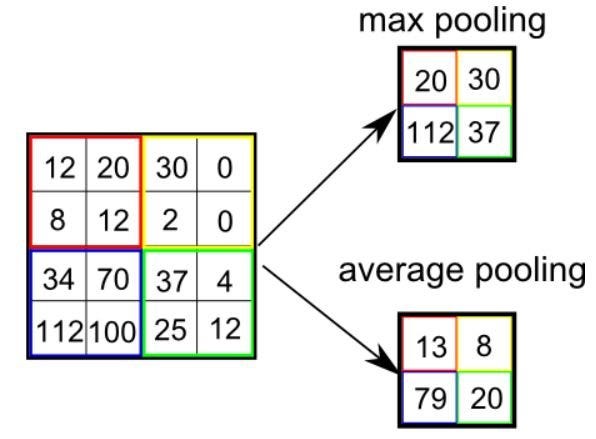 Типы пулинга
Типы пулинга
Сверточный слой и пулинговый слой вместе образуют i-й слой сверточной нейронной сети. В зависимости от сложности изображений количество таких слоев может быть увеличено с целью еще более точного захвата деталей низкого уровня, но ценой большей вычислительной мощности.
Выполнение описанного выше процесса позволяет модели успешно изучить признаки. Далее мы сглаживаем окончательный результат и передаем его в обычную нейронную сеть в целях классификации.
Классификация — Полностью Связанный Слой (Fully Connected Layer, FC Layer)

Добавление FC Layer — это (обычно) дешевый способ изучить нелинейные комбинации высокоуровневых признаков, представленных выходными данными сверточного слоя. FC Layer изучает возможную нелинейную функцию в этом пространстве.
Теперь, когда мы преобразовали наше входное изображение в подходящий формат для нашего многослойного персептрона, мы сведем изображение в вектор-столбец. Сглаженный вывод подается в нейронную сеть с прямой связью, и затем к каждой итерации обучения применяется обратное распространение. После серии эпох (epochs) модель способна различать доминирующие и некоторые низкоуровневые признаки изображений и классифицировать их с помощью техники Softmax.
Существуют множество архитектур доступных CNN, которые сыграли ключевую роль в построении алгоритмов, которые обеспечивают сейчас и будут обеспечивать работу Искусственного интеллекта как такового в ближайщем будущем. Некоторые из них перечисляю ниже:
Сверточная нейронная сеть, часть 1: структура, топология, функции активации и обучающее множество
Предисловие
Данные статьи (часть 2) являются частью моей научной работы в ВУЗе, которая звучала так: «Программный комплекс детектирования лиц в видеопотоке с использованием сверточной нейронной сети». Цель работы была — улучшение скоростных характеристик в процессе детектирования лиц в видеопотоке. В качестве видеопотока использовалась камера смартфона, писалось десктопное ПС (язык Kotlin) для создания и обучения сверточной нейросети, а также мобильное приложение под Android (язык Kotlin), которая использовала обученную сеть и «пыталась» распознать лица из видеопотока камеры. Результаты скажу получились так себе, использовать точную копию предложенной мной топологии на свой страх и риск (я бы не рекомендовал).
Введение
Наилучшие результаты в области распознавания лиц показала Convolutional Neural Network или сверточная нейронная сеть (далее – СНС), которая является логическим развитием идей таких архитектур НС как когнитрона и неокогнитрона. Успех обусловлен возможностью учета двумерной топологии изображения, в отличие от многослойного персептрона.
Сверточные нейронные сети обеспечивают частичную устойчивость к изменениям масштаба, смещениям, поворотам, смене ракурса и прочим искажениям. Сверточные нейронные сети объединяют три архитектурных идеи, для обеспечения инвариантности к изменению масштаба, повороту сдвигу и пространственным искажениям:

Именно поэтому в своей работе я использовал сверточную нейронную сеть, основанную на принципах неокогнитрона и дополненную обучением по алгоритму обратного распространения ошибки.
