Что такое LSI-фразы и почему они нужны в текстах
Технологии поискового маркетинга
Разработчики поисковых систем обращают наше внимание на то, что необходимо писать тексты для людей — полезные, интересные, информативные. И это не только слова: алгоритмы Panda и «Баден-Баден» не щадят страницы со слабым контентом и вытесняют их далеко за пределы ТОПа.
Что есть некачественный контент?
На этот вопрос мы постарались найти ответ в анализе последствий введения нового фильтра Яндекса.
Наряду с такими признаками, как
Именно об этом — качестве изложения — мы поговорим в новой статье и разберемся, при чем тут LSI-фразы и как с ними работать.
Что такое LSI
LSI-копирайтинг (LSI — аббревиатура от latent semantic indexing, что в переводе с английского языка означает «латентное семантическое индексирование») — методика написания и подачи текстового материала, повышающая его релевантность при анализе синонимов, слов, сопутствующих ключевому запросу, а также содержания и смысла текста поисковой системой.
Термин LSI стал звучать в профессиональной лексике оптимизаторов с запуском Google алгоритма Panda («Панда»). Но наиболее пристальное внимание ему стали уделять после прорыва поисковика в области семантического поиска и запуска алгоритма Hummingbird («Колибри»). Поисковая машина начала оценивать релевантность контента не столько на основании вхождения ключевого слова, сколько по степени смыслового соответствия текста исходному запросу. Над реализацией аналогичного подхода сейчас трудится и Яндекс.
Робот не просто цепляется за ключи как якоря, а сканирует и анализирует все содержание (контекст), что делает его оценку близкой к оценке человека.
В связи с этим закономерно появились термины LSI-фразы и LSI-копирайтинг. Они подразумевают расширение основного запроса, а именно: поиск его синонимов и сопутствующих тематических слов (латентных, то есть неочевидных ключей) и написание на их основе качественного материала.
Вместо расчета плотности и тошноты в дело вступает осмысленный подход, в основе которого лежит семантический анализ.
Цель этих действий — дать пользователю наиболее полный ответ на запрос, представить предметный текст в удобочитаемом виде.
Чем отличается LSI-текст от SEO-текста
Рассмотрим на примерах разницу между SEO-текстами и текстами, в которых учитывается LSI. Зададим в Яндексе запрос «купить эллиптический тренажер» и посмотрим на уровень качества контента сайтов с разных позиций.
На рис. 1 — описание раздела каталога интернет-магазина за пределами ТОП50. Мы видим изобилие основного ключа (12 раз в коротком тексте!). Копирайтер в точности подогнал текст под указанные запросы, отведя информативности и удобочитаемости второстепенное значение.
 Рис. 1. Пример классического SEO-текста, заточенного под ключевой запрос
Рис. 1. Пример классического SEO-текста, заточенного под ключевой запрос
На рис. 2 — текст магазина из ТОП10, претендующий называться естественным и информативным. Единственное замечание касается врезки о сервисных услугах с целью добавить на страницу ряд коммерческих ключей: «доступные цены», «большой выбор», «гарантии», «скидки», «доставка» и т. д. В данном контексте эта информация не несет полезной нагрузки.
 Рис. 2. Пример естественного текста, ориентированного на людей
Рис. 2. Пример естественного текста, ориентированного на людей
Текст из второго примера являет собой не просто набор слов, а смысловую единицу. Если скрыть в нем основной ключевой запрос «купить эллиптический тренажер», смысл не потеряется и из контекста мы поймем, о чем идет речь. Попробуйте сделать то же самое с текстом из первого примера — можно подставить любой другой вид тренажера и ничего не изменится, что говорит о шаблонном формате контента.
Далее рассмотрим, как построить основу (найти ядро запросов) для создания качественного релевантного текста, обогащенного LSI-лексикой.
Как найти слова для LSI-ядра
Начнем с того, что LSI-фразы условно можно разбить на две категории: синонимичные и сопутствующие (связанные тематикой с основным запросом). Первая группа слов позволяет избежать многочисленных повторов ключа, вторая — раскрыть тему текста. Можно предположить, что это будут НЧ-запросы, но это не совсем верно. LSI-фразы связаны по значению с основным запросом, и в их числе могут быть разные по частотности слова и словосочетания.
В нашем примере с эллиптическими тренажерами синонимами основного ключа могут быть:
Дополняющие тематические слова:
Вопрос в том, как собрать это ядро запросов. Рассмотрим несколько бесплатных способов.
1. Поисковые подсказки
Изучаем актуальный поисковый спрос в рамках искомого запроса. Яндекс выдает десять поисковых подсказок, Google — всего три.
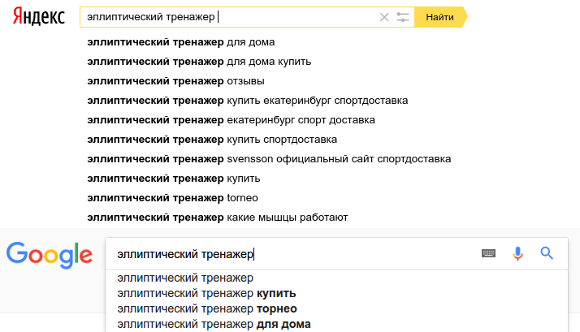 Рис. 3
Рис. 3
2. «Яндекс.Вордстат»
Находим «Запросы, похожие на …» в правой колонке сервиса «Вордстат» (рис.4).
3. «Вместе с этим ищут»
Смотрим на рекомендации Яндекса и Google, основанные на других интересах людей в рамках искомого запроса. Блок располагается в нижней части страницы с результатами поисковой выдачи (рис. 5).
 Рис. 5
Рис. 5
4. Тексты сниппетов в ТОП10
Ранее для поиска дополнительных слов можно было использовать поисковые подсветки Яндекса (выделенные слова в сниппетах наряду с искомым запросом). Однако сейчас в подсветках ничего кроме региона найти не удастся (рис. 6).
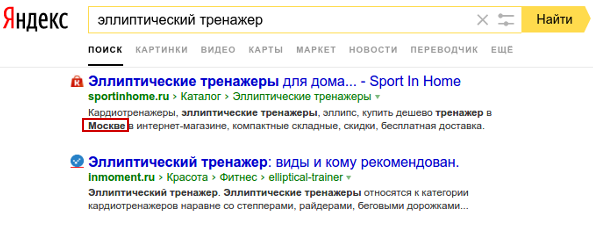 Рис. 6
Рис. 6
Так как подсветки более не помогают, можно использовать другой вариант работы со сниппетами — просмотреть тексты в ТОП10 и выделить наиболее часто встречающиеся слова. Важное примечание: для анализа следует брать сниппеты некоммерческих сайтов, если продвигаемый сайт является коммерческим, и наоборот (рис. 7).
