ИТ База знаний
Полезно
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Важное про OSPF LSA
Информация о топологии сети
Протокол маршрутизации OSPF (Open Shortest Path First) (про него можно прочитать тут, а про его настройку здесь) для обмена информации о топологии сети использует сообщения LSA (Link State Advertisement). Когда роутер получает LSA сообщение, он помещает его в базу Link-State DataBase (LSDB). Когда все базы между маршрутизаторами синхронизированы, OSPF использует алгоритм Shortest Path First, чтобы высчитать лучший маршрут между сетями.
Полный курс по Сетевым Технологиям
В курсе тебя ждет концентрат ТОП 15 навыков, которые обязан знать ведущий инженер или senior Network Operation Engineer

LSA содержат в себе информацию о маршруте передается внутри Link State Update (LSU) пакета. Каждый LSU пакет содержит в себе один или несколько LSA, и когда LSU отправляется между маршрутизаторами OSPF, он распространяет информацию LSA через сеть. Каждый LSA используется в определенных границах сети OSPF.
Выглядит это вот так:

Типы LSA
OSPF в настоящее время определяет 11 различных типов LSA, однако, несмотря на большое разнообразие LSA, только около половины из них обычно встречаются в сетях OSPF, но мы рассмотрим их все.
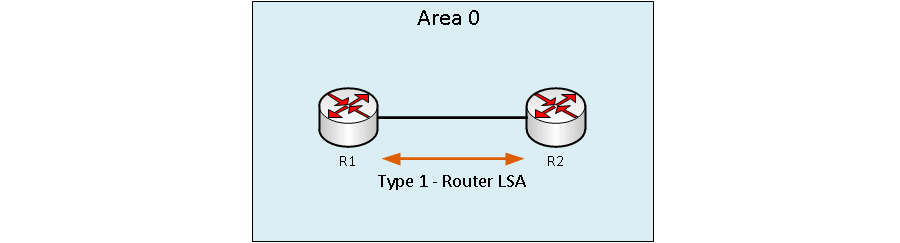
LSA Тип 1 – OSPF Router LSA
Пакеты LSA Type 1 (Router LSA) отправляются между маршрутизаторами в пределах одной и той же зоны (area) где они были созданы и не покидают эту зону. Маршрутизатор OSPF использует пакеты LSA Type 1 для описания своих собственных интерфейсов, а также передает информацию о своих соседях соседним маршрутизаторам в той же зоне.
LSA Тип 2 – OSPF Network LSA
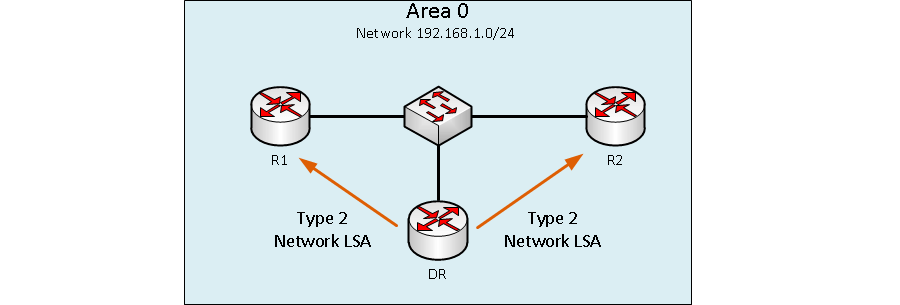
Пакеты LSA Type 2 (Network LSA) генерируются Designated Router’ом (DR) для описания всех маршрутизаторов, подключенных к его сегменту напрямую. Пакеты LSA Type 2 рассылаются между соседями в одной и той же зоны где они были созданы и остаются в пределах этой зоны.
LSA Тип 3 – OSPF Summary LSA
Пакеты LSA Type 3 (Summary LSA) генерируются с помощью пограничных маршрутизаторов Area Border Routers (ABR) и содержат суммарное сообщение о непосредственно подключенной к ним зоне и сообщают информацию в другие зоны, к которым подключен ABR. Пакеты LSA Type 3 отправляются в несколько зон по всей сети.