Структура сверточной нейронной сети
СНС состоит из разных видов слоев: сверточные (convolutional) слои, субдискретизирующие (subsampling, подвыборка) слои и слои «обычной» нейронной сети – персептрона, в соответствии с рисунком 1.
Рисунок 1 – топология сверточной нейронной сети
Первые два типа слоев (convolutional, subsampling), чередуясь между собой, формируют входной вектор признаков для многослойного персептрона.
Свое название сверточная сеть получила по названию операции – свертка, суть которой будет описана дальше.
Сверточные сети являются удачной серединой между биологически правдоподобными сетями и обычным многослойным персептроном. На сегодняшний день лучшие результаты в распознавании изображений получают с их помощью. В среднем точность распознавания таких сетей превосходит обычные ИНС на 10-15%. СНС – это ключевая технология Deep Learning.
Основной причиной успеха СНС стало концепция общих весов. Несмотря на большой размер, эти сети имеют небольшое количество настраиваемых параметров по сравнению с их предком – неокогнитроном. Имеются варианты СНС (Tiled Convolutional Neural Network), похожие на неокогнитрон, в таких сетях происходит, частичный отказ от связанных весов, но алгоритм обучения остается тем же и основывается на обратном распространении ошибки. СНС могут быстро работать на последовательной машине и быстро обучаться за счет чистого распараллеливания процесса свертки по каждой карте, а также обратной свертки при распространении ошибки по сети.
На рисунке ниже продемонстрирована визуализация свертки и подвыборки:
Топология сверточной нейросети
Определение топологии сети ориентируется на решаемую задачу, данные из научных статей и собственный экспериментальный опыт.
Можно выделить следующие этапы влияющие на выбор топологии:
Рисунок 2 — Топология сверточной нейросети
Входной слой
Входные данные представляют из себя цветные изображения типа JPEG, размера 48х48 пикселей. Если размер будет слишком велик, то вычислительная сложность повысится, соответственно ограничения на скорость ответа будут нарушены, определение размера в данной задаче решается методом подбора. Если выбрать размер слишком маленький, то сеть не сможет выявить ключевые признаки лиц. Каждое изображение разбивается на 3 канала: красный, синий, зеленый. Таким образом получается 3 изображения размера 48х48 пикселей.
Входной слой учитывает двумерную топологию изображений и состоит из нескольких карт (матриц), карта может быть одна, в том случае, если изображение представлено в оттенках серого, иначе их 3, где каждая карта соответствует изображению с конкретным каналом (красным, синим и зеленым).
Входные данные каждого конкретного значения пикселя нормализуются в диапазон от 0 до 1, по формуле:
Сверточный слой
Сверточный слой представляет из себя набор карт (другое название – карты признаков, в обиходе это обычные матрицы), у каждой карты есть синаптическое ядро (в разных источниках его называют по-разному: сканирующее ядро или фильтр).
Количество карт определяется требованиями к задаче, если взять большое количество карт, то повысится качество распознавания, но увеличится вычислительная сложность. Исходя из анализа научных статей, в большинстве случаев предлагается брать соотношение один к двум, то есть каждая карта предыдущего слоя (например, у первого сверточного слоя, предыдущим является входной) связана с двумя картами сверточного слоя, в соответствии с рисунком 3. Количество карт – 6.
Рисунок 3 — Организация связей между картами сверточного слоя и предыдущего
Размер у всех карт сверточного слоя – одинаковы и вычисляются по формуле 2:
Ядро представляет из себя фильтр или окно, которое скользит по всей области предыдущей карты и находит определенные признаки объектов. Например, если сеть обучали на множестве лиц, то одно из ядер могло бы в процессе обучения выдавать наибольший сигнал в области глаза, рта, брови или носа, другое ядро могло бы выявлять другие признаки. Размер ядра обычно берут в пределах от 3х3 до 7х7. Если размер ядра маленький, то оно не сможет выделить какие-либо признаки, если слишком большое, то увеличивается количество связей между нейронами. Также размер ядра выбирается таким, чтобы размер карт сверточного слоя был четным, это позволяет не терять информацию при уменьшении размерности в подвыборочном слое, описанном ниже.
