Hyper-Threading: «два-в-одном» от Intel, или Скрытые возможности Xeon
В нашем предыдущем материале по Intel Xeon 2,2 GHz мы писали, что использование однопроцессорных Xeon-систем лишено всякого смысла, поскольку при более высокой цене их производительность будет такой же, как и у Pentium 4 той же частоты. Теперь же, после более тщательного изучения, в это утверждение наверняка придется внести небольшую поправку. Технология Hyper-Threading, реализованная в Intel Xeon с ядром Prestonia, действительно работает и дает вполне ощутимый эффект. Хотя и вопросов при ее использовании тоже возникает немало…
Даешь производительность
«Быстрее, еще быстрее…». Гонка за производительностью длится уже не первый год, и порой даже трудно сказать, какой из компонентов компьютера ускоряется быстрее. Для этого изобретаются все новые и новые способы, и чем дальше, тем больше квалифицированного труда и высококачественных мозгов вкладывается в этот лавинообразный процесс.
Постоянный рост быстродействия, безусловно, нужен. По крайней мере, это прибыльный бизнес, и всегда найдется красивый способ подвигнуть пользователей на очередной апгрейд вчерашнего «суперпроизводительного CPU» на завтрашний «еще более супер…». Например, синхронное распознавание речи и синхронный же перевод на другой язык — это ли не мечта всех и каждого? Или необычайно реалистичные игры почти «киношного» качества (целиком поглощающие внимание и порой приводящие к серьезным изменениям в психике) — это ли не стремление множества геймеров от мала до велика?
Но давайте в данном случае вынесем за скобки маркетинговые аспекты, сосредоточившись на технических. Тем более что не все так уж мрачно: есть насущные задачи (серверные приложения, научные расчеты, моделирование и пр.), где все более высокая производительность, в частности центральных процессоров, действительно необходима.
Итак, какими же способами добиться увеличения их быстродействия?
Повышение тактовой частоты. Можно и дальше «утоньшать» технологический процесс и наращивать частоту. Но, как известно, это непросто и чревато всевозможными побочными эффектами вроде проблем с тепловыделением.
Наращивание ресурсов процессора — например, наращивание объема кэша, добавление новых блоков (Execution Units). Все это влечет за собой рост числа транзисторов, усложнение процессора, увеличение площади кристалла, а следовательно, стоимости.
Кроме того, предыдущие два способа дают, как правило, отнюдь не линейное повышение производительности. Это хорошо известно на примере Pentium 4: ошибки в предсказании ветвлений и прерывания вызывают сброс длинного конвейера, что сильно сказывается на общем быстродействии.
Многопроцессорность. Установка нескольких CPU и распределение работы между ними часто оказываются достаточно эффективными. Но такой подход не очень дешев — каждый дополнительный процессор увеличивает стоимость системы, да и дуальная материнская плата намного дороже обычной (не говоря уже о платах с поддержкой четырех и более CPU). Кроме того, далеко не все приложения получают от многопроцессорности выигрыш в производительности, достаточный для оправдания затрат.
Кроме «чистой» многопроцессорности, существует несколько «промежуточных» вариантов, позволяющих ускорить выполнение приложений:
Chip Multiprocessing (CMP) — два процессорных ядра физически располагаются на одном кристалле, используя общий или раздельный кэш. Естественно, размер кристалла получается достаточно большим, и на стоимости это не может не сказаться. Заметим, что несколько таких «сдвоенных» CPU также могут работать в многопроцессорной системе.
Time-Slice Multithreading. Процессор переключается между программными потоками через фиксированные промежутки времени. Накладные расходы порой получаются довольно внушительными, особенно если какой-либо процесс находится в ожидании.
Switch-on-Event Multithreading. Переключение задач при возникновении длительных пауз, например «непопаданий в кэш» (cache misses), большое число которых характерно для серверных приложений. В этом случае процесс, ожидающий загрузки данных из сравнительно медленной памяти в кэш, приостанавливается, высвобождая ресурсы CPU для других процессов. Однако Switch-on-Event Multithreading, как и Time-Slice Multithreading, не всегда позволяет достичь оптимального использования ресурсов процессора, — в частности из-за ошибок в предсказании ветвлений, зависимости инструкций и т. д.
Simultaneous Multithreading. В этом случае программные потоки выполняются на одном процессоре «одновременно», т. е. без переключения между ними. Ресурсы CPU распределяются динамически, по принципу «не используешь — отдай другому». Именно такой подход положен в основу технологии Intel Hyper-Threading, к рассмотрению которой мы и переходим.
Как работает Hyper-Threading
Как известно, нынешняя «парадигма компьютинга» предполагает многопоточные вычисления. Это касается не только серверов, где такое понятие существует изначально, но и рабочих станций и настольных систем. Потоки (threads) могут относиться как к одному, так и к разным приложениям, но почти всегда активных потоков больше, чем один (чтобы убедиться в этом, достаточно в Windows 2000/XP открыть Task Manager и включить отображение числа потоков). Вместе с тем обычный процессор может в один момент времени выполнять только один из потоков и вынужден постоянно переключаться между ними.