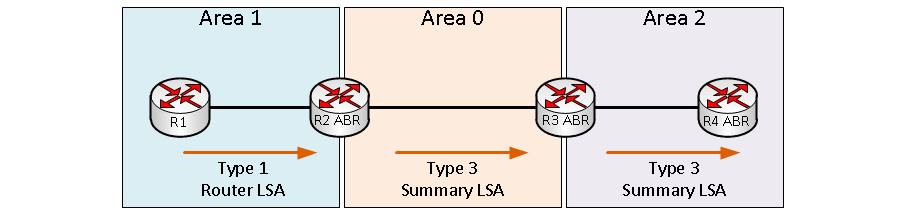
На рисунке показано как маршрутизатор R2 ABR создает Type 3 Summary LSA и отправляет их в зону Area 0. Таким же образом R3 ABR роутер создает пакеты Type 3 и отправляет их в Area 2. В таблице маршрутизации маршруты, полученные таким образом, отображаются как “O IA”
Видео: протокол OSPF (Open Shortest Path First) за 8 минут
LSA Тип 4 – OSPF ASBR Summary LSA

На схеме, когда R2 (ABR) принимает пакет LSA Type 1 от R1, он создаст пакет LSA Type 4 (Summary ASBR LSA), который передает маршрут ASBR, полученный из Area 1, и вводит его в Area 0. Хотя пакеты LSA Type 4 используются ABR для объявления маршрута ASBR через их зоны, он не будет использоваться самим ASBR в пределах его локальной зоны (Area 1); ASBR использует LSA Type 1 для информирования своих соседей (в данном случае R2) в своих сетях.
LSA Тип 5 – OSPF ASBR External LSA
Пакеты LSA Type 5 (ASBR External LSA) генерируются ASBR для передачи внешних перераспределенных маршрутов в автономную систему (AS) OSPF. Типичным примером LSA Type 5 будет внешний префикс или маршрут по умолчанию (default router), как показано на схеме.

Этот внешний маршрут/префикс перераспределяется в OSPF-сеть ASBR (R1) и в таблице маршрутизации будет отображаться как «O E1» или «O E2«.
LSA Тип 6 – OSPF Group Membership LSA
LSA Тип 7 – OSPF Not So Stubby Area (NSSA) External LSA
Пакеты LSA Type 7 (NSSA External LSA) используются для некоторых специальных типов зон, которые не позволяют внешним распределенным маршрутам проходить через них и таким образом блокируют распространение в них LSA Type 5. LSA Type 7 действуют как маска для LSA Type 5 пакетов, позволяя им перемещаться по этим специальным зоам и достигать ABR, который может переводить пакеты LSA Type 7 обратно в пакеты LSA Type 5.

На схеме ABR R2 переводит LSA Type 7 в LSA Type 5 и рассылает его в сеть OSPF.
LSA Тип 8 – OSPF External Attributes LSA (OSPFv2) / Link Local LSA (OSPFv3)
LSA Тип 9, 10 и 11
Обычно LSA этих типов используются для расширения возможностей OSPF. Практическое применение этих LSA заключается в Traffic Engineering’е MPLS, где они используются для передачи параметров интерфейса, таких как максимальная пропускная способность, незанятая полоса пропускания и т.д.
LSA Тип 9 – OSPF Link Scope Opaque (OSPFv2) / Intra Area Prefix LSA (OSPFv3)
LSA Type 9 в OSPFv2 (IPv4) определяется как Link Scope Opaque LSA для передачи OSPF информации. Для OSPFv3 он переопределяется для обработки префикса связи для специального типа зоны, называемого Stub Area.