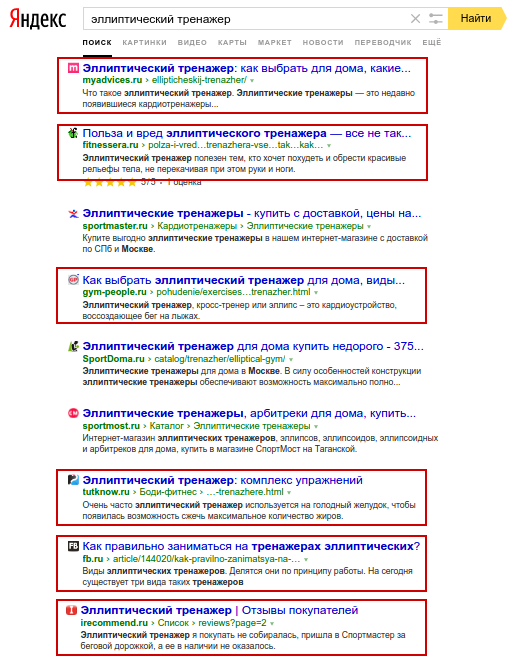 Рис. 7
Рис. 7
5. Генератор семантического ядра SeoPult
По сути этот инструмент агрегирует все перечисленные выше способы и исключает рутину. Указав основной запрос в ячейке и нажав кнопку «Семантика», вы за секунды получите список из нескольких десятков LSI-фраз (рис. 8). В их числе будут и синонимы, и расширяющие тематику слова. Фразы можно разбить на составляющие и брать для текста однословные запросы во избежание повторов ключа. Подборщик доступен в модуле контекстной рекламы на шаге 2, блок «Ручной подбор слов».
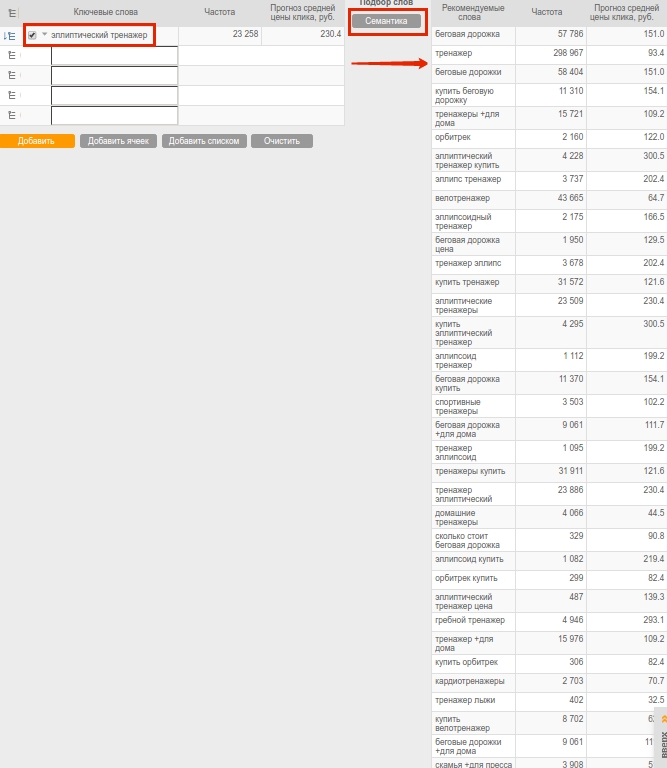 Рис. 8
Рис. 8
В результате проведенной работы вы соберете довольно широкое LSI-ядро, однако далеко не все слова будут необходимы для конкретного текста. Нужно исходить из задачи и оставлять только те запросы, которые удовлетворят требованиям. Например, описание для раздела каталога магазина и информационная статья о выборе тренажера будут иметь разное назначение и отличный набор фраз.
Найденные LSI-запросы можно использовать не только для написания новых текстов, но и коррекции существующих. После очередного текстового апдейта поисковых машин вполне вероятно, что обновленный контент появится в выдаче по дополненным ключам.
Применяй с умом
Написание текстов на основе LSI-фраз — метод рабочий, но тем не менее не решающий проблему качества контента. Можно собрать богатую семантику для насыщенной и полезной статьи, но применить ее так, что текст невозможно будет читать.
Пример на рисунке ниже является тому подтверждением.

Важно осмысленно подходить к тому, что вы пишите — не нужно превращать текст в бессвязный набор предложений.
Помните, что ключи можно использовать не только в теле текста, но также в заголовке (Title) и описании страницы (Description), заголовках H1 и подзаголовках.
Только при комплексной оптимизации и регулярном создание новых страниц сайта с тематическим контентом можно рассчитывать на внимание читателей и расположение поисковых машин. В реализации этой задачи вам помогут профессиональные копирайтеры и редакторы.
Что такое LSI-слова и как их использовать для SEO-продвижения
LSI-копирайтинг позволяет забыть про ключи типа «купить … москва недорого», писать для людей и при этом успешно продвигаться в поисковых системах.


Примерно с 2013 года стали появляться публикации в духе «SEO-копирайтинг умер, да здравствует LSI-копирайтинг».
Сначала тренд был задан новыми алгоритмами Google — «Панда» (2011) и «Колибри» (2013), которые использовали LSI (латентное семантическое индексирование). Затем — алгоритмами «Яндекса»: «Палех» (2016), «Королев» (2017) и «Баден-Баден» (2017), направленными на понимание естественного языка и борьбу с переоптимизированными текстами.
Латентный семантический анализ (по нему и производится латентное семантическое индексирование) — способ обработки информации на естественном языке. Технология позволяет машине понимать смысл и содержание текста по тематическим словам, синонимам и похожим запросам. Тем самым она исключает или по крайней мере минимизирует манипуляцию выдачей за счет вписывания популярных ключевиков.
В итоге оптимизаторы помимо стандартных SEO-запросов стали добавлять в ТЗ копирайтерам так называемые LSI-ключи.

Пишущий интернет-маркетолог, автор-фрилансер. Помогает развивать и продвигать блоги, делает контент для внешних площадок. Пишет об интернет-маркетинге, реже о финансах и бизнесе.
Что такое LSI-ключи
LSI-ключи — слова и фразы, связанные с основным запросом семантически, по смыслу. И это не только синонимы.
| Примеры основных SEO-запросов | Примеры LSI-ключей |
|---|---|
| туры в европу | отдых, экскурсионный, автобусный, путешествие, цена, способ, хороший |
| автосервис | ремонт, автомобиль, обслуживание, отзыв, работа, адрес, телефон, диагностика, двигатель, автотехцентр |
| китайский чай | сорт, цена, настоящий, пуэр, магазин, доставка, напиток, элитный, красный, чайный, свойство |
| цветы купить интернет-магазин | розы, букет, дешево, доставка, полевых, женщина, девушка, мосцветторг |
| интернет-маркетинг | продвижение, компания, инструмент, услуга, обучение, бизнес, сайт, клиент, продажа |
Само собой, дополнительная релевантная семантика позволяет сделать текст более живым, разбавить унылые ключевые слова или вообще отказаться от них — возможно, даже без вреда для продвижения в поисковых системах.
LSI-текст = полезный текст?
Не все так просто. Топорное вписывание LSI-слов вместо стандартных SEO-ключей также может привести к тексту, который формально подходит для продвижения, но:
К тому же страница со слабым, мало кому интересным текстом вряд ли получит много внешних ссылок, привлечет большой трафик и покажет хорошие поведенческие сигналы. А ведь все эти факторы оказывают куда большее влияние на продвижение в поиске, чем сам текст.


Как все-таки правильно использовать LSI-слова и фразы
Тщательно собирать LSI-слова и обязательно прописывать их в ТЗ копирайтерам, пожалуй, нужно только в следующей ситуации:
Тогда список дополнительных релевантных слов и фраз поможет авторам сразу копать в нужном направлении, быстрее разобраться в незнакомой теме, учесть важные моменты. Сложно будет схалтурить, просто вписывая поисковые запросы в разных вариациях.