Впервые технология Hyper-Threading была реализована в процессоре Intel Xeon MP (Foster MP), на котором и шла ее «обкатка». Напомним, что Xeon MP, официально представленный на IDF Spring 2002, использует родственное Pentium 4 Willamette ядро, содержит 256 KB L2-кэша и 512 KB/1 MB L3-кэша и поддерживает работу в 4-процессорных конфигурациях. Также поддержка Hyper-Threading наличествует в процессоре для рабочих станций — Intel Xeon (ядро Prestonia, 512 KB L2-кэша), вышедшем на рынок несколько раньше, чем Xeon MP. С двухпроцессорными конфигурациями на Intel Xeon наши читатели уже знакомы, поэтому мы рассмотрим возможности Hyper-Threading именно на примере этих CPU — как теоретически, так и практически. Как бы там ни было, а «простой» Xeon — вещь более приземленная и удобоваримая, чем Xeon MP в 4-процессорных системах…
Принцип действия Hyper-Threading основывается на том, что в каждый момент времени только часть ресурсов процессора используется при выполнении программного кода. Неиспользуемые ресурсы также можно загрузить работой — например, задействовать для параллельного выполнения еще одного приложения (либо другого потока этого же приложения). В одном физическом процессоре Intel Xeon формируются два логических процессора (LP — Logical Processor), которые разделяют между собой вычислительные ресурсы CPU. Операционная система и приложения «видят» именно два CPU и могут распределять работу между ними, как и в случае полноценной двухпроцессорной системы.

Одна из целей реализации Hyper-Threading — при наличии только одного активного потока позволить ему выполняться с тем же быстродействием, как и на обычном CPU. Для этого у процессора предусмотрены два основных режима работы: Single-Task (ST) и Multi-Task (MT). В режиме ST активным является только один логический процессор, который безраздельно пользуется доступными ресурсами (режимы ST0 и ST1); другой LP остановлен командой HALT. При появлении второго программного потока бездействовавший логический процессор активируется (посредством прерывания), и физический CPU переводится в режим MT. Останов неиспользуемых LP командой HALT возложен на операционную систему, которая в итоге и отвечает за такое же быстрое выполнение одного потока, как и в случае без Hyper-Threading.

Для каждого из двух LP хранится так называемый Architecture State (AS), что включает в себя состояние регистров различного типа — общего назначения, управляющих, APIC и служебных. У каждого LP есть свои APIC (контроллер прерываний) и набор регистров, для корректной работы с которыми вводится понятие Register Alias Table (RAT), отслеживающей соответствие между восемью регистрами общего назначения IA-32 и 128 регистрами физического CPU (по одной RAT на каждый LP).

При работе двух потоков поддерживаются два соответствующих набора Next Instruction Pointers. Большая часть инструкций берется из Trace Cache (TC), где они хранятся в декодированном виде, и доступ к TC два активных LP получают поочередно, через такт. В то же время, когда активен только один LP, он получает монопольный доступ к TC без чередования по тактам. Аналогичным же образом происходит и доступ к Microcode ROM. Блоки ITLB (Instruction Translation Look-aside Buffer), задействующиеся при отсутствии необходимых инструкций в кэше команд, дублируются и доставляют команды каждый для своего потока. Блок декодирования инструкций IA-32 Instruction Decode является разделяемым и в случае, когда требуется декодирование инструкций для обоих потоков, обслуживает их поочередно (опять-таки через такт). Блоки Uop Queue и Allocator разделяются надвое, отводя по половине элементов для каждого LP. Schedulers числом 5 штук обрабатывают очереди декодированных команд (Uops) несмотря на принадлежность к LP0/LP1 и направляют команды на выполнение нужным Execution Units — в зависимости от готовности к выполнению первых и доступности вторых. Кэши всех уровней (L1/L2 для Xeon, а также L3 для Xeon MP) являются полностью разделяемыми между двумя LP, однако для обеспечения целостности данных записи в DTLB (Data Translation Look-aside Buffer) снабжаются дескрипторами в виде ID логических процессоров.
При этом большинство приложений, получающих ускорение в многопроцессорных системах, могут также ускоряться и на CPU со включенным Hyper-Threading без каких-либо модификаций. Но существуют и проблемы: например, если один процесс находится в цикле ожидания, он может занять все ресурсы физического CPU, препятствуя работе второго LP. Таким образом, производительность при использовании Hyper-Threading может иногда и падать (до 20%). Для предотвращения этого Intel рекомендует вместо пустых циклов ожидания использовать инструкцию PAUSE (появилась в IA-32 начиная с Pentium 4). Также ведется достаточно серьезная работа по автоматической и полуавтоматической оптимизации кода при компиляции — например, в этом отношении ощутимо продвинулись компиляторы серии Intel OpenMP C++/Fortran Compilers (подробнее).
Еще одной целью первой реализации Hyper-Threading, по словам Intel, было сведение к минимуму роста числа транзисторов, площади кристалла и энергопотребления при заметном приросте быстродействия. Первая часть этого обязательства уже выполнена: добавление в Xeon/Xeon MP поддержки Hyper-Threading увеличило площадь кристалла и энергопотребление менее чем на 5%. Что же получилось со второй частью (производительностью), нам еще предстоит проверить.
