LSI-копирайтинг. Принципы, инструменты, рекомендации
20 минут на чтение
Задача поисковых систем — найти информацию, которая наиболее точно отвечает запросам пользователя. Для этого машины должны были научиться распознавать смысл на основе содержания, а не только по отдельным «маякам» — поисковым запросам.
Классическая схема «запрос-документ» стала неактуальной из-за заспамленности большинства тематик. Поэтому ей на смену пришли алгоритмы латентного семантического анализа, а затем нейросети. В ответ специалисты SEO стали внедрять LSI-копирайтинг.
Цель — повышение релевантности, полезности, актуальности и достоверности материала. LSI-копирайтинг помогает поисковым системам лучше понимать смысл и содержание текста. В результате сайт может попасть на первые страницы выдачи, даже имея минимальное количество ключевых слов.
На практике это значит, что в тексте необходимо использовать синонимы основного запроса, сопутствующие ключевые слова и дополнительные фразы из смежных тематик. Это позволит полностью охватить и раскрыть тему. Такой контент оценят и пользователи, и поисковые системы.
История
В 1988 latent semantic analysis (LSA) получил патент U.S. Patent 4,839,853. Создатели метода — группа инженеров-исследователей: Скотт Дирвестер, Сьюзен Дюмэ, Джордж Фурнаш, Ричард Харшман, Томас Ландауэр, Карен Lochbaum и Линн Стритер.
Первоначально LSA применяли для выявления семантической структуры и автоматического индексирования текста. Затем — для построения когнитивных моделей и представления баз знаний. В США метод использовался для проверки качества обучающих методик и знаний школьников.
Суть метода
LSA, латентный семантический анализ — способ обработки информации на естественном языке. Он анализирует связь между коллекциями документов и терминами, которые в них встречаются. Латентный семантический анализ сопоставляет запросы и документы согласно тематике. Это позволяет выявлять скрытые ассоциативные и семантические связи.
LSI — аббревиатура от latent semantic indexing, с английского — латентное семантическое индексирование. Это способ использования LSA в области поиска информации.
Проще говоря, LSA позволяет машинам понимать смысл и содержание документа. А при ранжировании уравнивает «веса» разных по написанию, но близких по смыслу слов. Таким образом структурируются синонимы и запросы схожей тематики.
Основа системы — терм-документная матрица, разбор которой и является LSA. Терм-документная матрица представляет собой таблицу, в которой совмещаются «термы» (слова, фразы, термины) и документы. Строки соответствуют документам, а столбцы — терминам. Число обозначает количество пересечений.

LSI в алгоритмах поисковых систем
Первое упоминание LSA в поисковых системах связано с алгоритмом Panda от Google. Обновление ставило себе цель — найти и снизить количество контента низкого качества, который был создан с целью манипуляции поисковой выдачей. Алгоритм был запущен в феврале 2011, а уже в 2012 году появились первые упоминания об LSI-копирайтинге.
Окончательно новые требования к качеству текстов сформировались к 2013 году. В это время Google запустил новый алгоритм — Hummingbird («Колибри»). Главное отличие нового алгоритма — поиск стал понимать поисковые запросы разговорного типа. Google научился отыскивать нужные документы, исходя из семантических связей, а не просто по запросам.
«Яндекс» подхватил эстафету в ноябре 2016 года — запустил алгоритм «Палех». Его задача — распознавать низкочастотные и сложные запросы из «длинного хвоста». То есть понимать запросы в разговорном ключе. Общая масса таких запросов составляет порядка 40% от объема текста.
Для работы алгоритма были использованы нейросети и машинное обучение. Подробнее о механике и принципах работы алгоритма можно прочитать в блоге «Яндекс» на Хабрахабре. Введение в работу «Палеха» подогрело интерес к LSI-текстам в русскоязычном интернете.
Весной 2017 года «Яндекс» вводит «Баден-Баден» — новый алгоритм определения текстов, которые перенасыщены ключевыми словами. Тысячи сайтов попадают под фильтр и понижаются в выдаче, условием возврата трафика называется отказ от SEO-текстов.
Осенью 2017 «Яндекс» запускает «Королев» — алгоритм поиска на основе нейросетей. По заявлению «Яндекс», алгоритм «…сопоставляет смысл запросов и веб-страниц…». Новый алгоритм работает на нейросетях, но при этом не отменяет LSI, а усиливает сложившиеся тенденции. Теперь писать SEO-тексты нет никакого смысла — вместо топа можно получить фильтр за переоптимизацию.
Об LSI-копирайтинге и его потенциале для бизнеса: ответы на вопросы и конкретные примеры
Недавнее интервью П. Панды об LSI-копирайтинге и возможностях этого формата с примерами, фактами и диванами оптом.
1. Вокруг аббревиатуры LSI ходит много мифов, легенд и предрассудков. Могли бы вы объяснить простыми словами, что это такое на самом деле?
Здравствуйте, Андрей. Вы сходу задаете настолько масштабные вопросы, что у меня сразу язык немного пересох в предвкушении объяснений. Но давайте попробуем.
На самом деле я не очень понимаю, зачем нужны мифы, если есть официальная позиция поисковых систем и явная смена вектора их развития. Чтобы понять, что такое LSI-копирайтинг и почему он должен был появиться, давайте вернемся назад лет на 10, когда все было иначе.
Как было раньше? Раньше было так: вводим «диван купить оптом Москва дешево» и на первом месте были жуткие SEO-простыни, в которых вписано по 300 миллионов запросов «диван купить оптом Москва дешево».
