Ранги оперативной памяти: что это такое, как узнать и какая лучше

Итак, оперативная память имеет следующие ключевые параметры:
И вроде, чтобы определить, насколько эффективна будет работа оперативной памяти, этого достаточно. Но если ввести еще одну переменную — ранг (rank, ранк) — она с ног на голову перевернет привычную парадигму выбора ОЗУ.
Что такое ранг оперативной памяти?
С приходом на рынок AMD Ryzen в инфополе массово заговорили о рангах оперативной памяти и их чудесных свойствах, особенно для любителей оверклокинга. Но для большинства пользователей понятие о «ранговости» свелось к размещению чипов памяти на текстолите ОЗУ:
Однако это неверное представление, ведь есть еще и применяемая в серверных системах четырехранговая и восьмиранговая память, которые в эту классификацию не вписываются. Предлагаем разобраться в этом подробнее.
Термин «Ранг» (ранк, rank) обозначает одномоментную передачу по шине блока данных плотностью 64 бита (72 бита для серверной ECC-памяти). В простейшем понимании, одноранговый DIMM-модуль (1R) содержит в себе 64-битный фрагмент информации, которым он за один такт работы делится с процессором.
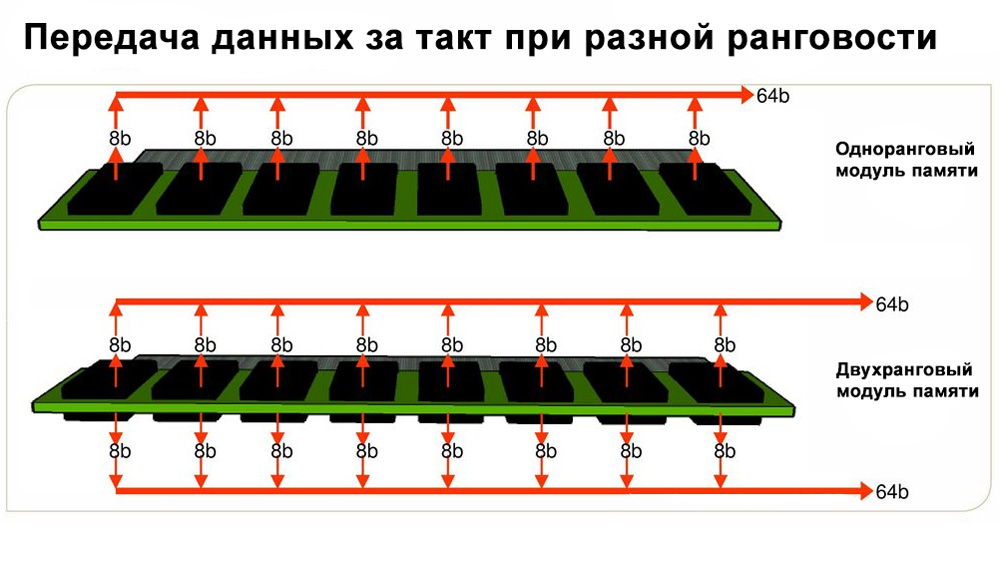
Максимальный объем однорангового модуля типа DDR4 — 8 ГБ, если память набиралась кристаллами по 1 ГБ. В этом случае, за основу можно было взять следующую константу:
Если на текстолите распаяно 16 ГБ по 8 кристаллов в 1 ГБ с двух сторон — это двухранговая память (2R).

В нынешнее время, современная память может быть набрана модулями, где кристаллы наслаиваются друг на друга, увеличивая емкость каждого вдвое.

Не так давно Samsung, Hynix, Micron и другие производители начали выпускать кристаллы повышенной плотности уже на 2 ГБ, поэтому емкость ОЗУ на кристаллах новой версии емкость 1R увеличилась до 16 ГБ.
Итого, в итоге имеем схему:
1 ранк = 8 ГБ (кристаллы «старой» версии по 1 ГБ);
1 ранк = 16 ГБ (кристаллы «новой» версии по 2 ГБ).
Память 4R встречается в продаже только в серверном сегменте. Визуально она выглядит так же, как и двухранговая, но при этом на одной стороне распаяно сразу два ранга (2 блока по 8 ГБ + кристалл коррекции ошибок). Программно модуль настроен таким образом, чтобы каждый из независимых блоков мог передавать по 72 бита информации за раз.

Аналогично для 8R-памяти, только она еще сложнее технически и программно.

В целом, принцип работы многоранговой памяти можно представить так:
В один момент времени работает только часть кристаллов — один ранк. А остальная «грядка» тем временем накапливает заряд и ищет внутри себя данные, чтобы отдать их процессору по шине.
Отличие одноранговой памяти от двухранговой на практике
На данный момент обойти лимит в 64 (72) бита за такт физически невозможно, поскольку так устроена работа стандарта DDR4. Но инженеры тоже не просто так едят свой хлеб, поэтому они додумались обойти ограничения довольно забавным способом: заставили чипы работать попеременно, фактически передавая 128 (144/288) бит вместо 64 (72).
Что это дает на практике? Разберем на примере сервера HPE ProLaint DL380 Gen10. Возьмем за основу тот факт, что в корпусе установлен один процессор Xeon Platinum 8ххх, поскольку у него самые широкие возможности. К тому же, чип поддерживает планки до 128 ГБ. Умножим это число на 12 (столько слотов ОЗУ выделено под процессор) и получим 1536 ГБ. Такого результата можно добить только с использованием 8R-планок с кристаллами по 2 ГБ.
Но тут стоит понимать, на серверной памяти DDR4 расположено 288 контактов, каждый из которых передает 1 бит данных. Если вдарить по всем потокам, ОС запестрит ошибками, поскольку больше 72 бит переварить не может. С 4R/8R-планками все еще сложнее: некоторые выдают только 36 бит вместо 72, и именуются Load-reduced Memory (LRDIMM), комплект с пониженной нагрузкой).