Практическая часть
По вполне понятным причинам мы не проводили тестов 4-процессорных серверных систем на Xeon MP со включенным Hyper-Threading. Во-первых, это достаточно трудоемко. А во-вторых, решись мы на такой подвиг — все равно сейчас, менее чем через месяц после официального объявления, абсолютно нереально заполучить это дорогостоящее оборудование. Поэтому решено было ограничиться той же системой с двумя Intel Xeon 2.2 GHz, на которой проводилось первое тестирование этих процессоров (см. ссылку в начале статьи). Система основывалась на материнской плате Supermicro P4DC6+ (чипсет Intel i860), содержала 512 MB RDRAM-памяти, видеокарту на чипе GeForce3 (64 MB DDR, драйверы Detonator 21.85), жесткий диск Western Digital WD300BB и 6X DVD-ROM; в качестве ОС использовалась Windows 2000 Professional SP2.
Для начала несколько общих впечатлений. При установке одного Xeon с ядром Prestonia на старте системы BIOS выводит сообщение о наличии двух CPU; если же установлены два процессора, пользователь видит сообщение о четырех CPU. Операционная система нормально распознает «оба процессора», но только если выполнены два условия.
Во-первых, в CMOS Setup у последних версий BIOS плат Supermicro P4DCxx появился пункт Enable Hyper-Threading, без разрешения которого ОС распознает только физический процессор(-ы). Во-вторых, для сообщения ОС о наличии дополнительных логических процессоров используются возможности ACPI. Поэтому для задействования Hyper-Threading в CMOS Setup должна быть включена опция ACPI, и для самой ОС также должен быть установлен HAL (Hardware Abstraction Layer) с поддержкой ACPI. Благо, в Windows 2000 смена HAL со Standard PC (или MPS Uni-/Multiprocessor PC) на ACPI Uni-/Multiprocessor PC производится легко — заменой «драйвера компьютера» в менеджере устройств. В то же время для Windows XP единственным законным способом перехода на ACPI HAL является переустановка системы поверх существующей инсталляции.
Для оценки производительности мы взяли уже знакомый читателям набор приложений, использовавшийся в тестированиях workstation-систем. Начнем, пожалуй, с конца и проверим «равноправность» логических CPU. Все предельно просто: сначала мы проводим тесты на одном процессоре с отключенным Hyper-Threading, а затем повторяем процесс, включив Hyper-Threading и используя только один из двух логических CPU (с помощью Task Manager). Поскольку в данном случае нас интересуют лишь относительные значения, результаты всех тестов приведены к виду «больше — лучше» и нормализованы (за единицу взяты показатели однопроцессорной системы без Hyper-Threading).
Что ж, как можно видеть, обещания Intel здесь выполнены: при наличии только одного активного потока производительность каждого из двух LP в точности равна быстродействию физического CPU без Hyper-Threading. Бездействующий LP (причем как LP0, так и LP1) действительно приостанавливается, а разделяемые ресурсы, насколько об этом можно судить по полученным результатам, полностью передаются в пользование активному LP.

Поэтому делаем первый вывод: два логических процессора на самом деле являются равноправными, а включение Hyper-Threading «не мешает» работе одного потока (что само по себе уже неплохо). Посмотрим теперь, «помогает» ли это включение, и если да, то где и как?
Рендеринг. Результаты четырех тестов в пакетах 3D-моделирования 3D Studio MAX 4.26, Lightwave 7b и A|W Maya 4.0.1 объединены в одну диаграмму ввиду их похожести.

Во всех четырех случаях (для Lightwave — две различные сцены) загрузка CPU при наличии одного процессора с выключенным Hyper-Threading практически постоянно держится на уровне 100%. Тем не менее при включении Hyper-Threading расчет сцен ускоряется (в результате чего у нас даже родилась шутка о загрузке CPU более 100%). В трех тестах виден прирост производительности от Hyper-Threading 14—18% — с одной стороны, негусто по сравнению со вторым CPU, но с другой — весьма неплохо, учитывая «бесплатность» этого эффекта. В одном из двух тестов с Lightwave прирост быстродействия практически нулевой (видимо, сказывается специфика этого полного странностей приложения). Но отрицательного результата нет нигде, а заметный прирост в трех других случаях обнадеживает. И это при том, что параллельные процессы рендеринга делают сходную работу и наверняка не лучшим образом могут одновременно задействовать ресурсы физического CPU.
Photoshop и MP3-кодирование. Кодек GOGO-no-coda 2.39c один из немногих поддерживает SMP, и на нем заметен 34%-ный прирост быстродействия от двухпроцессорности. Вместе с тем эффект от Hyper-Threading в данном случае нулевой (разницу в 3% мы существенной не считаем). А вот в тесте с Photoshop 6.0.1 (скрипт, состоящий из большого набора команд и фильтров) видно замедление при включении Hyper-Threading, хотя второй физический CPU добавляет в этом случае 12% производительности. Вот, собственно, первый случай, когда Hyper-Threading вызывает падение быстродействия…
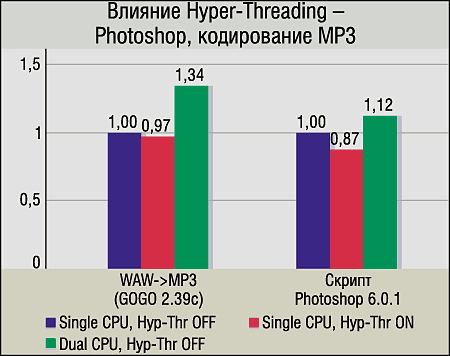
Профессиональный OpenGL. То, что SPEC ViewPerf и многие другие OpenGL-приложения часто замедляются в SMP-системах, известно давно.
