ML и DS оттенки кредитного риск-менеджмента | Компоненты

В предыдущей статье цикла о моделировании в задачах управления кредитным риском (здесь) мы провели обзор трех задач кредитного риск-менеджмента, нашли возможные точки приложения ML и DS к этим задачам и попутно ввели набор терминов для дальнейшей работы.
Сейчас мы расскажем о трех компонентах (PD, LGD, EAD), которые участвуют при расчете ожидаемых потерь: рассмотрим основные драйверы и методологию построения моделей. В конце статьи приведем сводную таблицу с особенностями работы с компонентами на различных этапах разработки, сформированную на основе нашего проектного опыта.
За подробностями добро пожаловать под кат.
PD или как ковер задает стиль всей комнате

Определение дефолта
Начнем с главной компоненты, которую необходимо оценивать (например, в случае базового или продвинутого ПВР) PD (a. k. a. probability of default) – вероятность дефолта клиента. В качестве свидетельства о дефолте клиента могут выступать разные события в кредитной истории. Часто – это просрочка платежа по кредитному договору 90 и более дней.
Для подсчета количества дней просрочки существует два метода: LIFO (last in first out) и FIFO (first in first out) [1]:
Для определения дефолта необходимо задать следующие три атрибута:
Но этого недостаточно для формирования целевого события. У целевого события есть еще один важный атрибут: горизонт сбора информации о дефолте, или горизонт моделирования.
Определение длины горизонта
Информация о дефолте используется для оценки ожидаемых потерь, под которые банк осуществляет резервирование. В этом случае возникает вопрос, а на каком периоде смотреть выходы в дефолт? Важно ли это? С точки зрения бизнеса, важно понимать период планирования, с точки зрения моделей мы хотим выбрать такой период, в котором будет охвачено не менее 80%-90% всех возможных выходов в дефолт для всех открытых и не находящихся в дефолте договоров на текущий момент времени.
Для целей выбора длины горизонта может быть использован винтажный анализ [2]. Он заключается в построении графической аналитики и последующего вывода о данных по ней. График может быть построен так:
При построении графика выше для каждой когорты было рассчитано значение, составляющее 80% от максимального числа наблюдений, вышедших в дефолт, а диапазон полученных значений обозначен серой полосой. По графику можно сделать вывод о том, что оптимальная длина горизонта лежит в интервале 6-8 месяцев.
Сегментирование выборки
Некоторые атрибуты настолько сильно коррелируют с целевой переменной, что вклад остальных практически нивелируется. Это приводит к моделям с плохим ранжированием внутри группы с одинаковым значением «главного» атрибута. Во избежание такой ситуации используют подход сегментации, в рамках которого выборку делят на два или несколько сегментов — по одному на каждое значение «главного» атрибута (драйвера), и для каждого из них строят отдельную модель. В кредитном риске один из таких драйверов – наличие или длительность просрочки по платежу.
Если выборка была разделена на два сегмента по длительности просрочки: сегмент с малой просрочкой и сегмент с большой просрочкой, и второй сегмент достаточно мал, то для него можно сделать простую модель на двух атрибутах: на скоринговом балле модели с малой просрочкой и длительности текущей просрочки. Если результат удовлетворяет всем требованиям валидации, то на нем можно остановиться.
Альтернативно можно разделить выборки на сегменты с просрочками за историю (I) и без просрочек за историю (II).
Необходимое условие для сегментации – достаточное количество дефолтных наблюдений в каждом из сегментов. А для того, чтобы выяснить целесообразность и границы новых сегментов используется roll-rate анализ [3]. Он заключается в разделении выборки на подсегменты на основании значений величины текущей просрочки и сравнении между ними среднего уровня дефолта. Те группы, уровень дефолта которых значимо различается, имеет смысл моделировать по отдельности.
Рассмотрим, например, сегментацию наблюдений по величине просрочки. На картинке ниже в качестве примера выделены следующие 5 сегментов, соответствующих интервалам (бакетам) значений просрочки: 0-4 дня, 5-14 дней, 15-29 дней, 30-59 дней, 60-89 дней. Эти сегменты рассматриваются в нескольких моментах времени: HY1_2015, HY2_2015 — соответственно, первое и второе полугодия 2015 года, HY1_2016, HY2_2016 — соответственно, первое и второе полугодия 2016 года. В процессе анализа нас интересует динамика выхода наблюдений в просрочку более 89 дней, поэтому для каждого из этих сегментов подсчитан процент клиентов, просрочка которых на горизонте наблюдения составила более 89 дней.