LSA Тип 10 – OSPF Area Scope Opaque LSA
Пакеты LSA Type 10 используются для потоковой передачи информации OSPF через маршрутизаторы других областей. Даже если эти маршрутизаторы не обрабатывают эту информацию, чтобы расширить функциональность OSPF, этот LSA используется для Traffic Engineering’а для объявлений MPLS и других протоколов.
LSA Тип 11– OSPF AS Scope Opaque LSA
Пакеты LSA Type 11 выполняют ту же задачу, что и пакеты LSA Type 10, но не пересылаются в специальные зоны (Stub зоны)
Полный курс по Сетевым Технологиям
В курсе тебя ждет концентрат ТОП 15 навыков, которые обязан знать ведущий инженер или senior Network Operation Engineer
Латентно-семантический анализ: реализация
Как упоминалось в предыдущей статье, латентно-семантический анализ (ЛСА / LSA) позволяет выявлять латентные связи изучаемых явлений или объектов, что является немаловажным критерием при моделировании процессов понимания и мышления.
Теперь я напишу немного о реализации ЛСА.
Немного истории
ЛСА был запатентован в 1988 году группой американских инжинеров-исследователей S.Deerwester at al [U.S. Patent 4,839,853 ].
В области информационного поиска данный подход называют латентно-семантическим индексированием (ЛСИ).
Впервые ЛСА был применен для автоматического индексирования текстов, выявления семантической структуры текста и получения псевдодокументов. Затем этот метод был довольно успешно использован для представления баз знаний и построения когнитивных моделей. В США этот метод был запатентован для проверки знаний школьников и студентов, а так же проверки качества обучающих методик.
Описание работы ЛСА
В качестве исходной информации ЛСА использует матрицу термы-на-документы (термы – слова, словосочетания или н-граммы; документы – тексты, классифицированные либо по какому-либо критерию, либо разделенные произвольным образом – это зависит от решаемой задачи), описывающую набор данных, используемый для обучения системы. Элементы этой матрицы содержат, как правило, веса, учитывающие частоты использования каждого терма в каждом документе или вероятностные меры (PLSA – вероятностный латентно-семантический анализ), основанные на независимом мультимодальном распределении.
Наиболее распространенный вариант ЛСА основан на использовании разложения вещественнозначной матрицы по сингулярным значениям или SVD-разложения (SVD – Singular Value Decomposition). С помощью него любую матрицу можно разложить в множество ортогональных матриц, линейная комбинация которых является достаточно точным приближением к исходной матрице.
Согласно теореме о сингулярном разложении в самом простом случае матрица может быть разложена на произведение трех матриц: 
где матрицы U и V – ортогональные, а S – диагональная матрица, значения на диагонали которой называются сингулярными значениями матрицы A.
Символ Т в обозначении матрицы означает транспонирование матрицы.
Особенность такого разложения в том, что если в матрице S оставить только k наибольших сингулярных значений, то линейная комбинация получившихся матриц будет наилучшим приближением исходной матрицы A к матрице Ă ранга k:
Основная идея латентно-семантического анализа состоит в следующем:
после перемножения матриц полученная матрица Ă, содержащая только k первых линейно независимых компонент исходной матрицы A, отражает структуру зависимостей (в данном случае ассоциативных), латентно присутствующих в исходной матрице. Структура зависимостей определяется весовыми функциями термов для каждого документа.
Выбор k зависит от поставленной задачи и подбирается эмпирически. Он зависит от количества исходных документов.
Если документов не много, например сотня, то k можно брать 5-10% от общего числа диагональных значений; если документов сотни тысяч, то берут 0,1-2%. Следует помнить, что если выбранное значение k слишком велико, то метод теряет свою мощность и приближается по характеристикам к стандартным векторным методам. А слишком маленькое значение k не позволяет улавливать различия между похожими термами или документами: останется только одна главная компонента, которая «перетянет на себя одеяло», т.е. все слабо и даже несвязанные термы. 
Рисунок 1. SVD-разложение матрицы А размерности (T X D) на матрицу термов U размерности (T X k), матрицу документов V размерности (k X D) и диагональную матрицу S размерности (k X k), где k – количество сингулярных значении диагональной матрицы S.