Ядро представляет собой систему разделяемых весов или синапсов, это одна из главных особенностей сверточной нейросети. В обычной многослойной сети очень много связей между нейронами, то есть синапсов, что весьма замедляет процесс детектирования. В сверточной сети – наоборот, общие веса позволяет сократить число связей и позволить находить один и тот же признак по всей области изображения.
Неформально эту операцию можно описать следующим образом — окном размера ядра g проходим с заданным шагом (обычно 1) все изображение f, на каждом шаге поэлементно умножаем содержимое окна на ядро g, результат суммируется и записывается в матрицу результата, как на рисунке 4.
Рисунок 4 — Операция свертки и получение значений сверточной карты (valid)
Операция свертки и получение значений сверточной карты. Ядро смещено, новая карта получается того же размера, что и предыдущая (same)
При этом в зависимости от метода обработки краев исходной матрицы результат может быть меньше исходного изображения (valid), такого же размера (same) или большего размера (full), в соответствии с рисунком 5.
Рисунок 5 — Три вида свертки исходной матрицы
В упрощенном виде этот слой можно описать формулой:
При этом за счет краевых эффектов размер исходных матриц уменьшается, формула:
Подвыборочный слой
Подвыборочный слой также, как и сверточный имеет карты, но их количество совпадает с предыдущим (сверточным) слоем, их 6. Цель слоя – уменьшение размерности карт предыдущего слоя. Если на предыдущей операции свертки уже были выявлены некоторые признаки, то для дальнейшей обработки настолько подробное изображение уже не нужно, и оно уплотняется до менее подробного. К тому же фильтрация уже ненужных деталей помогает не переобучаться.
В процессе сканирования ядром подвыборочного слоя (фильтром) карты предыдущего слоя, сканирующее ядро не пересекается в отличие от сверточного слоя. Обычно, каждая карта имеет ядро размером 2×2, что позволяет уменьшить предыдущие карты сверточного слоя в 2 раза. Вся карта признаков разделяется на ячейки 2х2 элемента, из которых выбираются максимальные по значению.
Обычно в подвыборочном слое применяется функция активации RelU. Операция подвыборки (или MaxPooling – выбор максимального) в соответствии с рисунком 6.
Рисунок 6 — Формирование новой карты подвыборочного слоя на основе предыдущей карты сверточного слоя. Операция подвыборки (Max Pooling)
Формально слой может быть описан формулой:
Полносвязный слой
Последний из типов слоев это слой обычного многослойного персептрона. Цель слоя – классификация, моделирует сложную нелинейную функцию, оптимизируя которую, улучшается качество распознавания.
Нейроны каждой карты предыдущего подвыборочного слоя связаны с одним нейроном скрытого слоя. Таким образом число нейронов скрытого слоя равно числу карт подвыборочного слоя, но связи могут быть не обязательно такими, например, только часть нейронов какой-либо из карт подвыборочного слоя быть связана с первым нейроном скрытого слоя, а оставшаяся часть со вторым, либо все нейроны первой карты связаны с нейронами 1 и 2 скрытого слоя. Вычисление значений нейрона можно описать формулой:
Выходной слой
Выбор функции активации
В данной работе в качестве функции активации в скрытых и выходном слоях применяется гиперболический тангенс, в сверточных слоях применяется ReLU. Рассмотрим наиболее распространенные функций активации, применяемые в нейронных сетях.
Функция активации сигмоиды
Эта функция относится к классу непрерывных функций и принимает на входе произвольное вещественное число, а на выходе дает вещественное число в интервале от 0 до 1. В частности, большие (по модулю) отрицательные числа превращаются в ноль, а большие положительные – в единицу. Исторически сигмоида находила широкое применение, поскольку ее выход хорошо интерпретируется, как уровень активации нейрона: от отсутствия активации (0) до полностью насыщенной активации (1). Сигмоида (sigmoid) выражается формулой:
График сигмоидальной функции в соответствии с рисунком ниже:
Крайне нежелательное свойство сигмоиды заключается в том, что при насыщении функции с той или иной стороны (0 или 1), градиент на этих участках становится близок к нулю.