По графику можно сделать следующие выводы:
EAD (Деньги в дефолте)
После того, как оценена вероятность дефолта заемщика, ставится вопрос – с какой суммой задолженности заемщик уйдет в дефолт? Эта сумма линейно влияет на размер ожидаемых потерь и, соответственно, объем резервов, и называется exposure at default – требования в дефолте. Итак, EAD – exposure at default – кредитные обязательства по договору на момент дефолта.
Напрямую, как правило, EAD не моделируют. Так как эта величина – денежная, её распределение не носит нормальный характер: в выборке могут присутствовать наблюдения очень большие и очень маленькие, не являющиеся при этом аномалиями. В зависимости от специфики портфеля можно выбрать разные целевые переменные – об этом подробнее будет сказано в последующих статьях цикла, но наиболее широко используемая – CCF – credit conversion factor – коэффициент кредитной конверсии – вычисляется следующим образом:
где:
Balance – сумма средств, которые клиент должен банку в момент наблюдения,
Limit – доступный клиенту лимит,
EAD – сумма средств, который клиент должен банку в момент дефолта.
Получается, что CCF – это та часть доступных на момент наблюдения средств, которая будет использована клиентом к моменту дефолта.
Как и вероятность дефолта, эту величину необходимо прогнозировать заранее. Обычно горизонт прогноза такой же, что и у PD.
Все описанное выше касалось денег до дефолта и во время него. А что происходит сразу после? Об этом компонента LGD.
LGD («Где деньги, Лебовски?»)
Даже в случае дефолта заемщика, часть средств возвращается в банк:
Поскольку временной интервал, на котором происходит т.н. «восстановление» (возвращение долга), может варьироваться поклиентно, возникает необходимость определить длину горизонта восстановления, на котором будет рассчитываться целевая переменная. На длину горизонта влияет в первую очередь доступность достаточного временного периода в данных для моделирования. Обычно длина горизонта лежит в диапазоне 3-5 лет после дефолта.
В общем случае LGD рассчитывается формуле:
где:
Ri – денежный поток от клиента (выплаты, реализация залога и др.), полученный на горизонте восстановления после дефолта,
T – временной период от момента учета возмещения после момента дефолта (в годах).
При расчете денежного потока, который идет на восстановление, обычно используется дисконтирование – механизм учета текущей стоимости денежных средств, полученных на горизонте восстановления. Особенно это актуально на больших горизонтах, когда стоимость денег может существенно изменяться.
Суммы возмещения, затрат и продажи долга при дисконтировании умножаются на «фактор дисконтирования» [4] P(T):
T – временной период от момента учета возмещения после момента дефолта (в годах),
r – ставка дисконтирования.
В качестве r может быть использована, например, процентная ставка по договору.
С компонентами, в первом приближении, понятно: все разные, а моделировать их нужно вместе! Есть ли какой-то подход, который позволит более-менее единообразно отобрать переменные для моделей и выбрать наиболее оптимальную комбинацию? Можно попробовать. О возможном варианте далее.
«Великолепный план, Уолтер … надёжный как … швейцарские часы» или pipeline разработки

Этапы моделирования компонент риска схематично изображены на следующей диаграмме (стрелки – дополнительные итерации, возникающие в процессе разработки):
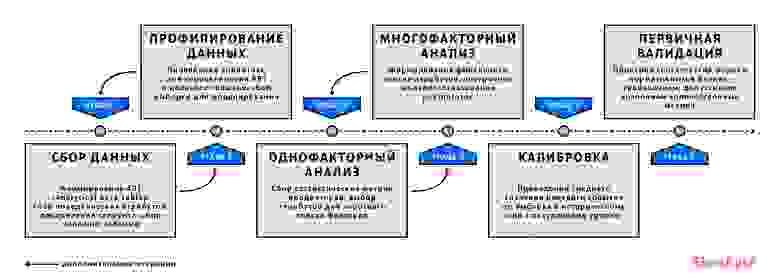
Подготовка данных
Подготовка данных включает в себя формирование трёх сущностей: наблюдения (сегмент), витрина дефолтов, витрина атрибутов,- с единым внешним ключом — ID заемщика или договора и временная метка.
Такая декомпозиция обеспечивает гибкий подход к формированию выборки – легко изменять горизонт, гранулярность наблюдений, определение дефолта и не беспокоиться о корректности сбора атрибутов для итоговой витрины.