А вот если над текстом работает автор, который имеет собственный опыт или умеет использовать чужую экспертизу, — все эти LSI-ключи не понадобятся. Дело в том, что качественный, экспертный, хорошо проработанный материал просто не может не включать синонимы, похожие запросы и околотематические слова.

Где брать ключи
для LSI-копирайтинга
Дополнительную семантику можно извлекать вручную и бесплатно, например, из «Яндекс.Вордстата», поисковых подсказок и блока «Вместе с … ищут».

Более простой и быстрый вариант — воспользоваться инструментами по сбору LSI-ключей: простыми бесплатными сервисами или SaaS-платформами для комплексной оптимизации. Примеры:
Ну а если вы устали писать для олдскульных SEO-специалистов сложные и скучные тексты, которые стыдно добавлять в портфолио, — обратите внимание на курс по копирайтингу от Skillbox. Он поможет пробить потолок в 100 руб. за тысячу знаков, навсегда забыть о несправедливых биржах и начать работать с серьезным бизнесом и известными агентствами.
LSI-копирайтинг
В конце марта 2017 года Яндекс ввел новый алгоритм ранжирования Баден-Баден, название которого (повторение одних и тех же слов) хорошо раскрывает его назначение: борьба с перенасыщенностью ключевыми сочетаниями. Переоптимизированные статьи неэффективны по одной простой причине — полной информационной бесполезности для пользователя.

LSI-копирайтинг: что это?
LSI-копирайтинг заключается не в создании привычного SEO-оптимизированного текста, насыщенного «ключами», а в полном раскрытии смысла ключевых запросов в максимально интересной для пользователя форме. «Ключи» в таком контенте — вспомогательный инструмент оптимизации. Основным же выступают слова и выражения, связанные с конкретной темой статьи.
Важно! Ориентируясь на неявное семантическое индексирование при написании материалов, оптимизированных под LSI-алгоритм индексации, необходимо по возможности избегать редко используемых, понятных только узким специалистам терминов. И таких сложноподчиненных предложений, как предыдущее. Нужно понимать, что ИИ, анализирующий контент на странице, все-таки искусственный, а не искусный. Пока.
Закажите LSI-копирайтинг у лучших авторов биржи





Принципы создания LSI-контента
Главный критерий ранжирования страниц по LSI-алгоритму — насколько полный ответ на свой вопрос получит пользователь, перейдя по ссылке, появившейся в «серпе» (топ выдачи). Следовательно, определяющим фактором становится не строгое наличие в тексте определенных словосочетаний — ключей, а ответ на замаскированный в поисковом запросе вопрос.
Процесс LSI-оптимизации будет понятнее при его рассмотрении в сравнении с традиционной или классической SEO. Отметим 3 принципиальных отличия.
Важно! Иногда отдельные хорошо LSI-оптимизированные и интересно написанные статьи могут появиться на верхних позициях выдачи, даже если в них нет набранного в строке поиска ключа в чистом виде.

Техника LSI-копирайтинга
Обобщить все можно одной фразой: приоритет смысла над технологией. Что касается внедрения ключевых словосочетаний (поисковых запросов), то их вставка должна быть обоснованной с точки зрения пользователя. Вставленный ключ должен дополнять ответ на вопрос. В противном случае он лишний.
Основные запросы или семантическое ядро LSI-текста должно быть обязательно расширено дополнительными словами, часто используемыми в этой тематике. В их подборе поможет анализ:
Включение в ядро найденных дополнительных фраз и слов не только поможет исчерпывающе ответить на вопрос пользователя, но и облегчит определение точной тематической направленности страницы для поисковых роботов.
Если все сделано по правилам ЛСИ-копирайтинга, но выйти в топ не получается, то полезно доработать содержательную сторону материала. Дополнить его графиками, таблицами, изображениями, экспертными заключениями и т. д.
Пример: два фрагмента
По запросу «концерт»:

Обратите внимание, что в этих фрагментах слово «концерт» отсутствует, тем не менее, на релевантности это никак не отразилось. Причем первый образец в выдаче стоит выше: в нем больше дополнительных слов, связанных с концертной тематикой.
В заключение. Вернемся к ранжированию по принципу Баден-Баден. В отличие от алгоритма, работающего по принципу неявного семантического индексирования, его можно если не обмануть, то обойти. Для этого достаточно отследить количество повторений слов на странице и добиться, чтобы между этими цифрами не было больших разрывов, а слова из ключей располагались вверху списка.
С LSI-индексированием грубое применение этой методики станет скорее тормозить продвижение. Анализируя содержание каждой фразы и определяя суммарную смысловую направленность контента в целом, алгоритм мгновенно выявит несоответствия и понизит (хорошо, если только понизит) ранг страницы. О нетематических «врезках» нужно забыть.
И последнее. Правильно сформированный LSI-контент стоит значительно дороже классического SEO. Причин две. Во-первых, требуется высокая квалификация исполнителя не только в написании текстов, но и в предметной области. Во-вторых, для полного раскрытия вопроса с учетом этого алгоритма потребуется в 3–5 раз больший объем статьи.
eTXT — биржа копирайтинга для новичков и профессионалов, здесь вы найдете специалиста по любой теме и с любым опытом. Регистрируйтесь и заказывайте LSI-копирайтинг на своих условиях!
LSI-фразы: что это такое и как их собрать
Делюсь самым эффективным алгоритмом поиска LSI-фраз, которые постоянно использую в работе. В итоге вы тоже научитесь за полчаса вычислять необходимое количество LSI и находить нужные.
Что такое LSI-копирайтинг
«Пишите для людей», – говорят они. Как поисковику дать понять, что содержание мой страницы удовлетворяет желания пользователей? Эту задачу выполняет LSI-копирайтинг.
Если пользователь вводит в поисковик фразу «консультация гинеколога», он, как минимум, хочет увидеть информацию о ценах, задать уточняющий вопрос и заполнить форму записи. То есть фразы «гинеколог задать вопрос», «гинеколог цены», «запись к гинекологу» и «гинеколог онлайн» являются синонимами запроса.
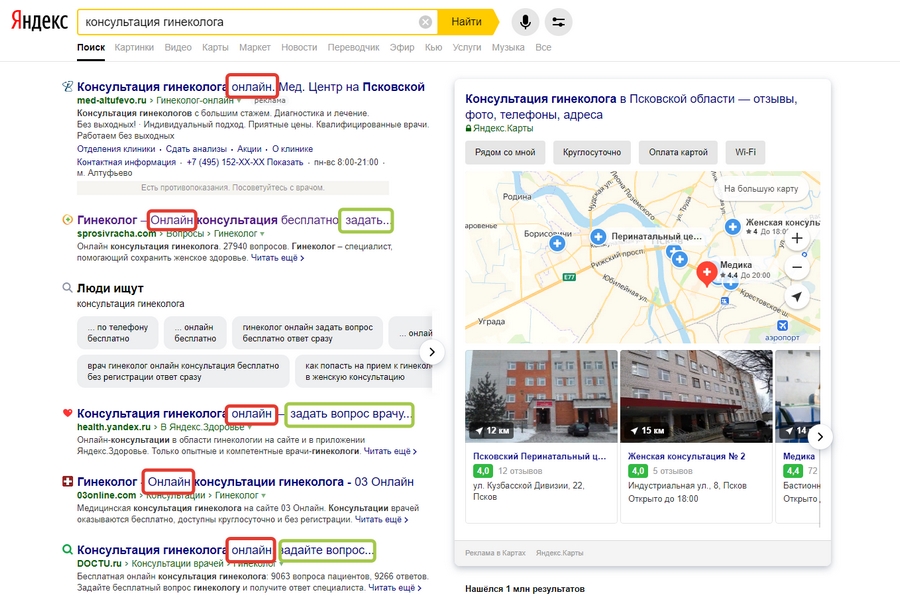
Поисковик запоминает, на каких страницах пользователи задерживаются дольше и, отталкиваясь контента этих страниц, составляет список LSI-фраз. Далее при поиске он использует уже не только конкретный запрос, но и LSI-фразы.