Объем корпуса для построения модели должен быть большим – желательно около трех-пяти миллионов словоупотреблений. Но метод работает и на коллекциях меньшего объема, правда несколько хуже.
Произвольное разбиение текста на документы обычно производят от тысячи до нескольких десятков тысяч частей примерно одинакового объема. Таким образом, матрица термы-на-документы получается прямоугольной и может быть сильно разраженной. Например, при объеме 5 млн. словоформ получается матрица 30-50 тысяч документов на 200-300 тысяч, а иногда и более, термов. В действительности, низкочастотные термы можно опустить, т.к. это заметно снизит размерность матрицы (скажем, если не использовать 5% от общего объема низкочастотных термов, то размерность сократиться в два раза), что приведет к снижению вычислительных ресурсов и времени.
Выбор сокращения сингулярных значений диагональной матрицы (размерности k) при обратном перемножении матриц, как я писал, дело произвольное. При вышеуказанной размерности матрицы оставляют несколько сотен (100-300) главных компонент. При этом, как показывает практика, зависимость количества компонент и точность меняются нелинейно: например, если начинать увеличивать их число, то точность будет падать, но при некотором значении, скажем, 10000 – опять вырастет до оптимального случая.
Ниже приведен пример возникновения и изменения главных факторов при уменьшении числа сингулярных элементов диагональной матрицы.
Точность можно оценивать на размеченном материале, например, заранее скорректировав результат по hсоответствию ответов на вопросы.
Более подробная информация об этом методе содержится, например, в обзорных статьях [см. список литературы].
Желающие попробовать работу LSA могут скачать бинарники для построения моделей и для их проверки и использования.
В программе для SVD разложения матрицы при построении моделей использован открытый код (Copyright Sergey Bochkanov (ALGLIB project).), поэтому программы распространяются без ограничений.
Применение
Достоинства и недостатки ЛСА
Достоинством метода можно считать его замечательную способность выявлять зависимости между словами, когда обычные статистические методы бессильны. ЛСА также может быть применен как с обучением (с предварительной тематической классификацией документов), так и без обучения (произвольное разбиение произвольного текста), что зависит от решаемой задачи.
Об основных недостатках я писал в предыдущей статье. К ним можно добавить значительное снижение скорости вычисления при увеличении объема входных данных (в частности, при SVD-преобразовании).
Как показано в [Deerwester et al.], скорость вычисления соответствует порядку , где — сумма количества документов и термов, k– размерность пространства факторов.
Небольшой демо-пример расчета матрицы близости полнотекстовых документов при разном количестве сингулярных элементов диагональной матрицы в SVD-преобразовании
На рисунках показано возникновение и изменение главных факторов при уменьшении числа сингулярных элементов диагональной матрицы от 100% до
12%. Трехмерные рисунки представляют собой симметричную матрицу, полученную в результате вычисления скалярного произведения векторов каждого эталонного документа с каждым тестируемым. Эталонный набор векторов – это заранее размеченный на 30 документов текст; тестируемый – с уменьшением числа сингулярных значений диагональной матрицы, полученной при SVD-анализе. На осях X и Y откладывается количество документов (эталонных и тестируемых), на оси Z – объем лексикона.
На рисунках хорошо видно, что при уменьшении числа сингулярных диагональных элементов на 20-30% факторы еще не достаточно ярко выявлены, но при этом возникают корреляции похожих документов (небольшие пики вне диагонали), которые сначала незначительно увеличиваются, а затем, с уменьшением числа сингулярных значений (до 70-80%) – исчезают. При автоматической кластеризации такие пики являются шумом, поэтому их желательно минимизировать. Если же целью является получение ассоциативных связей внутри документов, то следует найти оптимальное соотношение сохранения основного лексикона и примешивания ассоциативного.