Каждое наблюдение – ID заемщика или договора и временная метка; другими словами, нас интересует состояние заемщика или договора на конкретную дату. Обычно используются наблюдения, соответствующие временным срезам, отстоящим друг от друга на равные промежутки времени (например, квартальным).
В случае задачи резервирования объем данных должен включать в себя полный экономический цикл, что составляет примерно 5-7 лет.
Для формирования выборки необходимо учитывать горизонт.

В выборки для разработки и тестирования включаются наблюдения, для которых есть данные о выходе в дефолт на всем горизонте, поскольку включение наблюдений, для которых не прошел полный этап сбора (на картинке изображен красным цветом) приведёт к смещению величины уровня дефолта.
Из-за необходимости учитывать период сбора, оптимальная глубина данных составляет 2-3 горизонта наблюдения.
Также, если в модели планируется учесть какого-то рода сезонность — необходимо соответствующим образом выбирать глубину данных и периодичность срезов.
В таблице под катом перечислены основные группы и примеры атрибутов широкого списка переменных.
| Блок атрибутов | ЮЛ/ФЛ | Описание | Примеры |
| Профиль | ЮЛ | Данные, характеризующие компанию | ОКОПФ, ОКВЭД (отрасль), возраст компании, число руководителей. Количество полных лет/месяцев обслуживания в банке. |
| ФЛ | Анкета клиента, социодемографические данные | Семейное положение, пол, возраст, образование Количество полных лет/месяцев обслуживания в банке | |
| Государственные контракты | ЮЛ | Сводные данные по количеству и сумме государственных контрактов компании | Количество/сумма гос. контрактов за период. Динамика данных показателей. |
| ФЛ | — | — | |
| Арбитражные дела | ЮЛ | Сводные данные по количеству и сумме арбитражных дел, в которых компания принимала участие. | Количество/сумма арбитражных дел компании в качестве ответчика/истца/третьего лица за период. Динамика данных показателей. |
| ФЛ | Сводные данные по количеству и сумме арбитражных дел, в которых клиент принимал участие. | Количество/сумма арбитражных дел клиента в качестве ответчика/истца/третьего лица за период. Динамика данных показателей. | |
| Транзакционные агрегаты | ЮЛ | Сводные данные по количеству транзакций и оборотам для клиента | Количество/сумма операций списания/начислений за период. Оборот компании за период. Динамика данных показателей. |
| ФЛ | Сводные данные по количеству транзакций и оборотам для клиента | Количество/сумма операций списания/начислений за период. Оборот собственных средств клиента за период. Динамика данных показателей. | |
| Финансовые показатели | ЮЛ | Данные по финансовым показателям компании | Выручка, активы, общие обязательства EBITDA, OIBDA, Equity, оборачиваемость внеоборотных активов, оборачиваемость кредиторской задолженности и др. фин. показатели за период. Динамика данных показателей. |
| ФЛ | Данные по финансовым показателям клиента | Payment to income (PTI), debt to income (DTI) | |
| Контрагенты | ЮЛ | Взаимодействие с контрагентами, фигурантами списка клиентов с сомнительной репутацией | Флаг наличия транзакций с фигурантами списка клиентов с сомнительной репутацией за период, число уникальных контрагентов за период |
| ФЛ | Взаимодействие с другими ФЛ, входящими в список клиентов с сомнительной репутацией | Флаг наличия транзакций с фигурантами списка клиентов с сомнительной репутацией за период, число уникальных взаимодействий за период | |
| Внешние данные | ЮЛ | БКИ | Агрегированные показатели времени жизни договоров. Количество открытых договоров за период. Динамика открытия договоров. Агрегаты количества просрочек по контрактам за период в разрезе категорий просрочки. |
| ФЛ | БКИ | Агрегированные показатели времени жизни договоров. Количество открытых договоров за период. Динамика открытия договоров. Агрегаты количества просрочек по контрактам за период в разрезе категорий просрочки. | |
| Негативная история | ЮЛ | Попадание в список клиентов с сомнительной репутацией, срабатывание алгоритмов отслеживания мошеннических операций, результаты расследований | Количество срабатываний алгоритмов отслеживания мошеннических операций за период, флаг попадания в список клиентов с сомнительной репутацией |
| ФЛ | Попадание в список клиентов с сомнительной репутацией, срабатывание алгоритмов отслеживания мошеннических операций, результаты расследований | Количество срабатываний алгоритмов отслеживания мошеннических операций за период, флаг попадания в список клиентов с сомнительной репутацией | |
| Группа | ЮЛ | Данные по компаниям, связанных с данной | Вхождение в группу компаний с задолженностью/наличием арбитражных дел/присутствие компаний с высокорискованными ОКВЭДами |
| ФЛ | Данные по клиентам, связанных с данным | Вхождение в группу клиентов с негативной информацией – просрочка, фрод. | |
| Другие продукты | ЮЛ | Данные по другим используемым продуктам банка | Флаг использования других продуктов, количество продуктов, оборот по продуктам. Динамика показателей. |
| ФЛ | Данные по другим используемым продуктам банка | Флаг использования других продуктов, количество продуктов, оборот по продуктам. Динамика показателей. |
Один из способов увеличения интерпретируемости и стабильности модели – это использование в качестве атрибутов не абсолютных значений признаков, а относительных: нормированных, например, на доход (выручку) или отражающих тренд/динамику показателя на временном интервале.