OpenGL и двухпроцессорность: почему они не дружат
Много раз в статьях мы обращали внимание читателей на то, что двухпроцессорные платформы при выполнении профессиональных OpenGL-тестов очень редко показывают хоть сколько-нибудь существенное преимущество по сравнению с однопроцессорными. И мало того, нередки случаи, когда установка второго процессора наоборот, ухудшает быстродействие системы при отрисовке динамичных трехмерных сцен.
Естественно, замечали эту странность не только мы. Некоторые тестеры просто молча обходили этот факт — например, приводя результаты сравнения по тестам SPEC ViewPerf только для двухпроцессорных конфигураций, избегая таким образом объяснений «почему двухпроцессорная система медленнее?». Другие же строили все возможные фантастические предположения о когерентности кэшей, необходимости ее поддерживать, возникающих из-за этого накладных расходах и т.п. И почему-то никого не удивляло, что, например, следить за когерентностью процессорам почему-то приспичило именно при оконном OpenGL-рендеринге (по своей «вычислительной» сути мало чем отличающемся от любой другой расчетной задачи).
Теперь же упрощенно рассмотрим как выглядит OpenGL-рендеринг, выполняемый двумя потоками. Если приложение, «видя» два процессора, создает два потока OpenGL-рендеринга, то для каждого из них, согласно правилам OpenGL, создается свой gl-контекст. Соответственно каждый поток выполняет рендеринг в свой gl-контекст. Но проблема в том, что для окна, в которое происходит вывод изображения, только один gl-контекст может быть текущим в каждый момент. Соответственно потоки в этом случае просто «по очереди» выводят сгенерированное изображение в окно, делая попеременно свой контекст текущим. Нужно ли говорить, что такое «чередование контекстов» может очень дорого обходиться в смысле накладных расходов?
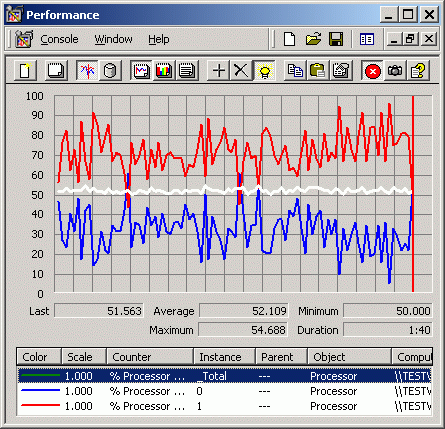
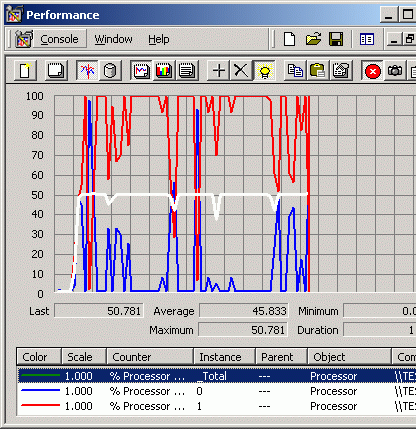
Синим и красным изображены графики загруженности CPU 0 и CPU 1 соответственно. Линия посередине — итоговый график CPU Usage. Три графика соответствуют двум сценам из 3D Studio MAX 4.26 и части теста SPEC ViewPerf (AWadvs-04).

CPU Usage: анимация 3D Studio MAX 4.26 — Anibal (with manipulators).max
CPU Usage: анимация 3D Studio MAX 4.26 — Rabbit.max
CPU Usage: SPEC ViewPerf 6.1.2 — AWadvs-04
Такая же картина повторяется еще в массе других приложений, задействующих OpenGL. Два процессора совершенно не утруждаются работой, и общий CPU Usage оказывается на уровне 50-60%. В то же время для однопроцессорной системы во всех этих случаях CPU Usage уверенно держится на уровне 100%.
Поэтому неудивительно то, что очень многие OpenGL-приложения не слишком ускоряются в дуальных системах. Ну а то, что они порой даже замедляются, имеет, на наш взгляд, вполне логичное объяснение.
Мы можем констатировать, что при двух логических CPU падение быстродействия еще более значительно, что вполне объяснимо: два логических процессора мешают друг другу точно так же, как и два физических. Но их общая производительность, естественно, оказывается при этом ниже, поэтому при включении Hyper-Threading она снижается еще больше, чем просто при работе двух физических CPU. Результат предсказуемый и вывод простой: Hyper-Threading, как и «настоящий» SMP, для OpenGL бывает противопоказан.
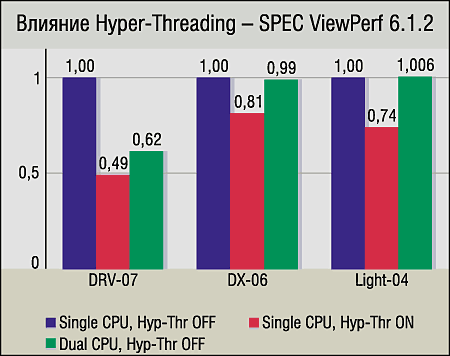
CAD-приложения. Предыдущий вывод подтверждается и результатами двух CAD-тестов — SPECapc for SolidEdge V10 и SPECapc for SolidWorks. Показатели графических составляющих этих тестов для Hyper-Threading похожи (хотя в случае SMP-системы для SolidEdge V10 результат немного выше). А вот результаты нагружающих процессор тестов CPU_Score заставляют задуматься: 5—10%-ный прирост от SMP и 14—19%-ное замедление от Hyper-Threading.
