Как постичь машинное обучение, если ты не великий математик
Предлагаем почитать перевод статьи Diego Isco с ресурса dev.to. Она будет полезна начинающим специалистам в области ML.

Несколько месяцев назад я изучал проекты, в которых благодаря машинному обучению успешно реализуются невероятные вещи.
И я загорелся этим. Сказал, что хочу этому научиться. Неважно, насколько трудно мне будет. Я хочу научиться, и я научусь.
Будем честны: все мы слышали о зарплатах инженеров по машинному обучению. Взгляните на это.

Впечатляет, правда? Но машинное обучение еще нужно освоить — и вот тут начинается мрак.
Воодушевленный, я начал изучать работы по этой теме, и знаете что? Везде — математика! Навороченные уравнения, линейная алгебра, векторы и странные символы.
В тот вечер я плакал как ребенок. Но, как хороший технарь, утер слезы и решил учиться самостоятельно.
Да, я просто еще один нерд, пытающийся осилить машинное обучение.
Но мне скучно изучать сложные темы. Особенно во время карантина. Поэтому я хочу попробовать что-нибудь другое. Я опишу свой процесс обучения.
Ход обучения
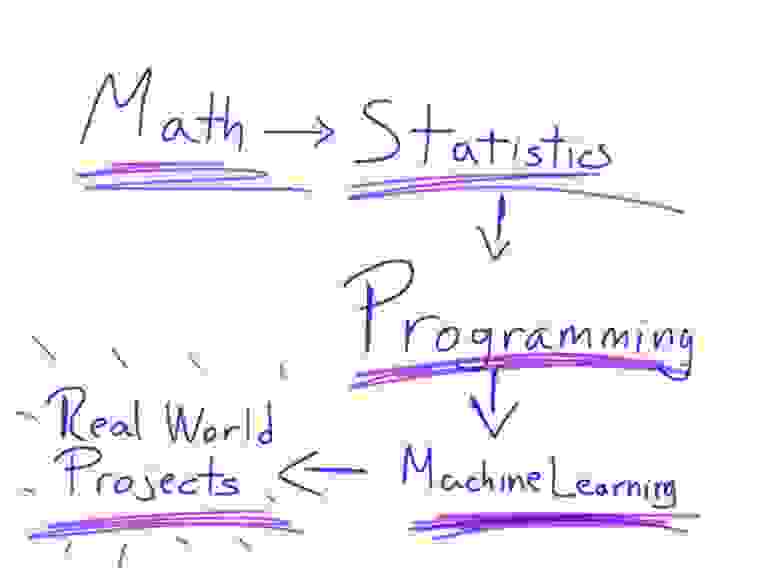
Математика → Статистика → Программирование → Машинное обучение → Любительские проекты
Когда вы будете искать на YouTube видео о машинном обучении, то обязательно наткнетесь на 3 основных — от Siral Raval, Jabril и Daniel Bourke.
Все они — выше всяких похвал. Поэтому я решил взять из этих видео лучшее.
Математика
Много споров по поводу того, насколько хорошо нужно знать математику для освоения машинного обучения. Но знать точно нужно.
Возможно, некоторые из вас чертовски гениальны в математике и вам достаточно вспомнить лишь отдельные вещи. Но большинству простых смертных вроде меня нужно всему учиться с нуля.
Хорошо, а что именно нужно знать? Всего-то линейную алгебру и матанализ.
Напоминаю: я не гений в математике. Я плохо разбираюсь в математике. Я завалил матанализ на всех курсах в университете!
Так вот, можно ли освоить теорию машинного обучения, не будучи гением в математике?
Есть один нюанс. Если вы не дружите с числами, то это потому, что не понимаете основ.
Помните основы? Об основах линейной алгебры и математического анализа рассказывает на канале 3Blue1Brown Грант Сандерсон. Ему надо дать Нобелевскую премию в области образования. Он просто берет математику объясняет ее в потрясающей форме. Как ребенку. Это прекрасно.
Итак, моим первым шагом было понять основы линейной алгебры и математического анализа. Поверьте, после этого все намного проще.
Мы посмотрели и осмыслили эти видео, теперь время применить свои знания на практике — на курсе линейной алгебры от крупнейшего специалиста в сфере преподавания математики — Гилберта Стрэнга из Массачусетского технологического института.
Подумать только: получать такое же образование, что и студенты, заплатившие тысячи долларов за очный курс! Да, диплома одного из лучших университетов мира не будет, но накопленные знания — вот что в итоге имеет значение.