Т.е. вы получаете больший объем, но сниженную производительность. Тайминги у такой памяти ниже, задержка доступа — выше, частота работы не превышает 2933 МГц для Xeon Platinum, 2666 МГц для Gold, 2400 для Silver и 2133 для Bronze.
Также сервер не позволит использовать память с разной ранговостью. Если вставили модуль 2R, будьте добры добавлять такие же, иначе сильно потеряете в скорости и стабильности.
В защиту 2R/4R скажем следующее:
Но не забывайте, что полностью раскрыть потенциал многоранговой оперативной памяти можно только при правильно подобранном процессоре. Более подробную информацию вы сможете получить у консультантов компании Маркет.Марвел.
Какой ранг памяти лучше?
Выбирая, что лучше: одноранговая или двухранговая оперативная память, стоит опираться на частотные показатели и объем передаваемых данных. Двухранговая память с частотой 3000 МГц обгоняет по производительности одноранговый модуль при частоте в 3333 МГц.
Также владельцы двухранговой памяти получают следующие преимущества:
Также двухранк, еще и в двух/четырех/шестиканале как нельзя кстати открывает себя в системах с интегрированной графикой, где GPU-модуль процессора черпает память напрямую из ОЗУ. Тут чем быстрее происходит шевеление информации — тем лучше.
Как узнать ранг оперативной памяти по маркировке?
Маркировка оперативной памяти разнится от производителя к производителю, но наиболее распространенными вариантами являются буквенные маркеры:
Также распространена маркировка формата 1Rх4, 2Rх8, 2Rх16, 4Rх4.
Первая часть — 1R, 2R, 4R, 8R — означает ранг.
А вторая х4, х8, х16 — то, сколько байтов за такт способен передавать каждый кристалл на планке.
Чтобы наработать скиллы по чтению маркировки, возьмем за пример память от HPE, поскольку она частенько встречается в серверном сегменте. У этого производителя маркировка планок памяти выглядит так:

Закрепляем результат следующими примерами:
Остались вопросы? Задайте их нашим консультантам и получите исчерпывающий ответ. Мы готовы предложить вам наилучшее решение для вашего оборудования, которое позволит получить максимум производительности.
Ранги оперативной памяти: что это такое, как узнать и какая лучше
3DS DIMM — многоэтажная динамическая память
В некоторых, очень отдельных областях применения вычислительной техники, памяти много не бывает. За любые деньги, но чтобы все (ну, или — большая часть) в памяти и моментально доступно! Так как скорость обращения к внешней памяти, какой бы быстрой она ни была, существенно ниже, чем скорость работы с внутренней, ряд приложений не может терять время на ожидания — потеря производительности дорого обходится. Но всему есть пределы, обусловленные как принятыми и стандартизованными спецификациями на интерфейс, протокол, и т.д., с одной стороны, так и принятыми конструктивными особенностями реальных комплектующих вычислительной техники — с другой. К примеру, максимальное количество поддерживаемых одним процессором модулей памяти, равно произведению числа каналов памяти на максимальное число модулей на одном канале. Обе цифры жестко ограничены возможностями центрального процессора. Больше каналов особенно не наделаешь. В серии процессоров Scalable, Intel увеличил с 3 до 4 число каналов работы с памятью, но при этом уменьшил число модулей в канале. Каждый из модулей вместе с линией передачи к нему ухудшает характеристики канала, вынуждая снижать скорость передачи данных. Умножаем полученное число на объем одного модуля и получаем максимальный объем оперативной памяти, который может быть подключен на один процессор. Что делать, если полученного объема мало?
Расширение не в плоскости, а по вертикали открывает новые горизонты. Легко увеличить емкость одного модуля динамической памяти путем напайки дополнительных чипов или увеличением емкости чипа за счет его площади не получается. Решили пойти другим путем. А что — если упаковать чипы памяти в несколько «этажей», но внутри одного корпуса?
Существенные доработки
Пришлось попутно решить несколько задач. Первая — собственно, многослойная упаковка. Полупроводниковый чип имеет контактные площадки для соединения с контактными площадками корпуса проволочными проводниками. Соответственно, накладываемый сверху чип необходимо располагать с прослойкой, чтобы иметь доступ к площадкам предыдущего слоя, да еще и распаять, не нарушив уже сформированные. Сложно и нетехнологично.
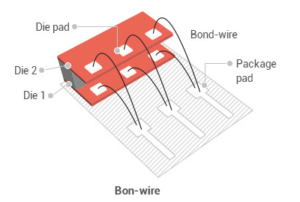
Вторая задача — разгрузка шины. Каждый наслаиваемый чип, непосредственно соединенный с шиной интерфейса ухудшает ее характеристики за счет привнесения паразитных емкостей и увеличения электрической нагрузки. Значит, необходима развязка. Остановились на следующей схеме: первый слой, «мастер», контактирует непосредственно с шиной интерфейса и имеет дополнительную логику-селектор для адресации к различным слоям. Последующие слои, «ведомые», соединяются с только с первым слоем и несколько отличаются схематически, поскольку этой дополнительной логики не имеют. А соединения между слоями осуществляются через сквозные проводники (through-silicon via, TSV).
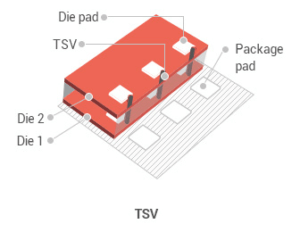
Что мы имеем в итоге? Или более емкие модули динамической памяти без увеличения емкости чипов, или тот же объем модуля, но на менее емких (значит — более дешевых) чипах памяти. 3DS упаковка затрагивает только компоновку кремниевых чипов в корпус, соответственно — модуль DIMM так же может быть построен с использованием дополнительных буферов для снижения нагрузки ( Load Reduced ).
Сравнение 3DS LRDIMM с обычной DDP LRDIMM
Потребление энергии
Так как в 3DS модулях используется тот же тип чипов, что и в обычных DDR DIMM, существенной разницы в потреблении энергии между 3DS и не-3DS модулями одинаковой емкости нет.
Производительность
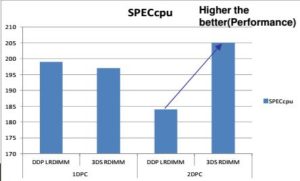
С производительностью картина неочевидная. В конфигурации с одним модулем на канал (1DPC, DIMM per channel), производительность 3DS памяти схожа с обычной, небольшое отставание наблюдается за за счет бОльшего числа рефреш циклов, необходимых модулю. Но в конфигурации с двумя модулями на один канал ( 2DPC) ситуация меняется кардинально — если обычная память «проседает» почти на 50%, 3DS память, наоборот — выигрывает от 20 до 50% по разным тестам. Объясняется это меньшим суммарным временем задержки от большего числа ранков. Графики результатов ниже.
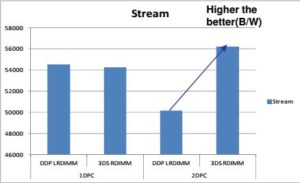
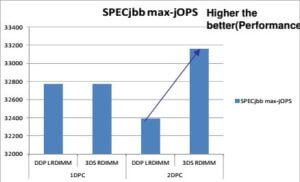
Совместимость
3DS модули не совместимы с другими типами памяти. То есть, на одном канале нельзя устанавливать модули разных типов.
Производители
О готовности производить 3DS модули объявили все ведущие игроки в области памяти
Заявил о «первом в мире» модуле 128GB 3DS LRDIMM с технологией упаковки TSV. Модуль строится на 8ГБ чипах, упакованных в 4 этажа.
| Тип | Технологи-ческие нормы | Базовая емкость чипа | Количество слоев | Емкость модуля | Шина данных | Скорость | Напряжение питания |
|---|---|---|---|---|---|---|---|
| DDR4 | 2ynm | 8Gb | TSV 4Hi | 128GB | x72 | 2400 | 1.2V |