Напомним, что в процессе обратного распространения ошибки данный (локальный) градиент умножается на общий градиент. Следовательно, если локальный градиент очень мал, он фактически обнуляет общий градиент. В результате, сигнал почти не будет проходить через нейрон к его весам и рекурсивно к его данным. Кроме того, следует быть очень осторожным при инициализации весов сигмоидных нейронов, чтобы предотвратить насыщение. Например, если исходные веса имеют слишком большие значения, большинство нейронов перейдет в состояние насыщения, в результате чего сеть будет плохо обучаться.
Сигмоидальная функция является:
Функция активации гиперболический тангенс
В данной работе в качестве активационной функции для скрытых и выходного слоев используется гиперболический тангенс. Это обусловлено следующими причинами:
Функция активации ReLU
Известно, что нейронные сети способны приблизить сколь угодно сложную функцию, если в них достаточно слоев и функция активации является нелинейной. Функции активации вроде сигмоидной или тангенциальной являются нелинейными, но приводят к проблемам с затуханием или увеличением градиентов. Однако можно использовать и гораздо более простой вариант — выпрямленную линейную функцию активации (rectified linear unit, ReLU), которая выражается формулой:
График функции ReLU в соответствии с рисунком ниже:
Преимущества использования ReLU:
Обучающие выборки использующиеся в экспериментах
Обучающая выборка состоит из положительных и отрицательных примеров. В данном случае из лиц и “не лиц”. Соотношение положительных к отрицательным примерам 4 к 1, 8000 положительных и 2000 отрицательных.
В качестве положительной обучающей выборки использовалась база данных LFW3D [7]. Она содержит цветные изображения фронтальных лиц типа JPEG, размером 90×90 пикселей, в количестве 13000. База данных предоставляется по FTP, доступ осуществляется по паролю. Для получения пароля необходимо заполнить на главной странице сайта простую форму, где указать свое имя и электронную почту. Пример лиц из базы данных показан в соответствии с рисунком ниже:
В качестве отрицательных обучающих примеров использовалась база данных SUN397 [8], она содержит огромное количество всевозможных сцен, которые разбиты по категориям. Всего 130000 изображений, 908 сцен, 313000 объектов сцены. Общий вес этой базы составляет 37 GB. Категории изображений весьма различны и позволяют выбирать более конкретную среду, где будет использоваться конечное ПС. Например, если априори известно, что детектор лиц предназначен только для распознавания внутри помещения, то нет смысла использовать обучающую выборку природы, неба, гор и т.д. По этой причине автором работы были выбраны следующие категории изображений: жилая комната, кабинет, классная комната, компьютерная комната. Примеры изображений из обучающей выборки SUN397 показаны в соответствии с рисунком ниже:
Результаты
Прямое распространение сигнала от входного изображения размером 90х90 пикселей занимает 20 мс (на ПК), 3000 мс в мобильном приложении. При детектировании лица в видеопотоке в разрешении 640х480 пикселей, возможно детектировать 50 не перекрытых областей размером 90х90 пикселей. Полученные результаты с выбранной топологией сети хуже по сравнению с алгоритмом Виолы-Джонса.
Выводы
Сверточные нейронные сети обеспечивают частичную устойчивость к изменениям масштаба, смещениям, поворотам, смене ракурса и прочим искажениям.
Ядро — представляет из себя фильтр, который скользит по всему изображению и находит признаки лица в любом его месте (инвариантность к смещениям).
Подвыборочный слой дает:
Обучение сверточной нейронной сети описано во второй части.
Ссылки
— Виды нейронных сетей (подобная схема классификации нейронных сетей)
— Нейронные сети для начинающих: раз и два.



