BGP: Управление LOCAL_PREFERENCE
Мы рассмотрели атрибут веса (wight) в прошлой статье, теперь рассмотрим LOCAL_PREFERENCE.
LP используется тогда, когда у нас есть два роутера, которые используются для выхода из нашей AS. И атрибут LP указывает на то, через какой роутер будет осуществляться выход. А weight из прошлой статьи указывать через какой интерфейс будет осщуствляться выход. Чем больше LP, тем приоритетнее.
Вот такая идеология.
Давайте сделаем топологию:
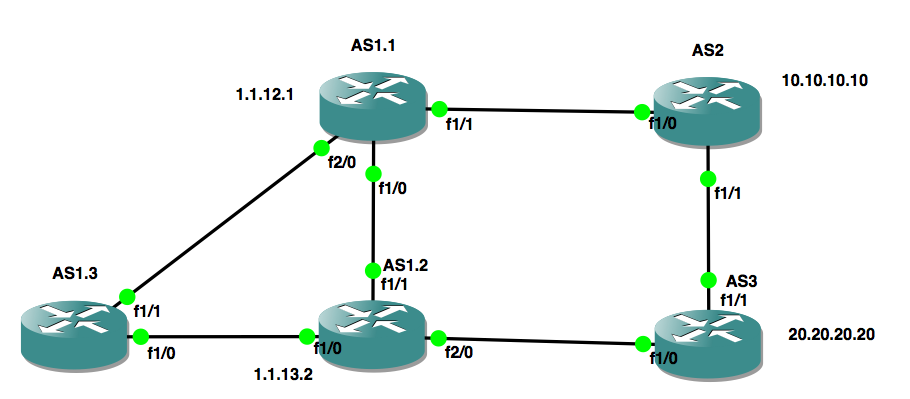
Нас будет интересовать AS1.3 и как мы с него достигаем сеток 10.10.10.10/32 и 20.20.20.20/32. Посмотрим что у нас по умолчанию:
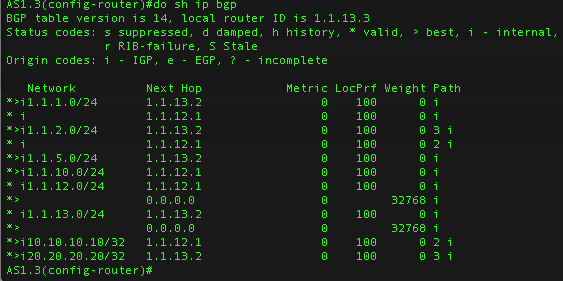
Здесь мы видим, что к сети 10-ок мы ходим через AS1.1, а в сеть 20-ок мы ходим через AS1.2, этот выбор на самом деле делается по кратчайшему AS-PATH, так как вес одинаковый, а так же одинаковый LocPrf.
А что если у нас линк, между AS1.2 и AS3 очень медленный, какой-нибудь 256кбит? Ведь BGP не смотрит на пропускную способность.
Тогда мы можем использовать атрибут Local Preference. На роутере AS1.1 поставил LocPrf = 200.
Делается это на AS1.1, на нейборе к AS2 через route-map на in, вот так:
AS1.1(config-route-map)#do sh run | s bgp
router bgp 1
no synchronization
bgp log-neighbor-changes
network 1.1.1.0 mask 255.255.255.0
network 1.1.10.0 mask 255.255.255.0
network 1.1.12.0 mask 255.255.255.0
neighbor 1.1.1.2 remote-as 1
neighbor 1.1.1.2 next-hop-self
neighbor 1.1.10.2 remote-as 2
neighbor 1.1.10.2 route-map LP in
neighbor 1.1.12.3 remote-as 1
neighbor 1.1.12.3 next-hop-self
no auto-summary
AS1.1(config-route-map)#
route-map LP permit 10
set local-preference 200
Теперь делаем пересылку апдейтов и получаем:
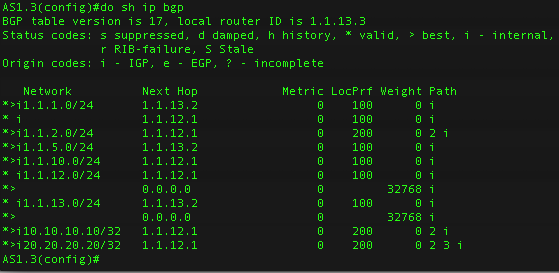
Мы видим, что теперь в сетки 10-ток и 20-ок мы ходим через AS1.1, так как LocPref у нас равен 200 и является более приоритетным.
Таким образом мы можем управлять исходищм трафиком, через какой роутер мы будем выходить из нашей AS. Если бы на роутере было бы еще два линка, то там с помощью weight возможно определить приоритетность того или иного выхода, как это делали в прошлой статье.