Объявил о массовом выпуске 64ГБ 3D TSV DDR4 DRAM в далеком 2014, а 128ГБ модули был готов массово выпускать в ноябре 2015 года.
128 ГБ TSV DDR4 RDIMM состоит из 144 чипов DDR4, расположенных в 36 4-гигабайтных пакетах DRAM, каждый из которых содержит четыре 8-гигабитных (Gb) микросхемы, произведенной по нормам 20-нанометров (нм), собранные с использованием передовой технологии упаковки TSV.

| Device configuration | 32Gb (128 Meg x 4 x 16 banks x4 ranks) |
| Part Number | Емкость модуля | Конфигурация | Производи-тельность | Скорость | Циклы (CL- t RCD- t RP) |
| MTA144ASQ16G72LSZ-2S6__ | 128GB | 16 Gig x 72 | 21.3 GB/s | 0.75ns/2666 MT/s | 22-19-19 |
| MTA144ASQ16G72LSZ-2S3__ | 128GB | 16 Gig x 72 | 19.2 GB/s | 0.83ns/2400 MT/s | 20-18-18 |

Производители систем
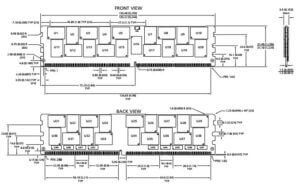
Готовность к использованию 3DS LRDIMM подтверждена (документ) компанией Supermicro в серии серверных материнских плат X11 под процессоры Intel Scalable (LGA3647). Краткое содержание — использовать в платах X11 можно, миксовать в одном канале 3DS LRDIMM с другими типами нельзя.
Перейдите в раздел каталога Серверы для выбора базовой модели и конфигурации готового сервера.
Далее идут технические подробности, которые не всем интересны.
Выбор слоя («этажа»), который в многоэтажной сборке называется «логическим ранком» происходит в селекторе мастер-чипа по сигналам линии шины CS_n, C1, C0.
![]()
CS_n показывает — к какому из слоев идет обращение — мастер или слейв
C0, C1 формируют адрес логического ранка. 2 линии адреса позволяют обращаться к 4 подчиненным слоям.
Блок-схема сборки, состоящей из мастер-чипа и 3 подчиненных слоев выглядит так:
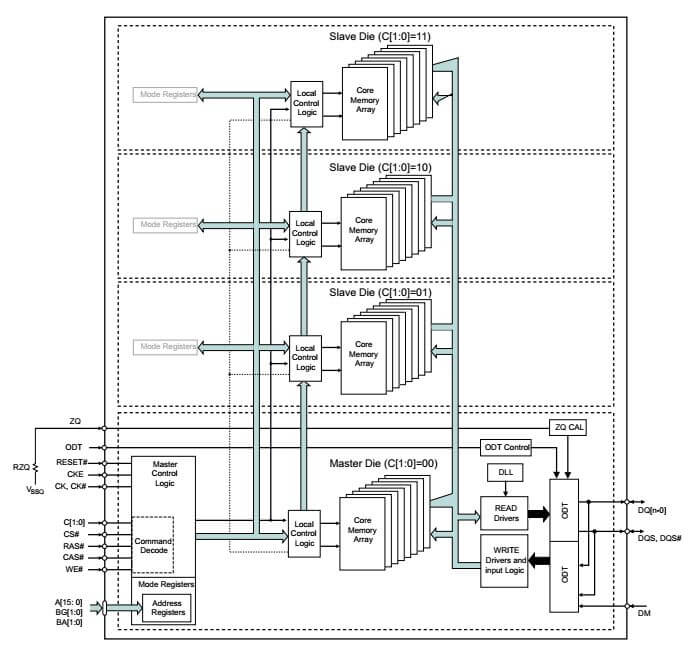
На мастер-слой добавлены блоки Master Control Logic, содержащий декодер команд и селектор слоя и общие для сборки буферы и блок ODT Control.
Выбираем оперативную память: руководство Hardwareluxx
Страница 4: Полезные сведения для профессионалов (серверы)
Что такое Registered (регистровые) DIMM?
Выше мы отметили, что в настольных платформах используются UDIMM (Unbuffered, небуферизованные), а в серверных часто встречаются RDIMM (Registered, регистровые). В случае UDIMM адресация памяти выполняется напрямую контроллером памяти, как и передача данных. В случае же RDIMM адресацию на себя берет отдельный чип-регистр, передача данных по-прежнему осуществляется напрямую контроллером памяти.
Цель RDIMM заключается в уменьшении нагрузки на контроллер, в результате на серверную материнскую плату можно устанавливать больше DIMM, существенно увеличивая емкость памяти сервера по сравнению с настольной системой. В случае полностью буферизованных модулей Fully Buffered DIMM (FB-DIMM) промежуточный буфер используется не только для адресации, но и для передачи данных. Стандарт LRDIMM (Load Reduced) является дальнейшей разработкой регистровой памяти, он обеспечивает еще большую емкость.