Однофакторный анализ
Целью проведения однофакторного анализа является уточнение широкого списка факторов таким образом, чтобы исключить неподходящие переменные.
Для проведения однофакторного анализа необходимо разбить выборку на выборки для разработки (train) и тестирования (test). Выборка для тестирования может быть сформирована одним из следующих способов:
Стоит отметить, что в идеальном мире (где достаточное число клиентов и дефолтов) корректнее разбивать исходную выборку на три части (разработка, валидация и тестирование). В рамках такого разбиения проведение однофакторного анализа ведется на выборках для разработки и валидации, а итоговое качество отбора оценивается на выборке для тестирования. Для упрощения мы здесь и далее рассматриваем разбиение на train/test.
Многофакторный анализ и финальная модель
Цель многофакторного анализа – построение оптимальной комбинации факторов из списка, образованного на предыдущем шаге, для максимизации предсказательной силы модели при сохранении стабильности.
Процесс многофакторного анализа заключается в построении множества моделей и выборе наилучшей из них. Модели строятся на различных наборах атрибутов из списка, сформированного на этапе однофакторного анализа,
Две самые распространенные модели для прогноза вероятности дефолта – это:
где:
DistrGood – отношение числа недефолтных наблюдений, имевших значение атрибута из данного бина, к общему числу недефолтных наблюдений;
DistrBad – отношение числа дефолтных наблюдений, имевших значение атрибута из данного бина, к общему числу дефолтных наблюдений.
Общие правила для выполнения категоризации атрибутов складываются из экспертных правил (принципы заполнения пропусков, условие монотонности WOE, соответствие логике атрибута) и статистических критериев (достаточность наблюдений в категории).
Одним из недостатков подхода с использованием значений WOE вместо реальных значений атрибута являются потенциально возможные скачки значений вероятности дефолта (PD). Для решения указанной проблемы может использоваться сглаживание порогов функции WOE с целью создания непрерывных «плавных» переходов между соседними значениями WOE. Чаще всего сглаживание может производиться с помощью сигмоиды или гиперболического тангенса.
После описанных выше преобразований над атрибутами модель логистической регрессии строится над преобразованными атрибутами. Для выбора оптимальной комбинации факторов может быть использовано несколько подходов: [6]:
При построении модели в качестве оптимизируемой метрики могут быть использованы информационные критерии (например, SBC [8], AIC [9]). Разбиение атрибутов на группы и расчет значений WOE производится на выборке для разработки, а затем сформированный биннинг и соответствующие ему значения WOE транслируются в выборку для тестирования.
В случае, когда нет требования интерпретируемости, может быть использована модель градиентного бустинга, наиболее часто используется реализация библиотеки Xgboost. В данном случае отсутствует требование к слабой корреляции атрибутов модели. В случае необходимости ограничить набор признаков модели, используется значимость атрибута – его вклад в итоговое качество, оцениваемое коэффициентом Джини, дает не менее 1% или уменьшает функцию потерь на величину, превышающую пороговое значение.
Итоговое качество модели определяется на тестовой выборке. Выборка для тестирования может формироваться тем же способом, что и при проведении однофакторного анализа.