BGP local preference
Атрибут Local Preference используется для управления исходящим трафиком BGP.
Характеристики атрибута Local preference:
1. Указывает маршрутизаторам внутри автономной системы как выйти за её пределы.
2. Этот атрибут передается только в пределах одной автономной системы.
4. Точкой выхода из автономной системы будет тот маршрутизатор, у которого значение атрибута больше.
5. Если eBGP-сосед получает обновление с выставленным значением local preference, он игнорирует этот атрибут.
Разберем атрибут Local preference на примере следующей топологии:

1. AR1, AR2 и AR3 находятся в AS 50.
2. AR4находится в AS 500.
3. BGPобъявляет интерфейс loopback 1 маршрутизатора AR1 и loopback 0 маршрутизатора AR4.
В данном примере мы проверим работу параметра default l ocal preference, который будет определять оптимальный маршрут для трафика, покидающего AS50. В нашем случае, мы сделаем так, что весь трафик покидающий AS 50 будет идти через AR3. Если BGP устройство получает несколько маршрутов от разных соседей и эти маршруты ведут в одно и тоже место назначения, то BGP устройство выберет маршрут с наибольшим значением local preference.
Настройки устройств выглядят следующим образом:
interface LoopBack0
ip address 1.1.1.1 32
interface LoopBack1
ip address 10.10.10.10 32
bgp 50
undo synchronization
undo summary automatic
group iBGP internal
peer iBGP next-hop-local
peer 10.1.1.2 group iBGP
peer 10.1.2.2 group iBGP
network 10.10.10.10 255.255.255.255
interface GigabitEthernet 0/0/0
ip address 10.1.1.1 30
interface GigabitEthernet 0/0/1
ip address 10.1.2.1 30
bgp 50
undo synchronization
undo summary automatic
group iBGP internal
peer iBGP next-hop-local
peer 10.1.1.1 group iBGP
peer 10.1.3.2 group iBGP
peer 5.1.1.2 as-number 500
network 5.1.1.0 255.255.255.252
default local-preference 200
interface GigabitEthernet 0/0/0
ip address 10.1.1.2 30
interface GigabitEthernet 0/0/2
ip address 10.1.3.1 30
interface GigabitEthernet 0/0/3
ip address 5.1.1.1 30
bgp 50
undo synchronization
undo summary automatic
group iBGP internal
peer iBGP next-hop-local
peer 10.1.2.1 group iBGP
peer 10.1.3.1 group iBGP
peer 5.2.2.2 as-number 500
network 5.2.2.0 255.255.255.252
default local-preference 300
interface GigabitEthernet 0/0/1
ip address 10.1.2.2 30
interface GigabitEthernet 0/0/2
ip address 10.1.3.2 30
interface GigabitEthernet 0/0/3
ip address 5.2.2.1 30
bgp 500
undo synchronization
undo summary automatic
peer 5.1.1.1 as-number 50
peer 5.2.2.1 as-number 50
network 4.4.4.4 255.255.255.255
interface GigabitEthernet 0/0/0
ip address 5.1.1.2 30
interface GigabitEthernet 0/0/1
ip address 5.2.2.2 30
Проверим IP и BGP таблицы маршрутизации на маршрутизаторе AR1:
Destination/Mask Proto Pre Cost Flags NextHop Interface
1.1.1.1/32 Direct 0 0 D 127.0.0.1 LoopBack0
4.4.4.4/32 IBGP 255 0 RD 10.1.1.2 GigabitEthernet0/0/0
5.1.1.0/30 IBGP 255 0 RD 10.1.1.2 GigabitEthernet0/0/0
5.2.2.0/30 IBGP 255 0 RD 10.1.2.2 GigabitEthernet0/0/1
10.1.1.0/30 Direct 0 0 D 10.1.1.1 GigabitEthernet0/0/0
10.1.1.1/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/0
10.1.2.0/30 Direct 0 0 D 10.1.2.1 GigabitEthernet0/0/1
10.1.2.1/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/1
10.10.10.10/32 Direct 0 0 D 127.0.0.1 LoopBack1
127.0.0.0/8 Direct 0 0 D 127.0.0.1 InLoopBack0
127.0.0.1/32 Direct 0 0 D 127.0.0.1 InLoopBack0
[AR1] display bgp routing-table
Total Number of Routes: 5
Network NextHop MED LocPrf PrefVal Path/Ogn
*>i 4.4.4.4/32 10.1.1.2 0 100 0 500i
* i 10.1.2.2 0 100 0 500i