Кроме обычных планарных чипов памяти разработана технология «бутерброда» из нескольких чипов под названием 3DS DIMM. Она позволяет значительно увеличить емкость модулей. Наконец, есть модули NVDIMM (Non-volatile), данные в которых не стираются в случае сбоя питания. Модули NVDIMM разделяются на NVDIMM-F (Flash Storage), NVDIMM-N (DRAM), NVDIMM-P (Persistent Memory) и NVDIMM-X (NAND Flash Storage).
Что такое ECC?
ECC означает «Error Correction Code» или код коррекции ошибок. При чтении данных из памяти или записи в память код ECC позволяет исправлять одиночные битовые ошибки. Что повышает надежность работы памяти в окружениях, где это необходимо. Например, в серверах и рабочих станциях. Для кода ECC добавляются 8 дополнительных бит (64 базовых + 8 дополнительных = 72).
Алгоритм ECC позволяет исправлять битовые ошибки, а также определять два ошибочных бита, но уже не исправлять их. Технологии Chipkill или Advanced ECC расширяют алгоритм ECC, позволяя корректировать до 4 ошибочных битов и определять до 8 ошибочных битов. Если ошибок будет много, то данная функция позволяет скрыть сбойный чип в системе без перезагрузки (отсюда и название «Chipkill»), при этом сервер продолжает стабильную работу. Технологии Chipkill или Advanced ECC работают как массив RAID на жестких дисках, опираясь на распределенное избыточное хранение данных.


Технология Memory Scrubbing производит постоянную проверку памяти на наличие ошибок, результаты отправляются серверным утилитам управления, например, IPMI (Intelligent Platform Management Interface) в BMC (Baseboard Management Controller).
Но для работы ECC вместе с функцией ChipKill/Advanced ECC необходимо чтобы процессор, материнская плата с BIOS и оперативная память поддерживали ECC. Данная технология обязательна для всех RDIMM, но также встречаются и UDIMM с ECC.
Примеры серверной памяти
Ниже представлены два изображения Registered DIMM с ECC:


Приведены два серверных RDIMM, по крайней мере, с одной стороны установлены 18 чипов памяти, по центру чипы ECC и регистра. Типичные RDIMM выпускаются в емкостях 8, 16 и 32 Гбайт, с тактовой частотой 2400 МГц, 2666 МГц, 2933 МГц и 3200 МГц.
Подписывайтесь на группы Hardwareluxx ВКонтакте и Facebook, а также на наш канал в Telegram (@hardwareluxxrussia).
Технологии
В настоящее время, имеют распространение следующие технологии организации оперативной памяти:
UDIMM (англ. Unbuffered DIMM) – небуферизованная память. Обычные планки ОЗУ, которые устанавливаются в персональных компьютерах и некоторых серверах начального уровня. Поддерживается установка до двух планок памяти на канал. Как правило, память типа UDIMM поддерживает технологию автоматической коррекции ошибок ECC, а объем одной планки составляет не более 16 ГБ.
RDIMM (англ. Registered DIMM) – регистровая память. Планки ОЗУ, широко применяющиеся в серверах. Снабжены специальным регистром, который буферизует управляющие и адресные команды контроллера памяти. Благодаря этому, снижается нагрузка на контроллер и появляется возможность использовать более объемные планки памяти и в большем количестве в рамках одного сервера. Объем планки типа RDIMM может достигать 32 ГБ.
LRDIMM (англ. Load-Reduced DIMM) – память со сниженной нагрузкой. Еще один тип ОЗУ с механизмом буферизации. В отличие от RDIMM, здесь в буфер отправляются не только управляющие и адресные команды, но и собственно данные. Эта технология позволяет значительно снизить нагрузку на контроллер памяти и использовать планки емкостью до 128 ГБ. Кроме того, в отличие от RDIMM, при использовании более двух планок LRDIMM на канал не снижается скорость работы памяти.
NVDIMM (англ. Non-Volatile DIMM) – энергонезависимая память. Технология организации ОЗУ с возможностью сохранения загруженных в память данных при штатном либо аварийном завершении работы системы. Память типа NVDIMM может использовать емкости флэш-накопителей (например, SSD) в качестве энергонезависимого хранилища, либо иметь специальный резервный модуль энергонезависимой флэш-памяти, в который будут переписываться данные при завершении работы.
Комбинировать память UDIMM, RDIMM и LRDIMM в рамках одного сервера не допускается. Требования к NVDIMM могут быть разными у разных производителей. Компания HPE в рамках новой серии Persistent Memory анонсировала планки NVDIMM на 8 ГБ для серверов DL360 Gen.9 и DL380 Gen.9. Для одного сервера допускается установка до 16 планок NVDIMM и имеется возможность совмещать их с RDIMM. При использовании HPE NVDIMM требуются процессоры Intel Xeon E5-2600 v4, наличие батареи поддержки кэш-памяти HPE Smart Storage Battery (в качестве источника питания при перезаписи данных в энергонезависимый модуль) и как минимум одной планки RDIMM.
Репликация – процесс передачи данных с одного устройства хранения на другие с целью создания резервной копии этих данных, обеспечения сценариев высокой доступности или катастрофоустойчивости. Существует 2 типа репликации: синхронная и асинхронная.
В системах хранения компании HPE имеются следующие решения по репликации:
При организации репликации для систем хранения обычно оперируют двумя показателями.
Recovery Point Objective (RPO) – допустимый объем возможных потерь данных в случае сбоя (потерю данных за какой промежуток времени мы можем допустить). Измеряется в секундах.
Recovery Time Objective (RTO) – допустимое время простоя системы в случае сбоя. Измеряется в секундах.
В случае с синхронной репликацией значение RPO стремится к 0, но зато предъявляются более высокие требования к каналам связи.
В случае с асинхронной репликацией значение RPO будет не 0. В системах хранения HPE, как правило, значение варьируется от 5 минут до 24 часов.
Тиринг (англ. Tiering) – это технология, с помощью которой СХД может самостоятельно перераспределять данные по накопителям на основе частоты их использования. Редко используемые данные перемещаются на более медленные накопители, а часто используемые – на более быстрые.
Тиринг дает возможность сэкономить на дорогих HDD или SSD, позволяя приобрести их в небольшом количестве и использовать более дешевые и объемные NLSAS/SATA для хранения основных данных, которые не используются в текущий момент. Согласно статистическим показателям, до 70% данных располагается на медленных дисках при использовании тиринга.
Как правило, в СХД выделяется 3 уровня или «тира» (от англ. Tier):