Что ж, мы усвоили этот длинный курс и попрактиковались, теперь черед математического анализа. В Академии Хана есть потрясающая программа, которая дает все, что надо для того, чтобы чувствовать себя уверенно, имея дело с мудреными уравнениями.
Статистика
Многих людей сбивает с толку то, насколько машинное обучение похоже на статистику. На самом деле они тесно связаны друг с другом, так что статистика — ключ к пониманию теории машинного обучения.
Поэтому сосредоточьтесь и учитесь.
А для облегчения этой задачи — бесплатный курс Probability — The Science of Uncertainty and Data от Массачусетского технологического института.
Читая учебную программу, вы можете подумать, что курс базовый, но это не так. Он охватывает достаточно тем, чтобы дать основы для понимания теории вероятности. Всем, кто любит поучиться, вот еще один курс — Statistics and Probability от Академии Хана. Это в дополнение, так что расслабьтесь.
Программирование
Если вы, как и я, инженер-программист, то для вас сейчас будет самое интересное.
Язык программирования, который необходимо знать, это Python. Король машинного обучения. Его простота делает процесс освоения материала очень легким — по крайней мере, поначалу.
Я предполагаю, что вы знаете программирование, так что не хочу пересказывать содержание курсов для изучения Python — их много. Кроме того, есть отличные книги. Вам решать, где набраться знаний.
Кому-то может быть удобнее изучать документацию или пользоваться подпиской на учебную онлайн-платформу, а у кого-то есть любимый учитель на Udemy. Главное, не забывайте практиковаться, чтобы лучше понимать, что происходит при программировании для машинного обучения.
Ладно, допустим, вы не знаете программирования, и это будет ваша первая строчка кода. В таком случае я бы выбрал Datacamp. Смело исследуйте тему самостоятельно и смотрите их курс по Python.
Машинное обучение
Мы уже далеко продвинулись. Изучили математику, статистику, алгоритмы, проплакали несколько ночей. Все ради этого момента.
Курс по машинному обучению от Эндрю Ына — наверное, один из лучших по теме. Он не для новичков, так что не убирайте далеко свои конспекты. Наконец то, как работают алгоритмы машинного обучения, сложится для вас в цельную картинку.
Еще один ресурс — это Introduction to Machine Learning for Coders. Хороший курс с детальными объяснениями алгоритмов машинного обучения.
Советую пройти оба, изучить вопрос с разных сторон, тогда вы сможете сказать, какой курс оказался наиболее понятным.
Не могу не упомянуть еще одну программу, которую очень хвалят. Но она платная: это Introduction to Machine Learning Course нa Udacity. Если у вас отложено немного денег и вы готовы инвестировать в себя, то это подходящий случай, но решайте сами.
Любительские проекты
Теперь вы уже знаете машинное обучение, но этого недостаточно. Вам нужно больше практики. Здесь вам поможет книга Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow.
После этого можно браться за любительские проекты, но уже с лучшими библиотеками машинного обучения. Если вам, как и мне, не нравится опираться на библиотеки без понимания, что к чему, то не волнуйтесь: вы уже разбираетесь. Поэтому я даю эту книгу в самом конце.
И напоследок
Прежде чем завершить, хочу дать несколько советов.
Как изучать Machine Learning 5 дней в неделю 9 месяцев подряд

Я изучал машинное обучение каждый день на протяжении девяти месяцев, а потом получил работу.
Я уволился из Apple. Запустил веб-стартап, но из этого ничего не вышло. Душа к этому не лежала.
Я хотел изучать машинное обучение. Это то, что меня воодушевляло. Я собирался изучить все до малейшей детали. Мне не нужно было программировать все эти правила, все сделают за меня. Но у меня не было работы.
А воодушевление не оплачивает мои счета.
По выходным я начал подрабатывать в Uber, чтобы платить за учебу.
Я обожал общаться с новыми людьми, но ненавидел постоянно быть за рулем. Пробки, тормоз, газ, постоянные мысли о бензине и заправке, воздух, кондиционер, переключение передач, куда можно и куда нельзя ехать, все эти мысли.
Я изучал машинное обучение. Днями напролет, пять дней в неделю. Было сложно. Да и сейчас не легче.
Через девять месяцев после получения своей личной степени по ИИ, я нашёл работу. И это была лучшая работа в моей жизни.
Как у меня получалось заниматься каждый день?
А вот как.