*>i 5.1.1.0/30 10.1.1.2 0 100 0 i
*>i 5.2.2.0/30 10.1.2.2 0 100 0 i
*> 10.10.10.10/32 0.0.0.0 0 0 i
Как видим, в IP таблице маршрутизации, loopback0 маршрутизатора AR4 доступен через 10.1.1.2 AR2. В BGP таблице маршрутизации, мы видим, что до сети 4.4.4.4/32 есть два выхода. Обратим внимание на столбец LocPrf. В нашем случае, оба выхода имеют одинаковые значения (100). Попробуем поменять их, тогда BGP сможет выбрать наилучший маршрут в зависимости от величины параметра local preference :
[AR2]bgp 50
default local-preference 200
[AR3]bgp 50
default local-preference 300
Теперь снова проверим IP и BGP таблицы маршрутизации на AR1:
Destination/Mask Proto Pre Cost Flags NextHop Interface
1.1.1.1/32 Direct 0 0 D 127.0.0.1 LoopBack0
4.4.4.4/32 IBGP 255 0 RD 10.1.2.2 GigabitEthernet0/0/1
5.1.1.0/30 IBGP 255 0 RD 10.1.1.2 GigabitEthernet0/0/0
5.2.2.0/30 IBGP 255 0 RD 10.1.2.2 GigabitEthernet0/0/1
10.1.1.0/30 Direct 0 0 D 10.1.1.1 GigabitEthernet0/0/0
10.1.1.1/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/0
10.1.2.0/30 Direct 0 0 D 10.1.2.1 GigabitEthernet0/0/1
10.1.2.1/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/1
10.10.10.10/32 Direct 0 0 D 127.0.0.1 LoopBack1
127.0.0.0/8 Direct 0 0 D 127.0.0.1 InLoopBack0
127.0.0.1/32 Direct 0 0 D 127.0.0.1 InLoopBack0
[AR1] display bgp routing-table
Total Number of Routes: 4
Network NextHop MED LocPrf PrefVal Path/Ogn
*>i 4.4.4.4/32 10.1.2.2 0 300 0 500i
*>i 5.1.1.0/30 10.1.1.2 0 200 0 i
*>i 5.2.2.0/30 10.1.2.2 0 300 0 i
*> 10.10.10.10/32 0.0.0.0 0 0 i
Запустим трассировку до AR 4 и посмотрим как пойдет трафик:
Вывод показывает, что весь трафик выходящий из AS 50 идет через маршрутизатор AR3.
Теперь посмотрим IP таблицу маршрутизации на маршрутизаторе AR4:
Destination/Mask Proto Pre Cost Flags NextHop Interface
4.4.4.4/32 Direct 0 0 D 127.0.0.1 LoopBack0
5.1.1.0/30 Direct 0 0 D 5.1.1.2 GigabitEthernet0/0/0
5.1.1.2/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/0
5.2.2.0/30 Direct 0 0 D 5.2.2.2 GigabitEthernet0/0/1
5.2.2.2/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/1
10.10.10.10/32 EBGP 255 0 D 5.1.1.1 GigabitEthernet0/0/0
127.0.0.0/8 Direct 0 0 D 127.0.0.1 InLoopBack0
127.0.0.1/32 Direct 0 0 D 127.0.0.1 InLoopBack0
Как видим, трафик из AS 500 идет через маршрутизатор AR2. Из этого можем сделать вывод, что параметр BGP local preference влияет только на исходящий из AS трафик.
У статьи есть другие ресурсы
Требуется войти для загрузки или просмотра. Нет аккаунта? Register
Локальное предпочтение для BGP маршрутов
О значениях предпочтения маршрутов (административное расстояние)
Процесс Junos OS маршрутизации назначает значение предпочтения по умолчанию (также известное как административное расстояние)каждому маршруту, который получает таблица маршрутизации. Значение по умолчанию зависит от источника маршрута. Предпочтительным является значение от 0 до 4294967295 (2 32 – 1), с более низким значением, указывающим на более предпочтительный маршрут. Табл. 1 перечисляет значения предпочтений по умолчанию.
Как узнать маршрут
Предпочтение по умолчанию
Утверждение для изменения предпочтения по умолчанию
Напрямую подключенная сеть
Статические и статические LPS
В Junos OS версиях до 10.4 при настройке статического MPLS LSP с помощью утверждения, значение предпочтения по умолчанию static-path будет 5. Начиная Junos OS версии 10.4, если по умолчанию задается значение static-label-switched-path 6. Предыдущее утверждение static-path конфигурации скрыто в Junos OS 10.4 и более поздних выпусках.