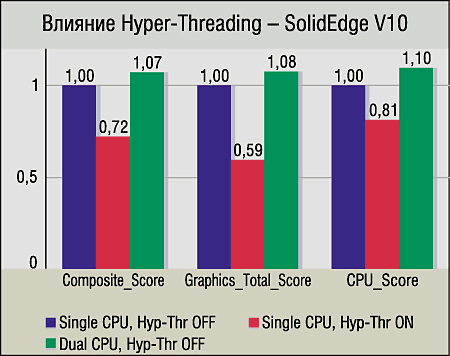
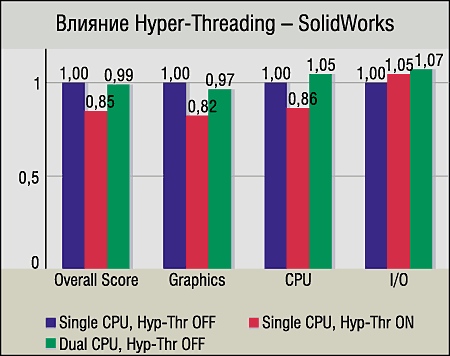
Но в конце концов, Intel честно признает в некоторых случаях возможность падения производительности при Hyper-Threading — например, при использовании пустых циклов ожидания. Мы можем лишь предположить, что это и является причиной (детальное исследование кода SolidEdge и SolidWorks выходит за рамки статьи). Ведь всем известен консерватизм разработчиков CAD-приложений, предпочитающих проверенную надежность и не особо спешащих переписывать код с учетом новых веяний в программировании.
Подведение итогов, или «Внимание, правильный вопрос»
Hyper-Threading работает, в этом никаких сомнений не остается. Безусловно, технология не универсальна: есть приложения, которым «плохеет» от Hyper-Threading, и в случае распространения этой технологии их желательно будет модифицировать. Но разве не то же самое произошло в свое время с MMX и SSE и продолжает происходить с SSE2.
Однако здесь встает вопрос о применимости этой технологии к нашим реалиям. Вариант однопроцессорной системы на Xeon с Hyper-Threading мы отбросим сразу (или допустим только как временный, в ожидании покупки второго процессора): даже 30%-ный прирост производительности никак не оправдывает цену — тогда уж лучше приобрести обычный Pentium 4. Остается число CPU от двух и выше.
А теперь давайте вообразим, что мы покупаем двухпроцессорную систему на Xeon (скажем, с Windows 2000/XP Professional). Два CPU установлены, Hyper-Threading включен, BIOS находит целых четыре логических процессора, сейчас ух как взлетим… Стоп. А вот сколько процессоров увидит наша операционная система? Правильно, два. Всего два, поскольку на большее число она просто не рассчитана. Это будут два физических процессора, т. е. работать все будет точно так же, как и при отключенном Hyper-Threading, — не медленнее (два «дополнительных» логических CPU просто остановятся), но и не быстрее (проверено дополнительными тестами, результаты не приводим по причине их полной очевидности). М-да, приятного мало…
Ну а с серверами все выходит достаточно просто. Например, Windows 2000 Advanced Server, установленный на двухпроцессорную Xeon-систему со включенным Hyper-Threading, «увидит» четыре логических процессора и будет преспокойно на ней работать. Для оценки того, что дает Hyper-Threading в серверных системах, мы приводим результаты Intel Microprocessor Software Labs для двухпроцессорных систем на Xeon MP и нескольких серверных приложений Microsoft.
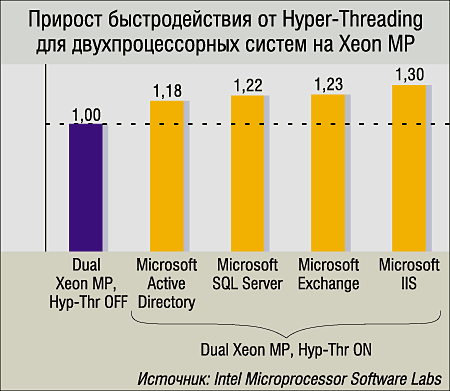
Прибавка производительности 20—30% для двухпроцессорного сервера «задаром» — вещь более чем заманчивая (особенно по сравнению с покупкой «настоящей» 4-процессорной системы).
Вот и выходит, что на текущий момент практическая применимость Hyper-Threading возможна только в серверах. Вопрос же с рабочими станциями зависит от решения с лицензированием ОС. Хотя и еще одно применение Hyper-Threading вполне реально — если и настольные процессоры получат поддержку этой технологии. К примеру (пофантазируем), чем плоха система с Pentium 4 с поддержкой Hyper-Threading, на которую установлена Windows 2000/XP Professional с поддержкой SMP. Впрочем, ничего невероятного в этом нет: полные энтузиазма разработчики Intel обещают повсеместное внедрение Hyper-Threading — от серверов до настольных и мобильных систем.