1. Уменьшите пространство поиска
Машинное обучение – это обширная область. Там и код, и математика, вероятность, статистика, данные и алгоритмы.
В учебных ресурсах нет недостатка. А изобилие вариантов равняется их отсутствию.
Если вы серьезно относитесь к обучению, то создайте для себя учебный план. Вместо того, чтобы тратить недели с мыслями о том, следует ли вам учить Python или R, начните курс на Coursera или edX, начините с математики или изучения кода, потратьте одну неделю разрабатывая приблизительный план, а затем придерживайтесь его.
Именно так я пришел к своей собственной степени магистра в области ИИ. Я решил, что сначала изучу код и в качестве языка программирования выбрал Python. Я повсюду искал разные курсы и книги и отобрал те, которые заинтересовали меня больше всего. Всем ли подойдет такой способ? Скорее всего, нет. Но он был моим, поэтому и сработал.
Как только у меня появился учебный план, путь, по которому я мог двигаться, я больше не мог терять времени на размышления. Я мог подняться с кровати, сесть за стол и выучить то, что было нужно (и что хотелось) выучить.
Я не был к себе строг. Если я находил что-то интересное, то сворачивал со своего пути и учил новые вещи.
Вам стоит создать свой собственный путь, если вы учитесь онлайн, а не в университете.
2. Измените свою окружающую обстановку
Первая апельсиновая ферма вашего дедушки потерпела неудачу.
Почва была хорошая. Он посадил семена. Да и оборудование не могло подвести.
Что же случилось?
Было слишком холодно. Апельсины растут при высоких температурах. Ваш дедушка знал как вырастить апельсины, но холодный климат не оставил им ни шанса.
Он переехал в более теплый город и снова попробовал открыть ещё одну ферму.
Через двенадцать месяцев апельсиновый сок вашего дедушки стал лучшим в городе.
Учиться – все равно что выращивать апельсины.
Без мотивации к обучению вам не поможет ни ноутбук, ни интернет, ни лучшие книги.
Почему?
Проблема в том, что вас окружает.
В вашей комнате куча вещей, на которые так легко отвлечься.
Вы пытаетесь заниматься с друзьями, но они не так преданы делу как вы.
Сообщения в Whatsapp приходят каждые семь минут.
Я превратил свою комнату в убежище для занятий. Вымыл её. Отключил все оповещения и положил телефон в комод в другой комнате.
Я предупредил своего друга, что поговорю с ним после 16:00, когда включу телефон. Он согласился.
Я обожаю проводить время с друзьями, но учебное время – только для учебы. Не можете весь день продержаться без телефона? Начните с одного часа. Подойдет любой ящичек, который вы не видите. «Не беспокоить» должно стоять по умолчанию.
Измените окружающую вас обстановку и знания будут течь к вам рекой.
3. Настройте систему так, чтобы вы всегда оставались победителем
Проблема №13 поставила меня в тупик. Я застрял.
Я хотел разобраться с ней ещё вчера, но не смог.
Сейчас мне нужно заниматься, но я так усердно работал вчера и ничего не вышло.
Я откладываю. Знаю, что должен учиться. Но не сегодня.
Черт возьми. Я уже был в подобной ситуации. Однако, ничего не изменилось.
Стопка книг уставилась на меня. Проблема №13. Я завожу таймер. 25 минут. Знаю, что может и не решу проблему, но я могу сесть и попытаться.
Прошло четыре минуты, ощущаю себя как в аду. Просто ужасно, но я не останавливаюсь. Через двадцать четыре минуты я не хочу останавливаться.
Таймер выключается, я завожу новый. И ещё один. Спустя три подхода я решаю проблему. Я говорю себе, что я лучший инженер в мире. Конечно, это неправда, но это не имеет значения.
Даже маленькое достижение – это достижение.
Вы не всегда можете контролировать свои успехи в учебе. Но вы можете контролировать время, уделенное каким-либо вещам.
Можете контролировать: четыре подхода по 25 минут в день.
Не можете контролировать: завершение каждой новой задачи в тот же день.
Настройте систему так, чтобы бы всегда выигрывали.
4. Иногда ничего не делайте
Я пришел вот к какому выводу. Обучение – это самый главный навык. Если я смогу научиться лучше обучаться, то смогу сделать что угодно лучше. Я смогу выучить машинное обучение, смогу стать хорошим программистом, смогу лучше писать. Я решил, что должен усовершенствовать свои способы обучения. И сразу же начал.