LPS, с сигнализацией на RSVP
RSVP, как описано в preference руководстве пользователя MPLS приложений
preference LDP, как описано в руководстве MPLS приложений пользователя
OSPF внутренний маршрут
Предпочтение OSPF по меткой
внутренний маршрут доступа
IS-IS маршрут 1-го уровня
IS-IS внутренний маршрут 2-го уровня
Предпочтение IS-IS по меткой
OSPF as внешние маршруты
OSPF внешние предпочтения
IS-IS маршрут 1-го уровня
IS-IS внешних предпочтений
IS-IS внешний маршрут 2-го уровня
IS-IS внешних предпочтений
BGP, экспорт, импорт
В общем, чем меньше область действия утверждения, тем выше приоритет его предпочтения, но меньшее значение набора маршрутов, на которое это влияет. Для изменения значения предпочтения по умолчанию для маршрутов, которые узнаются протоколами маршрутов, обычно применяется политика маршрутов при настройке отдельных протоколов маршрутов. Некоторые предпочтения можно также изменить другими настройками, которые указаны в таблице.
См. также
Примере: Настройка значения предпочтения для BGP маршрутов
В данном примере показано, как указать предпочтение для маршрутов, которые были BGP. Информацию о маршруте можно получить из нескольких источников. Для разрыва связей между одинаково конкретными маршрутами, которые узнаются из нескольких источников, каждый источник имеет значение предпочтения. Маршруты, которые узнаются посредством явного административного действия, например, статических маршрутов, имеют более предпочтительный характер по мере того, как маршруты, которые были выучены из протокола маршрутов, BGP или OSPF. Некоторые поставщики называют это административное расстояние.
Требования
До настройки этого примера специальная настройка после инициализации устройства не требуется.
Обзор
Информацию о маршруте можно получить из нескольких источников, например, из статической конфигурации, BGP или протокола внутреннего шлюза (IGP). Когда Junos OS определяет предпочтение маршрута в качестве активного маршрута, он выбирает маршрут с наименьшим предпочтением в качестве активного маршрута и устанавливает этот маршрут в таблица переадресации. По умолчанию программное обеспечение маршрутов назначает предпочтение 170 маршрутам, исходя из BGP. Из всех протоколов маршрутов BGP значением предпочтения по умолчанию, что означает, что маршруты, BGP являются наименее вероятными в качестве активного маршрута.
Некоторым поставщикам за (расстояние) 20 для внешних BGP (EBGP) и расстояние 200 для внутренних BGP (IGBP). Junos OS для EBGP и IBGP используется одинаковое значение (170). Однако эта разница между поставщиками не влияет на операционную деятельность, Junos OS всегда предпочтение от маршрутов EBGP по большему, чем маршрутов IBGP.
Другой областью, в которой различаются поставщики, является IGP расстояние по сравнению BGP расстояния. Например, некоторые поставщики назначьте расстояние 110 для OSPF маршрутов. Это больше, чем расстояние EBGP, равное 20, и приводит к выбору маршрута EBGP через эквивалентный OSPF маршруту. В том же сценарии Junos OS выбирает маршрут OSPF, поскольку по умолчанию предпочтение 10 для внутреннего маршрута OSPF и 150 для внешнего маршрута OSPF, которое оба ниже, чем 170 предпочтение, назначенное всем BGP маршрутам.
В среде с несколькими автовендорами может потребоваться изменить значение предпочтения для BGP, чтобы Junos OS выбрал маршрут EBGP вместо OSPF маршрут. Для этого можно включить утверждение в конфигурацию preference EBGP. Чтобы изменить значение предпочтения BGP по умолчанию, включите утверждение, указыв значение от 0 до preference 4294 967 295 (2 32 – 1).
Другой способ добиться совместимости с несколькимиvendor – включить утверждение advertise-inactive в конфигурацию EBGP. Это приводит к экспорту таблицы маршрутов BGP на лучший маршрут, который был BGP, даже если Junos OS не выбрал ее в качестве активного маршрута. По умолчанию BGP данные маршрутов, получаемые из сообщений обновления, в Junos OS маршрутной таблицы, и таблица маршрутов экспортирует только активные маршруты в BGP, которые BGP затем объявляется равноправным узлам. Утверждение advertise-inactive приводит к Junos OS о наилучшем маршруте BGP который неактивирован из-за IGP предпочтения. При использовании утверждения устройство Junos OS использует маршрут OSPF для переадребовки, а устройство другого поставщика использует маршрут advertise-inactive EBGP для переадребовки. Однако с точки зрения равноправного узла EBGP в соседней AS устройства обоих поставщиков ведут себя одинаково.
Топологии
В примере сети устройства R1 и device R2 имеют маршруты EBGP друг к другу, а также OSPF маршруты друг к другу.
В данном примере показаны таблицы маршрутов в следующих случаях:
Примите значения по умолчанию 170 для BGP и 10 для OSPF.
Состояния соседства
Для установления соседства используется TCP:179.
Hold timer может быть разным у пиров. При установлении сессии будет выбран наименьший.
Если сессия установилась в Established, но через какое-то время перешла в Idle по Hold timer expared (скорее всего через 90sec = 3*keepalive), то первым делом проверьте MTU на канале между роутерами.