Интересность? Ценность контента? Смысловая уникальность? Ничего этого не было в помине. Было сплошное манипулирование поисковой выдачей и страдание читателей.
То есть, изначально, когда поисковые системы не были столь гибкими и не могли отслеживать огромный пласт разных поведенческих факторов, алгоритм поиска был совершенно иным. Топорным. В его основе лежали принципы шингловой (технической) уникальности текста (до сих пор используется на биржах типа ETXT) и наличие конкретных ключевых запросов. Пусть и совершенно неадекватных.
Как мы уже выяснили, манипуляция поиском была глобальной. Это сегодня вы можете ввести «кривой» запрос уровня «диван купить оптом Москва дешево», но умные Яндекс и Google дадут вам совершенно иную выдачу, где подобные слова могут встречаться, но сами статьи явно не пересыпаны подобными вхождениями. 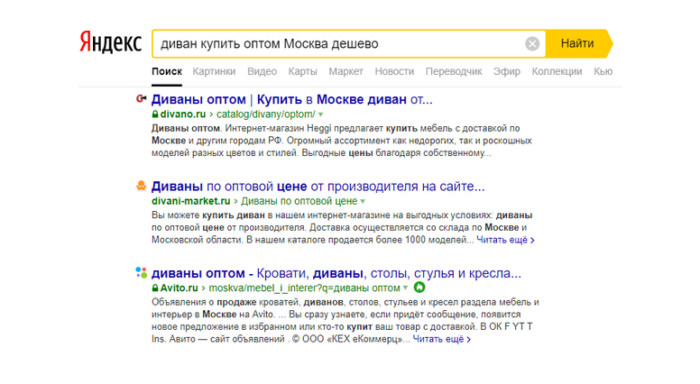
Раньше же была вполне стандартной ситуация, когда на вас сыпались списки статей с названиями, идентичными вашему запросу.
А что в итоге? В итоге Сеть захлестнула волна низкосортного бреда, единственная ценность которого — соответствие введенным ключам. Люди не получали пользы, потому что ТОП был оккупирован ужасными SEO-портянками.
Это распространилось настолько, что стало ясно — нужно что-то менять. К этому времени как раз и технологии развились значительно лучше, и нейронные сети стали реальностью, и поисковики значительно поумнели.
В итоге был совершен мощный поворот в сторону качества контента. Вспомните, еще 10 лет назад SEO-тексты были чем-то вроде ругательства. Сегодня же фразу «контент-король» не говорит только ленивый.
Это случилось потому, что поисковые системы значительно усилили и расширили алгоритмы анализа контента. Теперь совершенно недостаточно написать простыню текста с запросами.
Сегодня стали очень важны смысловая уникальность и поведенческие факторы. Если поисковики видят, что у вас «вроде бы все классно», но по факту со статьи массово уходят, то хоть золотом свой материал покройте, его все равно выкинет на самый край выдачи.
Поисковые системы больше не ориентируются только на запросы. Да, они до сих пор важны, но теперь важны даже не просто запросы, а расширенная семантика запроса вкупе с высокими поведенческими факторами.
Это именно та защита, которую поисковики дали сильному экспертному контенту..
А почему поисковикам настолько важен экспертный контент? Все просто: чем лучше Google или Яндекс ищут, тем выше лояльность аудитории. Следовательно, качество поиска нужно максимально усиливать и защищать.
Вот все это вкупе и дало то, что мы называем сегодня LSI-копирайтингом. Это совершенно новая модель ранжирования и анализа контента, основанная на совсем иных принципах, чем раньше.
Если вкратце, то Latent Semantic Indexing (скрытое семантическое индексирование) выглядит следующим образом:
1. Соответствие слов тематике статьи. Например, давайте возьмем это интервью. Пусть будет его основной темой запрос «что такое LSI-копирайтинг».
Соответственно, по такому запросу поисковые системы уже примерно понимают, какие именно слова будут использованы в тексте. Если они есть в материале, значит статья тематична.
Часть таких слов, если вы пишете даже сами (без анализа инструментами), все равно органично появится, но можно посмотреть и с помощью инструментов.
Например: 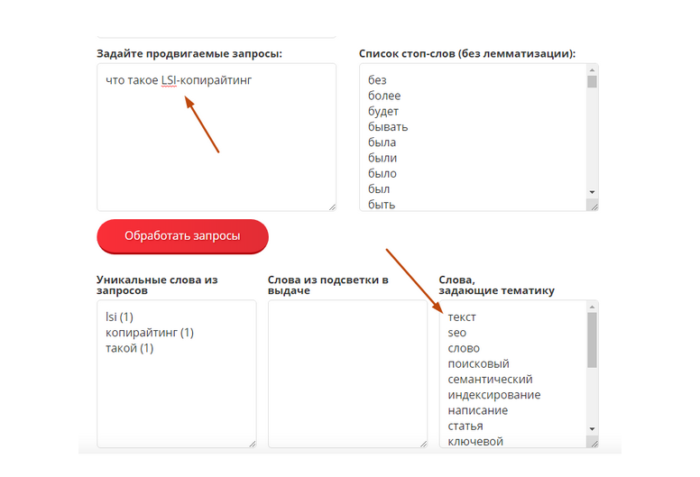
Как мы видим, слова совершенно органичны, и где-то половину из них я использовал в этом интервью, даже не глядя на анализ системы.
Это самый простой и достаточно действенный способ анализа контента.