Поисковик классифицирует страницу как коммерческую или информационную, отталкиваясь в том числе от LSI.
Сложно продвигать коммерческую страницу, если ее текстовый контент изобилует фразами, присущими информационному запросу, и наоборот. То есть LSI важен для правильной классификации страницы.
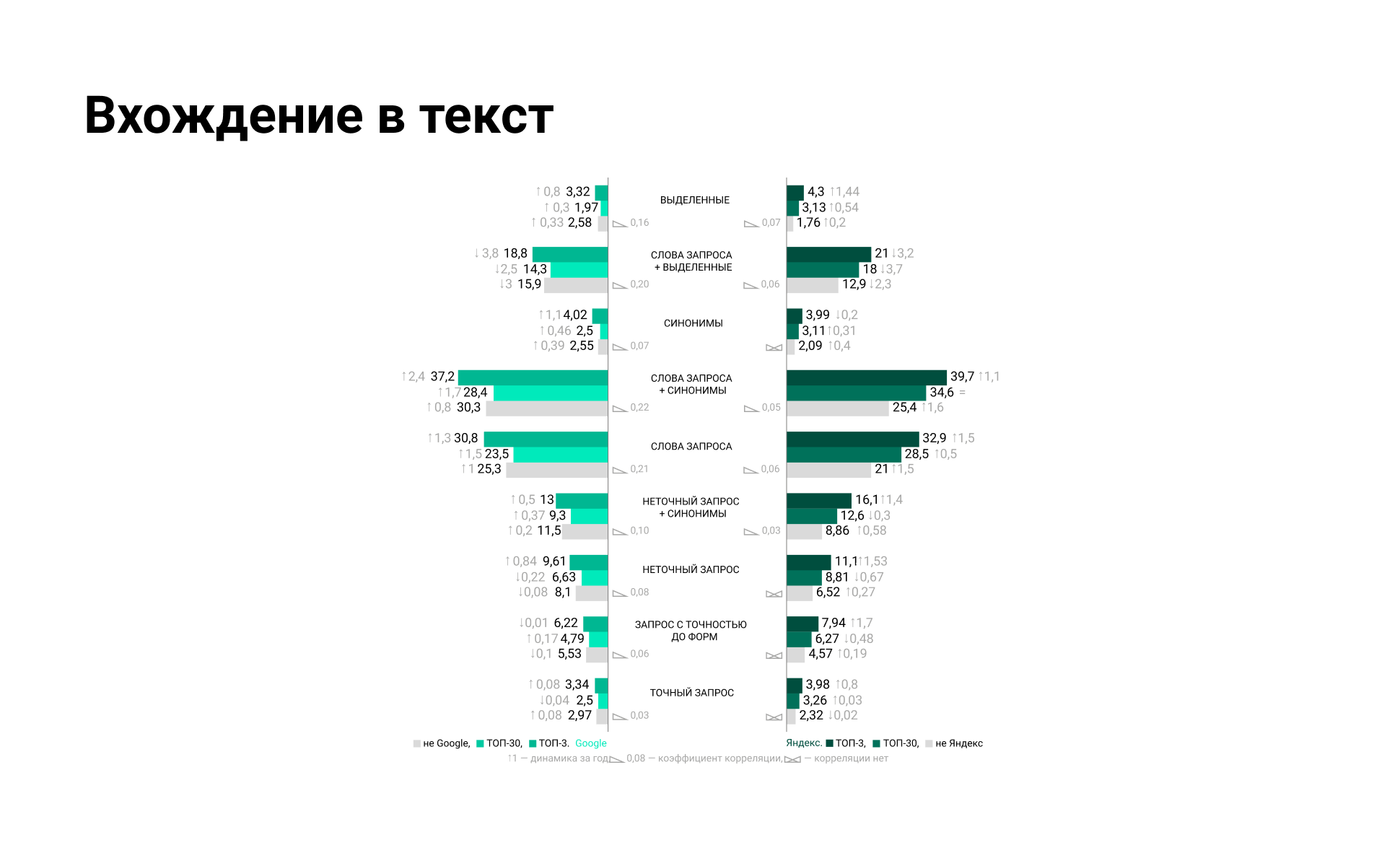
Ранжирование документов с LSI-оптимизацией и без
Между внутренними страницами сайта и внешними документами рассчитывается связь. Она похожа на связь при перелинковке и получении ссылок с других доменов, но только состоит из слов. Чем сильнее связь, тем лучше ранжируется страница. Напрямую об этом говорит патент Google (ранжирование документов с использованием словесных связей). Чем обширнее представлена LSI-семантика в документе и на сайте целиком, тем проще продвигать страницы.
Без применения LSI в конкурентных сферах делать нечего: поисковик воспримет контент сайта как недостаточно качественный, то есть неудовлетворяющий запросы.
Откуда взять LSI-семантику
Проблема 1. Как придумать синонимы и связанные фразы? Можно использовать мозговой штурм и сбор поисковых подсказок. В таком случае появляется другая проблема.
Проблема 2. Как понять, какие LSI-фразы из полученного массива имеют наибольшее значениее для поисковика?
Есть простой способ решить обе проблемы.
Шаг 1. Сбор маркерных запросов
Маркерные запросы – это костяк семантического ядра. Например, для коммерческого сайта по продаже кирпичей – «купить кирпичи», «кирпичи с доставкой» и т. д.
Базовая частотность – это сколько раз встречается фраза «купить кирпичи» во всех возможных вариациях: «купить силикатный кирпич», «купить красный кирпич дешево» и т. д.).
Точная частотность – количество конкретных запросов «купить кирпичи» без уточнений.
Чем больше разница между базовой частотностью и точным вхождением, тем больше можно сделать фраз из маркерного запроса добавляя другие слова и LSI-фразы.
Маркерные запросы имеют своей особенностью большую числовую разницу между базовой частотностью и точным вхождением фразы. Поэтому мы и ищем именно маркерные запросы по конкретному кластеру (смысловой группе) для 1 посадочный страницы.
Сформируйте и постранично сгруппируйте семантическое ядро для продолжения работы. Собирайте пока. Я пойду налью чай – вода уже закипает.