Если MTU где-то по пути зарезан/не соответствует MTU на интерфейсах bgp-пиров, можно либо решить вопрос с MTU на найденном проблемном участке, либо можно установить для сессии вручную размер mss (maximum segment size):
Признаки подобной проблемы в логах:
Сообщения
Все сообщения имеют Header
BGP header содержит:
keepalive message = BGP header без payload
BGP Operations
BGP хранит маршруты в трех местах:
Передача маршрутов производится по правилам (чтобы избежать routing loops):
По умолчанию IBGP пиры не меняют next-hop для маршрутов, полученных от EBGP.
Атрибуты (BGP attributes)
Включаются в Update сообщения и описывают BGP префиксы. Атрибуты используются для выбора активного пути.
Атрибуты пути разделены на 4 категории:
Local preference
Когда в сети есть 2 бордера, которые получают один и тот же маршрут извне, и бордеры навешивают одинаковый повышенный lpf через export policy, в таком случае соседи IBGP получат маршрут с измененным lpf, но трафик не сможет по-правильному пути выйти из AS. Из-за того что бордеры тоже друг от друга будут получать маршрут с повышенным lpf. Решение: правильно менять lpf через import policy.
Autonomous system path
Каждый сегмент атрибута AS path представлен в виде поля TLV (path segment type, path segment length, path segment value):
Операторы регулярных выражений
| От m до n | |
| m | |
| m или более | |
| * | Все |
| + | 1 или более |
| ? | 0 или 1 |
| | | Один из двух |
| ^ | Начало community |
| $ | Конец community |
| [] | Список или массив букв или цифр |
| ( ) | Группирует символы |
| () | Ничего (null) |
Next-hop
Next-hop resolution
Можно изменить с помощью policy на выходе (export к IBGP):
Или же на входе (import от EBGP peer):
Origin
Атрибут Origin — указывает на то, каким образом был получен маршрут в обновлении. Меняется с помощью policy.
Atomic aggregate
Aggregator
Communities
Значения от 0x00000000 до 0x0000FFFF и от 0xFFFF0000 до 0xFFFFFFFF зарезервированы.
Как правило community отображаются в формате ASN:VALUE. В таком формате, доступны для использования community от 1:0 до 65534:65535. В первой части указывается номер автономной системы, а во второй значение community, которое определяет политику маршрутизации трафика.
Некоторые значения communities предопределены. RFC1997 определяет три значения таких community. Эти значения должны одинаково распознаваться и обрабатываться всеми реализациями BGP, которые распознают атрибут community.
Если маршрутизатор получает маршрут, в котором указано предопределенное значение communities, то он выполняет специфическое, предопределенное действие основанное на значении атрибута.
Предопределенные значения communities (Well-known Communities):
no-export (0xFFFFFF01)
Все маршруты которые передаются с таким значением атрибута community не должны анонсироваться за пределы AS. То есть, маршруты не анонсируются EBGP-соседям, но анонсируются внешним соседям в конфедерации.
AS1 подключена к AS2 двумя линками (multinoming). AS1 анонсирует 172.17.0/16 в AS2. Для оптимальной маршрутизации, AS1 хочет посылать некоторые более специфичные маршруты через один из этих линков, при этом остальному интернету вовсе не обязательно получать эти специфики. Для этой цели AS1 использует community no-export, и посылает 172.17.0/17 в один из стыков с AS2, и 172.17.128/17 во второй стык. AS2 видит эти маршруты и выбирает их как более специфичные. Кроме того, эти маршруты видят все iBGP-соседи в пределах AS2. Тем не менее, за пределы AS2 в Интернет анонсируется только 172.17.0/16.
no-advertise (0xFFFFFF02)
Все маршруты которые передаются с таким значением атрибута community не должны анонсироваться другим BGP-соседям.
no-export-subconfed (0xFFFFFF03)
Все маршруты которые передаются с таким значением атрибута community не должны анонсироваться внешним BGP-соседям (ни внешним для конфедерации, ни настоящим внешним соседям). В Cisco это значение встречается и под названием local-as.
Маршрутизаторы, которые не поддерживают атрибут community, будут передавать его далее, так как это transitive атрибут.
С communities широко используются регулярные выражения.
Примеры
Список операторов регулярных выражений для Community
| От m до n | |
| m | |
| m или более | |
| * | Все |
| + | 1 или более |
| ? | 0 или 1 |
| | | Один из двух |
| ^ | Начало community |
| $ | Конец community |
| [] | Список или массив букв или цифр |
| ( ) | Группирует символы |
| () | Ничего (null) |
Действия с community
Multi exit discriminator (MED)
Сравнение MED (при прочих равных) происходит если один и тот же префикс приходит от одной AS.
Если будет анонс этого префикса с более низким MED, но из другой AS, то он не будет рассматриваться как вероятный вариант для использования.