На большинстве современных СХД тиринг работает в автоматическом режиме. Система самостоятельно анализирует частоту обращений к различным блокам данных того или иного LUN и перемещает их между уровнями хранения. Данный режим называется sub-LUN tiering. У HPE в некоторых СХД для него принято название Adaptive Optimization. Некоторое время назад был распространен ручной режим тиринга, когда система могла осуществить перенос только всего LUN и только по команде администратора. Этот функционал у HPE носит название Dynamic Optimization.
Сегодня тиринг реализован на всех основных SAN СХД компании HPE: MSA, StoreVirtual, 3PAR. Для его активации может потребоваться приобретение дополнительной лицензии.
Virtual Tier Affinity – дополнительное улучшение для тиринга в массивах HPE MSA, приоритизация данных на уровне LUN (механизм «Quality of Service»). Администратор может выставить для каждого LUN высокий, либо низкий приоритет. В первом случае данные LUN быстрее станут попадать на самый производительный уровень хранения и дольше там находиться. Во втором случае данные по умолчанию будут записываться на архивный (наименее производительный) уровень и быстрее туда опускаться в случае последующего поднятия.
Дедупликация – это технология, которая позволяет находить и исключать одинаковые (дублирующиеся) данные в рамках системы хранения с целью экономии дисковых объемов. С включенной дедупликацией одинаковые данные не будут записываться на накопители при последующих циклах записи, а будет записываться лишь ссылка на те данные, что уже записаны. Дедупликация бывает файловая и аппаратная.
В случае с файловой дедупликацией, операционная система отслеживает полностью идентичные файлы и хранит только одну копию этих файлов. Например, когда сотрудник внутри организации делает рассылку с вложением, на почтовом сервере Exchange это вложение сохраняется в единственном экземпляре. Получатели данного письма при открытии вложения просто перейдут по ссылке на этот файл.
Аппаратная дедупликация работает не на уровне идентичных файлов, а на уровне блоков данных. В этом случае, проверкой блоков занимается не операционная система, а контроллер системы хранения.
В системах хранения HPE дедупликация реализована для следующих моделей:
Компрессия (сжатие данных) – еще одна технология, позволяющая экономить объемы хранилища путем уменьшения размеров хранимых данных. В отличие от дедупликации, она не исключает копии, а посредством различных алгоритмов уменьшает размер (производит сжатие) имеющихся данных.
Как и дедупликация, компрессия бывает файловая и аппаратная.
При файловой компрессии, операционная система или специальное ПО пытается найти избыточные фрагменты в составе каждого файла и удалить их, что приведет к уменьшению его общего размера. Например, для текстового файла могут быть убраны ненужные пробелы в конце, а повторяющиеся слова или символы заменены особым, более компактным кодированием. Для изображений удаляются избыточные пиксели, в аудиофайлах исключаются малозаметные для слуха звуковые эффекты.
При аппаратной компрессии происходит сжатие блоков данных по специальным алгоритмам. Аппаратную компрессию выполняет контроллер системы хранения.
Процесс компрессии может происходить с потерями (англ. lossy), либо без потерь (англ. lossless). В первом случае исходные данные уже не могут быть полноценно восстановлены из сжатых данных. Такие результаты допустимы при сжатии изображений или аудио, где небольшое снижение качества является приемлемым. Во втором случае возможность восстановления предусматривается, что является предпочтительным для корпоративных СХД, хранящих важные данные.
Как правило, в системах хранения, поддерживающих и дедупликацию и компрессию, для оптимального использования вычислительных ресурсов вначале выполняется дедупликация, а затем – компрессия, которая затрагивает только оставшиеся данные и не применяется к тем данным, которые все равно будут удалены дедупликацией.
В системах хранения HPE реализация аппаратной компрессии в ближайшем будущем предполагается для 3PAR StoreServ.
Дедупликация и компрессия могут происходить в режиме реального времени (англ. inline), либо в режиме последующей обработки (англ. post-process). В первом случае данные подвергаются обработке, еще находясь в памяти, и уже затем записываются на накопители. Этот метод обеспечивает экономию места и меньшую нагрузку на дисковую подсистему, однако нагрузка на вычислительные ресурсы является существенной. Во втором случае данные записываются на накопители без изменений, а затем подвергаются дедупликации или компрессии согласно установленному расписанию. Это обеспечивает экономию вычислительных ресурсов и в некоторых случаях ускоряет первоначальную запись данных, однако требует больше места на дисках.
Важно отметить, что эффективность дедупликации и компрессии напрямую зависит от состава и структуры конкретных данных, к которым планируется применять указанные технологии. К примеру, для компрессии хорошо подходят транзакционные БД, где в рамках каждого экземпляра базы часто встречаются повторяющиеся последовательности данных. Дедупликация результативна в средах виртуализации и VDI, в которых попадается множество очень похожих файлов виртуальных машин. В некоторых же случаях, положительного эффекта от дедупликации и компрессии может не быть вовсе или он будет минимальным.
Количественным показателем эффективности указанных технологий в каждом конкретном случае является коэффициент дедупликации или компрессии, который записывается в формате A:B. Данное выражение показывает отношение объема, который должен был быть занят на СХД без учета действия технологий (значение A), к тому объему, который оказался реально занят после применения дедупликации или компрессии (значение B). Например, при коэффициенте дедупликации 2:1 данные, имеющие объем 2 ТБ, после применения технологии займут на СХД в 2 раза меньше места – лишь 1 ТБ.
Сетевой RAID по принципу своей работы аналогичен классическому RAID, только его элементами являются не отдельные диски, а отдельные контроллеры. Тома (LUN) обслуживаются всеми участвующими контроллерами, при этом уровень сетевого RAID мы можем задавать на уровне конкретного тома. К примеру, в рамках одного кластера для первого тома мы можем настроить сетевой RAID 10, а для второго – сетевой RAID 0. После этого, блоки данных в указанных томах будут записываться и распределяться соответственно уровню сетевого RAID.
В настоящее время, для SV3200 доступны следующие уровни сетевого RAID: 0, 10. Уровень 0 представляет собой обычное чередование записываемых блоков данных между контроллерами, и может быть реализован как в кластере, так и для единственной SV3200 (для двух ее контролеров). В случае сетевого RAID 10 при записи данных происходит чередование записываемых блоков между двумя контроллерами одной, а затем зеркалирование записанных данных на другую СХД. Данные уровни в сетевом RAID работают точно так же, как и в обычном (см. рисунок).

В 10м поколении серверов ProLiant HPE реализовал новые, не использовавшиеся ранее технологии. Это позволило улучшить показатели производительности, надежности и безопасности серверов.
Из основных усовершенствований стоит выделить:

HPE Nimble Storage – семейство систем хранения данных. Отличительные черты этих СХД – частичное (наряду с HDD), либо полное (all-flash) использование SSD накопителей во всех моделях, а также очень высокий уровень надежности. HPE заявляет о доступности Nimble Storage в 99,9999%, что достигается благодаря применению платформы облачной аналитики InfoSight. Относительно недавно была добавлена поддержка линейки продуктов HPE 3PAR в InfoSight.
Данная технология позволяет СХД непрерывно в автоматическом режиме собирать большое количество данных как о собственном состоянии, так и об окружающей инфраструктуре (подключенные сети, серверы, платформы виртуализации). Затем эти показатели отправляются в облачную систему, где с помощью сложных аналитических алгоритмов выявляются текущие проблемы и делаются прогнозы о будущем состоянии инфраструктуры. На основе данных выводов заказчику предоставляются автоматические исправления и рекомендации для администратора СХД. Например, при обнаружении у одного из клиентов проблемы в совместимости микропрограммы контроллеров СХД с приложениями гипервизора система автоматически заблокирует возможность установки данной версии прошивки на СХД у других клиентов, а тем у кого уже установлена схожая конфигурация будет предложен критический апдейт системы.
Такой подход помогает предотвращать сбои до их возникновения, причем во многих случаях без вмешательства администратора. По данным вендора, при использовании InfoSight 86% проблем разрешаются без участия ИТ-службы. Сюда входят инциденты как с самой СХД, так и с окружающей инфраструктурой. Причем по данным HPE, более половины проблем, как правило, не связаны с СХД.
InfoSight позволяет значительно сократить время на поиск проблемных узлов инфраструктуры в случае деградации производительности. Система в удобном графическом виде показывает текущее время отклика и статистику задержек за определенный период по проблемной ВМ не только относительно самой СХД, но и сети передачи данных SAN, а также приложений гипервизора. Отклонение каких-либо показателей в кратчайшие сроки позволит определить «узкое место» инфраструктуры. Не нужно переключаться между несколькими системами мониторинга, все показатели доступны в едином портале, так как InfoSight интегрируется с VmWare VCenter.
Благодаря оценке статистической информации сразу по большому количеству СХД, система позволяет провести более точный сайзинг инфраструктуры, чем это бы делалось в любом оффлайн-сайзере. Тем самым становится возможно более точно строить планы апргрейда, сократив, возможно излишние затраты на покупку ненужных компонентов.