Процессоры, ядра и потоки. Топология систем
В этой статье я попытаюсь описать терминологию, используемую для описания систем, способных исполнять несколько программ параллельно, то есть многоядерных, многопроцессорных, многопоточных. Разные виды параллелизма в ЦПУ IA-32 появлялись в разное время и в несколько непоследовательном порядке. Во всём этом довольно легко запутаться, особенно учитывая, что операционные системы заботливо прячут детали от не слишком искушённых прикладных программ.

Используемая далее терминология используется в документации процессорам Intel. Другие архитектуры могут иметь другие названия для похожих понятий. Там, где они мне известны, я буду их упоминать.
Цель статьи — показать, что при всём многообразии возможных конфигураций многопроцессорных, многоядерных и многопоточных систем для программ, исполняющихся на них, создаются возможности как для абстракции (игнорирования различий), так и для учёта специфики (возможность программно узнать конфигурацию).
Процессор
Конечно же, самый древний, чаще всего используемый и неоднозначный термин — это «процессор».
В современном мире процессор — это то (package), что мы покупаем в красивой Retail коробке или не очень красивом OEM-пакетике. Неделимая сущность, вставляемая в разъём (socket) на материнской плате. Даже если никакого разъёма нет и снять его нельзя, то есть если он намертво припаян, это один чип.

Мобильные системы (телефоны, планшеты, ноутбуки) и большинство десктопов имеют один процессор. Рабочие станции и сервера иногда могут похвастаться двумя или больше процессорами на одной материнской плате.
Поддержка нескольких центральных процессоров в одной системе требует многочисленных изменений в её дизайне. Как минимум, необходимо обеспечить их физическое подключение (предусмотреть несколько сокетов на материнской плате), решить вопросы идентификации процессоров (см. далее в этой статье, а также мою предыдущую заметку), согласования доступов к памяти и доставки прерываний (контроллер прерываний должен уметь маршрутизировать прерывания на несколько процессоров) и, конечно же, поддержки со стороны операционной системы. Я, к сожалению, не смог найти документального упоминания момента создания первой многопроцессорной системы на процессорах Intel, однако Википедия утверждает, что Sequent Computer Systems поставляла их уже в 1987 году, используя процессоры Intel 80386. Широко распространённой поддержка же нескольких чипов в одной системе становится доступной, начиная с Intel® Pentium.
Если процессоров несколько, то каждый из них имеет собственный разъём на плате. У каждого из них при этом имеются полные независимые копии всех ресурсов, таких как регистры, исполняющие устройства, кэши. Делят они общую память — RAM. Память может подключаться к ним различными и довольно нетривиальными способами, но это отдельная история, выходящая за рамки этой статьи. Важно то, что при любом раскладе для исполняемых программ должна создаваться иллюзия однородной общей памяти, доступной со всех входящих в систему процессоров.

К взлёту готов! Intel® Desktop Board D5400XS
Исторически многоядерность в Intel IA-32 появилась позже Intel® HyperThreading, однако в логической иерархии она идёт следующей.
Казалось бы, если в системе больше процессоров, то выше её производительность (на задачах, способных задействовать все ресурсы). Однако, если стоимость коммуникаций между ними слишком велика, то весь выигрыш от параллелизма убивается длительными задержками на передачу общих данных. Именно это наблюдается в многопроцессорных системах — как физически, так и логически они находятся очень далеко друг от друга. Для эффективной коммуникации в таких условиях приходится придумывать специализированные шины, такие как Intel® QuickPath Interconnect. Энергопотребление, размеры и цена конечного решения, конечно, от всего этого не понижаются. На помощь должна прийти высокая интеграция компонент — схемы, исполняющие части параллельной программы, надо подтащить поближе друг к другу, желательно на один кристалл. Другими словами, в одном процессоре следует организовать несколько ядер, во всём идентичных друг другу, но работающих независимо.
Первые многоядерные процессоры IA-32 от Intel были представлены в 2005 году. С тех пор среднее число ядер в серверных, десктопных, а ныне и мобильных платформах неуклонно растёт.
В отличие от двух одноядерных процессоров в одной системе, разделяющих только память, два ядра могут иметь также общие кэши и другие ресурсы, отвечающие за взаимодействие с памятью. Чаще всего кэши первого уровня остаются приватными (у каждого ядра свой), тогда как второй и третий уровень может быть как общим, так и раздельным. Такая организация системы позволяет сократить задержки доставки данных между соседними ядрами, особенно если они работают над общей задачей.
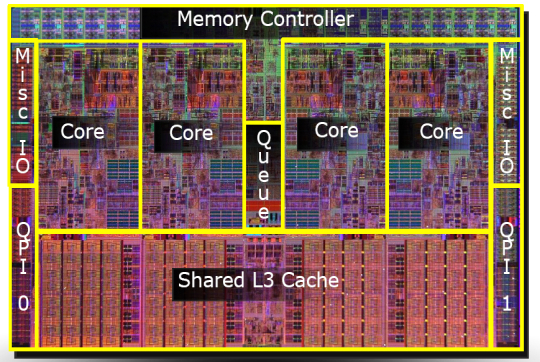
Микроснимок четырёхядерного процессора Intel с кодовым именем Nehalem. Выделены отдельные ядра, общий кэш третьего уровня, а также линки QPI к другим процессорам и общий контроллер памяти.
Гиперпоток
До примерно 2002 года единственный способ получить систему IA-32, способную параллельно исполнять две или более программы, состоял в использовании именно многопроцессорных систем. В Intel® Pentium® 4, а также линейке Xeon с кодовым именем Foster (Netburst) была представлена новая технология — гипертреды или гиперпотоки, — Intel® HyperThreading (далее HT).