2. Подбор синонимичных запросов, расширяющих и дополняющих тематику.
Давайте пофантазируем: вот мы пишем статью по запросу «что такое LSI-копирайтинг». Что еще нам, как читателем, будет интересно узнать?
Скорее всего, что-то вроде «примеры LSI-копирайтинга», «как работает LSI-копирайтинг», «Отличия LSI-текстов от SEO-контента», «правила создания LSI-текстов», их стоимость и прочие сопутствующие моменты.
Это также определяется как сервисами, так и с помощью мозгового штурма.
Следовательно, чем шире у нас статья, чем больше смежных (но интересных нашей ЦА) тем раскрыто, причем раскрыто экспертно (с фишками, кейсами, примерами, ошибками), тем круче и интересней считается контент в глазах ПС.
Естественно, все это работает только в том случае, если ваши посты подкреплены серьезными ПФ: репосты в соцсетях, много времени на странице, комментирование, невозвращение для поиска снова в ПС, добавление закладки и другие элементы положительной активности читателя.
Если же вы накупили пучок дешевых текстов по похожим темам на бирже и «хитро» собрали это в один материал, то такой контент быстро будет просчитан поисковиками. У него вряд ли будут высокие ПФ, следовательно, особых бонусов ждать не получится.
Да, какой-то трафик будет, но совсем не такой, какой вы могли бы получить, если бы все делали «по науке»,
Это не главная тема статьи, под этот ключ мы целенаправленно не работали, но за счет экспертности и высоких ПФ он все равно тоже входит в ТОП. И чем шире и экспертней статья, тем больше вашей семантики будет вверху поисковой выдачи.
Скажу еще больше: мы даже забираем те запросы, которых в их прямом значении нет в тексте или есть, но очень эпизодично. Скажем, вы пишете по теме «SMM-продвижение: лучшие сервисы», а в ТОП заходите еще и по запросу «Как продвинуться в социальных сетях».
Благодаря тому, что поисковые системы умнеют буквально на глазах и отслеживают уже даже скрытые логические, лингвистические и смысловые связки, у LSI-текстов невероятно много возможностей.
Это если совсем вкратце об определении LSI-формата. Если кто-то хочет прочитать более расширенную версию, могу предложить свое интервью на нашем сайте. Там про LSI-дано более полно и более подробно.
Так что не стоит верить мифам и легендам. Есть вполне четкие правила, по которым сегодня играют поисковые системы.
2. В чем потенциал LSI-копирайтинга и основные преимущества для продвижения бизнеса?
Ух, это мой самый любимый вопрос, меня на нем постоянно несет. Вообще потенциал LSI-копирайтинга для бизнеса огромен. Серьезно.
Главный плюс в том, что использование экспертных текстов с правильной LSI-оптимизацией позволяет ворваться в любые ТОП даже совершенно неизвестным компаниям и закрепиться там. При правильном подходе можно забирать ключевые запросы, которые раньше в выдаче вам даже не светили, а в рекламе стоят колоссальных денег.
Давайте я буду давать примеры, чтобы не быть голословным.
Вот. например, компания Aquarama, занимающаяся производством и продажей автомоек. Ее сильная сторона — отличные экспертные статьи по всей нужной им семантике. 
Это не один случайный пример, статей компании по самым разным запросам в ТОП сотни. Они серьезно подходят к работе, пишут развернутые экспертные материалы, а в итоге — самая горячая выдача и самые целевые клиенты. 
В итоге человек приходит, он видит ответы на свои вопросы, статус экспертов подтвержден, лояльность максимальна. До покупки — всего 1 шаг. И это все происходит органично, без колоссальных рекламных затрат. Контент, который работает сам на себя.
Еще пример. ТОП выдачи по запросу «автоворонки продаж». 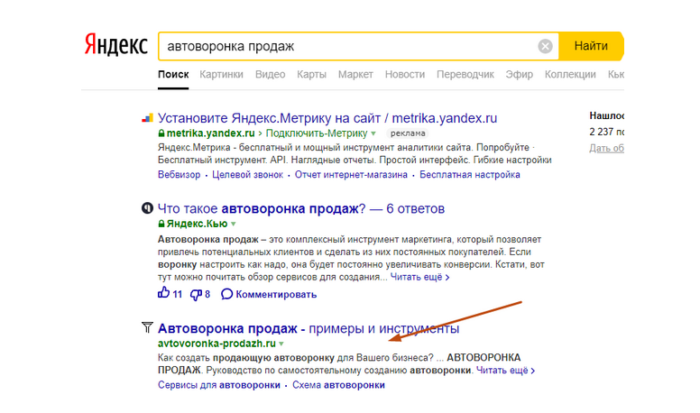
Ребята создали большую и подробную статью-лендинг на тему автоворонок. Пока вы не дойдете до конца, вы даже не поймете, что это продажник. Дана полная расшифровка, объяснены принципы работы автоворонки, примеры разных видов воронок. Много графики и нужных терминов. 
Никакой рекламы. Вообще. Только в самом конце призыв создать автоворонку у экспертов. А статус экспертов уже подтвержден тем, что человек дочитал до конца. Он уже получил максимум пользы, поэтому вероятность обращения опять же велика.
Скажу даже по нашему проекту https://petr-panda.ru/. У нас сейчас вообще нет страниц услуг. То есть, я отлично умею их делать, и если надо, сделаем как на примере выше, и зайдем в ТОП. Но пока нет вообще никакой необходимости.