Я прошел курс на Coursera «Учимся учиться». Одной из тем было сфокусированное и рассеянное мышление.
Сфокусированное мышление происходит при выполнении одной-единственной задачи.
Рассеянное мышление происходит, когда вы ни о чем не думаете.
На пересечении этих двух способов мышления располагается момент для лучшего обучения. Поэтому именно в душе к нам приходят лучшие идеи и мысли. Потому что там больше ничего не происходит.
Рассеянное мышление позволяет вашему мозгу связать воедино все то, что он поглощал во время сфокусированного мышления.
Загвоздка в том, что для того, чтобы оно правильно работало, нужно задействовать оба способа мышления.
Если вы делаете четыре подхода сфокусированного мышления по 25 минут, то потом отправляйтесь на прогулку. Вздремните. Сядьте и подумайте о том, что вы выучили.
Как только вы чаще начнете ничего не делать, то увидите ценность многих вещей из-за освободившегося пространства. Комната – это четыре стены вокруг пространства, в шине нет ничего, кроме воздуха, а корабль плывет из-за пустого пространства.
В вашей учебной рутине должно быть больше ничегонеделания.
5. Отстой, с которым нужно смириться
Сегодня вы выучите то, что забудете уже завтра.
Потом ещё, и снова забудете.
Вы проводите все выходные за учебой, идете на работу в понедельник и все повторяется.
Кто-то спросил меня как я надолго запоминаю то, что прочитал в книгах. Я ответил, что никак. Если повезет, я запомню 1% от всего содержания. Однако, когда этот 1% пересекается с 1% чего-то ещё, происходит волшебство. В такие моменты я чувствую себя экспертом по соединениям точек.
Ты понимаешь как много еще предстоит выучить, когда уже учишь что-то на протяжении года.
Когда это закончится?
Никогда. Вы всегда находитесь в самом начале пути.
6. Принцип трехлетки
На днях я был в парке.
Там был маленький мальчик – он бегал по всему парку, отлично проводя время. Забирался на горку и скатывался с неё, бежал за дерево и выбегал из-за него, в грязь, вверх и вниз по склону.
Он смеялся, прыгал и снова смеялся.
«Пойдем, Чарли, нам нужно идти».
Она уводила его, а он продолжал смеяться, размахивая своей синей пластиковой лопаткой.
Что же его так увлекло?
Он играл. Он веселился. Весь мир был в новинку. В нашей культуре есть четкая граница между работой и игрой. Обучение – это работа.
Вы должны учиться, чтобы получить работу. Вы должны работать, чтобы зарабатывать деньги. За деньги можно купить свободное время. И только в это свободное время вы можете быть как Чарли – носиться и смеяться.
Если вы воспринимаете учебу как работу, будет казаться, что вы в аду. Потому что всегда можно выучить больше. А вы знаете правило – только работа, никаких игр.
А теперь предположим, что учеба – это процесс прохождения от одной темы к следующей.
Как будто вы в игре соединяете разные предметы.
И тогда у вас, как и у Чарли, съезжающего с горки, появится такое же чувство.
Вы учите что-то одно, используете это, чтобы выучить что-то другое, застреваете, преодолеваете это и учитесь чему-то ещё. Превращаете весь процесс в танец.
Я узнал, что если у вас есть структурированные данные в виде таблиц, колонок или датафреймы, то такие ансамблевые алгоритмы как CatBoost, XGBoost и LightGBM подходят лучше всего. А для неструктурированных данных вроде картинок, видео, естественного языка или аудио, вашим выбором должны стать глубокое обучение и/или перенос обучения.
Я соединил точки. Сказал себе, что эксперт в этом. Танцевал от точки к точке.
Занимайтесь именно так, и к концу занятия у вас будет больше энергии, чем в его начале.
Это – принцип трехлетки. Воспринимать все как игру.
Ну, достаточно.
Мне пора спать.
Это бонус.
7. Сон
Если вы плохо спите, вы будете плохо учиться.
Наверное, и вы не спите достаточно.
Я точно не спал. Вечера пятницы и субботы были самыми прибыльными в Uber. Люди ходили в рестораны, на вечеринки, в ночные клубы. Я – нет, я водил. Я работал до 2-3 утра, возвращался домой и спал до рассвета в 7-8 утра. Два дня были сплошным кошмаром. Наступал понедельник, а я будто бы жил в другом часовом поясе. Во вторник было чуть лучше, к среде все вставало на свои места. Но наступала пятница и все повторялось.