Это дефолтное поведение, которое можно изменить с помощью:
MED назначается с помощью policy.
Возможные операции с MED
MED можно назначить внутри protocols bgp:
MED также можно назначить аналогичным образом через policy:
При использовании metric igp на префикс вешается MED, равный IGP метрики до роутера, который прислал этот префикс. При изменениях IGP metric, будет меняться и MED.
При использовании metric minimum-igp MED не будет меняться при изменениях IGP метрики.
Это дефолтное поведение и альтернатив этому нет.
Weight (проприетарный атрибут Cisco)
Механизмы управления трафиком
Входящим
Исходящим
Выбор лучшего пути (BGP Active Route Selection)
В Juniper можно посмотреть причину неактивности маршрута: Inactive reason в выводе sh route protocol bgp x.x.x.x extensive
Дефолтное поведение для EBGP маршрутов может быть изменено: path-selection external-router-id. При включении этой функции для роутера выбор активного EBGP маршрута от разных роутеров будет делаться по наименьшему router-id.
Multipath
Один и тот же маршрут прилетает с двух пиров одной AS или несколько копий маршрута прилетает с одного пира. Активный маршрут будет вставлен в routing table с несколькими next-hop и трафик будет балансироваться между двумя пирами (в forwarding table все же будет вставляться один next-hop). Для inactive маршрутов будет указан один next-hop. Multipath не вставит маршруты с одинаковым MED-plus-IGP cost, при разных IGP метриках до пиров. На роутере глобально должен быть включен load-balancing.
При включенном multipath, алгоритм выбора лучшего пути игнорирует router ID и peer ID.
Link Bandwidth Extended Community
При включенном multipath можно задать желаемую балансировку между линками через extended community. Это механизм описан в draft-ietf-idr-link-bandwidth-06, и не является стандартизированным, следовательно, возможно, он не будет работать с некоторыми вендорами. В JunOS поддерживается.
Позволяет делать балансировку пропорционально заданным в community скоростям.
R1 и R2 соединены напрямую через два сабинтерфейса, на каждом из которых висит своя /30 сеть
Multihop
Возможность поднять EBGP peering между роутерами, не имеющих прямого физического соединения. Сессия устанавливается на lo интерфейсах.
Важно в конфиге задать multihop. В таблице маршрутизации должен быть маршрут до пира.
При поднятии сессии на Lo интерфейсах используем:
TTL = 1 задаем, чтобы соседство установилось точно с одним ближайшим роутером. (либо другое значение, если роутер далеко)
Т.к. между роутерами теперь 2 физических линка, то можно балансировать трафик между ними.
Modifying AS Path
Option 1: remove-private
Роутер, на котором настроен remove-private перед передачей префиксов удаляет из AS path AS из указанного выше диапазона.
Можно настраивать на всех уровнях: protocols bgp, group, neighbor.
Option 2: local-as
При такой конфигурации R1, EBGP-сосед, который ожидает, что у R1 будет AS3333 сможет установить соседство с R1, хотя, по факту R1 принадлежит AS1111. Результат:
Если добавить ключевое слово private:
То R1 вообще не будет добавлять AS3333 при анонсе маршрутов, получаемых от 10.1.0.2 своим соседям.
as-override
Можно конфигурировать для группы или соседа.
Роутер ISP на полученном префиксе смотрит в AS path, AS пира заменяем на свою. При передаче префикса второму site ISP делает стандартный prepend своей AS. В итоге пиру в AS 65500 прилетит префикс с таким AS path:
loops
Тогда на CE2 прилетит префикс с AS path:
и роутер это сожрет.
Опции настройки для пиров
После задания passive для пира:
Route Reflection
Заменяем full-mesh на сети между PE.
Распространение маршрутов при использовании RR
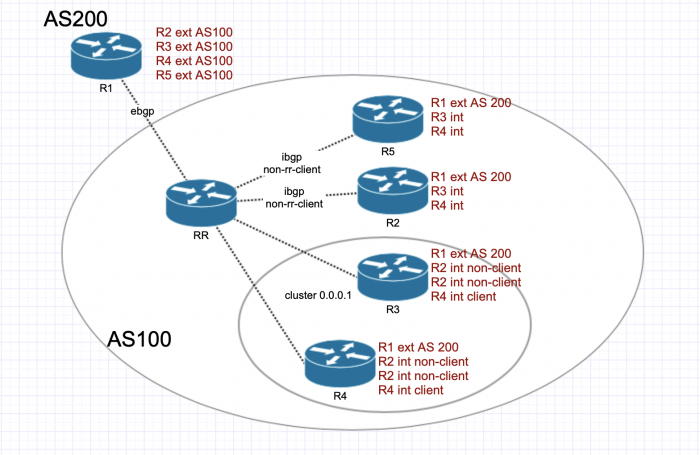
Будем использовать следующие обозначения:
Распространение маршрутов происходит следующим образом:
RR добавляет/изменяет атрибуты (без политик по дефолту):
Router ID первого роутера, который заслал маршрут в AS.