Сводная таблица по компонентам
| PD | LGD | EAD | |
| Целевое событие | Вероятность дефолта (например, просрочка 90+) на горизонте заданной длины | Часть долга, не возвращенная за период восстановления после дефолта | Размер долга, который клиент будет должен на момент дефолта |
| Тип задачи | Бинарная классификация | Регрессия | Регрессия |
| Горизонт | Срок, в течение которого клиент может попасть в дефолт (например, 1 год) | Период восстановления после дефолта (3-5 лет) | Срок, в течение которого клиент может попасть в дефолт (например, 1 год) |
| Глубина данных (оптимальная/минимальная) | Экономический цикл (5-7 лет)/2-3 горизонта выхода в дефолт | Экономический цикл (5-7 лет) / 2-3 горизонта восстановления + 1 горизонт выхода в дефолт (для недефолтных договоров) | Экономический цикл (5-7 лет)/2-3 горизонта выхода в дефолт |
| Алгоритмы | Интерпретируемые – логистическая регрессия, решающие деревья. Неинтерпретируемые – XGBoost, MLP | GLM, логистическая регрессия, деревья решений, цепочно-лестничные методы | GLM, логистическая регрессия |
| Основные драйверы | Время жизни договора, флаг наличия просрочек на некотором периоде, длительность текущей просрочки, оборот собственных средств, утилизация, обеспечение залогами, payment to income (PTI), debt to income (DTI), размер компании (для ЮЛ), отрасль (для ЮЛ) | Количество дней в просрочке, возраст дефолта, наличие других кредитных договоров у данного клиента и его платежное поведение по ним, обеспечение, размер компании | Количество дней в просрочке, размер утилизации на некотором периоде, время жизни договора, размер компании |
| Корректировка в рамках жизненного цикла модели | Калибровка | Калибровка/Downturn factor | Калибровка/Downturn factor |
| Особенные требования к данным | История дефолтов, определение группы связанных лиц, список банкротств | Требуются факты реализации залогов (чаще для ЮЛ), факты продажи и списания кредитов | Определение сегмента для моделирования («лимитных» продуктов), работа с траншами и корректное определение графика платежа по «лимитным» продуктам |
| Архитектура модели | Однокомпонентная – моделируется непосредственно PD в разрезе бизнес или аналитических сегментов | Однокомпонентная [Recovery Rate(RR)/LGD], или двухкомпонентная –(вероятность выздоровления, уровень восстановления (RR)) для двух сегментов (договора в дефолте и не в дефолте) | Однокомпонентная, но через вспомогательную переменную (например, CCF), двухкомпонентная – две вспомогательные компоненты |
| Основная метрика для количественной первичной валидации | Джини, биномиальный тест, тест Херфиндаля (распределение по рейтинговой шкале) | Джини модифицированный, Loss-shortfall, зависимость поведения от возраста дефолта/длительности просрочки | Джини модифицированный |
Выводы
Итак, в статье мы провели детализацию особенностей моделирования компонент ожидаемых потерь: PD, LGD и EAD.
Главный вывод можно сформулировать следующим образом: прежде чем мы дойдем до import xgboost as xgb ML необходимо существенную часть времени потратить на аналитику и учитывать особенности бизнес-процессов при разработке и тестировании модели. Формулу для DS, применительно к нашим компонентам, можно записать в следующем виде:
Однако здесь стоит иметь ввиду два момента. Во-первых, для сегмента физических лиц характерна большая доля ML и автоматизации решений, по сравнению с сегментом юридических лиц. Во-вторых, доля ML вырастает за счет привлечения продвинутых алгоритмов для анализа, например текстовых и геоданных, а также для поиска сложных паттернов поведения клиентов по разнородным источникам.
Авторы статьи: Александр Бородин (abv_gbc), Алиса Пугачёва (alisaalisa),
Артём Савинов (artysav), Илья Могильников (eienkotowaru).
Список использованных терминов и сокращений
СОДЕРЖАНИЕ
Определение
Убыток при дефолте зависит от объекта, поскольку обычно считается, что на такие убытки влияют ключевые характеристики сделки, такие как наличие обеспечения и степень подчиненности.
Как рассчитать LGD
Расчет LGD легко понять с помощью примера: если клиент не выполняет свои обязательства с непогашенным долгом в размере 200000 долларов США, и банк или страхование могут продать ценную бумагу (например, кондоминиум) по чистой цене 160 000 долларов США (включая затраты, связанные с обратная покупка), то LGD составляет 20% (= 40 000 долл. США / 200 000 долл. США).
Расчет LGD с использованием фундаментального подхода (для корпоративных, суверенных и банковских рисков)
Чтобы определить необходимый капитал для банка или финансового учреждения в соответствии с Базель II, учреждение должно рассчитать активы, взвешенные с учетом риска. Это требует оценки LGD для каждого корпоративного, суверенного и банковского риска. Есть два подхода к получению этой оценки: фундаментальный подход и продвинутый подход.