Такой нарушенный режим сна был просто недопустим. Я же хотел усовершенствовать свое обучение. Сон очищает мозг, позволяя образовываться новым связям. Я заканчивал работать в 10-11 вечера, возвращался домой и спал по 7-9 часов. Меньше денег, больше знаний.
Не меняйте сон на время для обучения. Делайте наоборот.
Машинное обучение – это обширная область.
И чтобы хорошо изучить не только её, но и что угодно, вы должны помнить:

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
Машинное обучение: с чего начать или как построить первую модель
В качестве первой задачи для машинного обучения возьмем что-то понятное и простое, например, прогноз стоимости жилья. Готовый датасет можно найти на сайте kaggle. На первых шагах обучения не стоит брать датасеты с большим количеством переменных, например, «House Prices: Advanced Regression Techniques» состоит из 80 переменных и advanced regression, остановимся на «House Sales in King County, USA» с 21 параметром. Скачиваем данные и анализируем предоставленное описание. В наличии дата, цена, количество спален, ванных комнат, общая и жилая площадь, этажность, оценка вида, вид на море, оценка общего состояния, грейд (оценка строительства и дизайна), площадь над и под уровнем земли, год постройки, год последнего ремонта, код зоны, координаты (долгота и широта), данные о площади домов 15 соседей.
Итак, мы выбрали задачу и готовы приступить к ее решению. Решение будет включать два этапа: анализ данных и построение моделей.
1. Работа с данными.
Сделаем отступление и отдельно отметим важность анализа данных. В настоящий момент все более-менее популярные алгоритмы уже написаны в виде библиотек и непосредственное построение модели сводится к нескольким строкам кода, например, k-ближайших соседей из sklearn в python:
Всего четыре строчки кода для получения результата. Так в чем же сложность? Сложность заключается в получении того самого X_train – данных, которые подаются на вход модели. Известный принцип «мусор на входе» = «мусор на выходе» (Англ. Garbage in – garbage out (GIGO)) в моделировании работает более чем на 100% и именно от работы с данными во многом будет зависеть качество полученного решения задачи машинного обучения.
Для анализа данных мы будем использовать pandas, для понимания и оценки «на глаз» используем простые графики из seaborn.
Импортируем библиотеки, читаем данные, выведем несколько записей из массива данных, посмотрим на типы данных и пропуски в них.
Массив данных состоит из 21613 записей без пропусков в данных и содержит только 1 текстовое поле date.
С каждым признаком поработаем подробнее и начнем с самого простого – откинем id (не несет полезной информации), zipcode (код зоны, где расположен дом) и координаты (lat & long), так как мы только знакомимся c machine learning, а корректное преобразование географических данных слишком специфично для начинающего специалиста.
Теперь посмотрим на дату объявления. Формат даты задан YYYYMMDDT000000, в целом ее тоже можно было бы удалить из датасета, но у нас есть поля год постройки (yr_built) и год последнего ремонта (yr_renovated), которые заданы в в формате года (YYYY), что не очень информативно. Оперируя датой объявления можно преобразовать год в возраст вычитанием (год объявления — год постройки / год ремонта). Отметим по части домов год ремонта стоит 0, и, предположив, что это означает отсутствие ремонта с постройки, заменим нули в году ремонта на год постройки, предварительно убедившись, что в данных отсутствуют некорректные записи, где год ремонта меньше года постройки:
Следующим параметром проанализируем цену и воспользуемся для этого «Ящиком с усами» (Box plot). Ящик с усами – простой и удобный график, показывающий одномерное распределение вероятностей, или, проще говоря, концентрацию данных. Отрисовывает медиану (линия в центре), верхний и нижний квартили (стороны ящика), края статистически значимой выборки («усы») и выбросы (точки за «усами»). Легко понять по картинке на нормальном распределении (справа). График позволяет быстро оценить где располагается большая часть данных (50% находятся внутри ящика), их симметричность (смещение медианы к одной из сторон ящика и/или длина «усов») и степень разброса – дисперсию (размеры ящика, размеры усов и количество точек-выбросов).