Список, включающий ID всех RR, которые обрабатывали данный префикс. Если RR получит маршрут, у которого в cluster list будет ID этого RR, то он его дропнет. Участвует при выборе активного маршрута (активным становится с наименьшим cluster list). Cluster ID добавляется к cluster list, когда маршрут отправляется. Cluster ID должен быть уникальным в рамках AS. При использовании нескольких RR, можно для всех использовать одинаковый cluster ID.
+ такой схемы: в таблице будет меньше маршрутов и при такой схеме можно добиться хорошей отказоустойчивости в сети.
Правила работы с Originator и Cluster List:
Соседство между RR можно устанавливать как внутри отдельной группы для кластера, так и в отдельной группе. В обоих случаях при передаче маршрутов между RR петель не будет, т.к. cluster ID будет одинаковыми. Каждый из RR в кластере устанавливает IBGP с другими RR, не входящих в кластер. В подобных схемах все-таки тоже стараются использовать уникальные cluster ID.
Configuration
RR-clients конфигурируются в отдельной группе, где должен быть включен: «cluster x.x.x.x»
Hierarchical Route Reflection
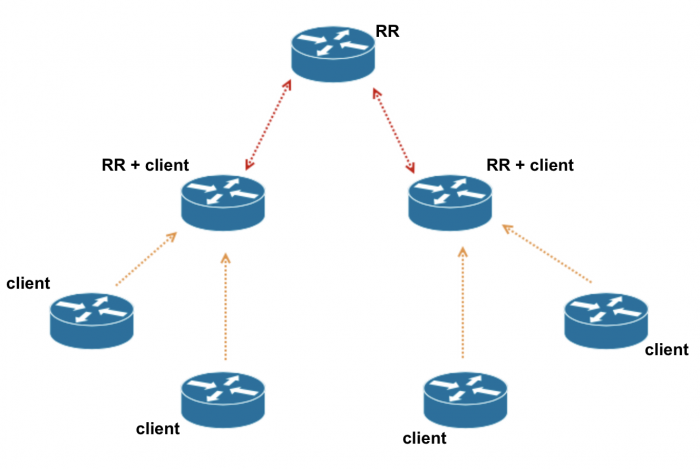
Отличие от предыдущих: в схеме появляются не только RR и client, но еще и роутеры, выполняющие обе функции в рамках разных кластеров. Clients могут устанавливать IBPG между собой full-mesh. Это удобно использовать, чтобы clients могли использовать маршруты от других clients нативно, без обработки RR. Чтобы RR не флудил копиями маршрутов, на нем можно включить no-client-reflect, это отключит пересылку маршрутов, полученных внутри кластера. Внешние маршруты при этом продолжают пересылаться.
Modifying Attributes on the RR
Все атрибуты BGP изменяются через policy. Если на RR есть EBGP, то с большой вероятностью будет активна ф-ия: next-hop-self. При этом, у маршрутов, полученных от client, также next-hop будет меняться. Что приведет к не оптимальному форвардингу трафика (должен идти напрямую к original роутеру, а будет идти через RR). Чтобы менять next-hop только у external: в policy матчим по interface ли neighbor.
Fake-group
По факту функционал RR включается/выключается только при добавлении/удалении соседу в группе с клиентами (с cluster).
Если на маршрутизаторе настроены EBGP с клиентами или IBGP c RR, для которых в конфигурации группы включены vpn-address-family, (inet-vpn, inet6 inet-mpvn, inet-mdt, inet6-mpvn, l2vpn, iso-vpn) и на маршрутизаторе в этих группах производится добавления первого соседа или удаления последнего, Juniper рестартует BGP сессии с RR и c EBGP пирами в VPN-address-family для отсылки NLRI с новой (удалением старой) address-family.
Для предотвращения подобных ситуаций можно предпринять следующие шаги:
Configuration
Fake группа имеет следующий вид для RR и PE:
IPv6 (6PE)
Если у нас есть настроенная ipv4 сеть и мы захотели передавать трафик и для ipv6 адресов (используя MPLS), то:
— требуется настроить family inet6 labeled-unicast explicit-null на сессии pe<>rr
эта family навешивает на ipv6 префикс label 2 (explicit-null для ipv6), что позволяет на сети в качестве транспорта использовать mpls, а на последнем роутере делать lookup в таблице inet6.0.
— на сети у нас скорей всего уже будет включен mapping ipv4 адресов в ipv6:
— при передаче префиксов pe->rr должен быть настроен в политике hext-hop self. При этом для ipv6 префиксов будет подставляться mapped ipv6 адрес lo0.