Ничто не ново под луной. HT — это частный случай того, что в литературе именуется одновременной многопоточностью (simultaneous multithreading, SMT). В отличие от «настоящих» ядер, являющихся полными и независимыми копиями, в случае HT в одном процессоре дублируется лишь часть внутренних узлов, в первую очередь отвечающих за хранение архитектурного состояния — регистры. Исполнительные же узлы, ответственные за организацию и обработку данных, остаются в единственном числе, и в любой момент времени используются максимум одним из потоков. Как и ядра, гиперпотоки делят между собой кэши, однако начиная с какого уровня — это зависит от конкретной системы.
Я не буду пытаться объяснить все плюсы и минусы дизайнов с SMT вообще и с HT в частности. Интересующийся читатель может найти довольно подробное обсуждение технологии во многих источниках, и, конечно же, в Википедии. Однако отмечу следующий важный момент, объясняющий текущие ограничения на число гиперпотоков в реальной продукции.
Ограничения потоков
В каких случаях наличие «нечестной» многоядерности в виде HT оправдано? Если один поток приложения не в состоянии загрузить все исполняющие узлы внутри ядра, то их можно «одолжить» другому потоку. Это типично для приложений, имеющих «узкое место» не в вычислениях, а при доступе к данным, то есть часто генерирующих промахи кэша и вынужденных ожидать доставку данных из памяти. В это время ядро без HT будет вынуждено простаивать. Наличие же HT позволяет быстро переключить свободные исполняющие узлы к другому архитектурному состоянию (т.к. оно как раз дублируется) и исполнять его инструкции. Это — частный случай приёма под названием latency hiding, когда одна длительная операция, в течение которой полезные ресурсы простаивают, маскируется параллельным выполнением других задач. Если приложение уже имеет высокую степень утилизации ресурсов ядра, наличие гиперпотоков не позволит получить ускорение — здесь нужны «честные» ядра.
Типичные сценарии работы десктопных и серверных приложений, рассчитанных на машинные архитектуры общего назначения, имеют потенциал к параллелизму, реализуемому с помощью HT. Однако этот потенциал быстро «расходуется». Возможно, по этой причине почти на всех процессорах IA-32 число аппаратных гиперпотоков не превышает двух. На типичных сценариях выигрыш от использования трёх и более гиперпотоков был бы невелик, а вот проигрыш в размере кристалла, его энергопотреблении и стоимости значителен.
Другая ситуация наблюдается на типичных задачах, выполняемых на видеоускорителях. Поэтому для этих архитектур характерно использование техники SMT с бóльшим числом потоков. Так как сопроцессоры Intel® Xeon Phi (представленные в 2010 году) идеологически и генеалогически довольно близки к видеокартам, на них может быть четыре гиперпотока на каждом ядре — уникальная для IA-32 конфигурация.
Логический процессор
Из трёх описанных «уровней» параллелизма (процессоры, ядра, гиперпотоки) в конкретной системе могут отсутствовать некоторые или даже все. На это влияют настройки BIOS (многоядерность и многопоточность отключаются независимо), особенности микроархитектуры (например, HT отсутствовал в Intel® Core™ Duo, но был возвращён с выпуском Nehalem) и события при работе системы (многопроцессорные сервера могут выключать отказавшие процессоры в случае обнаружения неисправностей и продолжать «лететь» на оставшихся). Каким образом этот многоуровневый зоопарк параллелизма виден операционной системе и, в конечном счёте, прикладным приложениям?
Далее для удобства обозначим количества процессоров, ядер и потоков в некоторой системе тройкой (x, y, z), где x — это число процессоров, y — число ядер в каждом процессоре, а z — число гиперпотоков в каждом ядре. Далее я буду называть эту тройку топологией — устоявшийся термин, мало что имеющий с разделом математики. Произведение p = xyz определяет число сущностей, именуемых логическими процессорами системы. Оно определяет полное число независимых контекстов прикладных процессов в системе с общей памятью, исполняющихся параллельно, которые операционная система вынуждена учитывать. Я говорю «вынуждена», потому что она не может управлять порядком исполнения двух процессов, находящихся на различных логических процессорах. Это относится в том числе к гиперпотокам: хотя они и работают «последовательно» на одном ядре, конкретный порядок диктуется аппаратурой и недоступен для наблюдения или управления программам.
Чаще всего операционная система прячет от конечных приложений особенности физической топологии системы, на которой она запущена. Например, три следующие топологии: (2, 1, 1), (1, 2, 1) и (1, 1, 2) — ОС будет представлять в виде двух логических процессоров, хотя первая из них имеет два процессора, вторая — два ядра, а третья — всего лишь два потока.
Windows Task Manager показывает 8 логических процессоров; но сколько это в процессорах, ядрах и гиперпотоках?
Linux top показывает 4 логических процессора.
Это довольно удобно для создателей прикладных приложений — им не приходится иметь дело с зачастую несущественными для них особенностями аппаратуры.