Знаете, почему их нет? Потому что хватает клиентов с экспертных материалов. У нас десятки подробных статей формата «Как написать продающий текст», «Примеры Landing Page по обучению» и так далее. В итоге люди приходят прямо с ПС и заказывают.
Потенциал LSI-копирайтинга для бизнеса реально огромен. Можно создать личный бренд, можно продвинуть услуги, можно вывести компанию в статус экспертов, можно забирать очень сложные ТОП даже у огромных холдингов.
Возможности экспертного контента еще настолько не раскрыты и настолько велики, что революция LSI-копирайтинга еще только-только зарождается.
3. Могли бы вы описать механику процесса, как и почему работает латентно-семантическое индексирование?
Механика процесса достаточно проста, если видеть все нюансы и иметь четкое представление о том, как это работает. И крайне сложна, если такого представления нет.
Я вряд ли смогу сказать об этом коротко, а долго — попросту не получится. Хотя бы потому, что в нашей программе обучения LSI-копирайтеров 55 уроков. Представляете? И некоторые из них по 30-40 минут очень сжатой и концентрированной информации.
4. Многие люди сейчас по-прежнему пишут тексты по техзаданиям, в которых указаны ключи с прямыми вхождениями, словоформами, пассажами, структурой с иерархией заголовков. И такие тексты неплохо ранжируются, даже без учета LSI. Как вы можете это прокомментировать?
Здесь начать можно с того, что совсем мусора с кривыми ключами в серьезных ТОП уже нет. Портянки SEO-текстов поисковики успешно выгнали на край географии. Загляните в Яндекс или Google по уже не раз упомянутому нами запросу «что такое LSI-копирайтинг». Там просто нет слабых статей.
На первых местах выдачи только очень сильные статьи от профессионалов. Это потому, что по этому запросу соперничают люди, которые хорошо смыслят в подобных текстах и ерунды не напишут.
Но есть еще миллионы запросов, куда LSI-контент попросту толком не добрался, поэтому соперничают более слабые игроки. Придут туда классные статьи, они потеснят выдачу.
Второй момент: текст- тексту рознь. Если автор владеет темой и может ее раскрыть, то даже по старинному ТЗ он напишет неплохо. Там так же будут нужные расширяющие запросы, релевантные слова и прочие признаки хорошего текста.
Важно понимать: что признаки идеального LSI-текста — это признаки органичной авторской статьи. И если такие признаки есть у «староверской» статьи, она вполне похожа на LSI. Другое дело, что если при создании конкретного LSI-текста идет ожидаемый результат, то у SEO-текстов в старом формате это, скорее, лотерея.
И еще один момент: я всегда говорю своим сотрудникам, читателям и студентам:
Продающие тексты заказывают не для того, что только они продают товары. Даже если вы просто поставите ценник и дадите характеристики, товары кто-то будет покупать. Информация — всегда информация, даже скудной информации хватает для принятия решения части клиентам. Продающие тексты заказывают, чтобы покупали больше.
Так и со старыми SEO-текстами. Где-то они усилены ссылками, где-то это траст сайта и его высокие поведенческие, где-то мощная группа в соцсетях и так далее. Есть очень много нюансов, которые помогают старому SEO. Порой информации и поддержки хватает, чтобы попасть в ТОП по части запросов.
И все же, чтобы контент максимально работал, нужно то, что дает ему такую возможность. А это сегодня по силам только LSI-копирайтингу.
5. Можно ли использовать LSI для продвижения посадочных страниц, изначально сделанных под контекстную рекламу? Есть ли у вас примеры, которые это подтверждают?
Да, безусловно можно. Миф о том, что посадочные страницы не для SEO, придумали жуткие вредители. В этом есть лишь очень небольшая часть правды, и заключается она в том, что поисковые системы и вправду не очень любят не обновляемые сайты.
Но здесь как раз все просто. Я, например, советую нашим клиентам делать дополнительный раздел под статьи и просто периодически добавлять немного контента.
В остальном же принципы идентичны. Поисковому роботу все равно, он видит только код и не особо разбирается в маркетинге.
Как пример могу показать один из одностраничников, к которому я писал текст, и который который уже более 2 лет сидит в ТОП Яндекс и Google по дорогим коммерческим запросам уровня «купить апидомик» и «продажа апидомика». 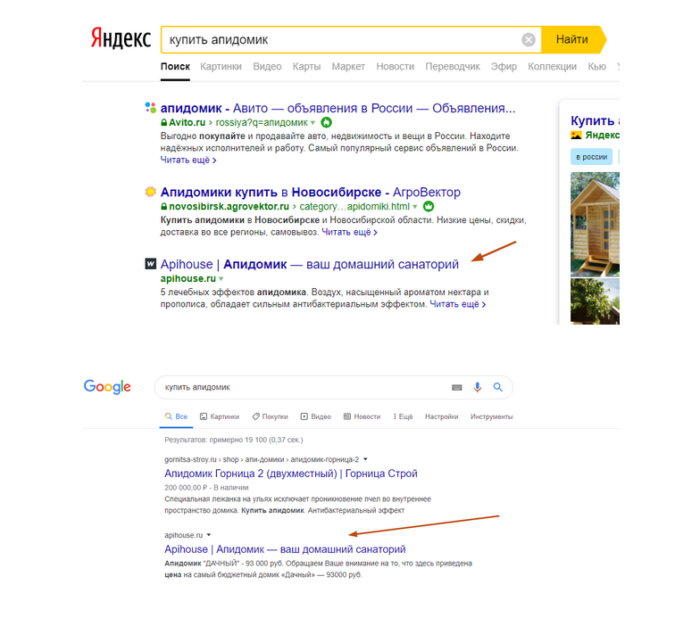
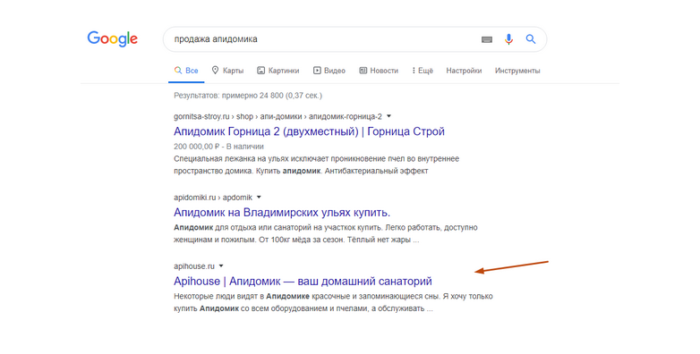
Как вы видите на примерах, этот одностраничник сидит намного выше, казалось бы огромных трастовых сайтов.