OSPF LSA в картинках
Тема протокола динамической маршрутизации OSPF уже не раз поднималась на хабре. Однако вопрос о том что такое LSA и какие они бывают, как мне кажется, недостаточно прозрачен. И я хотел бы рассказать об этом без привязки к конкретному производителю и консольным командам.
LSA type 1 — “кусочки с маршрутизаторами”
каждый маршрутизатор сообщает свой уникальный “router-id”, и подробный список интерфейсов.
для каждого интерфейса указывается:
IP адрес (если есть 3 )
тип интерфейса
“router-id” с которым установлено состояние смежности на это интерфейсе.
Если смежность(adjacencies) на интерфейсе не установлена, то в поле для “router-id” записывается маска сети для IP адреса и эту сторону кусочка можно считать “плоской” (дольше роутеров нет).
Если тип линка — точка-точка или виртуальное соединение, то теперь нужно найти другой кусочек, с известным “router-id” посредине и совместить соответствующие соединения.
Если тип интерфейса — Broadcast или NBMA (сеть множественного доступа), то на другом конце может быть много разных маршрутизаторов и тут нам становится необходимы
LSA type 2 — “кусочки с сетями”
LSA type 3 — “маршруты в другую область» 5
эту составляющую нарисуем как зелёный квадратик прицепленый к маршрутизатору, с информацией о сети из другой Area и стоимости соединения. Маршрутизатор к которому мы их подсоединяем — называется ABR. Интерфейсы к которым цепляем “рамочку” не указываются, т.к. они принадлежат другой области.
LSA type 5 — “маршруты других доменов маршрутизации”
LSA type 4 — длинный хвост.
что делать если маршрутизатор к которому надо прицепить сети из предыдущего пункта находится в другой Area? Специально для этого, устройства находящиеся на границе 2х Area передают не только “LSA type 3” но и “LSA type 4” в которых анонасируют, обо всех известных маршрутах к ASBR из других Area, и их стоимость. Нарисуем такой ASBR зелёным цветом. Особо интересный случай рассмотреный в этой статье, можно изобразить как оранжевый квадратик прицепленый к зелёному.
Получается, что на последнем рисунке:
синие маршрутизаторы с интерфейсами это LSA type 1
облачко с префиксом — LSA type 2
зелёные квадратики — LSA type 3
оранжевые квадратики это LSA type 5
зелёный роутер — LSA type 4
зелёные и оранжевые соеденительные линии несут информацию о стоимости соответвующего соединения.
маршрутизаторы y.y.y.y и z.z.z.z — ABR (в них входят зелёные линии)
маршрутизаторы k.k.k.k и w.w.w.w — ASBR (в них входят оранжевые линии)
LSA type 6 — на самом деле нигде и никем не используется, и основными вендорами не реализована. Поэтому пропускаем.
LSA type 7 — фактически полный аналог LSA type 5 для NSSA типов Area. При пересечении границы Area, в них и превращаются.
Остальные LSA с ИП маршрутами вобщем-то не связаны, поэтому их рассматривать не буду.
Маленький итог:
SFP процес который производит расчёт стоимости маршрутов алгоритмом Дейкстры — запускается только при изменениях в LSA 1 или 2 (обязательно при любых их изменениях).
Стоимость к маршрутам анонсируемым в других LSA получается простым сложением стоимости до ABR/ASBR и метрик зелёных и/или оранжевых “линков”.
Маршрутизатор может быть ABR и ASBR одновременно.
Когда “пазл” не складывается?
Достаточно часто бывает ситуация, когда из всех имеющихся кусочков — целостной картины не сложить. Это связано с тем что в Link State протоколах нет способа моментально отбросить “исчезнувший” ЛСА.
Рассмотрим последний рисунок.