Шаг 2. Поиск конкурентов для изъятия LSI-фраз
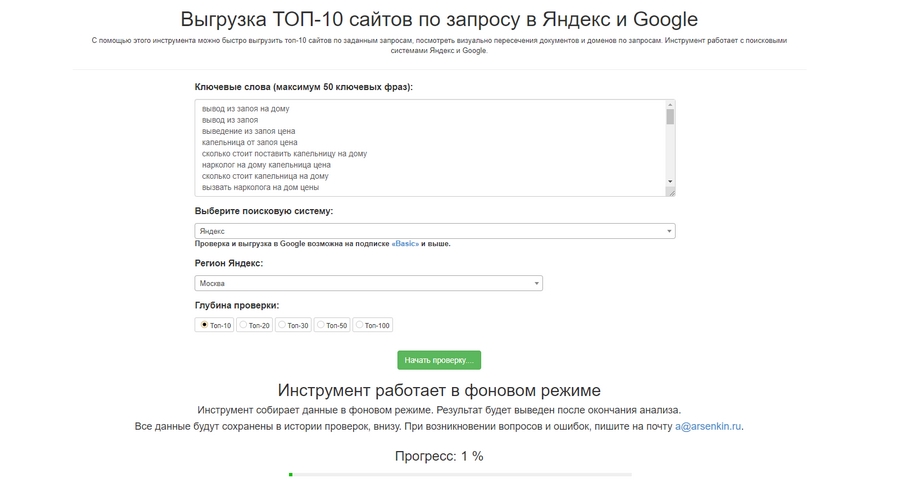
Открываем Arsenkin Tools, ищем инструмент «Выгрузка топ-10 сайтов». Забиваем туда все маркерные запросы для одной страницы, выставляем регион (всегда делайте это, даже если сайт без геопривязки) и жмем «Начать проверку».
В качестве альтернативы Arsenkin можно использовать сервисы Key Collector, PR-CY, Serpstat, Pixeltools, Topvisor.
Мы получили по каждому запросу из введенного нами списка по столбику. В каждом столбике 10 сайтов из топа «Яндекса» по этому запросу. Рекламные объявления, разумеется, в столбиках отсутствуют. Столбики разноцветные: одинаковые URL, разбросанные по разным столбикам, подсвечены одним оттенком:

Наша задача – пролистать ниже до этого блока:
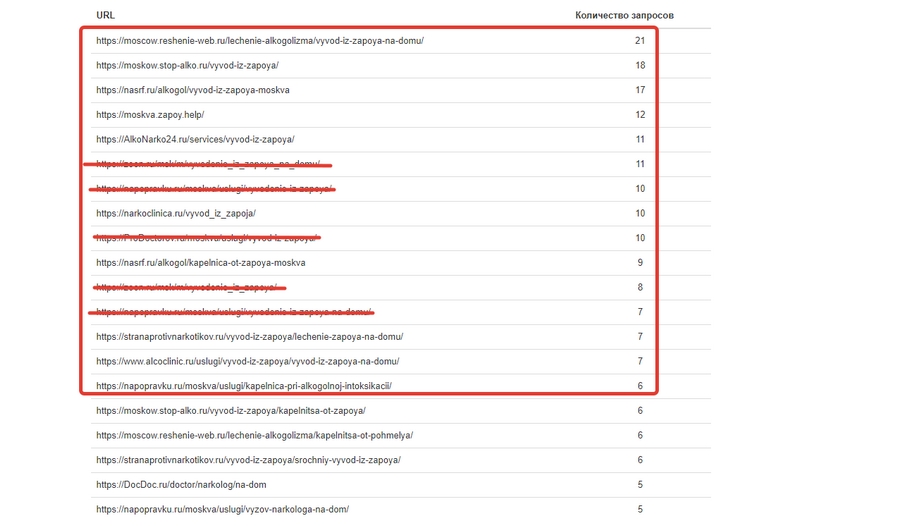
Как видите, я уже вычеркнул агрегаторы и выделил первые 10 подходящих ссылок. Эти страницы наиболее часто встречаются в результатах выгрузки, а значит, находятся в топе по большему количеству запросов, чем остальные. Делаем вывод, что маркерные запросы на этих страницах распарсены широко, охватывают много LSI, а страницы имеют хорошие поведенческие факторы.
Шаг 3. Таблица для исследования и веб-анализа LSI-семантики конкурентов
У меня было два варианта – считать все вручную для каждой страницы или внедрить формулы и сохранить шаблон для использования по мере необходимости. Я изготовил шаблон насколько мне это позволили навыки Excel. Я известный профессионал по Excel. Выглядит это вот так:
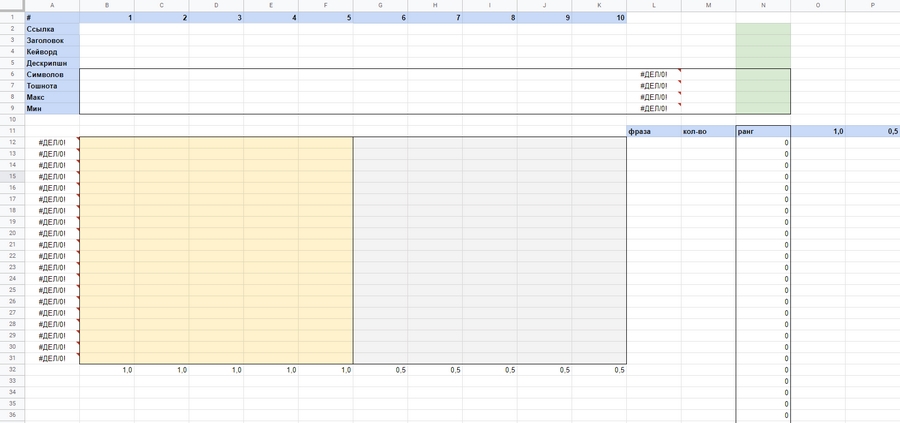
Обратим внимание на верхний блок и имеющиеся в нем строки: количество символов, тошнота, максимальная тошнота и минимальная тошнота. Мы вычислим эти значения для каждой из 10 страниц, а таблица посчитает среднее арифметическое. Так мы сможем увидеть тренды, в зависимости от которых страницы находятся в топе. Например, объем текста или плотность ключевых фраз.
Чуть ниже находятся два поля – бежевое и серое. Столбец формул левее этих полей представляет из себя переход от средней максимальной тошноты до средней минимальной тошноты, умноженный на 100 для удобства подсчетов.
В желтом поле будут находиться 5 страниц, возглавляющих топ, а в сером поле – замыкающая пятерка. Разница между первой и второй пятеркой заключается в их ранжировании. Первая пятерка имеет кратно превосходящий вес.
Все цифровые значения, которые мы получим в процессе работы, будем умножать на коэффициент. Для желтого поля он составит 1, а для серого – 0,5.
Справа внизу листа 1 – результаты нашей выборки, где каждому слову присваевается ранг. Чем выше ранг, тем ближе к максимальной тошноте должна быть плотность вхождений этого слова в тело документа. Чем ниже, тем ближе к минимуму, но все равно в интервале не меньше минимального.