Можно построить распределение только этого признака по всему массиву, но информативнее будет использовать 2 оси – например, цену и количество спален, что в свою очередь также покажет наличие связи между признаками:
Out price & bedrooms:
Из графика сразу видно наличие экстремальных значений price и bedrooms (только представьте дом с 33 спальнями! J). Наличие таких значений (иначе называемых как выбросы) в целевом признаке price часто приводит к переобучению модели, так именно они будут давать большую ошибку, которую алгоритмы стараются минимизировать. Из графика видно, что большая часть (если посчитать – 93,22%) лежит в диапазоне 0-1млн, а свыше 2млн – всего 198 значений (0,92%). От 1% датасета можно избавиться практически безболезненно, поэтому вызвав простой просмотр 217 записей предварительно отсортировав по цене, увидим искомую отметку price в 1 965 000 и удалим все что выше этой цены.
Подумаем немного над признаком bedrooms. Мы видим 13 домов с bedrooms = 0, а также странную запись о доме с 33 bedrooms. Поступим также как и с price, удалив нули из bedroms (а заодно и bathrooms):
Касательно дома с 33 спальнями – учитывая цену, можно предположить что это опечатка и спален на самом деле 3. Сравним жилую площадь этого дома (1620) со средней жилой площадью домов с 3 спальнями (1798,2), что ж вероятно наша догадка верна, поэтому просто изменим это значение на 3 и еще раз построим предыдущий box plot:
Чтож, значительно лучше. Аналогично bedrooms посмотрим и на bathrooms. Нулевые значения мы удалили, другие экстремальные значения в поле отсутствуют:
В полях sqft_living, floors, waterfront, view, condition, grade, sqft_living15 также все значения более-менее реальны, их трогать не будем:
А вот с sqft_lot и sqft_lot15 нужно что-то придумать и из-за больших значений вполне подойдет логарифмирование:
sqft_lot до и после:
sqft_above и sqft_basement – составные части sqft_living, поэтому также трогать их не будем.
На этом с предварительным анализом мы закончим и посмотрим на тепловую карту корреляций:
Изучив карту корреляций видим, что иногда признаки сильно коррелированы между собой, поэтому удалим часть признаков с высокой корреляцией – sqft_lot15 (оставим sqft_lot), yr_built (оставим yr_renovated), sqft_above (sqft_living).
На этом закончим работу с данными и перейдем к созданию модели.
В данной части мы построим 2 модели: линейную регрессию и дерево решений.
Все необходимые нам модели содержаться в библиотеке sklearn.
Для начала отделим целевую переменную от остальных данных для обучения, а также разделим выборки на обучающую (70%) и тестовую (30%, на которой мы проверим как работает модель):
Также из sklearn для оценки модели загрузим 3 метрики — mean_absolute_error (средняя абсолютная ошибка), mean_squared_error (Среднеквадратическое отклонение), r2_score (коэффициент детерминации):
Начнем с линейной регрессии:
Исходя из метрик можно сделать вывод о том, что Линейная регрессия показала лучший результат, поэтому логичнее выбрать ее. Однако, мы не задавались вопросами из чего состоит ошибка модели, не является ли модель переобученной, и пр. Вполне вероятно, что к ухудшению результата DecisionTreeRegressor приводит именно переобучение, так как мы даже не ограничивали глубину дерева в параметрах модели. Можем легко проверить это перебрирая глубину деревьев в коротком цикле:
Очевидно, что лучший показатель при max_depth=7, и, посмотрев, на метрики (MAE: 124861.441, √MSE 175322.737, R2_score: 0.626) становиться понятно, что модель с таким ограничением аналогична линейной регрессии по качеству.
Также мы можем попробовать оценить какие признаки оказались наиболее важны для модели для прогноза стоимости:
Исходя из графика видно, что на стоимость больше всего влияет grade – общая субъективная оценка дома риелторской компанией (что, кстати, говорит о компетентности оценки :-))), на втором месте – площадь дома, а на третьем – год последнего ремонта. Показатели количества спален, ванных комнат, этажей же модель посчитала незначимыми для прогноза.
Для лучшего понимания результатов, посчитаем среднюю ошибку в % — по линейной регрессии средняя ошибка 27,5%, то есть модель ошибается чуть больше, чем на четверть при прогнозе стоимости дома, что довольно много.
Можно ли улучшить результаты? Да, несомненно, на текущем этапе мы получили только базовое решение – некую отправную точку для сравнения лучше или хуже будут модели, которые мы можем создать более сложными методами или применяя более сложную обработку данных.
Мы только чуть-чуть затронули вопрос переобучения и совсем не прикасались к тому, из чего состоит ошибка модели и многим другим аспектам создания модели. Как правило, для ответов на эти вопросы и нахождения оптимального решения используют разнообразные методы валидации моделей, но об этом мы напишем в следующих статях.