Облачная система InfoSight является единой для заказчиков Nimble Storage по всему миру. Она использует общие базы и машинное обучение на основе уже имеющихся данных для постоянного совершенствования своих прогнозов. Собранные данные хранятся на вычислительных мощностях InfoSight в США.
В процессе диагностики собирается только служебная информация, собственные данные заказчика не затрагиваются.
Информация передается по защищенному SSL каналу. Некоторые примеры передаваемых данных:
Иногда, для устранения определенных проблем требуется снятие содержимого памяти контроллера (core data dump). В полученный снимок могут попасть некоторые пользовательские данные. В такой ситуации заказчик по своему желанию может разрешить передачу снимка в поддержку Nimble Storage. Передача не является обязательной, однако без нее возможности специалистов поддержки по работе над проблемой будут ограничены.
В случае своего согласия, заказчик оформляет письменное разрешение, отправляет его в поддержку Nimble и инициирует передачу снимка. Передача происходит по SSL каналу. HPE обязуется принять все необходимые технические меры для защиты конфиденциальности полученных данных заказчика, такие как контроль и аудит доступа персонала к данным, закрытие внешнего доступа через ACL, антивирусная защита, физическая защита серверных комнат и т.д.
Подключение СХД Nimble Storage к InfoSight осуществляется через сеть управления. Заказчик должен будет открыть следующие порты для исходящего трафика (никаких входящих соединений не требуется):

Технология HPE SmartCache позволяет использовать SSD накопители в качестве дополнительной кэш-памяти. Данное решение применяется в среде DAS (внутренние накопители сервера, либо локально подключенные DAS полки).
SmartCache работает как на чтение, так и на запись. При операциях чтения часто запрашиваемые данные помещаются в кэш из SSD накопителей. Операции записи происходят вначале на SSD-кэш, а затем данные перемещаются на HDD. Благодаря тому, что SSD по сравнению с HDD имеют значительно более высокую производительность, увеличивается скорость работы приложений (по данным HPE – до 4 раз).
SmartCache доступна с контроллерами Smart Array P-класса, которые имеют кэш типа FBWC емкостью не менее 1 Гбайт. Технология может использоваться на серверах 8го и более новых поколений. Настройка производится через средство управления контроллерами Smart Array – HPE Smart Storage Administrator.
SmartCache имеет собственную лицензию, при этом для некоторых контроллеров (например, P816i-a SR Gen.10) она включается по умолчанию, а для других требуется приобретать ее отдельно.

Схема работы файловой системы Nimble Storage

Схема работы Triple+ Parity RAID
В настоящее время, для подключения накопителей в персональных компьютерах, серверах и системах хранения наиболее часто используются 2 интерфейса: SAS и SATA. SAS (англ. Serial Attached SCSI) является преемником параллельной технологии SCSI (англ. Small Computer System Interface). SATA (англ. Serial ATA) – преемник параллельного интерфейса ATA (англ. Advanced Technology Attachment).
В отличие от своих предшественников, протоколы SAS и SATA предусматривают последовательную передачу данных, то есть вся информация передается единым потоком (в параллельных технологиях задействуется множество потоков). Последовательная передача данных позволяет достичь гораздо более высоких скоростей, чем параллельная. Кроме того, в протоколах SAS и SATA используется тип соединения «точка-точка» между контроллером и оконечным устройством, то есть каждый накопитель имеет полную полосу пропускания. В случае SCSI полоса пропускания общая, и она делится между всеми подключенными устройствами.
SAS по сравнению с SATA предоставляет более высокую пропускную способность и расширенную функциональность, а потому накопители на его основе чаще используются в серверах и системах хранения корпоративного класса. SATA, с другой стороны, имеет более низкую стоимость и применяется в большинстве персональных компьютеров, серверов и систем хранения начального уровня. Основные различия между протоколами:
| SATA | SAS | |
| Пропускная способность | 6 Гбит/с (SATA III) | 12 Гбит/с (SAS-3) ) |
| Набор команд | ATA | SCSI |
| Порты | 1 полудуплексный* | 2 полнодуплексных* |
| Глубина очереди | До 32 команд | До 254 команд |
| Длина кабелей | До 1 м (2 м для eSATA**) | До 10 м |
| Возможности расширения | До 15 устройств на 1 порт с использованием SATA мультипликатора | Более 65 тыс. устройств на 1 порт с использованием SAS расширителей |
| Обратная совместимость | SATA контроллер не поддерживает SAS накопители | SAS контроллер поддерживает SATA накопители |
| Дополнительные функции | Нет | Технология Multipath I/O, позволяющая подключать накопитель по 2 каналам (через 2 порта) и осуществлять резервирование путей / балансировку нагрузки Технология проверки контрольных сумм T.10 при записи данных Технология зонинга T.10, позволяющая разбить домен SAS на зоны для удобства настройки и управления (по аналогии с VLAN) |
* полудуплексный режим работы – возможность в определенный момент времени вести только прием, либо только передачу; полнодуплексный – возможность вести прием и передачу одновременно
** eSATA – англ. External SATA, интерфейс SATA для подключения внешних устройств
Общий обзор технологий и программных функций массивов HPE 3PAR StoreServ:
* КиБ – кибибайт, 1 КиБ равен 1024 байт
** Емкость динамически выделяется только под фактически записываемые данные
Функционал репликации в массивах HPE 3PAR StoreServ носит название Remote Copy (RC). Поддерживаются следующие режимы репликации:
При асинхронном периодическом режиме для репликации используются мгновенные снимки (снапшоты) томов (LUN), создаваемые через заданный интервал времени. На удаленный массив передаются только новые блоки данных, содержащиеся в снимке по сравнению с предыдущим снимком. При асинхронном потоковом режиме новые блоки накапливаются в локальном массиве в течение небольшого периода времени и затем реплицируются на удаленный массив.
С точки зрения среды передачи для репликации поддерживаются следующие варианты:
С точки зрения схем, по которым происходит репликация (топологий) поддерживаются следующие варианты:

Схема репликации Многие-ко-многим для 4 массивов. Каждый массив реплицирует данные на 4 других массива.