Шаг 4. Парсинг LSI-фраз и обработка результатов
Переходим на сервис SeoLik (или его аналог p2pi) и находим инструмент «Анализ контента»:
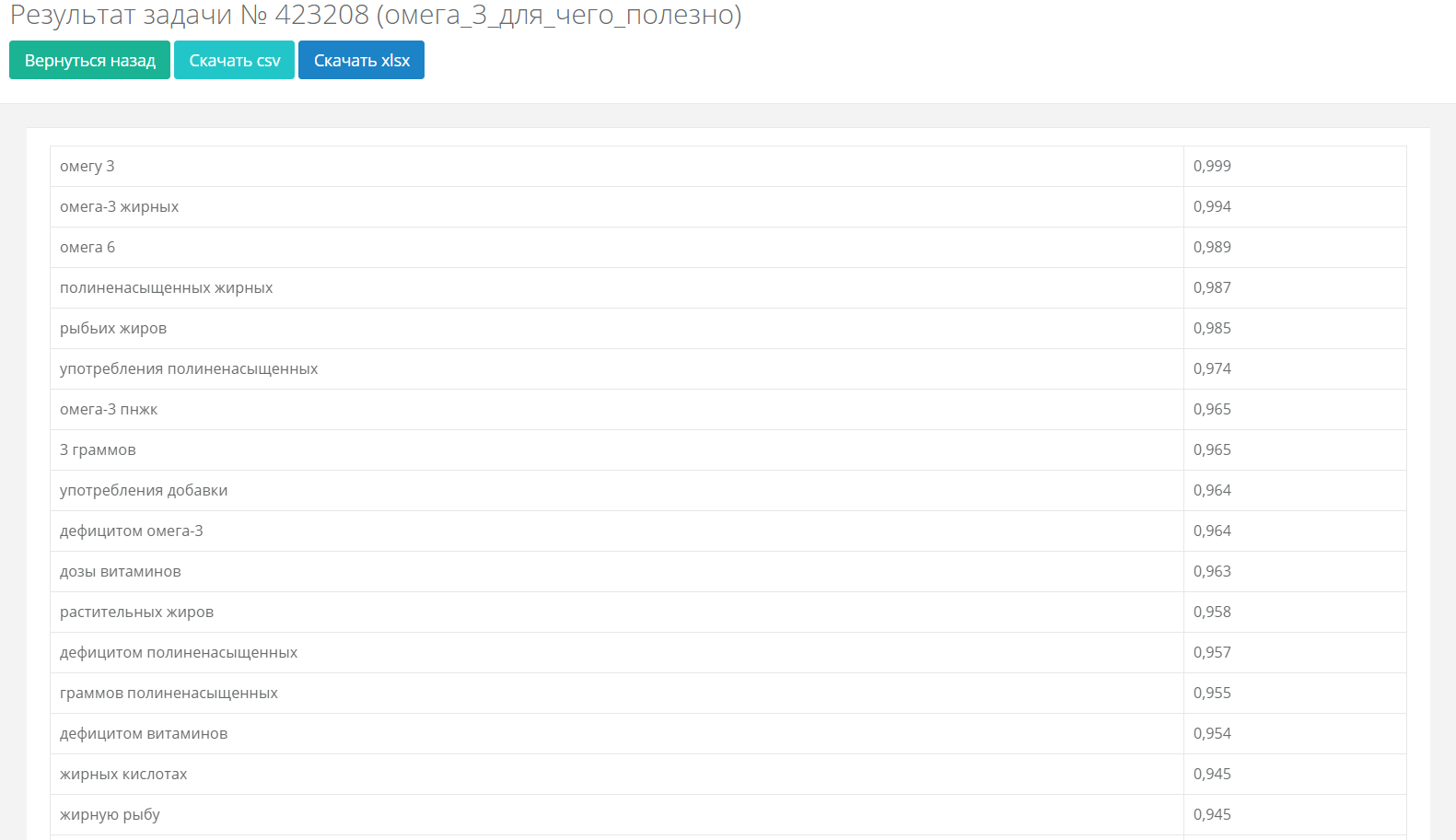
Берем первую из десяти ссылок и вставляем в окошко для анализа контента страницы. В результатах ищем поля с картинок ниже и выписываем значения из них в таблицу в соответствующие ячейки:

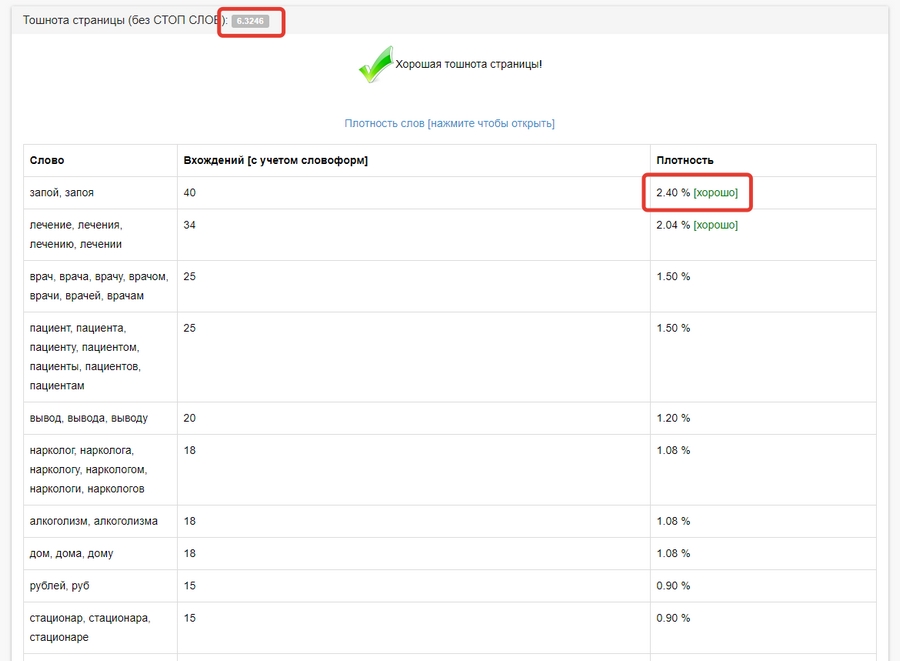
На второй картинке видим список слов. Выписываем первые 20 в желтое поле таблицы в столбик. Значение минимальной тошноты для этой страницы у нас будет равно тошноте 20-го слова: «запой», «лечение», «врач», «пациент» и т. д.
Ту же процедуру повторяем с остальными девятью страницами, постепенно заполняя желтое и серое поля:
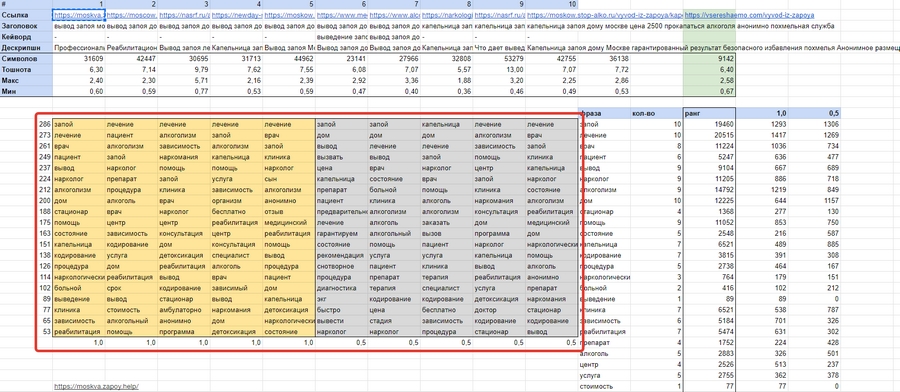
Теперь остановимся на желтом поле.