Таких примеров много, но все они работают по одному принципу: если преподнести текст хорошо и грамотно разбросать по нему ключи, плюс — подать все это на экспертном уровне, посадочные страницы будут попадать в ТОП, как и обычные сайты.
6. Можно ли использовать латентно-семантическое индексирование для продвижения небольших внутренних страниц коммерческих сайтов, например, карточек с описанием товаров, где объем текста не очень большой?
Да, конечно. Но там немного другая история. Если текста предполагается изначально мало, то нужно усиливать материал поведенческими факторами. Работает все, вплоть до опросов, видеообзоров товара и прочих элементов, позволяющих задержать человека на странице.
Но все же ключи нужны, другое дело, что теперь они уже не главный игрок, а, скажем так, правая рука.
7. Сейчас идет тенденция на автоматизацию. Есть ли какие-нибудь хорошие сервисы для автоматического сбора LSI слов?
Таких сервисов много. Мои любимые: Mutagen и PixelTools. А вообще, для сбора информации к LSI-статье используются разные виды инструментов. Какой-то лучше оценивает конкуренцию, какой-то хорошо собирает «хвосты», третий анализирует выдачу и сбивает кластеры. Это комплексная работа.
Важно понимать, что инструменты — это, конечно, здорово, но нельзя забывать и о мозговом штурме. В моей работе 80% — это именно штурм, а 20% — инструменты.
Человеческая интуиция, маркетинговое мышление, нестандартные ходы — все это крайне важно для написания классного LSI-текста.
8. Насколько долговечным вы лично считаете направление LSI-копирайтинга? Не ждет ли его забвение при очередном изменении поисковых алгоритмов или при развитии нейронных сетей?
Поисковым алгоритмам некуда меняться. Они взяли глобальный курс на качество авторского контента и его выделение на общем фоне. Это же не фишка, не баг, не хитрость какая-то. Это новые реалии, в которых мы будем теперь жить.
Поисковики поумнели, они могут себе теперь позволить то, что раньше было для них лишь мечтой. Так что это на очень-очень долгие годы, причем пока еще все только начинается.
9. Какие еще ключевые факторы влияют на продвижение страниц, если говорить о внутренней SEO текстов?
Это огромный пласт поведенческих факторов, которые учитываются поисковыми системами. Навигация по сайту, время на странице, возвращения из закладок — все это в комплексе влияет.
Скажу просто: даже если вы жутко крутой эксперт и написали идеальную LSI-статью, но при этом оформили ее как попало и слили абзацы в огромные простыни, это очень негативно повлияет на восприятие контента.
Очень-очень много нюансов.
10. Сколько времени нужно, чтобы освоить направление LSI-копирайтинга и уверенно продвигать свои сайты без помощи специалистов со стороны? Какие технические средства и затраты для этого нужны?
У нас есть единственная в Рунете программа профессионального обучения LSI-копирайтингу (давать ссылку не буду, можно погуглить), где студенты поднимаются до уровня достаточно уверенных LSI-копирайтеров за 2-3 месяца. При этом иногда компании приводят сотрудников, которые отлично ориентируются в секретах своего бизнеса, но крайне поверхностно разбираются в копирайтинге.
И все равно: даю домашние задания, показываю ошибки, постепенно все приходит. Так что минимум месяца полтора, максимум — месяца четыре.
Технических затрат не нужно, даже если средства крайне ограничены, есть бесплатные аналоги платных сервисов, которых вполне достаточно, чтобы писать полноценные LSI-тексты.
Если есть желание думать, проводить мозговые штурмы и учиться, проблемы не вижу — LSI-копирайтинг вам покорится.
Здравствуйте, Андрей. Вы сходу задаете настолько масштабные вопросы, что у меня сразу язык немного пересох в предвкушении объяснений. Но давайте попробуем.
На самом деле я не очень понимаю, зачем нужны мифы, если есть официальная позиция поисковых систем и явная смена вектора их развития. Чтобы понять, что такое LSI-копирайтинг и почему он должен был появиться, давайте вернемся назад лет на 10, когда все было иначе.
Как было раньше? Раньше было так: вводим “диван купить оптом Москва дешево” и на первом месте были жуткие SEO-простыни, в которых вписано по 300 миллионов запросов “диван купить оптом Москва дешево”.