Например, на роутере y.y.y.y упал интерфейс в сторону b.b.b.d (серого облака). Тогда y.y.y.y генерирует новый LSA типа1 (с тем же самым ID, но бо’льшим порядковым номером), где отключившегося интерфейса уже нет. z.z.z.z устанавливает в LSDB новый LSA, пересчитывает таблицу маршрутизации… Но всё ещё хранит в памяти все LSA полученые от g.g.g.g, m.m.m.m и k.k.k.k, связь с которыми уже потеряна. т.е. остались лишние кусочки. Аналогично, если вдруг у маршрутизатора поменяется “router-id”, то все остальные некоторое время хранят 2 копии LSA: со старым и с новым ID.
У каждого маршрутизатора имеется “router-id” и он обязательно должен быть уникальный. Что произойдёт если будут дубликаты — зависит от вендора и настроек, но одно можно утверждать уверенно — будут проблемы. Как самый простой пример: 2 маршрутизатора транслируют взаимоисключающие LSA; остальные будут устанавливать LSA с большим порядковым номером, а сети подключённые к другому устройству будут потеряны и недоступны. Это можно сравнить с потерей кусочка пазла.
Аналогично, не должно быть DR c одинаковыми IP адресами.
Смею надеяться, что сообщество найдёт такой стиль изложения интересным.
ИТ База знаний
Полезно
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Протокол маршрутизации OSPF: LSA, области и виртуальные ссылки
О состоянии канала
Прежде чем перейти к более сложным темам, мы завершим эту серию статей об основах OSPF. Здесь мы рассмотрим типы LSA, типы областей и виртуальные ссылки (LSA types, area types, и virtual links).
Полный курс по Сетевым Технологиям
В курсе тебя ждет концентрат ТОП 15 навыков, которые обязан знать ведущий инженер или senior Network Operation Engineer

OSPF LSA типы
Link State Advertisements (LSA) — Объявления состояния канала — это основа работы сетей на OSPF. Наполнение этих обновлений позволяют сети OSPF создать карту сети. Это происходит с помощью алгоритма кратчайшего пути Дейкстры.
Не все LSA OSPF равны. Ниже представлен каждый их них:
Изучите топологию OSPF, показанную на рисунке 1 ниже.
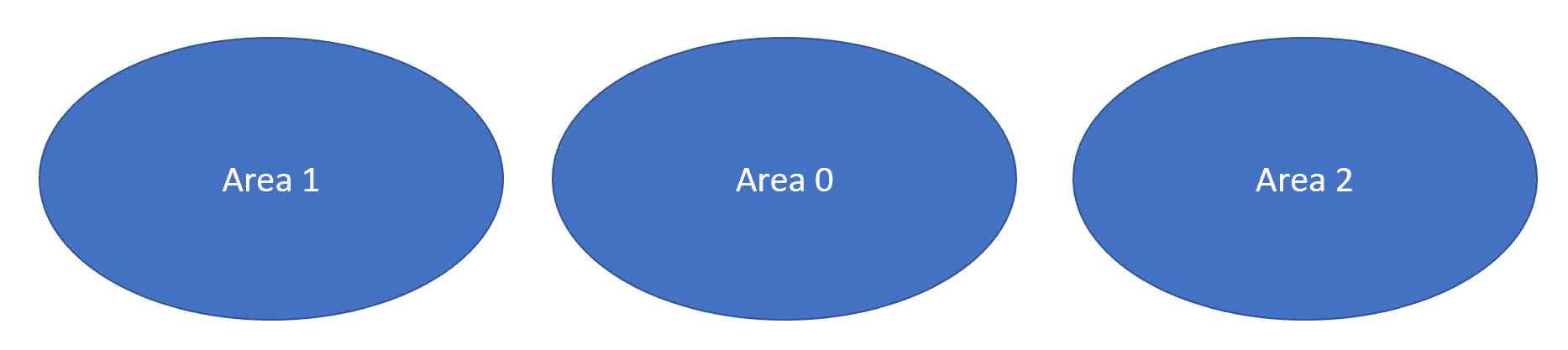
Рис. 1: Пример многозональной топологии OSPF
Область 1 ABR будет посылать Type 3 LSA в область 0. ABR, соединяющий область 0 и область 2, отправил эти Type 3 LSA в область 2, чтобы обеспечить полную достижимость в домене OSPF. Type 3 LSA остаются Type 3 LSA во время этой пересылки.