Нам нужно найти одинаковые фразы в каждом из пяти столбиков, перемножить каждую на соответствующее ей число из столбика левее желтого поля. Считаем сумму полученных значений, вписываем слово и полученный результат в соответствующие ячейки справа. В столбец «Количество» вписываем число совпадений.
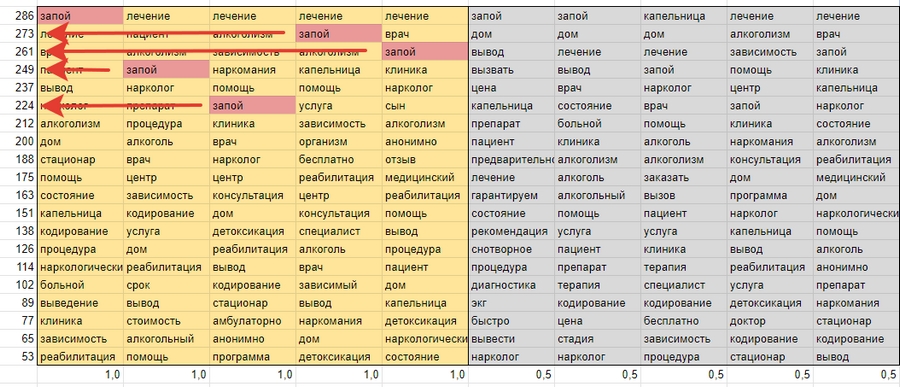
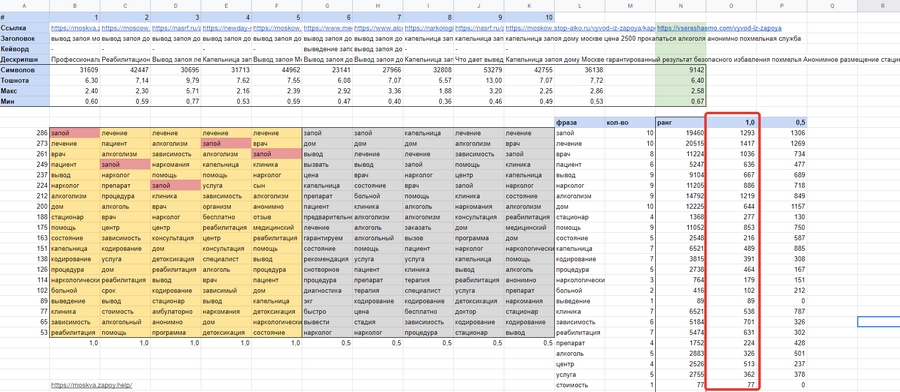
Ту же процедуру проделываем отдельно с серым полем, но результаты вычислений вписываем в столбец с коэффициентом 0,5:
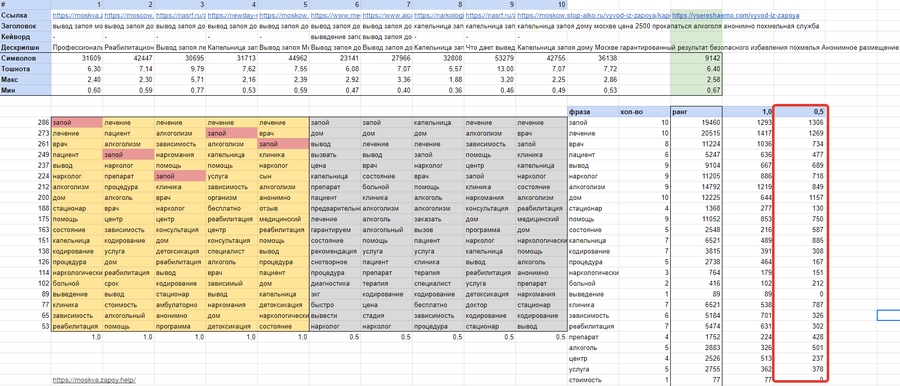
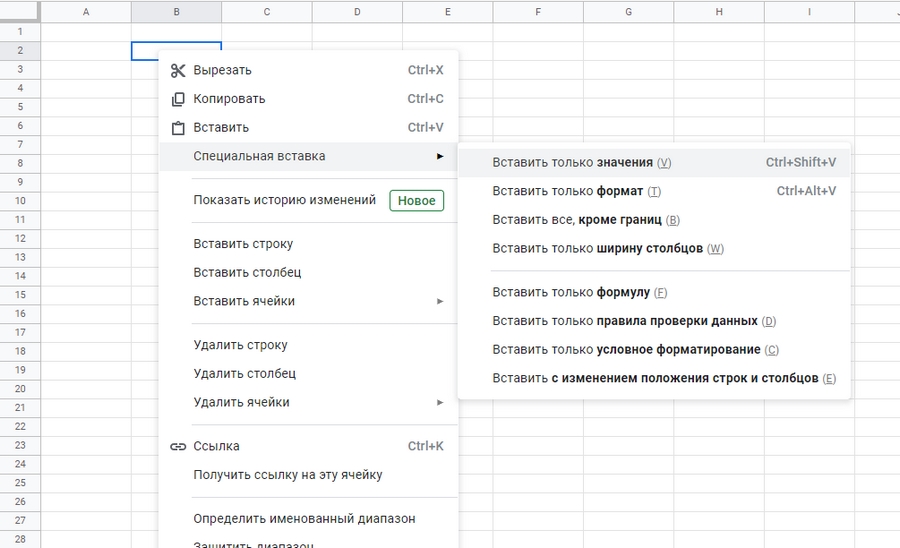
Копируем колонки «Фраза», «Количество» и «Ранг». Создаем новый лист в документе нажимам на ячейку B2 правой кнопкой мыши и выбираем «Специальная вставка» > «Вставить только значения»:
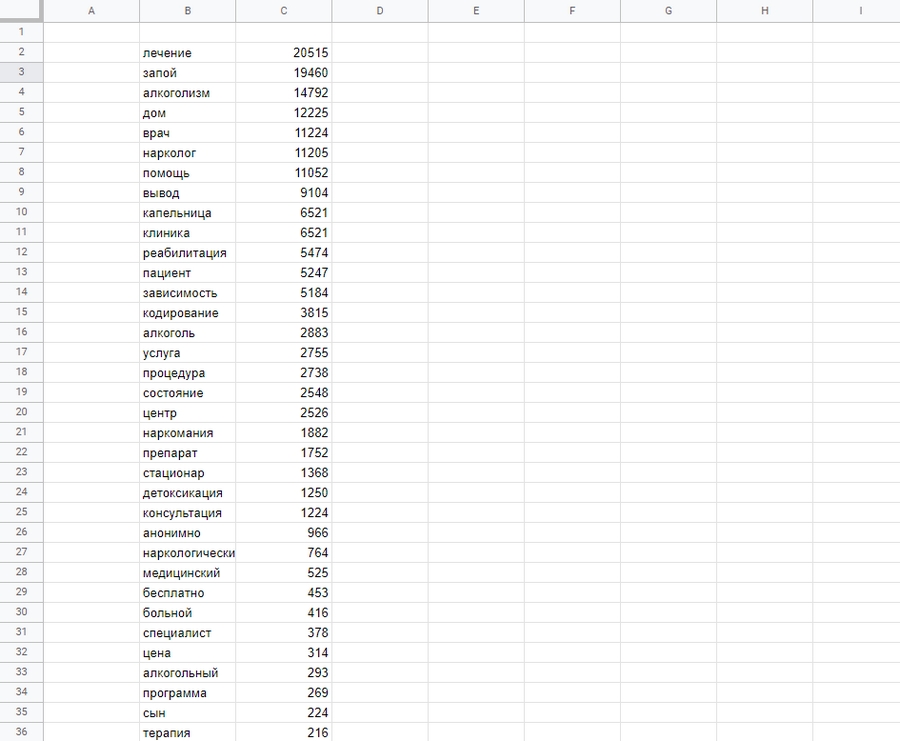
Удаляем столбец «Значения», фильтруем колонку «Ранг» от большего к меньшему. Получаем LSI-семантику. Располагаем слова по важности и узнаем плотность вхождений, которая у них должна быть:
Шаг 5. Сравнение
Теперь у нас два пути.