— на rr адреса ::ffff:172.30.5.5 не будет, поэтому полученный префикс будет в hidden, из-за неотрезовленного next-hop. Чтобы решить эту проблему прописываем статику:
receive в данном случае позволяет сделать маршрут активным, не прибегая к форвардингу трафика.
— после этого рефлектор спокойно рефлектит маршрут своим клиентам.
ну и проверяем, что и сам префикс стал активным:
Кстати, ipv6 tunneling перетаскивает как ldp, так и rsvp маршруты в inet6.3.
Confederations
Цель: разбить global AS на sub-AS.
Также в отличие от стандартного EBGP, в CBGP обычно соседство строится на loopback (добавляем multihop в настройки).
AS-path segment
При прохождение через CBGP линк, роутер добавляет sub-AS к AS-path в «()» в последовательности, как шел маршрут по сети.
AS Confederation Sequence не используется при выборе активного пути.
Этот атрибут имеет type code 3.
При агрегировании маршрутов внутри конфедерации, AS confederation sequence становится AS confederation set.
Этот атрибут имеет type code 4.
Оба атрибута используются только для предотвращения петель внутри конфедерации.
При анонсировании маршрутов из конфедерации дальше по сети по EBGP, private AS (sub-AS) стираются, поэтому все конфедерации извне видны как одна большая глобальная AS. При этом не требуется отдельно включать (remove-private). В случае с конфедерациями, все приватные AS итак сотрутся.
Но все роутеры внутри конфедерации обязательно должны знать номер глобальной AS.
Configuration
Route damping (flapping)
При различных обстоятельствах на сети могут возникать флапы маршрутов, что приводит к загрузке CPU на роутерах.
Чтобы избежать подобного поведения есть некоторые механизмы защиты от флапов, например: BGP route flap damping.
Damping игнорируется IBGP и работает только с EBGP и CBGP (confederation BGP).
Damping уменьшает кол-во update message, путем обозначения флапающих маршрутов непригодными стать активными маршрутами.
Когда маршрут прилетает на наш роутер (на котором настроен route damping), на префикс назначается значение merit = 0.
Как только роутер распознает некую нестабильность маршрута (префикс просто перестает долетать до роутера (или линк упал)):
После того, как префикс пропал и заново прилетел на роутер по BGP, его значение merit = 2000 (при дефолтных настройках)
После этого при исчезновении маршрута с роутера, его не будет видно в inet.0, но инфо можно будет посмотреть в
После того, как будет превышен supress threshold, инфо о маршруте можно будет посмотреть:
Либо в hidden, если маршрут приходит от пира.
Config
Как только включаем на роутере damping, без заданных параметров, для работы будут использоваться дефолтные значения.
Blackhole
Когда на сети определено специальное community для blackhole, и клиент посылает префикс, помеченный этим community, нужно реализовать блокировку трафика на нашей сети к этом префиксу. И желательно разослать этот префикс другим пирам и апстримам с их blackhole-community.
Блокировку трафика можно организовать несколькими способами.
1. зарулить трафик на префикс, у которого next-hop = discard.
Тема discard не раскрыта 🙂
3. сделать у префикса сразу next-hop discard.
без accept маршрут будет в hidden и не передастся своим ibgp соседям. (в hidden, так как next-hop unusable)
Политику применяем на клиентов и на ibgp сессии в рамках нашей aAS (+cbgp, если используем конфедерации)
Чтобы разослать префикс другим ebgp пирам добавляем еще одну строчку в политику:
Как известно, этот механизм используется в качестве обмена hello сообщениями с заданным интервалом, ниже, чем дефолтный интервал в других протоколах. Что позволяет протоколу быстрее обнаружить падение сессии.
Сильно нагружает CPU RE, поэтому с ним сильно перебарщивать не стоит.
Хосты устанавливают сессию и обмениваются hello.
Если перестали приходить hello, то BFD дает знать протоколу, что пропала связность между хостами.
Если значения таймеров у пиров не совпадают, то BFD использует наибольшее значение (используется режим adaptive-mode).
Это поведение по умолчанию можно выключить: no-adaptation.
Есть несколько способов настраивать BGP между роутерами, работающими с ipv6.
На интерфейсах обычные p2p адреса из /126 (/30) сеточки. Это самый примитивный вариант.
Настраиваем сессию на ipv6 адресах в отдельной группе. Если настраивать в группе, в которой настроены также сессии на ipv4-адресах, то сессия на ipv6 поднимется, но роутеры маршрутами обмениваться не будут.
— сессия строится на ipv4 адресах. в группе или на neighbor настроена передача family inet6 unicast.
— глобально требуется также включить:
Либо использовать отдельные lo, который будет выступать в роли router-id для сессии.