Другие типы LSA. Существуют ли другие типы LSA? Да. Но мы не часто сталкиваемся с ними. Например, Type 6 LSA используется для многоадресной (Multicast) передачи OSPF, и эта технология не прижилась, позволяя Protocol Independent Multicast передаче победить. Для завершения ниже показан полный список всех возможных типов LSA:
Видео: протокол OSPF (Open Shortest Path First) за 8 минут
OSPF типы LSA и типы Area
Одна из причин, по которой вы должны освоить различные типы LSA, заключается в том, что это поможет вам полностью понять потенциальную важность multi-area, особенно такого, который может включать специальные области. Ключом к важности специальных типов областей в OSPF является тот факт, что они инициируют автоматическую фильтрацию определенных LSA из определенных областей.
Например, подумайте о области 1, присоединенной к основной области области 0. Type 1 LSA заполнил область 1. Если у нас есть широковещательные сегменты, мы также имеем Type 2 LSA, циркулирующие в этой области. Area Border Router посылает LSA Type 3 в магистраль для суммирования префиксной информации из области 1.
Этот ABR также принимает эту информацию от магистрали для других областей, которые могут существовать. Если где-то в домене есть ASBR, наша область 1 получит LSA Type 4 и LSA Type 5, чтобы узнать местоположение этого ASBR и префиксы, которыми он делится с нами. Обратите внимание, что это является потенциальной возможностью для обмена большим количеством информации между областями. Именно поэтому у нас есть специальные типы зон!
OSPF LSAs и Stub Area (заглушка)
OSPF LSA и Totally Stubby Area (полностью короткая область)
Использование этой области имеют малые перспективы LSA. Использование этой области имеет смысл тогда, когда мы хотим снова заблокировать Type 4 и 5, но в данном случае мы блокируем даже LSA Type 3, которые описывают информацию префикса из других областей в нашем домене OSPF. Однако здесь имеется одно большое исключение. Нам нужен LSA Type 3 для маршрута по умолчанию, чтобы мы действительно могли добраться до других префиксов в нашем домене.
OSPF LSAs и Not So Stubby Area и Totally Not So Stubby Area
Запомните, что Not So Stubby Area должна иметь LSA Type 7. Эти LSA Type 7 допускают распространение тех внешних префиксов, которые входят в ваш домен OSPF благодаря этой созданной вами области NSSA. Очевидно, что эта область также имеет Type 1, Type 2 и Type 3 внутри нее. Type 4 и Type 5 будут заблокированы для входа в эту область, как и ожидалось. Вы также можете создать Totally Not So Stubby Area, ограничив Type 3 из этой области.
Virtual Links
Вспомните из нашего более раннего обсуждения OSPF, что все области в автономной системе OSPF должны быть физически связаны с основной областью (область 0). Там, где это невозможно, вы можете использовать виртуальную связь (virtual link) для подключения к магистрали через область, не являющуюся магистралью.
Учтите следующие факты о virtual link:
Вы создаете virtual link с помощью команды в режиме конфигурации OSPF:
Эта команда создает virtual link через область 1 с удаленным устройством OSPF с идентификатором маршрутизатора (Router ID) 3.3.3.3. Вы также настраиваете это удаленное устройство OSPF с помощью команды virtual-link. Например, если наше локальное устройство OSPF находится в Router ID 1.1.1.1, то соответствующая удаленная команда будет:
Примечание: virtual link — это всего лишь один из способов наладки нарушений в работе OSPF. Вы также можете использовать туннель GRE для исправления сбоев в работе OSPF.
Онлайн курс по Кибербезопасности
Изучи хакерский майндсет и научись защищать свою инфраструктуру! Самые важные и актуальные знания, которые помогут не только войти в ИБ, но и понять реальное положение дел в индустрии