Размещение без залога
В соответствии с фундаментальным подходом BIS предписывает фиксированные коэффициенты LGD для определенных классов необеспеченных требований:
Залог с залогом
* He и * Hc должны быть получены из следующей таблицы стандартных контролирующих стрижек:
Однако при определенных особых обстоятельствах надзорные органы, то есть местные центральные банки, могут решить не применять «стрижки», указанные в рамках комплексного подхода, а вместо этого применить нулевой код H.
Расчет LGD при расширенном подходе (и для розничного портфеля при фундаментальном подходе)
В соответствии с подходом A-IRB и для розничного портфеля в соответствии с подходом F-IRB банк сам определяет соответствующий убыток при дефолте, который будет применяться к каждой подверженности риску, на основе надежных данных и анализа. Анализ должен быть подтвержден как внутри компании, так и со стороны надзорных органов. Таким образом, банк, использующий внутренние убытки с учетом оценок по умолчанию для целей капитала, мог бы дифференцировать убытки с учетом значений по умолчанию на основе более широкого набора характеристик транзакции (например, типа продукта, более широкого диапазона типов обеспечения), а также характеристик заемщика. Ожидается, что эти значения представляют собой консервативный взгляд на долгосрочные средние показатели. Банку, желающему использовать свои собственные оценки LGD, необходимо будет продемонстрировать своему надзорному органу, что он может соответствовать дополнительным минимальным требованиям, относящимся к полноте и надежности этих оценок.
Оценщики стоимости обратной покупки (RVE) оказались лучшим инструментом для оценки LGD. Коэффициент стоимости выкупа представляет собой процент стоимости дома / квартиры (ипотека) или оборудования в данный момент времени по сравнению с его покупной ценой.
LGD спада
Расчет LGD (или LGD спада) ставит серьезные задачи перед разработчиками моделей и практиками. Окончательное урегулирование дефолтов может занять много лет, и окончательные убытки и, следовательно, окончательный LGD не могут быть рассчитаны до тех пор, пока не будет собрана вся эта информация. Кроме того, практикующим специалистам не хватает данных, поскольку реализация BIS II является довольно новой, а финансовые учреждения, возможно, только начали собирать информацию, необходимую для расчета отдельных элементов, из которых состоит LGD: EAD, прямые и косвенные убытки, ценности безопасности и потенциал, ожидаемое восстановление в будущем. Еще одна проблема, и, возможно, самая важная, заключается в том, что определения по умолчанию в разных учреждениях различаются. Это часто приводит к так называемым разным показателям излечения или проценту неудач без потерь. Расчет LGD (среднего) часто состоит из дефолтов с убытками и дефолтов без них. Естественно, когда к выборке наблюдений добавляется больше значений по умолчанию без потерь, LGD становится ниже. Это часто случается, когда определения дефолта становятся более «чувствительными» к ухудшению кредитоспособности или «ранним» признакам дефолта. Когда учреждения используют разные определения, параметры LGD становятся несопоставимыми.
В 2010 году исследователи Moody’s Analytics оценили LGD в соответствии с целевым вероятностным событием, которое должно быть зафиксировано в соответствии с Базелем. Они показывают, что рекомендации по LGD в связи с спадом в Базеле могут быть недостаточно консервативными. Их результаты основаны на структурной модели, которая учитывает систематический риск восстановления.
Исправление различных определений по умолчанию
LGD y = LGD x * (1-коэффициент излечения y ) / (1-коэффициент излечения x )
LGD для конкретной страны
В Австралии пруденциальный регулирующий орган APRA установил временный минимальный LGD спада в размере 20 процентов по ипотечным жилищным кредитам для всех заявителей на продвинутые подходы Базель II. Нижний предел 20 процентов не чувствителен к риску и предназначен для поощрения уполномоченных депозитных учреждений (ADI) к проведению дальнейшей работы, которая, по мнению APRA, будет в среднем ближе к 20 процентам, чем первоначальные оценки ADI.
Важность
LGD требует большего внимания, чем ему уделялось в последнее десятилетие, когда модели кредитного риска часто предполагали, что LGD не зависит от времени. Движение LGD часто приводит к пропорциональному движению необходимого экономического капитала. Согласно BIS (2006) учреждения, внедряющие Advanced-IRB вместо Foundation-IRB, испытают большее уменьшение капитала первого уровня, и внутренний расчет LGD является фактором, разделяющим эти два метода.