Интересность? Ценность контента? Смысловая уникальность? Ничего этого не было в помине. Было сплошное манипулирование поисковой выдачей и страдание читателей.
То есть, изначально, когда поисковые системы не были столь гибкими и не могли отслеживать огромный пласт разных поведенческих факторов, алгоритм поиска был совершенно иным. Топорным. В его основе лежали принципы шингловой (технической) уникальности текста (до сих пор используется на биржах типа ETXT) и наличие конкретных ключевых запросов. Пусть и совершенно неадекватных.
Как мы уже выяснили, манипуляция поиском была глобальной. Это сегодня вы можете ввести “кривой” запрос уровня “диван купить оптом Москва дешево”, но умные Яндекс и Google дадут вам совершенно иную выдачу, где подобные слова могут встречаться, но сами статьи явно не пересыпаны подобными вхождениями.
Раньше же была вполне стандартной ситуация, когда на вас сыпались списки статей с названиями, идентичными вашему запросу.
А что в итоге? В итоге Сеть захлестнула волна низкосортного бреда, единственная ценность которого – соответствие введенным ключам. Люди не получали пользы, потому что ТОП был оккупирован ужасными SEO-портянками.
Это распространилось настолько, что стало ясно – нужно что-то менять. К этому времени как раз и технологии развились значительно лучше, и нейронные сети стали реальностью, и поисковики значительно поумнели.
В итоге был совершен мощный поворот в сторону качества контента. Вспомните, еще 10 лет назад SEO-тексты были чем-то вроде ругательства. Сегодня же фразу “контент-король” не говорит только ленивый.
Это случилось потому, что поисковые системы значительно усилили и расширили алгоритмы анализа контента. Теперь совершенно недостаточно написать простыню текста с запросами.
Сегодня стали очень важны смысловая уникальность и поведенческие факторы. Если поисковики видят, что у вас “вроде бы все классно”, но по факту со статьи массово уходят, то хоть золотом свой материал покройте, его все равно выкинет на самый край выдачи.
Поисковые системы больше не ориентируются только на запросы. Да, они до сих пор важны, но теперь важны даже не просто запросы, а расширенная семантика запроса вкупе с высокими поведенческими факторами.
Это именно та защита, которую поисковики дали сильному экспертному контенту..
А почему поисковикам настолько важен экспертный контент? Все просто: чем лучше Google или Яндекс ищут, тем выше лояльность аудитории. Следовательно, качество поиска нужно максимально усиливать и защищать.
Вот все это вкупе и дало то, что мы называем сегодня LSI-копирайтингом. Это совершенно новая модель ранжирования и анализа контента, основанная на совсем иных принципах, чем раньше.
Если вкратце, то Latent Semantic Indexing (скрытое семантическое индексирование) выглядит следующим образом:
1. Соответствие слов тематике статьи. Например, давайте возьмем это интервью. Пусть будет его основной темой запрос “что такое LSI-копирайтинг”.
Соответственно, по такому запросу поисковые системы уже примерно понимают, какие именно слова будут использованы в тексте. Если они есть в материале, значит статья тематична.
Часть таких слов, если вы пишете даже сами (без анализа инструментами), все равно органично появится, но можно посмотреть и с помощью инструментов.
Как мы видим, слова совершенно органичны, и где-то половину из них я использовал в этом интервью, даже не глядя на анализ системы.
Это самый простой и достаточно действенный способ анализа контента.
2. Подбор синонимичных запросов, расширяющих и дополняющих тематику.
Давайте пофантазируем: вот мы пишем статью по запросу “что такое LSI-копирайтинг”. Что еще нам, как читателем, будет интересно узнать?
Скорее всего, что-то вроде “примеры LSI-копирайтинга”, “как работает LSI-копирайтинг”, “Отличия LSI-текстов от SEO-контента”, “правила создания LSI-текстов”, их стоимость и прочие сопутствующие моменты.
Это также определяется как сервисами, так и с помощью мозгового штурма.
Следовательно, чем шире у нас статья, чем больше смежных (но интересных нашей ЦА) тем раскрыто, причем раскрыто экспертно (с фишками, кейсами, примерами, ошибками), тем круче и интересней считается контент в глазах ПС.
Естественно, все это работает только в том случае, если ваши посты подкреплены серьезными ПФ: репосты в соцсетях, много времени на странице, комментирование, невозвращение для поиска снова в ПС, добавление закладки и другие элементы положительной активности читателя.
Если же вы накупили пучок дешевых текстов по похожим темам на бирже и “хитро” собрали это в один материал, то такой контент быстро будет просчитан поисковиками. У него вряд ли будут высокие ПФ, следовательно, особых бонусов ждать не получится.
Да, какой-то трафик будет, но совсем не такой, какой вы могли бы получить, если бы все делали “по науке”,
Это не главная тема статьи, под этот ключ мы целенаправленно не работали, но за счет экспертности и высоких ПФ он все равно тоже входит в ТОП. И чем шире и экспертней статья, тем больше вашей семантики будет вверху поисковой выдачи.
Скажу еще больше: мы даже забираем те запросы, которых в их прямом значении нет в тексте или есть, но очень эпизодично. Скажем, вы пишете по теме “SMM-продвижение: лучшие сервисы”, а в ТОП заходите еще и по запросу “Как продвинуться в социальных сетях”.
Благодаря тому, что поисковые системы умнеют буквально на глазах и отслеживают уже даже скрытые логические, лингвистические и смысловые связки, у LSI-текстов невероятно много возможностей.