Программное определение топологии
Конечно, абстрагирование топологии в единственное число логических процессоров в ряде случаев создаёт достаточно оснований для путаницы и недоразумений (в жарких Интернет-спорах). Вычислительные приложения, желающие выжать из железа максимум производительности, требуют детального контроля над тем, где будут размещены их потоки: поближе друг к другу на соседних гиперпотоках или же наоборот, подальше на разных процессорах. Скорость коммуникаций между логическими процессорами в составе одного ядра или процессора значительно выше, чем скорость передачи данных между процессорами. Возможность неоднородности в организации оперативной памяти также усложняет картину.
Информация о топологии системы в целом, а также положении каждого логического процессора в IA-32 доступна с помощью инструкции CPUID. С момента появления первых многопроцессорных систем схема идентификации логических процессоров несколько раз расширялась. К настоящему моменту её части содержатся в листах 1, 4 и 11 CPUID. Какой из листов следует смотреть, можно определить из следующей блок-схемы, взятой из статьи [2]:
Я не буду здесь утомлять всеми подробностями отдельных частей этого алгоритма. Если возникнет интерес, то этому можно посвятить следующую часть этой статьи. Отошлю интересующегося читателя к [2], в которой этот вопрос разбирается максимально подробно. Здесь же я сначала кратко опишу, что такое APIC и как он связан с топологией. Затем рассмотрим работу с листом 0xB (одиннадцать в десятичном счислении), который на настоящий момент является последним словом в «апикостроении».
APIC ID
В настоящий момент ширина числа, хранящегося в APIC ID, достигла полных 32 бит, хотя в прошлом оно было ограничено 16, а ещё раньше — только 8 битами. Нынче остатки старых дней раскиданы по всему CPUID, однако в CPUID.0xB.EDX[31:0] возвращаются все 32 бита APIC ID. На каждом логическом процессоре, независимо исполняющем инструкцию CPUID, возвращаться будет своё значение.
Выяснение родственных связей
Значение APIC ID само по себе ничего не говорит о топологии. Чтобы узнать, какие два логических процессора находятся внутри одного физического (т.е. являются «братьями» гипертредами), какие два — внутри одного процессора, а какие оказались и вовсе в разных процессорах, надо сравнить их значения APIC ID. В зависимости от степени родства некоторые их биты будут совпадать. Эта информация содержится в подлистьях CPUID.0xB, которые кодируются с помощью операнда в ECX. Каждый из них описывает положение битового поля одного из уровней топологии в EAX[5:0] (точнее, число бит, которые нужно сдвинуть в APIC ID вправо, чтобы убрать нижние уровни топологии), а также тип этого уровня — гиперпоток, ядро или процессор, — в ECX[15:8].
У логических процессоров, находящихся внутри одного ядра, будут совпадать все биты APIC ID, кроме принадлежащих полю SMT. Для логических процессоров, находящихся в одном процессоре, — все биты, кроме полей Core и SMT. Поскольку число подлистов у CPUID.0xB может расти, данная схема позволит поддержать описание топологий и с бóльшим числом уровней, если в будущем возникнет необходимость. Более того, можно будет ввести промежуточные уровни между уже существующими.
Важное следствие из организации данной схемы заключается в том, что в наборе всех APIC ID всех логических процессоров системы могут быть «дыры», т.е. они не будут идти последовательно. Например, во многоядерном процессоре с выключенным HT все APIC ID могут оказаться чётными, так как младший бит, отвечающий за кодирование номера гиперпотока, будет всегда нулевым.
Отмечу, что CPUID.0xB — не единственный источник информации о логических процессорах, доступный операционной системе. Список всех процессоров, доступный ей, вместе с их значениями APIC ID, кодируется в таблице MADT ACPI [3, 4].
Операционные системы и топология
Операционные системы предоставляют информацию о топологии логических процессоров приложениям с помощью своих собственных интерфейсов.
В FreeBSD топология сообщается через механизм sysctl в переменной kern.sched.topology_spec в виде XML:
В MS Windows 8 сведения о топологии можно увидеть в диспетчере задач Task Manager.
Также их предоставляет консольная утилита Sysinternals Coreinfo и API вызов GetLogicalProcessorInformation.
Полная картина
Проиллюстрирую ещё раз отношения между понятиями «процессор», «ядро», «гиперпоток» и «логический процессор» на нескольких примерах.
Система (2, 2, 2)
Система (2, 4, 1)
Система (4, 1, 1)
Прочие вопросы
В этот раздел я вынес некоторые курьёзы, возникающие из-за многоуровневой организации логических процессоров.
Как я уже упоминал, кэши в процессоре тоже образуют иерархию, и она довольно сильно связано с топологией ядер, однако не определяется ей однозначно. Для определения того, какие кэши для каких логических процессоров общие, а какие нет, используется вывод CPUID.4 и её подлистов.
Лицензирование
Некоторые программные продукты поставляются числом лицензий, определяемых количеством процессоров в системе, на которой они будут использоваться. Другие — числом ядер в системе. Наконец, для определения числа лицензий число процессоров может умножаться на дробный «core factor», зависящий от типа процессора!
Виртуализация
Системы виртуализации, способные моделировать многоядерные системы, могут назначить виртуальным процессорам внутри машины произвольную топологию, не совпадающую с конфигурацией реальной аппаратуры. Так, внутри хозяйской системы (1, 2, 2) некоторые известные системы виртуализации по умолчанию выносят все логические процессоры на верхний уровень, т.е. создают конфигурацию (4, 1, 1). В сочетании с особенностями лицензирования, зависящими от топологии, это может порождать забавные эффекты.