Схема репликации SLD
Репликация по указанным схемам может происходить между любыми моделями массивов 3PAR. Например, в рамках одной топологии можно использовать 3PAR 8200, 8450, 20850.

Технология NPAR реализована на некоторых сетевых адаптерах для серверов HPE. Она позволяет разделить пропускную способность порта адаптера на 4 независимые партиции (физические PCI функции). Каждой физической функции назначается собственная полоса пропускания так, чтобы суммарная пропускная способность четырех партиций не превышала пропускную способность того порта, на котором они настроены. К примеру, для порта 10 Гбит/с можно создать партиции 5 Гбит/с, 2 Гбит/с, 1 Гбит/с и 2 Гбит/с.

Для ОС сервера и для подключенного сетевого оборудования каждая физическая функция представляется как отдельный физический порт. Технология NPAR обеспечивает более эффективное использование пропускной способности адаптеров, позволяя задействовать имеющуюся полосу пропускания для большего количества задач. В частности, это актуально в средах VMware, где рекомендуется использовать несколько физических портов под разные типы трафика (Service Console, VMkernel, VM Network).
NVMe (англ. Non-Volatile Memory Express) – протокол передачи данных для SSD накопителей, подразумевающий непосредственное подключение накопителя к шине PCIe*. Данный стандарт был разработан с целью преодоления ограничений, присущих интерфейсам SATA и SAS, которые ориентированы на работу с HDD и зачастую не позволяют раскрыть потенциал производительности SSD. Вследствие недостаточной пропускной способности и глубины очереди традиционные интерфейсы могут стать «узким местом» и причиной задержек между мощными вычислительными ресурсами и построенной на SSD подсистемой хранения.
Пропускная способность интерфейса NVMe зависит от количества используемых линий PCIe. Максимально может использоваться 16 линий, и при полосе пропускания 1 Гбит на линию для PCIe 3.0 пропускная способность интерфейса будет составлять 16 Гбит (против 6 Гбит для SATA и 12 Гбит для SAS). Кроме того, NVMe предусматривает одновременную организацию нескольких (до 65 000) очередей с глубиной до 65 000 команд (в отличие от SATA и SAS, где очередь только одна с 32 и 254 командами соответственно).
SSD накопители, работающие по протоколу NVMe, имеют несколько возможных форм-факторов и способов подключения. Во-первых, они могут быть выполнены в формате PCIe карты расширения и устанавливаться в стандартный слот PCIe.

NVMe SSD накопитель в формате карты расширения PCIe
Во-вторых, они могут иметь формат карты M.2 и устанавливаться в специальный слот M.2.

NVMe SSD накопитель в формате M.2

Разъем под M.2 NVMe SSD
В-третьих, они могут иметь форм-фактор SFF накопителя, устанавливаться в SFF корзину для накопителей и подключаться к райзер-плате PCIe (данный формат называется U.2).

NVMe SSD накопитель размером SFF в формате U.2
* PCIe (англ. Peripheral Component Interconnect Express) – высокоскоростная шина с последовательной передачей данных, используемая для подключения компонентов расширения к материнской плате.
Storage Class Memory (память класса хранилища) – семейство технологий энергонезависимой памяти. К Storage Class Memory (SCM) относятся такие технологии, как магниторезистивная оперативная память (англ. Magnetoresistive Random-Access Memory, MRAM), резистивная память с произвольным доступом (англ. Resistive RAM, ReRAM), память на основе фазового перехода (англ. Phase Change Memory, PCM), 3D XPoint от Intel и Micron.
По производительности SCM в несколько раз превосходит стандартные SSD накопители и приближается к оперативной памяти (DRAM). Принципы ее архитектуры отличаются от принятых в классических SSD (NAND), благодаря чему SCM обеспечивает гораздо более низкие задержки и высокую износостойкость. Стоимость SCM решений выше, чем у обычных NAND SSD, но ниже, чем у оперативной памяти DRAM. Предполагается, что SCM устройства смогут устанавливаться в слоты для оперативной памяти DDR4, либо в слоты расширения PCIe и M.2. Во втором случае они будут работать по протоколу NVMe.
В настоящее время, различные производители работают над развитием и продвижением технологий SCM. Примерами конкретных реализаций служат мемристоры HPE, накопители Intel Optane (на основе технологии 3D XPoint), Micron QuantX (на основе технологии 3D XPoint) и Samsung Z-SSD.

SCM решения могут использоваться для размещения наиболее критичных нагрузок в серверах, а также в качестве самого быстрого или кэширующего уровня в системах хранения. Последний подход был реализован HPE в СХД 3PAR StoreServ путем установки в контроллеры массива SSD Intel Optane. По результатам внутренних тестов вендора, это привело к снижению задержек на 50% и увеличению производительности в IOPS на 80% (использовалась двухконтроллерная модель 3PAR 20450 с восемью SSD 15,36 ТБ и одним Intel Optane в каждом контроллере). Данное решение получило название 3PAR 3D Cache. Ожидается, что коммерчески доступным оно станет после того, как Intel наладит производство и поставку SSD Optane в широких масштабах.