Это если совсем вкратце об определении LSI-формата. Если кто-то хочет прочитать более расширенную версию, могу предложить свое интервью на нашем сайте. Там про LSI-дано более полно и более подробно.
Так что не стоит верить мифам и легендам. Есть вполне четкие правила, по которым сегодня играют поисковые системы.
Ух, это мой самый любимый вопрос, меня на нем постоянно несет. Вообще потенциал LSI-копирайтинга для бизнеса огромен. Серьезно.
Главный плюс в том, что использование экспертных текстов с правильной LSI-оптимизацией позволяет ворваться в любые ТОП даже совершенно неизвестным компаниям и закрепиться там. При правильном подходе можно забирать ключевые запросы, которые раньше в выдаче вам даже не светили, а в рекламе стоят колоссальных денег.
Давайте я буду давать примеры, чтобы не быть голословным.
Вот. например, компания Aquarama, занимающаяся производством и продажей автомоек. Ее сильная сторона – отличные экспертные статьи по всей нужной им семантике.
Это не один случайный пример, статей компании по самым разным запросам в ТОП сотни. Они серьезно подходят к работе, пишут развернутые экспертные материалы, а в итоге – самая горячая выдача и самые целевые клиенты.
В итоге человек приходит, он видит ответы на свои вопросы, статус экспертов подтвержден, лояльность максимальна. До покупки – всего 1 шаг. И это все происходит органично, без колоссальных рекламных затрат. Контент, который работает сам на себя.
Еще пример. ТОП выдачи по запросу “автоворонки продаж”.
Ребята создали большую и подробную статью-лендинг на тему автоворонок. Пока вы не дойдете до конца, вы даже не поймете, что это продажник. Дана полная расшифровка, объяснены принципы работы автоворонки, примеры разных видов воронок. Много графики и нужных терминов.
Никакой рекламы. Вообще. Только в самом конце призыв создать автоворонку у экспертов. А статус экспертов уже подтвержден тем, что человек дочитал до конца. Он уже получил максимум пользы, поэтому вероятность обращения опять же велика.
Скажу даже по нашему проекту https://petr-panda.ru/. У нас сейчас вообще нет страниц услуг. То есть, я отлично умею их делать, и если надо, сделаем как на примере выше, и зайдем в ТОП. Но пока нет вообще никакой необходимости.
Знаете, почему их нет? Потому что хватает клиентов с экспертных материалов. У нас десятки подробных статей формата “Как написать продающий текст”, “Примеры Landing Page по обучению” и так далее. В итоге люди приходят прямо с ПС и заказывают.
Потенциал LSI-копирайтинга для бизнеса реально огромен. Можно создать личный бренд, можно продвинуть услуги, можно вывести компанию в статус экспертов, можно забирать очень сложные ТОП даже у огромных холдингов.
Возможности экспертного контента еще настолько не раскрыты и настолько велики, что революция LSI-копирайтинга еще только-только зарождается.
Механика процесса достаточно проста, если видеть все нюансы и иметь четкое представление о том, как это работает. И крайне сложна, если такого представления нет.
Я вряд ли смогу сказать об этом коротко, а долго – попросту не получится. Хотя бы потому, что в нашей программе обучения LSI-копирайтеров 55 уроков. Представляете? И некоторые из них по 30-40 минут очень сжатой и концентрированной информации.
Если вот “совсем-совсем просто”, то шаги следующие:
Здесь начать можно с того, что совсем мусора с кривыми ключами в серьезных ТОП уже нет. Портянки SEO-текстов поисковики успешно выгнали на край географии. Загляните в Яндекс или Google по уже не раз упомянутому нами запросу “что такое LSI-копирайтинг”. Там просто нет слабых статей.
На первых местах выдачи только очень сильные статьи от профессионалов. Это потому, что по этому запросу соперничают люди, которые хорошо смыслят в подобных текстах и ерунды не напишут.
Но есть еще миллионы запросов, куда LSI-контент попросту толком не добрался, поэтому соперничают более слабые игроки. Придут туда классные статьи, они потеснят выдачу.
Второй момент: текст- тексту рознь. Если автор владеет темой и может ее раскрыть, то даже по старинному ТЗ он напишет неплохо. Там так же будут нужные расширяющие запросы, релевантные слова и прочие признаки хорошего текста.
Важно понимать: что признаки идеального LSI-текста – это признаки органичной авторской статьи. И если такие признаки есть у “староверской” статьи, она вполне похожа на LSI. Другое дело, что если при создании конкретного LSI-текста идет ожидаемый результат, то у SEO-текстов в старом формате это, скорее, лотерея.
И еще один момент: я всегда говорю своим сотрудникам, читателям и студентам:
Продающие тексты заказывают не для того, что только они продают товары. Даже если вы просто поставите ценник и дадите характеристики, товары кто-то будет покупать. Информация – всегда информация, даже скудной информации хватает для принятия решения части клиентам. Продающие тексты заказывают, чтобы покупали больше.
Так и со старыми SEO-текстами. Где-то они усилены ссылками, где-то это траст сайта и его высокие поведенческие, где-то мощная группа в соцсетях и так далее. Есть очень много нюансов, которые помогают старому SEO. Порой информации и поддержки хватает, чтобы попасть в ТОП по части запросов.
И все же, чтобы контент максимально работал, нужно то, что дает ему такую возможность. А это сегодня по силам только LSI-копирайтингу.