Шаг 6. Итог
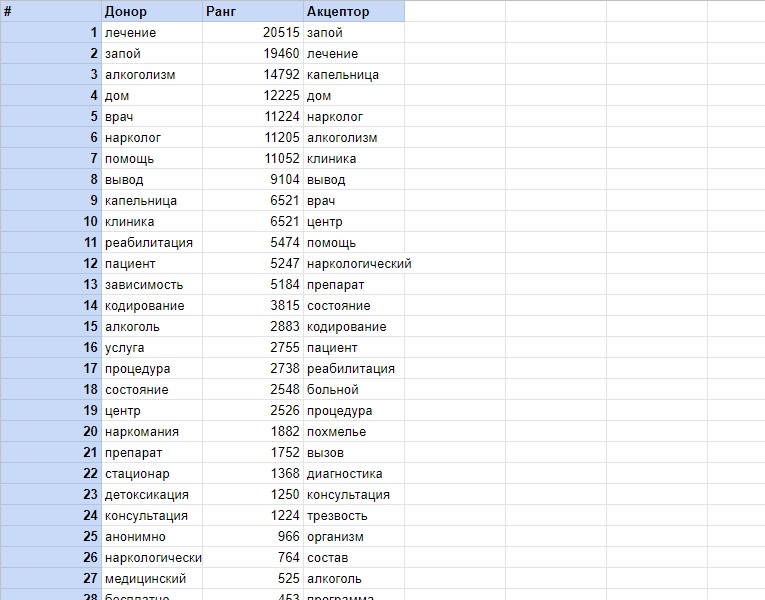
Завершающий этап состоит в сравнении двух списков слов и «подтягивании» LSI-фраз, которые редко встречаются в теле нашей страницы, до необходимого уровня. Проверку проводим в SeoLik (или в p2pi), добавляем нужные фразы или убираем лишние до тех пор, пока столбец «Донор» и «Акцептор» не будут равны.
Сравним донорскую LSI-семантику с LSI-семантикой нашей страницы. Красным маркером пометим фразы, плотность вхождений которых нужно увеличить, а зеленым – слова, которые необходимо удалить:
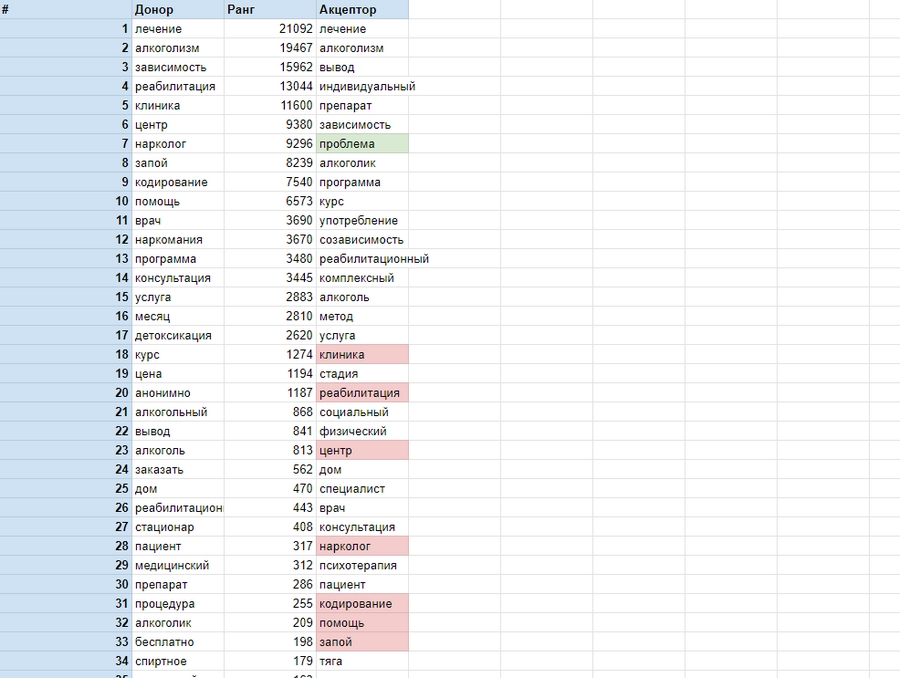
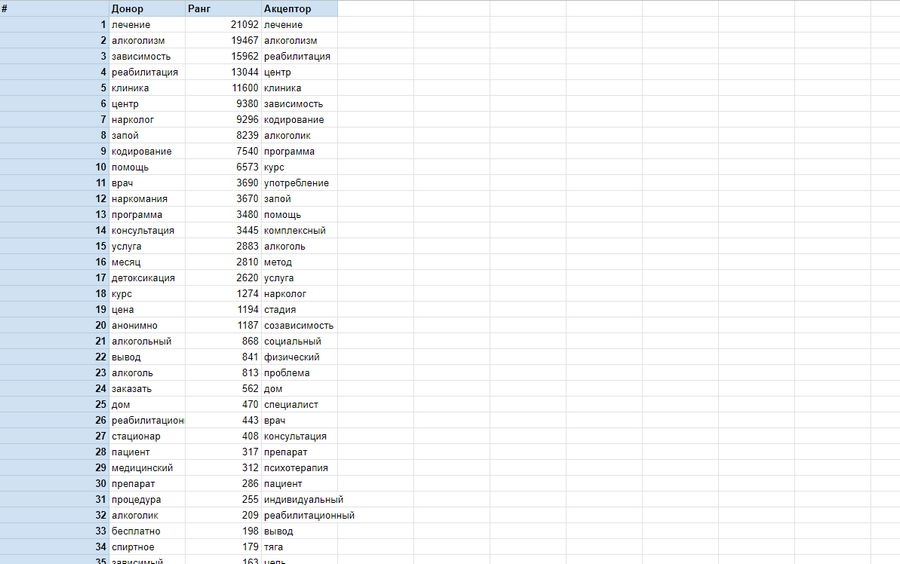
Мы получили список: «клиника», «реабилитация», «центр», «нарколог», «кодирование», «помощь», «запой». Вписываем слова в текст страницы-акцептора. Проводим повторный анализ контента, получаем результаты, на которых видно, что список и ранг LSI-фраз донора и акцептора приблизительно равны, что и требовалось.
В Google и «Яндексе», соцсетях, рассылках, на видеоплатформах, у блогеров