Да, безусловно можно. Миф о том, что посадочные страницы не для SEO, придумали жуткие вредители. В этом есть лишь очень небольшая часть правды, и заключается она в том, что поисковые системы и вправду не очень любят не обновляемые сайты.
Но здесь как раз все просто. Я, например, советую нашим клиентам делать дополнительный раздел под статьи и просто периодически добавлять немного контента.
В остальном же принципы идентичны. Поисковому роботу все равно, он видит только код и не особо разбирается в маркетинге.
Как пример могу показать один из одностраничников, к которому я писал текст, и который который уже более 2 лет сидит в ТОП Яндекс и Google по дорогим коммерческим запросам уровня “купить апидомик” и “продажа апидомика”.
Как вы видите на примерах, этот одностраничник сидит намного выше, казалось бы огромных трастовых сайтов.
Добился я этого тем, что:
Таких примеров много, но все они работают по одному принципу: если преподнести текст хорошо и грамотно разбросать по нему ключи, плюс – подать все это на экспертном уровне, посадочные страницы будут попадать в ТОП, как и обычные сайты.
Да, конечно. Но там немного другая история. Если текста предполагается изначально мало, то нужно усиливать материал поведенческими факторами. Работает все, вплоть до опросов, видеообзоров товара и прочих элементов, позволяющих задержать человека на странице.
Но все же ключи нужны, другое дело, что теперь они уже не главный игрок, а, скажем так, правая рука.
Таких сервисов много. Мои любимые: Mutagen и PixelTools. А вообще, для сбора информации к LSI-статье используются разные виды инструментов. Какой-то лучше оценивает конкуренцию, какой-то хорошо собирает “хвосты”, третий анализирует выдачу и сбивает кластеры. Это комплексная работа.
Важно понимать, что инструменты – это, конечно, здорово, но нельзя забывать и о мозговом штурме. В моей работе 80% – это именно штурм, а 20% – инструменты.
Человеческая интуиция, маркетинговое мышление, нестандартные ходы – все это крайне важно для написания классного LSI-текста.
Поисковым алгоритмам некуда меняться. Они взяли глобальный курс на качество авторского контента и его выделение на общем фоне. Это же не фишка, не баг, не хитрость какая-то. Это новые реалии, в которых мы будем теперь жить.
Поисковики поумнели, они могут себе теперь позволить то, что раньше было для них лишь мечтой. Так что это на очень-очень долгие годы, причем пока еще все только начинается.
Это огромный пласт поведенческих факторов, которые учитываются поисковыми системами. Навигация по сайту, время на странице, возвращения из закладок – все это в комплексе влияет.
Скажу просто: даже если вы жутко крутой эксперт и написали идеальную LSI-статью, но при этом оформили ее как попало и слили абзацы в огромные простыни, это очень негативно повлияет на восприятие контента.
Очень-очень много нюансов.
У нас есть единственная в Рунете программа профессионального обучения LSI-копирайтингу (давать ссылку не буду, можно погуглить), где студенты поднимаются до уровня достаточно уверенных LSI-копирайтеров за 2-3 месяца. При этом иногда компании приводят сотрудников, которые отлично ориентируются в секретах своего бизнеса, но крайне поверхностно разбираются в копирайтинге.
И все равно: даю домашние задания, показываю ошибки, постепенно все приходит. Так что минимум месяца полтора, максимум – месяца четыре.
Технических затрат не нужно, даже если средства крайне ограничены, есть бесплатные аналоги платных сервисов, которых вполне достаточно, чтобы писать полноценные LSI-тексты.
Если есть желание думать, проводить мозговые штурмы и учиться, проблемы не вижу – LSI-копирайтинг вам покорится.
На этом пока все. Большое спасибо, Петр, за уделенное время и развернутые ответы на вопросы.
Коллеги, если вам есть что сказать, прошу в комментарии.
Панда пробил дно. С какого перепою, 11 запросов в месяц, это дорогой коммерческий запрос?
Автор, ты хотя бы проверяй иногда, что несут интервьюируемые.
Вы пробиваете дно самостоятельно, без моей помощи, путаясь в самых простых вещах. А именно в разнице между частотностью запросов, конкурентностью и их коммерческой ценностью.
Если бы вы нормально разбирались в теме, то знали бы, что существует 3 формата определения запросов. Они делятся на:
Частотность поиска
Конкуренцию в поиске
Стоимость клика.
И эти вещи очень часто НЕ пересекаются.
Например, запрос «скачать песню». Почти 500 000 запросов только в Яндекс. Но цена первого места в рекламе всего 4 рубля. Это популярный частотный (высокочастотный) запрос с точки зрения SEO, но недорогой запрос с точки зрения Директа. А ведь мы о контекстной рекламе говорили в вопросе, может, помните?
Это просто песня, верно?
Такие запросы не могут быть высокочастотными по определению, потому что они не массовые. Апидомики нужны меньшему числу людей, чем песни. Но именно из-за этого там идет глобальная битва за каждого запросившего. Прибыль от продажи частного самолета или апидомика и прибыль от скачивания песни немножко разнятся.
Но самое забавное, что спецразмещение уже 50 рублей. Это, конечно, не элитные пентхааусы в Москве, но уже рядом с бентли и частными самолетами.
Или подобные запросы вы тоже коммерчески ценными не считаете?
Вывод: это высококкурентный запрос с хорошей ценой клика (изучите, кстати, почему понятие «высоконкурентный запрос» и понятие «высокочастотный запрос» абсолютно не идентичны, их роднит только приставка «высоко»).



